Foreword
In the web crawler, some websites will set anti crawler measures. The server will detect the number of requests of an IP in unit time. If it exceeds this threshold, it will directly refuse service and return some error messages, such as 403 Forbidden, "your IP access frequency is too high", which means that the IP is blocked, In this case, IP camouflage is required.
Basic principles of agency
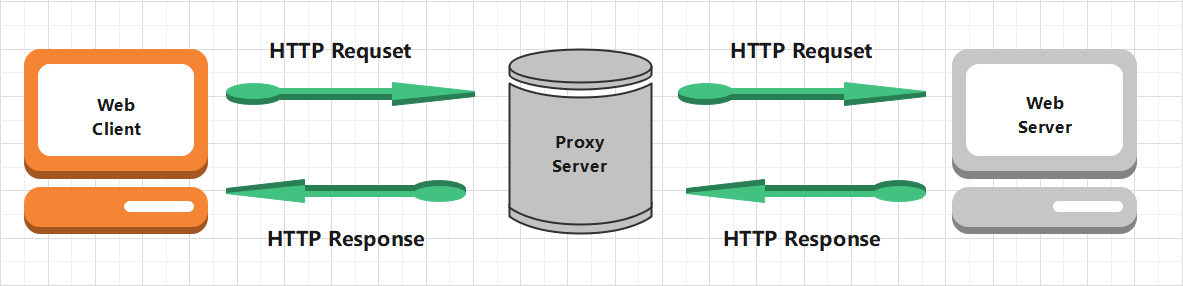
Proxy actually refers to the proxy server. Its function is to proxy the network information of network users and is the transit station of network information. Generally, when requesting access to the website, the Web server sends the request to the Web server first, and then sends the response back to us, as shown in the following figure:

If a proxy server is set, a bridge is actually established between the local machine and the server. At this time, the local machine does not directly send a request to the Web server, but sends a request to the proxy server. The request will be sent to the proxy server, and then the proxy server will send it to the Web server, Then, the proxy server forwards the response returned by the Web server to the local machine, as shown in the figure below. In this way, the Web page can also be accessed normally, but in this process, the real IP recognized by the Web server is no longer our local IP, and IP camouflage is successfully realized. This is the basic principle of proxy.
Role of agency
- Break through their own IP access restrictions and access some sites that cannot be accessed at ordinary times
- Access internal resources of some units or groups
- Improve access speed: usually, the proxy server sets a large hard disk buffer. When external information passes through, it will also be saved in the buffer. When other users access the same information again, the information will be directly taken out of the buffer and transmitted to users to improve access speed
- Hide the real IP as a firewall to protect your network security. In the crawler, you can prevent your IP from being blocked
Agent classification
1. Distinguish according to agreement
- FTP proxy server: it is mainly used to access FTP server. It generally has upload, download and cache functions. The ports are generally 21, 2121, etc
- HTTP proxy server: it is mainly used to access web pages. It generally has content filtering and caching functions. The ports are generally 80, 8080, 3128, etc
- SSL/TLS proxy: it is mainly used to access encrypted websites. It generally has SSL or TLS encryption function (up to 128 bit encryption strength), and the port is generally 443
- RTSP agent: it is mainly used to access Real streaming media server. It generally has cache function, and the port is generally 554
- Telnet agent: it is mainly used for telnet remote control (hackers often use it to hide their identity when invading computers). The port is generally 23
- POP3/SMTP proxy: it is mainly used for sending and receiving right-click in POP3/SMTP mode. It generally has cache function, and the port is generally 110 / 25
- SOCKS proxy: it only delivers data packets, and does not care about specific protocols and usage. Therefore, it is fast. It generally has cache function, and the port is generally 1080. SOCKS proxy protocol is divided into SOCK4 and SOCK5. SOCK4 only supports TCP, while the latter supports TCP and UDP, as well as various authentication mechanisms, server-side domain name resolution, etc.
2. Distinguish according to the degree of anonymity
- Highly anonymous proxy: it will forward the data packet intact. It seems to the server that it is really accessed by an ordinary client, and the recorded IP is the IP of the proxy server
- Ordinary anonymous proxy: it will make some changes on the data packet. The server may find that this is a proxy server, and there is a certain chance to trace the real IP of the client. The HTTP header that the proxy server usually adds is HTTP_VIA and HTTP_X_FORWORD_FOR
- Transparent proxy: not only changes the packet, but also tells the server the real IP of the client. In addition to using caching technology to improve browsing speed and content filtering to improve security, this agent has no other significant role. The most common example is the hardware firewall in the intranet
- Spy agent: refers to a geographic server created by an organization or individual to record data transmitted by users, and then conduct research, monitoring and other purposes
Common proxy settings
- Use the free agent on the Internet: it's best to use the high hidden agent. Here we will crawl all the agents in the agent website below
- Use paid agent service: paid agent will be more stable and effective than free agent, and can be selected according to demand
- ADSL dialing: dial the number once to change the IP, with high stability
Crawling proxy website IP
1. Locate the required web page element node and obtain the content
Take the cloud proxy website as an example. The website address is: Cloud proxy - high quality http proxy IP supply platform / share a large number of free proxy IP every day
Here, I choose to use the Xpath parsing library for matching crawling. Before using it, I need to ensure that the lxml library is installed. Lxml is a parsing library of Python, supports HTML and XML parsing, supports Xpath parsing, and has very high parsing efficiency. The installation method is:
pip3 install lxml
If there is no error, the installation is successful. If there is an error, such as the lack of libxml2 library, you can install it in wheel mode. The recommended link is: https://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml , download the corresponding wheel file, find the locally installed Python version and the corresponding lxml version of the system, such as Windows 64 bit and python 3.6, and download it locally in the following way:
pip3 install lxml-3.8.0-cp36-cp36m-win_amd64.whl
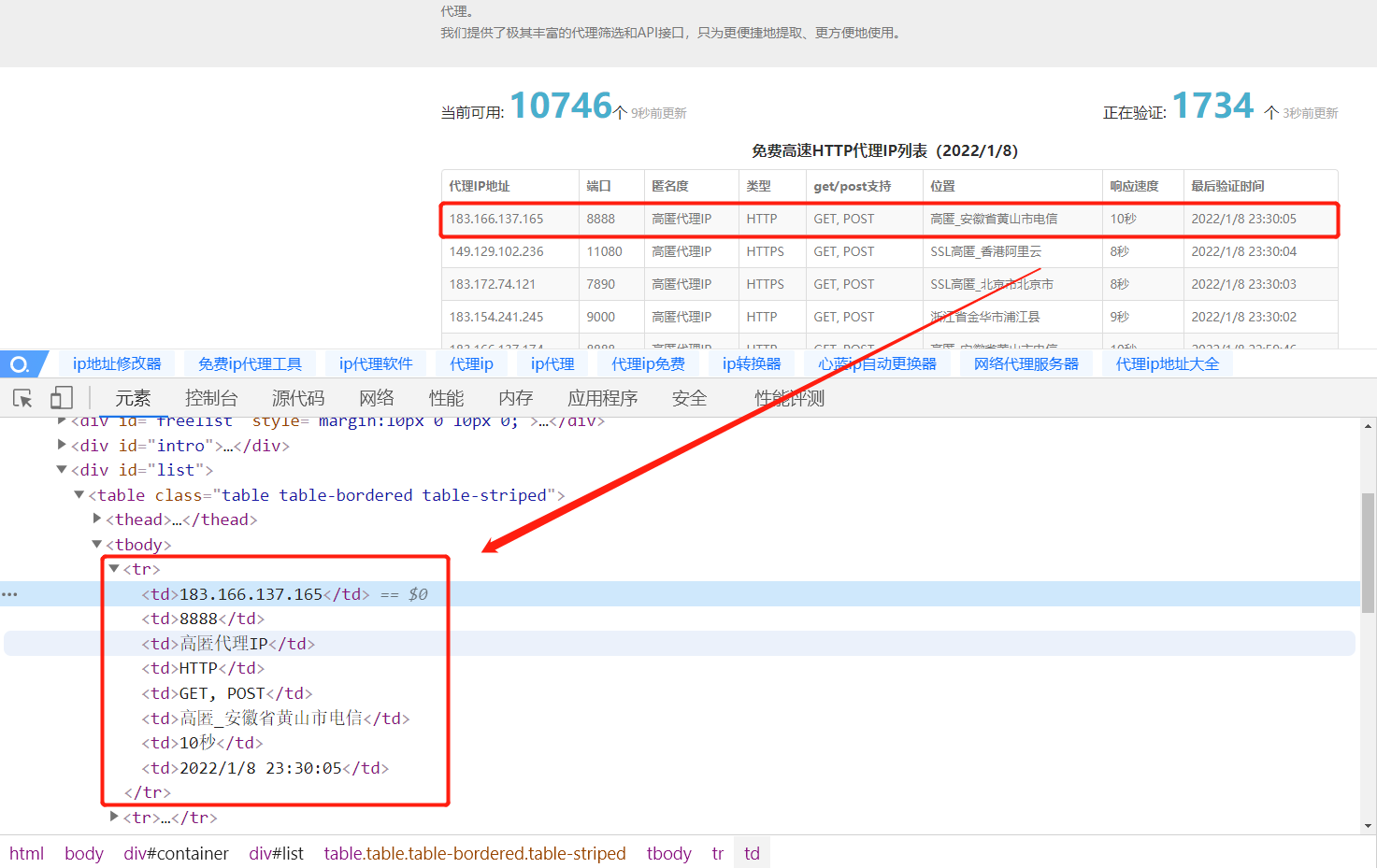
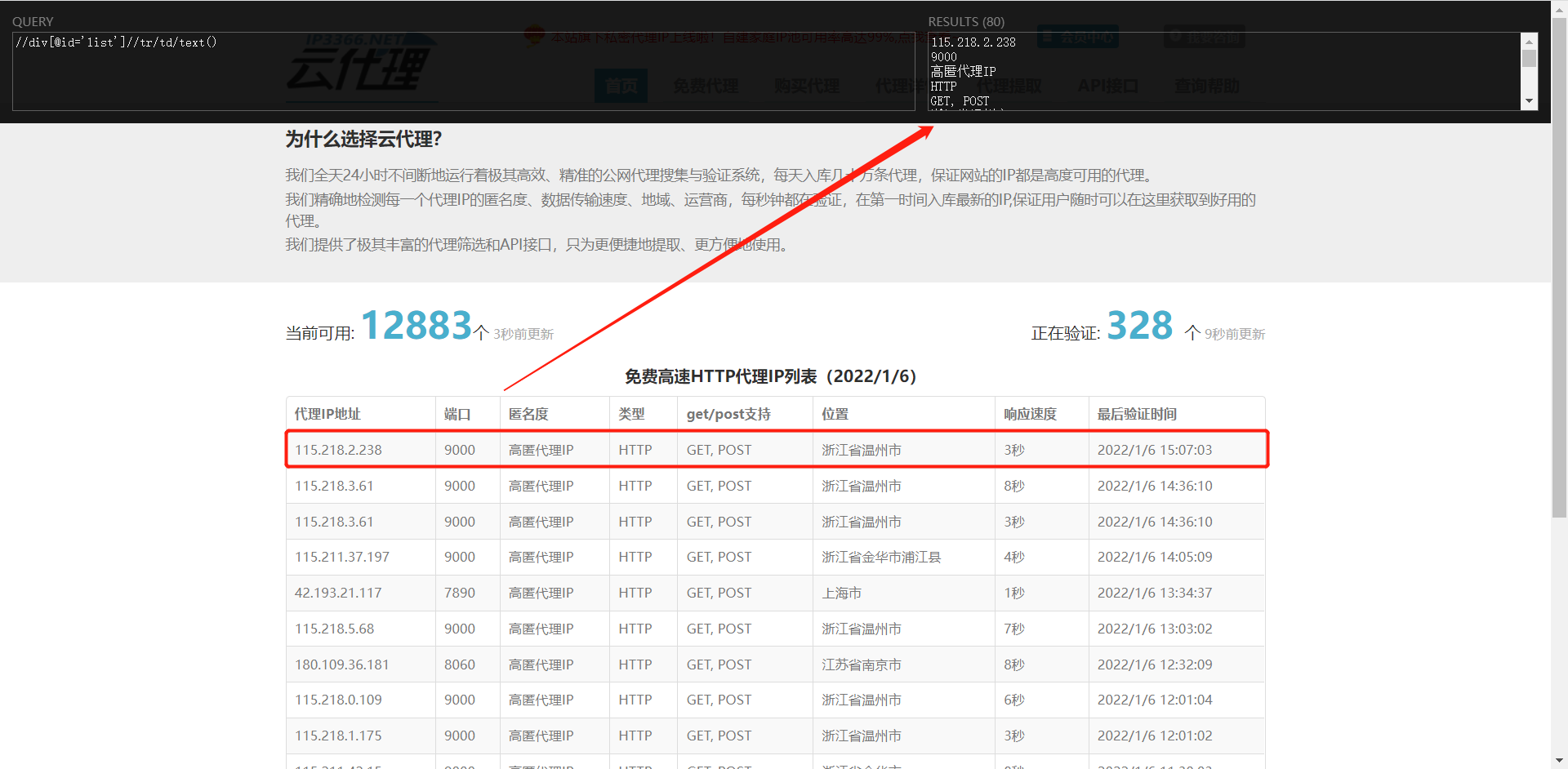
As shown in the figure, all the information we need is in < td > in the < tr > tag, so we can write the Xpath expression:
# Convert html string to_ ELEMENT object
html = etree.HTML(html)
result = html.xpath("//div[@id='list']//tr/td/text()")You can verify whether the browser plug-in Xpath Helper is correct. For the installation and use of relevant plug-ins, please refer to the blog: How to configure and use browser plug-ins, xpath helper and chropath download methods in selenium_ Yy_Rose's blog - CSDN blog_ xpath plugin
2. Connect to MySQL database and create tables
import pymysql
# Get database connection
db = pymysql.connect(host='localhost', user='root', passwd='123456', port=3306
, db='proxy')
# Get cursor
cursor = db.cursor()
# If there is no proxy database, you can perform the following operations
# cursor.execute("create database proxy default character set utf8")
# Delete the previously created table, otherwise the new data will be directly added after the old data, resulting in data redundancy
cursor.execute("drop table proxy_pool")
create_sql = "create table if not exists proxy_pool(" \
"agent IP address varchar(255) not null," \
"port int not null," \
"Anonymity text not null," \
"type varchar(255) not null," \
"support varchar(255) not null," \
"position text not null," \
"response speed text not null," \
"Last verification time varchar(255) not null)engine=innodb default charset=utf8;"
cursor.execute(create_sql)3. Write local txt
proxy_dir = 'proxy_pool.txt'
# Write in append mode
with open(proxy_dir, 'a', encoding='utf-8') as f:
# json. During dumps serialization, ASCII encoding is used by default for Chinese. If you want to output real Chinese, you need to specify ensure_ascii=False
f.write(json.dumps(content, ensure_ascii=False) + '\n')Complete code
# @Author : Yy_Rose
import requests
from lxml import etree
import json
from requests.exceptions import RequestException
import time
import pymysql
# Get database connection
db = pymysql.connect(host='localhost', user='root', passwd='123456', port=3306
, db='proxy')
# Get cursor
cursor = db.cursor()
# If there is no proxy database, you can perform the following operations
# cursor.execute("create database proxy default character set utf8")
# Delete the previously created table, otherwise the new data will be directly added after the old data, resulting in data redundancy
cursor.execute("drop table proxy_pool")
create_sql = "create table if not exists proxy_pool(" \
"agent IP address varchar(255) not null," \
"port int not null," \
"Anonymity text not null," \
"type varchar(255) not null," \
"support varchar(255) not null," \
"position text not null," \
"response speed text not null," \
"Last verification time varchar(255) not null)engine=innodb default charset=utf8;"
# Perform database operations
cursor.execute(create_sql)
# Get the object of HTTPResponse type and build the request header
def get_one_page(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64)'
' AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/86.0.4240.198 Safari/537.36',
'Cookie': 'Hm_lvt_c4dd741ab3585e047d56cf99ebbbe102=1640671968,'
'1641362375;'
' Hm_lpvt_c4dd741ab3585e047d56cf99ebbbe102=1641362386'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
# code
response.encoding = 'gbk'
return response.text
return None
except RequestException:
return None
# Parse get content
def parse_one_page(proxy_pool, html):
# Convert html string to_ ELEMENT object
content = etree.HTML(html)
# The first line is th tag content, so start from the second line
tr_cnotent_list = content.xpath("//div[@id='list']//tr")[1:]
for proxy_infos in tr_cnotent_list:
# The strip() method is used to remove the specified character (space or newline by default) or character sequence at the beginning and end of the string
proxy_pool.append([proxy_infos[0].text.strip(),
proxy_infos[1].text.strip(),
proxy_infos[2].text.strip(),
proxy_infos[3].text.strip(),
proxy_infos[4].text.strip(),
proxy_infos[5].text.strip(),
proxy_infos[6].text.strip(),
proxy_infos[7].text.strip()])
ip = proxy_infos[0].text.strip()
port = proxy_infos[1].text.strip()
anonymity = proxy_infos[2].text.strip()
ip_type = proxy_infos[3].text.strip()
support_type = proxy_infos[4].text.strip()
position = proxy_infos[5].text.strip()
response_speed = proxy_infos[6].text.strip()
verify_time = proxy_infos[7].text.strip()
# Insert the acquired data into the database
insert_into = (
"INSERT INTO proxy_pool(agent IP address,port,Anonymity,type,support,position,response speed,Last verification time)"
"VALUES(%s,%s,%s,%s,%s,%s,%s,%s);")
data_into = (
ip, port, anonymity, ip_type, support_type, position,
response_speed,
verify_time)
cursor.execute(insert_into, data_into)
# Submit the insert statement to the database
db.commit()
# Write local txt
def wirte_to_txt(content):
proxy_dir = 'proxy_pool.txt'
# Write in append mode
with open(proxy_dir, 'a', encoding='utf-8') as f:
# json. During dumps serialization, ASCII encoding is used by default for Chinese. If you want to output real Chinese, you need to specify ensure_ascii=False
f.write(json.dumps(content, ensure_ascii=False) + '\n')
# Print content to console
def print_list(proxy_list):
for i in range(10):
print(proxy_list[i])
wirte_to_txt(proxy_list[i])
def main(offset):
# Paging crawl
url = 'http://www.ip3366.net/?stype=1&page=' + str(offset)
html = get_one_page(url)
proxy_pool = []
parse_one_page(proxy_pool, html)
print_list(proxy_pool)
num = int(input("Please output how many pages you want to query ip:"))
print("The following is the queried data:")
if __name__ == '__main__':
# There are 10 pages in total and 100 records, and range() is left closed and right open
for page in range(1, num+1):
main(offset=page)
time.sleep(2)
Console printing:
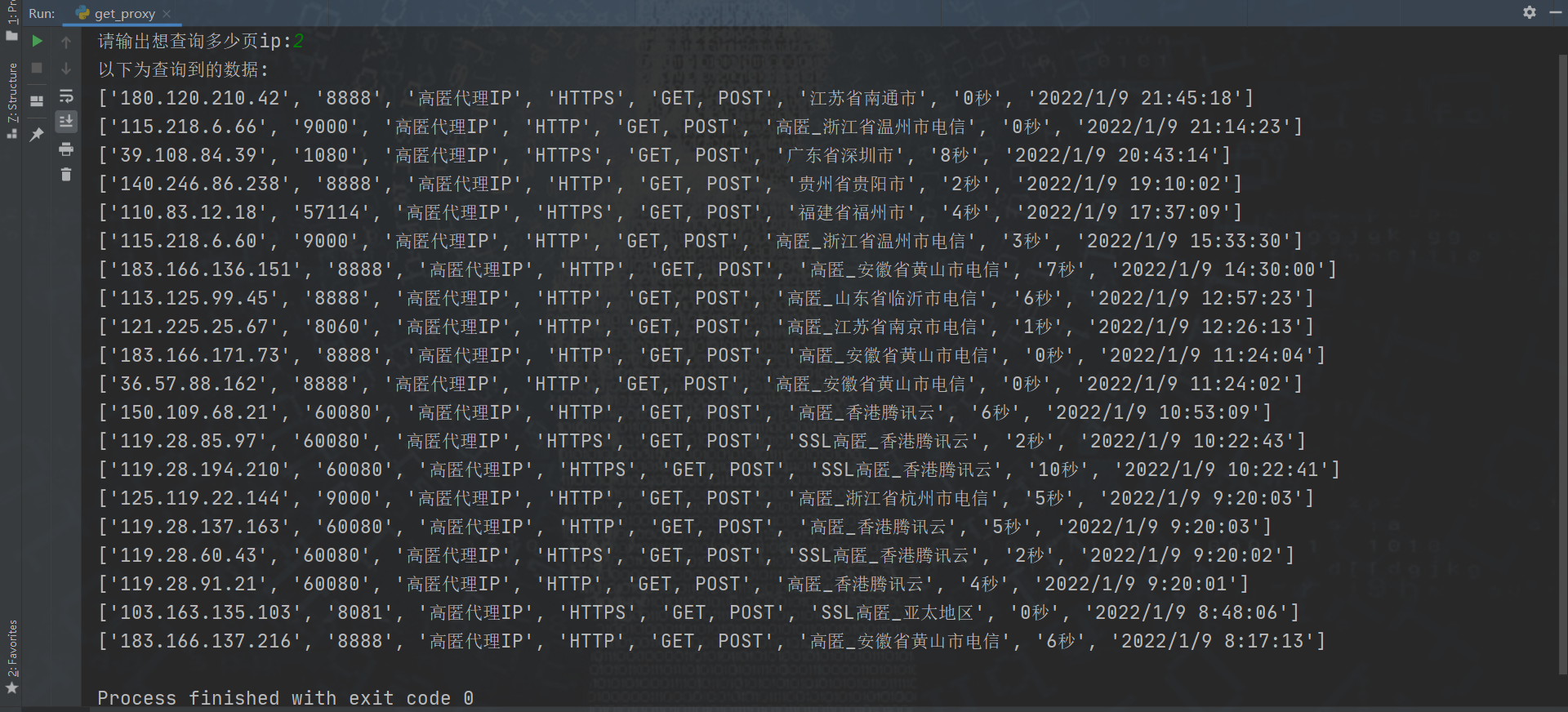 Local txt:
Local txt:
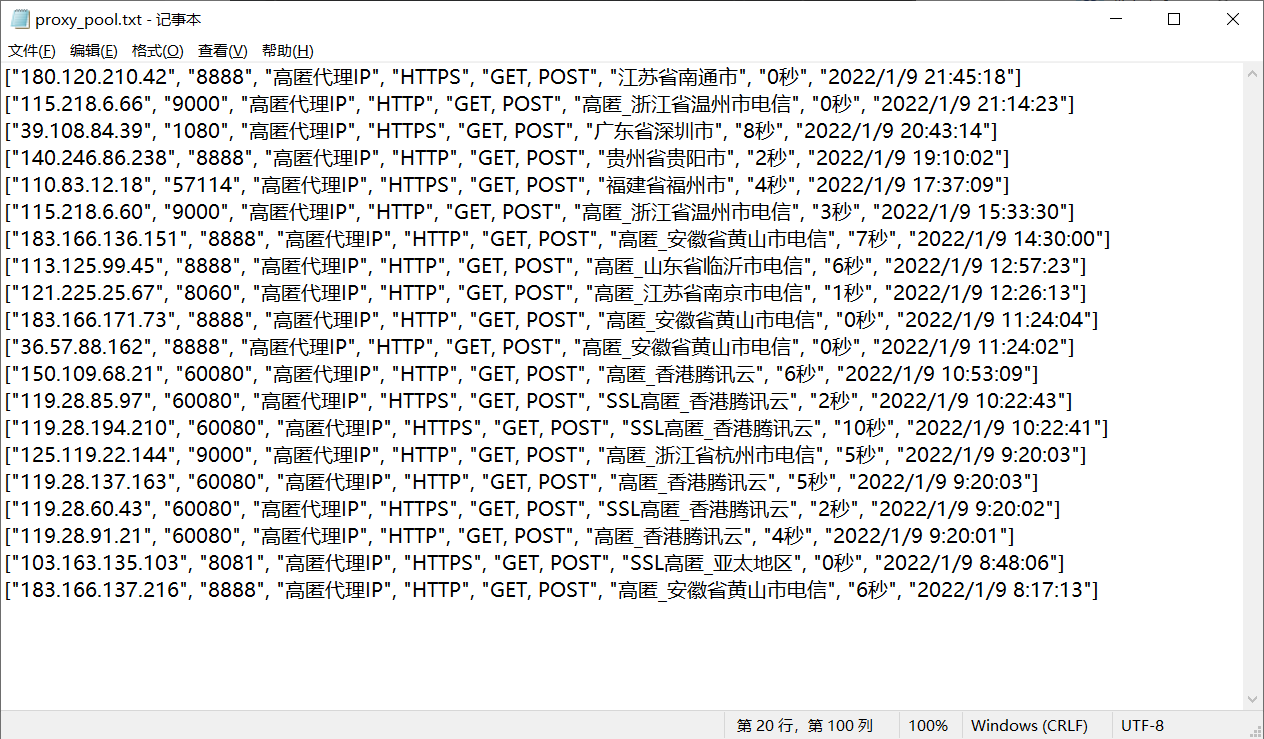
Database effect: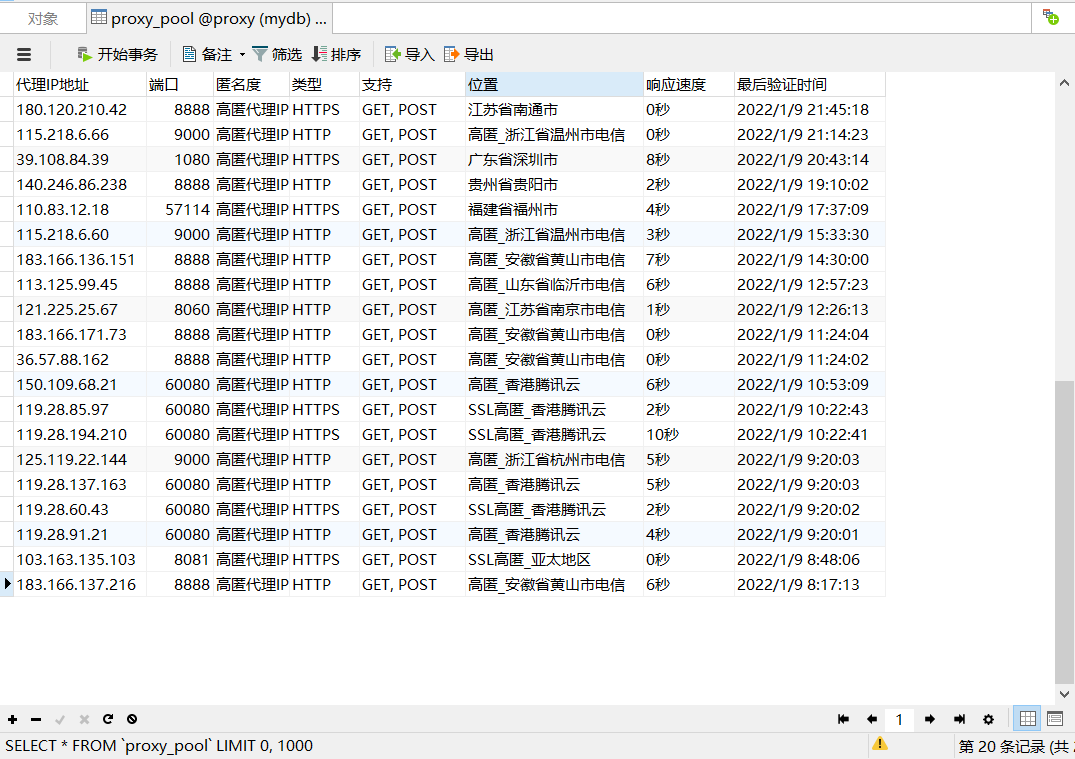
Error reporting during project writing
pymysql. err. Programmingerror: (1064, "you have an error in your SQL syntax; check the manual that responses to your MySQL server version for the right syntax to use near 'get / post supports varchar(255) not null, position text not null, response speed text not' at line 1")
Reason: the field name of the created table conflicts with the MySQL keyword. Change the get/post support to support
TypeError: not all arguments converted during string formatting
Reason: not all parameters are converted during string formatting
insert_into = (
"INSERT INTO proxy_pool(agent IP address,port,Anonymity,type,support,position,response speed,Last verification time)"
"VALUES(?,?,?,?,?,?,?,?);")Analysis possibility I:
What did you start with? Placeholder, which can use the position of the parameter to identify the variable, which is used for variable value transfer, support and last verification. There is more than one element in the time column,? Unable to match exactly, resulting in the number of parameters does not correspond
Just change it to% s,% s means str(), and the string can contain spaces and special characters, which can match the complete elements one by one
insert_into = (
"INSERT INTO proxy_pool(agent IP address,port,Anonymity,type,support,position,response speed,Last verification time)"
"VALUES(%s,%s,%s,%s,%s,%s,%s,%s);")Analysis possibility 2:
import sqlite3
In SQLite database, you can directly use the first method to insert one or more data, which is successfully inserted after testing
import pymysql
The first insertion method is not supported in MySQL database
pymysql.err.InterfaceError: (0, '')
Cause: the database connection was closed after the table was created, resulting in the failure of database operation, and an error occurred when inserting data
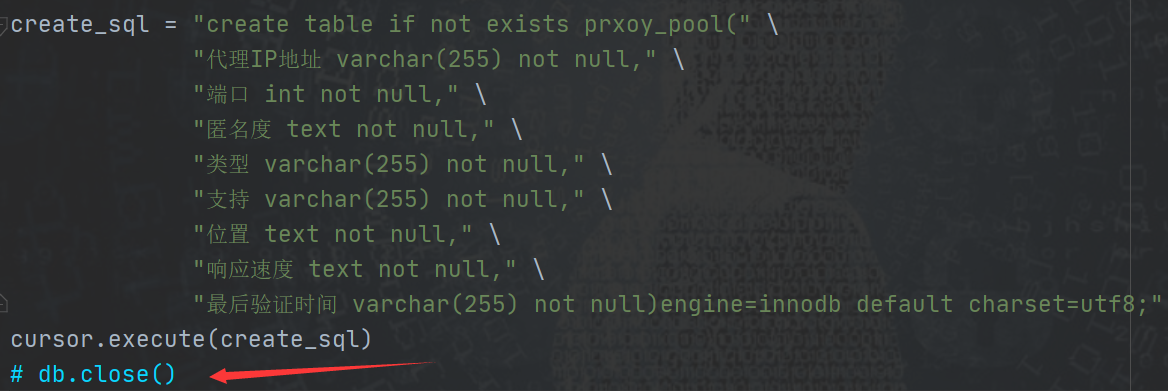
pymysql.err.DataError: (1366, "Incorrect string value: '\xE9\xAB\x98\xE5\x8C\xBF...' for column 'anonymity' at row 1")
Reason: the character set was not set to utf-8 format when creating the database. Just change it to utf8 -- UTF-8 Unicode. The following is the style that caused the error before:
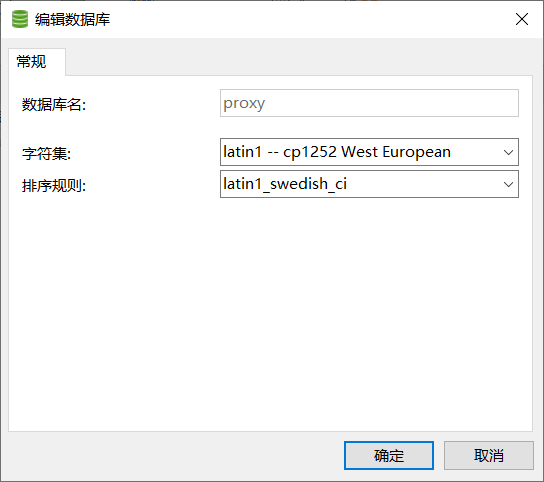
Summary
The above is the relevant knowledge of the agent and how to climb the agent IP list of the agent website. Welcome to comment, correct and exchange~