
Wang Hui, joined qunar.com in 2017. At present, he is responsible for anti crawler related risk control business, has a wide range of technical fields, and is continuously exploring the practice direction of intelligent risk control.
I preface
In Qunar intelligent risk control scenario, the risk control R & D team often applies some algorithm models to solve complex scenario problems. Typical examples are neural network model, decision tree model and so on. To complete the whole process from model training to deployment prediction, in addition to model algorithm, it is inseparable from the support of technical framework. This article will share with you the practical experience of building a distributed machine learning computing framework based on Tensorflow for Java and spark Scala in the prediction service deployment stage. It mainly focuses on the following points:
- What is tensorflow for Java & spark Scala?
- Frame selection and applicable scenarios
- How to use spark Scala integration Tensorflow for Java to build prediction services?
- Optimization and pit stepping experience in frame practice
II Frame selection
2.1 project scenario
The background of the project is to build a neural network model after collecting the user risk control data collected by the mobile client to analyze and predict the user risk offline.
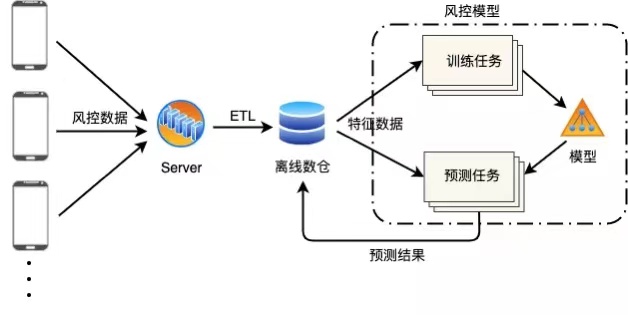
The client collects a large amount of data. At present, the amount of hourly characteristic data is about 300w, and it will be expanded to tens of millions in the future. At the same time, if we want to execute the prediction task every hour, we need to ensure that a calculation can be completed within hours, otherwise there will be task backlog. Therefore, even the off-line computing scenario with low real-time requirements still has the requirements of high-performance processing.
In this context, we expect to improve the efficiency of model prediction based on big data distributed machine learning computing framework.
2.2 frame selection
In the selection of distributed machine learning computing framework, one is the distributed capabilities supported by the machine learning framework itself, such as Tensorflow and pytoch, which have supported distributed computing; The other is the combination of big data distributed framework and machine learning framework, which integrates machine learning framework API through Spark, Flink and other big data frameworks.
At present, although the machine learning framework gradually has the distributed ability, the main purpose is to solve the problem of model training performance in the scenario of large amount of data and multiple model parameters. Compared with the traditional big data distributed framework, the advantages are the support for distributed training and the distributed scheme for machine learning scenarios. The disadvantage is that it does not provide a good solution for data consolidation and multi-level layering. Secondly, it needs to build and maintain clusters separately, which increases the operation and maintenance cost. Considering comprehensively, in the distributed prediction scenario, a scheme combining big data framework and machine learning framework is adopted.
Big data frameworks are usually divided into stream processing and batch processing. Stream processing is applicable to real-time and quasi real-time computing. Flink, Storm, Spark streaming, etc. all belong to stream processing framework; Batch processing is applicable to offline computing. Our scenario is a typical offline batch processing scenario. The mainstream batch processing frameworks currently include Spark and Hadoop MapReduce. Through the comparison of framework implementation, it can be found that although Spark memory based operation consumes more resources, it can bring great improvement in performance.
In the field of machine learning framework, TensorFlow and PyTorch have become the two most widely used frameworks in industry and academia respectively. TensorFlow is an open source deep learning framework created by Google developers and released in 2015. PyTorch is one of the latest in-depth learning frameworks. It was developed by the Facebook team and opened source on GitHub in 2017.
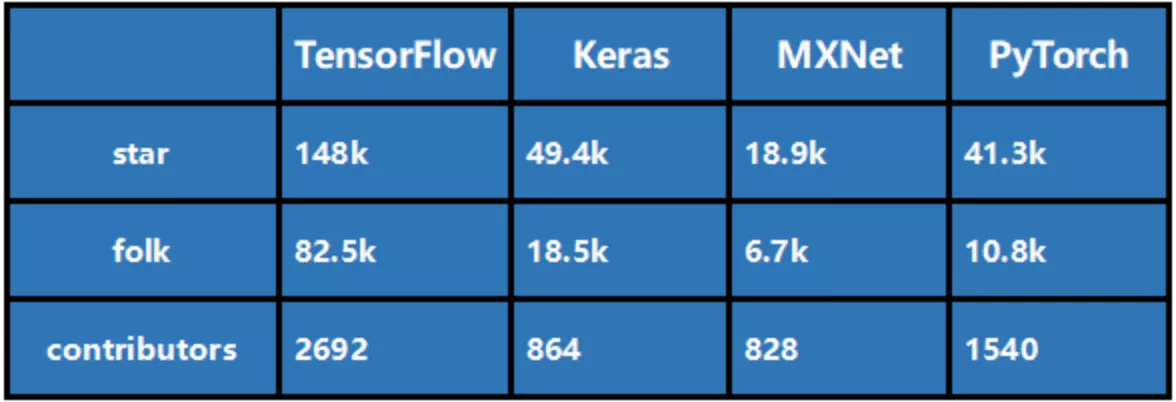
Comparing tensorflow and pytoch from multiple dimensions, we can find that pytoch has better API, fast start, dynamic graph, easy debugging and other advantages. It is suitable for researchers to build models quickly and has fast iteration speed. Tensorflow has advantages in multi language support, cross platform capability, performance and production deployment, and is suitable for production deployment. This is why pytoch is more popular in academia, while tensorflow maintains the leading position in industry. Tensorflow and pytoch are trying to get closer to each other's advantages, but this situation should not change in the short term.

Through the above analysis, combined with the actual application scenarios, the algorithm structure of the risk control model is not very complex and can be quickly built under Tensorflow and pytoch. Therefore, considering the difficulty of model production environment deployment and the needs of cross platform deployment, we choose Tensorflow to build the model.
2.3 why choose tensorflow for Java & spark Scala?
Among the integration schemes of Spark and Tensorflow, one is to use PySpark+Tensorflow for Python in Python environment, which is also the most practical scheme at present. The other is Spark Scala + Tensorflow for Java in Java/Scala environment. We choose the second scheme mainly for performance considerations. The performance differences between the two frameworks are compared below:
2.3.1 Tensorflow for Java and spark Scala introduction
TensorFlow has supported the installation and operation of multiple client languages, but Python is still the only well supported language at present. Tensorflow for Java is an API provided by Tensorflow for Java programs. These APIs are suitable for loading models created in Python and executing in Java applications.
Spark Scala is the spark task development tool in the Scala language environment. Because Scala also runs on the JVM and is compatible with the Java language, it can integrate Java applications. The development language of spark framework is also Scala, because Scala adopts functional programming and has advantages in parallel and concurrent computing programming.
2.3.2 performance comparison
As mentioned above, tensorflow for Java & spark Scala is selected to meet the requirements of high-performance scenarios. The performance differences between the two schemes are analyzed below.
Spark's runtime architecture is as follows. The user's spark application runs on the Driver, is encapsulated into tasks through spark scheduling, and then sends these Task information to the Executor for execution. The Scala version of spark runs under this native architecture.
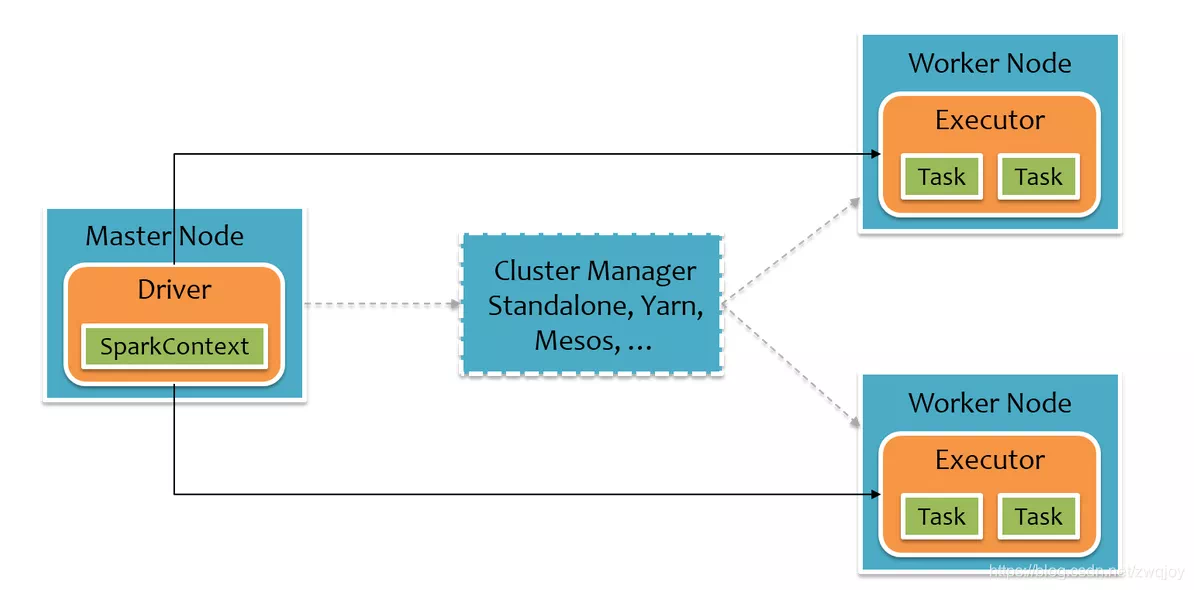
The runtime structure of PySpark is as follows. In order not to destroy Spark's existing runtime architecture, spark wraps a layer of Python API around it, realizes the interaction between Python and Java with the help of Py4j, and then writes spark applications through python.
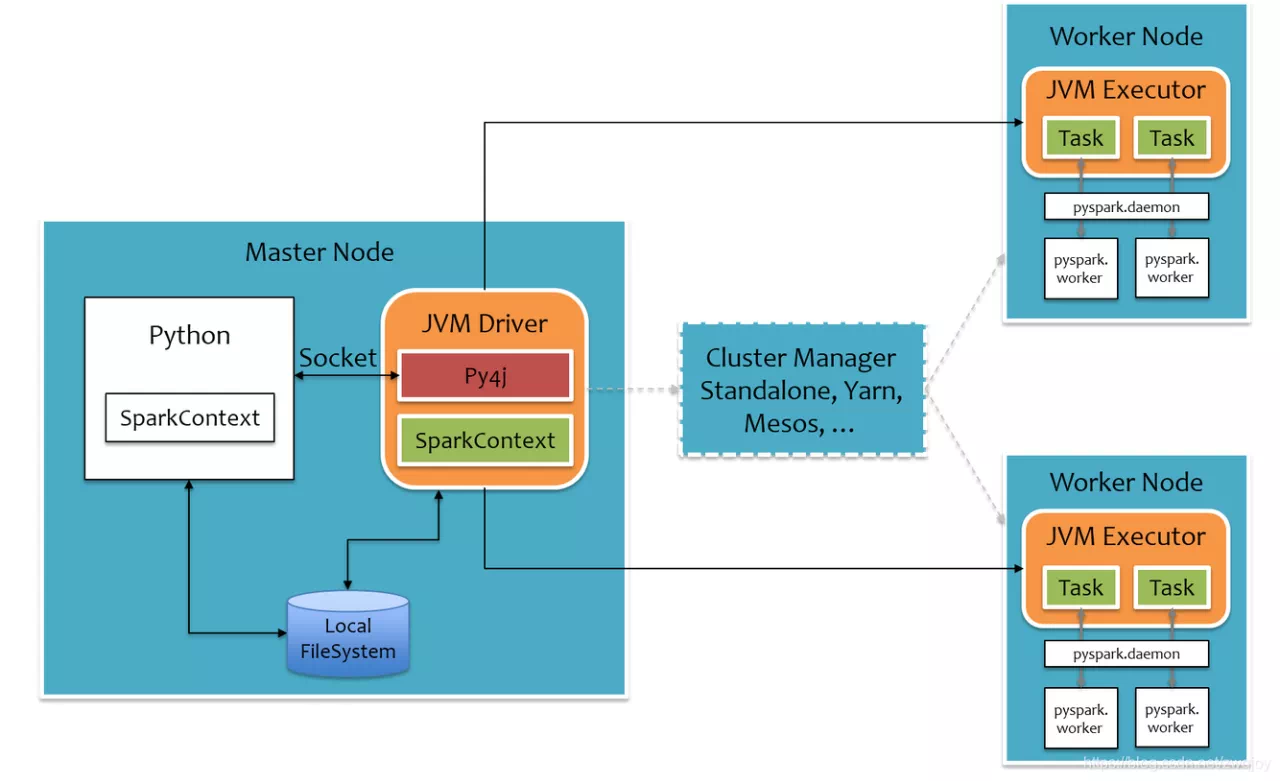
It can be seen from this that the performance of PySpark is weaker than spark Scala for two main reasons:
- First, there is a layer of Python to Java conversion on the Driver side;
- Second, in order to run user-defined Python functions or Lambda expressions, the Executor side starts a python process for each Task, and sends Python functions or Lambda expressions to the python process for execution through socket communication.
Then compare the differences between Tensorflow for Python and Tensorflow for Java. The bottom layers of both are Tensorflow C + + function libraries, and there is little difference in performance. In the upper layer, the Java language will be faster than python. There will be differences in scenarios where many preprocessing operations need to be done before calling Tensorflow API.
In conclusion, scheme 2 is better than scheme 1 in performance.
Of course, scheme 1 also has its advantages in other aspects, such as high development efficiency, low integration difficulty (without cross platform), high API support, etc.
Subsection 2.4
Summary of this section:
-
It is a relatively feasible and effective scheme to realize distributed machine learning prediction based on the combination of Spark big data framework and Tensorflow machine learning framework.
-
Spark and Tensorflow integration based on Tensorflow for Java and spark Scala can bring higher performance.
-
The current scheme is applicable to the off-line prediction scenario of high-performance distributed machine learning model under big data.
III Application practice
In practice, the project application process: first, train the model based on the sample data and generate the model file. Then read the feature data in Spark, call Tensorflow Java API to load the model, predict and get the result set.
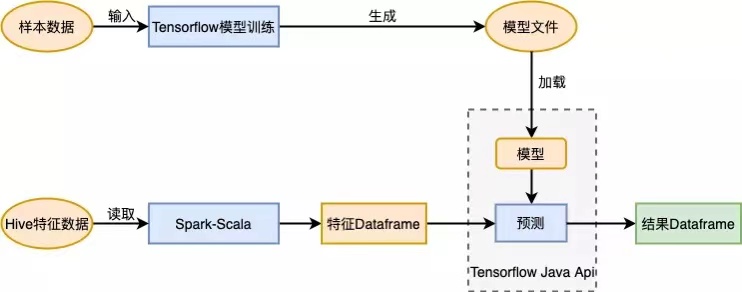
3.1 training model
3.1.1 training model file
In our project, model training is implemented based on Python+Tensorflow+Keras. Here, the MNIST dataset CNN classification is taken as an example to demonstrate the model training code. After training, the model file saved in protobuf format is obtained, and the protobuf format file can load the model across platforms.
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Dropout,Convolution2D,MaxPooling2D,Flatten
from tensorflow.keras.optimizers import Adam
def train_model():
# Load the training set and test set data for independent heat coding
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
y_train = tf.keras.utils.to_categorical(y_train,num_classes=10)
y_test = tf.keras.utils.to_categorical(y_test,num_classes=10)
# Define sequential model
model = Sequential()
# Convolution layer, pooling layer, flattening, full connection
model.add(Convolution2D(input_shape=(28, 28, 1), filters=32, kernel_size=5, strides=1, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=2, strides=2, padding = 'same'))
model.add(Convolution2D(64, 5, strides=1, padding='same', activation='relu'))
model.add(MaxPooling2D(2,2,'same'))
model.add(Flatten())
model.add(Dense(1024,activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(10,activation='softmax'))
# Define optimizer, loss function, calculation accuracy during training
adam = Adam(lr=1e-4)
model.compile(optimizer=adam,loss='categorical_crossentropy',metrics=['accuracy'])
# Training model
model.fit(x_train,y_train,batch_size=64,epochs=10,validation_data=(x_test, y_test))
# Save model
model.save('./model/model_v1', save_format="tf")
3.1.2 viewing model files
Enter the model file directory and execute the following command to display the model file information. The information in red circle is the label, signature, input tensor, output tensor and prediction method name of the model from top to bottom. This information will be used later when loading model predictions.
saved_model_cli show --dir ./model_v1/ --all

3.2 model prediction
3.2.1 project construction & frame introduction
Create a new Scala project and introduce Spark and Tensorflow dependencies
<!-- scala -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- spark hadoop -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${spark.scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${spark.scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${spark.scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- tensorflow -->
<dependency>
<groupId>org.tensorflow</groupId>
<artifactId>tensorflow</artifactId>
<version>1.15.0</version>
</dependency>
3.2.2 model file loading
Call Tensorflow API to load the pre trained protobuff format model file to obtain the SavedModelBundle type model object. Model files can be saved in the project resource directory and then loaded from the resource directory (Tensorflow does not support recording models directly from HDFS, and how to implement them will be described later).
package com.tfspark
import org.apache.spark.sql.SparkSession
import org.tensorflow.SavedModelBundle
import org.{tensorflow => tf}
object ModelLoader {
//modelPath is the path of the model under resource, and modelTag is obtained from the model file information
def loadModelFromLocal(spark: SparkSession, modelPath: String, modelTag: String): SavedModelBundle = {
val bundle = tf.SavedModelBundle.load(modelPath, modelTag)
}
}
3.2.3 calling Tensorflow API prediction
In the Java version of Tensorflow, it is similar to Tensorflow 1 0, you need to establish a session, specify the characteristic data of the feed and the prediction result of the fetch, and then execute the run method.
The information obtained by viewing the model file will be passed in here as a parameter.
package com.tfspark.tensorflow
import com.qunar.rdc.util.TfUtil
import org.tensorflow.SavedModelBundle
import scala.collection.mutable.WrappedArray
import org.{tensorflow => tf}
object TensorFlowCnnProcessor {
def predict(broads: SavedModelBundle, features: WrappedArray[WrappedArray[WrappedArray[Float]]]): Int = {
val sess = bundle.session()
// Feature data formatting
val x = tf.Tensor.create(Array(features.map(a => a.map(b => b.toArray).toArray).toArray))
// The input tensor name and output tensor name in the incoming model information, as well as the formatted characteristic data are required to execute the prediction
val y = sess.runner().feed("serving_default_hmc_input:0", x).fetch("StatefulPartitionedCall:0").run().get(0)
// The result is a two-dimensional array of 1x2
val result = Array.ofDim[Float](y.shape()(0).toInt,y.shape()(1).toInt)
y.copyTo(result)
// Returns the maximum coordinate, which is the classification result, corresponding to the one hot code
TfUtil.argMaxOneDim(result(0))
}
}
3.2.4 Spark combined with Tensorflow prediction
Spark reads the prediction data from Hive, converts it into characteristic data after preprocessing, and calls Tensorflow API for prediction. The Tensorflow API is combined with spark distributed data set to realize the integration of distributed batch processing framework and machine learning.
// Register the prediction method that encapsulates the Tensorflow API as a udf function
val sensorPredict = udf((features: WrappedArray[WrappedArray[WrappedArray[Float]]]) => {predict(bundle, features)})
// Dataframe calling udf function
val resultDf = featureDf.withColumn("predict_result", sensorPredict(col("feature"))
3.3 service deployment
3.3.1 environmental dependence
For the project integrating spark Scala and Tensorflow for Java, make the dependency package through maven: tfspark-1.0.0-jar-with-dependencies jar .
Run the jar package on the hadoop cluster where the spark runtime environment is deployed. The dependent cluster environment needs to install spark, hadoop, hive and other big data components in advance.
3.3.2 execution script
Spark submit executes the jar package and specifies the main function class com tfspark. Predictmain, specify the jar package path, set the number of executor s and cores executing tasks, as well as memory parameters, and pass in the model file version parameters.
sudo -u root /usr/local/Cellar/apache-spark/2.4.3/bin/spark-submit --class com.tfspark.PredictMain --master yarn --deploy-mode client --driver-memory 6g --executor-memory 6g --num-executors 5 --executor-cores 4 /tmp/tfspark-1.0.0-jar-with-dependencies.jar model_v1
3.4 practical results
Complete the integration of Tensorflow for Java and spark Scala, and realize the combination of big data distributed batch processing framework and machine learning. Load and apply the model file generated in Python environment to Java platform to achieve the effect of cross platform application of machine learning model.
It has been successfully applied to online projects. The prediction of 300w data model is completed every hour. The task takes 9m and the throughput reaches 5500 + / s. Realize high-performance offline model prediction in big data scenario, and open up the whole application process.
IV Optimization & pit stepping experience
Time length performance optimization
In section 3.2.4, we demonstrate the routine operation procedure of Spark calling Tensorflow API in DataFrame. At the beginning of the launch of our project according to the above implementation method, the execution time of 300w data was about 20m. After analysis, it is considered that there is room for optimization in performance.
- Problem point: each piece of data will call the model prediction method once, which will cause some reusable objects to be created many times, and the same method process will be called many times.
- Optimization idea: call the prediction method in batch. Reduce duplicate object creation and method process execution.
- Solution: use mapPartition operator in RDD mode instead of map operator to obtain feature array and call in batch.
Compare the implementation of mapPartition operator and map operator:
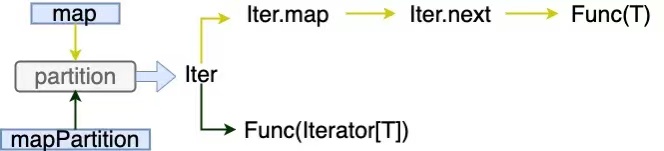
Both are iterators for operating partition. The map operator obtains each element through the iterator and calls the operation function. The function input parameter is the element type. mapPartition directly passes the iterator to the operation function, and the function input parameter is the iterator type of the element collection. Therefore, the difference is that mapPartition operates all partition elements in one method and calls the operation function once; Map can only operate on one element at a time and call the operation function multiple times.
Therefore, mapPartition is more suitable for scenarios with duplicate object creation or process call than map, which can improve performance and efficiency; The prominent disadvantage of mapPartition is that it may lead to OO, because multiple elements are loaded at a time, which takes up more memory than one element at a time compared with map, and can not be garbage collected in time.
Tensorflow API supports batch calling of incoming arrays. By converting iterators into arrays through mapPartition, batch prediction can be performed, which improves efficiency.
float[][] matrix = new float[m][n];
Tensor<Float> ft = Tensor.create(matrix, Float.class);
val y = sess.runner().feed("serving_default_hmc_input:0", ft).fetch("StatefulPartitionedCall:0").run().get(0)
Results: after batch prediction using mapPartition operator in RDD mode, the task duration decreased significantly from 20m to 9m.
Model file hot update
-
Problem point: we mentioned above that the model file is stored in the project resource directory. When the model structure remains unchanged, this method is not convenient to update the model file and the service needs to be redeployed.
-
Solution: improve the storage mode and store the model file in HDFS. Get model data from HDFS every time. Tensorflow itself does not provide an API for loading models directly from HDFS, but Spark can read from HDFS to local and then load from local. In this way, when the model structure remains unchanged, you only need to upload a new model file each time, overwrite the original HDFS file or upgrade the version number, and then you can hot update.
//modelPath is the path of the model under HDFS, and modelTag is obtained from the model file information spark.sparkContext.addFile(modelPath, true) val localPath = SparkFiles.get(modelPath) tf.SavedModelBundle.load(localPath, modelTag)
Tensorflow library file not found
Error reporting: an error libtensorflow is reported when the prediction task is executed on the hadoop cluster_ jni. So file not found.
Exception in thread "main" java.lang.UnsatisfiedLinkError: /tmp/tensorflow_native_libraries-1613705012956-0/libtensorflow_jni.so: libtensorflow_framework.so.1: cannot open shared object file: No such file or directory
at java.lang.ClassLoader$NativeLibrary.load(Native Method)
at java.lang.ClassLoader.loadLibrary0(ClassLoader.java:1941)
at java.lang.ClassLoader.loadLibrary(ClassLoader.java:1824)
at java.lang.Runtime.load0(Runtime.java:809)
at java.lang.System.load(System.java:1086)
-
Cause analysis: by checking the error log, it is concluded that Tensorflow depends on the C environment and requires the version of the C basic library. The versions of the basic libraries in the cluster C environment are inconsistent. Some of them have too low or too high versions, resulting in incompatibility with Tensorflow, and some machine tasks report errors.
-
Solution: provide two ideas.
The first scheme is to repair the cluster environment, but if it is a public cluster, changing the basic database will have a great impact.
The second scheme is to use a single physical machine without Hadoop cluster and Spark Local mode to start multiple executors to perform tasks, so as to ensure the consistency of the environment.
In practice, we adopt the second method.
V summary
The purpose of this paper is to share my thoughts and experience in the practical application of distributed machine learning computing framework for your reference and exchange.
By comparing the advantages and disadvantages of different frameworks and analyzing the impact of bottom implementation on performance, this paper expounds the thinking process of selection. It clarifies why tensorflow for Java & spark Scala is suitable for the prediction scenario of high-performance distributed machine learning model under big data. Combined with practical experience, the overall process of framework application in the project is demonstrated. It also summarizes the thinking in the process of performance and deployment process optimization.
Due to the limited level, there are many mistakes in the article. Please correct it.