catalogue
One diagonal bar and two diagonal bars
background
The basic positioning mode of elements has been explained in the previous chapter. Leaving an xpath that hasn't been explained in detail. This article is devoted to explaining this content
XPath positioning
XPath is the language used to locate XML document nodes. However, HTML can be seen as an implementation of XML(XHTML). Selenium users can use this powerful language to target elements of Web applications. XPath extends a single method of locating with the id or name attribute, creating many possibilities, such as locating the third check box of the page
One of the main reasons for using XPath is that when the element you want to locate does not have an appropriate id or name attribute, you can use XPath to absolutely locate the element (not recommended) or associate the element with another element with a certain id or name (i.e. relative positioning). XPath locators can also be used to find elements with attributes other than id and name.
The absolute XPath location contains all elements from the HTML root node, and some minor changes will fail. Use the id or name attribute to find a nearby element (ideally the parent element), so that you can rely on their relative relationship to determine the location of the target element. This situation is much less likely to change, and the test program we write will be more reliable.
Let's take another example:
<html> <body> <form id="loginForm"> <input name="username" type="text" /> <input name="password" type="password" /> <input name="continue" type="submit" value="Login" /> <input name="continue" type="button" value="Clear" /> </form> </body> <html>
The form element can be positioned in this way (the meaning of one / two diagonal bars in the path is different, and the text will be attached with a specific explanation):
login_form = driver.find_element_by_xpath("/html/body/form[1]")
login_form = driver.find_element_by_xpath("//form[1]")
login_form = driver.find_element_by_xpath("//form[@id='loginForm']")
The above meanings respectively:
Absolute path (if any) HTML Minor changes will fail) HTML The first one form element id Attribute is'loginForm'of form element
The username element can be positioned as follows:
username = driver.find_element_by_xpath("//from[input/@name='username']")
username = driver.find_element_by_xpath("//form[@id='loginForm']/input[1]")
username = driver.find_element_by_xpath("//input[@name='username']")The above meanings respectively:
first form Elemental name Property is'username'of input Child element id Attribute is'loginForm'of form First element input Child element name Attribute is'username'The first one input element
Thank you Selenium Python Chinese document
One diagonal bar and two diagonal bars

2. Locate the element by tag name
For example, all input tag elements: find_element_by_xpath("//input")
3. Parent child positioning element
Find the child element find with the parent element's tag name span and all its tags called input_ element_ by_ xpath("//span/input")
4. Brother node selection
Selection of neighboring sibling nodes: following sibling:: two colons
//div / following sibling:: p select the adjacent p node in the div
Selection of neighboring sibling nodes: preceding sibling:: this method is used in CSS_ Not in selector
//div / preceding sibling:: p [2] select the second node adjacent to the front in the div. all the previous p nodes are selected without [2]
5. Locate elements according to element content (very practical)
find_element_by_xpath("//p[contains(text(),'jinggong ')]")
<p id="jgwab"> <i class="c-icon-jgwablogo"></i> Jinggong network Anbei No. 11000002000001 </p>
Another use of contains / / input[contains(@class,'s')]# indicates that the class attribute contains an element of S.
6. Combined positioning elements
find_element_by_xpath("//span/input[@class = 's_ipt']) # / / attribute value of parent element tag name / tag name: it means that the class attribute under the input tag under span is s_ Elements of IPT
Multiple attribute combination positioning (also very common)
find_element_by_xpath("//input[@class = 's_ipt' and @name = 'wd']) # refers to the element with id attribute kw and name attribute wd under the input tag
find_element_by_xpath("//p[contains(text(),'jinggong ') and @id ='jgwab']) # refers to the element whose content under the p tag contains" Jinggong "and whose ID attribute is jgwab
7. Select the node
//div/p[2] select the second p node under div; Equivalent to CSS_ Div > p: nth of type (2) in the selector corresponds to the second node of type p
//div/*[2] select the second element under div
//div/p[position()=2]
position()=2 specifies the second position; Equivalent to / / div/p[2] above
Position() > = 2 position ≥ 2
Position() < 2 position < 2
position()!= 2 position is not equal to 2
//div/p[last()] select the penultimate p node under div; Last() last
//div/p[last()-1] select the penultimate p node under div;
//div/p[position()=last()] last
//div/p[position()=last()-1] penultimate
//Div / P [position() > = last() - 2] penultimate, second, third
8. You can also use Xpath to find in webelement object Indicates the current node
food = driver.find_element_by_id('food')
eles = food.find_elements_by_xpath(".//p") . Indicates the current node
eles = food.find_elements_by_xpath("...") finds the parent node of the current node
9. Lazy method
Use the firebug tool of Sohu browser to copy the XPath path, but this method requires high levels. You can modify it yourself at that time
Xpath (XML Path Language),yes W3C Defined for use in XML Select the language of the node in the document
1: From root/start
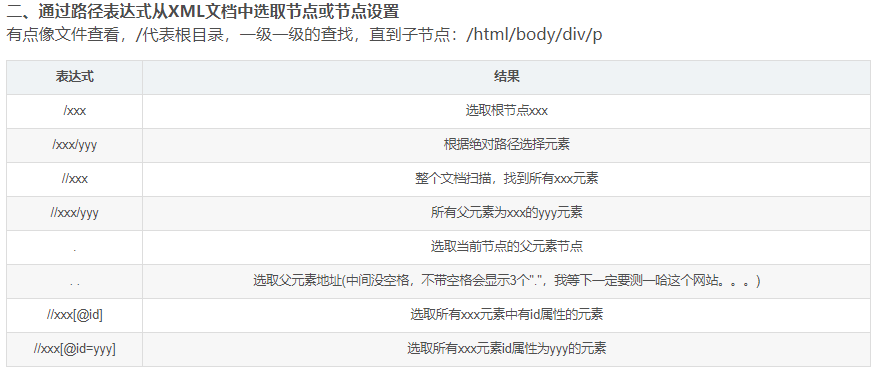
Kind of like Linux File view,/Represents the root directory, level-by-level search, direct child nodes, equivalent to css_selector Medium>number
/html/body/div/p
two. Select according to element attributes:
To find a specific element, you must enter the beginning of the standard in front//, which means to find all descendant elements from the current node
//Div / * all elements under div
//div//p first find the div in the whole document, and then find the P node in the div (as long as it is internal, it is not limited to whether to follow closely); Equivalent to CSS_ ('div p ') in selector
//Div / P is the direct child node of div; Equivalent to CSS_ In the selector ('div > p ')
//*[@ style] find all elements that contain style, and add @ to all attributes; Equivalent to CSS_ ('* [style]') in selector
//p[@spec='len '] must be quoted; Equivalent to CSS_ In the selector ("p[spec='len ']")
//P [@ id ='kw '] in XPath, ID and class are treated the same as other elements, and there is no other method
three. Select the node
//div/p[2] select the second p node under div; Equivalent to CSS_ Div > p: nth of type (2) in the selector corresponds to the second node of type p
//div/*[2] select the second element under div
//Div / P [position() = 2] position() = 2 specifies the second position; Equivalent to / / div/p[2] above
position()>=2 Position ≥ 2
position()<2 Position less than 2
position()!=2 Position not equal to 2
//div/p[last()] select the penultimate p node under div; Last() last
//div/p[last()-1] select the penultimate p node under div;
//div/p[position()=last()] last
//div/p[position()=last()-1] penultimate
//Div / P [position() > = last() - 2] penultimate, second, third
four. Combination selection
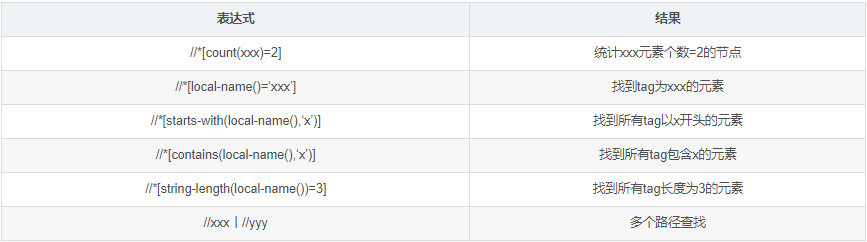
//p | //button select all p and buttons, which is equivalent to CSS_ p, button in selector
//Input [@ id ='kw 'and @ class ='su'] select the input element with id=kw and class=su
five. Selection of sibling nodes
Selection of adjacent sibling nodes: following-sibling:: Two colons
//div / following sibling:: p select the adjacent p node in the div
Selection of adjacent front nodes: preceding-sibling::Add element label after # This method is in CSS_ Not in selector
Selection of adjacent front nodes following-sibling:: Add element label after
//div / preceding sibling:: p [2] select the second node adjacent to the front in the div. all the previous p nodes are selected without [2]
six. Select parent node
//p[@spec='len']/.. Select the upper node of the P node. This method is in CSS_ Not in selector
//p[@spec='len']/../.. Upper node of upper node
seven. stay webelement Use search in object Xpath When searching, you must use.Indicates the current node
food = driver.find_element_by_id('food')
eles = food.find_elements_by_xpath(".//p "). Indicates the current node
eles = food.find_elements_by_xpath("..") Find the parent node of the current nodeThe above contents refer to those of other friends on the Internet.