preface
Hi! hello everyone!
Recently, most of the hot lists on CSDN are Python crawler articles. It can be seen that everyone's enthusiasm for Python is still very high, so I code this article overnight these days in combination with some tutorials. If you want technical exchange, you can go to my home page and have technical exchange together. You have been an audience in CSDN for many years and sent an article for the first time. I hope you can make progress together!
This article can be said to be the most complete Python crawler tutorial in Station C, from software installation to actual combat crawling. Not only rich cases, but also direct code analysis, which can make people more intuitively understand the meaning of each line of code! (the article is long. It is recommended to like the collection first and then watch it!)
First show you my girlfriend!

Chapter 1 Introduction to Python zero basic syntax
1.1 Python and PyCharm installation
1. Install Python 3 on Windows
(1) Open the browser and visit the Python official website( https://www.python.org/ ).
(2) Move the mouse to the Downloads link and click the Windows link.
(3) According to the reader's Windows Version (32-bit or 64 bit), download the corresponding Python version 3.5. If it is windows 32-bit, click to download Windows x86 executable installer. If it is windows 64 bit, click to download Windows x86-64 executable installer.
(4) Click Run file, check Add Python 3.5 to PATH, and then click Install Now to complete the installation.
In the computer, open the command prompt (cmd) and enter python. The interface shown in the figure shows that the python environment is installed successfully.
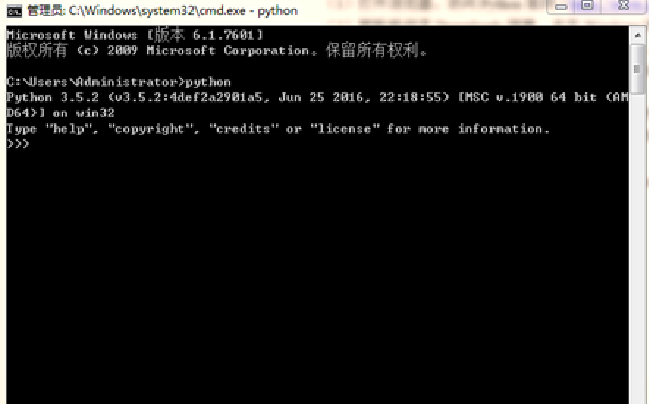
The prompt > > > on the interface indicates that you have entered the python interactive environment. Enter the code and press enter to run the Python code. Enter exit() and press enter to exit the python interactive environment.
2. Installing Python 3 on MAC
The MAC comes with Python 2.7. You need to install Python 3.5 on the python official website. Installation on the MAC is easier than under Windows, and you can complete it by clicking the next button all the time. Open the terminal and enter Python 3 to enter the interactive environment of Python 3 on Mac.
3. Installing Python 3 on Linux
Most Linux system computers have Python 2 and python 3 built-in. You can view the current version of Python 3 by entering Python – version on the terminal. If you need to install a specific version of python, you can enter in the terminal:
sudo apt-get install python3.5
1.1.2 PyCharm installation
After installing the python environment, readers also need to install an integrated development environment (IDE), which integrates code writing function, analysis function, compilation function and debugging function. Here we recommend the most intelligent and easy-to-use Python IDE called PyCharm. Enter PyCharm's official website( http://www.jetbrains.com/pycharm/ ), download the Community Edition.
How to use PyCharm to associate Python interpreter so that PyCharm can run Python code.
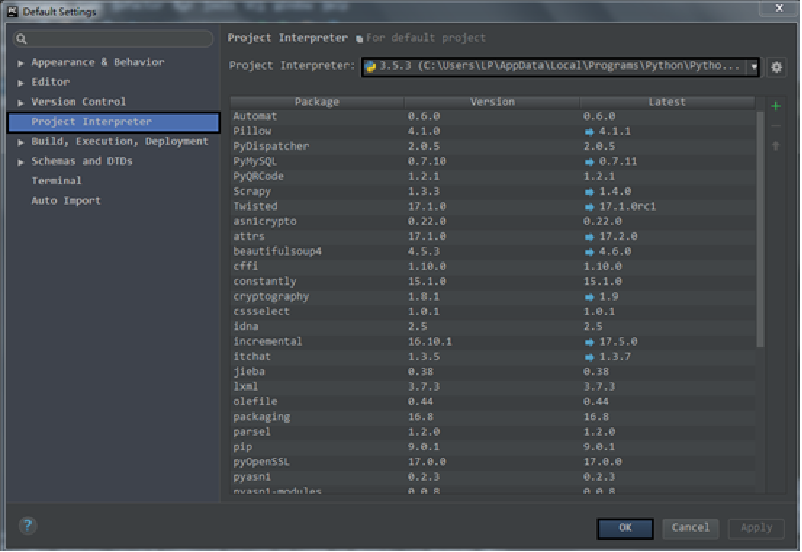
(1) Open PyCharm and select File > default settings in the menu bar.
(2) Click Project Interpreter, select Python environment on the right side of the window, select Python 3.5, and click OK to associate the Python interpreter (as shown in the figure below).
1.2 variables and strings
1.2.1 variables
Variables in Python are easy to understand, for example:
a = 1
This operation is called assignment, which means that the value 1 is assigned to the variable a.
Note: in Python, the statement end does not need to be completed with a semicolon, and variables do not need to be defined in advance.
Now there are variables a and b. we can exchange the values of variables a and b through the following code:
a = 4 b = 5 t = a #Assign a value to the t variable a = b #Assign the b value to the a variable b = t #Assign the t value to the b variable print(a,b) # result 5 4
This method is similar to exchanging the drinks in two cups. We only need to add one more cup to complete the exchange of drinks.
1.2.2 "addition" and "multiplication" of strings
Since most Python crawler objects are text, the use of strings is particularly important. In Python, a string consists of double or single quotation marks and characters in quotation marks. First, look at the "addition" of strings through the following code:
a = 'I' b = ' love' c = ' Python' print(a + b + c) #String addition # result I love Python
In the crawler code, URL s are often constructed. For example, when crawling a web page link, there are only some: / u/9104ebf5e177. This part of the link is inaccessible and needs to be updated http://www.jianshu.com At this time, you can merge strings by "adding".
Python strings can not only be added, but also multiplied by a number:
a = 'word' print(a*3) #String multiplication #result wordwordword
The string is multiplied by a number, which means the number of copies of the string.
1.2.3 slicing and indexing of strings
The slicing and indexing of strings is to obtain some information of strings through string[x]:
a = 'I love python' print(a[0]) #Take the first element of the string #result I print(a[0:5]) #Take the first to fifth elements of the string #result I lov print(a[-1]) #Take the last element of the string #result n
The slice and index of the string can be clearly understood through the following figure:

1.2.4 string method
As an object-oriented language, Python has corresponding methods for each object, as well as strings. It has a variety of methods. Here are some methods commonly used in crawlers.
1.split() method
a = 'www.baidu.com'
print(a.split('.'))
# result ['www', 'baidu', 'com']
2. Repeat() method
a = 'There is apples'
b = a.replace('is','are')
print(b)
# result There are apples
This method is similar to the find and replace function in text.
3.strip() method
a = ' python is cool ' print(a.strip()) # result python is cool
The strip() method returns a string with spaces on both sides (excluding the interior) removed. You can also specify the characters to be removed and list them as parameters.
4.format() method
Finally, explain the easy-to-use string formatter. First look at the code.
a = '{} is my love'.format('Python')
print(a)
# result Python is my love
The string formatter is like a multiple-choice question, leaving space for the questioner to choose. In the process of crawling, some parameters of web page links are variable. At this time, using string formatter can reduce the use of code.
String formatter demo
1.3 functions and control statements
1.3.1 function
"Leave the dirty work to the function". First, take a look at the method of defining the function in Python.
def Function name (parameter 1, parameter 2...): return 'result'
The area function of a right triangle can be calculated by making an input right angle edge:
def function(a,b): return '1/2*a*b' #You can also write this def function(a,b): print( 1/2*a*b)
Note: don't worry about the difference. return returns a value, and the second is to call a function to execute the printing function.
By entering function(2,3), you can call the function to calculate the area of a right triangle with right angles of 2 and 3.
1.3.2 judgment statement
Judgment statements are often used in crawler practice. The format of Python judgment statements is as follows:
if condition: do else: do
Note: don't forget colons and indents
Let's look at the format of multiple conditions
if condition: do elif condition: do else: do
When using the password at ordinary times, you can log in if the password is correct, and you need to continue to enter it if it is wrong.
def count_login():
password = input('password:')
if password == '12345':
print('Input succeeded!')
else:
print('Error, enter again')
count_login()
count_login()
(1) Run the program, Enter the password and press Enter.
(2) If the input string is 12345, "input succeeded!" will be printed, The program is over.
(3) If the input string is not 12345, print "error, enter again" and continue to run the program until the input is correct to.
Readers can also design more interesting, such as "exit the program after 3 input failures".
1.3.3 circular statements
Python loop statements include a for loop and a while loop, as shown in the following code.
#for loop for item in iterable: do #item represents an element, and iterable is a collection for i in range(1,11): print(i) #The result is to output 1 to 10 in turn. Remember that 11 is not output, and range is a Python built-in function. #while Loop while condition: do
1.4 Python data structure
1.4.1 list
Most of the data crawled out of the list structure is the most crawled data structure. First, introduce the most salient features of the list:
(1) Each element in the list is mutable.
(2) The elements of the list are ordered, that is, each element has a corresponding position (similar to the slice index of a string).
(3) The list can hold all objects.
1.4.2 dictionary
The dictionary data structure of Python is similar to that of real dictionaries, which is expressed in the form of key value pairs ('key '-' value '). This article only explains the creation of the dictionary, and the operation of the dictionary will be introduced in detail later.
user_info = {
'name':'xiaoming',
'age':'23',
'sex':'man'
1.4.3 tuples and sets
Tuples and collections are rarely used in crawlers. Here is a brief introduction. Tuples are similar to lists, but the elements of tuples cannot be modified and can only be viewed. The format of tuples is as follows.
tuple = (1,2,3)
The concept of set is similar to that in mathematics. The elements in each collection are unordered and non repeatable objects. Sometimes, duplicate data can be removed through the collection.
list = ['xiaoming','zhangyun','xiaoming']
set = set(list)
print(set)
# result {'zhangyun', 'xiaoming'}
1.5 Python file operation
1.5.1 open file
In Python, open the file through the open() function. The syntax is as follows:
open(name[, mode[, buffering]])
The open() function uses the file name as the only mandatory argument, and then returns a file object. Mode and buffering are optional parameters. In Python file operation, the input of mode parameter is necessary, while buffering is less used.
1.5.2 reading and writing documents
With the class file object named f in the previous section, you can write and read data through the f.write() method and f.read() method.
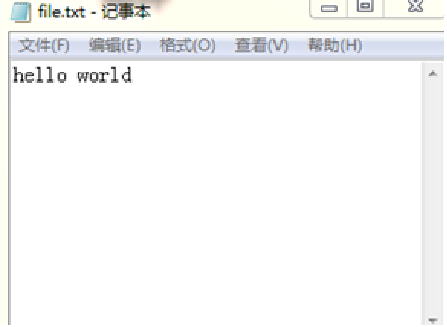
f = open('C:/Users/Administrator/Desktop/file.txt','w+')
f.write('hello world')
At this time, open file.on this machine Txt file, you can see the results shown in the figure below.
If you run the program again, the contents in the txt file will not be added. You can modify the mode parameter to 'r +' and write to the file all the time.
1.5.3 closing documents
When you finish reading and writing, you should remember to use the close() method to close the file. This ensures Python's buffer cleanup (temporarily storing data in memory for efficiency reasons) and file security. Close the file with the following code.
f = open('C:/Users/Administrator/Desktop/file.txt','r')
content = f.read()
print(content)
f.close()
1.6 Python object oriented
1.6.1 definition class
Class is a collection of objects that describe the same properties and methods. People can be divided into different kinds by different skin colors, different kinds of food, and different kinds of goods, but if they are divided into the same kind of objects, they must have similar characteristics and behavior.
For the same bicycle, their composition structure is the same: frame, wheel, pedal, etc. The class of this bicycle can be defined through Python:
class Bike: compose = ['frame','wheel','pedal']
By using class to define a bicycle class, the variable compose in the class is called the variable of the class, and the professional term is the attribute of the class. In this way, as like as two peas, the bicycle that customers buy is composed of the same structure.
my_bike = Bike() you_bike = Bike() print(my_bike.compose) print(you_bike.compose) #The properties of the class are the same
1.6.2 instance properties
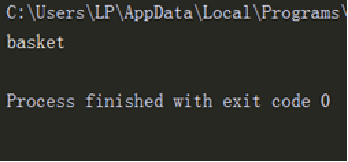
For the same bike, some customers will transform it after they buy it, add a basket to put things, etc.
class Bike:
compose = ['frame','wheel','pedal']
my_bike = Bike()
my_bike.other = 'basket'
print(my_bike.other) #Instance properties
The results are shown in the figure below.
1.6.3 example method
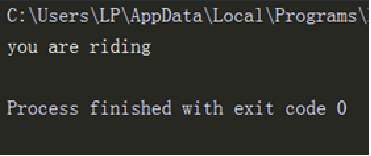
Whether the reader remembers the format() method of the string. Methods are functions. Methods are used for instances, so they are also called instance methods. For a bicycle, its way is to ride.
class Bike:
compose = ['frame','wheel','pedal']
def use(self):
print('you are riding')
my_bike = Bike()
my_bike.use()
The results are shown in the figure below.
1.6.4 inheritance of classes
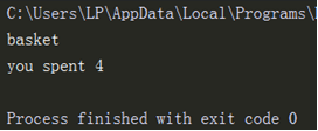
With the changes of the times, more and more shared bicycles appear. The new shared bicycles are similar to the original structure, but have more payment functions.
class Bike:
compose = ['frame','wheel','pedal']
def __init__(self):
self.other = 'basket' #Define the properties of the instance
def use(self,time):
print('you ride {}m'.format(time*100))
class Share_bike(Bike):
def cost(self,hour):
print('you spent {}'.format(hour*2))
bike = Share_bike()
print(bike.other)
bike.cost(2)
Class inheritance
Chapter 2 crawler principle and web page structure
2.1 reptile principle
2.1.1 network connection
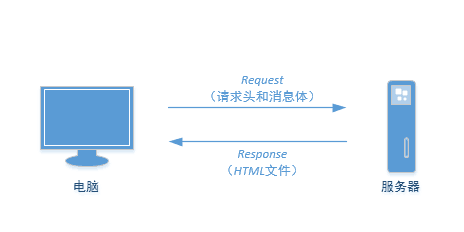
The network connection is like buying drinks on the self-service beverage vending machine: the buyer only needs to select the required drinks and put in coins (or notes), and the self-service beverage vending machine will pop up the corresponding products. The same is true for network connection. As shown in the figure below, the local computer (buyer) sends a Requests request (purchase) to the server (self-service beverage vending machine) with the request header and message body (coin and required beverage), and the corresponding server (self-service beverage vending machine) will return the corresponding HTML file of the local computer as the Response (corresponding commodity).
2.1.2 reptile principle
After understanding the basic principle of network connection, the principle of crawler is well understood. The network connection requires a request from the computer and a Response from the server. Reptiles also need two things:
(1) The analog computer initiates Requests to the server.
(2) Receive the content of the server-side Response and parse and extract the required information.
However, Internet web pages are complex, and one request and response can not obtain web page data in batch. At this time, it is necessary to design the process of crawler. This book mainly uses the process required by two kinds of crawlers: multi page and cross page crawler process.
Multi page web crawler process:
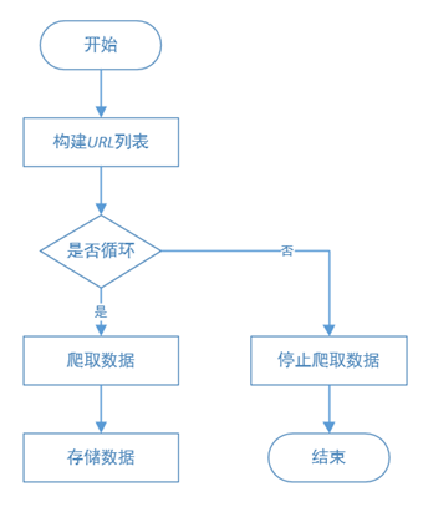
Cross page web crawler process:
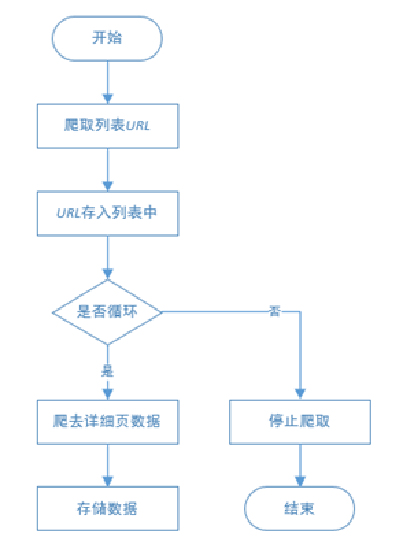
2.2 web page structure
2.2.1 installation of Chrome browser
The installation of Chrome browser is the same as that of ordinary software, and no configuration is required. Enter chrome in the search engine and click download and install. After the installation is completed, open and the following error will appear.
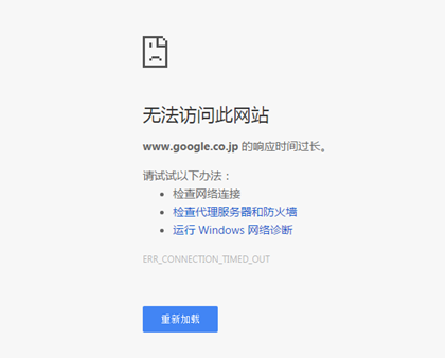
This is because the default search engine of Chrome browser is Google search engine, and the domestic network cannot be opened. The solution is:
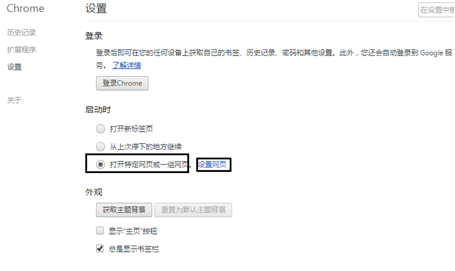
(1) Open the Chrom e browser settings.
(2) In the "on startup" column, select to open a specific web page or a group of web pages.
(3) Click the "set Web page" link, enter the search engine or web page commonly used by readers, and click the "OK" button.
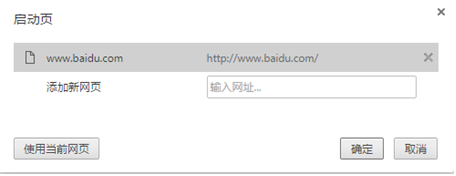
(4) Exit Chrome browser and open the set Web page. The operation effect is shown in the figure below
Chrome browser settings web page (I)
Chrome browser settings web page (2)
Chrome browser settings web page (3)
2.2.2 web page structure
Now open any web page( http://bj.xiaozhu.com/ ), right-click the blank space, and select the "check" command in the pop-up shortcut menu to see the code of the web page.
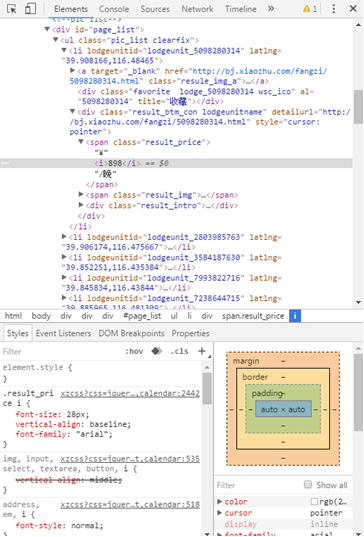
When analyzing this figure, the upper part is HTML file, the lower part is CSS style, and the tag is JavaScript. The web page users browse is the result of the browser rendering. The browser is like a translator, translating HTML, CSS and JavaScript to get the web interface used by users.
2.2.3 Query Web page information
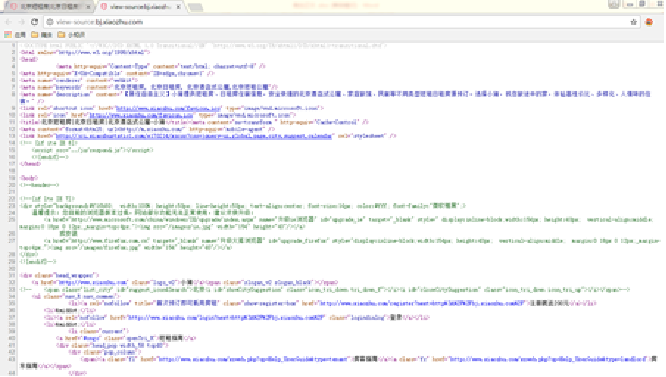
Open web page( http://bj.xiaozhu.com/ ), right-click the blank space of the web page and select view web page source code from the shortcut menu to view the source code of the web page, as shown in the figure.
Chapter 3 my first crawler
3.1 Python third party libraries
3.1.1 concept of Python third-party library
Part of the reason why Python is powerful and increasingly popular is due to Python's powerful third-party libraries. In this way, users do not need to understand the underlying ideas and write the most functions with the least code.
Without using the third library, users have to start with raw materials and make them step by step. How long does it take to make a wheel? The use of a third-party library is different. The wheels and body of the car have been manufactured and can be used after splicing (some cars are directly given to the user). This ready to use is a Python third-party library
3.1.2 installation method of Python third-party library
1. Install in PyCharm
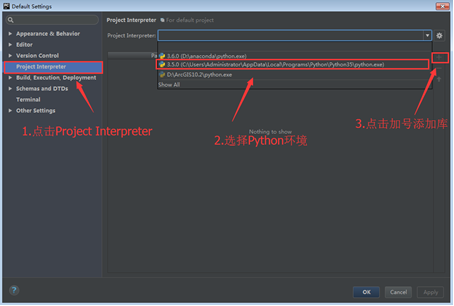
(1) Open PyCharm and select File > default settings in the menu bar.
(2) Click the Project Interpreter option on the left and select the Python environment on the right of the window.
(3) Click the "+" button to add a third-party library.
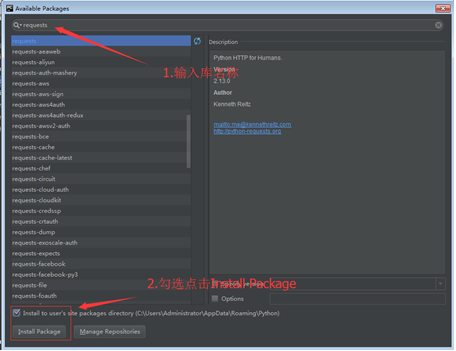
(4) Enter the name of the third-party library and select the library to download.
(5) Check the Install to users site check box and click the Install Package button. The operation process is shown in the figure.
2. Install in pip
After installing Python, pip will also be installed at the same time. We can enter in cmd on the command line:
pip --version
If the following prompt appears, pip is successfully installed:
pip 9.0.1 from D:\anaconda\lib\site-packages (python 3.6)
After pip is successfully installed, enter the following code in command line cmd to download the third-party library:
pip3 install packagename #Package name is the name of the installation library. Enter PIP3 install beatifulsoup4 here to download the beatifulsoup4 library.
Note: if it is Python 2, pip3 is changed to pip
Prompt after installation:
Successfully installed packagename
3. Download whl file
Sometimes problems may occur in the installation of the first two methods, which may be caused by network reasons or package dependencies. At this time, manual installation is required. This method is the most reliable.
(1) Enter http://www.lfd.uci.edu/ ~Gohlke / Python LIBS /, search the lxml library, and click download to local, as shown in the figure.

(2) To the command line, enter:
pip3 install wheel
(3) Wait for the execution to complete. After successful execution, enter on the command line:
cd D:\python\ku #The following is the path to download the whl file
(4) Finally, on the command line, enter:
pip3 install lxml-3.7.2-cp35-cp35m-win_amd64.whl # lxml-3.7.2-cp35-cp35m-win_amd64.whl is the full pathname of the file you downloaded
In this way, the library can be downloaded locally, and the dependent packages can be automatically installed through the whl file.
3.1.3 usage of Python third-party libraries
After successfully installing the Python third-party library, you can import and use the third-party library through the following methods:
import xxxx #xxxx is the name of the imported library, such as import requests
Note: the way to import the beautiful soup library is from BS4 import beautiful soup.
3.2 three reptile Libraries
3.2.1 Requests Library
The official documents of the Requests library point out: let HTTP serve human beings. Careful readers will find that the function of Requests library is to request websites to obtain web page data. Let's start with a simple example to explain how to use the Requests library.
import requests
res = requests.get('http://bj.xiaozhu.com / '# website is the website of Xiaozhu short rent network in Beijing
print(res)
#The result returned in pycharm is < response [200] >, indicating that the request for the web address is successful. If it is 404400, the request for the web address fails.
print(res.text)
#Some results of pycharm are shown in the figure
3.2.2 beautiful soup Library
The beautiful Soup library is a very popular Python module. Through the beautiful Soup library, you can easily parse the web page requested by the Requests library, and parse the web page source code into a Soup document to filter and extract data.
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1;
WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/53.0.2785.143 Safari/537.36'
}
res =
requests.get('http://bj.xiaozhu.com/',headers=headers)
soup = BeautifulSoup(res.text,'html.parser')
#Parse the returned results
print(soup.prettify())
3.2.3 Lxml Library
The Lxml library is a Python package based on libxm12, an XML parsing library. The module is written in C language, and the parsing speed is faster than beautiful soup. The specific use methods are explained in the following chapters.
3.3 comprehensive example - crawling short rental information in Beijing
3.3.1 reptile thinking analysis
(1) Crawling through the 13 pages of information about Piggy's short rent in Beijing and browsing manually, the following is the website of the first four pages:
http://bj.xiaozhu.com/
http://bj.xiaozhu.com/search-duanzufang-p2-0/
http://bj.xiaozhu.com/search-duanzufang-p3-0/
http://bj.xiaozhu.com/search-duanzufang-p4-0/
Just change the number after p to construct a 13 page web address.
(2) This crawler is carried out in the details page, so you need to crawl the URL link entering the details page first, and then crawl the data.
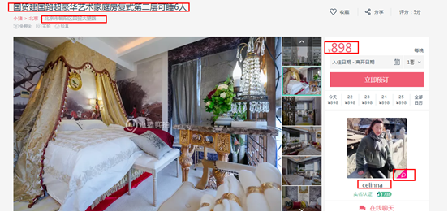
(3) The information to be crawled is:
Title, address, price, landlord's name
The landlord's gender has been linked to the landlord's Avatar,
As shown in the figure.
3.3.2 crawler code and analysis
The code is as follows:
01 from bs4 import BeautifulSoup
02 import requests
03 import time #Import the corresponding library file
04
05 headers = {
06 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like 07 Gecko) Chrome/53.0.2785.143 Safari/537.36'
08 } #Join request header
09
10 def judgment_sex(class_name): #Define the function to judge the user's gender
11 if class_name == ['member_ico1']:
12 return 'female'
13 else:
14 return 'male'
15
16 def get_links(url): #Defines the function to get the url of the detailed page
17 wb_data = requests.get(url,headers=headers)
18 soup = BeautifulSoup(wb_data.text,'lxml')
19 links = soup.select('#page_list > ul > li > a') #links is a list of URLs
20 for link in links:
21 href = link.get("href")
22 get_info(href) #Loop out the url and call get in turn_ Info function
23
24 def get_info(url): #Define a function to get web page information
25 wb_data = requests.get(url,headers=headers)
26 soup = BeautifulSoup(wb_data.text,'lxml')
27 tittles = soup.select('div.pho_info > h4')
28 addresses = soup.select('span.pr5')
29 prices = soup.select('#pricePart > div.day_l > span')
30 imgs = soup.select('#floatRightBox > div.js_box.clearfix > div.member_pic > a > img')
31 names = soup.select('#floatRightBox > div.js_box.clearfix > div.w_240 > h6 > a')
32 sexs = soup.select('#floatRightBox > div.js_box.clearfix > div.member_pic > div')
33 for tittle, address, price, img, name, sex in zip(tittles,addresses,prices,imgs,names,sexs):
34 data = {
35 'tittle':tittle.get_text().strip(),
36 'address':address.get_text().strip(),
37 'price':price.get_text(),
38 'img':img.get("src"),
39 'name':name.get_text(),
40 'sex':judgment_sex(sex.get("class"))
41 }
42 print(data) #Get the information and print it through the dictionary
43
44 if __name__ == '__main__': #It is the main entrance of the program
45 urls = ['http://bj.xiaozhu.com/search-duanzufang-p{}-0/'.format(number) for number in 46 range(1,14)] # Construct multi page url
47 for single_url in urls:
48 get_links(single_url) #Loop call get_links function
49 time.sleep(2) #Sleep for 2 seconds
Some results of the operation are shown in the figure.
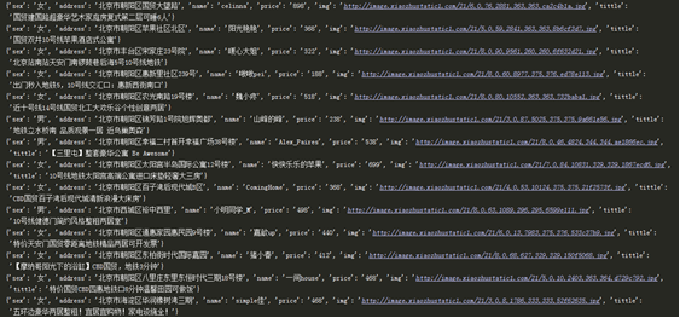
Code analysis:
(1)
01 from bs4 import BeautifulSoup 02 import requests 03 import time #Import the corresponding library file
The library required by the importer. The Requests library is used to request web pages to obtain web page data. Beautiful soup is used to parse web page data. The sleep() method of the time library allows the program to pause.
(2)
05 headers = {
06 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like 07 Gecko) Chrome/53.0.2785.143 Safari/537.36'
08 } #Join request header
Through the developer tool of Chrome browser, copy the user agent, which is used to disguise as a browser to facilitate the stability of crawlers.
(3)
16 def get_links(url): #Defines the function to get the url of the detailed page
17 wb_data = requests.get(url,headers=headers)
18 soup = BeautifulSoup(wb_data.text,'lxml')
19 links = soup.select('#page_list > ul > li > a') #links is a list of URLs
20 for link in links:
21 href = link.get("href")
22 get_info(href) #Loop out the url and call get in turn_ Info function
Get defined_ The links() function is used to get the link to enter the details page.
(4)
24 def get_info(url): #Define a function to get web page information
25 wb_data = requests.get(url,headers=headers)
26 soup = BeautifulSoup(wb_data.text,'lxml')
27 tittles = soup.select('div.pho_info > h4')
28 addresses = soup.select('span.pr5')
29 prices = soup.select('#pricePart > div.day_l > span')
30 imgs = soup.select('#floatRightBox > div.js_box.clearfix > div.member_pic > a > img')
31 names = soup.select('#floatRightBox > div.js_box.clearfix > div.w_240 > h6 > a')
32 sexs = soup.select('#floatRightBox > div.js_box.clearfix > div.member_pic > div')
33 for tittle, address, price, img, name, sex in zip(tittles,addresses,prices,imgs,names,sexs):
34 data = {
35 'tittle':tittle.get_text().strip(),
36 'address':address.get_text().strip(),
37 'price':price.get_text(),
38 'img':img.get("src"),
39 'name':name.get_text(),
40 'sex':judgment_sex(sex.get("class"))
41 }
42 print(data) #Get the information and print it through the dictionary
Define get_info() function, which is used to obtain web page information and output information.
(5)
10 def judgment_sex(class_name): 11 if class_name == ['member_ico1']: 12 return 'female' 13 else: 14 return 'male'
Define judgment_ The sex() function is used to determine the gender of the landlord.
(6)
44 if __name__ == '__main__': #It is the main entrance of the program
45 urls = ['http://bj.xiaozhu.com/search-duanzufang-p{}-0/'.format(number) for number in 46 range(1,14)] # Construct multi page url
47 for single_url in urls:
48 get_links(single_url) #Loop call get_links function
49 time.sleep(2) #Sleep for 2 seconds
It is the main entrance of the program.
Chapter 4 regular expressions
4.1 common symbols of regular expressions
4.1.1 general characters
Regular expressions have three general characters, as shown in the table.

4.1.2 predefined character set
There are 6 predefined character sets for regular expressions, as shown in table.

4.1.3 quantifier
See table for the list of Quantifiers in regular.

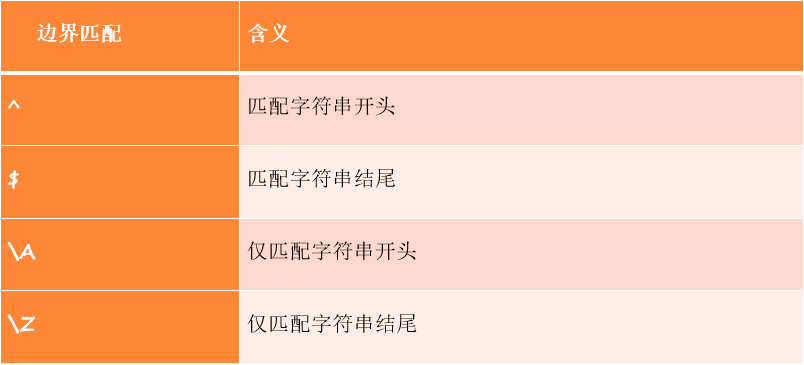
4.1.4 boundary matching
See table for key symbols of boundary matching.
4.2 re module and its method
4.2.1 search() function
The search () function of the re module matches and extracts the first regular content, and returns a regular expression object. The syntax of the search() function is:
re.match(pattern, string, flags=0)
(1) pattern is the regular expression that matches.
(2) String is the string to match.
(3) flags is the flag bit, which is used to control the matching method of regular expressions, such as case sensitive, multi line matching, etc.
It can be seen that the search() function returns a regular expression object. The string "1" is matched through the regular expression. You can return the matched string through the following code:
import re
a = 'one1two2three3'
infos = re.search('\d+',a)
print(infos.group()) #group method to get information
4.2.2 sub() function
The re module provides a sub() function to replace the matching items in the string. The syntax of the sub() function is:
re.sub(pattern, repl, string, count=0, flags=0)
(1) pattern is the regular expression that matches.
(2) repl is the replaced string.
(3) String is the original string to be found and replaced.
(4) counts is the maximum number of times to replace after pattern matching. By default, 0 means to replace all matches.
(5) flags is the flag bit, which is used to control the matching method of regular expressions, such as case sensitive, multi line matching, etc.
4.2.3 findall() function
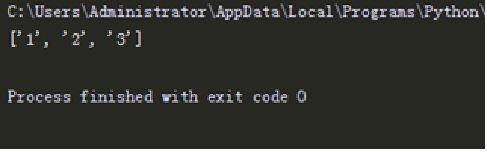
The findall() function matches all the regular contents and returns the results in the form of a list. For example, 'one1two2three3' in the above, only the first regular result can be matched through the search() function, and all numbers of the string can be returned through findall.
import re
a = 'one1two2three3'
infos = re.findall('\d+',a)
print(infos)
The results are shown in the figure.
4.2.4 re module modifier
The re module contains some optional flag modifiers to control the matching pattern, as shown in the table.
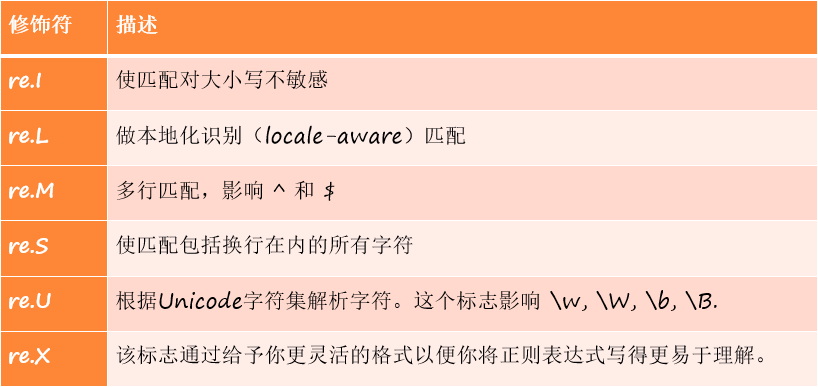
In reptiles, re S is the most commonly used modifier, which can match newline.
4.3 comprehensive example - climbing through the sky full-text novel
4.3.1 reptile thinking analysis
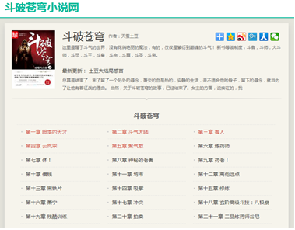
(1) The content of crawling is the full-text novel of the sky breaking novel network, as shown in the figure.
(2) Crawl the information of all chapters and browse manually. The following are the websites of the first five chapters:
http://www.doupoxs.com/doupocangqiong/2.html
http://www.doupoxs.com/doupocangqiong/5.html
http://www.doupoxs.com/doupocangqiong/6.html
http://www.doupoxs.com/doupocangqiong/7.html
http://www.doupoxs.com/doupocangqiong/8.html
There is no obvious law between Chapter 1 and Chapter 2, but the URL law after chapter 2 is very obvious, paging through digital recursion. Manual input http://www.doupoxs.com/doupocangqiong/3.html , you will find the 404 interface.
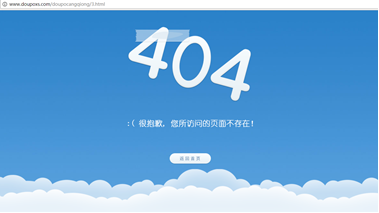
So the specific idea is: start from the first chapter to construct the URL. If there are 404 errors in the middle, skip and don't crawl.
(3) The information to be crawled is full text information, as shown in the figure below.
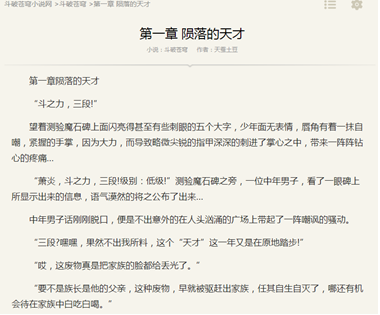
(4) Use Python to operate the file and store the crawled information in the local txt text.
4.3.2 crawler code and analysis
The code is as follows:
01 import requests
02 import re
03 import time #Import the corresponding library file
04
05 headers = {
06 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like 07 Gecko) Chrome/56.0.2924.87 Safari/537.36'
08 } #Join request header
09
10 f = open('C:/Users/LP/Desktop/doupo.txt','a+') #Create a new txt document and append it
11
12 def get_info(url): #Define functions to get information
13 res = requests.get(url,headers=headers)
14 if res.status_code == 200: #Judge whether the request code is 200
15 contents = re.findall('<p>(.*?)</p>',res.content.decode('utf-8'),re.S)
16 for content in contents:
17 f.write(content+'\n') #Regular get data written to txt file
18 else:
19 pass #pass if it's not 200
20
21 if __name__ == '__main__': #Program main entrance
22 urls = ['http://www.doupoxs.com/doupocangqiong/{}.html'.format(str(i)) for i in 23 range(2,1665)] # Construct multi page url
24 for url in urls:
25 get_info(url) #Loop call get_info function
26 time.sleep(1) #Sleep for 1 second
f.close() #Close txt file
The running results are saved on the computer in a document named doupo, as shown in the figure

Code analysis:
(1)
01 import requests 02 import re 03 import time #Import the corresponding library file
The library required by the importer. The Requests library is used to request web pages to obtain web page data. Using regular expressions does not need to parse web page data with beautiful soup, but uses the re module in Python to match regular expressions. The sleep() method of the time library allows the program to pause.
(2)
05 headers = {
06 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like 07 Gecko) Chrome/56.0.2924.87 Safari/537.36'
08 } #Join request header
Through the developer tool of Chrome browser, copy the user agent, which is used to disguise as a browser to facilitate the stability of crawlers.
(3)
10 f = open('C:/Users/LP/Desktop/doupo.txt','a+') #Create a new txt document and append it
Create a new TXT document to store the full-text information of the novel.
(3)
12 def get_info(url): #Define functions to get information
13 res = requests.get(url,headers=headers)
14 if res.status_code == 200: #Judge whether the request code is 200
15 contents = re.findall('<p>(.*?)</p>',res.content.decode('utf-8'),re.S)
16 for content in contents:
17 f.write(content+'\n') #Regular get data written to txt file
18 else:
19 pass #pass if it's not 200
Define get_info() function, which is used to obtain web page information and store information. After the URL is passed in, make a request. Locate the novel text content through regular expression and write it into TXT document.
(4)
21 if __name__ == '__main__': #Program main entrance
22 urls = ['http://www.doupoxs.com/doupocangqiong/{}.html'.format(str(i)) for i in 23 range(2,1665)] # Construct multi page url
24 for url in urls:
25 get_info(url) #Loop call get_info function
26 time.sleep(1) #Sleep for 1 second
It is the main entrance of the program. Through the observation of web page URLs, all novel URLs are constructed through the derivation of the list, and get is called in turn_ Info() function, time Sleep (1) means to pause the program for one second every cycle to prevent the crawler from failing due to the fast frequency of requesting web pages.
Chapter 5 Lxml library and Xpath syntax
5.1 Lxml library installation and usage
1.Mac system
Before installing Lxml, you need to install Command Line Tools. One installation method is to enter:
xcode-select –install
If the installation is Successful, the word "Successful" will be prompted. If the installation fails, you can also use brew or download dmg for installation. Please Baidu for specific methods.
Then you can install the Lxml library and enter:
pip3 install lxml
This completes the installation of Lxml Library under Mac system.
2.Linux system
The installation of Lxml Library in Linux system is the simplest. Enter:
sudo apt-get install Python 3-lxml
This completes the installation of Lxml Library under Linux system.
Note: the Lxml library installed under Windows 7 has been explained in the previous article.
5.1.2 Lxml library usage
1. Modify HTML code
2. Read HTML file
3. Parsing HTML files
5.2 Xpath syntax
5.2.1 node relationship
1. Parent node
2. Child nodes
3. Sibling node
4. Predecessor node
5. Descendant node
5.2.2 node selection
XPath uses path expressions to select nodes in XML documents. Nodes are selected along the path or step, as shown in the table.

5.2.3 application skills
In the actual combat of the crawler, the Xpath path can pass through
Chrome is copied, as shown in the figure.
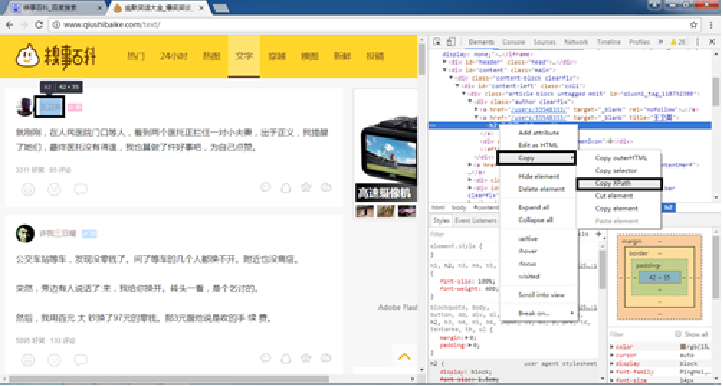
(1) Position the mouse to the data you want to extract, right-click, and select check from the shortcut menu.
(2) Right click the selected element in the web page source code.
(3) Select the Copy Xpath command. Then you can get:
//*[@id="qiushi_tag_118732380"]/div[1]/a[2]/h2
The user id can be obtained through the code:
import requests
from lxml import etree
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'
}
url = 'http://www.qiushibaike.com/text/'
res = requests.get(url,headers=headers)
selector = etree.HTML(res.text)
id = selector.xpath('//*[@id="qiushi_tag_118732380"]/div[1]/a[2]/h2/text()')
print(id)
Note: the text information in the label can be obtained through / text().
The result is:
['Wang Weiying']
5.2.4 performance comparison
As mentioned earlier, the parsing speed of Lxml library is fast, but it is "groundless". In this section, we will compare the performance of regular expression, beautiful soup and Lxml through code.
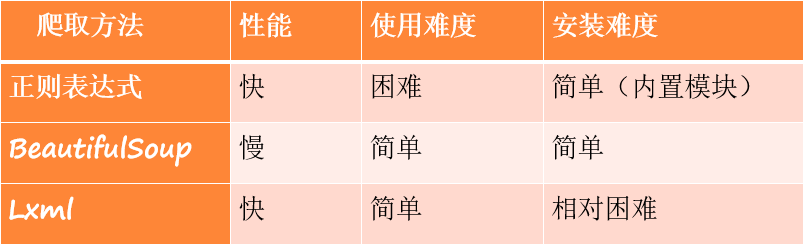
5.3 comprehensive example - crawling watercress
5.3.1 data storage to CSV
The data crawled in the previous article is either printed on the screen or stored in TXT documents. These formats are not conducive to data storage. Think about it. What do readers usually use to store data? Most readers may use Microsoft Excel to store data, and large-scale data use database (which will be explained in detail below). CSV is a common file format for storing tabular data. Excel and many applications support CSV format because it is very concise.
5.3.2 reptile thinking analysis
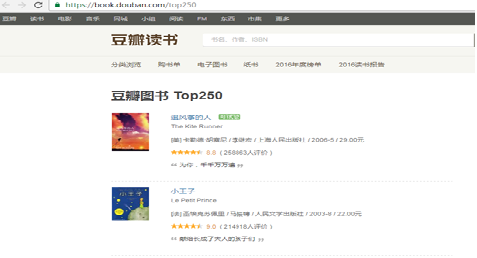
(1) The crawling content is the information of Douban Book Top 250, as shown in the figure.
(2) Climb the top 10 pages of Douban book and browse manually. The following is the website of the first 4 pages:
https://book.douban.com/top250
https://book.douban.com/top250?start=25
https://book.douban.com/top250?start=50
https://book.douban.com/top250?start=75
Then change the URL on page 1 to https://book.douban.com/top250?start=0 It can also browse normally, so just change the number after start = to construct a 10 page web address.
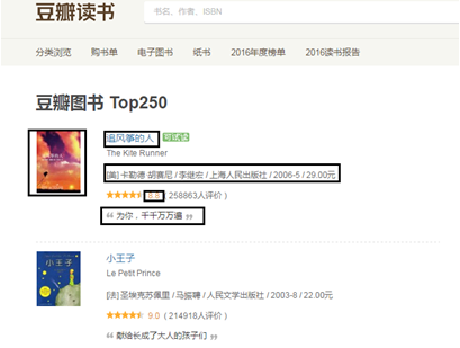
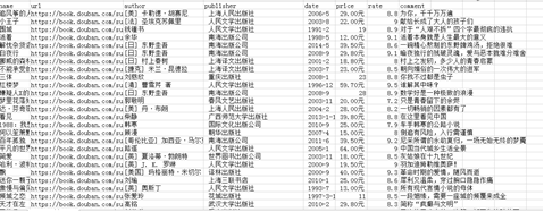
(3) The information to be crawled includes: book title, book URL link, author, publishing house, publishing time, book price, score and evaluation, as shown in the figure.
(4) Use the CSV Library in Python to store the crawled information in the local CSV text.
5.3.3 crawler code and analysis
The code is as follows:
01 01 from lxml import etree
02 02 import requests
03 03 import csv #Import the corresponding library file
04
05 fp = open('C://Users/LP/Desktop/doubanbook.csv','wt',newline='',encoding='utf-8 ') # create csv
06 writer = csv.writer(fp)
07 writer.writerow(('name', 'url', 'author', 'publisher', 'date', 'price', 'rate', 'comment'))#Write header
08
09 urls = ['https://book. douban. com/top250? start={}'. Format (STR (I)) for I in range (0250,25)]# construct urls
10
11 headers = {
12 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like 13 Gecko) Chrome/55.0.2883.87 Safari/537.36'
14 } #Join request header
15
16 for url in urls:
17 html = requests.get(url,headers=headers)
18 selector = etree.HTML(html.text)
19 infos = selector.xpath('//tr[@class="item"]') # Take the large label and cycle
20 for info in infos:
21 name = info.xpath('td/div/a/@title')[0]
22 url = info.xpath('td/div/a/@href')[0]
23 book_infos = info.xpath('td/p/text()')[0]
24 author = book_infos.split('/')[0]
25 publisher = book_infos.split('/')[-3]
26 date = book_infos.split('/')[-2]
27 price = book_infos.split('/')[-1]
28 rate = info.xpath('td/div/span[2]/text()')[0]
29 comments = info.xpath('td/p/span/text()')
30 comment = comments[0] if len(comments) != 0 else "empty"
31 writer.writerow((name,url,author,publisher,date,price,rate,comment)) #Write data
32
33 fp.close() #Close csv file
The running results are saved in the computer in a CSV file named doublanbook. If you open it through Excel, there will be a garbled error, as shown in the figure.

You can open it in Notepad, save it as, modify the code to UTF-8, and there will be no garbled code, as shown in the figure.
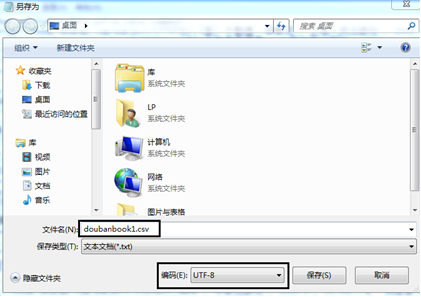
At this time, if you open it through Excel, there will be no garbled code, as shown in the figure.
Code analysis:
(1)
01 01 from lxml import etree 02 02 import requests 03 03 import csv #Import the corresponding library file
The library required by the importer. The Requests library is used to request web pages to obtain web page data. The Lxml library always parses and extracts data. csv libraries are used to store data.
(2)
05 fp = open('C://Users/LP/Desktop/doubanbook.csv','wt',newline='',encoding='utf-8 ') # create csv
06 writer = csv.writer(fp)
07 writer.writerow(('name', 'url', 'author', 'publisher', 'date', 'price', 'rate', 'comment'))#Write header
Create a CSV file and write header information.
(3)
09 urls = ['https://book. douban. com/top250? start={}'. Format (STR (I)) for I in range (0250,25)]# construct urls
Construct all URL links.
(4)
11 headers = {
12 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like 13 Gecko) Chrome/55.0.2883.87 Safari/537.36'
14 } #Join request header
Through the developer tool of Chrome browser, copy the user agent, which is used to disguise as a browser to facilitate the stability of crawlers.
(5)
16 for url in urls:
17 html = requests.get(url,headers=headers)
18 selector = etree.HTML(html.text)
19 infos = selector.xpath('//tr[@class="item"]') # Take the large label and cycle
20 for info in infos:
21 name = info.xpath('td/div/a/@title')[0]
22 url = info.xpath('td/div/a/@href')[0]
23 book_infos = info.xpath('td/p/text()')[0]
24 author = book_infos.split('/')[0]
25 publisher = book_infos.split('/')[-3]
26 date = book_infos.split('/')[-2]
27 price = book_infos.split('/')[-1]
28 rate = info.xpath('td/div/span[2]/text()')[0]
29 comments = info.xpath('td/p/span/text()')
30 comment = comments[0] if len(comments) != 0 else "empty"
31 writer.writerow((name,url,author,publisher,date,price,rate,comment)) #Write data
First, loop the URL, and find the label of each information according to the principle of "grasping the big first and then the small, and looking for the loop point", as shown in the figure.
Then, the details are crawled and finally written to the CSV file.
(6)
33 fp.close() #Close csv file
Close the file.
5.4 comprehensive example - crawling starting point Chinese network novel information
5.4.1 data storage in Excel
Using the third-party library xlwt of Python, you can write data into Excel and install it through pip:
pip3 install xlwt
The execution result is shown in the figure.
The data can be written to Excel through the following code:
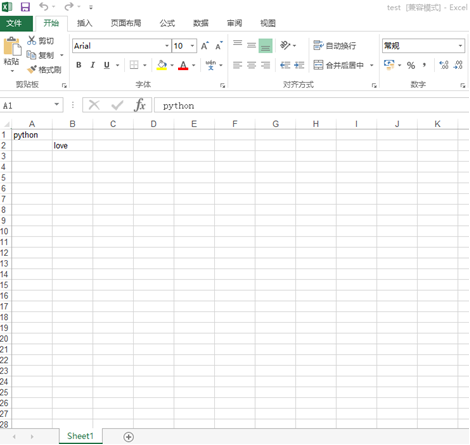
import xlwt #Import library files written to excel
book = xlwt.Workbook(encoding='utf-8') #Create Workbook
sheet = book.add_sheet('Sheet1') #Create worksheet
sheet.write(0,0,'python') #Write data in the corresponding cell
sheet.write(1,1,'love')
book.save('test.xls') #Save to file
After running, you can find the Excel file locally, and the results are shown in the figure.
1) Import xlwt library.
(2) Create a workbook through the Workbook() method.
(3) Create a worksheet named Sheet1.
(4) When writing data, you can see that the first and second parameters are the cell position of Excel table, and the third is the writing content.
(5) Save to file.
5.4.2 reptile thinking analysis
(1) The crawled content is all the work information of the starting point Chinese network( http://a.qidian.com/ ), as shown in the figure.
 (2) Climb the first 100 pages of all works information on the starting point Chinese website and browse manually. The following is the website of the second page:
(2) Climb the first 100 pages of all works information on the starting point Chinese website and browse manually. The following is the website of the second page:
http://a.qidian.com/?size=-1&sign=-1&tag=-1&chanId=-1&subCateId=-1&orderId=&update=-1&page=2&month=-1&style=1&action=-1&vip=-1
I guess these fields are used to control the classification of works. We crawl all works, delete some parameters in turn, check and find that they are changed to http://a.qidian.com/?page=2 , the same information can also be accessed. The rationality is proved by multi page test, so as to construct a 100 page URL.
(3) The information to be crawled includes: novel name, author ID, novel type, completion status, summary and number of words, as shown in Figure 5.27.
4) Use xlwt library to store the crawled information in the local Excel table.
5.4.3 crawler code and analysis
The code is as follows:
01 import xlwt
02 import requests
03 from lxml import etree
04 import time #Import the corresponding library file
05
06 all_info_list = [] #Initialize the list and store the crawler data
07
08 def get_info(url): #Define functions to get crawler information
09 html = requests.get(url)
10 selector = etree.HTML(html.text)
11 infos = selector.xpath('//ul[@class="all-img-list cf"]/li') # Position the large label to cycle
12 for info in infos:
13 title = info.xpath('div[2]/h4/a/text()')[0]
14 author = info.xpath('div[2]/p[1]/a[1]/text()')[0]
15 style_1 = info.xpath('div[2]/p[1]/a[2]/text()')[0]
16 style_2 = info.xpath('div[2]/p[1]/a[3]/text()')[0]
17 style = style_1+'·'+style_2
18 complete = info.xpath('div[2]/p[1]/span/text()')[0]
19 introduce = info.xpath('div[2]/p[2]/text()')[0].strip()
20 word = info.xpath('div[2]/p[3]/span/text()')[0].strip('Ten thousand words')
21 info_list = [title,author,style,complete,introduce,word]
22 all_info_list.append(info_list) #Store data in list
23 time.sleep(1) #Sleep for 1 second
24
25 if __name__ == '__main__': #Program main entrance
26 urls = ['http://a.qidian.com/?page={}'.format(str(i)) for i in range(1,29655)]
27 for url in urls:
28 get_info(url)
29 header = ['title','author','style','complete','introduce','word'] #Define header
30 book = xlwt.Workbook(encoding='utf-8') #Create Workbook
31 sheet = book.add_sheet('Sheet1') #Create payroll
32 for h in range(len(header)):
33 sheet.write(0, h, header[h]) #Write header
34 i = 1
35 for list in all_info_list:
36 j = 0
37 for data in list:
38 sheet.write(i, j, data)
39 j += 1
40 i += 1 #Write crawler data
41 book.save('xiaoshuo.xls') #Save file
After running, save the data into Excel table, as shown in the figure.
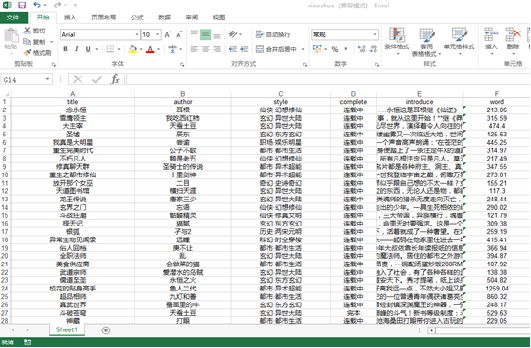
Code analysis:
(1)
01 import xlwt 02 import requests 03 from lxml import etree 04 import time #Import the corresponding library file
Libraries required by the importer,
xlwt is used to write data to
In the Excel file, the requests Library
Used to request web pages. lxml library for
Parse and extract data. time library
The sleep() method allows the program to pause.
(2)
06 all_info_list = [] #Initialize the list and store the crawler data
Define all_info_list list, used to store crawled data.
(3)
08 def get_info(url): #Define functions to get crawler information
09 html = requests.get(url)
10 selector = etree.HTML(html.text)
11 infos = selector.xpath('//ul[@class="all-img-list cf"]/li') # Position the large label to cycle
12 for info in infos:
13 title = info.xpath('div[2]/h4/a/text()')[0]
14 author = info.xpath('div[2]/p[1]/a[1]/text()')[0]
15 style_1 = info.xpath('div[2]/p[1]/a[2]/text()')[0]
16 style_2 = info.xpath('div[2]/p[1]/a[3]/text()')[0]
17 style = style_1+'·'+style_2
18 complete = info.xpath('div[2]/p[1]/span/text()')[0]
19 introduce = info.xpath('div[2]/p[2]/text()')[0].strip()
20 word = info.xpath('div[2]/p[3]/span/text()')[0].strip('Ten thousand words')
21 info_list = [title,author,style,complete,introduce,word]
22 all_info_list.append(info_list) #Store data in list
23 time.sleep(1) #Sleep for 1 second
Define the function to obtain crawler information: it is used to obtain novel information and store the novel information in the form of list in all_info_list.
Note: there are lists in the list, which is stored to facilitate writing to Excel.
(5)
25 if __name__ == '__main__': #Program main entrance
26 urls = ['http://a.qidian.com/?page={}'.format(str(i)) for i in range(1,29655)]
27 for url in urls:
28 get_info(url)
29 header = ['title','author','style','complete','introduce','word'] #Define header
30 book = xlwt.Workbook(encoding='utf-8') #Create Workbook
31 sheet = book.add_sheet('Sheet1') #Create payroll
32 for h in range(len(header)):
33 sheet.write(0, h, header[h]) #Header write
34 i = 1
35 for list in all_info_list:
36 j = 0
37 for data in list:
38 sheet.write(i, j, data)
39 j += 1
40 i += 1 #Write crawler data
41 book.save('xiaoshuo.xls') #Save file
Function main entrance, construct 100 page URL, call the function in turn to obtain novel information, and finally write the information into Excel file.
Chapter 6 using API
6.1 use of API
6.1.1 API overview
Now there are more and more APIs. Some "mature" websites will construct APIs for themselves to provide use for users or developers. For example, you can query routes and locate coordinates through Baidu map API. Query singer information and download lyrics through some music APIs. Real time translation of multiple languages through translation API. You can even spend a little money on APIStore( http://apistore.baidu.com/ )Purchase API services on, as shown in the figure.
6.1.2 API usage
The API uses a very standard set of rules to generate data, and the generated data is organized in a very standard way. Because the rules are very standard, some simple and basic rules are easy to learn and can quickly master the usage of API. However, not all APIs are easy to use, and some API rules are many and complex. It is recommended to carefully read the help document of the API before use.
6.1.3 API verification
Some simple APIs do not require authentication, but most APIs now require users to submit authentication. The purpose of submitting verification is to calculate the cost of API calls. This kind of API is commonly used in paid APIs, such as a weather query API. You need to purchase apikey as verification to call the API
6.2 parsing JSON data
6.2.1 JSON parsing library
Python has a standard library for parsing JSON data, which can be used through the following code:
import json
Unlike other Python parsing libraries, the JSON parsing library does not parse JSON data into JSON objects or JSON nodes, but converts JSON data into dictionaries, JSON arrays into lists, and JSON strings into Python strings. In this way, you can easily operate on JSON data.
6.2.2 spik API call
Readers usually use translation software to translate English. This section teaches readers to create their own translation gadgets by using spik API.
(1) Open APIStore( http://apistore.baidu.com/ ).
(2) Click "more" in the product category, as shown in the figure.
(3) Select "translate" and find the spik API, as shown in the figure below.
(4) After entering, you will be prompted to log in to baidu account. You don't need to log in to the account. Delete it. Select API to read help documents and examples, as shown in the figure below.
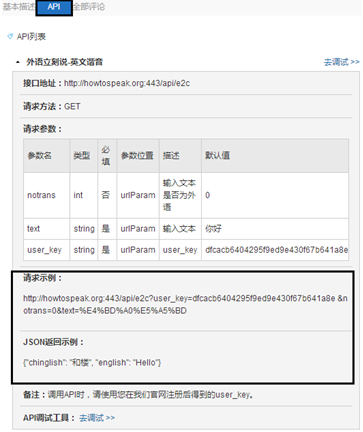
You can translate in real time through the following code:
import requests
import json #Import library
word = input('Please enter Chinese: ') #Input Chinese
url = 'http://howtospeak.org:443/api/e2c?user_key=dfcacb6404295f9ed9e430f67b641a8e ¬rans=0&text={}'.format(word)
res = requests.get(url)
json_data = json.loads(res.text)
english_word = json_data['english']
print(english_word) #Parsing and extracting English words
After running the program, the reader can input the Chinese sentence to be translated and press Enter to output the English translation, as shown in the figure.

6.2.3 Baidu map API call
Geographic location information is an interesting part of crawler's actual combat. In this section, the location name will be converted into latitude and longitude through Baidu map API. Baidu map API can be called through the following code.
import requests
address = input('Please enter location:')
par = {'address': address, 'key': 'cb649a25c1f81c1451adbeca73623251'} #get request parameters
url = 'http://restapi.amap.com/v3/geocode/geo'
res = requests.get(url, par)
print(res.text)
After running the program, Enter the location name and press Enter to return the results, as shown in the figure.

6.3 comprehensive example - crawling Pexels pictures
6.3.1 image crawling method
There are generally two methods for image crawling:
(1) The first is through urllib The URLretrieve module in request is used as follows:
urlretrieve(url,path)
URL is the picture link, and path is the local address where the picture is downloaded.
(2) However, sometimes the first method will report an error when crawling the picture, so the second method must be used, that is, to request the picture link and then store it in the file.
6.3.2 reptile thinking analysis
(1) Climb Pexels( https://www.pexels.com/ )The website provides a large number of shared picture materials. The picture quality is very high, and because of sharing, it can be used for personal and commercial purposes free of charge, as shown in the figure.

(2) Since the website is a foreign language website, you need to enter English. By manually entering several keywords, you can find that the changes of the website are as follows:
https://www.pexels.com/search/book/
https://www.pexels.com/search/office/
https://www.pexels.com/search/basketball/
Use this rule to construct URL s.
(3) Convert Chinese to English through spik API. In this way, the URL can be constructed by entering Chinese.
(4) Use the second method of crawling pictures in Python to download pictures.
Chapter 7 database storage
7.1 MongoDB database
7.1.1 NoSQL overview
NoSQL generally refers to non relational databases. With the development of internet web2 0 website, the traditional relational database is dealing with web2 0 websites, especially super large-scale and highly concurrent SNS type web2 0 pure dynamic website has been unable to meet its needs, exposing many insurmountable problems, while non relational database has developed very rapidly due to its own characteristics. The generation of NoSQL database is to solve the challenges brought by large-scale data sets and multiple data types, especially the problems of big data application. NoSQL database has four categories: key value storage database (such as Redis), column storage database (such as Hbase), document database (such as MongoDB) and graphic database (such as Graph).
7.1.2 MongoDB installation
1.MongoDB database installation
2.Pymongo third party library installation
3. Installation of mongodb visual management tool Robomongo
7.1.3 use of mongodb
This book focuses on the actual combat of crawlers and will not explain too much database operation knowledge. Readers can learn by themselves. This section mainly explains how to use Pymongo third-party library to create databases and collections in Python environment and insert the data obtained by crawlers. Finally, it explains how to export collections as CSV files.
Beginners may not understand the concepts of database and set. Database and set are very similar to Excel files and tables in them. An excel file can have multiple tables and a database can also have multiple sets.
7.2 MySQL database
7.2.1 overview of relational database
Relational database is a database based on relational model. It processes the data in the database with the help of mathematical concepts and methods such as set algebra. Various entities in the real world and various relationships between entities are represented by relational model. That is, data attributes are associated with other data.
7.2.2 MySQL installation
1.MySQL database installation
2.Pymysql third party library installation
3.MySQL visual management tool SQLyog installation
7.2.3 MySQL usage
Open the command line window under the bin folder of MySQL installation path, and enter the following command to establish the database:
create database mydb;
Enter the mydb database through "use mydb" and create a data table through the following command:
CREATE TABLE students ( name char(5), sex char(1), grade int )ENGINE INNODB DEFAULT CHARSET=utf8 ;#Create data table
You can also create databases and data tables in SQLyog, and view the newly created databases and data tables in SQLyog
250 music climbing - Top 3.7
7.3.1 reptile thinking analysis
(1) The crawling content is the information of Douban music top250, as shown in the figure.
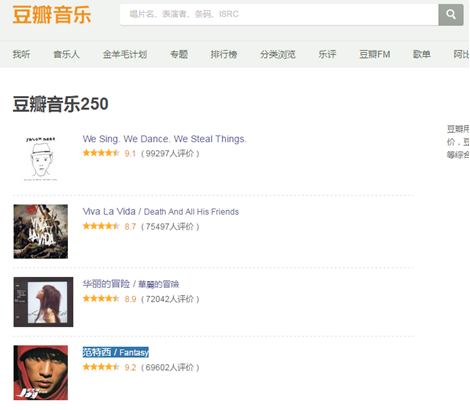
(2) Climb the top 10 pages of Douban book and browse manually. The following is the website of the first 4 pages:
https://music.douban.com/top250
https://music.douban.com/top250?start=25
https://music.douban.com/top250?start=50
https://music.douban.com/top250?start=75
Then change the URL on the first page to https://music.douban.com/top250?start=0 It can also browse normally, so just change the number after start = to construct a 10 page web address.
(3) Because the information on the detail page is more abundant, this crawler is carried out in the detail page, so you need to crawl the URL link into the detail page first, and then crawl the data.
(4) The information to be crawled includes: song name, performer, genre, release time, publisher and score, as shown in the figure below.
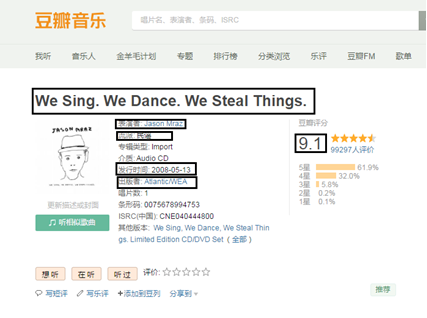
(5) The pymongo Library in Python is used to store the crawled information in the MongoDB database.
Chapter 8 multi process crawler
8.1 multithreading and multiprocessing
8.1.1 overview of multithreading and multiprocessing
When a computer runs a program, it creates a process that contains code and status. These processes are executed by one or more CPUs of the computer. However, each CPU will execute only one process at the same time, and then quickly switch between different processes, which gives people the feeling that multiple programs are running at the same time. Similarly, in a process, the execution of the program is also switched between different threads, and each thread executes different parts of the program.
8.1.2 multi process usage
Python uses the multiprocessing library for multiprocessing crawler. This book uses the process pool method of the multiprocessing library for multiprocessing crawler. The usage method is as follows:
01 from multiprocessing import Pool 02 pool = Pool(processes=4) #Create process pool 03 pool.map(func,iterable[,chunksize])
(1) The first line is used to import the Pool module of the multiprocessing library.
(2) The second line is used to create a process pool. The processes parameter is set to the number of processes.
(3) The third line uses the map() function to run the process. The func parameter is the function to be run. In the actual battle of the crawler, it is the crawler function. iterable is an iteration parameter. In actual crawler combat, it can iterate for multiple URL lists.
8.1.3 performance comparison
The speed of multi process crawler is much better than that of serial crawler, but "words are useless". This section will compare the performance of serial crawler and multi process crawler through code.
8.2 comprehensive example - Hot review articles of climbing simple books
8.2.1 reptile thinking analysis
(1) The content crawled is the information of the hot review article of the "home page contribution" of the simple book( http://www.jianshu.com/c/bDHhpK ), as shown in the figure.
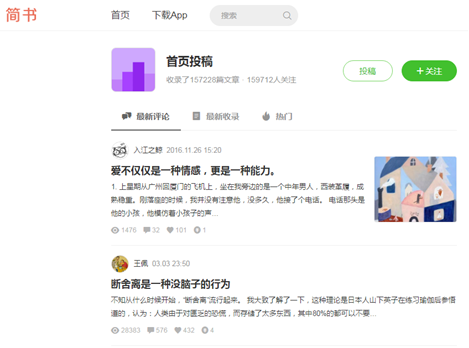
(2) When you manually browse the web page, you will find that there is no paging interface, but you can browse all the time, which indicates that the web page uses asynchronous loading.
Open the developer tool of Chrome browser (press F12) and click the Network tab, as shown in the figure.
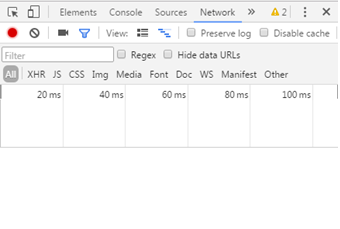
When you manually slide down the mouse to browse the web page, you will find that some files will be loaded in the Network tab, as shown in the figure.
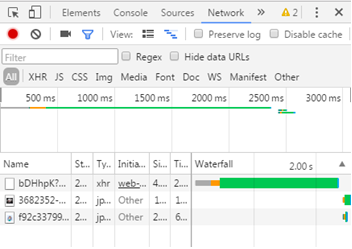
Open the first loading file, and you can see the requested URL in the Headers section
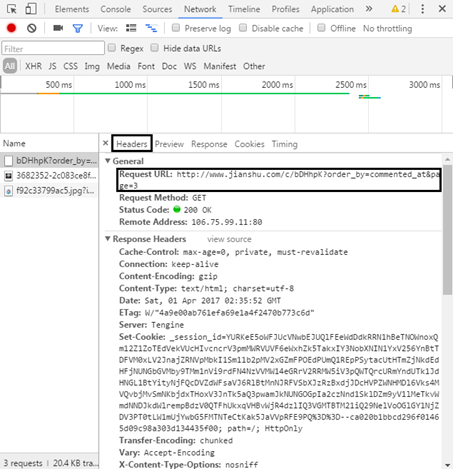
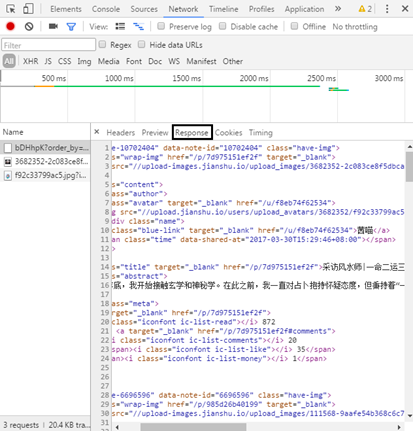
In the Response section, you can see that the returned content is the article information
By paying attention, you only need to modify the numbers behind the page to return different pages, so as to construct the URL. A total of 10000 URLs are crawled this time.
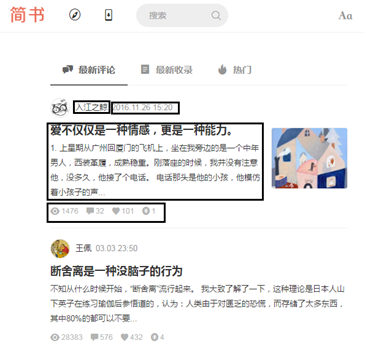
(3) The information to be crawled includes: user ID, Article Publication date, article title, article content, page views, comments, likes and rewards, as shown in the figure.
(4) The multi process crawler method and pymongo Library in Python are used for multi process crawler, and the crawled information is stored in the MongoDB database.
8.3 comprehensive example - crawling transfer network second-hand market
8.3.1 reptile thinking analysis
(1) The crawling content is all the commodity information of the second-hand market of zhuanzhuan.com. Here, you must first crawl the URL of each category.
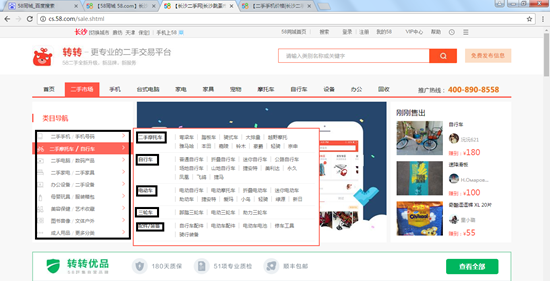
(2) During large-scale data crawling, we need to carefully observe the page structure. Through observation, the second-hand mobile phone number structure is different from that of other commodity pages, so we want to eliminate its URL.
(3) The paging URL is constructed through the method in the previous article, but the number of pages in each category is different. Here, 100 pages are artificially set. If the web page has no data, it can be skipped and not grabbed through the program method.
(4) Crawl data on the commodity details page. The information to be crawled includes: commodity information, commodity price, region, browsing volume and quantity of commodities to be purchased.
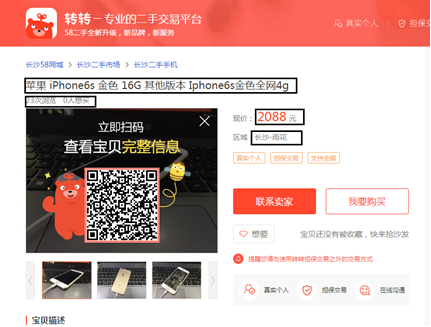
(5) The multi process crawler method and pymongo Library in Python are used for multi process crawler, and the crawled information is stored in the MongoDB database.
Chapter 9 asynchronous loading
9.1 asynchronous loading technology and crawler method
9.1.1 overview of asynchronous loading technology
Asynchronous loading technology (AJAX), namely asynchronous JavaScript and XML, is a web development technology to create interactive web applications. AJAX can make web pages update asynchronously by exchanging a small amount of data with the server in the background. This means that a part of a web page can be updated without reloading the whole web page.
9.1.2 example of asynchronously loading web pages
The information of the hot review article of the "home page submission" of the brief book introduced in the previous article is browsed through the slide, there is no pagination information, but has been browsed all the time, and the website information has not changed. Traditional web pages cannot load such huge information at one time. Through analysis, it can be judged that the web page uses asynchronous loading technology.
Readers can also judge whether the web page adopts asynchronous loading technology by checking whether the data is in the web page source code. As shown in the figure, the article information of the sliding simple book is not in the web page source code, so as to judge whether asynchronous loading technology is used.
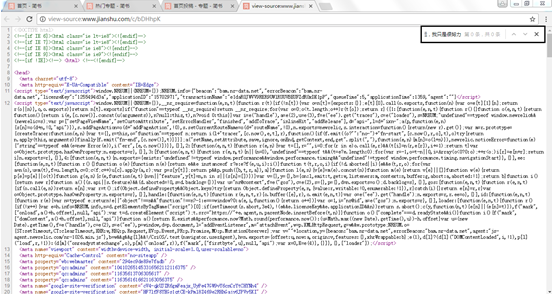
9.1.3 reverse engineering
Using asynchronous loading technology, it is no longer to load all web content immediately, and the displayed content is not in the HTML source code. In this way, the data cannot be captured correctly through the method in the previous article. If you want to grab the web page data through the asynchronous loading method, you need to understand how the web page loads the data. This process is called reverse engineering. The Network tab of Chrome browser can view all file information in the process of web page loading. By viewing and filtering these files, find the loading files that need to grab data, so as to design crawler code.
9.2 comprehensive example - crawling user dynamic information of simplified books
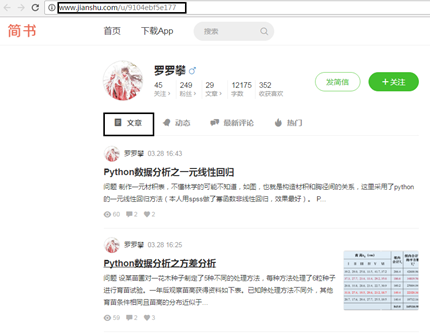
9.2.1 reptile thinking analysis
(1) The content of crawling is the dynamic information of the user( http://www.jianshu.com/u/9104ebf5e177 ).
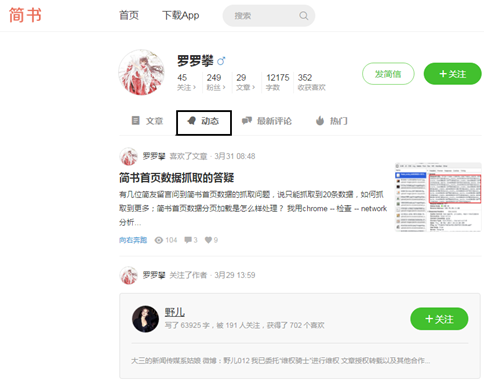
(2) When you open the web page URL for the first time and select dynamic, you will find that the web page URL has not changed, as shown in the figure below. It is judged that the web page adopts asynchronous loading technology.
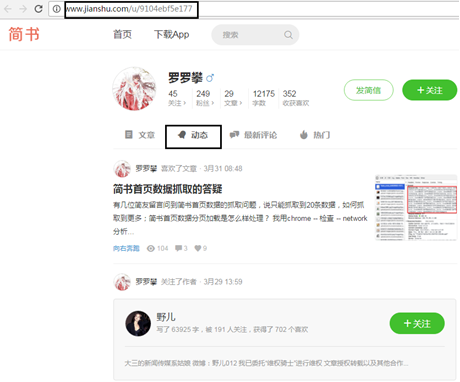
(3) Open the developer tool of Chrome browser (press F12), click the Network tab, select the XHR item, and you can find the file with the user's "dynamic" content loaded on the web page, as shown in the figure.
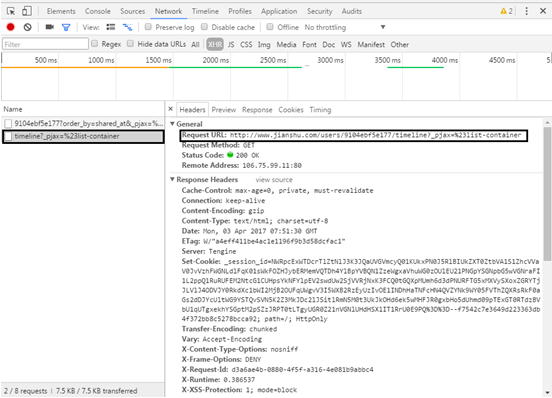
(4) Observe the Response of the file and find that the returned XML file is the user's "dynamic" content (as shown in the figure). Each li tag is a user's dynamic content. Deleting the string after the timeline can also return the correct content, so as to construct the URL of the first page as http://www.jianshu.com/users/9104ebf5e177/timeline .
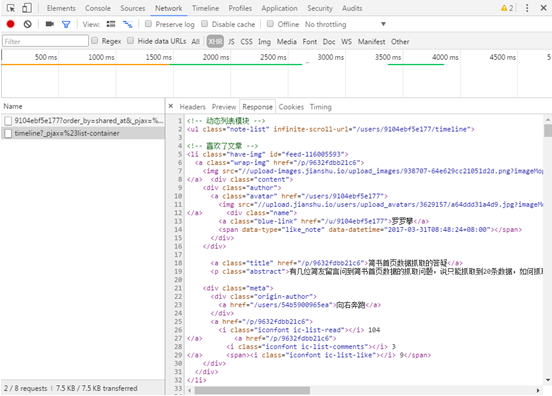
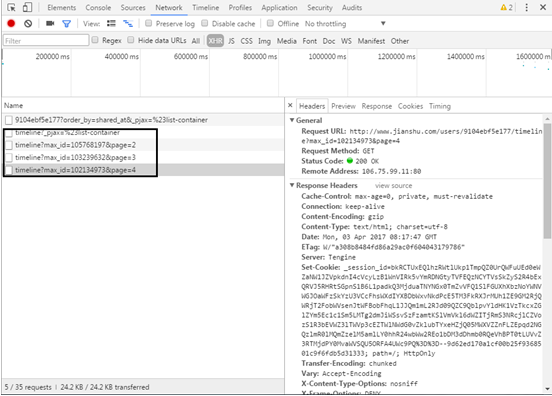
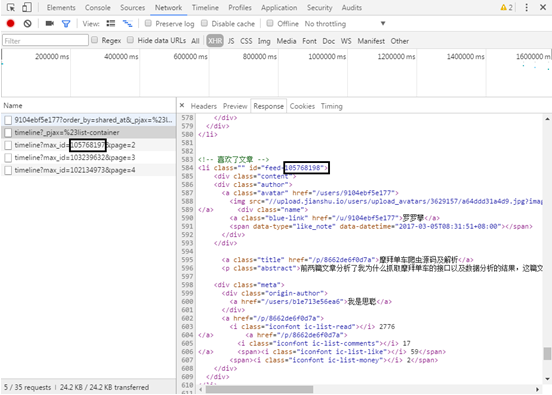
(5) Through browsing, you will find that asynchronous loading technology is also used for paging processing, as shown in Figure 9.16, so as to record the URL s of the previous pages:
http://www.jianshu.com/users/9104ebf5e177/timeline?max_id=105768197&page=2
http://www.jianshu.com/users/9104ebf5e177/timeline?max_id=103239632&page=3
http://www.jianshu.com/users/9104ebf5e177/timeline?max_id=102134973&page=4
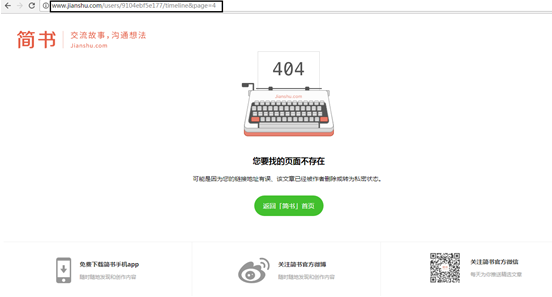
(6) Manually delete Max in URL_ ID, it is found that the normal content cannot be returned, as shown in the figure, indicating max_id is a key field, and the author found that the max of each page_ IDs are different, and there is no obvious law by observing numbers, and the focus of constructing URL is how to obtain max_id number.
(7) According to the above analysis, each li tag is a dynamic content of the user. The author found that the id field of li tag has a string of irregular digital information.
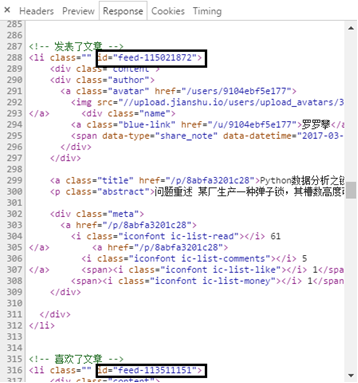
Through observation, it is found that the id number in the last li tag of the previous page is just the max in the URL of the next page_ Add 1 to the id number to construct the paging URL.
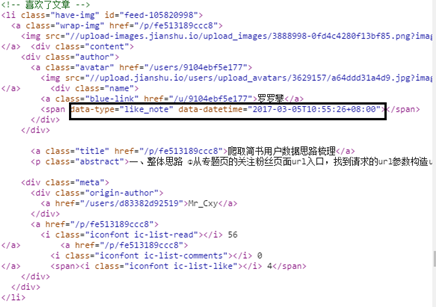
(8) Since the Response returns an XML document, you can grab the data through the lxml library. The content to be crawled is the user's "dynamic" type and time information, as shown in the figure.
(9) Finally, the crawled information is stored in the MongoDB database.
9.3 comprehensive example (II) -- seven popular days of climbing and taking simple books
9.3.1 reptile thought analysis
(1) The content of crawling is the popular information of the 7th day of Jianshu( http://www.jianshu.com/trending/weekly )
(2) The web page also uses AJAX technology to realize paging. Open the developer tool of Chrome browser (press F12), click the Network tab, select the XHR item, and you can find the page turning web file.
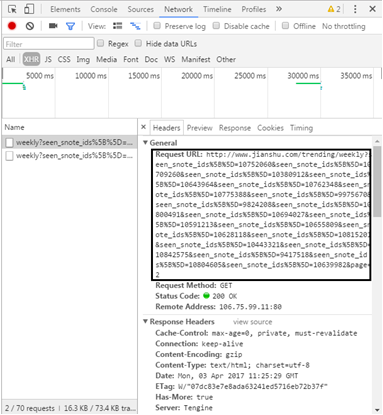
(3) Manually delete the string in the middle of the URL and find http://www.jianshu.com/trending/weekly?page= You can return the correct content and find that there is no information from page 7 to page 11, so as to construct all URLs.
(4) This crawler is carried out in the details page, so you need to crawl the URL link entering the details page first, and then crawl the data.
(5) The information to be crawled includes: author ID, article name, release date, number of words, reading, comments, likes, number of appreciation, and included topics.

(6) By judging whether the elements are in the web page source code to identify the asynchronous loading technology, it is found that the asynchronous loading technology is used in the number of reading, comments, likes, appreciation and included topics.
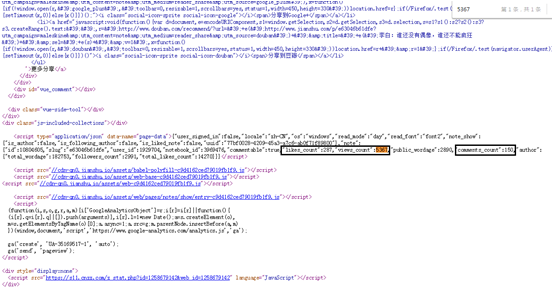
(7) Reading, commenting and liking although asynchronous loading technology is adopted, its content is
(8) Open the developer tool of Chrome browser (press F12), click the Network tab, select the XHR item, and you can find the file information of rewards and included topics.
(9) The URL of the reward request contains a string of digital information and cannot be deleted
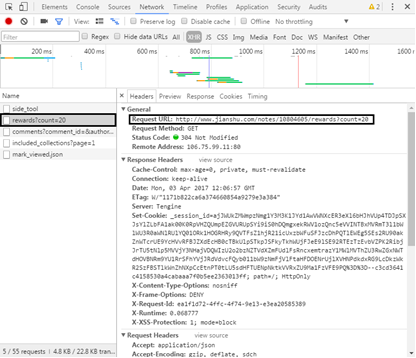
But I found this string of numbers in the web page source code

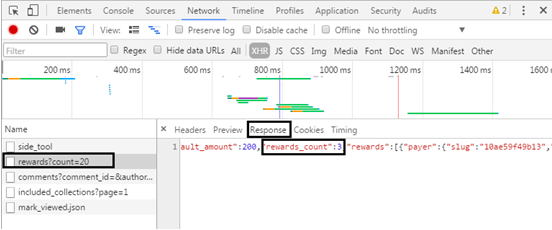
The URL can be constructed by obtaining the digital information in the web page source code. The URL returns JSON data, which can be obtained through the JSON library.
(10) In the same way, find the document containing the topic
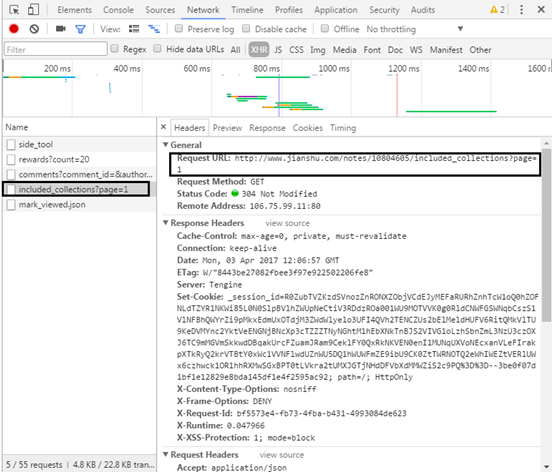
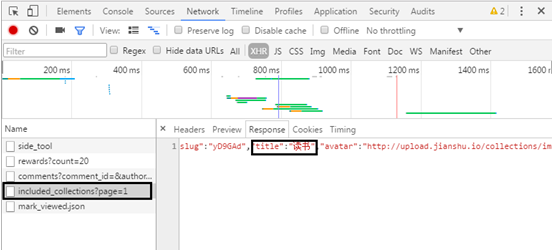
The URL also returns JSON data.
(11) Finally, the crawled information is stored in the MongoDB database.
Chapter 10 form interaction and simulated Login
10.1 form interaction
10.1.1 POST method
The POST method of the Requests library is simple to use. It only needs to simply pass the data of a dictionary structure to the data parameter. In this way, when the request is initiated, it will be automatically encoded into form form to complete the form filling.
import requests
params = {
'key1':'value1',
'key2':'value2',
'key3':'value3'
}
html = requests.post(url,data=params) #post method
print(html.text)
10.1.2 view web page source code submission form
Douban net( https://www.douban.com/ )For example, form interaction.
(1) Open douban.com, locate the login location, use Chrome browser to "check" and find the location of the login element.
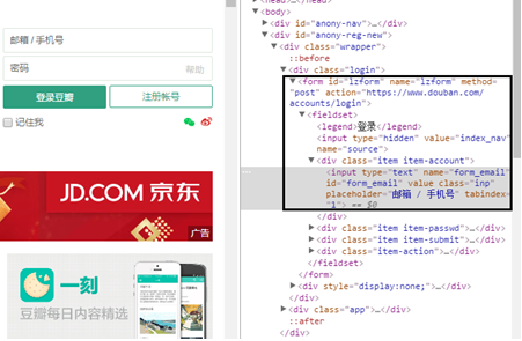
(2) According to step 1, find the source code information of the form in the web page source code.
 (3) For the form source code, there are several important components. They are the action attribute of the form tag and the input tag. The action property is the URL of the form submission. Input is the field submitted by the form, and the name attribute of the input tag is the field name of the submitted form.
(3) For the form source code, there are several important components. They are the action attribute of the form tag and the input tag. The action property is the URL of the form submission. Input is the field submitted by the form, and the name attribute of the input tag is the field name of the submitted form.
(4) According to the form source code, you can construct a form to log in to the web page:
import requests
url = 'https://www.douban.com/accounts/login'
params = {
'source':'index_nav',
'form_email':'xxxx',
'form_password':'xxxx'
}
html = requests.post(url,params)
print(html.text)
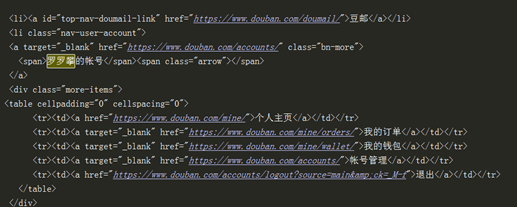
(5) By comparing the unlisted and logged in Douban pages.
It can be seen that the author's account name is in the upper right corner after login. Check whether there is this information through the web page source code printed by the code to determine whether Douban has been logged in, as shown in the figure below, indicating that the login is successful.
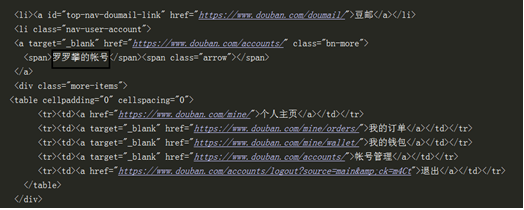
10.1.3 reverse engineering submission form
For beginners, observing the web page source code of the form may be a headache, insensitive to the input tag, and may miss some fields submitted by the form. This section views the form interaction through the Network tab in the developer tool of Chrome browser, so as to construct the field information of the submitted form
10.2 simulated Login
10.2.1 cookie overview
Cookie refers to the data stored on the user's local terminal by some websites in order to identify the user's identity and carry out session tracking. Internet shopping companies provide users with products of interest by tracking users' cookie information. Similarly, because cookies store the user's information, we can simulate login to the website by submitting cookies.
10.2.2 submitting cookie s to simulate login
Similarly, take douban.com as an example to find cookie information and submit it to simulate logging in to douban.com.
(1) Enter douban.com, open the developer tool of Chrome browser, and click the Network option.
(2) Manually enter the account and password to log in, and you will find that many files will be loaded in the Network.
(3) At this time, you do not need to view the file information of the login web page, but directly view the file information after login, and you can see the corresponding cookie information.
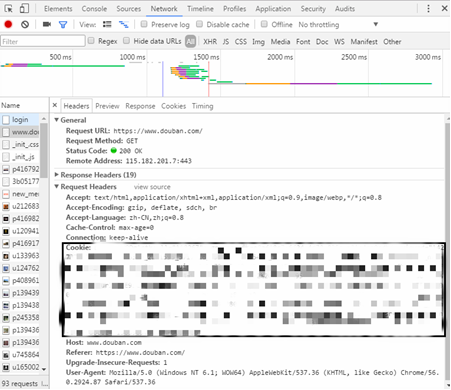 (4) The simulated Login of douban.com can be completed by adding cookie information in the request header:
(4) The simulated Login of douban.com can be completed by adding cookie information in the request header:
import requests
url = 'https://www.douban.com/'
headers = {
'Cookie':'xxxxxxxxxxxxxx'
}
html = requests.get(url,headers=headers)
print(html.text)
(5) Check whether the login is successful through the above method. As shown in the figure, the simulated Login is successful.
10.3 comprehensive example (I) -- crawling to pull hook Recruitment Information
10.3.1 reptile thought analysis
(1) The content of crawling is to pull the hook net( https://www.lagou.com/ )Recruitment information on Python.
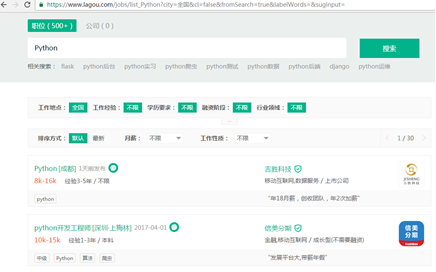
(2) Through observation, the web page element is not in the web page source code, indicating that the web page uses AJAX technology
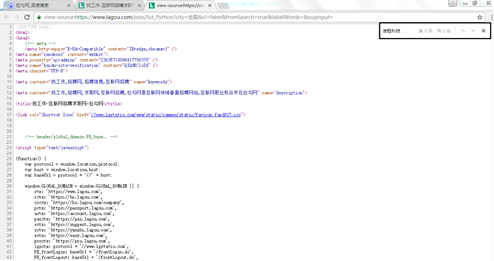
(3) Open the developer tool of Chrome browser (press F12), click the Network tab, select the XHR item, and you can see the file loading recruitment information. You can see the requested URL in Headers.
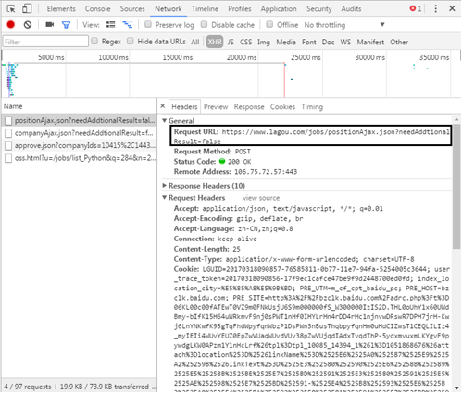
The "? Of the web address The following string can be omitted. The returned information can be seen in the Response), and the information is in JSON format.
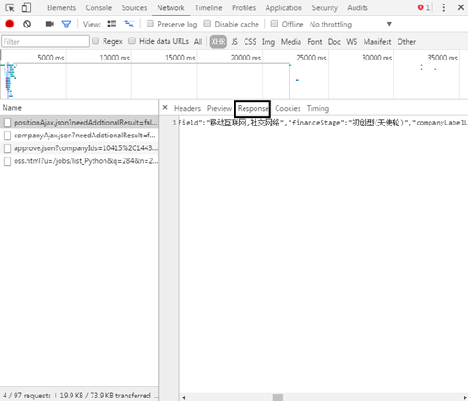
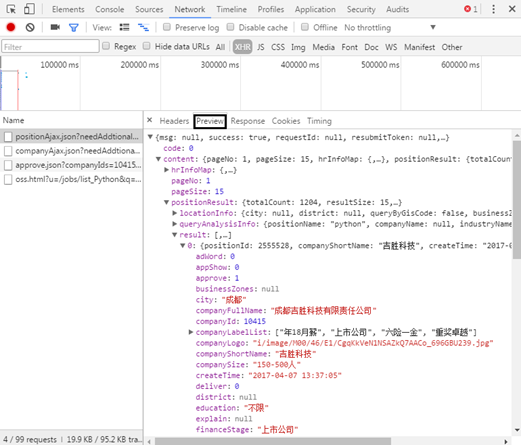
(4) When the JSON format is very complex, you can observe it through the "Preview" tag, as shown in the figure. It is found that the recruitment information is in the content positionresult result, and most of the information in it is the crawler's content.
(5) When turning the page manually, it is found that the web page URL has not changed, so AJAX technology is also adopted. Open the developer tool of Chrome browser (press F12), click the Network tab, select the XHR item, and turn the page manually. You can find the page turning web file, but the requested URL has not changed.
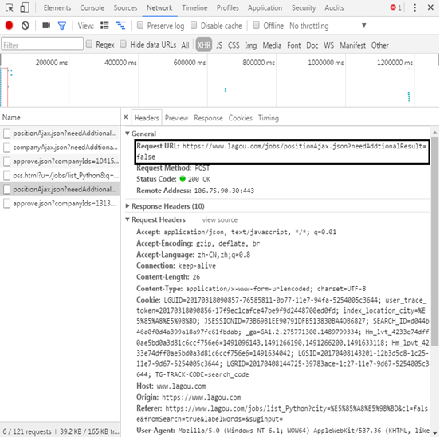
Through careful observation, it is requested that the web page be the POST method, and the submitted form data changes the number of pages according to the "pn" field.
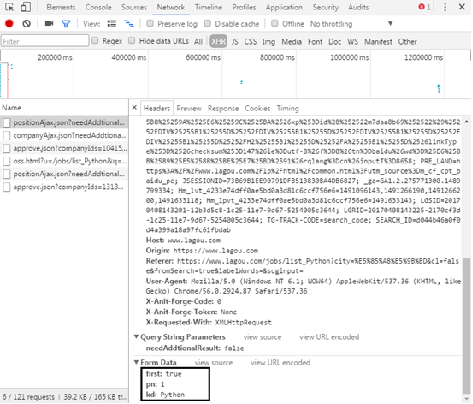
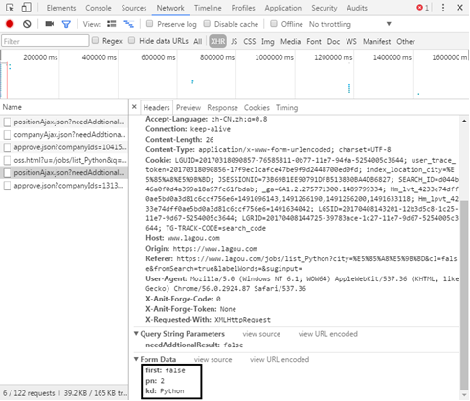
(6) The total quantity of recruitment information can be found in the returned JSON data.
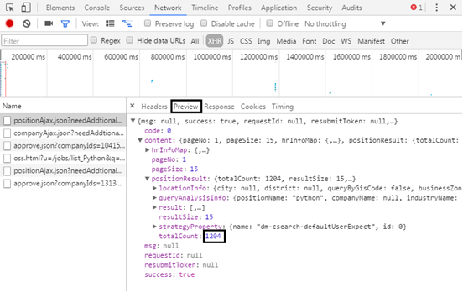
Each page contains 15 recruitment information. The pull hook network has only 30 pages of information by default. By capturing the total number of recruitment information, divide by 15. If it is less than 30 pages, the calculation result will be taken as the total number of pages. If it is greater than 30, take 30 pages. Finally, the data is stored in the MongoDB database.
10.4 comprehensive example - crawling Sina Weibo circle of friends information
10.4.1 word cloud production
1. Personal BDP
As mentioned earlier, personal BDP is an online data visualization analysis tool, and learned to make maps. This time, we will use personal BDP to make word cloud.
2.jieba word segmentation and TAGUL online word cloud tool
Make word cloud with personal BDP, and make keyword and word cloud at one go. This section will use the Python third-party library jieba to extract the keywords of the text, and then use the TAGUL online word cloud tool to make the word cloud.
10.4.2 reptile thinking analysis
(2) After logging in through Sina Weibo web version, open the developer tool of Chrome browser (press F12), select the tool in the shape of mobile phone in the upper left corner, refresh the web page, and then convert it to Sina Weibo on the mobile terminal.
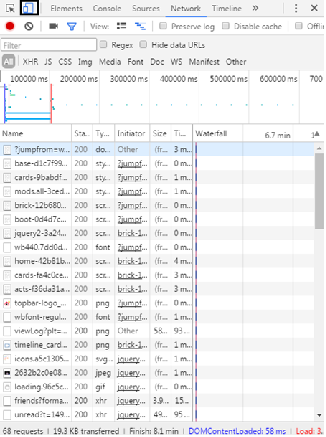
(3) Through observation, the web page element is not in the web page source code, indicating that the web page uses AJAX technology.

(4) Open the developer tool of Chrome browser (press F12), click the Network tab, select the XHR item, and you can see the file that loads the circle of friends information. You can see the requested URL in Headers.
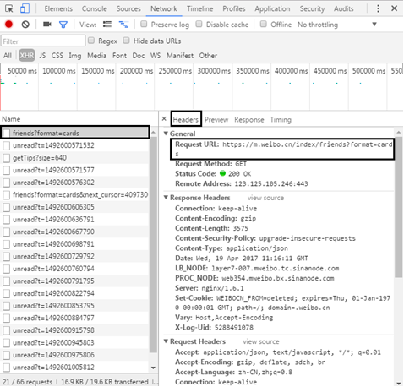
In Response, you can see the returned information in JSON format.
(5) You can find the URL of the next page through the manual drop-down.
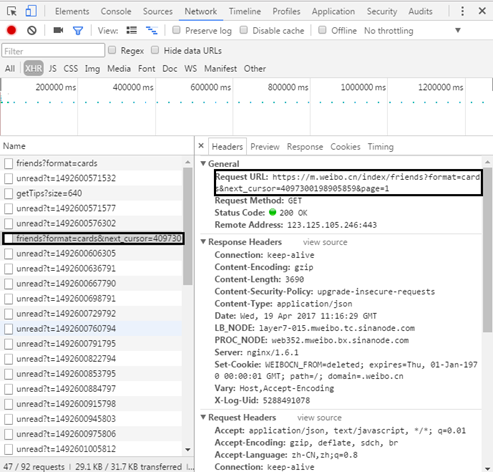
Next in URL_ In the cursor field, by observing the Preview tag in the URL of the first page, the returned JSON data happens to have next_cursor, exactly the same as the number in the URL of this page.
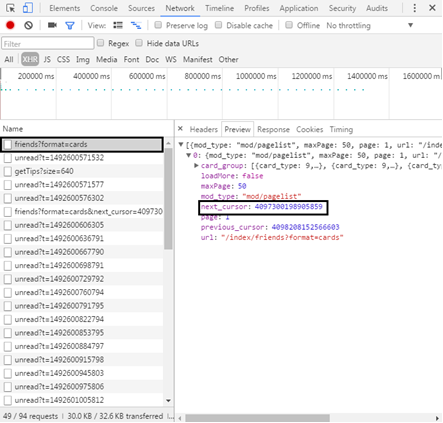
After multiple verification and confirmation, the URL of the next page can be constructed in this order.
(6) By submitting cookie information, simulate login to Sina Weibo and copy cookie information.
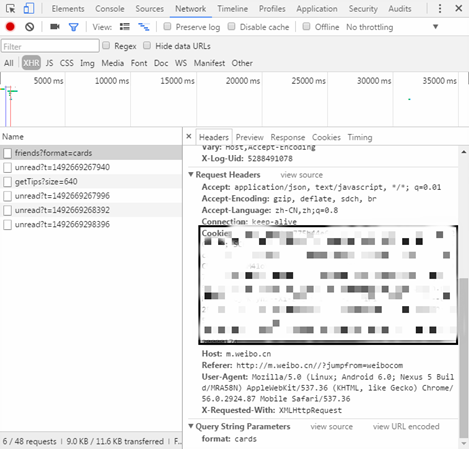 (7) Crawl the microblog information on 50 pages of the circle of friends, save it to the TXT document, and finally make the word cloud through word segmentation.
(7) Crawl the microblog information on 50 pages of the circle of friends, save it to the TXT document, and finally make the word cloud through word segmentation.
Chapter 11 Selenium simulation browser
11.1 Selenium&PhantomJS
11.1.1 Selenium concept and installation
Selenium is a tool for Web application testing. Selenium runs directly in the browser, just like a real user. Due to this nature, selenium is also a powerful network data collection tool, which allows the browser to automatically load pages. In this way, Web pages using asynchronous loading technology can also obtain the data they need.
Selenium module is a third-party library of Python, which can be installed through pip:
pip3 install selenium
11.1.2 browser selection and installation
Selenium does not have a browser and needs to be used with a third-party browser. The Webdriver commands supported by Webdriver are:
from selenium import webdriver help(webdriver)
View the results after execution, as shown in the figure.
11.2 use of selenium & phantom JS
11.2.1 simulate browser operation
The combination of Selenium and phantom JS can fully simulate all operations of the user on the browser, including filling in the content of the input box, clicking, screenshot, sliding and other operations. In this way, users can log in to the website without constructing a form or submitting cookie information
11.2.2 obtaining asynchronous loading data
Driver mentioned above The web page source code requested by the get () method contains information loaded asynchronously, so that Javascript data can be easily obtained.
11.3 comprehensive example (I) -- crawling QQ space
11.3.1 CSV file reading
In the previous article, I explained how to use the Python third-party library CSV to store data into CSV files. CSV library can not only store CSV data, but also read CSV files.
The CSV file can be read by the following code:
import csv
fp = open('C:/Users/LP/Desktop/doubanbook.csv',encoding='utf-8')
reader = csv.reader(fp)
for row in reader:
print(row)
fp.close()
11.3.2 reptile thinking analysis
(1) Get QQ friend number from QQ mailbox. Open QQ mailbox and select address book
Select some QQ friends, select "tools" | "export contacts"
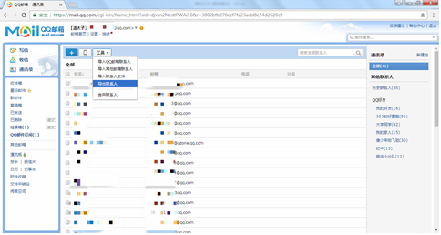
Export as a CSV file, so that you can read the CSV file through the CSV library and take out your friend's QQ number.
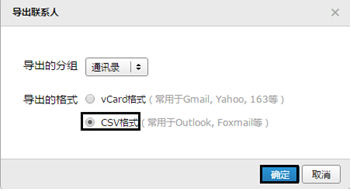
(2) The links mentioned by friends in QQ space are: http://user.qzone.qq.com/ {friend QQ number} / 311. When opening QQ space for the first time, you need to log in. As shown in the figure, use Selenium and phantom JS and select an account and password to log in.

(3) Crawl content for friends to talk about and publish time.
(4) Store the crawl data in the MongoDB database.
Chapter 12 Scrapy crawler framework
12.1 Scrapy installation and use
12.1.1 Scrapy installation
Since the Scrapy crawler framework relies on many third-party libraries, make sure that the following third-party libraries are installed before installing Scrapy.
1.lxml Library
2.zope.interface library
3.twisted Library
4. Opensll Library
5.pywin32 Library
6.Scrapy Library
12.1.2 creating a Scrapy project
Take the one page rental information of pig short rent as an example, as shown in the figure. Write the Scrapy crawler code.
12.1.3 introduction to scrapy documents
1.items.py
items. The PY file is used to define the items crawled by the crawler. In short, it is to define the field information crawled.
2.pipelines.py
pipelines.py file is mainly used to process crawler data. In actual crawler projects, it is mainly used to clean and store crawler data.
3.settings.py
settings.py file is mainly used to set crawler items, such as filling in request headers and setting pipelines Py process crawler data, etc.
12.1.4 scripy crawler compilation
1.items.py
2.xiaozhuspider.py
3.pipelines.py
4.settings.py
12.1.5 Scrapy crawler operation
The operation of the Scrapy crawler framework also requires the use of a command-line window. Go back to the xiaozhu folder and enter the following command to run the crawler. The running results are shown in the figure.
scrapy crawl xiaozhu
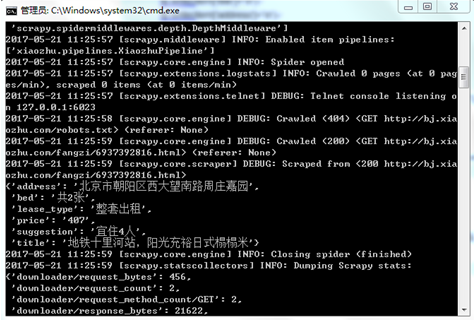
12.2 comprehensive example - crawling for popular topic information in short books
12.2.1 reptile thought analysis
(1) The content crawled is the information of popular topics in simple books( http://www.jianshu.com/recommendations/collections?order_by=hot ), as shown in the figure
(2) When you enter a popular topic for the first time, you enter "recommended". When you switch to "popular", the web page URL does not change, which indicates that the web page uses asynchronous loading.
Open the developer tool of Chrome browser (press F12) and click the Network tab.
Refresh the web page, jump to "recommended", manually click "popular", select XHR, and you will find that a file will be loaded in the Network tab.
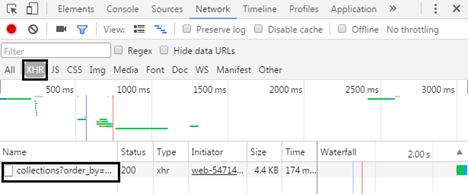
Open the loading file, and you can see the URL of the popular topic in the Headers section.
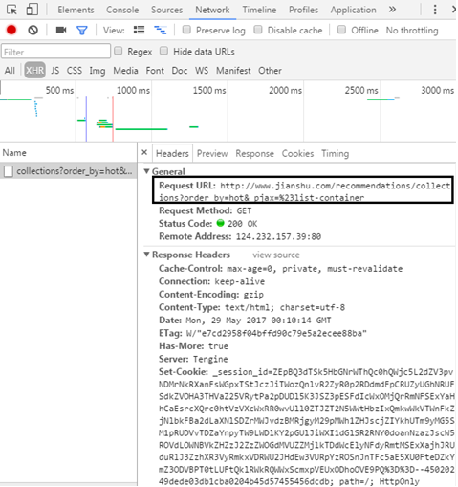
In the Response section, you can see that the returned content is the letter of the hot topic.
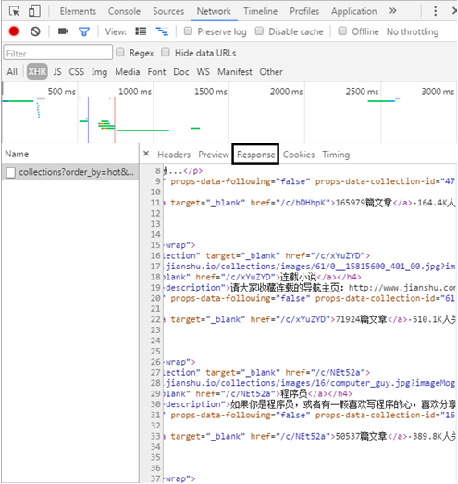
(3) Asynchronous loading technology is also adopted for the popular topics page of simple books. Open the developer tool, manually slide and turn the page to check the URL change. It can be seen that the page is turned by changing the number after the page, and the URL of the first page is changed to http://www.jianshu.com/recommendations/collections?page=1&order_by=hot , you can also access it normally. Finally, observe that there are 38 pages to construct all URLs.
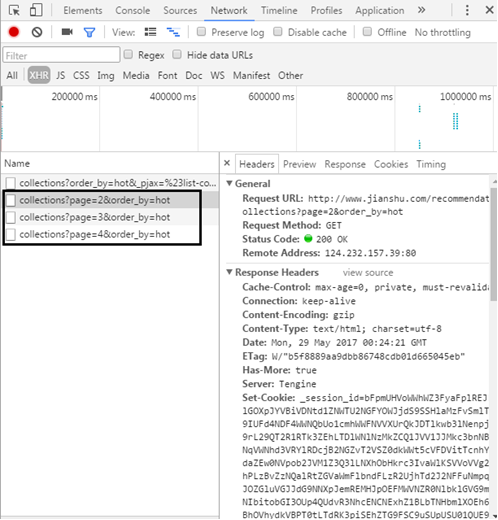
(4) The information to be crawled includes: topic name, introduction, articles included and number of people concerned.
(5) The crawler is crawled by using the scrape framework, and the crawler information is stored in the CSV file through the Feed exports function.
12.3 a comprehensive example -- crawling to know the essence of Python topic
12.3.1 reptile thought analysis
(1) the content of crawling is information that knows the essence of Python topic. https://www.zhihu.com/topic/19552832/top-answers?page=1 ).
(2) Crawl 50 pages of information and browse manually. The following is the website of the first 4 pages:
https://www.zhihu.com/topic/19552832/top-answers?page=1
https://www.zhihu.com/topic/19552832/top-answers?page=2
https://www.zhihu.com/topic/19552832/top-answers?page=3
https://www.zhihu.com/topic/19552832/top-answers?page=4
By observing the law, it is easy to construct all URL s
(3) The information to be crawled includes Python questions, likes, users who answer questions, user information and answer content.
(4) Crawling is carried out by using the Scrapy frame through pipeline Py stores the data in the MongoDB database.
12.4 comprehensive example - articles included in the special topics of crawling simplified books
12.4.1 reptile thought analysis
(1) The content of crawling is the collected article information of the IT Internet topic in the brief book( http://www.jianshu.com/c/V2CqjW?order_by=added_at&page=1 )
(2) When you first enter the IT Internet topic, you enter the "latest comments". When you switch to "latest collection", the web page URL does not change, which indicates that the web page uses asynchronous loading.
Open the developer tool of Chrome browser (press F12) and click the Network tab.
Open the loading file, and you can see the URL of articles included in IT Internet topics in the Headers section.
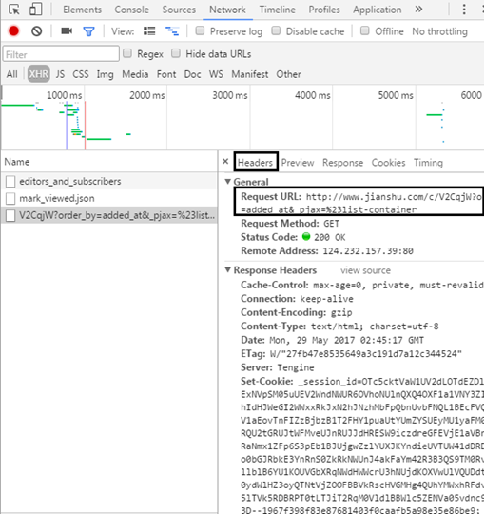
In the Response section, you can see that the returned content is the information of the included article.
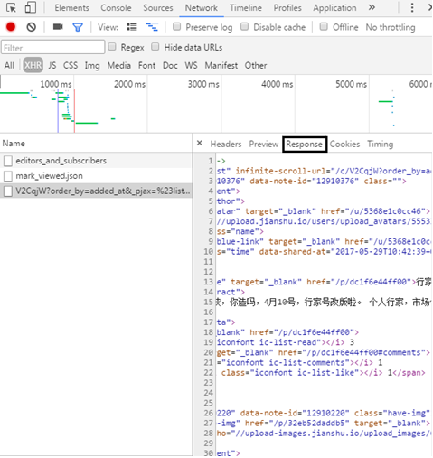
(3) Page flipping also adopts asynchronous loading technology. Open the developer tool and manually slide page flipping to view the URL changes.
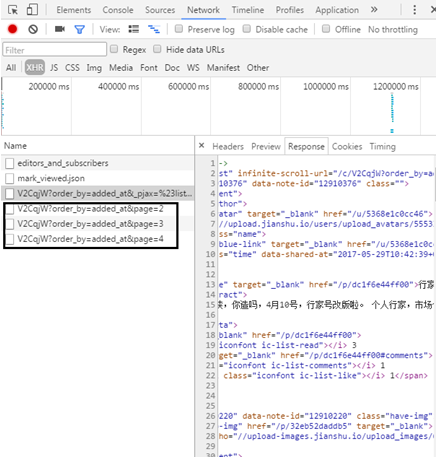
It can be seen that the page is turned by changing the number after the page, and the URL of the first page is changed to:
http://www.jianshu.com/c/V2CqjW?order_by=added_at&page=1 , you can also access it normally, and finally construct a 100 page URL.
(4) The information to be crawled includes: user ID, publishing time, article title, reading volume, comments, likes and rewards.
(5) Crawling is carried out by using the Scrapy frame through pipeline Py stores data in MySQL database.