preface
Now many companies are using HikariCP. HikariCP has also become the default connection pool of SpringBoot. With SpringBoot and microservices, HikariCP will be widely popularized.
The blogger will take you to analyze why HikariCP is favored by Spring Boot from the perspective of source code. The article directory is as follows:
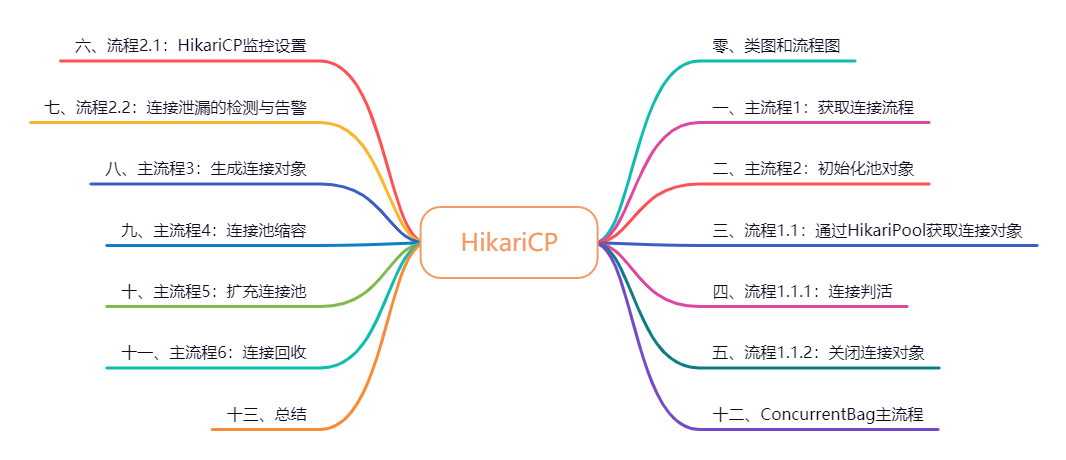
Zero, class diagram and flow chart
Before starting, let's learn about the interaction process between classes when HikariCP obtains a connection, so as to facilitate the reading of the following detailed process.
Get the interaction between classes when connecting:
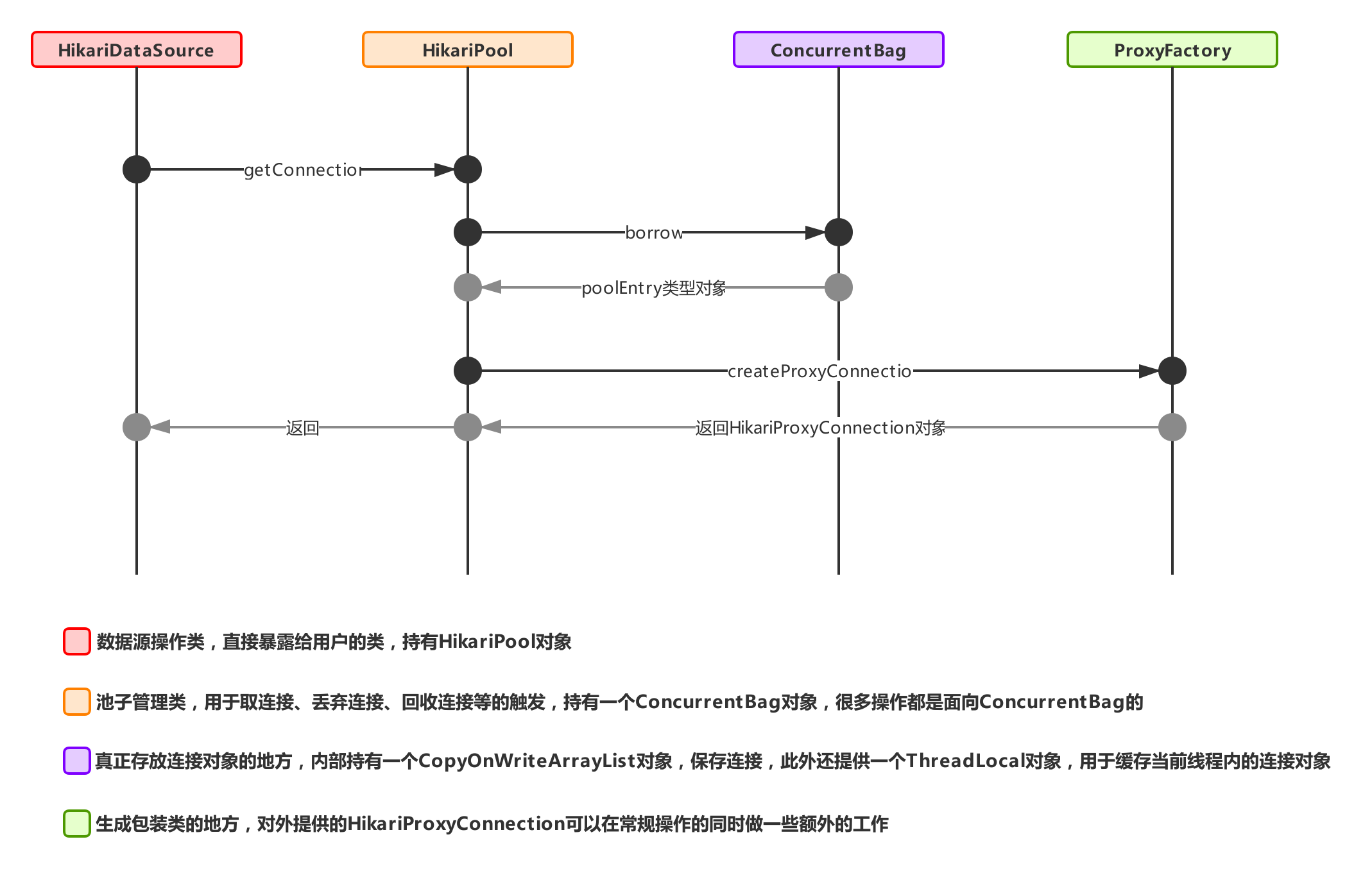
1, Main process 1: get connection process
The entry for HikariCP to obtain a connection is the getConnection method in HikariDataSource. Now let's see the specific process of this method:
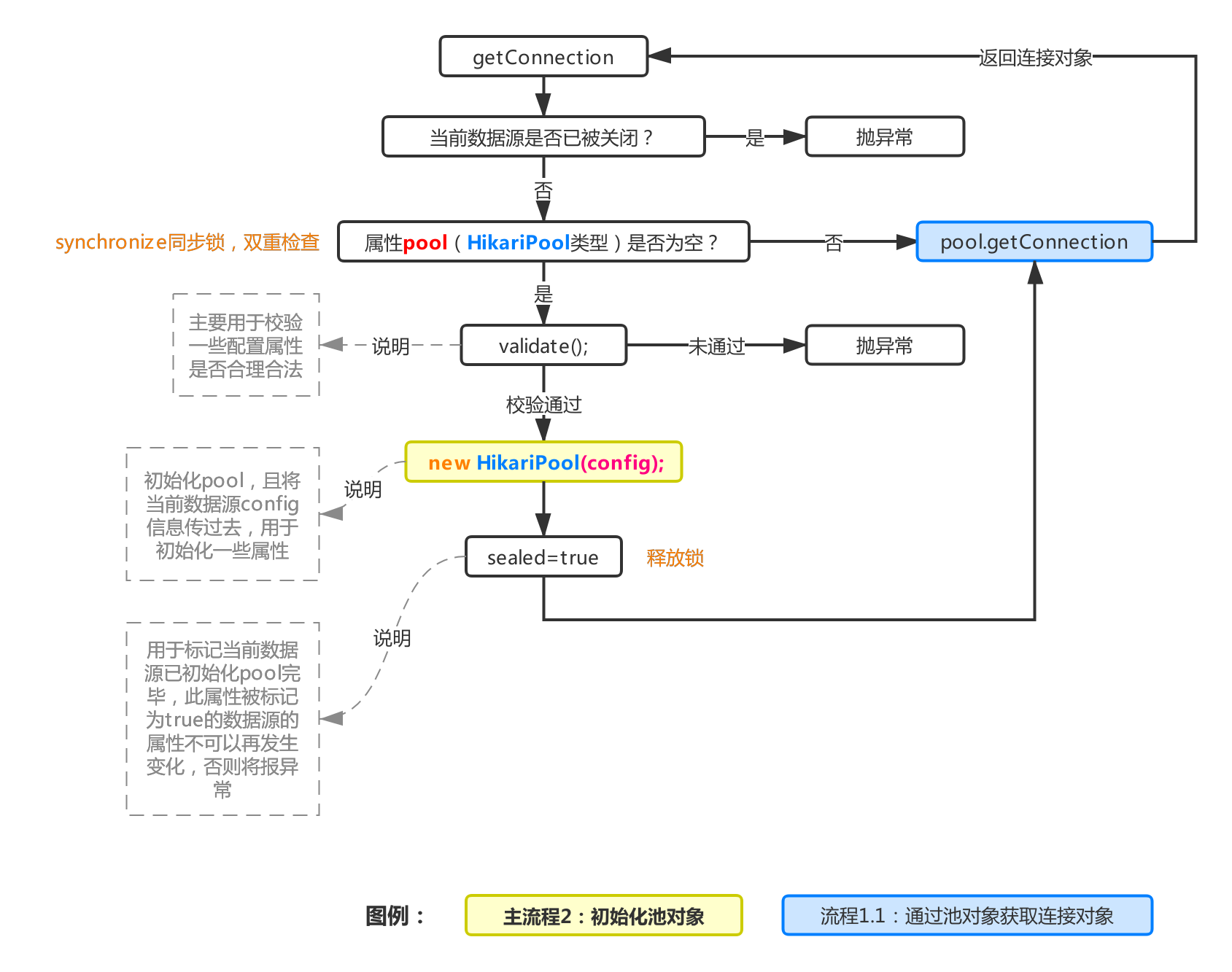
The above is the flow chart when HikariCP obtains a connection. As can be seen from Figure 1, each datasource object will hold a HikariPool object, which is recorded as pool. After initialization, the datasource object pool is empty, so the pool attribute will be instantiated at the first getConnection (refer to main process 1). During initialization, the config attribute in the current datasource needs to be passed, It is used for the initialization of the pool. Finally, it is marked sealed, and then the getConnection method is called according to the pool object (refer to process 1.1). After successful acquisition, the connection object is returned.
2, Main process 2: initializing pool objects
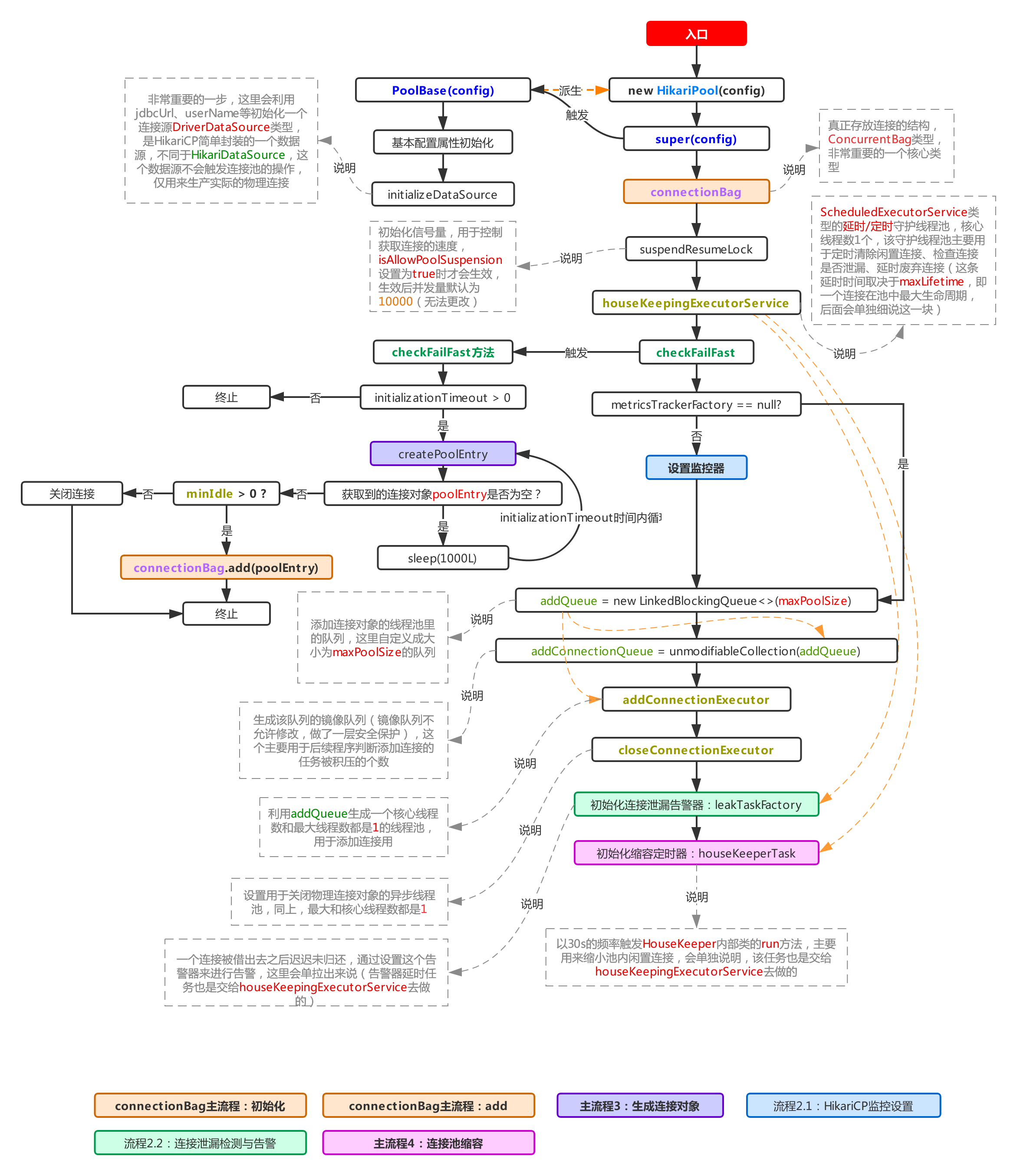
This process is used to initialize the entire connection pool. This process will initialize all the attributes in the connection pool. The main processes have been pointed out in the figure above, which is briefly summarized as follows:
- Use config to initialize various connection pool properties and generate a data source DriverDataSource for production physical connections
- Initialize the core class connectionBag that stores the connection object
- Initialize a delay task thread pool type object houseKeepingExecutorService, which is used to execute some delay / timing tasks later (for example, the connection leak check delay task, refer to process 2.2 and main process 4. In addition, the object is also responsible for actively recovering and closing the connection after maxLifeTime. Refer to main process 3 for this process)
- To warm up the connection pool, HikariCP will initialize a connection object in the checkFailFast of the process and put it into the pool. Of course, the process must be triggered to ensure that the initializationtimeout is > 0 (the default value is 1). This configuration attribute represents the time left for the warm-up operation (the default value is 1. There will be no retry in case of pre heating failure). Unlike Druid's control of the number of preheating connection objects through initialSize, HikariCP only preheats one connection object into the pool.
- Initialize a thread pool object addConnectionExecutor, which is used to expand the connection object later
- Initialize a thread pool object closeConnectionExecutor to close some connection objects. How to trigger the closing task? Refer to process 1.1.2
3, Process 1.1: obtain connection objects through HikariPool
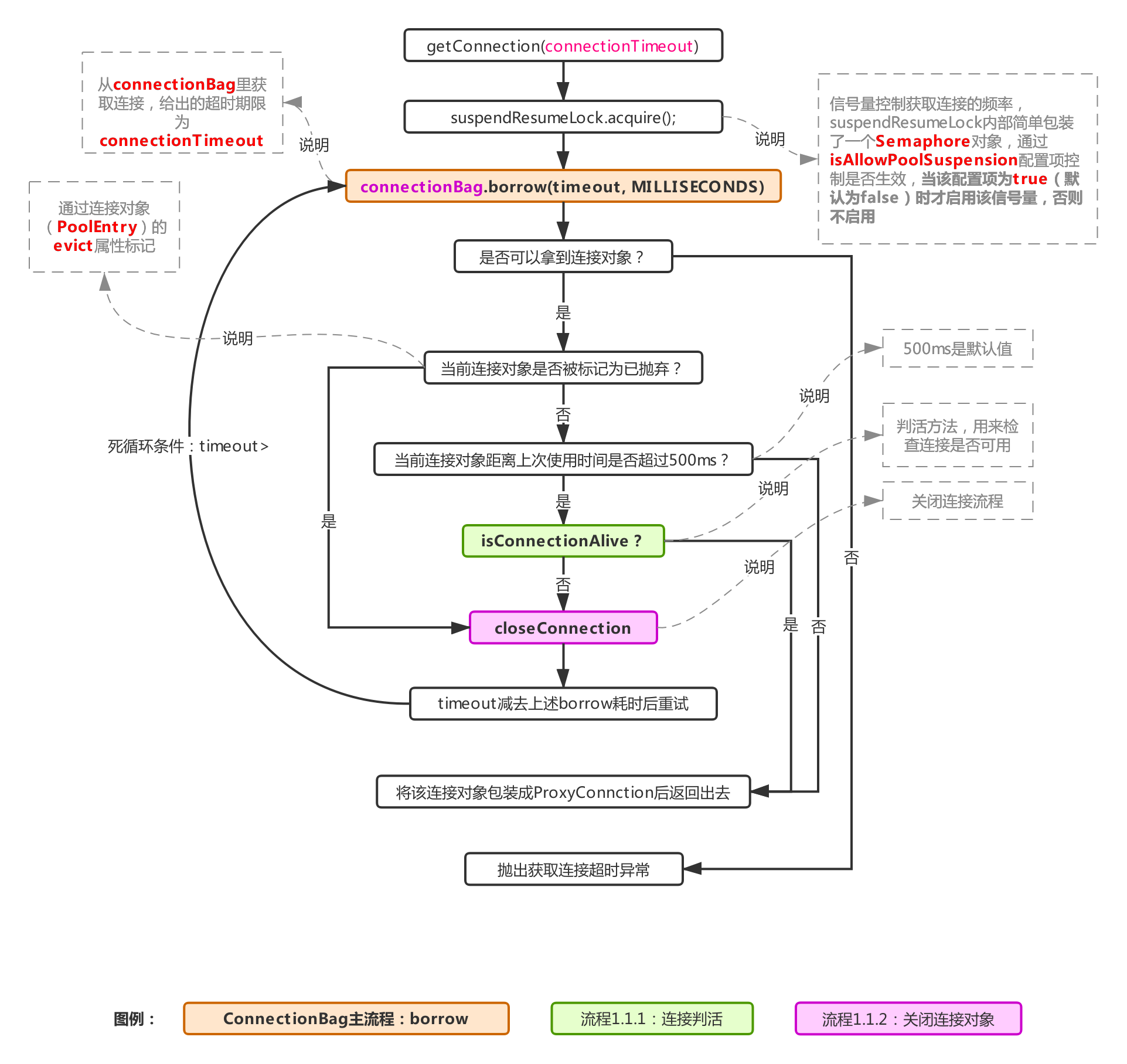
It can be seen from the initial structure diagram that each HikariPool maintains a ConcurrentBag object to store connection objects. As can be seen from the above figure, in fact, the getConnection of HikariPool obtains the connection from ConcurrentBag (by calling its border method, corresponding to the ConnectionBag main process). In the long connection check, it is different from the Druid mentioned earlier, When the connection object is not marked as "discarded", the long connection liveness check here will be checked every time it is taken out as long as it is more than 500ms from the last use (500ms is the default value and can be controlled by configuring the system parameter of com.zaxxer.hikari.aliveBypassWindowMs). emmmm, that is to say, HikariCP frequently checks the liveness of long connections, However, its concurrency performance is still better than Druid, indicating that frequent long connection inspection is not the key to the performance of connection pool.
This is actually due to the lock free implementation of HikariCP. When the CPU load is not as high as that of other connection pools, the concurrency performance difference is caused. Later, we will talk about the specific practices of HikariCP. Even Druid has lock control when obtaining connections, generating connections and returning connections, because we can know from the previous article on analyzing Druid, The connection pool resources in Druid are shared by multiple threads, and lock competition is inevitable. Lock competition means that the thread state changes frequently, and frequent thread state changes mean that the CPU context switching will also be frequent.
Returning to process 1.1, if the connection is empty, an error will be reported directly. If it is not empty, the corresponding check will be carried out. If it passes the check, it will be packaged into a ConnectionProxy object and returned to the business party, If it fails, call the closeConnection method to close the connection (corresponding to process 1.1.2, which will trigger the remove method of ConcurrentBag to discard the connection, and then hand over the actual driver connection to the closeConnectionExecutor thread pool to close the driver connection asynchronously).
4, Process 1.1.1: connection judgment
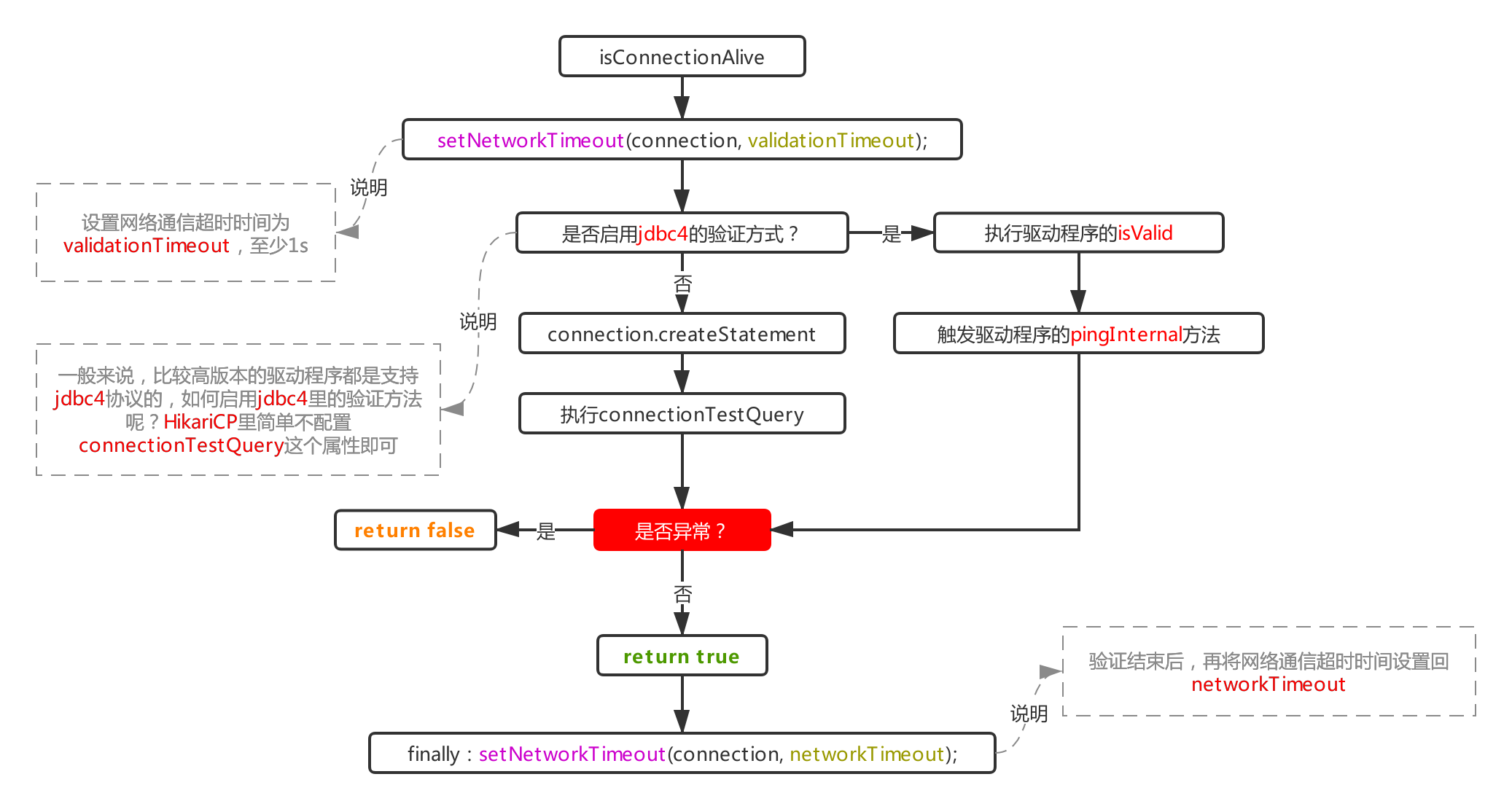
Follow the activity judgment process in the above process 1.1 to see how the next activity is done. First, let's talk about the verification method (note that the connection object accepted by this method is not a poolEntry, but an actually driven connection object held by poolEntry). We knew it when we introduced Druid earlier, Druid determines whether Ping is enabled according to whether there is a ping method in the driver. However, it is more simple and rough when it comes to HikariCP. It only determines whether Ping is enabled according to whether connectionTestQuery is configured:
this.isUseJdbc4Validation = config.getConnectionTestQuery() == null;
Therefore, if the general driver is not a particularly low version, it is not recommended to configure this item. Otherwise, it will use the method of createstatement + extract. This method is obviously more inefficient than simply sending heartbeat data by ping.
In addition, the value of networkTimeout will be reset through the driver's connection object to make it become validationTimeout, indicating the timeout of a verification. Why should this property be reset here? When using the ping method for verification, there is no way to setQueryTimeout through a statement, so it can only be controlled by the timeout of network communication. This time can be controlled through the connection parameter socketTimeout of jdbc:
jdbc:mysql://127.0.0.1:3306/xxx?socketTimeout=250
This value will eventually be assigned to the networkTimeout field of HikariCP, which is why this field is used in the last step to restore the driver connection timeout attribute; Speaking of this, why should we restore it again? This is easy to understand. When the verification is over and the connection object is still alive, its networkTimeout value is still equal to validationTimeout (unexpected). Obviously, before taking it out for use, it needs to restore the value of the cost, that is, the networkTimeout attribute in HikariCP.
5, Process 1.1.2: close connection object
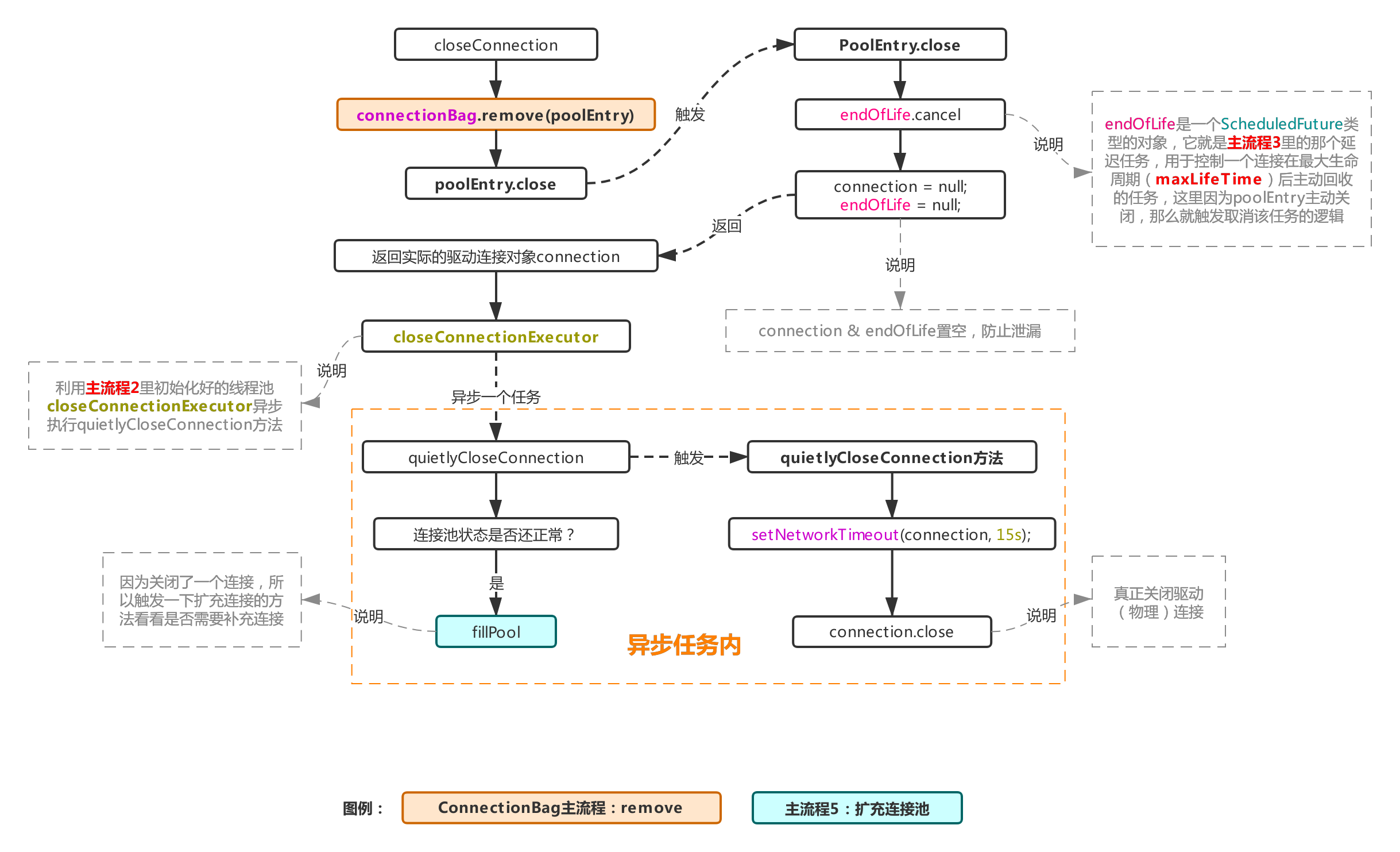
This process is simply a process of actively closing dead connections that fail to pass the verification in process 1.1.1. First, the connection object will be removed from the ConnectionBag, and then the actual physical connection will be handed over to a thread pool for asynchronous execution. This thread pool is the thread pool closeConnectionExecutor initialized when initializing the pool in main process 2, Then start the actual connection closing operation in the asynchronous task. Because actively closing a connection is equivalent to missing a connection, an operation of expanding the connection pool (refer to main process 5) will be triggered.
6, Process 2.1: HikariCP monitoring settings
Unlike Druid, which has so many monitoring indicators, HikariCP will expose several indicators of great concern to us, such as the number of idle connections in the current connection pool, the total number of connections, how long a connection has been used to return, how long it takes to create a physical connection, etc. in this section, we will break down the monitoring of HikariCP's connection pool in detail, First, find the metrics folder under HikariCP, which contains some monitoring interfaces implemented in specifications, and some ready-made implementations (for example, HikariCP has its own support for prometheus, micrometer and dropwizard. I don't know the latter two. prometheus is directly called prometheus below):
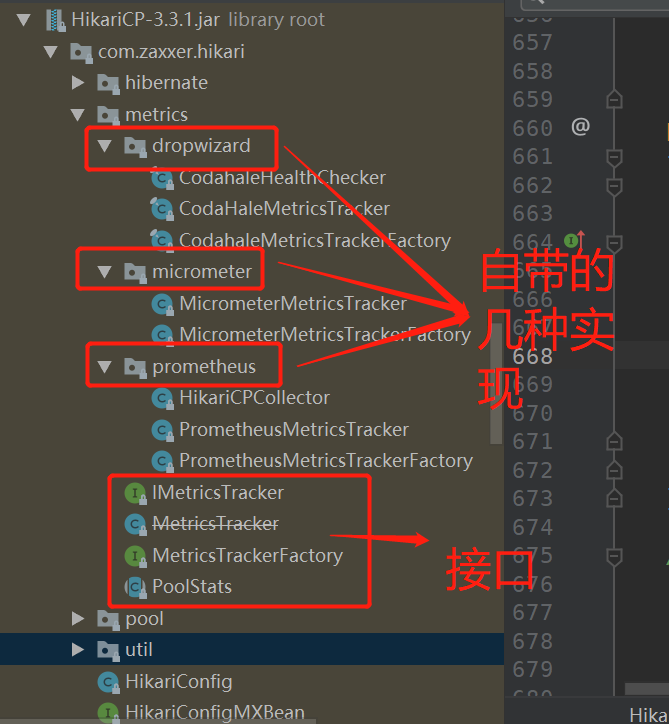
Next, let's focus on the definition of the interface:
//The implementation of this interface is mainly responsible for collecting the time-consuming information of some actions
public interface IMetricsTracker extends AutoCloseable
{
//The trigger point of this method is used to record the time spent in creating an actual physical connection (main process 3)
default void recordConnectionCreatedMillis(long connectionCreatedMillis) {}
//The trigger point of this method is in getConnection (main process 1), which is used to record the actual time consumption when obtaining a connection
default void recordConnectionAcquiredNanos(final long elapsedAcquiredNanos) {}
//The trigger point of this method is used to record the time spent when a connection is retrieved (main process 6)
default void recordConnectionUsageMillis(final long elapsedBorrowedMillis) {}
//The trigger point of this method is also in getConnection (main process 1). It is used to record the times of obtaining connection timeout. Each time the obtaining connection timeout occurs, it will trigger a call of this method
default void recordConnectionTimeout() {}
@Override
default void close() {}
}After you understand the trigger points, let's take a look at the interface definition of MetricsTrackerFactory:
//It is used to create an instance of IMetricsTracker and record the properties in the PoolStats object on demand (the properties in this object are thread pool status indicators such as the current number of idle connections in the connection pool)
public interface MetricsTrackerFactory
{
//Return an IMetricsTracker object and pass PoolStats
IMetricsTracker create(String poolName, PoolStats poolStats);
}See the notes for the above interface usage. For the new PoolStats class, let's see what it does:
public abstract class PoolStats {
private final AtomicLong reloadAt; //Time (timestamp) when the next refresh is triggered
private final long timeoutMs; //The frequency of refreshing the following attribute values is 1s by default and cannot be changed
// Total connections
protected volatile int totalConnections;
// Number of idle connections
protected volatile int idleConnections;
// Number of active connections
protected volatile int activeConnections;
// The number of business threads blocked because they could not get an available connection
protected volatile int pendingThreads;
// maximum connection
protected volatile int maxConnections;
// Minimum number of connections
protected volatile int minConnections;
public PoolStats(final long timeoutMs) {
this.timeoutMs = timeoutMs;
this.reloadAt = new AtomicLong();
}
//Here, take obtaining the maximum number of connections as an example. Others are similar to this
public int getMaxConnections() {
if (shouldLoad()) { //Should I refresh
update(); //Refresh attribute values. Note that the implementation of this update is in HikariPool, because the direct or indirect source of these attribute values is HikariPool
}
return maxConnections;
}
protected abstract void update(); //Implementation has been mentioned above in ↑
private boolean shouldLoad() { //Determines whether to refresh the attribute value according to the update frequency
for (; ; ) {
final long now = currentTime();
final long reloadTime = reloadAt.get();
if (reloadTime > now) {
return false;
} else if (reloadAt.compareAndSet(reloadTime, plusMillis(now, timeoutMs))) {
return true;
}
}
}
}In fact, this is where these properties are obtained and refreshed. Where is this object generated and thrown to the create method of MetricsTrackerFactory? This is the main point of this section: the process of setting the monitor in main process 2. Let's see what happened there:
//Monitor setting method (this method is in HikariPool, and the metricsTracker property is used by HikariPool to trigger the method call in IMetricsTracker)
public void setMetricsTrackerFactory(MetricsTrackerFactory metricsTrackerFactory) {
if (metricsTrackerFactory != null) {
//MetricsTrackerDelegate is a wrapper class and a static internal class of HikariPool. It is the class that actually holds the IMetricsTracker object and actually triggers the method call in IMetricsTracker
//First, the create method of the MetricsTrackerFactory class will be triggered to get the IMetricsTracker object, then the PoolStat object will be initialized with getPoolStats, and then passed to MetricsTrackerFactory
this.metricsTracker = new MetricsTrackerDelegate(metricsTrackerFactory.create(config.getPoolName(), getPoolStats()));
} else {
//If monitoring is not enabled, it is directly equal to an empty class without an implementation method
this.metricsTracker = new NopMetricsTrackerDelegate();
}
}
private PoolStats getPoolStats() {
//Initialize the PoolStats object and specify the update method that 1s triggers a property value refresh
return new PoolStats(SECONDS.toMillis(1)) {
@Override
protected void update() {
//The update method of PoolStat is implemented to refresh the values of each attribute
this.pendingThreads = HikariPool.this.getThreadsAwaitingConnection();
this.idleConnections = HikariPool.this.getIdleConnections();
this.totalConnections = HikariPool.this.getTotalConnections();
this.activeConnections = HikariPool.this.getActiveConnections();
this.maxConnections = config.getMaximumPoolSize();
this.minConnections = config.getMinimumIdle();
}
};
}Here, even if the monitor of HikariCP is registered, in order to achieve its own monitor and get the above indicators, it is necessary to go through the following steps:
- Create a new class to implement the IMetricsTracker interface. We will record this class as IMetricsTrackerImpl here
- Create a new class to implement the MetricsTrackerFactory interface. Here, we record this class as MetricsTrackerFactoryImpl, and instantiate the above IMetricsTrackerImpl in its create method
- Register the setMetricsTrackerFactory method that calls the HikariPool after the MetricsTrackerFactoryImpl instantiation is registered to the Hikari connection pool.
The above does not mention how to monitor the properties in PoolStats. Here, because the Create method is called once, it is gone. The Create method only receives the instance of the PoolStats object. If it is not processed, the instance will be lost to the monitoring module with the end of the create call. Therefore, if you want to get the properties in PoolStats, You need to start a daemon thread to hold the PoolStats object instance, obtain its internal attribute value regularly, and then push it to the monitoring system. If Prometheus and other monitoring systems use pull to obtain monitoring data, you can follow the implementation of HikariCP's native Prometheus monitoring and customize a Collector object to receive the PoolStats instance, In this way, Prometheus can pull regularly. For example, HikariCP is implemented according to the MetricsTrackerFactory defined by Prometheus monitoring system (corresponding to the Prometheus MetricsTrackerFactory class in Figure 2):
@Override
public IMetricsTracker create(String poolName, PoolStats poolStats) {
getCollector().add(poolName, poolStats); //Give the received PoolStats object directly to the Collector, so that whenever the Prometheus server triggers a call to the collection interface, PoolStats will follow the internal property acquisition process
return new PrometheusMetricsTracker(poolName, this.collectorRegistry); //Returns the implementation class of the IMetricsTracker interface
}
//Custom Collector
private HikariCPCollector getCollector() {
if (collector == null) {
//Register with Prometheus collection center
collector = new HikariCPCollector().register(this.collectorRegistry);
}
return collector;Through the above explanation, you can know how to customize your own monitor in HikariCP and how it is different from Druid's monitoring. In many cases, it needs to be customized. Although our company also uses Prometheus monitoring, because the naming of monitoring indicators in the native Prometheus collector of HikariCP does not meet our specifications, we customized one. If you have similar problems, you might as well try it.
🍁 There is no drawing in this section. It is pure code, because it is not easy to explain this part. This part has little to do with the overall process of the connection pool. At best, it obtains some properties of the connection pool itself. The trigger points in the connection pool are also clearly explained in the comments of the above code segment. It may be better understood by looking at the code definition.
7, Process 2.2: detection and alarm of connection leakage
This section corresponds to sub process 2.2 in main process 2. When initializing the pool object, an attribute called leakTaskFactory is initialized. This section will see what it is used for.
7.1: what does it do?
If a connection is taken out and used for more than leakDetectionThreshold (configurable, default 0), a connection leakage warning will be triggered to inform the business party that there is a connection leakage problem.
7.2: process details
This attribute is a ProxyLeakTaskFactory type object, and it also holds the thread pool object houseKeepingExecutorService, which is used to produce ProxyLeakTask objects, and then uses the houseKeepingExecutorService above to delay the run method in the object. The trigger point of this process is in the step of packaging ProxyConnection object in process 1.1 above. Let's see the specific flow chart:
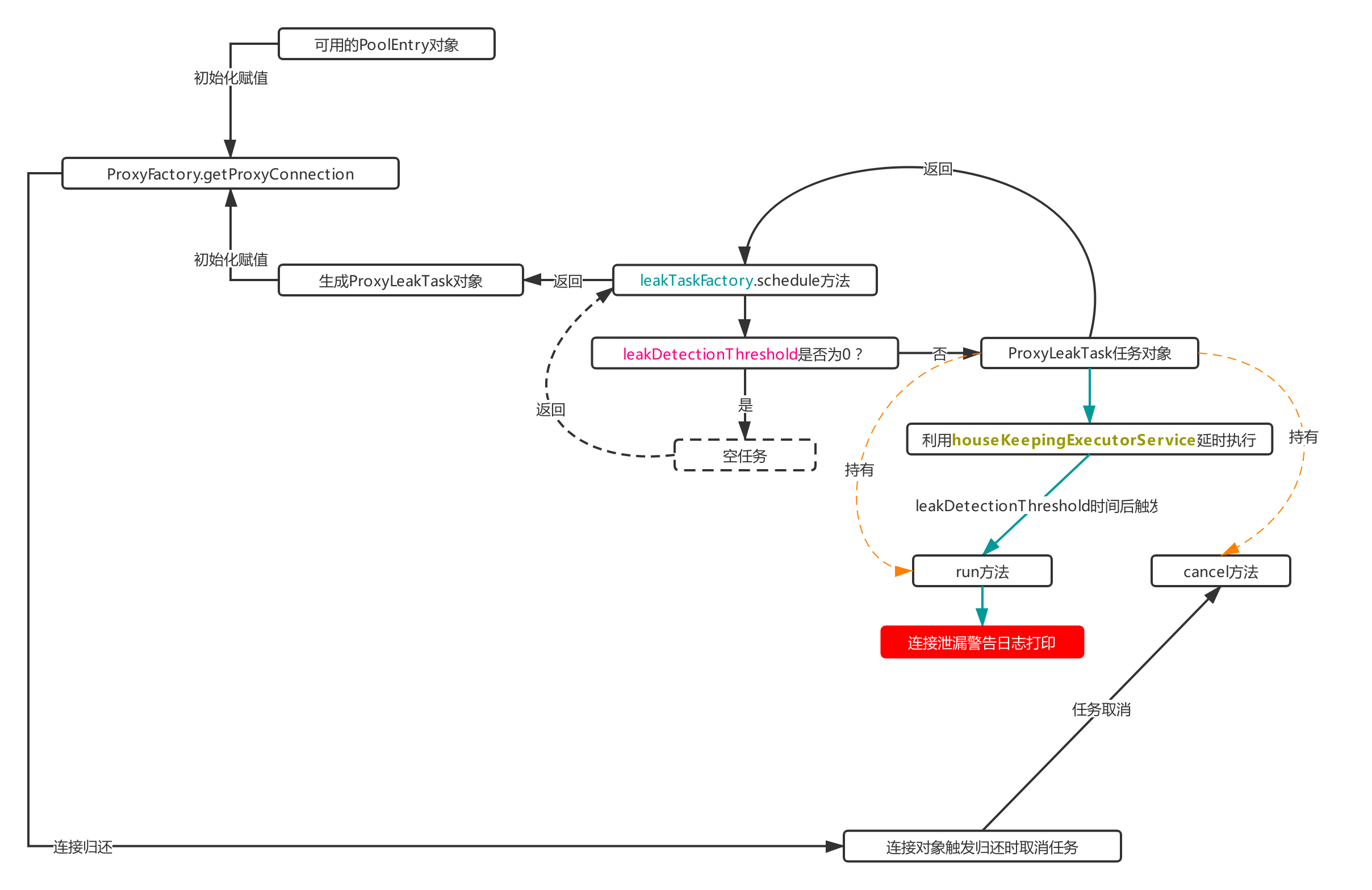
Each time ProxyConnection objects are generated in process 1.1, the above process will be triggered. As can be seen from the flowchart, ProxyConnection objects hold PoolEntry and ProxyLeakTask objects. The leakTaskFactory object is used to initialize ProxyLeakTask objects. ProxyLeakTask can be initialized through its schedule method, And pass its instance to ProxyConnection for initialization assignment (ps: it is known from the figure that ProxyConnection will actively cancel the leak check task when triggering the recycling event, which is why ProxyConnection needs to hold the ProxyLeakTask object).
As can be seen from the above flowchart, a ProxyLeakTask object with an actual delayed task will be generated only when the leakDetectionThreshold is not equal to 0. Otherwise, a meaningless empty object will be returned. Therefore, to enable the connection leak check, first set the leakDetectionThreshold configuration. This attribute indicates that the borrowed connection has not been returned after this time, and a connection leak alarm will be triggered.
The reason why ProxyConnection holds the ProxyLeakTask object is that it can listen to whether the connection triggers the return operation. If it triggers, it calls the cancel method to cancel the delayed task to prevent false alarm.
From this process, we can know that like Druid, HikariCP also has connection object leakage inspection. Compared with Druid's active recovery of connections, HikariCP is simpler to implement. It only prints the warning log when triggered and does not take specific measures to force recovery.
Like Druid, this process is closed by default, because the third-party framework is generally used in actual development. The framework itself will ensure timely close connection and prevent connection object leakage. Whether it is opened or not depends on whether the business needs to be opened. If it must be opened, how to set the size of leakDetectionThreshold also needs to be considered. The author's Spring Boot column and Mybatis column have been completed, focusing on the official account [code ape technology column] reply keywords Spring Boot advanced, Mybatis advanced acquisition.
8, Main process 3: generate connection object
This section describes the createEntry method in main process 2. This method uses the driverdatasource object in PoolBase to generate an actual connection object (if you forget where the driverdatasource was initialized, you can see the role of the initializeDataSource method in PoolBase in main process 2), and then wrap it into a PoolEntry object with the PoolEntry class, Now let's look at the main properties of this wrapper class:
final class PoolEntry implements IConcurrentBagEntry {
private static final Logger LOGGER = LoggerFactory.getLogger(PoolEntry.class);
//Modify the state attribute through cas
private static final AtomicIntegerFieldUpdater stateUpdater;
Connection connection; //Actual physical connection object
long lastAccessed; //Refresh the time when recycling is triggered, indicating "last use time"
long lastBorrowed; //This time is refreshed after the border in getConnection succeeds, indicating "the last lending time"
@SuppressWarnings("FieldCanBeLocal")
private volatile int state = 0; //Connection status, enumeration value: IN_USE (in use), NOT_IN_USE (idle), REMOVED, RESERVED (marked as RESERVED)
private volatile boolean evict; //Whether it is marked as abandoned is used in many places (for example, in process 1.1, it is used to judge whether the connection has been abandoned, and for example, the direct abandonment logic triggered when the clock is dialed back in main process 4)
private volatile ScheduledFuture<?> endOfLife; //It is used to discard the connection delay task when the connection life cycle (maxLifeTime) is exceeded. Here, the poolEntry needs to hold the object, mainly because it needs to cancel the task when the object is actively closed (which means that it does not need to be actively invalid when the maxLifeTime is exceeded)
private final FastList openStatements; //All statement objects generated on the current connection object are used to actively close these objects when recycling connections to prevent missing statements
private final HikariPool hikariPool; //Hold pool object
private final boolean isReadOnly; //Is it read-only
private final boolean isAutoCommit; //Is there a transaction
}The above is all the attributes in the whole PoolEntry object. Here, let's talk about the endooflife object. It is a delay task using the thread pool object houseKeepingExecutorService. This delay task is generally triggered at about maxLifeTime after the connection object is created. Specifically, see the createEntry code below:
private PoolEntry createPoolEntry() {
final PoolEntry poolEntry = newPoolEntry(); //Generate actual connection object
final long maxLifetime = config.getMaxLifetime(); //Get the configured maxLifetime
if (maxLifetime > 0) { //Do not enable active expiration policy when < = 0
// Calculate the random number to be subtracted
// Source note: variance up to 2.5% of the maxlifetime
final long variance = maxLifetime > 10_000 ? ThreadLocalRandom.current().nextLong(maxLifetime / 40) : 0;
final long lifetime = maxLifetime - variance; //Generate actual delay time
poolEntry.setFutureEol(houseKeepingExecutorService.schedule(
() -> { //For the actual delay task, softEvictConnection is triggered directly here, and the connection object will be marked as abandoned in softEvictConnection, and then try to modify its state to STATE_RESERVED, if successful, close connection will be triggered (corresponding to process 1.1.2)
if (softEvictConnection(poolEntry, "(connection has passed maxLifetime)", false /* not owner */)) {
addBagItem(connectionBag.getWaitingThreadCount()); //After recycling, if a connection is missing from the connection pool, an attempt will be made to add a new connection object
}
},
lifetime, MILLISECONDS)); //Assign a value to endooflife and submit a delayed task, which will be triggered after lifetime
}
return poolEntry;
}
//Trigger new connection task
public void addBagItem(final int waiting) {
//Front prompt: refer to main process 2 for the relationship and initialization between addConnectionQueue and addConnectionExecutor
//When the number of submitted tasks in the queue for adding connections exceeds the number of threads blocked due to failure to obtain connections, the task of submitting connections and adding connections is performed
final boolean shouldAdd = waiting - addConnectionQueue.size() >= 0; // Yes, >= is intentional.
if (shouldAdd) {
//Submit the task to the thread pool addConnectionExecutor. PoolEntryCreator is a class that implements the Callable interface. The call method of this class will be introduced in the form of flow chart below
addConnectionExecutor.submit(poolEntryCreator);
}
}Through the above process, we can know that HikariCP generally adds a connection to the pool through the createEntry method. Each connection is packaged as a PoolEntry object. When the object is created, a delay task will be submitted to close and discard the connection. This time is our configured maxLifeTime. In order to ensure that it does not expire at the same time, HikariCP will also use maxLifeTime to subtract a random number as the final delay time of the delayed task. Then, when the abandoned task is triggered, it will also trigger addBagItem to add a connection task (because a connection is abandoned, one needs to be added to the pool). The task will be executed by the addConnectionExecutor thread pool defined in main process 2. Then, Now let's look at the task flow of asynchronously adding connection objects:
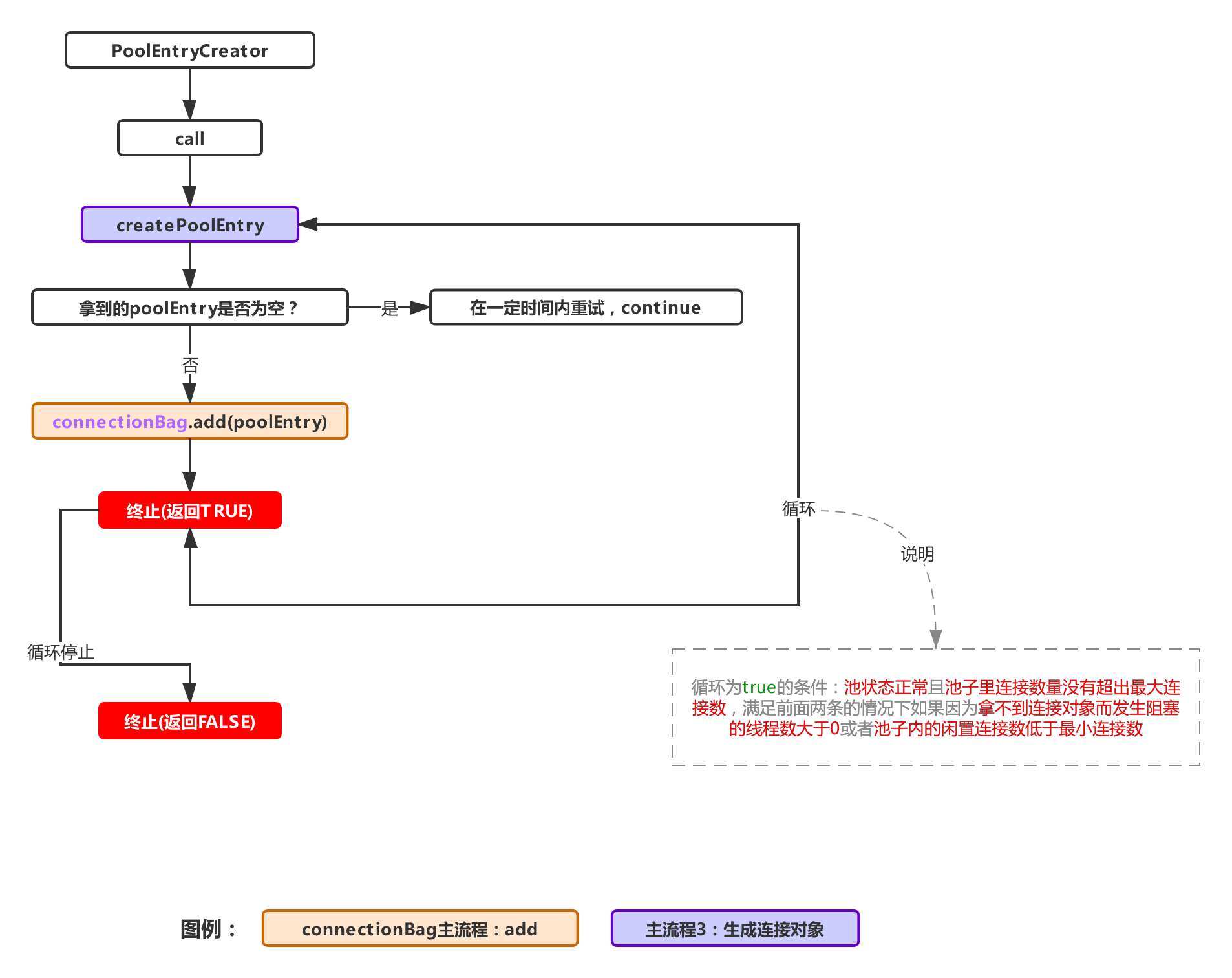
This process is used to add connections to the connection pool. Combined with createEntry, it is because these two processes are closely related. In addition, the main process 5 (fillPool, extended connection pool) will also trigger this task.
9, Main process 4: connection pool volume reduction
HikariCP will clean up connections that have been idle for too long according to the minIdle timing. This timing task is enabled when the main process 2 initializes the connection pool object. Like the above process, it also uses the houseKeepingExecutorService thread pool object as the executor of the timing task.
Let's see how to enable this task in main process 2:
//The default value of housekeepingPeriodMs is 30s, so the interval of scheduled tasks is 30s this.houseKeeperTask = houseKeepingExecutorService.scheduleWithFixedDelay(new HouseKeeper(), 100L, housekeepingPeriodMs, MILLISECONDS);
In this section, we will focus on the HouseKeeper class, which implements the Runnable interface. The recycling logic is mainly in its run method. Let's take a look at the logic flow chart of the run method:
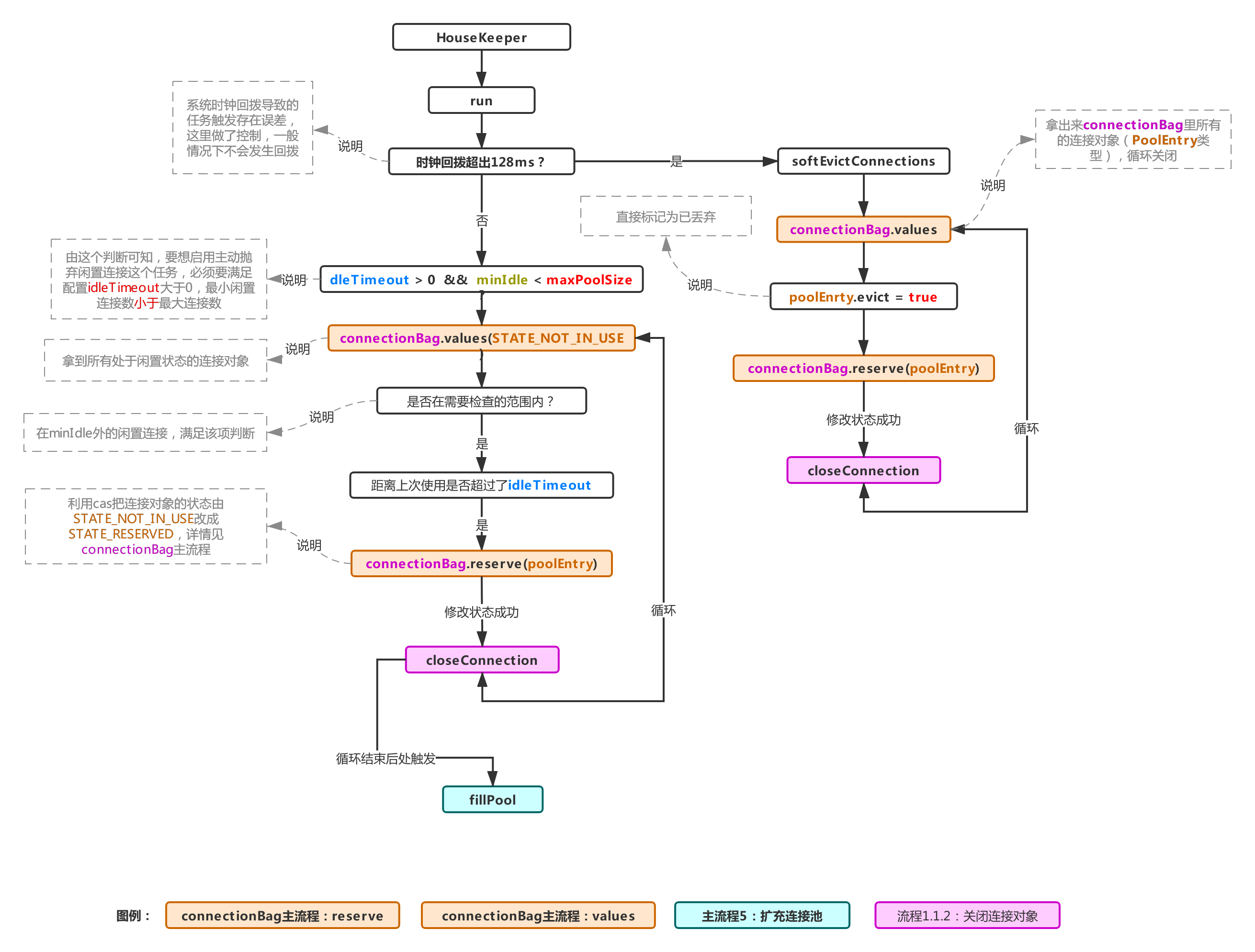
The above process is specifically done in the run method of HouseKeeper. Since the system time callback will cause errors when the scheduled task reclaims some connections, the following judgment exists:
//now is the current system time, previous is the time when the task was triggered last time, and housekeepingPeriodMs is how often the task is triggered //That is, plus millis (previous, housekeeping period MS) represents the current time //If the system time is not called back, then plusMillis(now, 128) must be greater than the current time. If the system time is called back //If the callback time exceeds 128ms, the following judgment is true, otherwise it will never be true if (plusMillis(now, 128) < plusMillis(previous, housekeepingPeriodMs))
This is a measure taken by hikariCP when the system clock is dialed back. As can be seen from the flow chart, it directly takes out all connection objects in the pool, marks them one by one as abandoned, and tries to modify the status value to STATE_RESERVED (these States will be described later, which will not be discussed here). If the system clock does not change (the logic of this block will be hit in most cases), as shown in the figure, all connections in the current pool in the idle state (STATE_NOT_IN_USE) will be taken out, and then the range to be checked will be calculated, and then the connection state will be modified in a cycle:
//Get all idle connections
final List notInUse = connectionBag.values(STATE_NOT_IN_USE);
//Calculate the amount of idle time to be checked. In short, the minimum minIdle connections in the pool need to be alive, so you need to calculate the idle objects beyond this range for inspection
int toRemove = notInUse.size() - config.getMinIdle();
for (PoolEntry entry : notInUse) {
//Within the check range and idle time exceeds idleTimeout, then try to change the connection object state from state_ NOT_ IN_ Change use to STATE_RESERVED succeeded
if (toRemove > 0 && elapsedMillis(entry.lastAccessed, now) > idleTimeout && connectionBag.reserve(entry)) {
closeConnection(entry, "(connection has passed idleTimeout)"); //When the above conditions are met, the connection is closed
toRemove--;
}
}
fillPool(); //Because some connections may be recycled, you need to trigger the connection pool expansion process again to check whether you need to add new connections.The above code is the process logic in the flowchart when there is no callback system time. The process is enabled only when idleTimeout is greater than 0 (equal to 0 by default) and minIdle is less than maxPoolSize. It is not enabled by default. If it needs to be enabled, it can be configured according to conditions.
10, Main process 5: expand connection pool
This process mainly depends on the fillPool method in HikariPool. This method has appeared in many of the above processes. Its function is to initiate the operation of expanding the number of connections when the connection is abandoned and the connection pool connection is not enough. This is a very simple process. Let's look at the source code (minor changes have been made to the source code to make the code structure clearer):
// PoolEntryCreator has seen the implementation process of call method in main process 3, but there are two PoolEntryCreator objects,
// This is a more detailed place for logging. I won't talk about this part. For ease of understanding, you only need to know that the two objects execute the same call method
private final PoolEntryCreator poolEntryCreator = new PoolEntryCreator(null);
private final PoolEntryCreator postFillPoolEntryCreator = new PoolEntryCreator("After adding ");
private synchronized void fillPool() {
// This judgment is to calculate the number of connections to be expanded according to the relevant data in the current pool,
// The judgment method is to use the difference between the maximum number of connections and the current total number of connections, and the difference between the minimum number of connections and the number of idle connections in the current pool, and take the smallest one
int needAdd = Math.min(maxPoolSize - connectionBag.size(),
minIdle - connectionBag.getCount(STATE_NOT_IN_USE));
//Subtract the currently queued tasks, that is, the number of connections to be added in the end
final int connectionsToAdd = needAdd - addConnectionQueue.size();
for (int i = 0; i < connectionsToAdd; i++) {
//In general, the postFillPoolEntryCreator task will be hit at the last time of the loop. In fact, the log will be printed at the last time (the interference logic can be ignored)
addConnectionExecutor.submit((i < connectionsToAdd - 1) ? poolEntryCreator : postFillPoolEntryCreator);
}
}It can be seen from this process that the task of adding a new connection is finally handled by the addConnectionExecutor thread pool, and the topic of the task is PoolEntryCreator. For this process, please refer to main process 3
Then needAdd's calculation:
Math.min(maximum connection - Total number of current connections in the pool, Minimum number of connections - Number of idle connections in the pool)
Judging by this method, you can ensure that the number of connections in the pool will never exceed maxPoolSize or lower than minIdle. When the connection is tight, it can ensure that the capacity can be expanded in the number of minidles each time. Therefore, if the value of maxPoolSize is the same as that of minIdle configuration, no capacity expansion will occur when the connection in the pool is tight.
11, Main process 6: connection recovery
At the beginning, the actual physical connection object will be packaged as a PoolEntry object and stored in the ConcurrentBag. Then, when it is obtained, the PoolEntry object will be packaged as a ProxyConnection object and exposed to the user. Triggering connection recycling is actually triggering the close method in ProxyConnection:
public final void close() throws SQLException {
// Original note: closing statements can cause connection instance, so this must run before the conditional below
closeStatements(); //All statement objects generated during the use of this connection object by the business party shall be close d uniformly to prevent leakage of closure
if (delegate != ClosedConnection.CLOSED_CONNECTION) {
leakTask.cancel(); //Cancel the connection leakage inspection task, refer to process 2.2
try {
if (isCommitStateDirty && !isAutoCommit) { //After the execution statement exists and the transaction is opened, the transaction needs to be actively rolled back when calling close
delegate.rollback(); //RollBACK
lastAccess = currentTime(); //Refresh last used time
}
} finally {
delegate = ClosedConnection.CLOSED_CONNECTION;
poolEntry.recycle(lastAccess); //Trigger recovery
}
}
}This is the close method in ProxyConnection. You can see that it will eventually call the PoolEntry's recycle method for recycling. In addition, the last use time of the connection object is refreshed at this time. This time is a very important attribute that can be used to judge the idle time of a connection object. Let's take a look at the PoolEntry's recycle method:
void recycle(final long lastAccessed) {
if (connection != null) {
this.lastAccessed = lastAccessed; //Refresh last used time
hikariPool.recycle(this); //Trigger HikariPool's recycling method and pass yourself to it
}
}As mentioned earlier, each PoolEntry object holds the HikariPool object, which is convenient to trigger some operations of the connection pool. As can be seen from the above code, the recycle method in HikariPool will eventually be triggered. Let's look at the recycle method of HikariPool:
void recycle(final PoolEntry poolEntry) {
metricsTracker.recordConnectionUsage(poolEntry); //Relevant monitoring indicators, ignored
connectionBag.requite(poolEntry); //Finally, the request method of connectionbag is triggered to return the connection. For this process, refer to the request method in the main process of connectionbag
}The above is the logic of connecting the recycling part, which is simpler than other processes.
12, ConcurrentBag mainstream
This class is used to store the final PoolEntry type connection objects and provides basic functions of adding, deleting and querying. It is held by HikariPool. Almost all the above operations are completed in HikariPool. HikariPool is used to manage the actual connection production action and recycling action. The actual operation is the ConcurrentBag class. Sort out the trigger points of all the above processes:
- Main process 2: when initializing HikariPool, initialize ConcurrentBag (construction method). When preheating, get the connection object through createEntry and call ConcurrentBag Add adds a connection to ConcurrentBag.
- Process 1.1: when obtaining a connection through HikariPool, call concurrentbag Borrow gets a connection object.
- Main process 6: through concurrentbag Require returns a connection.
- Process 1.1.2: when the connection is triggered to be closed, it will pass the concurrentbag Remove removes the connection object. According to the previous process, the trigger points for closing the connection are: the connection exceeds the maximum life cycle, maxLifeTime actively discards, the health check fails to actively discard, and the connection pool shrinks.
- Main process 3: when adding a connection asynchronously, call ConcurrentBag Add adds a connection to ConcurrentBag. According to the previous process, the trigger point for adding a connection is: after the connection exceeds the maximum life cycle, maxLifeTime actively discards the connection and expands the connection pool.
- Main process 4: connection pool resizing task by calling concurrentbag Values filter out the connection objects that need to be operated, and then pass the concurrentbag Reserve completes the modification of the state of the connection object, and then triggers the closing and removing of the connection through process 1.1.2.
Through the sorting of trigger points, we can know that the main methods in the structure are the parts marked as label color in the above trigger points, and then let's see the basic definitions and main methods of this class:
public class ConcurrentBag<T extends IConcurrentBagEntry> implements AutoCloseable {
private final CopyOnWriteArrayList<T> sharedList; //The final place to store the PoolEntry object is a CopyOnWriteArrayList
private final boolean weakThreadLocals; //The default is false. When true, a connection object can be in a weak reference state in the list in the threadList below to prevent memory leakage (see Note 1)
private final ThreadLocal<List<Object>> threadList; //Thread level cache. The connection objects obtained from the sharedList will be cached into the current thread. When browsing, they will be taken from the cache first, so as to achieve lock free implementation in the pool
private final IBagStateListener listener; //Internal interface. HikariPool implements this interface, which is mainly used by ConcurrentBag to actively notify HikariPool to trigger the asynchronous operation of adding connection objects (that is, the process triggered by addConnectionExecutor in main process 3)
private final AtomicInteger waiters; //The current number of business threads blocked because the connection cannot be obtained. This has also occurred in previous processes. For example, addBagItem in main process 3 will judge whether to add a connection according to this indicator
private volatile boolean closed; //Marks whether the current ConcurrentBag has been closed
private final SynchronousQueue<T> handoffQueue; //This is a ready to produce and ready to sell queue. It is used to get the newly created connection object in the add method in time when the connection is not enough. For details, please refer to the following code of border and add
//Internal interface, which is implemented by the PoolEntry class
public interface IConcurrentBagEntry {
//The state of the connection object has been involved in many parts of the previous process, such as the volume reduction of the main process 4
int STATE_NOT_IN_USE = 0; //let ... lie idle
int STATE_IN_USE = 1; //in use
int STATE_REMOVED = -1; //obsolete
int STATE_RESERVED = -2; //Mark retention, an intermediate state between idle and abandoned, is mainly triggered by volume reduction
boolean compareAndSet(int expectState, int newState); //Try to use cas to modify the state value of the connection object
void setState(int newState); //Set status value
int getState(); //Get status value
}
//Refer to the explanation of the listener attribute above
public interface IBagStateListener {
void addBagItem(int waiting);
}
//Get connection method
public T borrow(long timeout, final TimeUnit timeUnit) {
// Omit
}
//Recycling connection method
public void requite(final T bagEntry) {
//Omit
}
//Add connection method
public void add(final T bagEntry) {
//Omit
}
//Remove connection method
public boolean remove(final T bagEntry) {
//Omit
}
//Obtain all qualified connection collections in the current pool according to the connection status value
public List values(final int state) {
//Omit
}
//Get all connections in the current pool
public List values() {
//Omit
}
//Use cas to transfer the state of the incoming connection object from state_ NOT_ IN_ Change use to STATE_RESERVED
public boolean reserve(final T bagEntry) {
//Omit
}
//Gets the number of connections in the current pool that match the incoming status value
public int getCount(final int state) {
//Omit
}
}From this basic structure, we can see how HikariCP optimizes the traditional connection pool implementation. Compared with Druid, HikariCP prefers lock free implementation to avoid lock competition as much as possible.
12.1: borrow
This method is used to obtain an available connection object. The trigger point is process 1.1. HikariPool uses this method to obtain the connection. Let's see what this method does:
public T borrow(long timeout, final TimeUnit timeUnit) throws InterruptedException {
// Source comment: try the thread local list first
final List<Object> list = threadList.get(); //First, get the previously cached connection object collection from the cache of the current thread
for (int i = list.size() - 1; i >= 0; i--) {
final Object entry = list.remove(i); //Remove it first, and the recycling method will add again
final T bagEntry = weakThreadLocals ? ((WeakReference<T>) entry).get() : (T) entry; //Weak references are not enabled by default
// After obtaining the object, try to change its state from state through cas_ NOT_ IN_ Change use to STATE_IN_USE, note that if other threads are also using this connection object,
// If the attribute is successfully modified, the cas of the current thread will fail, and the loop will continue to try to get the next connection object
if (bagEntry != null && bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry; //After cas is set successfully, it means that the current thread bypasses the interference of other threads, successfully obtains the connection object, and returns directly
}
}
// Source comments: otherwise, scan the shared list then poll the handoff queue
final int waiting = waiters.incrementAndGet(); //If an available connection object cannot be found in the cache, it is considered that "back to source" is required, with waiters+1
try {
for (T bagEntry : sharedList) {
//Loop sharedList and try to change the connection status value from state_ NOT_ IN_ Change use to STATE_IN_USE
if (bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
// If we may have stolen another waiter's connection, request another bag add
if (waiting > 1) { //When the number of blocked threads is greater than 1, you need to trigger the addBagItem method of HikariPool to add connections to the pool. Refer to main process 3 for the implementation of this method
listener.addBagItem(waiting - 1);
}
return bagEntry; //cas is set successfully. Like the above logic, it means that the current thread bypasses the interference of other threads, successfully obtains the connection object and returns directly
}
}
//This shows that not only the list in the thread cache cannot compete for the connection object, but also the available connection can not be found in the sharedList. At this time, it is considered that HikariPool needs to be notified, and it is time to trigger the add connection operation
listener.addBagItem(waiting);
timeout = timeUnit.toNanos(timeout); //At this time, the timeout control is used to obtain the time
do {
final long start = currentTime();
//Try to get the newly added connection object from the handoffQueue queue queue (generally, the newly added connection object will be offer ed into the queue in addition to the sharedList)
final T bagEntry = handoffQueue.poll(timeout, NANOSECONDS);
//If the available connection object is still not obtained after the specified time, or the object is successfully set through cas after being obtained, there is no need to retry and the object is returned directly
if (bagEntry == null || bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry;
}
//This indicates that the connection object is obtained from the queue, but the cas setting fails, indicating that the object is first used by other threads. If the time is enough, try to obtain it again
timeout -= elapsedNanos(start); //timeout minus the elapsed time indicates the available time for the next cycle
} while (timeout > 10_000); //Only continue when the remaining time is greater than 10s. Generally, this cycle will only go once, because the timeout is rarely larger than 10s
return null; //Timeout, still return null
} finally {
waiters.decrementAndGet(); //After this step goes out, HikariPool receives the result of border, which is regarded as going out of the block, so waiters-1
}
}Taking a closer look at the notes, the process is roughly divided into three main steps:
- Get connection from thread cache
- Can't get from sharedList
- If it cannot be obtained, it triggers the addition of connection logic and attempts to obtain the newly generated connection object from the queue
12.2: add
This process will add a connection object into the bag. Usually, the addBagItem method in main process 3 triggers the addition operation through the addConnectionExecutor asynchronous task. The main process of this method is as follows:
public void add(final T bagEntry) {
sharedList.add(bagEntry); //Add it directly to the sharedList
// Source notes: spin until a thread takes it or none are waiting
// Referring to the browse process, thread scheduling is initiated when there are threads waiting to obtain available connections, and the current incoming connection state is still idle, and there are no consumers waiting to obtain in the queue
while (waiters.get() > 0 && bagEntry.getState() == STATE_NOT_IN_USE && !handoffQueue.offer(bagEntry)) { //Note that a connection object will be offer ed into the queue
yield();
}
}In combination with the row, a connection object will be added to the queue when there is a waiting thread, which makes it easier to poll the connection object where the waiting occurs in the row.
12.3: requite
This process will recycle a connection. The trigger point of this method is in main process 6. The specific code is as follows:
public void requite(final T bagEntry) {
bagEntry.setState(STATE_NOT_IN_USE); //Recycling means that after use, change the state to STATE_NOT_IN_USE status
for (int i = 0; waiters.get() > 0; i++) { //If there is a waiting thread, try to pass it to the queue and let borrow get it
if (bagEntry.getState() != STATE_NOT_IN_USE || handoffQueue.offer(bagEntry)) {
return;
}
else if ((i & 0xff) == 0xff) {
parkNanos(MICROSECONDS.toNanos(10));
}
else {
yield();
}
}
final List<Object> threadLocalList = threadList.get();
if (threadLocalList.size() < 50) { //The maximum number of caches in the connection set in the thread is 50. When the connection is recycled here, it will be added to the cache of the current thread again to facilitate the next row
threadLocalList.add(weakThreadLocals ? new WeakReference<>(bagEntry) : bagEntry); //Weak reference is not enabled by default. If it is enabled, there is no risk of memory leakage for the connection objects in the cache collection
}
}12.4: remove
This is responsible for removing a connection object from the pool. The trigger point is in process 1.1.2, and the code is as follows:
public boolean remove(final T bagEntry) {
// The following two cas operations change from other status to removal status. If either operation succeeds, it will not go to the following warn log
if (!bagEntry.compareAndSet(STATE_IN_USE, STATE_REMOVED) && !bagEntry.compareAndSet(STATE_RESERVED, STATE_REMOVED) && !closed) {
LOGGER.warn("Attempt to remove an object from the bag that was not borrowed or reserved: {}", bagEntry);
return false;
}
// Remove directly from sharedList
final boolean removed = sharedList.remove(bagEntry);
if (!removed && !closed) {
LOGGER.warn("Attempt to remove an object from the bag that does not exist: {}", bagEntry);
}
return removed;
}It should be noted here that only the objects in the sharedList are removed during removal, and the corresponding objects in the cached set in each thread are not removed. Will there be a connection to get them from the cache again at this time? Yes, but it will not be returned. Instead, it will be removed directly. Looking carefully at the border code, it is found that when the status is not idle, it will be removed when it is taken out, and then it can not be taken out. Naturally, the recycling method will not be triggered.
12.5: values
This method has an overloaded method, which is used to return the collection of connected objects in the current pool. The trigger point is in main process 4, and the code is as follows:
public List values(final int state) {
//Filter out the set of objects that meet the status values and return them in reverse order
final List list = sharedList.stream().filter(e -> e.getState() == state).collect(Collectors.toList());
Collections.reverse(list);
return list;
}
public List values() {
//Return all connected objects (note that the clone below is a shallow copy)
return (List) sharedList.clone();
}12.6: reserve
This method simply converts the state value of the connection object from state_ NOT_ IN_ Change use to STATE_RESERVED, the trigger point is still the main process 4, which is used during volume reduction. The code is as follows:
public boolean reserve(final T bagEntry){
return bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_RESERVED);
}12.7: getCount
This method is used to return the total number of connections that meet a certain status value in the pool. The trigger point is main process 5. When expanding the connection pool, it is used to obtain the total number of idle connections. The code is as follows:
public int getCount(final int state){
int count = 0;
for (IConcurrentBagEntry e : sharedList) {
if (e.getState() == state) {
count++;
}
}
return count;
}The above is the main method of ConcurrentBag and the main process of processing connection objects.
13, Summary
Basically, the whole life cycle from production to acquisition to recycling to abandonment of a connection is managed in HikariCP. Compared with the previous Druid implementation, it is very different, mainly the lock free access connection of HikariCP. This article does not involve the description of FastList, because this structure is rarely used from the perspective of connection management, FastList is mainly used to store the statement object generated by the connection object and the connection object cached in the thread; The author's Spring Boot column and Mybatis column have been completed, focusing on the official account [code ape technology column] reply keywords Spring Boot advanced, Mybatis advanced acquisition.
In addition, HikariCP also uses javassist technology to generate the initialization of ProxyConnection during compilation. There is no relevant description here. There are many articles on HikariCP optimization on the Internet, most of which mention the implementation of bytecode optimization, fastList and concurrentbag. This article mainly analyzes the implementation of HikariPool and concurrentbag, To explain what the HikariCP does differently than Druid.
Finally
Recently, I compiled a complete set of "summary of Java core knowledge points". To be honest, as a java programmer, you should take a good look at this material whether you need an interview or not. Kwai won't lose my hand. Many of my fans got the Offer of Tencent's byte express.
Enter[ Java advanced road group ], find the administrator to get Oh -!