0. Introduction
The official java clients of elasticsearch include tranport client and rest high level client, but the operation of index addition, deletion, modification and query is not simple enough. Therefore, we introduce spring data elasticsearch to implement CRUD of index
1. Version correspondence
Before introducing spring data, we should first understand the corresponding relationship between versions. We can spring data official document Found in
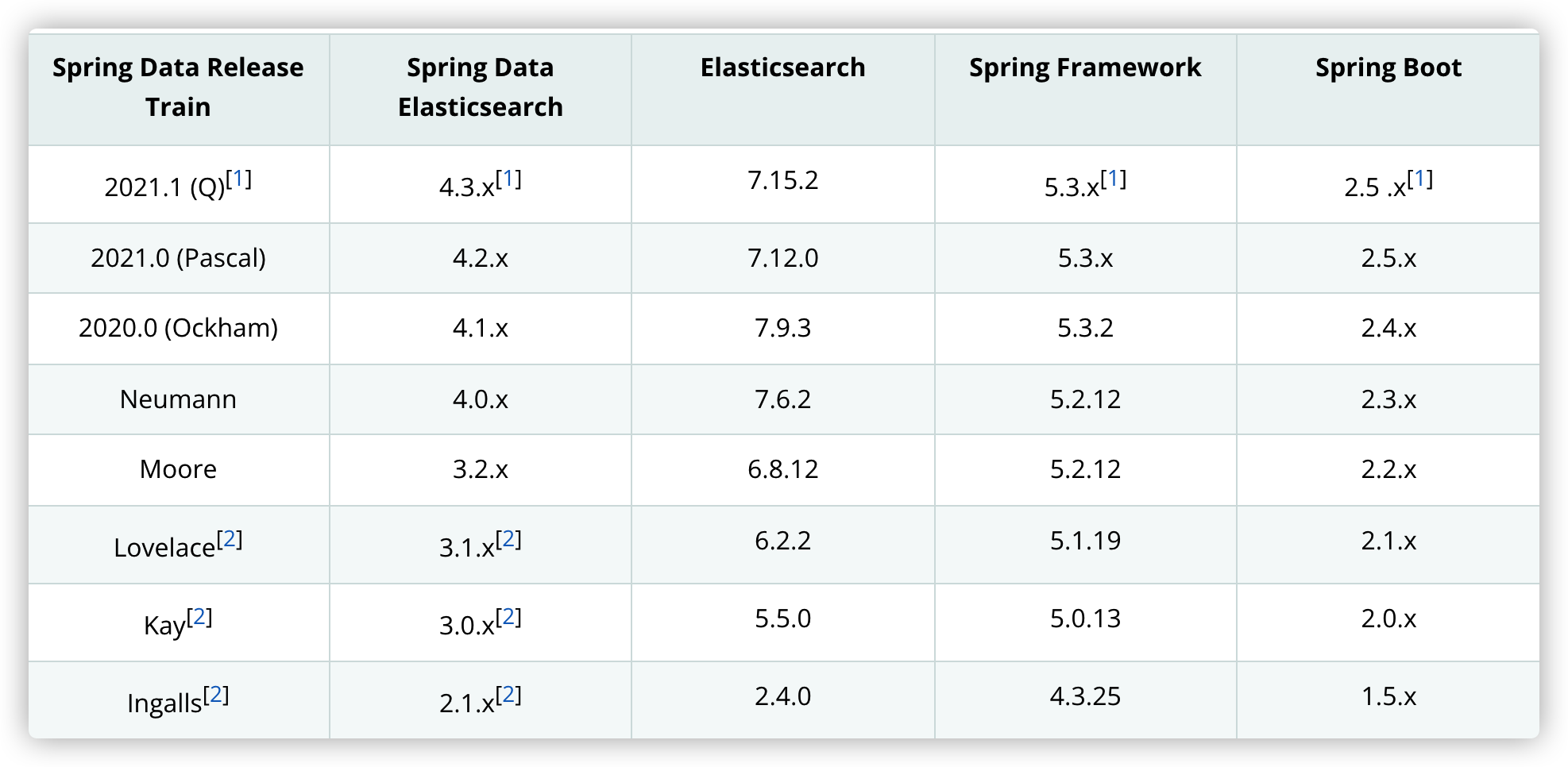
Here, my es uses version 7.14.0, so I need to introduce spring data elasticsearch4 3. X version dependency
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
<version>4.3.0</version>
</dependency>
It should be noted that spring boot also integrates spring data
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
2. Implement CRUD
1. Create entity class
/**
* @author whx
* @date 2022/1/6
*/
@Data
@Document(indexName = "user")
@Setting(
sortFields = {"createTime"},
sortOrders = {Setting.SortOrder.desc},
replicas = 0
)
@NoArgsConstructor
public class UserES implements Serializable {
private static final long serialVersionUID = 1L;
/**
* User ID
*/
@Id
private Long id;
/**
* User code
*/
@Field(type=FieldType.Keyword)
private String code;
/**
* User platform
*/
@Field(type=FieldType.Long)
private Long userType;
/**
* account number
*/
@Field(type=FieldType.Text)
private String account;
/**
* nickname
*/
@Field(type=FieldType.Text)
private String name;
/**
* real name
*/
@Field(type=FieldType.Text)
private String realName;
/**
* mailbox
*/
@Field(type=FieldType.Text)
private String email;
/**
* mobile phone
*/
@Field(type=FieldType.Keyword)
private String phone;
/**
* birthday
*/
@Field(type=FieldType.Date)
private Date birthday;
/**
* Gender
*/
@Field(type=FieldType.Integer)
private Integer sex;
/**
* Role ID
*/
@Field(type=FieldType.Long)
private List<Long> roleIds;
/**
* Direct department ID
*/
@Field(type=FieldType.Keyword)
private List<String> deptIds;
/**
* Position ID
*/
@Field(type=FieldType.Long)
private List<Long> postIds;
/**
* All parent department ID S
*/
@Field(type=FieldType.Long)
private List<String> parentDeptIds;
/**
* Platform type (for wechat users)
*/
@Field(type = FieldType.Keyword)
private String clientId;
/**
* Third party platform Id (for wechat users)
*/
@Field(type= FieldType.Keyword)
private String thirdPlatformUserId;
/**
* PC Bind user ID
*/
@Field(type=FieldType.Long)
private String tenantUserId;
/**
* User source: 0 pc 1 wx
*/
@Field(type=FieldType.Integer)
private Integer userSource;
/**
* tenant
*/
@Field(type=FieldType.Keyword)
private String tenantId;
/**
* Creator
*/
@Field(type=FieldType.Long)
private Long createUser;
/**
* Create Department
*/
@Field(type=FieldType.Keyword)
private String createDept;
/**
* Creation time
*/
@Field(type=FieldType.Date)
private Date createTime;
}
Because I also need to synchronize mysql data to es, I also need to create a transformation method in the UserES class. The entity class conversion here can be written according to your specific needs. The following is for reference only
public static UserES build(User user){
UserES userES = Objects.requireNonNull(BeanUtil.copy(user, UserES.class));
userES.userSource = 0;
if(!StringUtils.isEmpty(user.getRoleId())){
userES.roleIds = java.util.Arrays.stream(user.getRoleId().split(",")).map(Long::parseLong).collect(Collectors.toList());
}
if(!StringUtils.isEmpty(user.getPostId())){
userES.postIds = java.util.Arrays.stream(user.getPostId().split(",")).map(Long::parseLong).collect(Collectors.toList());
}
if(!StringUtils.isEmpty(user.getDeptId())){
userES.deptIds = java.util.Arrays.stream(user.getDeptId().split(",")).collect(Collectors.toList());
}
return userES;
}
public static UserES build(UserWxmini user){
UserES userES = Objects.requireNonNull(BeanUtil.copy(user, UserES.class));
userES.userSource = 1;
userES.name = user.getNickName();
return userES;
}
public static List<UserES> buildList(List<User> list){
return list.stream().map(UserES::build).collect(Collectors.toList());
}
public static List<UserES> buildUserWxList(List<UserWxmini> list){
return list.stream().map(UserES::build).collect(Collectors.toList());
}
2. When you create the repository interface, you can see that you only need to inherit the ElasticsearchCrudRepository interface
/**
* User ES client
* @author whx
* @date 2022/1/6
*/
public interface UserRepositoryElastic extends ElasticsearchCrudRepository<UserES,Long> {
}
3. The ElasticsearchCrudRepository interface has its own common CRUD methods, which we can use directly
Introduce UserRepositoryElastic into the serviceImpl class
4. Common CRUD methods of ElasticsearchCrudRepository interface
deleteById(id); findById(id); findAll(); findAllById(ids); save(new UserES()); existsById(id); count();
3. How to customize methods
3.1 automatically generate derived methods through the syntax of spring data
For example, query by name
public interface UserRepositoryElastic extends ElasticsearchCrudRepository<UserES,Long> {
Page<UserES> findByName(String name,Pageable page);
}
Syntax support
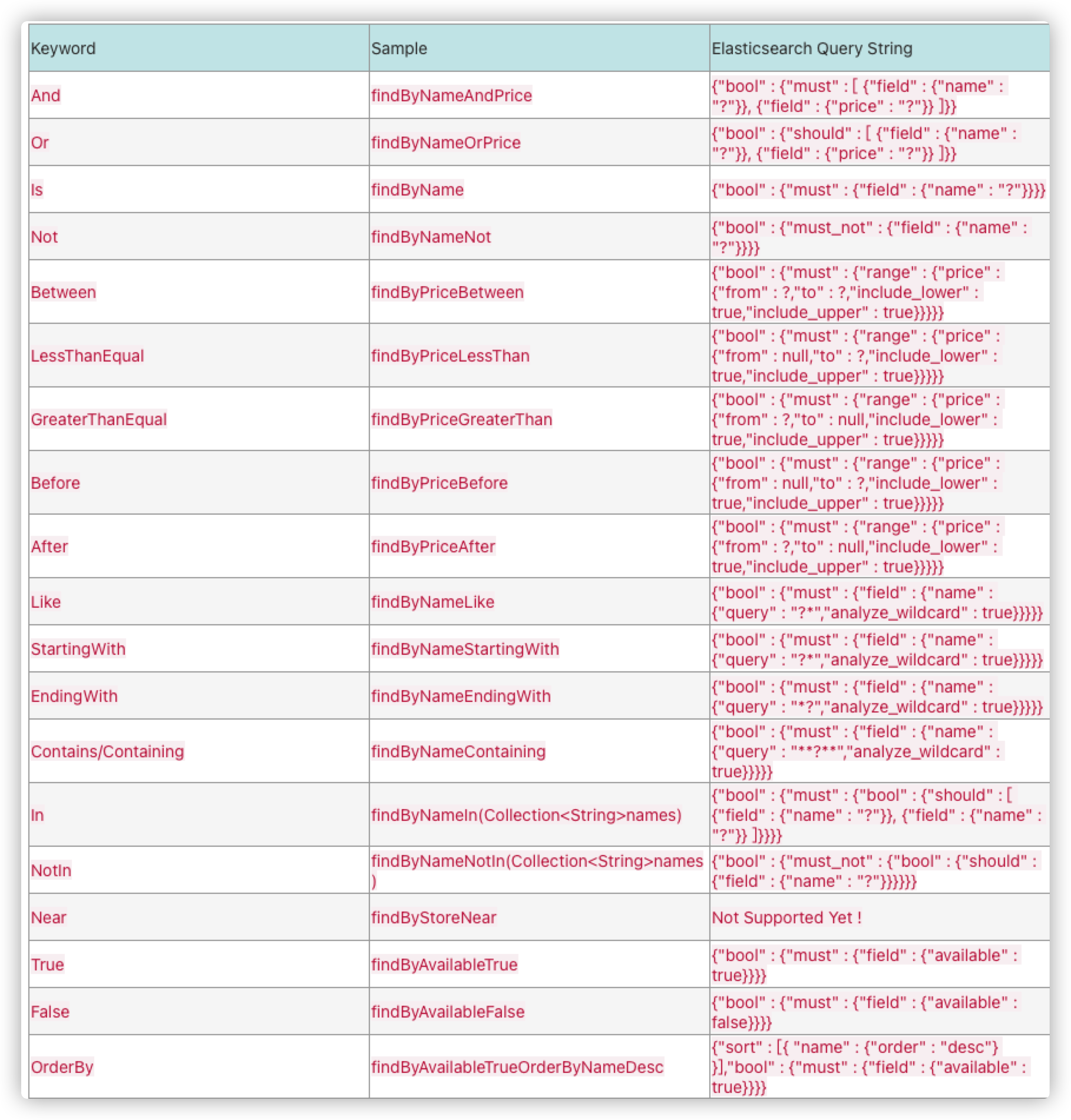
3.2 custom Query through @ Query
Query is the DSL statement of the query,? 0 indicates the first parameter
@Query("{"bool" : {"must" : {"field" : {"name" : "?0"}}}}")
Page<EsProduct> findByName(String name,Pageable pageable);
4. MySQL data into es
4.1 full synchronization of Mysql to es
Full synchronization should only be called once, and subsequent updates are achieved through incremental synchronization
@Service
@AllArgsConstructor
public class UserServiceImpl extends BaseServiceImpl<UserMapper, User> implements IUserService {
private final UserRepositoryElastic userRepositoryElastic;
@Override
@TenantIgnore
public R transferFromMysqlToEs(){
// Query all user data (here is the selectList method of the mybatis plus framework directly called)
List<User> users = baseMapper.selectList(Wrappers.lambdaQuery());
// Synchronize all user data into es
userRepositoryElastic.saveAll(UserES.buildList(users));
return R.success("Operation succeeded");
}
}
4.2 mysql incremental synchronization to es
Incremental synchronization using spring data elasticsearch is to insert operations for es into the original operation code. For example, when adding or modifying user information, synchronize and modify the data in ES
public R<Boolean> submit(User user){
boolean res = this.saveOrUpdate(user);
if(res){
userRepositoryElastic.save(UserES.build(user));
}
return R.data(res);
}
Synchronously delete data in es when deleting
public R remove(List<Long> ids){
baseMapper.deleteBatchIds(ids);
ids.forEach(userRepositoryElastic::deleteById);
return R.success("Delete succeeded");
}
4.3 advantages and disadvantages
Advantages: spring data elasticsearch is used to synchronize data. Because it is implemented based on code, it can realize complex transformation logic without deploying third-party plug-ins.
Disadvantages: the code is highly invasive. If there are many types of business data to be synchronized, a large number of source code modifications are required and the workload is heavy. And it will increase the time-consuming of the original method.
5. Other synchronization schemes for MySQL synchronization to ES
5.1 synchronize mysql to ES through canal
Installation: Synchronize mysql to ES through canal
Advantages: it is implemented based on bin log to ensure performance and no code intrusion. And data conversion can be realized through custom code.
Disadvantages: canal needs to be installed and maintained. For data with consistency requirements, high availability of canal cluster needs to be done well. The historical data before binlog is not enabled cannot be fully synchronized, which can be supplemented by logstash
5.2 synchronize mysql to ES through logstash input JDBC
Installation: Synchronize mysql to ES through logstash input JDBC
Advantages: it is realized by logstash under ELK system. If ELK is used, there is no large deployment cost. It supports full incremental synchronization and does not need to open bin log
Disadvantages: logstash needs to be installed and maintained, and its performance is not as good as canal
5.3 recommended scheme
Logstash input JDBC is used to achieve full synchronization, and canal is used to achieve incremental synchronization.