GitHub 7.5k star volume, PyTorch implementation of various visual transformers, and sorted out
- catalogue
- Blogger introduction
- brief introduction
- Project introduction
- distillation
- Deep ViT
- Threshold value
- Token to token ViT
- CCT
- Cross ViT
- PiT
- LeViT
- CvT
- Twins SVT
- RegionViT
- CrossFormer
- NesT
- MobileViT
- Simple mask image modeling
- Shielded self encoder
- 💫 Click to receive the data directly 💫
catalogue
Blogger introduction

💂 Personal home page: Suzhou program white 💂 Individual communities: CSDN programs across the country 🤟 The author introduces: member of China DBA Alliance (ACDU) and administrator of program ape (yuan) gathering place of CSDN all over the country. Currently engaged in industrial automation software development. Good at C#, Java, machine vision, underlying algorithms and other languages. Qiyue software studio was established in 2019 and Suzhou Kaijie Intelligent Technology Co., Ltd. was registered in 2021 🎗️ Undertake software app, applet, website and other development, application development in key industries (SaaS, PaaS, CRM, HCM, bank core system, regulatory submission platform, system construction, artificial intelligence assistant), big data platform development, business intelligence, app development, ERP, cloud platform, intelligent terminal and product solutions. Testing software product testing, application software testing, testing platform and products, testing solutions. Operation and maintenance database maintenance (SQL Server, Oracle, MySQL), operating system maintenance (Windows, Linux, Unix and other common systems), server hardware equipment maintenance, network equipment maintenance, operation and maintenance management platform, etc. Operation services, IT consulting, IT services, business process outsourcing (BPO), cloud / infrastructure management, online marketing, data collection and labeling, content management and marketing, design services, localization, intelligent customer service, big data analysis, etc.
brief introduction
In the past year or two, Transformer's cross-border CV mission is no longer new.
Since Google proposed Vision Transformer (ViT) in October 2020, various visual transformers have begun to show their skills in the fields of image synthesis, point cloud processing, visual language modeling and so on.
After that, the implementation of Vision Transformer in PyTorch has become a research hotspot. There are many excellent projects in GitHub, and today's introduction is one of them.
The project is called "Vit PyTorch", which is a Vision Transformer implementation. It shows a simple method to use only a single transformer encoder to realize visual classification SOTA results in PyTorch.
The current star volume of the project has reached 7.5k. The creator is Phil Wang. ta has 147 resource libraries on GitHub.
The author of the project also provides a dynamic diagram:

Project introduction
First, let's look at the installation, use, parameters, distillation and other steps of vision transformer pytorch.
The first step is to install:
$ pip install vit-pytorch
The second step is to use:
import torch
from vit_pytorch import ViT
v = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(1, 3, 256, 256)
preds = v(img) # (1, 1000)The third step is the required parameters, including the following:
- image_size: internal. Picture size. If you have a rectangular image, make sure that your image size is the maximum width and height
- patch_size: internal. Number of patches. image_size must be divisible by patch_size. The number of patches is: n = (image_size // patch_size) ** 2, and N must be greater than 16.
- num_classes: internal. Number of classes to classify.
- dim: internal. The last dimension NN of the output tensor after linear transformation Linear(..., dim).
- depth: internal. Number of transformer blocks.
- heads: internal. The number of heads in the multi head attention layer.
- mlp_dim: internal. Dimension of MLP (feedforward) layer.
- channels: integer. The default value is 3. Number of channels for the image.
- dropout: floating between [0, 1], default 0.
- Drop out rate. emb_dropout: floating between [0, 1], default 0.
- Embedded drop out rate. pool: string, cls token pooling or mean pooling.
distillation
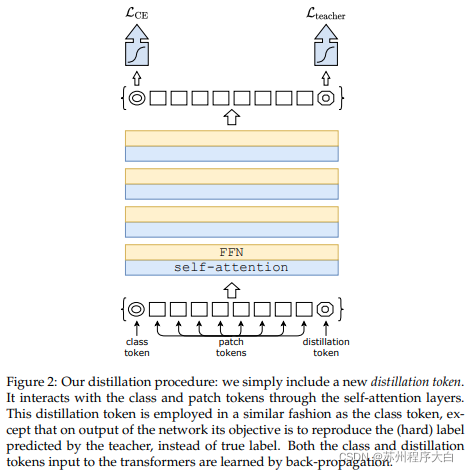
current A paper It shows that distilling knowledge from convolution network to visual converter using distillation token can produce small and efficient visual converter. The repository provides an easy way to distill.
former. Refine from Resnet50 (or any teacher) to visual converter.
import torch
from torchvision.models import resnet50
from vit_pytorch.distill import DistillableViT, DistillWrapper
teacher = resnet50(pretrained = True)
v = DistillableViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 8,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
distiller = DistillWrapper(
student = v,
teacher = teacher,
temperature = 3, # temperature of distillation
alpha = 0.5, # trade between main loss and distillation loss
hard = False # whether to use soft or hard distillation
)
img = torch.randn(2, 3, 256, 256)
labels = torch.randint(0, 1000, (2,))
loss = distiller(img, labels)
loss.backward()
# after lots of training above ...
pred = v(img) # (2, 1000)The DistillableViT class is the same ViT, except how the forward pass is handled, so you should be able to load parameters back to ViT, and you have completed distillation training.
You are OK to_vit uses a convenient method to retrieve the ViT instance on the DistillableViT instance.
v = v.to_vit() type(v) # <class 'vit_pytorch.vit_pytorch.ViT'>
Deep ViT
This article paper It is pointed out that ViT strives to participate in deeper places (the past 12 layers), and it is suggested to mix the attention of each head after softmax as a solution, which is called re attention. The results are consistent with those of NLP Talking Heads The papers are consistent.
You can use it as follows:
import torch
from vit_pytorch.deepvit import DeepViT
v = DeepViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(1, 3, 256, 256)
preds = v(img) # (1, 1000)Threshold value
this paper The difficulty of training visual converter at a deeper level is also pointed out, and two solutions are proposed. First, it recommends per channel multiplication of the output of the residual block. Secondly, it suggests that patches be focused on each other, and only CLS tokens are allowed to focus on the last few layers of patches.
They also added Talking Heads , improvements were noted.
You can use this scheme as follows:
import torch
from vit_pytorch.cait import CaiT
v = CaiT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 12, # depth of transformer for patch to patch attention only
cls_depth = 2, # depth of cross attention of CLS tokens to patch
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1,
layer_dropout = 0.05 # randomly dropout 5% of the layers
)
img = torch.randn(1, 3, 256, 256)
preds = v(img) # (1, 1000)Token to token ViT

this paper It is proposed that the first several layers should down sample the image sequence through expansion, resulting in the overlap of image data in each tag, as shown in the above figure. You can use this variant with ViT as follows.
import torch
from vit_pytorch.t2t import T2TViT
v = T2TViT(
dim = 512,
image_size = 224,
depth = 5,
heads = 8,
mlp_dim = 512,
num_classes = 1000,
t2t_layers = ((7, 4), (3, 2), (3, 2)) # tuples of the kernel size and stride of each consecutive layers of the initial token to token module
)
img = torch.randn(1, 3, 224, 224)
preds = v(img) # (1, 1000)CCT
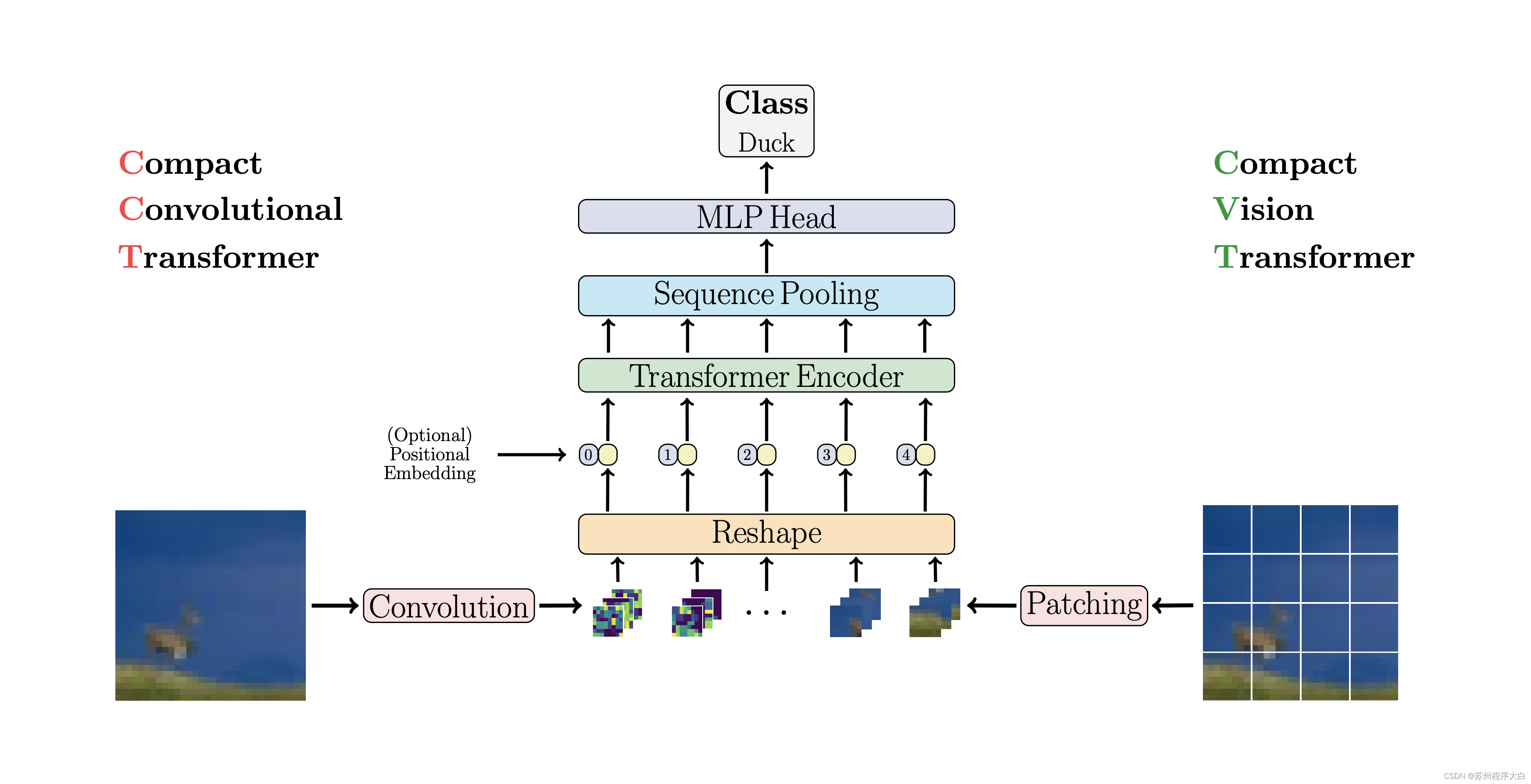
CCT proposes compact converters by using convolution rather than patching and executing sequence pools. This makes CCT have high precision and a small number of parameters.
You can use it in two ways:
import torch
from vit_pytorch.cct import CCT
model = CCT(
img_size=224,
embedding_dim=384,
n_conv_layers=2,
kernel_size=7,
stride=2,
padding=3,
pooling_kernel_size=3,
pooling_stride=2,
pooling_padding=1,
num_layers=14,
num_heads=6,
mlp_radio=3.,
num_classes=1000,
positional_embedding='learnable', # ['sine', 'learnable', 'none']
)Alternatively, you can use one of several predefined models [2,4,6,7,8,14,16] that predefine the number of layers, attention heads, mlp ratios, and embedded dimensions.
import torch
from vit_pytorch.cct import cct_14
model = cct_14(
img_size=224,
n_conv_layers=1,
kernel_size=7,
stride=2,
padding=3,
pooling_kernel_size=3,
pooling_stride=2,
pooling_padding=1,
num_classes=1000,
positional_embedding='learnable', # ['sine', 'learnable', 'none']
)Official repository Include links to trained model checkpoints.
Cross ViT

this paper It is suggested that two visual converters process images of different scales and cross process one at a time. They showed improvements over the basic visual converter.
import torch
from vit_pytorch.cross_vit import CrossViT
v = CrossViT(
image_size = 256,
num_classes = 1000,
depth = 4, # number of multi-scale encoding blocks
sm_dim = 192, # high res dimension
sm_patch_size = 16, # high res patch size (should be smaller than lg_patch_size)
sm_enc_depth = 2, # high res depth
sm_enc_heads = 8, # high res heads
sm_enc_mlp_dim = 2048, # high res feedforward dimension
lg_dim = 384, # low res dimension
lg_patch_size = 64, # low res patch size
lg_enc_depth = 3, # low res depth
lg_enc_heads = 8, # low res heads
lg_enc_mlp_dim = 2048, # low res feedforward dimensions
cross_attn_depth = 2, # cross attention rounds
cross_attn_heads = 8, # cross attention heads
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(1, 3, 256, 256)
pred = v(img) # (1, 1000)PiT
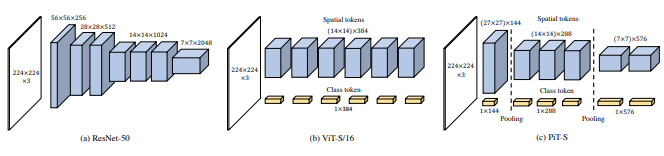
this paper It is recommended that the token be down sampled by using the pooling process of deep convolution.
import torch
from vit_pytorch.pit import PiT
v = PiT(
image_size = 224,
patch_size = 14,
dim = 256,
num_classes = 1000,
depth = (3, 3, 3), # list of depths, indicating the number of rounds of each stage before a downsample
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
# forward pass now returns predictions and the attention maps
img = torch.randn(1, 3, 224, 224)
preds = v(img) # (1, 1000)LeViT
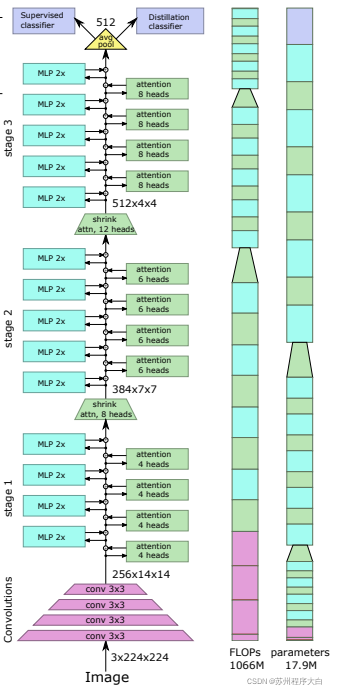
This article paper Some changes are proposed, including (1) convolution embedding instead of block by block projection (2) down sampling in the stage (3) additional nonlinearity in attention (4) two-dimensional relative position deviation instead of initial absolute position deviation (5) batch norm instead of layer norm.
import torch
from vit_pytorch.levit import LeViT
levit = LeViT(
image_size = 224,
num_classes = 1000,
stages = 3, # number of stages
dim = (256, 384, 512), # dimensions at each stage
depth = 4, # transformer of depth 4 at each stage
heads = (4, 6, 8), # heads at each stage
mlp_mult = 2,
dropout = 0.1
)
img = torch.randn(1, 3, 224, 224)
levit(img) # (1, 1000)CvT
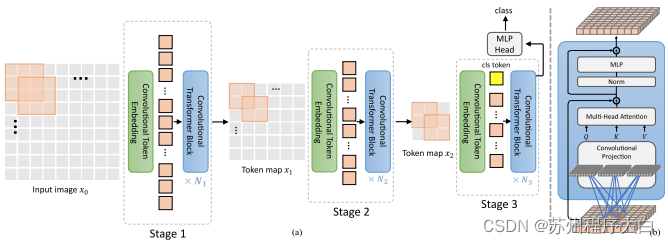
this paper Mixed convolution and attention are proposed. Specifically, convolution is used to embed and down sample images / feature maps in three stages. Depth convolution is also used to project queries, keys, and values for attention.
import torch
from vit_pytorch.cvt import CvT
v = CvT(
num_classes = 1000,
s1_emb_dim = 64, # stage 1 - dimension
s1_emb_kernel = 7, # stage 1 - conv kernel
s1_emb_stride = 4, # stage 1 - conv stride
s1_proj_kernel = 3, # stage 1 - attention ds-conv kernel size
s1_kv_proj_stride = 2, # stage 1 - attention key / value projection stride
s1_heads = 1, # stage 1 - heads
s1_depth = 1, # stage 1 - depth
s1_mlp_mult = 4, # stage 1 - feedforward expansion factor
s2_emb_dim = 192, # stage 2 - (same as above)
s2_emb_kernel = 3,
s2_emb_stride = 2,
s2_proj_kernel = 3,
s2_kv_proj_stride = 2,
s2_heads = 3,
s2_depth = 2,
s2_mlp_mult = 4,
s3_emb_dim = 384, # stage 3 - (same as above)
s3_emb_kernel = 3,
s3_emb_stride = 2,
s3_proj_kernel = 3,
s3_kv_proj_stride = 2,
s3_heads = 4,
s3_depth = 10,
s3_mlp_mult = 4,
dropout = 0.
)
img = torch.randn(1, 3, 224, 224)
pred = v(img) # (1, 1000)Twins SVT

Should writing A hybrid local and global attention is proposed, along with the position coding generator (proposed in) CPVT )And the global average pool to achieve the same results Sven , there is no transfer window, CLS token, nor the additional complexity of location embedding.
import torch
from vit_pytorch.twins_svt import TwinsSVT
model = TwinsSVT(
num_classes = 1000, # number of output classes
s1_emb_dim = 64, # stage 1 - patch embedding projected dimension
s1_patch_size = 4, # stage 1 - patch size for patch embedding
s1_local_patch_size = 7, # stage 1 - patch size for local attention
s1_global_k = 7, # stage 1 - global attention key / value reduction factor, defaults to 7 as specified in paper
s1_depth = 1, # stage 1 - number of transformer blocks (local attn -> ff -> global attn -> ff)
s2_emb_dim = 128, # stage 2 (same as above)
s2_patch_size = 2,
s2_local_patch_size = 7,
s2_global_k = 7,
s2_depth = 1,
s3_emb_dim = 256, # stage 3 (same as above)
s3_patch_size = 2,
s3_local_patch_size = 7,
s3_global_k = 7,
s3_depth = 5,
s4_emb_dim = 512, # stage 4 (same as above)
s4_patch_size = 2,
s4_local_patch_size = 7,
s4_global_k = 7,
s4_depth = 4,
peg_kernel_size = 3, # positional encoding generator kernel size
dropout = 0. # dropout
)
img = torch.randn(1, 3, 224, 224)
pred = model(img) # (1, 1000)RegionViT
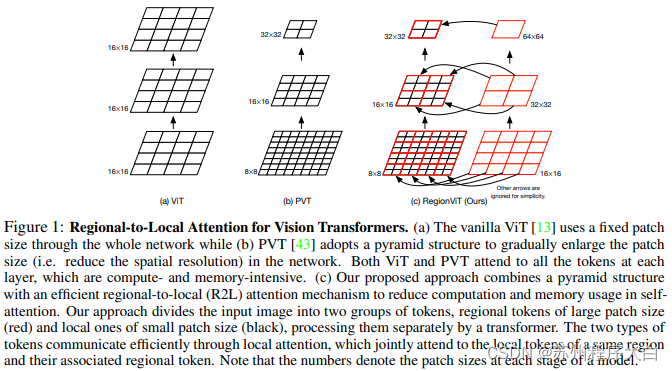
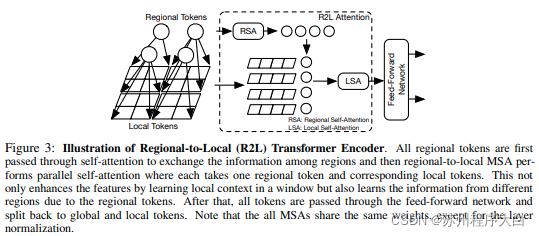
book writing The feature map is divided into local regions, so that the local markers are coordinated with each other. Each local region has its own region token, and then processes all its local tokens and other region tokens.
You can use it as follows:
import torch
from vit_pytorch.regionvit import RegionViT
model = RegionViT(
dim = (64, 128, 256, 512), # tuple of size 4, indicating dimension at each stage
depth = (2, 2, 8, 2), # depth of the region to local transformer at each stage
window_size = 7, # window size, which should be either 7 or 14
num_classes = 1000, # number of output classes
tokenize_local_3_conv = False, # whether to use a 3 layer convolution to encode the local tokens from the image. the paper uses this for the smaller models, but uses only 1 conv (set to False) for the larger models
use_peg = False, # whether to use positional generating module. they used this for object detection for a boost in performance
)
img = torch.randn(1, 3, 224, 224)
pred = model(img) # (1, 1000)CrossFormer
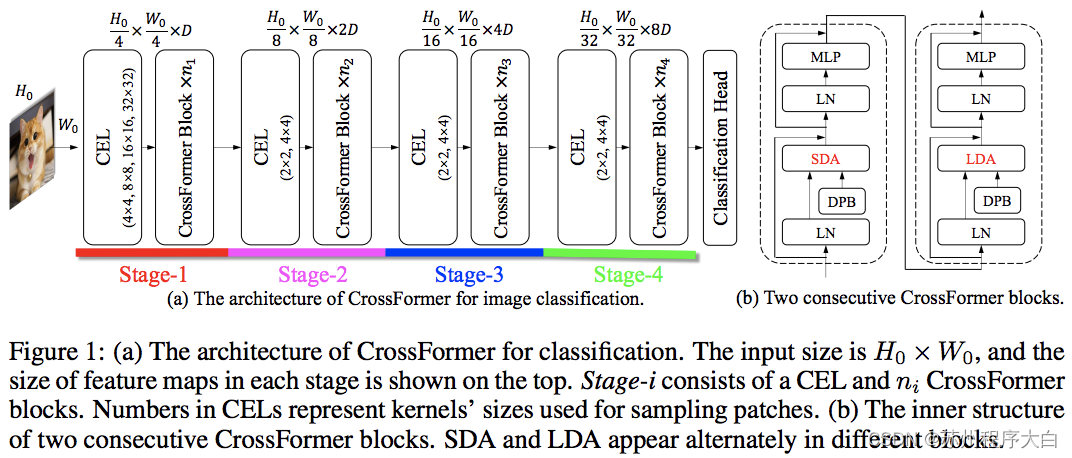
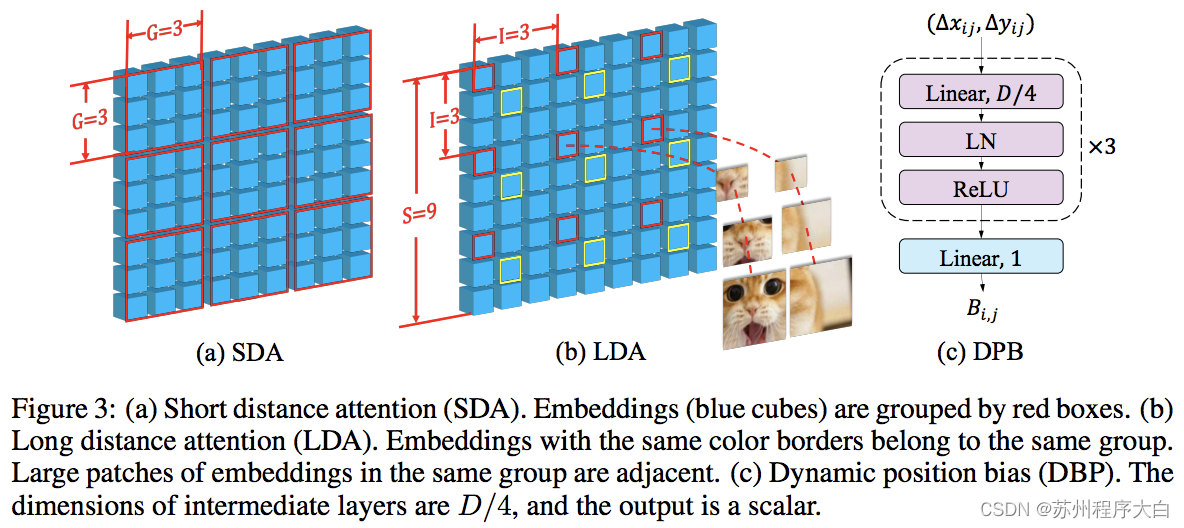
this paper PVT and Eurasia alternately use local and global concerns. Global attention is done across window dimensions to reduce complexity, just like the scheme for axial attention.
They also have a cross scale embedding layer, which they prove to be a common layer that can improve all visual converters. Dynamic relative position deviation is also developed to allow the network to be extended to higher resolution images.
import torch
from vit_pytorch.crossformer import CrossFormer
model = CrossFormer(
num_classes = 1000, # number of output classes
dim = (64, 128, 256, 512), # dimension at each stage
depth = (2, 2, 8, 2), # depth of transformer at each stage
global_window_size = (8, 4, 2, 1), # global window sizes at each stage
local_window_size = 7, # local window size (can be customized for each stage, but in paper, held constant at 7 for all stages)
)
img = torch.randn(1, 3, 224, 224)
pred = model(img) # (1, 1000)NesT
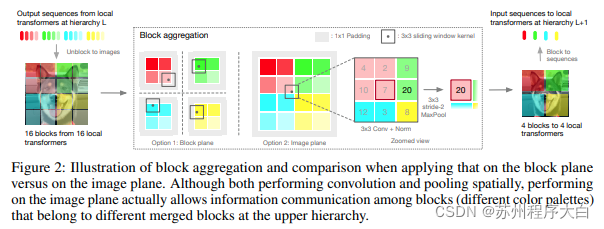
this paper When deciding to process hierarchical images, attention is focused only on local blocks, which aggregate because it moves the hierarchy of tokens. Aggregation is done in the image plane and contains a convolution and subsequent maxpool to allow it to transfer information across boundaries.
You can use the following code (for example, NesT-T)
import torch
from vit_pytorch.nest import NesT
nest = NesT(
image_size = 224,
patch_size = 4,
dim = 96,
heads = 3,
num_hierarchies = 3, # number of hierarchies
block_repeats = (8, 4, 1), # the number of transformer blocks at each heirarchy, starting from the bottom
num_classes = 1000
)
img = torch.randn(1, 3, 224, 224)
pred = nest(img) # (1, 1000)MobileViT

This paper introduces MobileViT, a lightweight and universal vision transformer for mobile devices. MobileViT provides different perspectives for global processing of information using converters.
You can use the following code (for example, mobilevit_xs)
import torch
from vit_pytorch.mobile_vit import MobileViT
mbvit_xs = MobileViT(
image_size = (256, 256),
dims = [96, 120, 144],
channels = [16, 32, 48, 48, 64, 64, 80, 80, 96, 96, 384],
num_classes = 1000
)
img = torch.randn(1, 3, 256, 256)
pred = mbvit_xs(img) # (1, 1000)Simple mask image modeling

This paper presents a simple masking image modeling (SimMIM) scheme, which uses only a linear projection off masking token for the pixel space followed by an L1 loss and the pixel value of the masking patch. The results are competitive with other more complex methods.
You can use it as follows:
import torch
from vit_pytorch import ViT
from vit_pytorch.simmim import SimMIM
v = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 8,
mlp_dim = 2048
)
mim = SimMIM(
encoder = v,
masking_ratio = 0.5 # they found 50% to yield the best results
)
images = torch.randn(8, 3, 256, 256)
loss = mim(images)
loss.backward()
# that's all!
# do the above in a for loop many times with a lot of images and your vision transformer will learn
torch.save(v.state_dict(), './trained-vit.pt')Shielded self encoder

A new paper by Kaiming He proposes a simple automatic encoder scheme, in which the visual converter processes a set of unshielded patches, while the smaller decoder attempts to reconstruct the shielded pixel values.
DeepReader quick paper review
AI coffee break with Letitia
You can use it with the following code
import torch
from vit_pytorch import ViT, MAE
v = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 8,
mlp_dim = 2048
)
mae = MAE(
encoder = v,
masking_ratio = 0.75, # the paper recommended 75% masked patches
decoder_dim = 512, # paper showed good results with just 512
decoder_depth = 6 # anywhere from 1 to 8
)
images = torch.randn(8, 3, 256, 256)
loss = mae(images)
loss.backward()
# that's all!
# do the above in a for loop many times with a lot of images and your vision transformer will learn
# save your improved vision transformer
torch.save(v.state_dict(), './trained-vit.pt')