starting point
I have been using the computer for decades. In this process, I have experienced the collapse of software system, the damage of hard disk, the hanging of mainboard, the update of computer and the change of external memory. I have accumulated a lot of data / files over time. Sometimes I have deliberately backed up several times for important photos. In order to save the backup of various stages for the project that took several months, sorting out these data is a headache, Of course, it doesn't matter. Anyway, storage media are getting cheaper and cheaper. Here's the laziest way. As long as you grasp it, you can basically find what you need quickly.
Recommend a time-saving and easy-to-use lazy method suitable for mass users
prerequisite:
- All data are on the local win computer;
- File names have their own characteristics, which are easy to identify. You can know the contents of the file name at a glance;
- A query artifact is installed on the computer Listary , please refer to the previous link for details.
This is the most time-saving and easy-to-use lazy method. It should be the best solution for users who don't have a large amount of personal + data and rarely change computers. As long as you can do the second point well and install Listary at the same time, generally speaking, you can avoid the dilemma of missing files, and you can find characteristic files immediately even in a mess, This method should be able to meet 95% of individual users; There is no best method for everyone in the world, only the method that is most suitable for you; If you choose this lazy scheme, you don't have to look at the following introduction.
For people who work with computers all day, they need to think more about this problem, so as to find the data or documents you need faster, avoid repeated work, and avoid valuable data being buried and forgotten. For a long time in the past, I have been looking for suitable tools. I have been trying to find out the duplicate files and reorganize the files, but I haven't found a suitable tool. I didn't see hope until I saw some Python sharing recently. At the same time, I also saw that relying on tools alone is not enough. The foundation should be more important, so let's start from the foundation.
Manage the basis of documents
Although there are the above lazy methods, there will still be sequelae. You will find problems during migration at the latest, so it is very important to lay a good foundation.
Without the help of the system, this matter should be considered from three perspectives:
I Classification of data / files
a. For individuals, important + confidential data (passwords, keys, certificates or photos related to property or identity authentication, the highest level of confidentiality). This kind of data has high confidentiality requirements, but the quantity and volume are relatively small. These data can be backed up in multiple places;
b. Personal and family information (relatively speaking, confidentiality requirements are not high, such as incoming and outgoing letters, various applications / job seekers, monthly bills, insurance policies, various certificates, etc.);
c. Photos, videos and audio (these are very large, of course, there are many or garbage without retention value);
d. Education / learning (books, educational videos, learning materials, etc.);
e. Related to work, in reality, it is very common to use employees' private computers in enterprises, so it is also important to separate private data from company data;
f. Software, the usage habits in this aspect will cause great differences. In order to avoid unnecessary virus risk, using the virus-free software package verified by yourself is a safer method and saves more time.
What we are talking about here is classification. We can treat these classifications differently, which is also the basis of organized management, so it is very important!
II Where data / documents are stored
When you walk into an office and glance at the computer screen, most of the computer desktops are full. The clean owner of the computer desktop is usually dressed up. His computer is not used for work; Everyone has their own habits and hobbies. The desktop is a very convenient and intuitive place, but it is not a good place to save files for a long time. Because the desktop is in Disk C, it is not easy to be too large. For a single computer, there is a certain emphasis on where to store data / files;
Generally, it is recommended that the computer is divided into 4 disks, namely, C, D, E, F and disk; The following figure is the recommended specification for enterprises. Individuals can also refer to it.
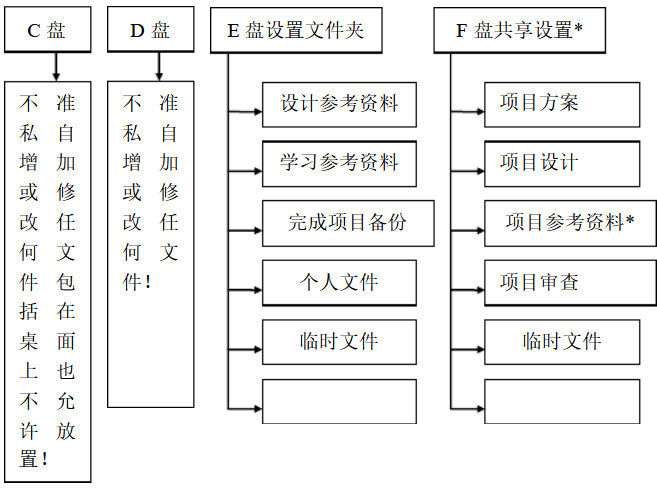 Generally, Disk C can be set to 100G. If you have experience, it can be reduced accordingly. Disk D 100G is enough. The rest can be distributed to E and f according to your needs. F is only needed for public and private use of your computer. An important advantage of such partition is that in addition to being organized, in case of problems in the win system, the E disk data can be easily copied, and the E disk data can not be overwritten by reinstalling win.
Generally, Disk C can be set to 100G. If you have experience, it can be reduced accordingly. Disk D 100G is enough. The rest can be distributed to E and f according to your needs. F is only needed for public and private use of your computer. An important advantage of such partition is that in addition to being organized, in case of problems in the win system, the E disk data can be easily copied, and the E disk data can not be overwritten by reinstalling win.
In addition, we usually have mobile hard disk drive , U SB flash disk Cloud disk,SAN Or shared hard disk of LAN; Taking a little time to understand and plan here will make you get rich returns in the future. Reasonable multiple backups of important files, such as mobile hard disk + cloud disk backup, will enable you to reduce or avoid the impact of emergencies.
This place will be ignored by many people. Most people may always live well and have no trouble in their life, but many people must have learned a painful lesson.
III Specification and skills of data / file name and folder name
Good name: it is clear at a glance, so that people can know the contents without further viewing, so as to avoid questions. In addition, there are other attributes, such as owner, place time, creation time, serial number, version number and serial number.
It is best to be unique, with characteristics, easy to remember + easy to search
If you need to separate keywords from file names, underline them instead of spaces.
Introduce document version management and document number at the end of the file name.
Except for the period in western Do not include commas, semicolons, minus signs, quotation marks and question marks.
Different scenarios have different requirements, and rules can be flexibly used for naming. For example, for documents received from colleagues, keep the source file name, which can facilitate collaborative work.
| number | File name example |
|---|---|
| 1 | Alipay Po_ Monthly report_ 2021.11.xlsx (PO is the account owner, November 2021) |
| 2 | Night view of Suzhou River_ Dog_ 2021.10_SDIM8079.X3F (ah Gou is the photographer, SDIM8079.X3F is the original file name of the photo) |
If the work unit doesn't require it, maybe not many people will be so self disciplined. In the private field, almost no one will spend time on it. Just when you look at the photos 20 years ago, you may feel it necessary. Of course, if you master some name change tools, you will find that it doesn't take so much trouble.
Tools and methods for querying duplicate files
As mentioned earlier, the computer has been used for decades and has accumulated a lot of data. The computer has been changed for several waves. Now it also uses several computers at the same time. Secondly, it also uses the shared hard disk of the LAN. Therefore, the situation is relatively complex. Over time, a lot of duplicate files have been generated. The first thing I think of is to use ready-made tools.
Off the shelf query tool
There are a lot of sharing about query tools on the Internet, and some introductions are also very detailed. Some are listed below for reference:
Duplicate Cleaner
Ashisoft Duplicate File Finder Pro
EF Duplicate MP3 Finder
Puran Duplicate File Finder
FindDuplicate Introduction of these five models
DoubleKiller
dupeGuru
CCleaner Free
 These tools have a feature that they are operable when the number of repetitions is small. When the amount is large, it is actually too time-consuming and people can hardly see the hope of ending. So after using CCleaner Free several times, it stopped.
These tools have a feature that they are operable when the number of repetitions is small. When the amount is large, it is actually too time-consuming and people can hardly see the hope of ending. So after using CCleaner Free several times, it stopped.
Python sharing on the Internet
Many Python shares about finding duplicate files can be found on the Internet, but there are still certain requirements for users. At least they should be able to build a python environment. The following two shares should be detailed enough: 1. Installing Python under Windows,2. Build win, IOS, UNIX and python environment.
The following is the online sharing that has been tested and can run
#coding:utf-8
import os
def walk(dirname):
'''
Output all files in the specified directory and files in subfolders with a list as an absolute path.
'''
names = []
for name in os.listdir(dirname):
# os.listdir() Return a list containing the names of the entries in the directory given by path.
path = os.path.join(dirname, name)
# os.path.join() Join one or more path components intelligently
if os.path.isfile(path):
# os.path.isfile() Return True if path is an existing regular file. Determine whether it is a file
names.append(path)
else:
names.extend(walk(path)) # list.extend()
return names # Returns the list of all files under the specified file
def find_suffix_file(dirname, suffix):
'''
Outputs files with the specified suffix in a list.
'''
target_files = []
names = walk(dirname) # Call the custom function walk()
for name in names:
if name.endswith(suffix):
target_files.append(name)
return target_files # Return to target file list
def call_cmd(cmd):
'''
windows Next file MD5 Equal verification:(LINUX Next, use md5sum command)
certutil -hashfile route/file.exe MD5
certutil -hashfile route/file.exe SHA1
certutil -hashfile route/file.exe SHA256
'''
fp = os.popen(cmd) # Call the system command line under Python to return a file object
# Open a pipe to or from command cmd.
# The return value is an open file object connected to the pipe,
# which can be read or written depending on whether mode is 'r' (default) or 'w'.
result = fp.read() # Read the contents returned by the command line execution
state = fp.close() # Close file object
assert state is None # Asserts whether the file object is closed
return result # Returns the result of a command line calculation
def compute_md5(filename):
'''
compute the MD5 value of the file
'''
# Build command line command
cmd = 'certutil -hashfile "' + filename + '" MD5'
# Note: when the command is built, because the file path contains spaces, the spaces will be recognized as separators when the command line is executed,
# It is incorrectly identified as multiple parameters, resulting in the error "CertUtil: too many parameters".
# Therefore, the file path should be enclosed in double quotation marks' '.
result = call_cmd(cmd) # Call CMD to calculate MD5 value
file_md5 = tuple(result.split('\n'))[1] # Parse the read content,
return file_md5 # Returns the MD5 value of the file
def check_file(dirname, suffix):
d = {} # Create an empty dictionary. Add md5_value as key and file as value
target_files = find_suffix_file(dirname, suffix)
for file in target_files:
md5_value = compute_md5(file) # Calculate md5_value
if md5_value in d: #
d[md5_value].append(file) # Collect file s with the same MD5 value as a list
else:
d[md5_value] = [file]
for md5_value, file in d.items():
if len(file)>1: # If it is greater than 1, it indicates that there are likely to be duplicate files with different file names.
print(file) # Here is a list of duplicate file s collected
if __name__ == '__main__':
# Note: under the specified directory, when the file path contains spaces, an error AssertionError will be reported
dirname = r'D:\CloudMusic' #Pay attention to the writing method of path under Windows
suffix = '.mp3'
check_file(dirname, suffix)
Original source: Python [exercise] find duplicate files in the specified directory and print them
But this program can't be wrong. If there is an empty file, the program will make an error, and there are other possibilities of error. In addition, this program is too slow. More than fifty G of data takes more than 10 hours. If there is an error, we have to start from scratch, so this program can only be used for a small amount of data.
Another solution idea
Reading files one by one in Python is still a problem when there are a large number of files. There are native commands to traverse folders on windows and Linux, which is much faster. Then use this file to read the MD5 value of the file, and then compare the MD5 value to find out the duplicate files. This is much faster, but there are still many troubles. If there is Chinese windows, There are still many unexpected problems when English windows is mixed with other Western windows. Here are some necessary steps:
Step 1: traverse the folder with the following Dos command
This Dos command is very fast. It can be saved in a few seconds as folders txt
dir d:\software /s >folders.txt
Open folders Txt file
Driver D The volume in is doc
The serial number of the volume is 16 E2-F484
D:\software Directory of
2020/10/28 20:28 <DIR> .
2020/10/28 20:28 <DIR> ..
2020/10/28 20:51 <DIR> Adobe Acrobat DC 2018 SP
2019/01/03 10:58 32,044,568 BaiduNetdisk_6.7.0.8.exe
2020/08/03 05:47 <DIR> e6440_driver
2020/05/10 11:02 76,324,794 FirefoxPortable64-76.0.zip
2020/08/03 05:47 <DIR> FirefoxPortable64-81
2020/08/08 06:23 148,454,821 gnucash-4.0.setup.exe
2019/01/02 10:10 4,366,368 npp.7.6.2.Installer.exe
2020/08/03 05:47 <DIR> printer
2020/08/13 06:45 <DIR> tools
2019/09/09 12:01 7,941,304 TreeSizeFreeSetup.exe
2019/02/07 08:13 37,926,600 WeChat_C1012.exe
2020/07/04 19:36 28,258 wolcmd.zip
7 Files three hundred and seven,086,713 byte
D:\software\Adobe Acrobat DC 2018 SP Directory of
......
D:\software\tools\wolcmd Directory of
2020/08/13 06:44 <DIR> .
2020/08/13 06:44 <DIR> ..
2020/08/13 06:44 50,176 WolCmd.exe
1 Files 50,176 byte
Total number of documents listed:
2014 Files 2,352,871,091 byte
815 Directories 249,901,621,248 Available bytes
Use LS - LR > folders under Linux Txt is also very fast.
Next, you can complete the following steps in Python
Step 2: clean the DOS output table above
This is a difficult part, because there is a lot of uncertainty, which varies from person to person. For example, files with size 0, file names with commas or question marks, etc. will make mistakes. This is also a clear problem, and there are errors for unknown reasons, so the Code is omitted. If your file is relatively simple, it may not be so troublesome, so you don't need this step. Just do the third step directly. If there is a problem, you will continue to interrupt the fourth step until the problem is eliminated.
Step 3: build - > Folder + file name
In this step, you should pay attention to impfilename - > folders Txt is whether the name and format of the exported file in the first step match the following program. If not, several parameters need to be changed.
# Build folder + file name, e.g. D:\software\WeChat_C1012.exe
import pandas as pd
from pandas import DataFrame
import time
import chardet
impfilename = 'E:\\temp\\folders.txt' # The folder name can be adjusted according to the situation
expfilename = 'E:\\temp\\Export file name.txt'
print('start time Begin: ', time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
f = open(impfilename,'rb')
content = f.read()
result = chardet.detect(content)
f.close()
coding = result.get('encoding')
df = pd.read_csv(impfilename,header= None,encoding=coding,sep=';')
# Chinese version
dateformat = '%Y/%m/%d' # Chinese date format
directory = ' Directory of'
erase = '<DIR> .| Files| Available bytes|The serial number of the volume is|Driver'
df = df[~df[0].str.contains(erase)]
df[1] = df[0].str[36:] # Intercept file name
df[2] = df[0].str[33:35] # The last two digits of the intercepted file size = '0' to be excluded
df[3] = df[0].str[:10]
df[3] = pd.to_datetime(df[3], format=dateformat, errors='coerce')
df_dir = df
df_dir.loc[df_dir[0].str.contains(directory), 1] = df_dir[0].str[1:-4]
df_dir.loc[df_dir[0].str.contains(directory), 2] = directory
df_dir = df_dir.drop(df_dir[df_dir[2] == ' 0'].index) # Delete rows of size 0
df_dir_columns = df_dir.columns
df_dir_filename = list(df_dir[df_dir_columns[1]].values)
df_dir_dimtext = list(df_dir[df_dir_columns[2]].values)
df_dir_date = list(df_dir[df_dir_columns[3]].values)
filename=[]
for i in range(len(df_dir_filename)):
if df_dir_dimtext[i] == directory:
fdirectory = df_dir_filename[i]
i = i + 1
while pd.notnull(df_dir_date[i]) == True:
filename.append(fdirectory + "\\" + df_dir_filename[i])
i = i + 1
if i >= len(df_dir_filename):
break
else:
# skip entry
pass
DataFrame(filename).to_csv(expfilename, quoting=1, mode='w', index=False, header=False, encoding='utf-8')
print('End time End: ', time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
Output result:
"D:\software\BaiduNetdisk_6.7.0.8.exe" "D:\software\FirefoxPortable64-76.0.zip" "D:\software\gnucash-4.0.setup.exe" "D:\software\npp.7.6.2.Installer.exe" "D:\software\TreeSizeFreeSetup.exe" "D:\software\WeChat_C1012.exe" "D:\software\wolcmd.zip" "D:\software\Adobe Acrobat DC 2018 SP\ABCPY.INI" "D:\software\Adobe Acrobat DC 2018 SP\AcroPro.msi" ............ "D:\software\tools\ccsetup568.exe" "D:\software\tools\HDTune Pro v5.6\HDTune Pro v5.6.exe" "D:\software\tools\HDTune Pro v5.6\SN.txt" "D:\software\tools\wolcmd\WolCmd.exe"
Approximate speed: from thousands to tens of thousands of pieces are completed in a few seconds.
Step 4: read out the MD5 value to generate a summary table
This step takes a long time, because the computer needs to access the files one by one, which is also an error prone part, because even if there seems to be no problem in win, there may be an error when accessing the files with Dos command.
Finally, a summary table of folder + file name + md5 code is generated
import pandas as pd
from pandas import DataFrame
import time
import os
impfilename = 'E:\\temp\\Your import file name.txt'
expfilename = 'E:\\temp\\filename_md5no.txt'
df = pd.read_csv(impfilename, header=0, encoding="utf-8", sep=';')
df_columns = df.columns
df_filename = list(df[df_columns[0]].values)
df_md5 =[]
def call_cmd(cmd):
# print(cmd)
fp = os.popen(cmd) # Call the system command line under Python to return a file object
result = fp.read() # Read the contents returned by the command line execution
state = fp.close() # Close file object
return result # Returns the result of a command line calculation
def compute_md5(filename):
# Build command line command
cmd = 'certutil -hashfile "' + filename + '" MD5'
try:
result = call_cmd(cmd) # Call CMD to calculate MD5 value
file_md5 = tuple(result.split('\n'))[1] # Parse the read content,
except FileNmaeError:
print('Error: Invalid argument. i:', i,'Error file name:' ,filename)
return file_md5 # Returns the MD5 value of the file
if __name__ == '__main__':
# exportzeil = []
print('start time Begin: ', time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
print (df_filename)
print (df.columns)
for i in range(len(df_filename)):
filename = df_filename[i]
md5nr_s = compute_md5(filename)
df_md5.append("'" + filename + "'" + ";" + md5nr_s)
i = i + 1
df2 = df_md5[0:]
DataFrame(df2).to_csv(expfilename, quoting=0, mode='w', index=False, header=False, encoding='utf-8')
print('End time End: ', time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
The output results are as follows:
'D:\software\BaiduNetdisk_6.7.0.8.exe';5e1f5a17f624ce31dfca9456b62caaff 'D:\software\FirefoxPortable64-76.0.zip';6a7959a947ec63b50a5dab7c0bdea0b4 ... ... ... ... 'D:\software\tools\wolcmd\WolCmd.exe';803d8f3dcea3ac390a5e371c83c33061
Step 5: compare the summary table to find out the duplicate values
In the general table of step 4, duplicate documents are found by comparison. The purpose of separating step 4 and step 5 is to compare more flexibly and faster. The general table can be completed in sections when necessary. If you think clearly, you may like this practice.
import pandas as pd
from pandas import DataFrame
impfilename = 'E:\\temp\\filename_md5no.txt' #Replace the corresponding file name
expfilename = 'C:\\Users\\internet\Downloads\\E:\\temp\\d_md5_files.txt'
df = pd.read_csv(impfilename, header=None,sep=';',names=['name', 'md5'])
filenames = list(df['name'].values)
md5s = list(df['md5'].values)
d = {}
d_name=[]
for i in range(len(filenames)):
md5 = md5s[i]
filename = filenames[i]
if md5 in d:
d[md5].append(filename)
i=i+1
else:
d[md5] = [filename]
i=i+1
for md6, file in d.items():
if len(file)>1:
d_name.append(file)
df2 = d_name[1:]
DataFrame(df2).to_csv(expfilename, quoting=0, mode='w', index=False, header=False, encoding='utf-8',sep=';')
Duplicate file name output
d:\software\FirefoxPortable64-81\FirefoxPortable64\App\DefaultData\settings\FirefoxPortableSettings.ini; d:\software\FirefoxPortable64-81\FirefoxPortable64\Data\settings\FirefoxPortableSettings.ini d:\software\FirefoxPortable64-81\FirefoxPortable64\Other\Source\License.txt; d:\software\FirefoxPortable64-81\FirefoxPortable64\Data\profile\gmp-widevinecdm\4.10.1582.2\License.txt ............
In the case of large amount of data, duplicate file names may be very long and can be processed in EXCEL. In principle, it is not recommended to use automatic processing, because automatic deletion is too easy and it is too late to find errors, so it is not recommended to delete them automatically.
Step six? Probably the most effective cleaning method - > compressed package
In the process of processing more than 50 G files, it is found that a little processing of many old data can greatly reduce the burden of management. In terms of the number of data, the number of self-produced files is very limited. The largest number of self-produced files may be photos, but the number of photos with preservation value should also be very limited; The largest number of possible learning materials, especially software packages, project data or materials downloaded from the Internet. These materials are time-consuming. Some can be deleted, but some still have retention value. Here is a method to greatly reduce the number of files.
For example, the software package wordpress-5.2.4 has 1835 files. If you get a few more versions, the number of files will be doubled. Therefore, if this kind of file package is not accessed for more than half a year, these data should be packaged. In order to facilitate the search, in addition to the compressed package, use the dir command to make the file list of the compressed package, so as to reduce the number of files, You can take into account the query speed. In this specific case with a size of more than 50 G, compress the original more than 180000 files to less than 20000 and repeat the files.
| wordpress-5.2.4 | Before compression | After compression |
|---|---|---|
| Number of documents | 1835 | 2 |
| file size | 43MB | 12MB |

| Dos command | explain |
|---|---|
| dir e:\temp /t:w /s | Traverse e:\temp to display the last modification time |
| dir e:\temp /t:a /s | Traverse e:\temp to display the last access time |
Project data can also be processed in this way
experience
With MD5 comparison, you can find all duplicate files. You don't know if you don't check them. You'll be surprised if you check them. There are many files that are repeated 10 to 20 times. By looking for duplicate files, you can quickly find some structural problems. You can adjust the folder structure to more reasonably organize the documents.
How to organize files on the computer efficiently ? Author: XNOM, this sharing is very good