preface
Spark computing framework encapsulates three data structures for high concurrency and high throughput data processing
Handle different application scenarios. The three data structures are:
- RDD: distributed elastic dataset
- Accumulator: distributed shared write only variable
- Broadcast variables: distributed shared read-only variables
Chapter 8 RDD (distributed elastic data set)
8.1 what is RDD
RDD (Resilient Distributed Dataset) is called distributed elastic dataset and is the most basic data processing model in Spark. Code is an abstract class, which represents an elastic, immutable, partitioned collection in which the elements can be calculated in parallel.
8.1.1 elasticity
- Storage elasticity: automatic switching between memory and disk;
- Fault tolerant elasticity: data loss can be recovered automatically;
- Elasticity of calculation: calculation error retry mechanism;
- Elasticity of slicing: it can be sliced again as needed.
8.1.2 distributed
- Data is stored on different nodes of the big data cluster
8.1.3 data set
- RDD encapsulates computing logic and does not save data
8.1.4 data abstraction
- RDD is an abstract class, which needs the concrete implementation of subclasses
8.1.5 immutability
RDD encapsulates the computing logic and cannot be changed. If you want to change it, you can only generate a new RDD
The new RDD encapsulates computing logic
8.1.6 divisible and parallel computing
8.2 core attributes
/* * Internally,each RDD is characterized by five main properties: * * - A list of partitions * - A function for computing each split * - A list of dependencies on other RDDs * - Optionally,a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned) * - Optionally,a list of preferred locations to compute each split on (e.g. block locations for * an HDFS file) */
8.2.1 partition list
- There is a partition list in RDD data structure, which is used for parallel computing when executing tasks. It is an important attribute to realize distributed computing.
/*
* Implemented by subclasses to return the set of partitions in this RDD. This method will only
* be called once,so it is safe to implement a time-consuming computation in it.
*
* The partitions in this array must satisfy the following property :
* `rdd.partitions.zipWithIndex.forall { case (partition, index)=> partition.index == index }`
*/
protected def getPartitions: Array[Partition]
8.2.2 partition calculation function
- Spark uses partition function to calculate each partition during calculation
/* * :: DeveloperApi :: * Implemented by subclasses to compute a given partition. */ @DeveloperApi def compute(split: Partition, context: TaskContext): Iterator[T]
8.2.3 dependencies between RDDS
- RDD is the encapsulation of computing models. When multiple computing models need to be combined in requirements, it is necessary to establish dependencies on multiple RDDS
/* * Implemented by subclasses to return how this RDD depends on parent RDDs. This method will only * be called once,so it is safe to implement a time-consuming computation in it. */ protected def getDependencies: Seq[Dependencyl_]] = deps
8.2.4 divider (optional)
- When the data is KV type data, you can customize the partition of the data by setting the divider
/* * Optionally overridden by subclasses to specify how they are partitioned. */ @transient val partitioner: Option[Partitioner] = None
8.2.5 preferred location (optional)
- When calculating data, you can select different node locations for calculation according to the status of the calculation node
/* * Optionally overridden by subclasses to specify placement preferences. */ protected def getPreferredLocations(split: Partition): Seq[String] = Nil
8.3 execution principle
- From the perspective of computing, computing resources (memory & CPU) and computing model (logic) are required in the process of data processing. During execution, it is necessary to coordinate and integrate computing resources and computing models.
- When executing, Spark framework first applies for resources, and then decomposes the data processing logic of the application into computing tasks one by one. Then, the task is sent to the calculation node that has allocated resources, and the data is calculated according to the specified calculation model. Finally, the calculation results are obtained.
- RDD is the core model for data processing in Spark framework. Next, let's take a look at the working principle of RDD in Yan environment:
8.3.1 start the Yan cluster environment
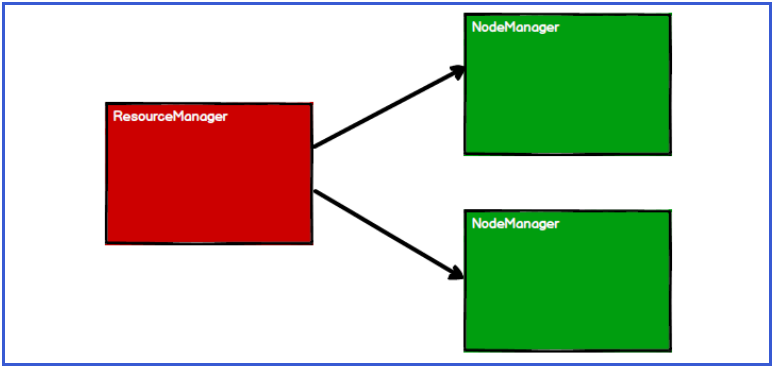
8.3.2 Spark creates scheduling nodes and computing nodes by applying for resources
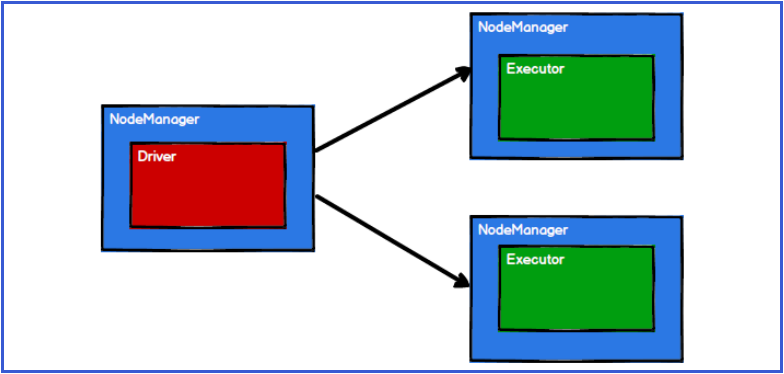
8.3.3 Spark framework divides computing logic into different tasks according to requirements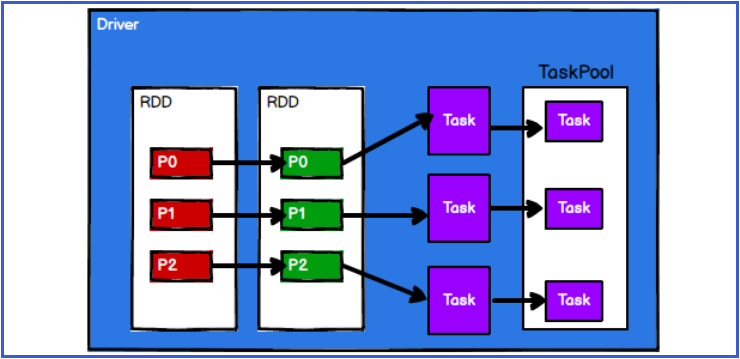
8.3.4 the scheduling node sends the task to the corresponding computing node for calculation according to the status of the computing node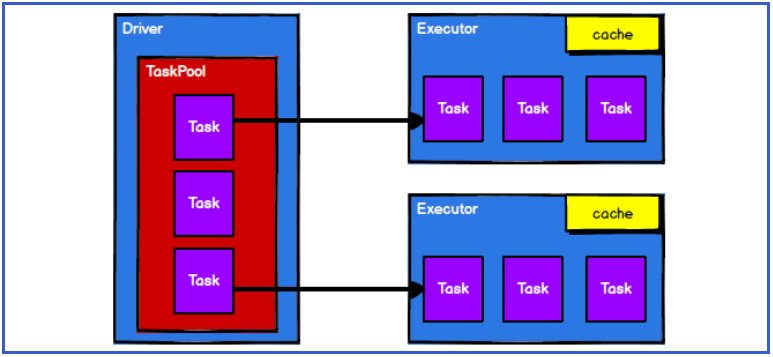
From the above process, we can see that RDD is mainly used to encapsulate logic, generate tasks and send them to the Executor node for calculation. Later, we will take a look at the specific data processing of RDD in Spark framework.
Statement: This article is a note taken during learning. If there is any infringement, please inform us to delete it!
Original video address: https://www.bilibili.com/video/BV11A411L7CK