Gated Channel Transformation for Visual Recognition (GCT)
- This article is a reproduction of an Attention article invested by Baidu & Syndney in CVPR2020. It proposes a general and lightweight change unit, which combines normalization method and Attention mechanism, which is easy to analyze the relationship between channels (competition or cooperation) and facilitate joint training with the parameters of the network itself.
github: https://github.com/z-x-yang/GCT
preface
- The author points out that SENet uses the full connection layer (FC layer) to deal with channel wise embeddings, which will make it difficult for the full connection layer to analyze the correlation of channels between different layers of the network.
- Therefore, the author proposes the Gated Channel Transformation (GCT) module, which is mainly designed as follows:
- 1. Replace FC with a normalization module to model the characteristic relationship between channels
- 2. Model the characteristic relationship between channels through gating
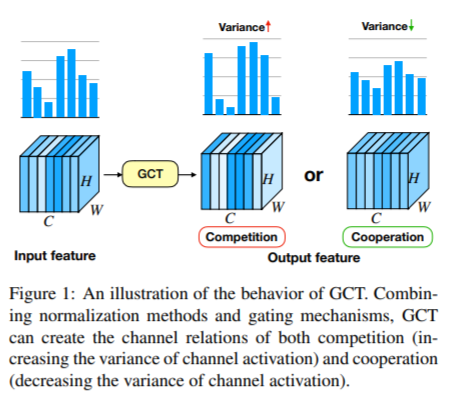
- 3. Through normalization module and gating mechanism, GCT module can capture the competition and cooperation between channel features.
- The main innovation of this paper is to propose a new attention mechanism, which is a channel & spatial attention. The test performance of each CV task is as follows
Related code
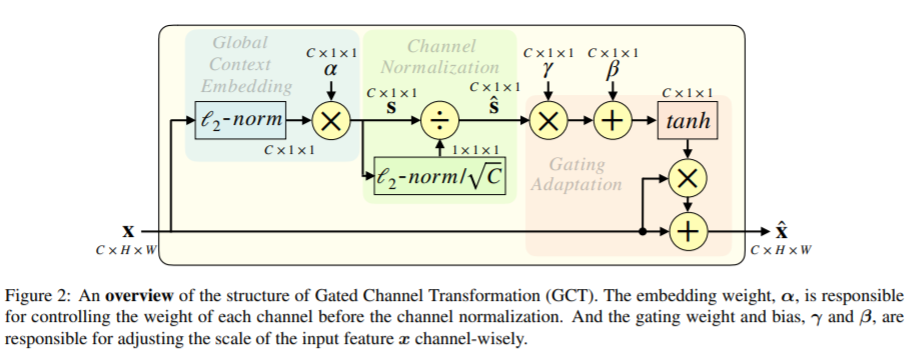
The specific network structure is shown in the figure above:
-
1. Global context embedding: firstly, after the feature map is input into the attention module, the global pooling method is not adopted, because the global pooling will fail in some cases. Here, the author uses L2 norm for global context embedding
-
2. Channel Normalization: L2 norm al, √ C is still used in this part to avoid the value of s^c being too small when C is relatively large. Compared with the FC layer of SE, the Channel Normalization method has less computation.
-
3. Gating adaptation: weights are designed here γ And bias β To control whether the channel feature is activated. When the characteristic weight of a channel γ When c is positively activated, GCT will promote the "competition" between the characteristics of this channel and those of other channels. When the characteristics of a channel γ When c is negatively activated, GCT will promote the "cooperation" between the characteristics of this channel and those of other channels.
import paddle
import paddle.nn as nn
import cv2
class BasicConv(nn.Layer):
def __init__(
self,
in_planes,
out_planes,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
relu=True,
bn=True,
bias_attr=False,
):
super(BasicConv, self).__init__()
self.out_channels = out_planes
self.conv = nn.Conv2D(
in_planes,
out_planes,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias_attr=bias_attr,
)
self.bn = (
nn.BatchNorm2D(out_planes, epsilon=1e-5, momentum=0.01)
if bn
else None
)
self.relu = nn.ReLU() if relu else None
def forward(self, x):
x = self.conv(x)
if self.bn is not None:
x = self.bn(x)
if self.relu is not None:
x = self.relu(x)
return x
class ZPool(nn.Layer):
def forward(self, x):
#print(x.shape)#[4, 16, 512, 16][512, 1, 16][4, 1, 512, 16]
#print(paddle.max(x, 1).unsqueeze(1).shape)
#print(paddle.mean(x, 1).unsqueeze(1).shape)
return paddle.concat(
(paddle.max(x, 1).unsqueeze(1),
paddle.mean(x, 1).unsqueeze(1))
,axis=1)
class AttentionGate(nn.Layer):
def __init__(self):
super(AttentionGate, self).__init__()
kernel_size = 7
self.compress = ZPool()
self.conv = BasicConv(
2, 1, kernel_size, stride=1, padding=(kernel_size - 1) // 2, relu=False
)
def forward(self, x):
x_compress = self.compress(x)
x_out = self.conv(x_compress)
scale = paddle.nn.functional.sigmoid(x_out)
return x * scale
class TripletAttention(nn.Layer):
def __init__(self, no_spatial=False):
super(TripletAttention, self).__init__()
self.cw = AttentionGate()
self.hc = AttentionGate()
self.no_spatial = no_spatial
if not no_spatial:
self.hw = AttentionGate()
def forward(self, x):
x_perm1 = x.transpose([0, 2, 1, 3])
x_out1 = self.cw(x_perm1)
x_out11 = x_out1.transpose([0, 2, 1, 3])
x_perm2 = x.transpose([0, 3, 2, 1])
x_out2 = self.hc(x_perm2)
x_out21 = x_out2.transpose([0, 3, 2, 1])
if not self.no_spatial:
x_out = self.hw(x)
x_out = 1 / 3 * (x_out + x_out11 + x_out21)
else:
x_out = 1 / 2 * (x_out11 + x_out21)
return x_out
[1, 512, 16, 16]
verification
input size = 64,512,16,16 --> GCT --> output size = 64,512,16,16
import paddle
import paddle.nn.functional as F
import math
from paddle import nn
class GCT(nn.Layer):
def __init__(self, num_channels, epsilon=1e-5, mode='l2', after_relu=False):
super(GCT, self).__init__()
self.alpha = self.create_parameter(shape=[1, num_channels, 1, 1],default_initializer=paddle.nn.initializer.Assign(paddle.ones([1, num_channels, 1, 1])))
self.gamma = self.create_parameter(shape=[1, num_channels, 1, 1],default_initializer=paddle.nn.initializer.Assign(paddle.zeros([1, num_channels, 1, 1])))
self.beta = self.create_parameter(shape=[1, num_channels, 1, 1],default_initializer=paddle.nn.initializer.Assign(paddle.zeros([1, num_channels, 1, 1])))
self.epsilon = epsilon
self.mode = mode
self.after_relu = after_relu
def forward(self, x):
if self.mode == 'l2':
embedding = (x.pow(2).sum((2,3), keepdim=True) + self.epsilon).pow(0.5) * self.alpha
norm = self.gamma / (embedding.pow(2).mean(axis=1, keepdim=True) + self.epsilon).pow(0.5)
elif self.mode == 'l1':
if not self.after_relu:
_x = paddle.abs(x)
else:
_x = x
embedding = _x.sum((2,3), keepdim=True) * self.alpha
norm = self.gamma / (paddle.abs(embedding).mean(dim=1, keepdim=True) + self.epsilon)
else:
print('Unknown mode!')
sys.exit()
gate = 1. + paddle.tanh(embedding * norm + self.beta)
return x * gate
if __name__=="__main__":
a = paddle.rand([64,512,16,16])
model = GCT(512)
a = model(a)
print(a.shape)
[64, 512, 16, 16]
Verify GCT performance
This experiment verifies the performance by building a ResNet18 network. The insertion location of GCT module is as follows.
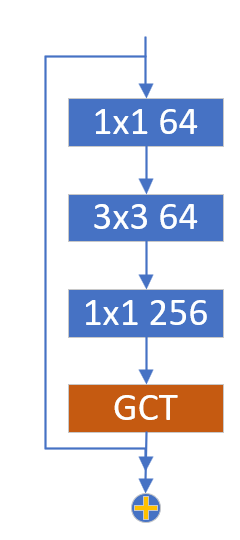
GCT_ResNet18 build
import paddle
import paddle.nn as nn
from paddle.utils.download import get_weights_path_from_url
class BasicBlock(nn.Layer):
expansion = 1
def __init__(self,
inplanes,
planes,
stride=1,
downsample=None,
groups=1,
base_width=64,
dilation=1,
norm_layer=None):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2D
if dilation > 1:
raise NotImplementedError(
"Dilation > 1 not supported in BasicBlock")
self.conv1 = nn.Conv2D(
inplanes, planes, 3, padding=1, stride=stride, bias_attr=False)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2D(planes, planes, 3, padding=1, bias_attr=False)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class BottleneckBlock(nn.Layer):
expansion = 4
def __init__(self,
inplanes,
planes,
stride=1,
downsample=None,
groups=1,
base_width=64,
dilation=1,
norm_layer=None):
super(BottleneckBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2D
width = int(planes * (base_width / 64.)) * groups
self.conv1 = nn.Conv2D(inplanes, width, 1, bias_attr=False)
self.bn1 = norm_layer(width)
self.conv2 = nn.Conv2D(
width,
width,
3,
padding=dilation,
stride=stride,
groups=groups,
dilation=dilation,
bias_attr=False)
self.bn2 = norm_layer(width)
self.conv3 = nn.Conv2D(
width, planes * self.expansion, 1, bias_attr=False)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU()
self.downsample = downsample
self.stride = stride
self.attention = GCT(planes * self.expansion)
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.attention(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Layer):
def __init__(self,
block,
depth=50,
width=64,
num_classes=1000,
with_pool=True):
super(ResNet, self).__init__()
layer_cfg = {
18: [2, 2, 2, 2],
34: [3, 4, 6, 3],
50: [3, 4, 6, 3],
101: [3, 4, 23, 3],
152: [3, 8, 36, 3]
}
layers = layer_cfg[depth]
self.groups = 1
self.base_width = width
self.num_classes = num_classes
self.with_pool = with_pool
self._norm_layer = nn.BatchNorm2D
self.inplanes = 64
self.dilation = 1
self.conv1 = nn.Conv2D(
3,
self.inplanes,
kernel_size=7,
stride=2,
padding=3,
bias_attr=False)
self.bn1 = self._norm_layer(self.inplanes)
self.relu = nn.ReLU()
self.maxpool = nn.MaxPool2D(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
if with_pool:
self.avgpool = nn.AdaptiveAvgPool2D((1, 1))
if num_classes > 0:
self.fc = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2D(
self.inplanes,
planes * block.expansion,
1,
stride=stride,
bias_attr=False),
norm_layer(planes * block.expansion), )
layers = []
layers.append(
block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(
block(
self.inplanes,
planes,
groups=self.groups,
base_width=self.base_width,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.with_pool:
x = self.avgpool(x)
if self.num_classes > 0:
x = paddle.flatten(x, 1)
x = self.fc(x)
return x
def _resnet(arch, Block, depth, pretrained, **kwargs):
model = ResNet(Block, depth, **kwargs)
if pretrained:
assert arch in model_urls, "{} model do not have a pretrained model now, you should set pretrained=False".format(
arch)
weight_path = get_weights_path_from_url(model_urls[arch][0],
model_urls[arch][1])
param = paddle.load(weight_path)
model.set_dict(param)
return model
def resnet18(pretrained=False, **kwargs):
return _resnet('resnet18', BasicBlock, 18, pretrained, **kwargs)
def resnet34(pretrained=False, **kwargs):
return _resnet('resnet34', BasicBlock, 34, pretrained, **kwargs)
def resnet50(pretrained=False, **kwargs):
return _resnet('resnet50', BottleneckBlock, 50, pretrained, **kwargs)
def resnet101(pretrained=False, **kwargs):
return _resnet('resnet101', BottleneckBlock, 101, pretrained, **kwargs)
def resnet152(pretrained=False, **kwargs):
return _resnet('resnet152', BottleneckBlock, 152, pretrained, **kwargs)
def wide_resnet50_2(pretrained=False, **kwargs):
kwargs['width'] = 64 * 2
return _resnet('wide_resnet50_2', BottleneckBlock, 50, pretrained, **kwargs)
def wide_resnet101_2(pretrained=False, **kwargs):
kwargs['width'] = 64 * 2
return _resnet('wide_resnet101_2', BottleneckBlock, 101, pretrained,
**kwargs)
Ta_res18 = resnet18(num_classes=10) paddle.Model(Ta_res18).summary((1,3,224,224))
Cifar10 data preparation
import paddle.vision.transforms as T
from paddle.vision.datasets import Cifar10
paddle.set_device('gpu')
# Data preparation
transform = T.Compose([
T.Resize(size=(224,224)),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225],data_format='HWC'),
T.ToTensor()
])
train_dataset = Cifar10(mode='train', transform=transform)
train_loader = paddle.io.DataLoader(train_dataset, batch_size=64, shuffle=True, drop_last=True)
ResNet18 training at Cifar10
# Model preparation
res18 = paddle.vision.models.resnet18(num_classes=10)
res18.train()
# Training preparation
epoch_num = 10
optim = paddle.optimizer.Adam(learning_rate=0.001,parameters=res18.parameters())
loss_fn = paddle.nn.CrossEntropyLoss()
res50_loss = []
res50_acc = []
for epoch in range(epoch_num):
for batch_id, data in enumerate(train_loader):
inputs = data[0]
labels = data[1].unsqueeze(1)
predicts = res18(inputs)
loss = loss_fn(predicts, labels)
acc = paddle.metric.accuracy(predicts, labels)
loss.backward()
if batch_id % 100 == 0:
print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id, loss.numpy(), acc.numpy()))
if batch_id % 20 == 0:
res50_loss.append(loss.numpy())
res50_acc.append(acc.numpy())
optim.step()
optim.clear_grad()
GCT_ResNet18 training in Cifar10 dataset
# Model preparation
gct_res18 = resnet18(num_classes=10)
gct_res18.train()
# Training preparation
epoch_num = 10
optim = paddle.optimizer.Adam(learning_rate=0.001,parameters=gct_res18.parameters())
loss_fn = paddle.nn.CrossEntropyLoss()
gct_res18_loss = []
gct_res18_acc = []
for epoch in range(epoch_num):
for batch_id, data in enumerate(train_loader):
inputs = data[0]
labels = data[1].unsqueeze(1)
predicts = gct_res18(inputs)
loss = loss_fn(predicts, labels)
acc = paddle.metric.accuracy(predicts, labels)
loss.backward()
if batch_id % 100 == 0:
print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id, loss.numpy(), acc.numpy()))
if batch_id % 20 == 0:
gct_res18_loss.append(loss.numpy())
gct_res18_acc.append(acc.numpy())
optim.step()
optim.clear_grad()
Drawing ResNet18 and GCT_ResNet18 training curve
import matplotlib.pyplot as plt
plt.figure(figsize=(18,12))
plt.subplot(211)
plt.xlabel('iter')
plt.ylabel('loss')
plt.title('train loss')
x=range(len(gct_res18_loss))
plt.plot(x,res18_loss,color='b',label='ResNet18')
plt.plot(x,gct_res18_loss,color='r',label='ResNet18 + GCT')
plt.legend()
plt.grid()
plt.subplot(212)
plt.xlabel('iter')
plt.ylabel('acc')
plt.title('train acc')
x=range(len(gct_res18_acc))
plt.plot(x, res18_acc, color='b',label='ResNet18')
plt.plot(x, gct_res18_acc, color='r',label='ResNet18 + GCT')
plt.legend()
plt.grid()
plt.show()
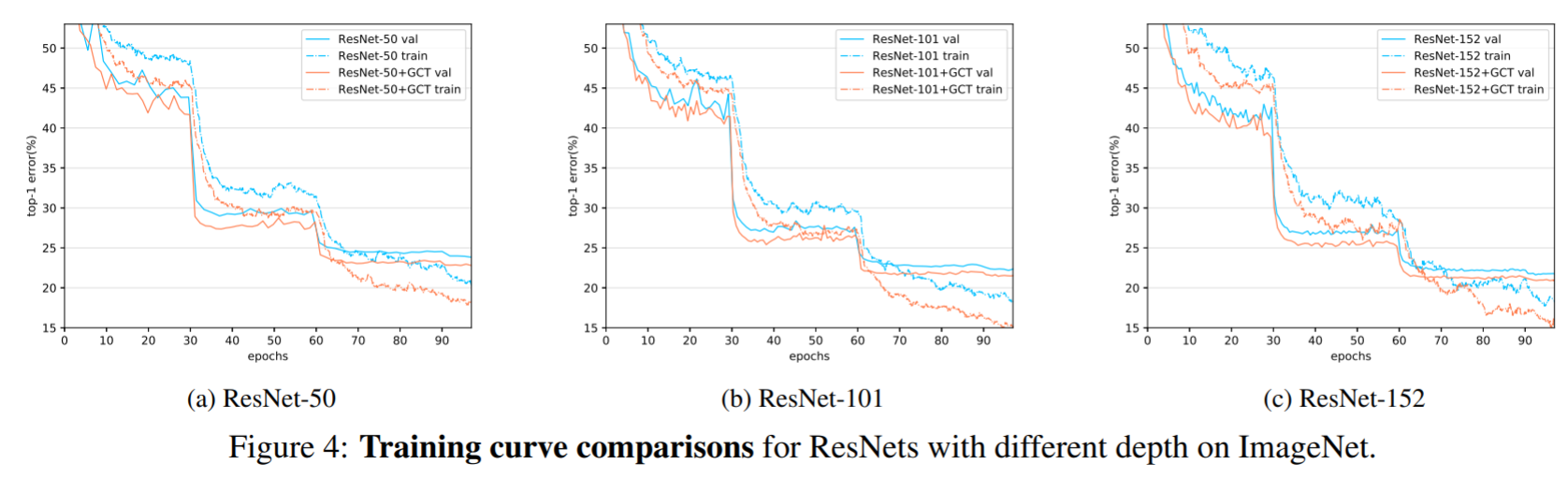
- Summary of model training: through the curve, it can be seen that after adding GCT attention mechanism, the robustness of the model is better, and the recognition accuracy is also improved to a certain extent, indicating the effectiveness of GCT attention.
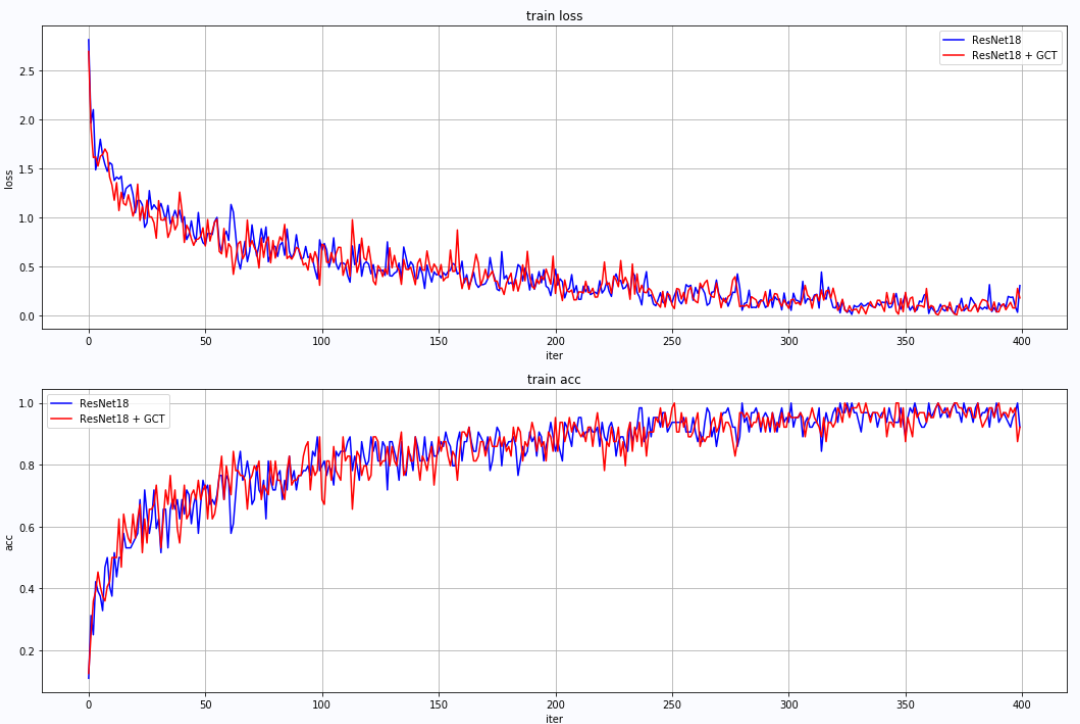
summary
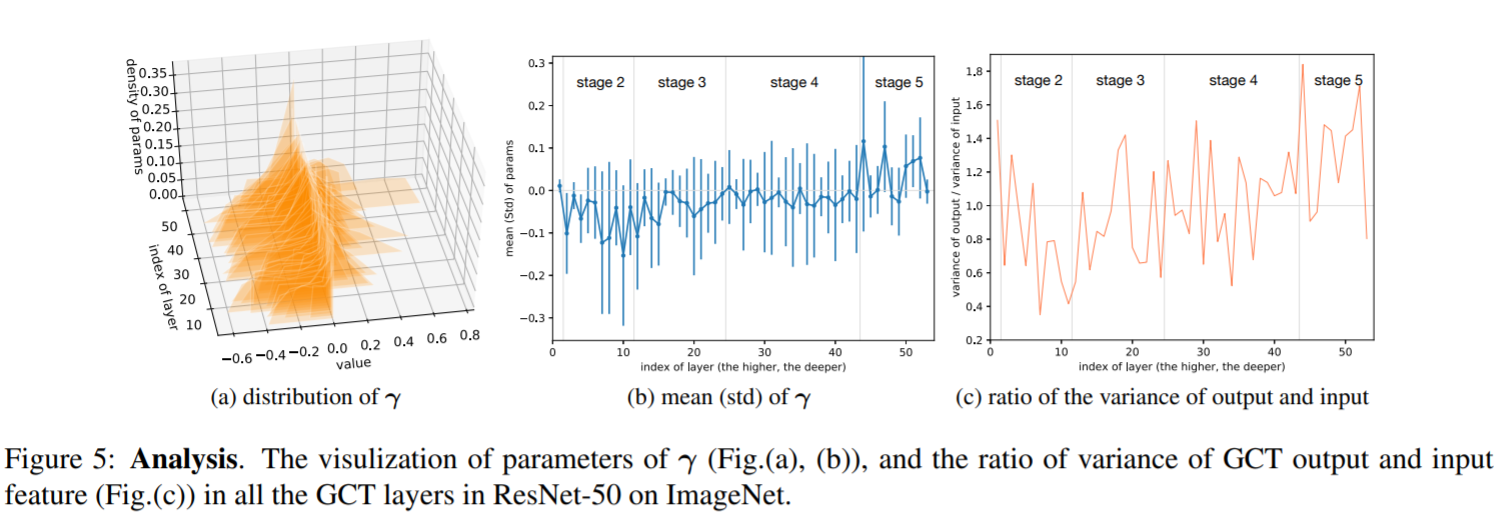
- Another interesting aspect of the paper is that the author has done an experiment to analyze in RestNet50, γ The impact of changes on the network. It can be seen that:
- 1. In the shallow layer of the network, γ The value of is relatively small, generally below 0, indicating the cooperative relationship between features;
- 2. In the deep layer of the network, γ The value of is increasing to more than 0, indicating that there is a competitive relationship between features, which is helpful for classification.
Special thanks for coming from the world (for reference in this article) https://aistudio.baidu.com/aistudio/projectdetail/1884947?channelType=0&channel=0)
Please click here View the basic usage of this environment
Please click here for more detailed instructions.