This article mainly introduces the operation of Python to crawl the hero winning rate and selection rate information of the hero League on OPGG. It has a good reference value and hopes to be helpful to you. Let's follow Xiaobian and have a look
The website is opgg, and the website is: http://www.op.gg/champion/statistics
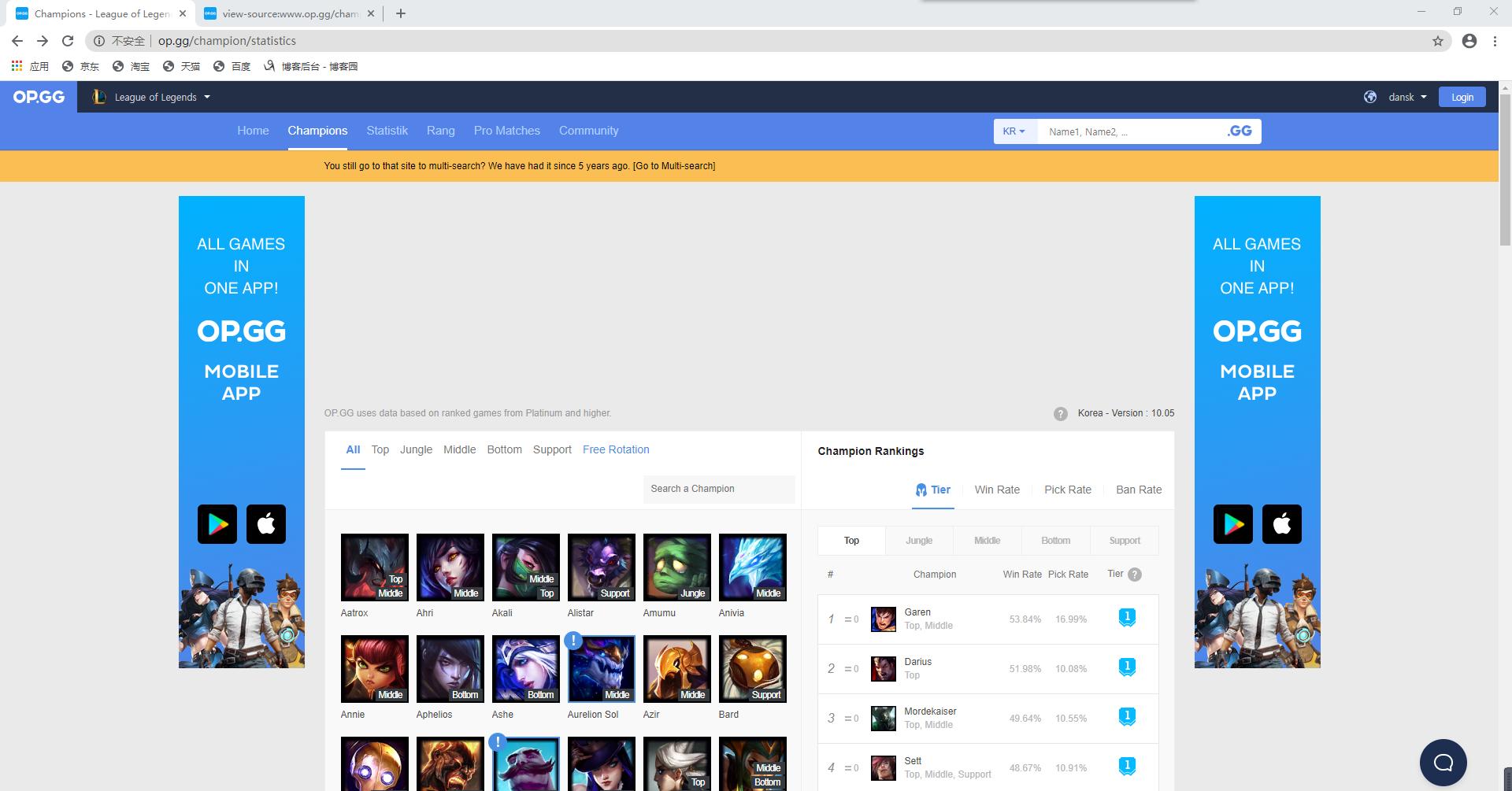
It can be seen from the website interface that there are details of heroes on the right. Taking Garen as an example, the winning rate is 53.84%, the selection rate is 16.99%, and the common location is the previous order
Now analyze the web page source code (right click the mouse in the menu to find and view the web page source code). Quickly locate Garen by finding "53.84%"

It can be seen from the code that the hero name, winning rate and selection rate are all in the td tag, and each hero information is in a tr tag. The td parent tag is the TR tag and the TR parent tag is the tbody tag.
Find the tbody tag

There are 5 tbody tags in the code (there are "tbody" at the beginning and end of the tbody tag, so there are 10 "tbody") in total. Analyze the field contents, including the previous order, playing field, medium order, ADC and auxiliary information

For the heroes in the above list, we need to first find the tbody tag, then find the tr tag (each tr tag is the information of a hero), and then get the details of the hero from the sub tag td tag
2, Crawling steps
Crawl website content - > extract required information - > output hero data
getHTMLText(url)->fillHeroInformation(hlist,html)->printHeroInformation(hlist)
The getHTMLText(url) function returns the html content in the url link
The fillHeroInformation(hlist,html) function extracts the required information from html and stores it in the hlist list
The printHeroInformation(hlist) function outputs the hero information in the hlist list
3, Code implementation
1. getHTMLText(url) function
def getHTMLText(url): #Return html document information
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text #Return html content
except:
return ""
2. fillHeroInformation(hlist,html) function

Take a tr tag as an example. There are seven td tags in the TR tag. The div tag with the attribute value of "champion index table_name" in the fourth td tag is the hero name, the fifth td tag is the winning rate, and the sixth td tag is the selection rate. Store these information in the hlist list
def fillHeroInformation(hlist,html): #Save hero information to hlist list
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find(name = "tbody",attrs = "tabItem champion-trend-tier-TOP").children: #Traverse the child tag of the previous single tbody tag
if isinstance(tr,bs4.element.Tag): #Judge whether tr is a tag type and remove empty lines
tds = tr('td') #Find the td tag under the tr tag
heroName = tds[3].find(attrs = "champion-index-table__name").string #Hero name
winRate = tds[4].string #winning probability
pickRate = tds[5].string #Selection rate
hlist.append([heroName,winRate,pickRate]) #Add hero info to hlist list
3. printHeroInformation(hlist) function
def printHeroInformation(hlist): #Output hlist list information
print("{:^20}\t{:^20}\t{:^20}\t{:^20}".format("Hero name","winning probability","Selection rate","position"))
for i in range(len(hlist)):
i = hlist[i]
print("{:^20}\t{:^20}\t{:^20}\t{:^20}".format(i[0],i[1],i[2],"top"))
4. main() function
Assign the website address to the url, create a new hlist list, call the getHTMLText(url) function to obtain the html document information, use the fillHeroInformation(hlist,html) function to store the hero information in the hlist list, and then use the printHeroInformation(hlist) function to output the information
def main():
url = "http://www.op.gg/champion/statistics"
hlist = []
html = getHTMLText(url) #Get html document information
fillHeroInformation(hlist,html) #Write hero information to hlist list
printHeroInformation(hlist) #Output information
4, Result demonstration
1. Website interface information

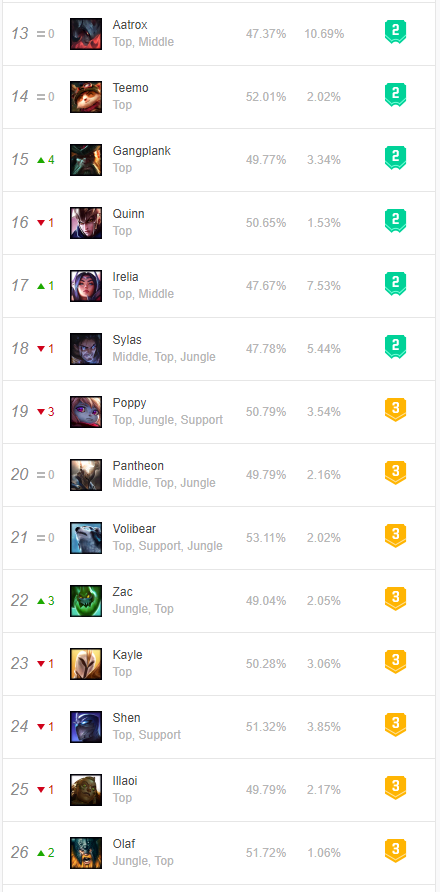
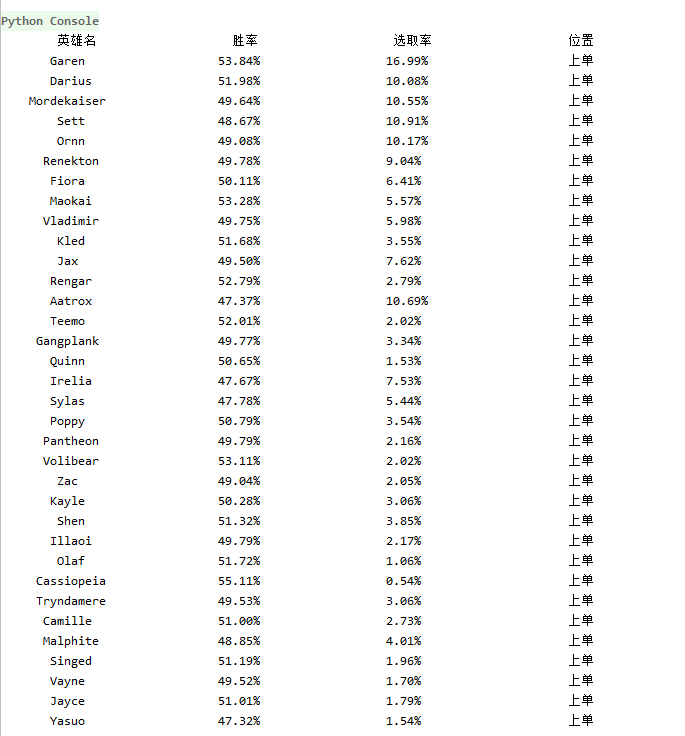
2. Crawling results

5, Complete code
import requests #Import requests Library
import bs4 #Import bs4 Library
from bs4 import BeautifulSoup #Import BeautifulSoup Library
def getHTMLText(url): #Return html document information
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text #Return html content
except:
return ""
def fillHeroInformation(hlist,html): #Save hero information to hlist list
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find(name = "tbody",attrs = "tabItem champion-trend-tier-TOP").children: #Traverse the child tag of the previous single tbody tag
if isinstance(tr,bs4.element.Tag): #Judge whether tr is a tag type and remove empty lines
tds = tr('td') #Find the td tag under the tr tag
heroName = tds[3].find(attrs = "champion-index-table__name").string #Hero name
winRate = tds[4].string #winning probability
pickRate = tds[5].string #Selection rate
hlist.append([heroName,winRate,pickRate]) #Add hero info to hlist list
def printHeroInformation(hlist): #Output hlist list information
print("{:^20}\t{:^20}\t{:^20}\t{:^20}".format("Hero name","winning probability","Selection rate","position"))
for i in range(len(hlist)):
i = hlist[i]
print("{:^20}\t{:^20}\t{:^20}\t{:^20}".format(i[0],i[1],i[2],"top"))
def main():
url = "http://www.op.gg/champion/statistics"
hlist = []
html = getHTMLText(url) #Get html document information
fillHeroInformation(hlist,html) #Write hero information to hlist list
printHeroInformation(hlist) #Output information
main()
If you need to crawl the field, medium order, ADC or auxiliary information, you only need to modify it
fillHeroInformation(hlist,html)
In function
for tr in soup.find(name = "tbody",attrs = "tabItem champion-trend-tier-TOP").children sentence
Modify the attrs attribute value to
"tabItem champion-trend-tier-JUNGLE"
"tabItem champion-trend-tier-MID"
"tabItem champion-trend-tier-ADC"
"tabItem champion-trend-tier-SUPPORT"
Just wait!
The above is my personal experience. I hope I can give you a reference, and I hope you can support the script house. If you have any mistakes or don't consider completely, please don't hesitate to comment.