Recently, I have been working on the file search function (ElasticSearch for search). After searching the document at the front end, I need to preview the document in the browser and highlight and locate the search keywords. Kkfileview, an open source project selected for document preview, can preview documents well, but it does not have the function of previewing document keyword highlighting. Under the guidance of the leaders of the kkfileview technical exchange group, we know that pdfjs needs to be modified. Please see the specific steps below. [Note: only the highlighting and positioning functions of kkfileview preview in pdf format are realized here]
Key words: ElasticSearch; kkFileView; PDF JS # multi keyword highlighting # keyword positioning
Reference blog: https://blog.csdn.net/a973685825/article/details/81285819
GitHub address of kkfileview: https://github.com/kekingcn/kkFileView
pdf. GitHub address of JS: https://github.com/mozilla/pdf.js
catalogue
One is to obtain highlighted keywords
One is to obtain highlighted keywords
Whatever else, first we need to get the highlighted keywords. For our search, I use_ analyze this API to obtain the word segmentation results of query statements as our highlighted keywords. There are a lot of information about elastic search online, so I won't repeat it here. Form the obtained keywords into a string and separate them with spaces (of course, you can also use other separators, and then pay attention to the separators when converting the string into an array). Name it keyString and pass in the keyword parameters when calling kkfileview (see its official w for how to call kkfileview).
# keyString is a string of keywords separated by spaces. Example: "knowledge map Overview" # Compared with before, keyString is added to the last face 'http://127.0.0.1:8012/onlinePreview?url='+encodeURIComponent(Base64.encode(url)) + keyString;
II. kkfileview pass keywords
kkfileview mainly serves as a connecting link between the preceding and the following. First, get the keyString from ES, and then pass it to PDF js. Let's see how to get it. There are a lot of project files, but rest assured, we only need to modify server / SRC / main / resources / Web / PDF FTL and server / SRC / main / Java / CN / keking / Web / controller / onlinepreviewcontroller Java these two files.
kkfileview through onlinepreviewcontroller The onlinePreview function in the java file gets the parameters in the url, so we need to modify this function to get the keyString. Two modifications are required: 1. Add keyString to the function parameter; 2 add the keyword attribute to the model. For details, see the comments in the code block below.
@RequestMapping(value = "/onlinePreview")
// The parameter passed to this function adds a keyString
public String onlinePreview(String url, String keyword, Model model, HttpServletRequest req) {
String fileUrl;
try {
fileUrl = new String(Base64.decodeBase64(url), StandardCharsets.UTF_8);
} catch (Exception ex) {
String errorMsg = String.format(BASE64_DECODE_ERROR_MSG, "url");
return otherFilePreview.notSupportedFile(model, errorMsg);
}
FileAttribute fileAttribute = fileHandlerService.getFileAttribute(fileUrl, req);
model.addAttribute("file", fileAttribute);
model.addAttribute("keyword", keyword); // Added this line
FilePreview filePreview = previewFactory.get(fileAttribute);
logger.info("Preview Area url: {},previewType: {}", fileUrl, fileAttribute.getType());
return filePreview.filePreviewHandle(fileUrl, model, fileAttribute);
}After modifying the above part, kkfileview has obtained the highlighted keyword. Now you need to pass it to PDF JS, need to modify PDF The script part of the FTL file is actually to get the keywords first, and then pass them to PDF through the url js. Notice the pdfExt here. This is a new folder I created, which will be discussed in part 5.
var url = '${finalUrl}';
var baseUrl = '${baseUrl}'.endsWith('/') ? '${baseUrl}' : '${baseUrl}' + '/';
if (!url.startsWith(baseUrl)) {
url = baseUrl + 'getCorsFile?urlPath=' + encodeURIComponent(url);
}
// First, get the keyword from our model
var keyword = '${keyword}';
// Then add the keyword parameter at the end
// In the source code of kkfileview, there is disabledownload in the parameter, which was deleted by me
// Note the pdfExt here. This is a new folder I created, which will be mentioned later
document.getElementsByTagName('iframe')[0].src = "${baseUrl}pdfExt/web/viewer.html?file=" + encodeURIComponent(url)+ "&keyword="+ keyword;
document.getElementsByTagName('iframe')[0].height = document.documentElement.clientHeight - 10;
III. PDF JS get keywords
pdf.js can get the file address parameters. We first find out where this part of the code is written, and then add the code to get the keyword parameters. pdf.js is in Web / viewer JS this part of the code gets the address of the file.
(function rewriteUrlClosure() {
// Run this code outside DOMContentLoaded to make sure that the URL
// is rewritten as soon as possible.
const queryString = document.location.search.slice(1);
const m = /(^|&)file=([^&]*)/.exec(queryString);
defaultUrl = m ? decodeURIComponent(m[2]) : "";
// Example: chrome-extension://.../http://example.com/file.pdf
const humanReadableUrl = "/" + defaultUrl + location.hash;
history.replaceState(history.state, "", humanReadableUrl);
if (top === window) {
// eslint-disable-next-line no-undef
chrome.runtime.sendMessage("showPageAction");
}
})();Then we just need to follow this example to obtain the keyword parameter. I put the code to obtain the keyword parameter in the getViewerConfiguration function of this file.
function getViewerConfiguration() {
// Added this part of the code
const queryString = document.location.search.slice(1);
const m = /(^|&)keyword=([^&]*)/.exec(queryString);
const keyword = m ? decodeURIComponent(m[2]) : "";
console.log("keyword", keyword);
let errorWrapper = null;
if (typeof PDFJSDev === "undefined" || !PDFJSDev.test("MOZCENTRAL")){
errorWrapper = {
container: document.getElementById("errorWrapper"),
errorMessage: document.getElementById("errorMessage"),
closeButton: document.getElementById("errorClose"),
errorMoreInfo: document.getElementById("errorMoreInfo"),
moreInfoButton: document.getElementById("errorShowMore"),
lessInfoButton: document.getElementById("errorShowLess"),
};
}
// There are too many contents, which are omitted here
}Well, now our PDF JS finally got the keyword. Let's talk about how to highlight the keyword
IV. PDF JS highlight keywords
Now let's look at PDF JS file. Before reading this part, it is strongly recommended to read the content of the article and the first reference blog. As mentioned in the reference blog, our way to highlight keywords is to call PDF JS has its own search function to pass in keywords. Let's see how to do this part.
(1) we need to import keywords into Web / viewer In the input box of id="findInput" in the HTML file, that is, here below.
<div id="findbarInputContainer">
<input id="findInput" class="toolbarField" title="Find" placeholder="Find in document..." tabindex="91" data-l10n-id="find_input">
<div class="splitToolbarButton">
<button id="findPrevious" class="toolbarButton findPrevious" title="Find the previous occurrence of the phrase" tabindex="92" data-l10n-id="find_previous">
<span data-l10n-id="find_previous_label">Previous</span>
</button>
<div class="splitToolbarButtonSeparator"></div>
<button id="findNext" class="toolbarButton findNext" title="Find the next occurrence of the phrase" tabindex="93" data-l10n-id="find_next">
<span data-l10n-id="find_next_label">Next</span>
</button>
</div>
</div>Once the id is found, it is easy to modify the value. I choose to modify it in the getViewerConfiguration function, as shown below
function getViewerConfiguration() {
//Here is the code just added
const queryString = document.location.search.slice(1);
const m = /(^|&)keyword=([^&]*)/.exec(queryString);
const keyword = m ? decodeURIComponent(m[2]) : "";
console.log("keyword", keyword);
let errorWrapper = null;
if (typeof PDFJSDev === "undefined" || !PDFJSDev.test("MOZCENTRAL")) {
errorWrapper = {
container: document.getElementById("errorWrapper"),
errorMessage: document.getElementById("errorMessage"),
closeButton: document.getElementById("errorClose"),
errorMoreInfo: document.getElementById("errorMoreInfo"),
moreInfoButton: document.getElementById("errorShowMore"),
lessInfoButton: document.getElementById("errorShowLess"),
};
}
// This part of code is added to pass the value of keyword to input
document.getElementById("findInput").value = keyword;
// To disable findbar, see the reference blog for specific reasons
document.getElementById("findbar").style.display = "none";
return {
//There are too many contents, which are omitted here
}
}
(2) then we need to handle the value passed to findinput and modify the web / APP JS
async _initializeViewerComponents() {
// ellipsis
//Modify the content of this judgment
if (!this.supportsIntegratedFind) {
this.findBar = new PDFFindBar(appConfig.findBar, eventBus, this.l10n); // Instantiate PDFFindBar
// Get value
const highLightStr = appConfig.findBar.findField.value;
// Convert the string into an array (if the keystring separator passed in when you call kkfileview is not a space, remember to modify it here
const highLightWords = highLightStr.split(" ");
// Pass the array to our newly added function (we'll talk about it in the next step)
wordHighLight(highLightWords);
}
// ellipsis
}(3) then we go to Web / APP JS file, add the function wordHighLight mentioned just now, where the search execution function is called
function wordHighLight(hightLightWords) {
// Copied from reference blog
const evt = {
// Source: pdffindbar, / / the instance of pdffindbar. I'm not sure what it is for?
type: "", // It should be empty by default
// You can jump to the query location by default, which just meets the requirements
query: hightLightWords, // Highlighted keywords
phraseSearch: false, // The whole text matching is supported. If multiple words are matched, the matching can only be false
caseSensitive: false, // The default is false. Case is ignored during search
highlightAll: true, // Set to true to highlight all keywords
// findPrevious: true,
};
PDFViewerApplication.findController.executeCommand("find" + evt.type, {
// Search execution function
query: evt.query,
phraseSearch: evt.phraseSearch,
caseSensitive: evt.caseSensitive,
highlightAll: evt.highlightAll,
findPrevious: evt.findPrevious,
});
}(4) now we need to modify the code to execute the search. We need to highlight multiple keywords (after all, there are often more than one keyword in the search statement), but PDF The search function of JS can only highlight a single keyword, so we need to modify Web / PDF a little_ find_ controller. JS file.
wordHighLight ==> executeCommand ==>_ nextMatch ==> _ calculateMatch ==> _ calculateWordMatch (= = > means calling), let's modify it first_ Calculatematch. See the following code and comments for details.
_calculateMatch(pageIndex) {
let pageContent = this._pageContents[pageIndex];
const pageDiffs = this._pageDiffs[pageIndex];
// We're going to revise it later_ query function
// Note that the previous query was a string, but now it is an array
const query = this._query;
const { caseSensitive, entireWord, phraseSearch } = this._state;
if (query.length === 0) {
// Do nothing: the matches should be wiped out already.
return;
}
if (!caseSensitive) {
pageContent = pageContent.toLowerCase();
// Modified here and added a loop, because the current query is not a string, but an array
for (let i = 0; i < query.length; i++) {
query[i] = query[i].toLowerCase();
}
}
if (phraseSearch) {
this._calculatePhraseMatch(
query,
pageIndex,
pageContent,
pageDiffs,
entireWord
);
} else {
this._calculateWordMatch(
query,
pageIndex,
pageContent,
pageDiffs,
entireWord
);
}
// When `highlightAll` is set, ensure that the matches on previously
// rendered (and still active) pages are correctly highlighted.
if (this._state.highlightAll) {
this._updatePage(pageIndex);
}
if (this._resumePageIdx === pageIndex) {
this._resumePageIdx = null;
this._nextPageMatch();
}
// Update the match count.
const pageMatchesCount = this._pageMatches[pageIndex].length;
if (pageMatchesCount > 0) {
this._matchesCountTotal += pageMatchesCount;
this._updateUIResultsCount();
}
}Then we're going to modify it_ query content
get _query() {
const query = this._state.query;
// The previous query statement was a string, but now it has been changed to an array, so it needs to be processed circularly
if (typeof query === "object" && query.length !== 0) {
for (let i = 0; i < query.length; i++) {
if (query[i] !== this._rawQuery[i]) {
this._rawQuery[i] = query[i];
[this._normalizedQuery[i]] = normalize(query[i]);
}
}
} else {
// This is the original version. In fact, this branch is not used now, because it must be of obj type
if (query !== this._rawQuery) {
this._rawQuery = this._state.query;
[this._normalizedQuery] = normalize(this._state.query);
}
}
return this._normalizedQuery;
}Similarly, because we put this_ Rawquery and {this_ Normalizedquery has become an array type for use, so these two variables need to be defined before use, otherwise an error will be reported. It can be defined in the executeCommand function.
executeCommand(cmd, state) {
if (!state) {
return;
}
const pdfDocument = this._pdfDocument;
if (this._state === null || this._shouldDirtyMatch(cmd, state)) {
this._dirtyMatch = true;
}
this._state = state;
if (cmd !== "findhighlightallchange") {
this._updateUIState(FindState.PENDING);
}
// Added the following two lines
this._rawQuery = new Array(this._state.query.length);
this._normalizedQuery = new Array(this._state.query.length);
this._firstPageCapability.promise.then(
// Too much content, omitted here, not pasted
);
}Then we'll revise it_ The calculateWordMatch function mainly adds a loop
_calculateWordMatch(query, pageIndex, pageContent, pageDiffs, entireWord) {
const matchesWithLength = [];
// Divide the query into pieces and search for text in each piece.
// Changed to a cycle
for (let x = 0; x < query.length; x++) {
const queryArray = query[x].match(/\S+/g);
for (let i = 0, len = queryArray.length; i < len; i++) {
const subquery = queryArray[i];
const subqueryLen = subquery.length;
let matchIdx = -subqueryLen;
while (true) {
matchIdx = pageContent.indexOf(subquery, matchIdx + subqueryLen);
if (matchIdx === -1) {
break;
}
if (
entireWord &&
!this._isEntireWord(pageContent, matchIdx, subqueryLen)
) {
continue;
}
const originalMatchIdx = getOriginalIndex(matchIdx, pageDiffs),
matchEnd = matchIdx + subqueryLen - 1,
originalQueryLen =
getOriginalIndex(matchEnd, pageDiffs) - originalMatchIdx + 1;
// Other searches do not, so we store the length.
matchesWithLength.push({
match: originalMatchIdx,
matchLength: originalQueryLen,
skipped: false,
});
}
}
}
// Prepare arrays for storing the matches.
this._pageMatchesLength[pageIndex] = [];
this._pageMatches[pageIndex] = [];
// Sort `matchesWithLength`, remove intersecting terms and put the result
// into the two arrays.
this._prepareMatches(
matchesWithLength,
this._pageMatches[pageIndex],
this._pageMatchesLength[pageIndex]
);
}At this point, our code will be modified.
V. packaging PDF js
Now we're going to put the revised PDF JS package and put it in kkfileview, and let kkfileview call our modified instead of the default.
(1) package PDF js
Package PDF JS method is written in GitHub readme. Just run gulp generic in terminal.
Run gulp generic in terminal
Package succeeded

(2) kkfileview create a new folder
kkfileview uses the packaged PDF by default JS is placed in the folder server/src/main/resources/static/pdfjs. I created a new folder named pdfExt under server/src/main/resources/static to prepare the modified PDF JS files are packaged here.
(3) copy files
Then it's very simple. Put PDF Copy the contents in the build/generic directory of the JS project to the pdfExt folder created by kkfileview.
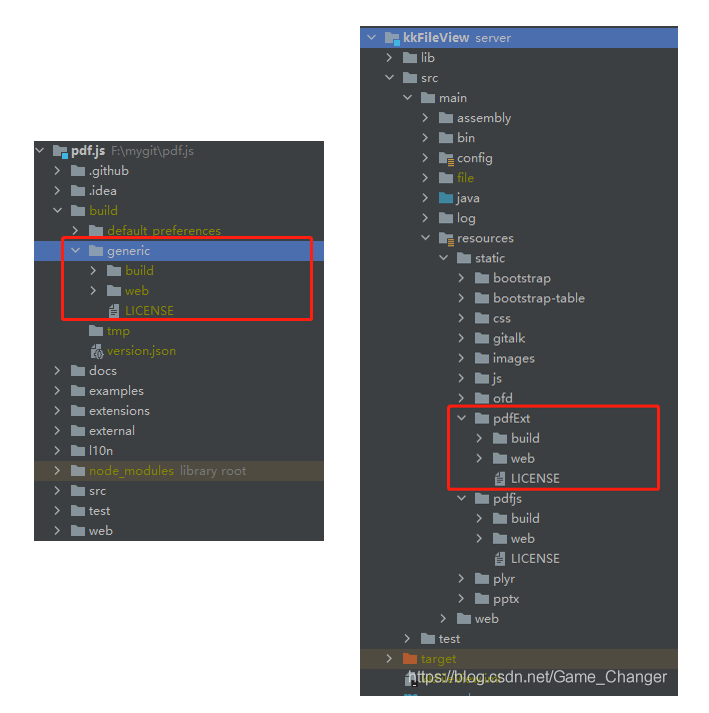
Operation effect
My query statement is "knowledge map"_ The results returned by analyze (that is, the results after word segmentation and other preprocessing of query statements) are "knowledge" and "map". These two words are my highlighted keywords. When you open the preview file, you can see that all words related to "knowledge" and "Atlas" are highlighted. And you can automatically locate the location where the first keyword appears when you open the file.

epilogue
All the modifications are completed here. You can run it to try the effect. The first time to write a blog, please forgive the imperfections and hope to help you. what? You said I only talked about how to achieve highlighting, not how to achieve positioning? It can be found after running, PDF JS has its own search function, which has helped us to locate the keyword. As long as you can successfully transfer the highlighted keyword according to the above method, the problem of keyword positioning will be solved naturally
Finally, I would like to thank the Kaohsiung leaders in kk open source technology exchange group 2 for providing me with ideas for modification and helping me find a reference blog.