[Source Parsing] Deep Learning Distributed Training Framework horovod(20) - Elastic Training Operator
0x00 Summary
Horovod is a distributed training framework based on ALReduce. Horovod is widely used in data parallel training due to its support for mainstream deep learning frameworks such as TensorFlow, PyTorch, and communication optimization.
This is the last article on horovod on k8s to see how MPI-Operator might be improved, primarily by learning the source code from the blog content of the Elastic Training Operator author team. So this paper mainly focuses on a large number of sources.
The links to other articles in this series are as follows:
[\Source Parsing] Deep learning of the distributed training framework Horovod - (1) Basic knowledge
[\Source Parsing] Deep learning distributed training framework horovod(3) - What's behind Horovodrun
[\Source Parsing] In-depth Learning Distributed Training Framework horovod(5) - Fusion Framework
[\Source Parsing] In-depth Learning Distributed Training Framework horovod(7) - Distributed Optimizer
[Source Parsing] In-depth Learning Distributed Training Framework horovod(8) - on spark
[Source Parsing] Deep Learning Distributed Training Framework horovod(9) - Start on spark
[Source Parsing] In-depth learning distributed training framework horovod(10) - run on spark
[Source Parsing] Deep Learning Distributed Training Framework horovod(11)-on spark-GLOO Scheme
Hoovod(13) - Driver for Elastic Training
[Source Parsing] In-depth Learning Distributed Training Framework horovod(15) - Radio & Notification
Hoovod(17) - Fault Tolerance for Elastic Training
[Source Parsing] Deep Learning Distributed Training Framework horovod(18) - kubeflow tf-operator
0x01 Background Knowledge
Both sections 0x01 and 0x02 come from the Elastic Training Operator team blog content, which is really great.
1.1 Elastic
Kubernetes and cloud computing provide agility and scalability. We can set up flexibility strategies for training tasks through cluster-AutoScaler and other components, and use the flexibility of Kubernetes to create GPU devices on demand to reduce idling.
However, this scaling mode is slightly inadequate for offline tasks such as training:
- Fault tolerance is not supported, when some Worker s fail due to device reasons, the entire task needs to stop and start over.
- Training tasks usually take a long time, take up a lot of energy and lack flexibility. When resources are insufficient, resources cannot be freed for other businesses on demand unless the task is terminated.
- Training tasks take a long time, do not support worker dynamic configuration, can not safely use preemptive instances, play the best value-for-money ratio in the cloud
How to give flexibility to training tasks is the key path to improve cost-effectiveness. Recently, distributed frameworks such as horovod have gradually supported Elastic Training, or flexibility training. That is, to allow a training worker to expand or shrink dynamically during the execution of a training task, never causing the interruption of the training task. A small amount of modification to the adapter is required in the code, for reference: https://horovod.readthedocs.io/en/stable/elastic_include.html .
Disadvantages of 1.2 mpi-operator
In mpi-operator, the Worker s participating in training are designed and maintained as static resources. Supporting the flexible training mode adds flexibility to tasks, but also challenges the operation and maintenance layer, such as:
- The horovordrun provided by horovod must be used as the entrance. The launcher in horovod logs on to the worker through ssh, and the landing tunnel between the launcher and the worker needs to be opened.
- Elastic Driver module responsible for calculating resilience by specifying discover_ The host script gets the latest worker topology information to pull up or stop the worker instance. When the worker changes, first update discover_ Return value of host script.
- In scenarios such as preemption or price calculation, it is sometimes necessary to specify worker extensions, K8s native layout meta-language deployment, and statefulset cannot meet the specified extensions.
To address these issues, we have designed and developed et-operator, which provides TrainingJob CRD descriptions of training tasks, ScaleOut and ScaleIn CRD descriptions of scaling and shrinking operations, and their combination makes our training tasks more flexible. Open source this project, welcome you to ask for, communicate, and spit out.
Open source solution address: https://github.com/AliyunContainerService/et-operator
0x02 Overall Architecture
TrainingJob Controller has the following main functions:
- Maintain the creation/deletion lifecycle of TrainingJob as well as subresource management.
- Perform a scaling operation.
- Fault tolerance, when the worker is expelled, create a new worker to join the training.
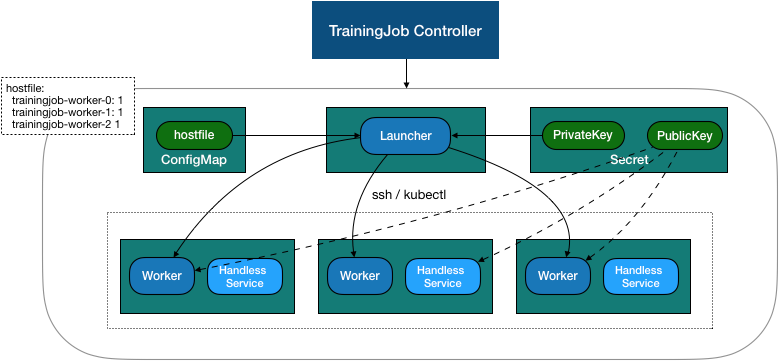
2.1 Resource Creation
TrainingJob subresources are created in the following order:
- Create a key pair to get through ssh and create a secret.
- Create workers, including service s and pod s, and mount the secret public key.
- Create configmap with discover_host script, hostfile.
- Create a launcher and mount configmap. Since hostfiles are subsequently modified with topological relationships, hostfiles are copied from configmap to a separate directory through initcontainer.
TrainingJob related resources:
2.2 Roles
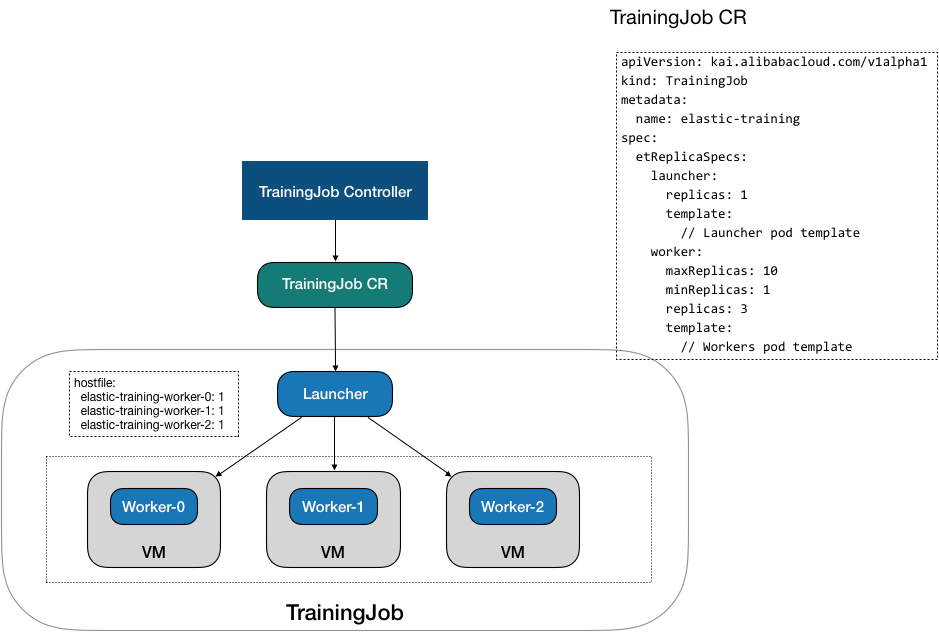
The configuration of TrainingJob CR is divided into Lanucher and Worker. Specify mirroring and startup execution of tasks in Launcher. The default et-operator generates a hostfile and discover_based on worker assignments Host script, discover_host script mounted to Launcher's/etc/edl/discover_hosts.sh file, specified by the--host-discovery-script parameter in the horovodrun execution of the entry script. Specify the mirroring and GPU usage of the worker in the Worker settings and the allowable range for the number of copies of the worker through maxReplicas / minReplicas.
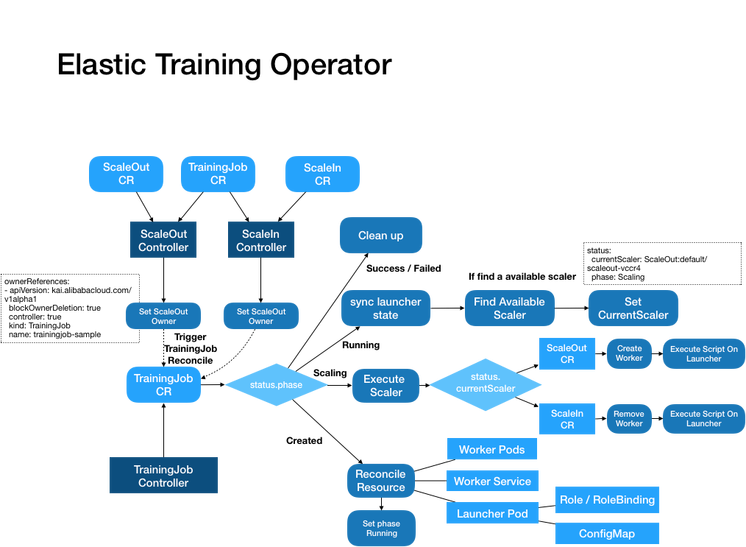
2.3 Main Procedures
The main program diagrams are as follows:
0x03 Entry
In fact, learning ETO is mainly about how to expand and shrink. But to learn this, we still need to comb the program logic.
Those who are not familiar with K8S will also like to see how their CRD s are used.
3.1 Creation
The entry code is main. The go/main function, as you can see from the entry,
- Controller generated. Manager.
- Using this Manager, three Reconcilers are built: TrainingJobReconciler, ScaleInReconciler, and ScaleOutReconciler.
- Then start Manager;
func main() {
mgr, err := ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{
Scheme: scheme,
MetricsBindAddress: metricsAddr,
LeaderElection: enableLeaderElection,
Port: 9443,
})
const jobPollInterval = "5s"
if err = controllers.NewReconciler(mgr, parseDurationOrPanic(jobPollInterval)).SetupWithManager(mgr); err != nil {
os.Exit(1)
}
if err = controllers.NewScaleOutReconciler(mgr, parseDurationOrPanic(jobPollInterval)).SetupWithManager(mgr); err != nil {
os.Exit(1)
}
if err = controllers.NewScaleInReconciler(mgr, parseDurationOrPanic(jobPollInterval)).SetupWithManager(mgr); err != nil {
os.Exit(1)
}
if err := mgr.Start(ctrl.SetupSignalHandler()); err != nil {
os.Exit(1)
}
}
3.2 Settings
The configuration here is to set up a response function for the message, which CR s it responds to.
-
In addition to TrainingJob, et-operator supports both ScaleOut and ScaleIn CRD s to expand and shrink training tasks.
-
Now a ScaleOut CR is sent, and the ScaleOutController triggers the Reconcile. The simple work here is to find the corresponding TrainingJob for Scaler based on the Selector field in ScaleOut CR and set it on the OwnerReferences of the CR.
-
Updates to the ScaleOut CR belonging to TrainingJob were heard in TrainingJobController, which triggered the Reeconcile of TrainingJob, traversed to filter the ScaleIn and ScaleOut pointed to by OwnerReference under TrainingJob, and scaled up or down to the creation and state time.
-
When zooming, you can use spec.toDelete in ScaleIn CR. Count or spec.toDelete. The podNames field specifies a scaled worker. Configuring the number of shrinks through count calculates the high-to-low shrink Worker through index.
func (r *ScaleInReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&kaiv1alpha1.ScaleIn{}).
Complete(r)
}
func (r *ScaleOutReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&kaiv1alpha1.ScaleOut{}).
Complete(r)
}
func (r *TrainingJobReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&kaiv1alpha1.TrainingJob{}).
Owns(&kaiv1alpha1.ScaleIn{}).
Owns(&kaiv1alpha1.ScaleOut{}).
Owns(&corev1.Pod{}).
Owns(&corev1.Service{}).
Owns(&corev1.ConfigMap{}).
Owns(&corev1.Secret{}).
// Ignore status-only and metadata-only updates
//WithEventFilter(predicate.GenerationChangedPredicate{}).
Complete(r)
}
0x04 TrainingJobReconciler
Follow the code to find the subtleties of its design ideas.
4.1 Reconcile
The function of reconcile method in k8s operator is continuous watch, which triggers the reconcile method when resources change, and how many times the reconcile method will be executed theoretically.
The Reconcile method is called when a message comes.
func (r *TrainingJobReconciler) Reconcile(req ctrl.Request) (ctrl.Result, error) {
// Fetch latest training job instance.
sharedTrainingJob := &kaiv1alpha1.TrainingJob{}
err := r.Get(context.Background(), req.NamespacedName, sharedTrainingJob)
trainingJob := sharedTrainingJob.DeepCopy()
// Check reconcile is required.
// No need to do reconcile or job has been deleted.
r.Scheme.Default(trainingJob)
return r.ReconcileJobs(trainingJob)
}
4.2 ReconcileJobs
Since the status in the message is "", initializeJob is run and reconcileResource is reconciled.
func (r *TrainingJobReconciler) ReconcileJobs(job *kaiv1alpha1.TrainingJob) (result reconcile.Result, err error) {
oldJobStatus := job.Status.DeepCopy()
defer func() {
latestJob := &kaiv1alpha1.TrainingJob{}
err := r.Get(context.Background(), types.NamespacedName{
Name: job.Name,
Namespace: job.Namespace,
}, latestJob)
if err == nil {
if latestJob.ObjectMeta.ResourceVersion != job.ObjectMeta.ResourceVersion {
latestJob.Status = job.Status
job = latestJob
}
}
r.updateObjectStatus(job, oldJobStatus)
}()
switch job.Status.Phase {
case commonv1.JobSucceeded, commonv1.JobFailed:
err = r.cleanup(job)
case "", commonv1.JobCreated: // Initialize if state is empty or JobCreated
r.initializeJob(job)
err = r.reconcileResource(job)
case commonv1.JobRunning:
err = r.reconcileJobRunning(job)
case commonv1.Scaling:
err = r.executeScaling(job)
}
if err != nil {
if IsRequeueError(err) {
return RequeueAfterInterval(r.PollInterval, nil)
}
return RequeueAfterInterval(r.PollInterval, err)
}
return NoRequeue()
}
4.3 reconcileResource
reconcileResource actually calls doSteps, calling a state machine to continue initialization.
func (r *TrainingJobReconciler) reconcileResource(job *kaiv1alpha1.TrainingJob) error {
steps := r.newSteps()
err := r.doSteps(job, steps)
return err
}
4.4 doSteps
newSteps builds a simple state machine and is an initialization step that is executed sequentially, and doSteps branches differently based on the state.
There are a few points to explain:
- The following states after Created should be: WorkersCreated --> WorkersReady ----> LauncherCreated --> JobRunning.
- This is the post-event state, which should be reached after the corresponding action is completed.
- In the for loop, if the current Job has reached a state, skip continuing until an incomplete state, and execute the corresponding action. So in theory, it's going to go from WorkersCreated to JobRunning.
- In an Action corresponding to a state, Job is set to this completion state after execution is complete.
The code is as follows:
func (r *TrainingJobReconciler) newSteps() []Step {
return []Step{
Step{
JobCondition: commonv1.WorkersCreated,
Action: r.createTrainingJobWorkers,
},
Step{
JobCondition: commonv1.WorkersReady,
Action: r.waitWorkersRunning,
},
Step{
JobCondition: commonv1.LauncherCreated,
Action: r.createLauncher,
},
Step{
JobCondition: commonv1.JobRunning,
Action: r.syncLauncherState,
},
}
}
func (r *TrainingJobReconciler) doSteps(job *kaiv1alpha1.TrainingJob, steps []Step) error {
for _, step := range steps {
if hasCondition(*job.GetJobStatus(), step.JobCondition) {
continue
}
err := step.Action(job)
break
}
return nil
}
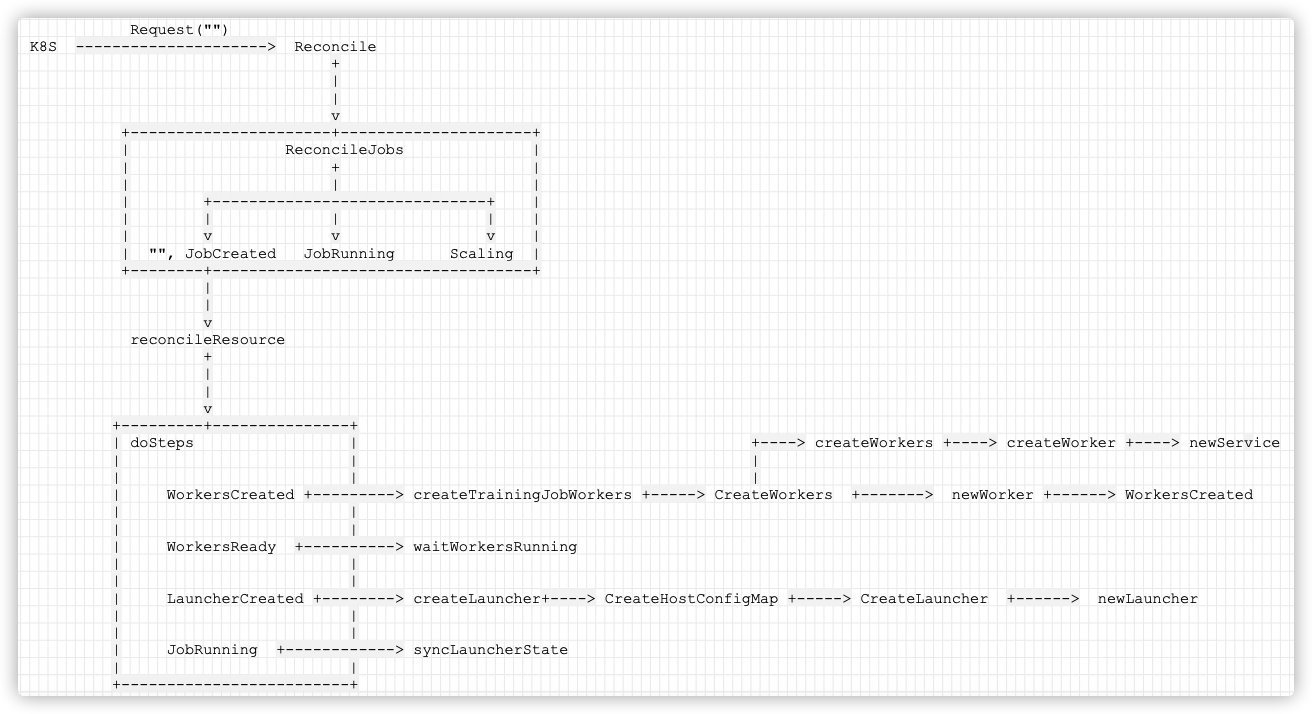
So the following are specific:
Request("")
K8S +--------------------> Reconcile
+
|
|
v
+----------------------+---------------------+
| ReconcileJobs |
| + |
| | |
| +------------------------------+ |
| | | | |
| v v v |
| "", JobCreated JobRunning Scaling |
+--------+-----------------------------------+
|
|
v
reconcileResource
+
|
|
v
+---------+---------------+
| doSteps |
| |
| |
| WorkersCreated +---------> createTrainingJobWorkers
| |
| |
| WorkersReady +----------> waitWorkersRunning
| |
| |
| LauncherCreated +--------> createLauncher
| |
| |
| JobRunning +------------> syncLauncherState
| |
+-------------------------+
4.5 createTrainingJobWorkers
In the doSteps step, start with the createTrainingJobWorkers Action. This will set the Job status to WorkersCreated.
func (r *TrainingJobReconciler) createTrainingJobWorkers(job *kaiv1alpha1.TrainingJob) error {
if job.GetAttachMode() == kaiv1alpha1.AttachModeSSH {
if cm, err := r.GetOrCreateSecret(job); cm == nil || err != nil {
updateStatus(job.GetJobStatus(), common.JobFailed, trainingJobFailedReason, msg)
return nil
}
}
workers := getJobReplicasWorkers(job)
job.Status.TargetWorkers = workers
// Create worker
if err := r.CreateWorkers(job, workers); err != nil {
updateStatus(job.GetJobStatus(), common.JobFailed, trainingJobFailedReason, msg)
return nil
}
// Set new state
updateJobConditions(job.GetJobStatus(), common.WorkersCreated, "", msg)
return nil
}
4.5.1 CreateWorkers
CreateWorkers creates a worker, which, as described earlier in this article, contains service s and pod s, so the creation process is as follows:
-
Call another function with the same name, CreateWorkers, to indirectly create the workerService.
-
Call newWorker to create a Pod.
func (r *TrainingJobReconciler) CreateWorkers(job *kaiv1alpha1.TrainingJob, workers []string) error {
return r.createWorkers(job, workers, func(name string, index string) *corev1.Pod {
worker := newWorker(job, name, index)
return worker
})
}
4.5.1.1 createWorkers
createWorker is called iteratively to generate a series of workers based on the configuration.
func (r *TrainingJobReconciler) createWorkers(job *kaiv1alpha1.TrainingJob, workers []string, newPod PodTplGenerator) error {
// Traverse, create
for _, podName := range workers {
index, err := getWorkerIndex(job.Name, podName)
if err != nil {
return err
}
_, err = r.createWorker(job, int32(index), newPod)
if err != nil {
return err
}
}
return nil
}
4.5.1.2 createWorker
The worker Pod is judged by its parameters here, and if it does not exist, a worker is created.
func (r *TrainingJobReconciler) createWorker(job *kaiv1alpha1.TrainingJob, index int32, workerPodTempl PodTplGenerator) (*corev1.Pod, error) {
name := getWorkerName(job.Name, int(index))
indexStr := strconv.Itoa(int(index))
pod := &corev1.Pod{}
nsn := types.NamespacedName{
Name: name,
Namespace: job.Namespace,
}
err := r.Get(context.Background(), nsn, pod)
if err != nil {
// If the worker Pod doesn't exist, we'll create it.
if errors.IsNotFound(err) {
// If you don't have a pod, you can also create a pod here
worker := workerPodTempl(name, indexStr)
if job.GetAttachMode() == kaiv1alpha1.AttachModeSSH {
util.MountRsaKey(worker, job.Name)
}
if err = r.Create(context.Background(), worker); err != nil {
return nil, err
}
}
}
service := &corev1.Service{}
err = r.Get(context.Background(), nsn, service)
if errors.IsNotFound(err) {
// Call newService for specific creation
err = r.Create(context.Background(), newService(job, name, indexStr))
}
return nil, nil
}
4.5.1.3 newService
It's a million turns to come here to create a service.
func newService(obj interface{}, name string, index string) *corev1.Service {
job, _ := obj.(*kaiv1alpha1.TrainingJob)
labels := GenLabels(job.Name)
labels[labelTrainingRoleType] = worker
labels[replicaIndexLabel] = index
return &corev1.Service{ // Specific creation
ObjectMeta: metav1.ObjectMeta{
Name: name,
Namespace: job.Namespace,
Labels: labels,
OwnerReferences: []metav1.OwnerReference{
*metav1.NewControllerRef(job, kaiv1alpha1.SchemeGroupVersionKind),
},
},
Spec: corev1.ServiceSpec{
ClusterIP: "None",
Selector: labels,
Ports: []corev1.ServicePort{
{
Name: "ssh-port",
Port: 22,
},
},
},
}
}
4.5.2 newWorker
newWorker built Pod, which is a more common routine.
func newWorker(obj interface{}, name string, index string) *corev1.Pod {
job, _ := obj.(*kaiv1alpha1.TrainingJob)
labels := GenLabels(job.Name)
labels[labelTrainingRoleType] = worker
labels[replicaIndexLabel] = index
podSpec := job.Spec.ETReplicaSpecs.Worker.Template.DeepCopy()
// keep the labels which are set in PodTemplate
if len(podSpec.Labels) == 0 {
podSpec.Labels = make(map[string]string)
}
for key, value := range labels {
podSpec.Labels[key] = value
}
// RestartPolicy=Never
setRestartPolicy(podSpec)
container := podSpec.Spec.Containers[0]
// if we want to use ssh, will start sshd service firstly.
if len(container.Command) == 0 {
if job.GetAttachMode() == kaiv1alpha1.AttachModeSSH {
container.Command = []string{"sh", "-c", "/usr/sbin/sshd && sleep 365d"}
} else {
container.Command = []string{"sh", "-c", "sleep 365d"}
}
}
podSpec.Spec.Containers[0] = container
// Created pod
return &corev1.Pod{
ObjectMeta: metav1.ObjectMeta{
Name: name,
Namespace: job.Namespace,
Labels: podSpec.Labels,
Annotations: podSpec.Annotations,
OwnerReferences: []metav1.OwnerReference{
*metav1.NewControllerRef(job, kaiv1alpha1.SchemeGroupVersionKind),
},
},
Spec: podSpec.Spec,
}
}
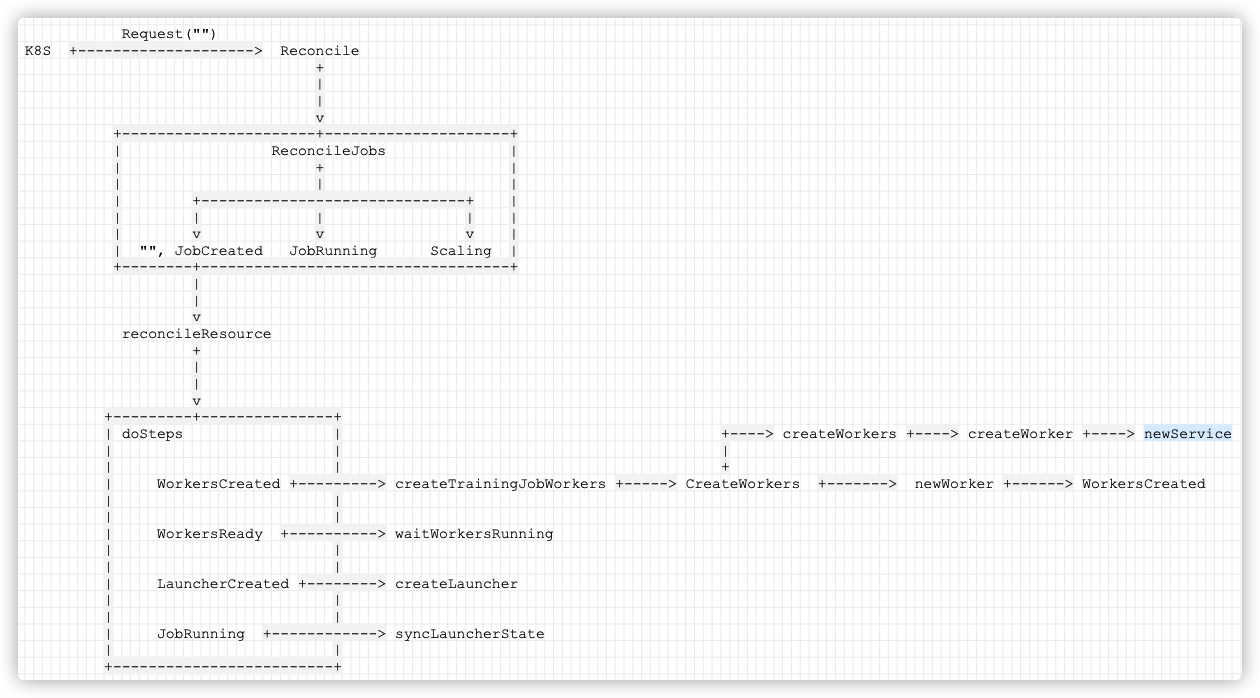
The logic is as follows:
Request("")
K8S +--------------------> Reconcile
+
|
|
v
+----------------------+---------------------+
| ReconcileJobs |
| + |
| | |
| +------------------------------+ |
| | | | |
| v v v |
| "", JobCreated JobRunning Scaling |
+--------+-----------------------------------+
|
|
v
reconcileResource
+
|
|
v
+---------+---------------+
| doSteps | +----> createWorkers +----> createWorker +----> newService
| | |
| | +
| WorkersCreated +---------> createTrainingJobWorkers +-----> CreateWorkers +-------> newWorker +------> WorkersCreated
| |
| |
| WorkersReady +----------> waitWorkersRunning
| |
| |
| LauncherCreated +--------> createLauncher
| |
| |
| JobRunning +------------> syncLauncherState
| |
+-------------------------+
Mobile phones are as follows:
4.8 createLauncher
Once the worker is set up, Launcher is set up. So continue with createLauncher.
func (r *TrainingJobReconciler) createLauncher(job *kaiv1alpha1.TrainingJob) error {
if _, err := r.GetOrCreateLauncherServiceAccount(job); err != nil {
updateStatus(job.GetJobStatus(), commonv1.JobFailed, trainingJobFailedReason, msg)
return nil
}
if _, err := r.GetOrCreateLauncherRole(job, 0); err != nil {
updateStatus(job.GetJobStatus(), commonv1.JobFailed, trainingJobFailedReason, msg)
return nil
}
if _, err := r.GetLauncherRoleBinding(job); err != nil {
updateStatus(job.GetJobStatus(), commonv1.JobFailed, trainingJobFailedReason, msg)
return nil
}
if cm, err := r.CreateHostConfigMap(job); cm == nil || err != nil {
updateStatus(job.GetJobStatus(), commonv1.JobFailed, trainingJobFailedReason, msg)
return nil
}
launcher, err := r.GetLauncherJob(job)
if launcher == nil {
if _, err := r.CreateLauncher(job); err != nil {
updateStatus(job.GetJobStatus(), commonv1.JobFailed, trainingJobFailedReason, msg)
return nil
}
}
updateJobConditions(job.GetJobStatus(), commonv1.LauncherCreated, "", msg)
return nil
}
Let's take two key steps.
4.8.1 CreateHostConfigMap
Get the configuration about host here.
func (r *TrainingJobReconciler) CreateHostConfigMap(job *kaiv1alpha1.TrainingJob) (*corev1.ConfigMap, error) {
return r.createConfigMap(job, newHostfileConfigMap)
}
func (r *TrainingJobReconciler) createConfigMap(job *kaiv1alpha1.TrainingJob, newCm func(job *kaiv1alpha1.TrainingJob) *corev1.ConfigMap) (*corev1.ConfigMap, error) {
cm := &corev1.ConfigMap{}
name := ctrl.Request{}
name.NamespacedName.Namespace = job.GetNamespace()
name.NamespacedName.Name = job.GetName() + configSuffix
err := r.Get(context.Background(), name.NamespacedName, cm)
if errors.IsNotFound(err) {
if err = r.Create(context.Background(), newCm(job)); err != nil {
return cm, err
}
}
return cm, nil
}
4.8.2 Create pod
4.8.2.1 CreateLauncher
pod creation here
func (r *TrainingJobReconciler) CreateLauncher(obj interface{}) (*corev1.Pod, error) {
job, ok := obj.(*kaiv1alpha1.TrainingJob)
launcher := newLauncher(job) // Create pod
if job.GetAttachMode() == kaiv1alpha1.AttachModeSSH {
util.MountRsaKey(launcher, job.Name)
}
err := r.Create(context.Background(), launcher)
return launcher, nil
}
4.8.2.2 newLauncher
Here's how to build a Pod.
func newLauncher(obj interface{}) *corev1.Pod {
job, _ := obj.(*kaiv1alpha1.TrainingJob)
launcherName := job.Name + launcherSuffix
labels := GenLabels(job.Name)
labels[labelTrainingRoleType] = launcher
podSpec := job.Spec.ETReplicaSpecs.Launcher.Template.DeepCopy()
// copy the labels and annotations to pod from PodTemplate
if len(podSpec.Labels) == 0 {
podSpec.Labels = make(map[string]string)
}
for key, value := range labels {
podSpec.Labels[key] = value
}
podSpec.Spec.InitContainers = append(podSpec.Spec.InitContainers, initContainer(job))
//podSpec.Spec.InitContainers = append(podSpec.Spec.InitContainers, kubedeliveryContainer())
container := podSpec.Spec.Containers[0]
container.VolumeMounts = append(container.VolumeMounts,
corev1.VolumeMount{
Name: hostfileVolumeName,
MountPath: hostfileMountPath,
},
corev1.VolumeMount{
Name: configVolumeName,
MountPath: configMountPath,
},
corev1.VolumeMount{
Name: kubectlVolumeName,
MountPath: kubectlMountPath,
})
if job.GetAttachMode() == kaiv1alpha1.AttachModeKubexec {
container.Env = append(container.Env, corev1.EnvVar{
Name: "OMPI_MCA_plm_rsh_agent",
Value: getKubexecPath(),
})
}
podSpec.Spec.Containers[0] = container
podSpec.Spec.ServiceAccountName = launcherName
setRestartPolicy(podSpec)
hostfileMode := int32(0444)
scriptMode := int32(0555)
podSpec.Spec.Volumes = append(podSpec.Spec.Volumes,
corev1.Volume{
Name: hostfileVolumeName,
VolumeSource: corev1.VolumeSource{
EmptyDir: &corev1.EmptyDirVolumeSource{},
},
},
corev1.Volume{
Name: kubectlVolumeName,
VolumeSource: corev1.VolumeSource{
EmptyDir: &corev1.EmptyDirVolumeSource{},
},
},
corev1.Volume{
Name: configVolumeName,
VolumeSource: corev1.VolumeSource{
ConfigMap: &corev1.ConfigMapVolumeSource{
LocalObjectReference: corev1.LocalObjectReference{
Name: job.Name + configSuffix,
},
Items: []corev1.KeyToPath{
{
Key: hostfileName,
Path: hostfileName,
Mode: &hostfileMode,
},
{
Key: discoverHostName,
Path: discoverHostName,
Mode: &hostfileMode,
},
{
Key: kubexeclFileName,
Path: kubexeclFileName,
Mode: &scriptMode,
},
},
},
},
})
return &corev1.Pod{
ObjectMeta: metav1.ObjectMeta{
Name: launcherName,
Namespace: job.Namespace,
Labels: podSpec.Labels,
Annotations: podSpec.Annotations,
OwnerReferences: []metav1.OwnerReference{
*metav1.NewControllerRef(job, kaiv1alpha1.SchemeGroupVersionKind),
},
},
Spec: podSpec.Spec,
}
}
At this point, a new training job has been run with the following logical extensions:
Request("")
K8S ---------------------> Reconcile
+
|
|
v
+----------------------+---------------------+
| ReconcileJobs |
| + |
| | |
| +------------------------------+ |
| | | | |
| v v v |
| "", JobCreated JobRunning Scaling |
+--------+-----------------------------------+
|
|
v
reconcileResource
+
|
|
v
+---------+---------------+
| doSteps | +----> createWorkers +----> createWorker +----> newService
| | |
| | |
| WorkersCreated +---------> createTrainingJobWorkers +-----> CreateWorkers +-------> newWorker +------> WorkersCreated
| |
| |
| WorkersReady +----------> waitWorkersRunning
| |
| |
| LauncherCreated +--------> createLauncher+----> CreateHostConfigMap +-----> CreateLauncher +------> newLauncher
| |
| |
| JobRunning +------------> syncLauncherState
| |
+-------------------------+
Mobile phones are as follows:
Finished creating a new job, let's look at the key technical points of this article, scaleOut and scaleIn.
0x05 ScaleOut
5.1 Ideas
The ScaleOut task CR is as follows:
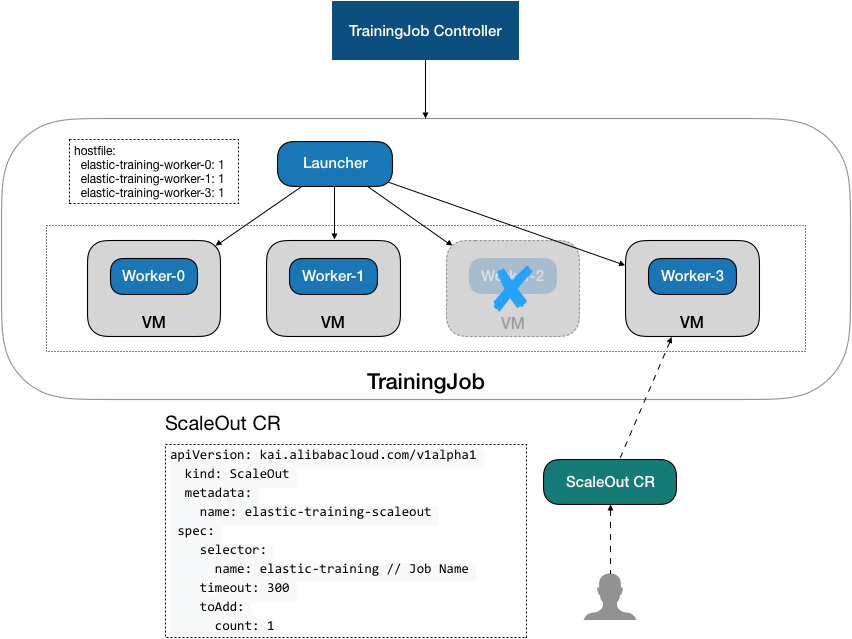
Now a ScaleOut CR is sent, and the ScaleOutController triggers the Reconcile. The simple work here is to find the corresponding TrainingJob for Scaler based on the Selector field in ScaleOut CR and set it on the OwnerReferences of the CR.
Take a ScaleOut operation as an example:
- apiVersion: kai.alibabacloud.com/v1alpha1
kind: ScaleOut
metadata:
creationTimestamp: "2020-11-04T13:54:26Z
name: scaleout-ptfnk
namespace: default
ownerReferences:
- apiVersion: kai.alibabacloud.com/v1alpha1
blockOwnerDeletion: true
controller: true
kind: TrainingJob
name: elastic-training // Pointing to Extension Object TrainingJob
uid: 075b9c4a-22f9-40ce-83c7-656b329a2b9e
spec:
selector:
name: elastic-training
toAdd:
count: 2
5.2 Reconcile
A ScaleOut CR is sent and the ScaleOutController triggers the Reconcile. The main thing is to call setScalingOwner.
func (r *ScaleOutReconciler) Reconcile(req ctrl.Request) (ctrl.Result, error) {
scaleOut, err := getScaleOut(req.NamespacedName, r.Client)
if err != nil {
// Error reading the object - requeue the request.
return RequeueImmediately()
}
if scaleOut == nil || scaleOut.DeletionTimestamp != nil {
return NoRequeue()
}
if isScaleFinished(*scaleOut.GetJobStatus()) {
return NoRequeue()
}
return setScalingOwner(r, scaleOut, r.PollInterval)
}
5.3 setScalingOwner
setScalingOwner is one of the keys.
The main thing to do here is to set one when ScaleOut CR does not have OwnerReferences set.
The logic is to find the TrainingJob corresponding to Scaler based on the Selector field in ScaleOut CR and set it on OwnerReferences of the CR.
func setScalingOwner(r client.Client, scaler Scaler, pollInterval time.Duration) (ctrl.Result, error) {
ownerRefs := scaler.GetOwnerReferences()
if len(ownerRefs) == 0 {
trainingJob := &kaiv1alpha1.TrainingJob{}
nsn := types.NamespacedName{}
nsn.Namespace = scaler.GetNamespace()
nsn.Name = scaler.GetSelector().Name
err := r.Get(context.Background(), nsn, trainingJob)
gvk := kaiv1alpha1.SchemeGroupVersionKind
ownerRefs = append(ownerRefs, *metav1.NewControllerRef(trainingJob, schema.GroupVersionKind{Group: gvk.Group, Version: gvk.Version, Kind: gvk.Kind}))
scaler.SetOwnerReferences(ownerRefs)
initializeJobStatus(scaler.GetJobStatus())
updateJobConditions(scaler.GetJobStatus(), v1.JobCreated, "", msg)
err = r.Status().Update(context.Background(), scaler)
err = r.Update(context.Background(), scaler)
}
return NoRequeue()
}
// RequeueAfterInterval requeues after a duration when duration > 0 is specified.
func RequeueAfterInterval(interval time.Duration, err error) (ctrl.Result, error) {
return ctrl.Result{RequeueAfter: interval}, err
}
5.4 TrainingJobController
Updates to the ScaleOut CR belonging to TrainingJob were heard in TrainingJobController, which triggered the Reeconcile of TrainingJob, traversed to filter the ScaleIn and ScaleOut pointed to by OwnerReference under TrainingJob, and scaled up or down to the creation and state time.
5.4.1 Reconcile
func (r *TrainingJobReconciler) Reconcile(req ctrl.Request) (ctrl.Result, error) {
rlog := r.Log.WithValues("trainingjob", req.NamespacedName)
// Fetch latest training job instance.
sharedTrainingJob := &kaiv1alpha1.TrainingJob{}
err := r.Get(context.Background(), req.NamespacedName, sharedTrainingJob)
trainingJob := sharedTrainingJob.DeepCopy()
// Check reconcile is required.
// No need to do reconcile or job has been deleted.
r.Scheme.Default(trainingJob)
return r.ReconcileJobs(trainingJob)
}
5.4.2 ReconcileJobs
func (r *TrainingJobReconciler) ReconcileJobs(job *kaiv1alpha1.TrainingJob) (result reconcile.Result, err error) {
oldJobStatus := job.Status.DeepCopy()
logger.Infof("jobName: %v, phase %s", job.Name, job.Status.Phase)
defer func() {
latestJob := &kaiv1alpha1.TrainingJob{}
err := r.Get(context.Background(), types.NamespacedName{
Name: job.Name,
Namespace: job.Namespace,
}, latestJob)
if err == nil {
if latestJob.ObjectMeta.ResourceVersion != job.ObjectMeta.ResourceVersion {
latestJob.Status = job.Status
job = latestJob
}
}
r.updateObjectStatus(job, oldJobStatus)
}()
switch job.Status.Phase {
case commonv1.JobSucceeded, commonv1.JobFailed:
err = r.cleanup(job)
case "", commonv1.JobCreated:
r.initializeJob(job)
err = r.reconcileResource(job)
case commonv1.JobRunning:
err = r.reconcileJobRunning(job)
case commonv1.Scaling:
err = r.executeScaling(job)
default:
logger.Warnf("job %s unknown status %s", job.Name, job.Status.Phase)
}
if err != nil {
if IsRequeueError(err) {
return RequeueAfterInterval(r.PollInterval, nil)
}
return RequeueAfterInterval(r.PollInterval, err)
}
return NoRequeue()
}
There are two lines, JobRunning, Scaling, and JobRunning, depending on the current job status.
Let's do one analysis.
5.5 JobRunning
The first step is to get to the JobRunning state, so let's take a look at what to do.
5.5.1 reconcileJobRunning
func (r *TrainingJobReconciler) reconcileJobRunning(job *kaiv1alpha1.TrainingJob) error {
if err := r.syncLauncherState(job); err != nil {
return err
}
if err := r.syncWorkersState(job); err != nil {
return err
}
if job.Status.Phase == commonv1.JobRunning {
return r.setTrainingJobScaler(job) // Now that you are in the JobRunning state, you can start setting up scaler s
}
return nil
}
5.5.2 setTrainingJobScaler
First, through availableScaleOutList or availableScaleInList, then update.
func (r *TrainingJobReconciler) setTrainingJobScaler(job *kaiv1alpha1.TrainingJob) error {
scaleOut, err := r.availableScaleOutList(job) // Find scaleout list
scaleIn, err := r.availableScaleInList(job) // Find scaleIn list
scalerList := append(scaleOut, scaleIn...) // merge
// Select the latest scaling job
r.updateLatestScaler(job, scalerList) // Start Setting
return nil
}
5.5.3 updateLatestScaler
Find the last Scaler based on the creation time and state time.
func (r *TrainingJobReconciler) updateLatestScaler(job *kaiv1alpha1.TrainingJob, scalers []Scaler) error {
var latestScaler Scaler
if len(scalers) == 0 {
return nil
}
for i, _ := range scalers {
scalerItem := scalers[i]
// Find the last Scaler based on creation time and state time
if latestScaler == nil || latestScaler.GetCreationTimestamp().Time.Before(scalerItem.GetCreationTimestamp().Time) {
latestScaler = scalerItem
}
}
return r.updateCurrentScaler(job, latestScaler)
}
5.5.4 updateCurrentScaler
Set the scaler found.
func (r *TrainingJobReconciler) updateCurrentScaler(job *kaiv1alpha1.TrainingJob, scaleItem Scaler) error {
job.Status.CurrentScaler = scaleItem.GetFullName()
msg := fmt.Sprintf("trainingJobob(%s/%s) execute %s", job.Namespace, job.Name, scaleItem.GetFullName())
// Set state
r.updateScalerState(scaleItem, job, newCondition(common.Scaling, scalingStartReason, msg))
if err := r.updateObjectStatus(scaleItem, nil); err != nil {
return err
}
return nil
}
5.5.5 updateScalerState
This will set common.Scaling. So next time you run, you'll go to the Scaling branch.
func (r *TrainingJobReconciler) updateScalerState(scaleObj Scaler, trainingJob *kaiv1alpha1.TrainingJob, condition common.JobCondition) error {
jobPhase := common.Scaling // Set common.Scaling. So next time you run, you'll go to the Scaling branch
currentJob := scaleObj.GetFullName()
if condition.Type == common.ScaleSucceeded || condition.Type == common.ScaleFailed {
jobPhase = common.JobRunning
currentJob = ""
}
setCondition(trainingJob.GetJobStatus(), condition)
updateStatusPhase(trainingJob.GetJobStatus(), jobPhase)
updateTrainingJobCurrentScaler(trainingJob.GetJobStatus(), currentJob)
setCondition(scaleObj.GetJobStatus(), condition)
updateStatusPhase(scaleObj.GetJobStatus(), condition.Type)
return nil
}
The logic is as follows:
1 Request("")
K8S +--------------------> Reconcile <------------------+
2 ScaleOut CR + |
K8S +--------------------> | |
| |
v |
+----------------------+---------------------+ |
| ReconcileJobs | |
| + | |
| | | |
| +------------------------------+ | |
| 1 | | 2 3 | | |
| v v v | |
| "", JobCreated JobRunning Scaling | |
+--------+-------------+---------------------+ |
| | |
1 | | 2 |
v v |
reconcileResource reconcileJobRunning |
+ + |
1 | | 2 |
| | |
v v |
+--------------------+----+ setTrainingJobScaler |
| doSteps | + |
| | | 2 |
| | | |
| WorkersCreated | v |
| | updateScalerState |
| | + |
| WorkersReady | | |
| | | 2 |
| | v |
| LauncherCreated | common.Scaling |
| | + |
| | | |
| JobRunning | | 2 |
| | | |
+-------------------------+ +-------------------------+
5.6 Scaling
5.6.1 executeScaling
Extensions vary depending on the type of scale.
func (r *TrainingJobReconciler) executeScaling(job *kaiv1alpha1.TrainingJob) error {
if err := r.syncLauncherState(job); err != nil {
return err
}
if job.Status.CurrentScaler == "" {
updateStatusPhase(job.GetJobStatus(), common.JobRunning)
return nil
}
if isFinished(*job.GetJobStatus()) {
return nil
}
scalerType, scalerName := getScalerName(job.Status.CurrentScaler)
// Processing differently depending on in or out
if scalerType == "ScaleIn" {
scaleIn, err := getScaleIn(scalerName, r)
if scaleIn == nil || isScaleFinished(*scaleIn.GetJobStatus()) {
finishTrainingScaler(job.GetJobStatus())
return nil
}
oldStatus := scaleIn.Status.DeepCopy()
defer r.updateObjectStatus(scaleIn, oldStatus)
// Perform specific zoom operations
if err = r.executeScaleIn(job, scaleIn); err != nil {
return err
}
} else if scalerType == "ScaleOut" {
scaleOut, err := getScaleOut(scalerName, r)
if scaleOut == nil || isScaleFinished(*scaleOut.GetJobStatus()) {
finishTrainingScaler(job.GetJobStatus())
return nil
}
oldStatus := scaleOut.Status.DeepCopy()
defer r.updateObjectStatus(scaleOut, oldStatus)
// Perform specific capacity expansion operations
if err = r.executeScaleOut(job, scaleOut); err != nil {
}
}
return nil
}
5.6.2 executeScaleOut
Expand.
- Use setScaleOutWorkers for scaleOut.Status.AddPods adds a new pods.
- Use workersAfterScaler to get the final worker.
- Use executeScaleScript to scale.
func (r *TrainingJobReconciler) executeScaleOut(job *kaiv1alpha1.TrainingJob, scaleOut *kaiv1alpha1.ScaleOut) error {
initializeJobStatus(scaleOut.GetJobStatus())
if err := r.validateScaleOut(scaleOut); err != nil {
r.updateScalerFailed(scaleOut, job, err.Error())
return err
}
if err := r.setScaleOutWorkers(job, scaleOut); err != nil {
return err
}
err := r.ScaleOutWorkers(job, scaleOut)
if err != nil {
msg := fmt.Sprintf("%s create scaleout workers failed, error: %v", scaleOut.GetFullName(), err)
r.ScaleOutFailed(job, scaleOut, msg)
return err
}
scaleOutWorkers, err := r.getScalerOutWorkers(job, scaleOut)
workerStatuses, _ := r.workerReplicasStatus(scaleOut.GetJobStatus(), scaleOutWorkers)
if workerStatuses.Active < *scaleOut.Spec.ToAdd.Count {
if IsScaleOutTimeout(scaleOut) {
msg := fmt.Sprintf("scaleout job %s execution timeout", scaleOut.GetFullName())
r.ScaleOutFailed(job, scaleOut, msg)
}
return NewRequeueError(fmt.Errorf("wait for workers running"))
}
hostWorkers := r.workersAfterScaler(job.Status.CurrentWorkers, scaleOut)
// execute scalein script
// Execute scale script
if err := r.executeScaleScript(job, scaleOut, hostWorkers); err != nil {
msg := fmt.Sprintf("%s execute script failed, error: %v", scaleOut.GetFullName(), err)
r.ScaleOutFailed(job, scaleOut, msg)
return err
} else {
job.Status.TargetWorkers = r.workersAfterScaler(job.Status.TargetWorkers, scaleOut)
r.updateScalerSuccessd(scaleOut, job)
}
return nil
}
5.6.3 executeScaleScript
At this point, call hostfileUpdateScript to update the host file;
The executeOnLauncher is finally called to execute the script.
func (r *TrainingJobReconciler) executeScaleScript(trainingJob *kaiv1alpha1.TrainingJob, scaler Scaler, workers []string) error {
if isScriptExecuted(*scaler.GetJobStatus()) {
return nil
}
msg := fmt.Sprintf("trainingjob(%s/%s): execute script on launcher for %s", trainingJob.Namespace, trainingJob.Name, scaler.GetFullName())
slots := getSlots(trainingJob)
scriptSpec := scaler.GetScriptSpec()
var script string
// Get the script
if scriptSpec.Script != "" {
script = scalerScript(scriptSpec.GetTimeout(), scriptSpec.Env, scriptSpec.Script, scaler.GetPodNames(), slots)
} else {
hostfilePath := getHostfilePath(trainingJob)
script = hostfileUpdateScript(hostfilePath, workers, slots)
}
// Execute script
_, _, err := r.executeOnLauncher(trainingJob, script)
updateJobConditions(scaler.GetJobStatus(), common.ScriptExecuted, "", msg)
return nil
}
5.6.3.1 hostfileUpdateScript
Get the final script string.
func hostfileUpdateScript(hostfile string, workers []string, slot int) string {
return fmt.Sprintf(
`echo '%s' > %s`, getHostfileContent(workers, slot), hostfile)
}
5.6.3.2 getHostfileContent
Get host file content
func getHostfileContent(workers []string, slot int) string {
var buffer bytes.Buffer
for _, worker := range workers {
buffer.WriteString(fmt.Sprintf("%s:%d\n", worker, slot))
}
return buffer.String()
}
5.6.3.3 executeOnLauncher
Execute on pod
func (r *TrainingJobReconciler) executeOnLauncher(trainingJob *kaiv1alpha1.TrainingJob, script string) (string, string, error) {
var err error
var launcherPod *corev1.Pod
if launcherPod, err = r.GetLauncherJob(trainingJob); err != nil {
}
if launcherPod != nil {
stdOut, stdErr, err := kubectlOnPod(launcherPod, script)
return stdOut, stdErr, nil
}
return "", "", nil
}
5.6.3.4 kubectlOnPod
Pull the worker.
func kubectlOnPod(pod *corev1.Pod, cmd string) (string, string, error) {
cmds := []string{
"/bin/sh",
"-c",
cmd,
}
stdout, stderr, err := util.ExecCommandInContainerWithFullOutput(pod.Name, pod.Spec.Containers[0].Name, pod.Namespace, cmds)
if err != nil {
return stdout, stderr, err
}
return stdout, stderr, nil
}
The logic is as follows:
1 Request("")
K8S +--------------------> Reconcile <------------------+
2 ScaleOut CR + |
K8S +--------------------> | |
| |
v |
+----------------------+---------------------+ |
| ReconcileJobs | |
| + | |
| | | |
| +------------------------------+ | |
| 1 | | 2 3 | | |
| v v v | | 3
| "", JobCreated JobRunning Scaling +-----------> executeScaling
+--------+-------------+---------------------+ | +
| | | |
1 | | 2 | | 3
v v | v
reconcileResource reconcileJobRunning | executeScaleOut
+ + | +
1 | | 2 | |
| | | | 3
v v | v
+--------------------+----+ setTrainingJobScaler | executeScaleScript
| doSteps | + | +
| | | 2 | |
| | | | | 3
| WorkersCreated | v | v
| | updateScalerState | hostfileUpdateScript
| | + | +
| WorkersReady | | | | 3
| | | 2 | |
| | v | v
| LauncherCreated | common.Scaling | executeOnLauncher
| | + | +
| | | | |
| JobRunning | | 2 | | 3
| | | | v
+-------------------------+ +-------------------------+ kubectlOnPod
0x06 ScaleIn
6.1 Ideas
The ScaleIn task CR is as follows:
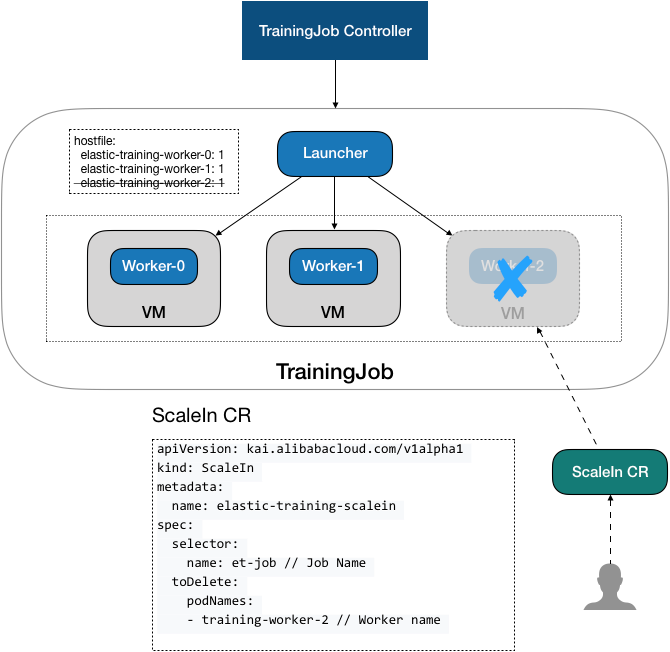
When zooming, you can use spec.toDelete in ScaleIn CR. Count or spec.toDelete. The podNames field specifies a scaled worker.
Configuring the number of shrinks through count calculates the high-to-low shrink Worker through index.
apiVersion: kai.alibabacloud.com/v1alpha1
kind: ScaleIn
metadata:
name: scalein-workers
spec:
selector:
name: elastic-training
toDelete:
count: 1
If you want to shrink a specific Worker, you can configure podNames:
apiVersion: kai.alibabacloud.com/v1alpha1
kind: ScaleIn
metadata:
name: scalein-workers
spec:
selector:
name: elastic-training
toDelete:
podNames:
- elastic-training-worker-1
Run an example of a worker with a specified number of scales:
kubectl create -f examples/scale_in_count.yaml
6.2 Reconcile
A scaleInCR is sent and the Controller triggers the Reconcile. The main thing is to call setScalingOwner.
func (r *ScaleInReconciler) Reconcile(req ctrl.Request) (ctrl.Result, error) {
//silog := r.Log.WithValues("scalein", req.NamespacedName)
scaleIn, err := getScaleIn(req.NamespacedName, r.Client)
if isScaleFinished(*scaleIn.GetJobStatus()) {
return NoRequeue()
}
// These are basically all kinds of checks
return setScalingOwner(r, scaleIn, r.PollInterval)
}
6.3 setScalingOwner
setScalingOwner is one of the keys.
The main thing to do here is to set one when ScaleIn CR does not have OwnerReferences set.
The logic is to find the corresponding TrainingJob for Scaler based on the Selector field in ScaleIn CR and set it on the OwnerReferences of the CR.
The various error check codes are removed below.
func setScalingOwner(r client.Client, scaler Scaler, pollInterval time.Duration) (ctrl.Result, error) {
ownerRefs := scaler.GetOwnerReferences()
if len(ownerRefs) == 0 {
trainingJob := &kaiv1alpha1.TrainingJob{}
nsn := types.NamespacedName{}
nsn.Namespace = scaler.GetNamespace()
nsn.Name = scaler.GetSelector().Name
err := r.Get(context.Background(), nsn, trainingJob)
gvk := kaiv1alpha1.SchemeGroupVersionKind
ownerRefs = append(ownerRefs, *metav1.NewControllerRef(trainingJob, schema.GroupVersionKind{Group: gvk.Group, Version: gvk.Version, Kind: gvk.Kind}))
scaler.SetOwnerReferences(ownerRefs)
initializeJobStatus(scaler.GetJobStatus())
updateJobConditions(scaler.GetJobStatus(), v1.JobCreated, "", msg)
err = r.Status().Update(context.Background(), scaler)
err = r.Update(context.Background(), scaler)
}
return NoRequeue()
}
6.4 executeScaleIn
JobRunning state processing is similar to ScaleOut, so skip and look directly at processing executeScaleIn.
When zooming, you can use spec.toDelete in ScaleIn CR. Count or spec.toDelete. The podNames field specifies a scaled worker.
Configuring the number of shrinks through count calculates the high-to-low shrink Worker through index.
The specific combination code is:
setsSaleInToDelete specifies which to delete;
executeScaleScript executes the script;
DeleteWorkers deletes the worker;
func (r *TrainingJobReconciler) executeScaleIn(job *kaiv1alpha1.TrainingJob, scaleIn *kaiv1alpha1.ScaleIn) error {
if scaleIn.DeletionTimestamp != nil || isScaleFinished(*scaleIn.GetJobStatus()) {
logger.Info("reconcile cancelled, scalein does not need to do reconcile or has been deleted")
return nil
}
initializeJobStatus(scaleIn.GetJobStatus())
//TODO: Validate the scalein count for minSize
err := r.setsSaleInToDelete(job, scaleIn)
currentWorkers := r.workersAfterScaler(job.Status.CurrentWorkers, scaleIn)
// execute scalein script
if err := r.executeScaleScript(job, scaleIn, currentWorkers); err != nil {
msg := fmt.Sprintf("%s execute script failed, error: %v", scaleIn.GetFullName(), err)
r.updateScalerFailed(scaleIn, job, msg)
return nil
}
toDeleteWorkers := scaleIn.GetPodNames()
remainWorkers := false
if scaleIn.Spec.Script == "" {
if shutdownWorkers, err := r.checkWorkerShutdown(job, toDeleteWorkers); err != nil {
return err
} else {
if len(toDeleteWorkers) != len(shutdownWorkers) {
remainWorkers = true
toDeleteWorkers = shutdownWorkers
}
}
}
if err := r.DeleteWorkers(job, toDeleteWorkers); err != nil {
msg := fmt.Sprintf("%s delete resource failed, error: %v", scaleIn.GetFullName(), err)
r.updateScalerFailed(scaleIn, job, msg)
return nil
}
// wait pods deleted
deleted, _ := r.isWorkersDeleted(job.Namespace, scaleIn.GetPodNames())
if deleted {
job.Status.TargetWorkers = r.workersAfterScaler(job.Status.TargetWorkers, scaleIn)
job.Status.CurrentWorkers = currentWorkers
r.updateScalerSuccessd(scaleIn, job)
return nil
}
if remainWorkers {
msg := "wait for workers process shutdown"
logger.Info(msg)
return NewRequeueError(fmt.Errorf(msg))
}
return nil
}
6.5 setsSaleInToDelete
Through spec.toDelete in ScaleIn CR. Count or spec.toDelete. The podNames field specifies a scaled worker.
func (r *TrainingJobReconciler) setsSaleInToDelete(job *kaiv1alpha1.TrainingJob, scaleIn *kaiv1alpha1.ScaleIn) error {
podNames := scaleIn.Status.ToDeletePods
if len(podNames) != 0 {
return /*filterPodNames(workers, podNames, false), */ nil
}
workers, err := r.GetWorkerPods(job)
toDelete := scaleIn.Spec.ToDelete
if toDelete.PodNames != nil {
workers = filterPodNames(workers, toDelete.PodNames, false)
} else if toDelete.Count > 0 {
if toDelete.Count < len(workers) {
allPodNames := getSortPodNames(job.Name, workers)
deletePodNames := allPodNames[len(workers)-toDelete.Count:]
workers = filterPodNames(workers, deletePodNames, false)
}
}
for _, worker := range workers {
scaleIn.Status.ToDeletePods = append(scaleIn.Status.ToDeletePods, worker.Name)
}
return nil
}
6.6 DeleteWorkers
Delete the worker service and pods specifically.
func (r *TrainingJobReconciler) DeleteWorkers(trainingJob *kaiv1alpha1.TrainingJob, workers []string) error {
if err := r.DeleteWorkerServices(trainingJob, workers); err != nil {
return fmt.Errorf("delete services failed: %++v", err)
}
if err := r.DeleteWorkerPods(trainingJob, workers); err != nil {
return fmt.Errorf("delete pods failed: %++v", err)
}
return nil
}
6.7 DeleteWorkerPods
Delete pods.
func (r *TrainingJobReconciler) DeleteWorkerPods(job *kaiv1alpha1.TrainingJob, pods []string) error {
workerPods, err := r.GetWorkerPods(job)
if pods != nil {
workerPods = filterPodNames(workerPods, pods, false)
}
for _, pod := range workerPods {
deleteOptions := &client.DeleteOptions{GracePeriodSeconds: utilpointer.Int64Ptr(0)}
if err := r.Delete(context.Background(), &pod, deleteOptions); err != nil && !errors.IsNotFound(err) {
r.recorder.Eventf(job, corev1.EventTypeWarning, trainingJobFailedReason, "Error deleting worker %s: %v", pod.Name, err)
//return err
}
r.recorder.Eventf(job, corev1.EventTypeNormal, trainingJobSucceededReason, "Deleted pod %s", pod.Name)
}
return nil
}
The logic is as follows:
1 Request("")
K8S-----------------> Reconcile <------------------+
2 ScaleOut CR + |
K8S-----------------> | |
| |
v |
+----------------------+---------------------+ |
| ReconcileJobs | |
| + | |
| | | |
| +------------------------------+ | |
| 1 | | 2 3 | | |
| v v v | | 3
| "", JobCreated JobRunning Scaling +---------> executeScaling -----+
+--------+-------------+---------------------+ | + |
| | | | |
1 | | 2 | | 3 | 4
v v | v v
reconcileResource reconcileJobRunning | executeScaleOut executeScaleIn
+ + | + +
1 | | 2 | | |
| | | | 3 | 4
v v | v v
+------------+--------+ setTrainingJobScaler | executeScaleScript executeScaleScript
| doSteps | + | + +
| | | 2 | | |
| | | | | 3 | 4
| WorkersCreated | v | v v
| | updateScalerState | hostfileUpdateScript DeleteWorkers
| | + | + +
| WorkersReady | | | | 3 | 4
| | | 2 | | |
| | v | v v
| LauncherCreated | common.Scaling | executeOnLauncher DeleteWorkerPods
| | + | + +
| | | | | |
| JobRunning | | 2 | | 3 | 4
| | | | v v
+---------------------+ +-------------------------+ kubectlOnPod Delete
Now that the Horovod series has been analyzed, look forward to the next article on parameter servers.
0xEE Personal Information
Thoughts on Life and Technology
WeChat Public Account: Rosie's Thoughts
Stay tuned if you want to get timely news feeds from individuals who write articles or if you want to see the technical data that they recommend.
