◆ summary
In this paper, the author tries to combine non blocking and blocking queues to become a new combined thread pool. The thread pool has a shared task queue, and each worker thread has a work task queue. Tasks submitted by thread pool users are first saved in the shared task queue. The scheduler thread of the thread pool assigns the tasks in the shared task queue to the work task queue of the worker thread, and the worker thread obtains and executes the tasks from the work task queue.
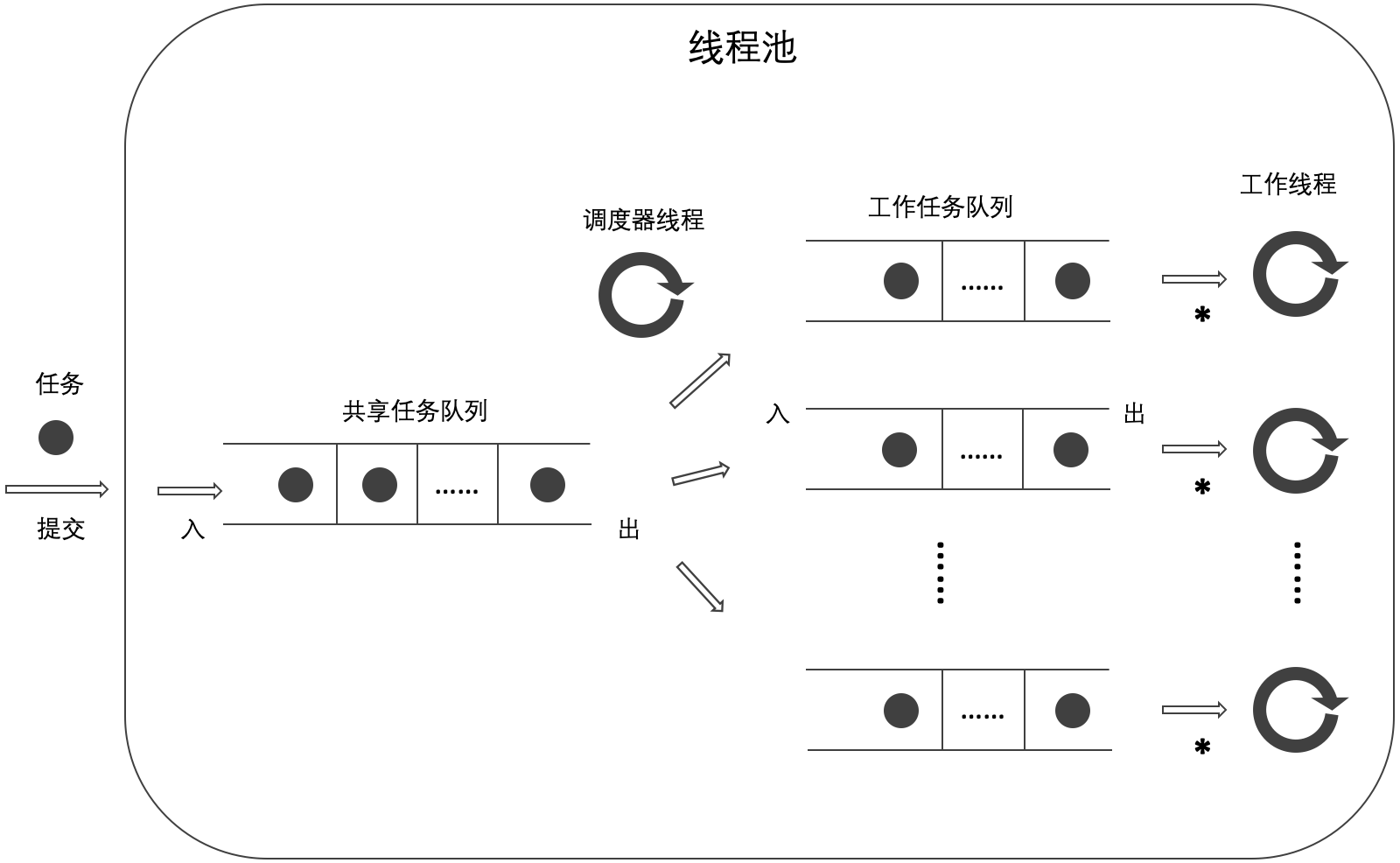
[note] in the figure, * indicates that the way in which a worker thread obtains a task will vary depending on the type of work task queue.
The author adopts different types of shared task queue and work task queue, which are combined into three schemes,
| No | Shared task queue type | Work task queue type |
|---|---|---|
| 1 | block | Blocking exclusive |
| 2 | block | Non blocking mutual assistance |
| 3 | block | Non blocking mutual aid 2B |
The following description of this thread pool will briefly describe Blocking shared task queue , Block exclusive task queue ,Non blocking task queue and Non blocking task queue Content of the. If there is any ambiguity, please refer to the blog corresponding to the link first.
◆ implementation
The following code gives the implementation of scheme 1, (blocking_shared_blocking_unique_pool.h)
class Thread_Pool {
private:
struct Task_Wrapper { ...
};
atomic<bool> _suspend_;
atomic<bool> _done_;
Blocking_Queue<Task_Wrapper> _poolqueue_; // #1
thread _scheduler_; // #3
unsigned _workersize_;
thread* _workers_;
Blocking_Queue<Task_Wrapper>* _workerqueues_; // #2
void work(unsigned index) {
Task_Wrapper task;
while (!_done_.load(memory_order_acquire)) {
_workerqueues_[index].pop(task); // #7
task();
while (_suspend_.load(memory_order_acquire))
std::this_thread::yield();
}
}
void stop() {
size_t remaining = 0;
_suspend_.store(true, memory_order_release);
remaining = _poolqueue_.size(); // #8
for (unsigned i = 0; i < _workersize_; ++i)
remaining += _workerqueues_[i].size();
_suspend_.store(false, memory_order_release);
while (!_poolqueue_.empty())
std::this_thread::yield();
for (unsigned i = 0; i < _workersize_; ++i)
while (!_workerqueues_[i].empty())
std::this_thread::yield();
std::fprintf(stderr, "\n%zu tasks remain before destructing pool.\n", remaining);
_done_.store(true, memory_order_release);
_poolqueue_.push([] {}); // #9
for (unsigned i = 0; i < _workersize_; ++i)
_workerqueues_[i].push([] {});
for (unsigned i = 0; i < _workersize_; ++i)
if (_workers_[i].joinable())
_workers_[i].join();
if (_scheduler_.joinable())
_scheduler_.join();
delete[] _workers_;
delete[] _workerqueues_;
}
void schedule() {
Task_Wrapper task;
while (!_done_.load(memory_order_acquire)) {
_poolqueue_.pop(task); // #6
_workerqueues_[rand() % _workersize_].push(std::move(task));
}
}
public:
Thread_Pool() : _suspend_(false), _done_(false) {
try {
_workersize_ = thread::hardware_concurrency();
_workers_ = new thread[_workersize_]();
_workerqueues_ = new Blocking_Queue<Task_Wrapper>[_workersize_](); // #4
for (unsigned i = 0; i < _workersize_; ++i)
_workers_[i] = thread(&Thread_Pool::work, this, i);
_scheduler_ = thread(&Thread_Pool::schedule, this); // #5
} catch (...) { ...
}
}
...
};
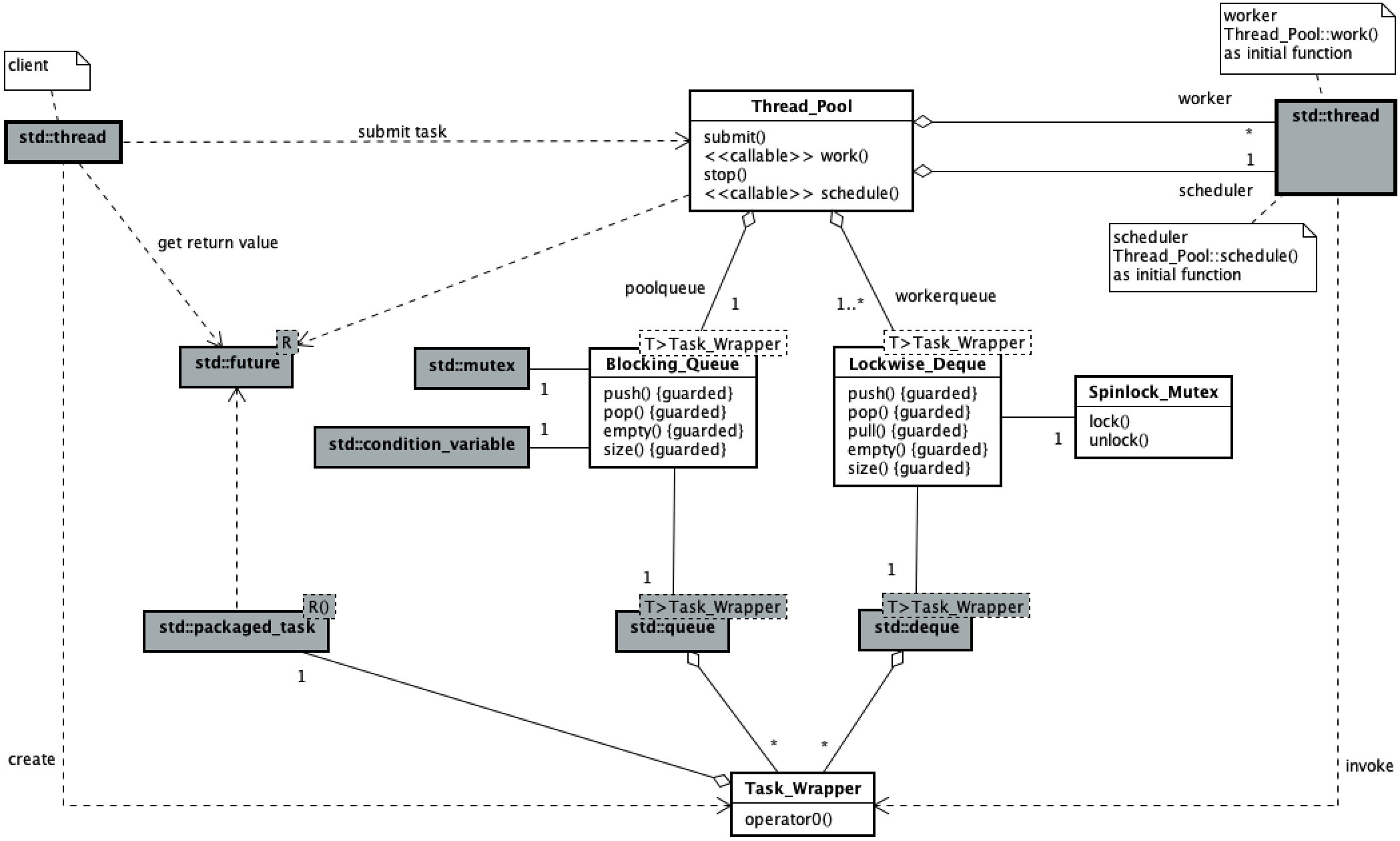
The thread pool defines blocked shared task queues (#1), blocked work task queues (#2), and scheduler threads (#3). When thread pool objects are created, they are initialized (#4, #5). The scheduler thread of the thread pool assigns the tasks in the shared task queue to the work task queue (#6), and the work threads obtain the tasks from the head of their respective work task queue and execute them (#7). When counting the remaining work tasks, total the remaining tasks in the shared task queue and work task queue (#8). In order to avoid the deadlock problem, a dummy task (#9) is put into the shared task queue and each work task queue to ensure that both the scheduler thread and each work thread can exit the circular waiting.
The following code gives the implementation of scheme 2, (blocking_shared_lockwise_mutual_pool.h)
class Thread_Pool {
private:
struct Task_Wrapper { ...
};
atomic<bool> _suspend_;
atomic<bool> _done_;
Blocking_Queue<Task_Wrapper> _poolqueue_; // #1
thread _scheduler_; // #3
unsigned _workersize_;
thread* _workers_;
Lockwise_Queue<Task_Wrapper>* _workerqueues_; // #2
void work(unsigned index) {
Task_Wrapper task;
while (!_done_.load(memory_order_acquire)) {
if (_workerqueues_[index].pop(task))
task();
else
for (unsigned i = 0; i < _workersize_; ++i)
if (_workerqueues_[(index + i + 1) % _workersize_].pop(task)) { // #7
task();
break;
}
while (_suspend_.load(memory_order_acquire))
std::this_thread::yield();
}
}
void stop() {
size_t remaining = 0;
_suspend_.store(true, memory_order_release);
remaining = _poolqueue_.size(); // #8
for (unsigned i = 0; i < _workersize_; ++i)
remaining += _workerqueues_[i].size();
_suspend_.store(false, memory_order_release);
while (!_poolqueue_.empty())
std::this_thread::yield();
for (unsigned i = 0; i < _workersize_; ++i)
while (!_workerqueues_[i].empty())
std::this_thread::yield();
std::fprintf(stderr, "\n%zu tasks remain before destructing pool.\n", remaining);
_done_.store(true, memory_order_release);
_poolqueue_.push([] {}); // #9
for (unsigned i = 0; i < _workersize_; ++i)
if (_workers_[i].joinable())
_workers_[i].join();
if (_scheduler_.joinable())
_scheduler_.join();
delete[] _workers_;
delete[] _workerqueues_;
}
void schedule() {
Task_Wrapper task;
while (!_done_.load(memory_order_acquire)) {
_poolqueue_.pop(task); // #6
_workerqueues_[rand() % _workersize_].push(std::move(task));
}
}
public:
Thread_Pool() : _suspend_(false), _done_(false) {
try {
_workersize_ = thread::hardware_concurrency();
_workers_ = new thread[_workersize_]();
_workerqueues_ = new Lockwise_Queue<Task_Wrapper>[_workersize_](); // #4
for (unsigned i = 0; i < _workersize_; ++i)
_workers_[i] = thread(&Thread_Pool::work, this, i);
_scheduler_ = thread(&Thread_Pool::schedule, this); // #5
} catch (...) { ...
}
}
...
};
The thread pool defines blocking shared task queue (#1), non blocking mutual aid work task queue (#2) and scheduler thread (#3). When thread pool objects are created, they are initialized (#4, #5). The scheduler thread of the thread pool assigns the tasks in the shared task queue to the work task queue (#6), and the work threads obtain and execute the tasks from the head of their own work task queue. When there is no task in its own work task queue, this worker thread will get the task from the work task queue header of other worker threads (#7). When counting the remaining work tasks, total the remaining tasks in the shared task queue and work task queue (#8). In order to avoid the deadlock problem, a dummy task (#9) is put into the shared task queue to ensure that the scheduler thread can exit the loop waiting.
The following code gives the implementation of scheme 3, (blocking_shared_lockwise_mutual_2b_pool.h)
class Thread_Pool {
private:
struct Task_Wrapper { ...
};
atomic<bool> _suspend_;
atomic<bool> _done_;
Blocking_Queue<Task_Wrapper> _poolqueue_; // #1
thread _scheduler_; // #3
unsigned _workersize_;
thread* _workers_;
Lockwise_Deque<Task_Wrapper>* _workerqueues_; // #2
void work(unsigned index) {
Task_Wrapper task;
while (!_done_.load(memory_order_acquire)) {
if (_workerqueues_[index].pull(task))
task();
else
for (unsigned i = 0; i < _workersize_; ++i)
if (_workerqueues_[(index + i + 1) % _workersize_].pop(task)) { // #7
task();
break;
}
while (_suspend_.load(memory_order_acquire))
std::this_thread::yield();
}
}
void stop() {
size_t remaining = 0;
_suspend_.store(true, memory_order_release);
remaining = _poolqueue_.size(); // #8
for (unsigned i = 0; i < _workersize_; ++i)
remaining += _workerqueues_[i].size();
_suspend_.store(false, memory_order_release);
while (!_poolqueue_.empty())
std::this_thread::yield();
for (unsigned i = 0; i < _workersize_; ++i)
while (!_workerqueues_[i].empty())
std::this_thread::yield();
std::fprintf(stderr, "\n%zu tasks remain before destructing pool.\n", remaining);
_done_.store(true, memory_order_release);
_poolqueue_.push([] {}); // #9
for (unsigned i = 0; i < _workersize_; ++i)
if (_workers_[i].joinable())
_workers_[i].join();
if (_scheduler_.joinable())
_scheduler_.join();
delete[] _workers_;
delete[] _workerqueues_;
}
void schedule() {
Task_Wrapper task;
while (!_done_.load(memory_order_acquire)) {
_poolqueue_.pop(task); // #6
_workerqueues_[rand() % _workersize_].push(std::move(task));
}
}
public:
Thread_Pool() : _suspend_(false), _done_(false) {
try {
_workersize_ = thread::hardware_concurrency();
_workers_ = new thread[_workersize_]();
_workerqueues_ = new Lockwise_Deque<Task_Wrapper>[_workersize_](); // #4
for (unsigned i = 0; i < _workersize_; ++i)
_workers_[i] = thread(&Thread_Pool::work, this, i);
_scheduler_ = thread(&Thread_Pool::schedule, this); // #5
} catch (...) { ...
}
}
...
};
The thread pool defines blocking shared task queue (#1), non blocking work task queue (#2) and scheduler thread (#3). When thread pool objects are created, they are initialized (#4, #5). The scheduler thread of the thread pool assigns the tasks in the shared task queue to the work task queue (#6), and the work threads obtain and execute the tasks from the tail of their respective work task queue. When there is no task in its own work task queue, this worker thread will get the task from the head of the work task queue of other worker threads (#7). When counting the remaining work tasks, total the remaining tasks in the shared task queue and work task queue (#8). In order to avoid the deadlock problem, a dummy task (#9) is put into the shared task queue to ensure that the scheduler thread can exit the loop waiting.
◆ logic
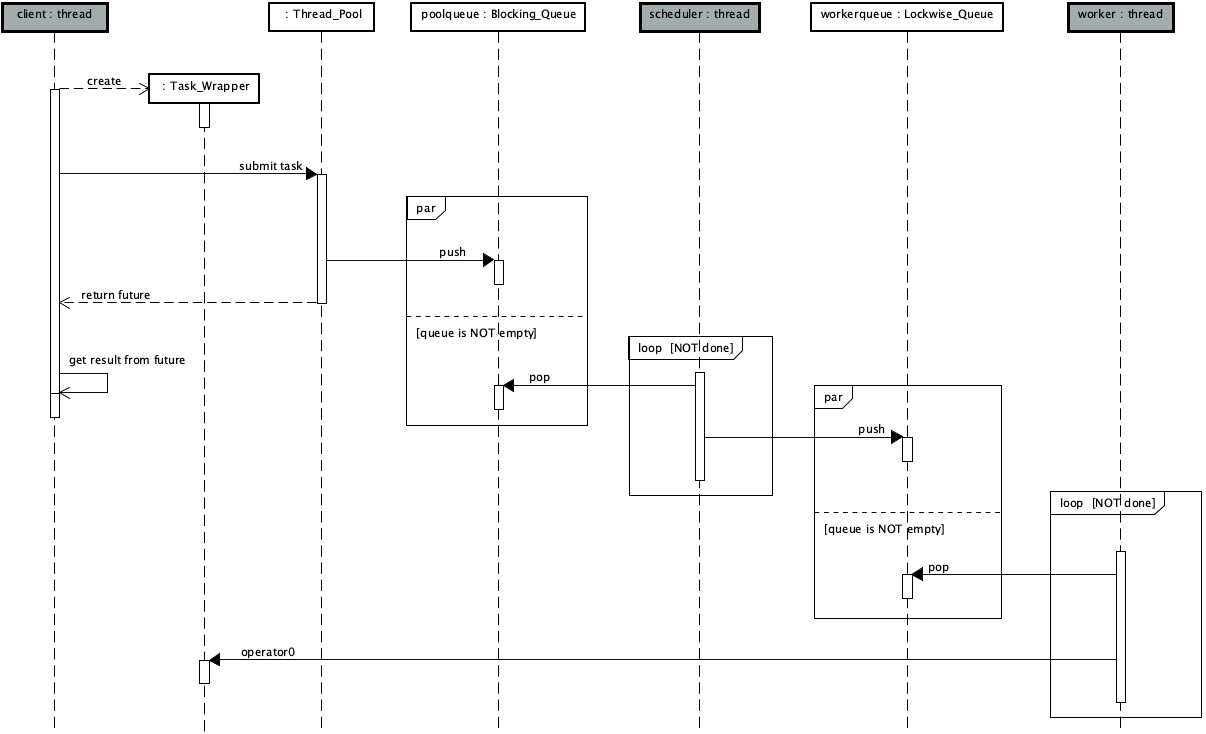
The following class diagram and sequence diagram respectively show the main logical structure of scheme 1 and the concurrent process of tasks submitted by thread pool users, scheduler threads and worker threads,
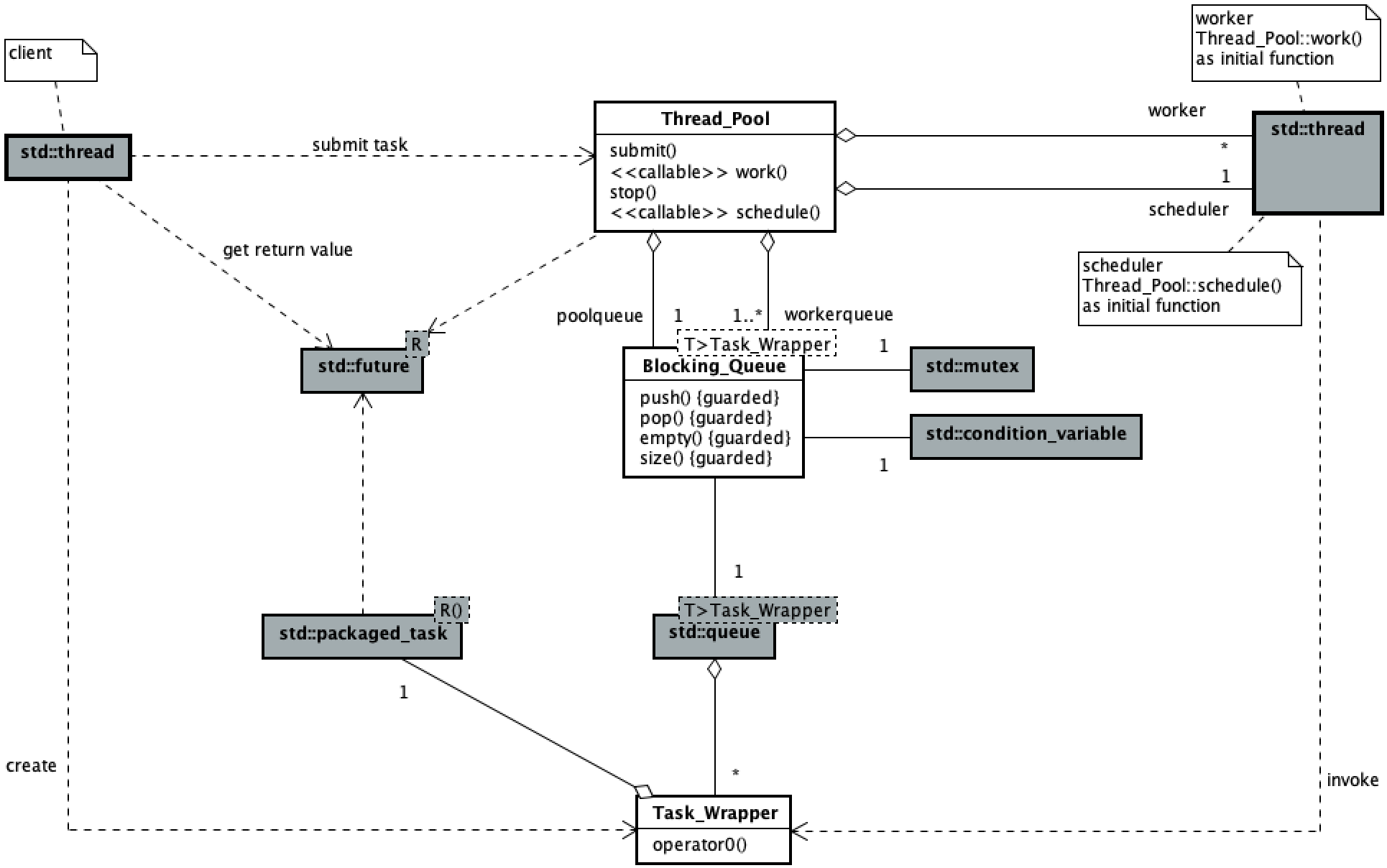
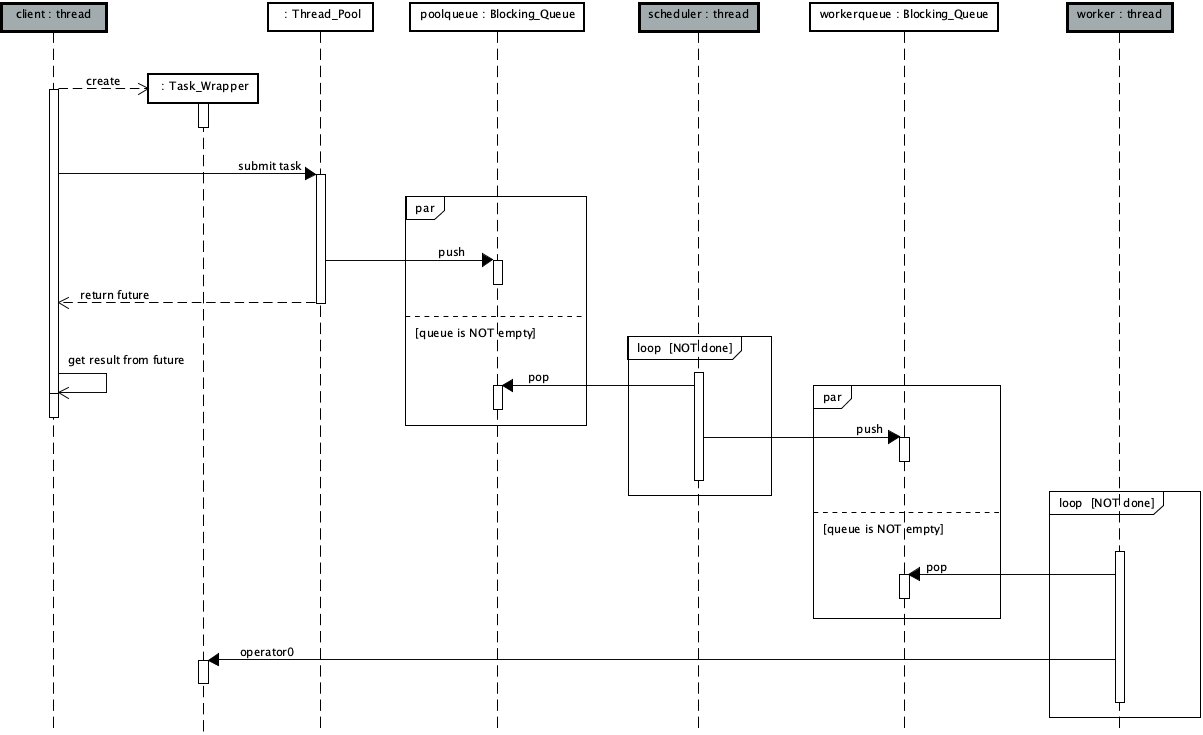
[note] in the figure, the initial functions of scheduler thread and worker thread are identified by stereotype, and the calling relationship is explained in the annotation, the same below.
The following is the logic of scheme 2,
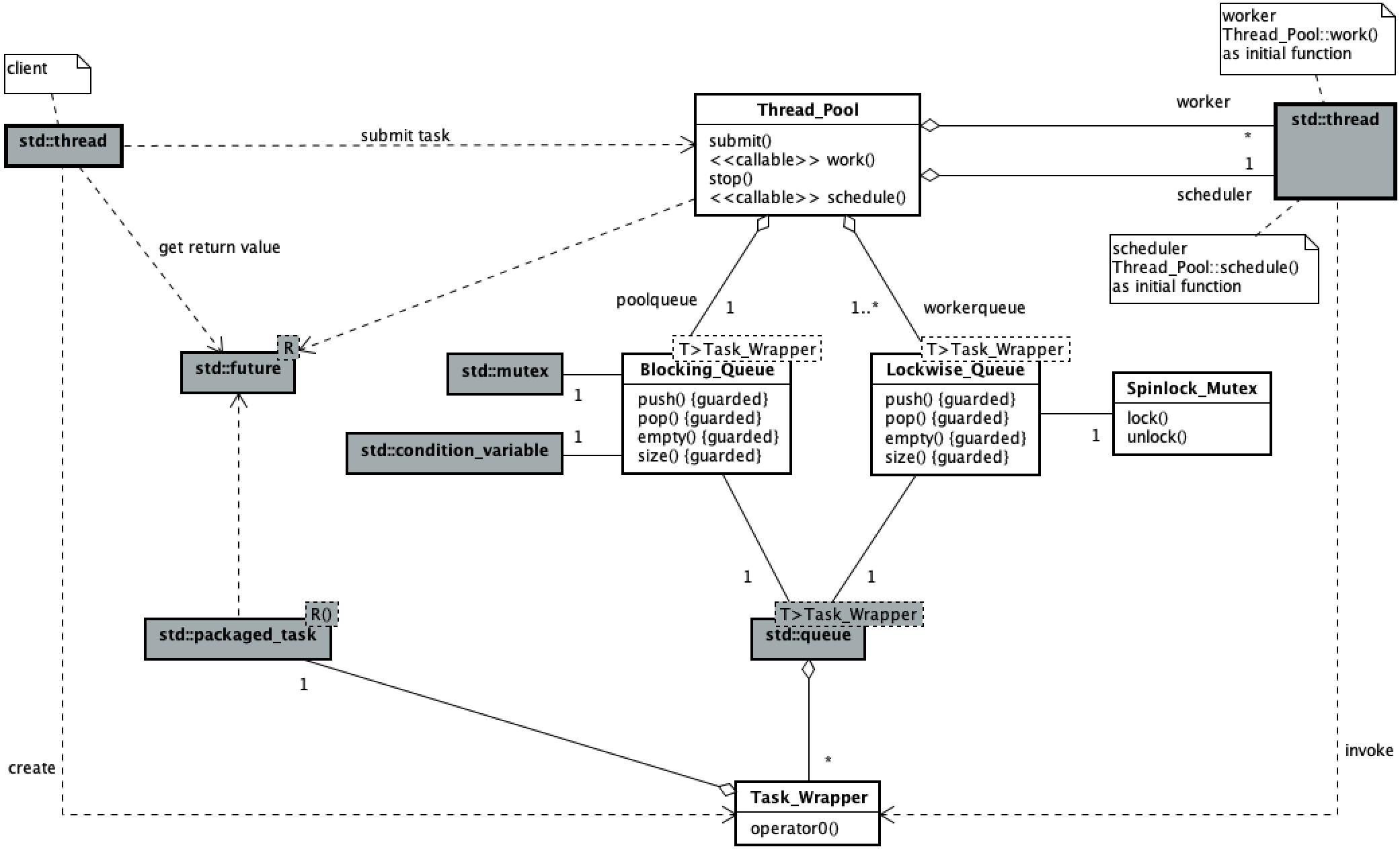
The following is the logic of scheme 3,
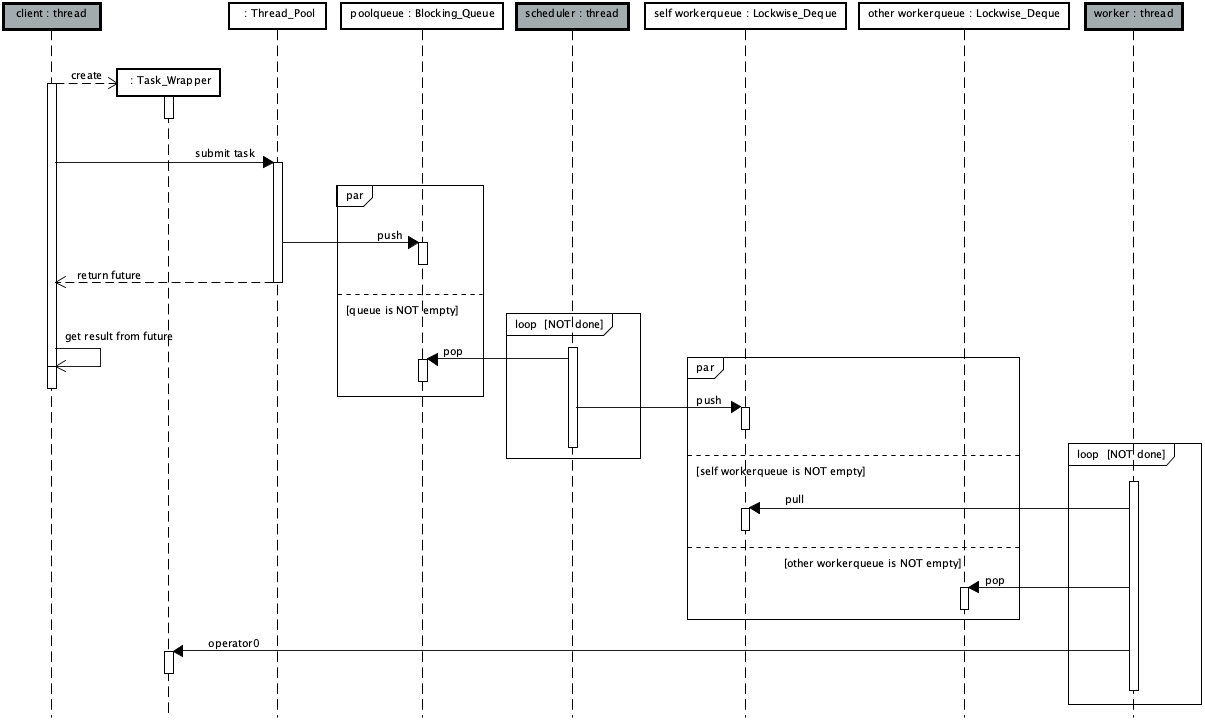
◆ verification
The validation process uses Simple thread pool (3) Test cases defined in. The author compares the test results with Simple thread pool (8) The results are as follows,
Figure 1 illustrates the comparison of the difference in throughput 1 in different thinking times in the submission cycle of 0.5 minutes, 1 minute and 3 minutes.
[note] the three combination schemes are abbreviated as BSBU, BSLM and BSLM2B, the same below.
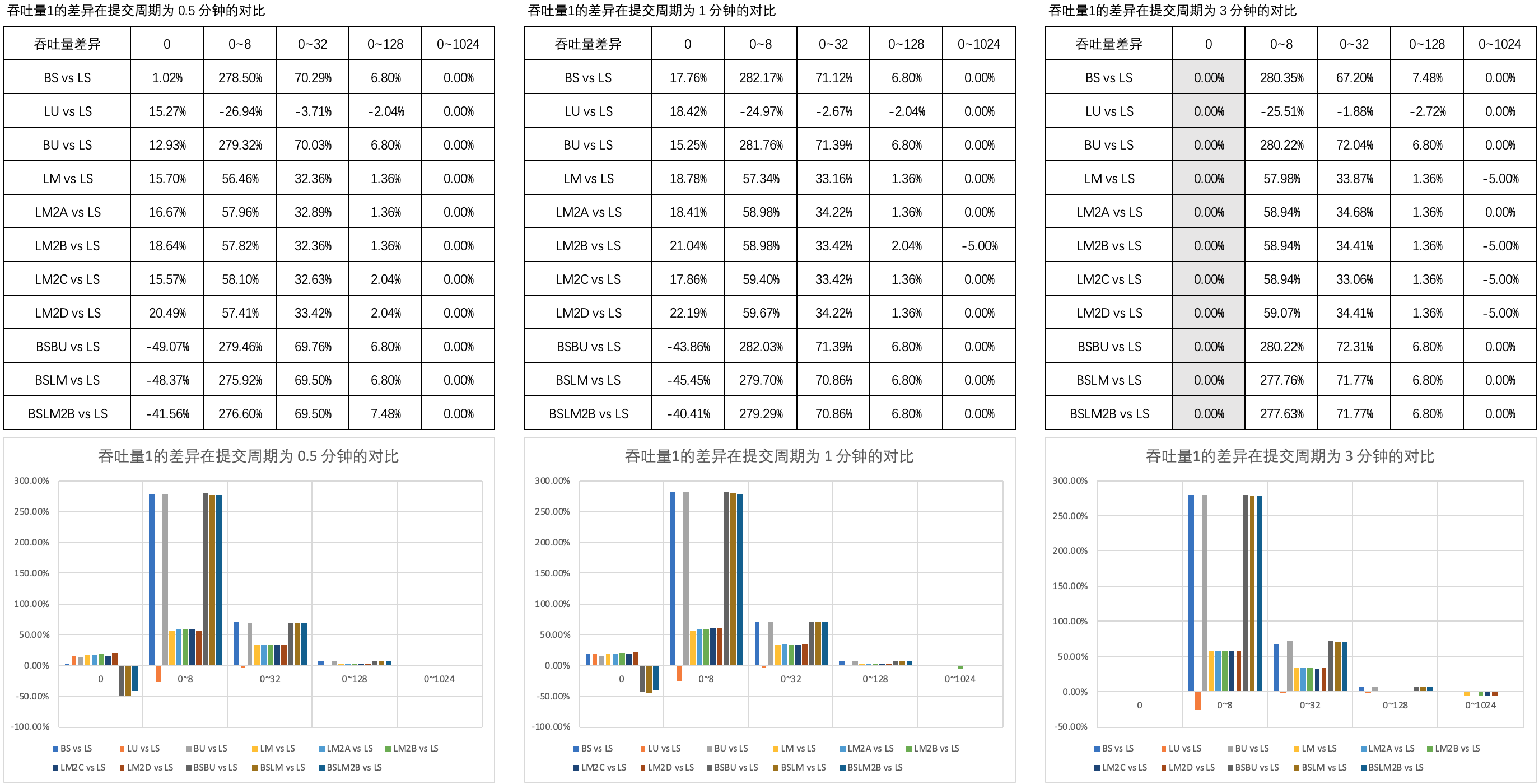
As you can see,
- When the thinking time is 0, the throughput of BSBU, BSLM and BSLM2B is significantly worse than that of other types; This difference did not change significantly after the extension of the submission cycle;
- When the thinking time is not 0, the throughput of BSBU, BSLM and BSLM2B is equivalent to that of BS and BU, which is better than that of other types, but the difference will not change due to the extension of the submission cycle; With the increase of thinking time, the throughput difference between BSBU, BSLM and BSLM2B and other types of throughput gradually disappears.
Figure 2 shows the comparison of the difference in throughput 2 in different thinking time in the submission cycle of 0.5 minutes, 1 minute and 3 minutes.
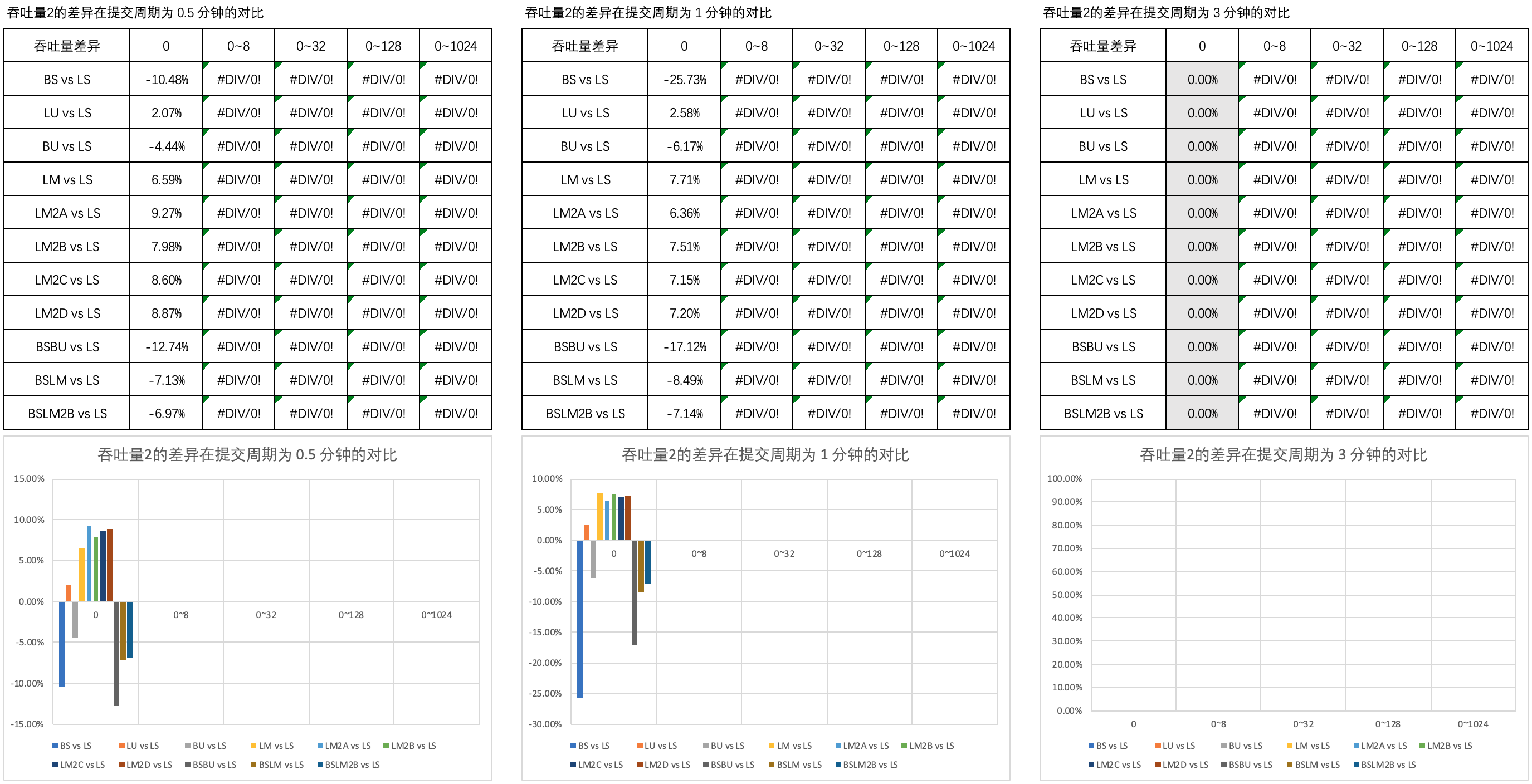
As you can see,
- When the thinking time is 0, the throughput of BSBU, BSLM and BSLM2B is significantly worse than that of LM and LM2 series, and slightly better than that of BS and BU; This difference did not change significantly after the extension of the submission cycle;
- When the thinking time is not 0, there is no basic data for comparison.
Figure 3 illustrates the comparison of throughput differences in different thinking times in 0.5 minute, 1 minute and 3 minute submission cycles.
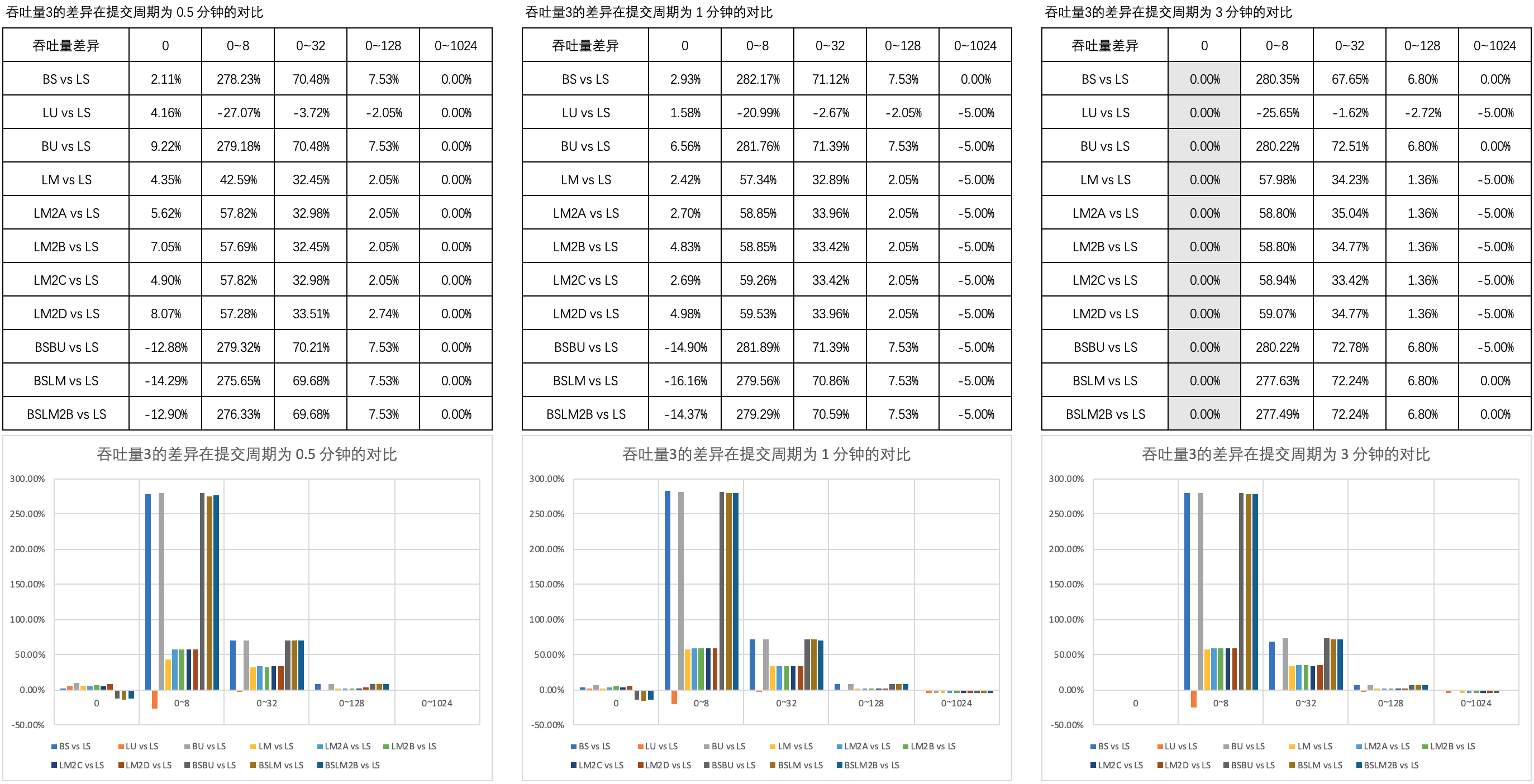
- When the thinking time is 0, the throughput of BSBU, BSLM and BSLM2B is significantly worse than that of other types; This difference did not change significantly after the extension of the submission cycle;
- When the thinking time is not 0, the throughput of BSBU, BSLM and BSLM2B is equivalent to that of BS and BU, which is better than that of other types, but the difference will not change due to the extension of the submission cycle; With the increase of thinking time, the throughput difference between BSBU, BSLM and BSLM2B and other types of throughput gradually disappears.
Based on the above comparative analysis, the author believes that,
- The throughput capacity of the combined type is biased towards the blocking type;
- The combined scheme does not improve the throughput capacity, and is obviously inferior to other types when the response thinking time is 0.
◆ finally
For complete code examples and test data, please refer to [github] cnblogs/15754987 .