preface
Everyone is familiar with mobile phone wallpaper. I believe whoever turns on his mobile phone wants his wallpaper to be his favorite picture,
But when a wallpaper is used for a long time, it will want to change a picture full of freshness (excluding those who love it),



However, the time of selecting pictures is always constant. Sometimes a long time of selection may not be able to select the one you like, and you are tired of fighting back
So how to write a code directly and automatically download the type of mobile phone wallpaper you are interested in
Contents of this meeting:
python crawls 4K ultra clear picture quality mobile phone wallpaper
development environment
Knock the code. You can't even knock the code 👀
- Python 3.8
- Pycharm
How to configure the python interpreter in pycharm?
- Select File > > > setting > > > Project > > > Python interpreter
- Click the gear and select add
- Add python installation path

How does pycharm install plug-ins?
- Select File > > > setting > > > plugins
- Click Marketplace and enter the name of the plug-in you want to install, such as translation / Chinese
- Select the appropriate plug-in and click Install
- After the installation is successful, the option to restart pycharm will pop up. Click OK and the restart will take effect
Module use
The first module needs to be installed. Otherwise, even if your code comes out, it will still be unhappy and report errors without the module. The other two modules are self-contained and do not need to be installed
- Requests > > > PIP install requests data requests
- re regular parsing data
- os automatically creates folders
Many small partners do not know how to install the module or report the reasons for errors. Now let's explain it in detail
- If you install a python third-party module:
- win + R enter cmd, click OK, enter the installation command pip install module name (pip install requests) and press enter
- Click terminal in pychart to enter the installation command
- Installation failure reason:
-
Failure 1: pip is not an internal command
Solution: set the environment variable -
Failure 2: a large number of red flags (read time out) appear
Solution: because the network link times out, you need to switch the image source
Tsinghua University: https://pypi.tuna.tsinghua.edu.cn/simple
Alibaba cloud: http://mirrors.aliyun.com/pypi/simple/
China University of science and technology https://pypi.mirrors.ustc.edu.cn/simple/
Huazhong University of Technology: http://pypi.hustunique.com/
Shandong University of Technology: http://pypi.sdutlinux.org/
Watercress: http://pypi.douban.com/simple/
For example: pip3 install -i https://pypi.doubanio.com/simple/ Module name -
Failure 3: cmd shows that it has been installed or successfully installed, but it still cannot be imported in pycharm
Solution: you may have installed multiple python versions (anaconda or python can be installed). Just uninstall one
Or you haven't set up the python interpreter in pycharm

-
We want to implement a crawler case
The first thing to do:
Is to analyze the data content we want and where we can get it (developer tools to capture and analyze)
Through analysis, you can know that you want to obtain the original wallpaper URL > > > obtain each wallpaper detail page URL > > > list page obtain the wallpaper detail page
The second step is our code implementation step
1. Send request, Send request for wallpaper list page 2. get data, Gets the value returned by the server response data 3. Parse data, Extract the wallpaper detail page we want url 4. Send request, For wallpaper details page url Send request 5. get data, Gets the value returned by the server response data 6. Parse data, Extract the pictures we want url And picture title 7. Save data, Save local 8. Multi page crawling, Send the request according to the change law of the wallpaper list page
Code display
Let's import our data request module first
import requests # pip install requests
Importing regular expression modules
import re # The built-in module does not need to be installed
for page in range(4, 11):
print(f'===================Crawling to No{page}Data content of the page===================')
# 1. Send a request for the wallpaper list page
url = f'https://m.bcoderss.com/tag/%e5%8a%a8%e6%bc%ab/page/{page}/'
# The purpose of headers request header is to disguise python code
# If it is identified as a crawler, the program will not return data or other data
headers = {
'cookie': 'UM_distinctid=17dffa7aa3a189-048d4b23bef5a4-4303066-1fa400-17dffa7aa3bbfe; Hm_lvt_ce3020881c73bb20f0830ef4ed0a61fb=1640671718; CNZZDATA1278590218=1385918032-1640661155-%7C1640667485; Hm_lpvt_ce3020881c73bb20f0830ef4ed0a61fb=1640676345',
'origin': 'https://m.bcoderss.com',
'referer': url,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36',
}
response = requests.post(url=url, headers=headers)
# 2. Get the data and get the response data (text data) returned by the server
# print(response.text) # String type
# 3. Parse the data and extract the url of the wallpaper detail page we want
# Regular expression, you can get the response Textextract directly
# Returns the list data type. For a list, I don't want its first element, operation
# split() is a string method. The position of the slice list element is counted from 0
# Through the findall method in the re module, the response Find all about < li > < a target = "_blank" href = "(. *?)" in text What we want is the data content in ()
img_url_list = re.findall('<li><a target="_blank" href="(.*?)"', response.text)[1:]
# Extract the elements in the list one by one
for img_url in img_url_list:
# Extract wallpaper details page url

# 4. Send a request for the wallpaper detail page url
response_1 = requests.get(url=img_url, headers=headers)
# 5. Get the data and get the response data returned by the server
# print(response_1.text) gets text data
# 6. Analyze data
img_info = re.findall('<img alt=".*?" title="(.*?)" src="(.*?)">', response_1.text)[0]
img_name = img_info[0]
new_title = re.sub(r'[\/:*?"<>|\n]', '', img_name)
img_link = img_info[1]
# 7. Save data, save local
# To save picture data, get binary data
img_content = requests.get(url=img_link, headers=headers).content # response.content get binary data
with open('img\\' + new_title + '.jpg', mode='wb') as f:
f.write(img_content)
print(img_name, img_link)
Effect display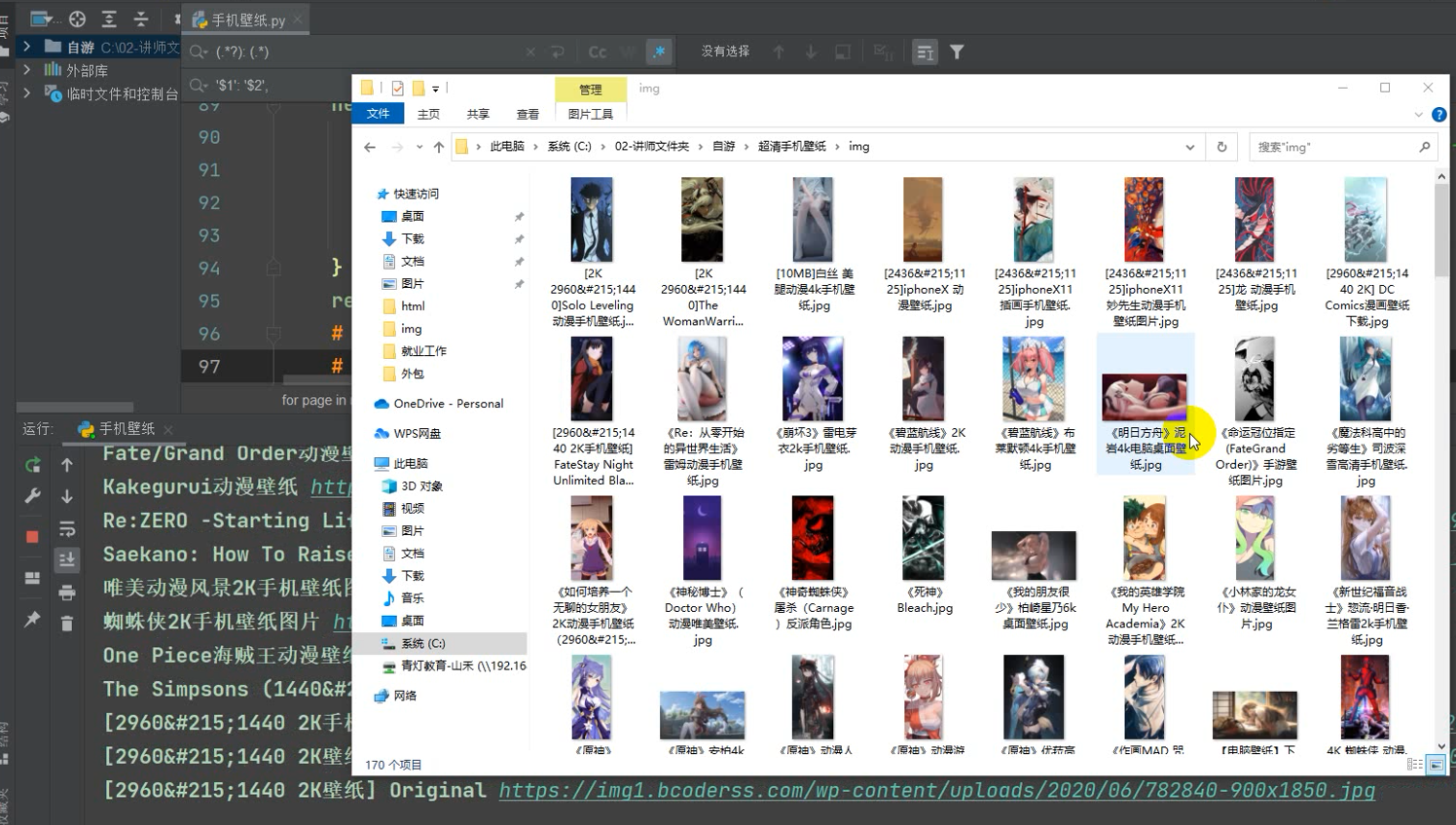






Well, my article will end here!
There are more suggestions or questions to comment on or send me a private letter! Come on, let's work together
Like to pay attention to the blogger, or like to collect and comment on my article, Ba!!!