This article is shared from Huawei cloud community< Near data processing (NDP), crowning the performance improvement of GaussDB(for MySQL) >, author: GaussDB database.

In the last article< Chief scientist reveals to you: how powerful is the vertical integration of GaussDB(for MySQL) cloud stack >We introduced the architecture of GaussDB(for MySQL). In this article, we will focus on how GaussDB(for MySQL) offloads query processing to the storage layer. We call this feature Near Data Processing (NDP).
Opportunity of NDP
To perform a query operation on the compute node instance, you first need to load the data page into the InnoDB buffer pool. Compared with the traditional database using local storage, the cloud database needs to obtain data through the network, so the delay of reading page data from the storage node is much higher. Compared with the community version of MySQL, GaussDB(for MySQL) supports parallel queries and can read data into the buffer pool in parallel through multiple threads. However, when the amount of table data is large (including millions or even more data rows), and a large amount of data needs to be scanned for analysis and query, the IO cost will become very high by loading all the required data into the buffer pool. Therefore, we need a better method to solve this problem.
Our solution is based on the close integration between GaussDB(for MySQL) computing nodes and storage nodes to push down some query processing operations to the distributed storage system close to the data, which is called operator push down in database terminology. In this way, we can take advantage of the total bandwidth of multiple storage nodes. In the cloud environment, the storage system contains hundreds of nodes. We hope to make full use of the scalability of the storage system and avoid the network becoming a performance bottleneck. NDP allows partial query processing to be executed on storage nodes in a massively parallel manner, and significantly reduces network IO.
NDP has many benefits, including:
- Multi tenant large-scale distributed cloud storage system is used to process data in parallel at multiple nodes
- Significantly reduce the network IO, and only return the rows (filtering) that meet the WHERE conditions and the results of the columns (projection) or aggregation operations involved in the query, rather than returning the complete data pages from the storage node to the computing node
- Avoid removing frequently accessed data pages from the cache pool due to a large number of scans
So how does the storage tier handle it?
Operator push down is usually applicable to full table scanning, index scanning, range query and other scenarios. The WHERE condition can be pushed down to the storage layer. The currently supported data types include:
- Numeric, integer, float, double
- Time type (date, time, timestamp)
- String type (char, varchar), etc
Operator push down can be perfectly combined with parallel queries of computing nodes. Conceptually, a query is first split into multiple worker threads at the computing layer (vertical expansion) for parallel processing, and each worker thread can trigger operator push down. Due to the strategy of data distribution in distributed storage, the load of each worker thread will be distributed to multiple nodes of the storage system (horizontal expansion), and each storage node will push down requests by the process pool processing operator.
In the query optimization stage, the optimizer automatically decides whether to enable operator push down according to statistics and execution plan. In addition, users can also use hint to control whether the query operation enables operator push down.
Operator push down can handle cold data well. However, GaussDB(for MyQL) is an OLTP system, which usually contains concurrent update operations. In the current calculation push down implementation, MVCC processing is only performed at the calculation node, and the storage node only processes visible rows. For rows whose visibility cannot be judged, return to the calculation node as is, and play back the corresponding data through undo log.
What benefits will we get from operator push down?
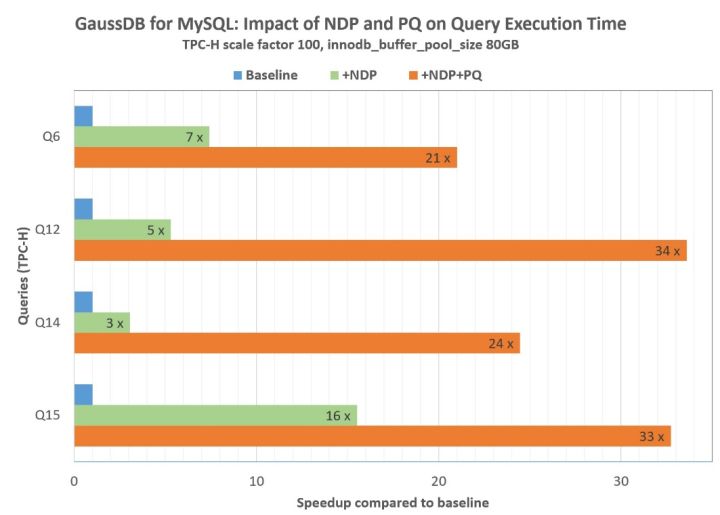
Taking the TPC-H standard test set (scale factor: 100) as an example, the CPU is 16 cores, the memory is 128GB, and the buffer pool size of the computing node database is set to 80GB, which is verified by cold data.
The following figure shows the Query results of TPC-H Q6, Q12, q14 and Q15 queries, all with 20-40 times performance improvement. Taking Q12 as an example, only NDP is enabled. With the help of distributed storage computing power and network IO reduction, the performance is improved by 5 times. At the same time, when parallel Query is enabled at the computing node, the performance is improved by 7 times, and the overall improvement is about 35 times. This improvement effect is very significant.
These functions mentioned in this article can be used in the actual production environment, and this is just the beginning. As we push more calculations to the storage tier, more queries will benefit from this optimization, and we can expect greater performance improvement.
How do I enable NDP?
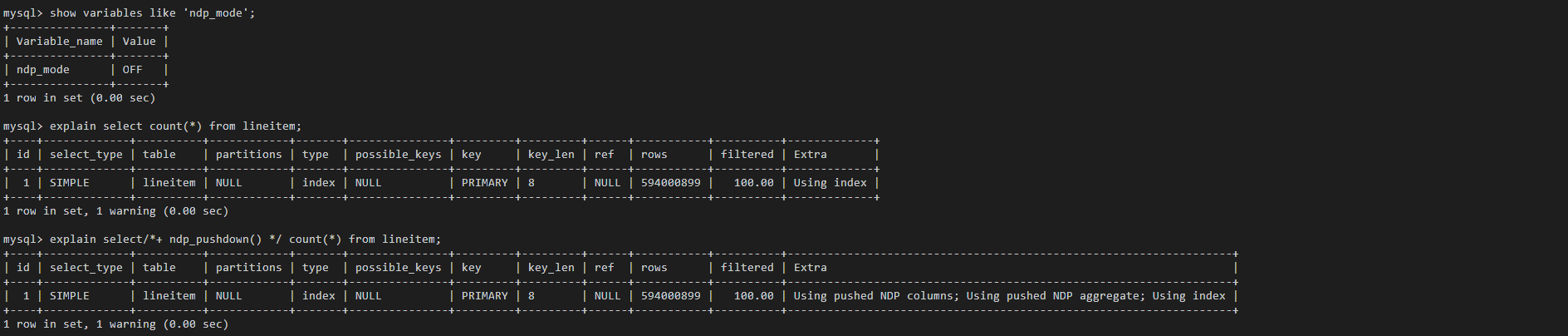
Turn on the NDP switch to take effect for the current Session, and the optimizer automatically determines whether to push down the calculation.
mysql> show variables like 'ndp_mode'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | ndp_mode | ON | +---------------+-------+ 1 row in set (0.00 sec) mysql> explain select count(*) from lineitem; +----+-------------+----------+------------+-------+---------------+---------+---------+------+-----------+----------+-------------------------------------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+----------+------------+-------+---------------+---------+---------+------+-----------+----------+-------------------------------------------------------------------+ | 1 | SIMPLE | lineitem | NULL | index | NULL | PRIMARY | 8 | NULL | 594000899 | 100.00 | Using pushed NDP columns; Using pushed NDP aggregate; Using index | +----+-------------+----------+------------+-------+---------------+---------+---------+------+-----------+----------+-------------------------------------------------------------------+ 1 row in set, 1 warning (0.00 sec)

Make NDP effective for the current Query by hint.
mysql> show variables like 'ndp_mode'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | ndp_mode | OFF | +---------------+-------+ 1 row in set (0.00 sec) mysql> explain select count(*) from lineitem; +----+-------------+----------+------------+-------+---------------+---------+---------+------+-----------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+----------+------------+-------+---------------+---------+---------+------+-----------+----------+-------------+ | 1 | SIMPLE | lineitem | NULL | index | NULL | PRIMARY | 8 | NULL | 594000899 | 100.00 | Using index | +----+-------------+----------+------------+-------+---------------+---------+---------+------+-----------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) mysql> explain select/*+ ndp_pushdown() */ count(*) from lineitem; +----+-------------+----------+------------+-------+---------------+---------+---------+------+-----------+----------+-------------------------------------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+----------+------------+-------+---------------+---------+---------+------+-----------+----------+-------------------------------------------------------------------+ | 1 | SIMPLE | lineitem | NULL | index | NULL | PRIMARY | 8 | NULL | 594000899 | 100.00 | Using pushed NDP columns; Using pushed NDP aggregate; Using index | +----+-------------+----------+------------+-------+---------------+---------+---------+------+-----------+----------+-------------------------------------------------------------------+ 1 row in set, 1 warning (0.00 sec)
Challenges and future directions
NDP has many benefits, but it also has some technical challenges that we need to solve. For example, the distributed storage system is shared by multiple tenants. In order to avoid competing for resources by different tenants, we need to implement single tenant level resource management and control. In addition, when the optimizer decides to use NDP, it needs to consider the amount of data triggered by network IO and the amount of data buffered in the buffer pool.
GaussDB(for MySQL) is a cloud native database. The architecture supports an extremely powerful and flexible NDP framework. In the future, we plan to use this framework not only for query processing, but also to further expand the database functions in the storage layer, which can be used in combination with query push down. We believe that the deep integration of cloud stack is the key to releasing the power of cloud database. Huawei cloud is in a leading position in achieving this goal, as proved by GaussDB(for MySQL).
Please keep your attention. We will bring you more wonderful technology sharing in the future. Welcome to the official website of Huawei cloud to learn more about GaussDB(for MySQL): https://www.huaweicloud.com/product/gaussdb_mysql.html
Click focus to learn about Huawei cloud's new technologies for the first time~