Common problems in redis development - cache penetration - cache avalanche - redis brain crack - cache breakdown
preface
In our daily development, we all use the database to store data. Because there is usually no high concurrency in general system tasks, it seems that there is no problem. However, once the demand for a large amount of data is involved, such as the rush purchase of some commercial products, or when the home page has a large amount of visits in an instant, The system that only uses the database to save data will have serious performance disadvantages because it is disk oriented and the disk read / write speed is relatively slow. In an instant, thousands of requests come, and the system needs to complete thousands of read / write operations in a very short time. At this time, the database is often unable to bear, which is extremely easy to cause the paralysis of the database system, Serious production problems that eventually lead to service downtime. In order to overcome the above problems, projects usually introduce NoSQL technology, which is a memory based database and provides certain persistence functions.
Redis technology is one of NoSQL technologies, but the introduction of redis may cause cache penetration, cache avalanche, cache breakdown and other problems. This paper makes a more in-depth analysis of these problems
1, Redis cache penetration
What is cache penetration?
In short, when acquiring data, first go to redis to find the data result, and then go to MySQL to find the data result. If the result is still not found, then every thread will have to access the database. In this way, the pressure on the database will be great, and the database will collapse. This phenomenon is called cache penetration
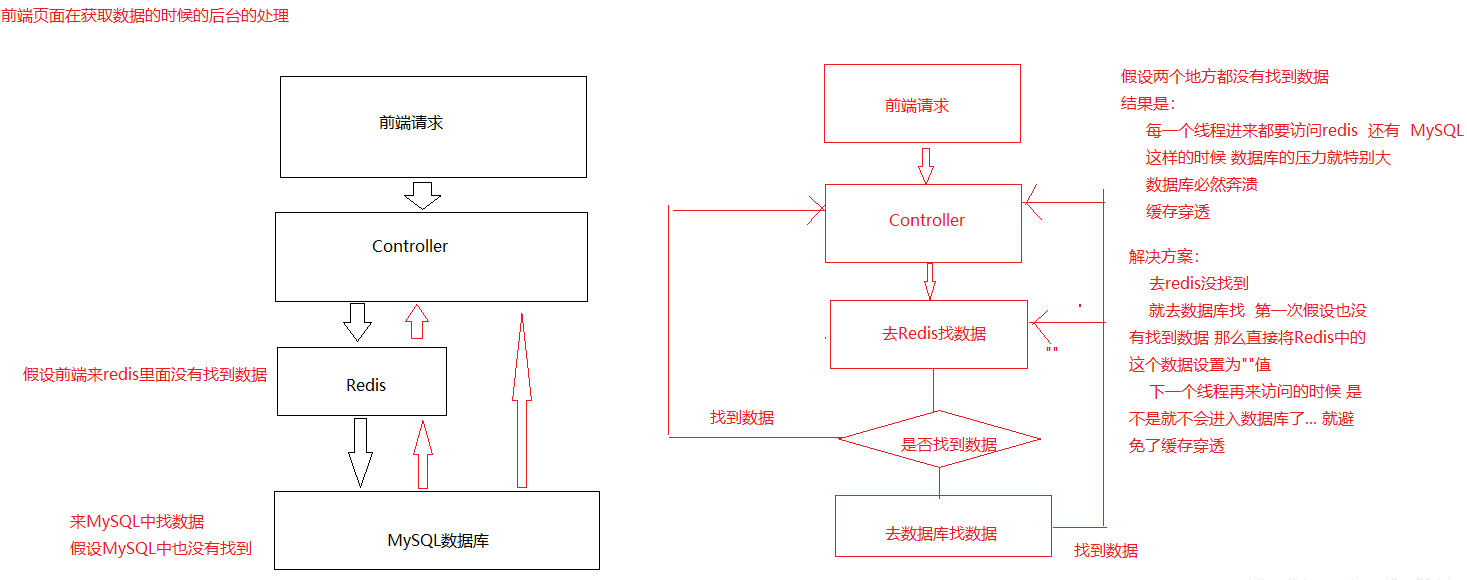
2, Cache avalanche under Redis
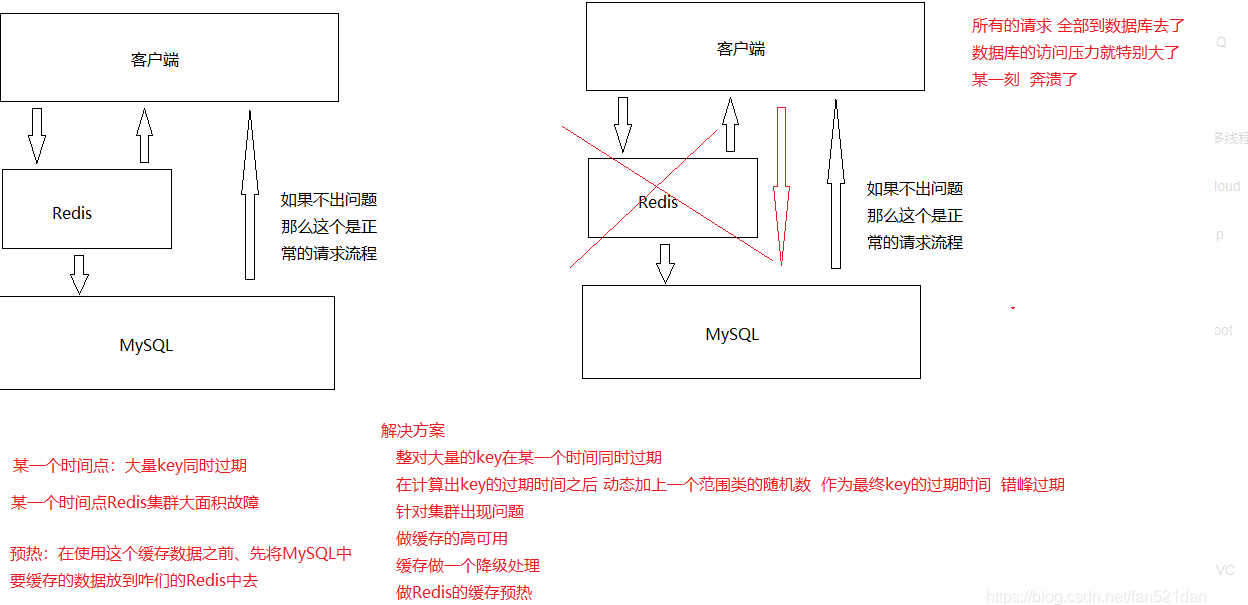
3, Redis's brain crack problem

When the client writes data to the master server, but the master server dies before the master server has time to synchronize, a new master server will be elected at this time. The original master server will recover after a period of time. At this time, the original master server can only be used as a slave server. There is no way to synchronize the data of the original master server The problem is redis's brain crack
Solution
Min-slave-to-write 1 means that when our client writes data, at least one slave server on the master server is connected normally before writing this data
Min slave Max lag 10: this means that the master-slave synchronization time is 10s
4, Buffer breakdown
Note the difference between and cache penetration. Cache breakdown means that a key is very hot and is constantly carrying large concurrency. Large concurrency focuses on accessing this point. When the key fails, the continuous large concurrency breaks through the cache and directly requests the database, which is like cutting a hole in a barrier.
When a key expires, a large number of requests are accessed concurrently. This kind of data is generally hot data. Because the cache expires, the database will be accessed at the same time to query the latest data and write back to the cache, resulting in excessive pressure on the database at the moment.
Solution:
1. Set hotspot data never to expire
From the perspective of the cache layer, the expiration time is not set, so there will be no problems after the hot key expires.
2. Add mutex
Distributed lock: using a distributed lock ensures that there is only one thread for each key to query the back-end service at the same time, and other threads do not have the permission to obtain the distributed lock, so they only need to wait. This method transfers the pressure of high concurrency to distributed locks, because it has a great test on distributed locks.
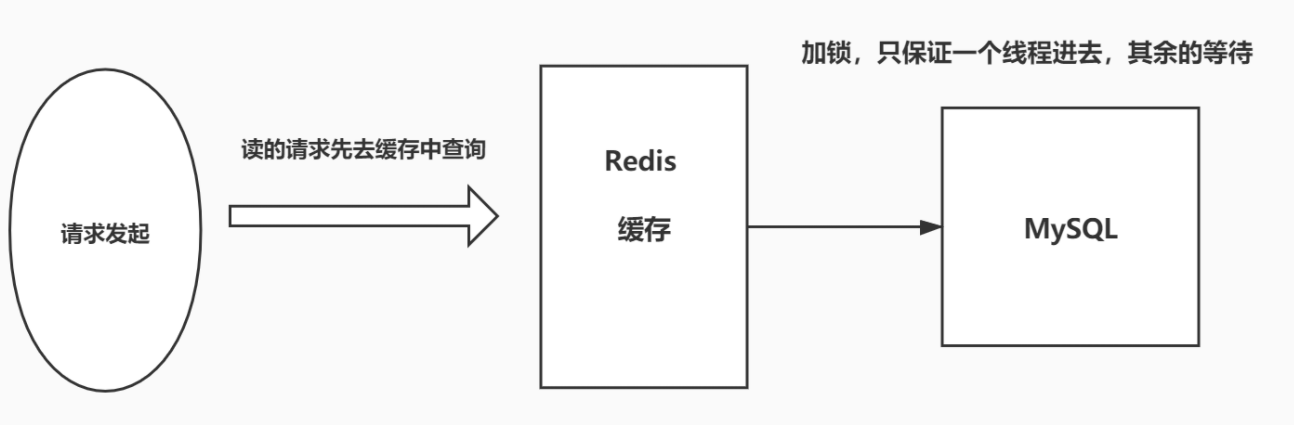
JAVA code implementation
static Lock reenLock = new ReentrantLock();
public String findPubConfigByKey1(String key) throws InterruptedException {
PubConfig result = new PubConfig();
// Read data from cache
result = redisService.getObject(PubConfigKeyConstants.TABLE_NAME + "_"+key, PubConfig.class) ;
if (result== null ) {
if (reenLock.tryLock()) {
try {
System.out.println("Got the lock,from DB Write cache after getting database");
// Query data from database
result = pubConfigRepository.queryPubConfigInfoByKey(key);
// Write the queried data to the cache
Gson g = new Gson();
String value = g.toJson(result);
redisService.setNx(PubConfigKeyConstants.TABLE_NAME + "_"+key, value);
} finally {
reenLock.unlock();// Release lock
}
} else {
// Check the cache first
result = redisService.getObject(PubConfigKeyConstants.TABLE_NAME + "_"+key, PubConfig.class) ;
if (result== null) {
System.out.println("I didn't get the lock,There is no data in the cache,Take a nap first");
Thread.sleep(100);// Take a nap
return findPubConfigByKey1(key);// retry
}
}
}
return result.getValue();
}
summary
For the business system, it is always the specific analysis of the specific situation. There is no best, only the most appropriate.
For other cache problems, such as cache full and data loss, we can learn by ourselves. Finally, we also mention the three words LRU, RDB and AOF. Generally, we use LRU strategy to deal with overflow, and Redis's RDB and AOF persistence strategy to ensure data security under certain circumstances.