Core configuration
More configurations in redisdoc.com/topic/sentinel
sentinel can monitor multiple master nodes and distinguish them by naming, such as master1, master2
sentinel monitor master1 172.10.0.5 2 sentinel monitor master2 ..
Standard for sentinels to judge the downline of master nodes
#Sentinel will ping each node. If there is still no reply after 30 seconds, it will judge whether to go offline sentinel down-after-milliseconds mymaster 30000
What are subjective offline and objective offline
One sentinel thinks that the master node is offline, which is called "subjective". When n stations think it is offline, it is called "objective". N is the number 2 on the last side of the first point configuration. When offline, failover is enabled.Limit the number of replication initiated to the new node after failover
The sentinel leader does failover work. It will send a command to each slave node to initiate replication to the new master node. This parameter determines whether this step is concurrent or serial.
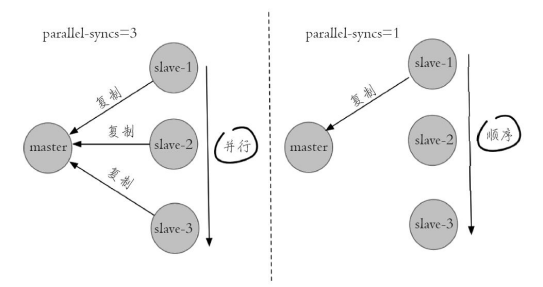
If the master node has too many slave nodes, all slave nodes replicate concurrently, which will put pressure on the master node.#`1 ` means that only one can be copied at a time sentinel parallel-syncs mymaster 1
Configure the password to connect to the monitored master node
sentinel auth-pass <master-name> <password>
sentinel command
Connect any sentinel (no need to enter the container). 22531 is the external mapping port of sentinel 1. 22531 = > 26379
[root@VM-0-8-centos ~]# redis-cli -p 22531 127.0.0.1:22531>
1 displays all monitored masters and their status
SENTINEL masters
127.0.0.1:22531> SENTINEL masters
1) 1) "name"
2) "mymaster" #Custom name
3) "ip"
4) "172.10.0.5"
5) "port"
6) "6379"
..Displays the information and status of the specified master
SENTINEL master <master name>
127.0.0.1:22531> SENTINEL master mymaster 1) "name" 2) "mymaster" 3) ...
Displays all slave nodes of the specified master
SENTINEL slaves <master name>
127.0.0.1:22531> SENTINEL slaves mymaster 1) 1) "name" 2) "172.10.0.2:6379" 3) "ip" 4) "172.10.0.2" 5) "port" 6) "6379" ... 2) 1) "name" 2) "172.10.0.4:6379" 3) "ip" 4) "172.10.0.4" ...Returns the ip and port of the specified master., If a failover is in progress or has been completed, the ip and port of the slave promoted to master will be displayed.
SENTINEL get-master-addr-by-name <master name>
127.0.0.1:22531> SENTINEL get-master-addr-by-name mymaster 1) "172.10.0.5" 2) "6379"
The sentinel is forced to perform failover, and the consent of other sentinels is not required. However, the latest configuration will be sent to other sentinels after failover.
SENTINEL failover <master name>
Tip: if the current cli is a sentinel1 node, the sentinel1 node will perform failover.
127.0.0.1:22531> sentinel failover mymaster OK
sentinel1 log
//Command received # Executing user requested FAILOVER of 'mymaster' //Increment the cluster status version number, which will be adopted by the new master selected next. # +new-epoch 4 //Start failover of Redis cluster named "mymaster" # +try-failover master mymaster 172.10.0.5 6379 //Vote for yourself as a leader # +vote-for-leader b0d33c8c68f57a0e3e628bf5cded4419a492177c 4 //The selection of leaders is complete (i.e. myself) # +selected-leader master mymaster 172.10.0.5 6379 //Start looking for a suitable slave in the cluster # +failover-state-select-slave master mymaster 172.10.0.5 6379 //172.10.0.2 selected # +selected-slave slave 172.10.0.2:6379 172.10.0.2 6379 @ mymaster 172.10.0.5 6379 //Send the slaveof no one command to 172.10.0.2 to become the master node * +failover-state-send-slaveof-noone slave 172.10.0.2:6379 172.10.0.2 6379 @ mymaster 172.10.0.5 6379 //Wait for promotion to the master node (wait for other sentinel to confirm the slave) * +failover-state-wait-promotion slave 172.10.0.2:6379 172.10.0.2 6379 @ mymaster 172.10.0.5 6379 //Promotion success (it means that all other sentinel are confirmed to be successful) # +promoted-slave slave 172.10.0.2:6379 172.10.0.2 6379 @ mymaster 172.10.0.5 6379 //Update the configuration information of all slave in the master node # +failover-state-reconf-slaves master mymaster 172.10.0.5 6379 //Send the "slave of" command to the specified slave 172.10.0.4 to follow the new master * +slave-reconf-sent slave 172.10.0.4:6379 172.10.0.4 6379 @ mymaster 172.10.0.5 6379 //The target slave is performing a slaveof operation * +slave-reconf-inprog slave 172.10.0.4:6379 172.10.0.4 6379 @ mymaster 172.10.0.5 6379 //After the target slave configuration information is updated, the leader can start reconfig for the next slave * +slave-reconf-done slave 172.10.0.4:6379 172.10.0.4 6379 @ mymaster 172.10.0.5 6379 //Update configuration completed # +failover-end master mymaster 172.10.0.5 6379 //This failover is complete. //Each sentinel starts to monitor the new master # +switch-master mymaster 172.10.0.5 6379 172.10.0.2 6379 * +slave slave 172.10.0.4:6379 172.10.0.4 6379 @ mymaster 172.10.0.2 6379 * +slave slave 172.10.0.5:6379 172.10.0.5 6379 @ mymaster 172.10.0.2 6379
sentinel2 and sentinel3 logs
# +new-epoch 4 # +config-update-from sentinel b0d33c8c68f57a0e3e628bf5cded4419a492177c 172.10.0.11 26379 @ mymaster 172.10.0.5 6379 # +switch-master mymaster 172.10.0.5 6379 172.10.0.2 6379 * +slave slave 172.10.0.4:6379 172.10.0.4 6379 @ mymaster 172.10.0.2 6379 * +slave slave 172.10.0.5:6379 172.10.0.5 6379 @ mymaster 172.10.0.2 6379 * +convert-to-slave slave 172.10.0.5:6379 172.10.0.5 6379 @ mymaster 172.10.0.2 6379
It can be seen that the sentinel cluster does not vote. sentinel1 directly completes the failover (even if the current primary node is in normal state), and then sends the latest configuration to other sentinels.
Summarize the principle of sentinel
The implementation principle of Sentinel is mainly divided into the following three steps.
Problem detection mainly focuses on three scheduled tasks. These three internal execution tasks can ensure that Sentinel will know immediately if there is a problem.
Finding problems mainly refers to subjective offline and objective offline. When a Sentinel machine finds a problem, it will go offline subjectively, but when multiple sentinels find a problem, it will go offline objectively.
Finding the person to solve the problem mainly focuses on the leader election. How to elect a leader at multiple nodes in Sentinel.
To solve the problem, we mainly talk about failover, that is, how to failover.
Three timed tasks within Sentinel.
Each Sentinel performs Info Replication on the Master and Slave every 10 seconds.
Every 2 seconds, each Sentinel exchanges information (pub/sub) through the channel of the Master node.
ping other sentinels and Redis every 1 second.
The first scheduled task means that Redis Sentinel can make failure judgment and failover for Redis nodes. There are three scheduled tasks within Redis as the basis to find Slave nodes from Info Replication. This command can determine the master-Slave relationship.
The second scheduled task is similar to publishing and subscribing. Sentinel will determine the master-slave relationship and interact through the 'sentinel:hello' channel. Understanding the master-slave relationship can help better automate Redis operation. Then sentinel will tell the system to send messages to other sentinel nodes, and finally reach a consensus. At the same time, sentinel nodes can perceive each other.
The third timing task refers to heartbeat detection for each node and other Sentinel, which is the basis for failure determination.
How sentinel selects the appropriate Slave node
Redis actually has a priority configuration. In the configuration file, the parameter slave priority is the priority configuration of the sell node. If it exists, it returns. If it does not exist, it continues.
When the above priority is not satisfied, Redis will also select the Slave node with the largest copy offset. If it exists, it will return. If it does not exist, it will continue. The reason for choosing the largest offset is that the smaller the offset, the less close it is to the Master data. Now the Master hangs up, indicating that there may be problems with the machine data with a small offset. This is why the Slave with the largest offset is selected.
If the offsets are the same, Redis will select the node with the smallest runid by default.