Model test
Now that you know how to train medical diagnostic models, let's talk about how to test such models.
Next you will learn how to test such a model. You will learn how to use training, validation, and test sets correctly. And in order to evaluate your model, you need a strong ground truth.
When we are doing machine learning, the data set is usually divided into training set and test set.
- Training set: used to develop and select models. In practical application, the training set is further divided into training set and verification set. The training set is used for learning the model, and the verification set is used for super parameter adjustment.
- Test set: used to finally report our results
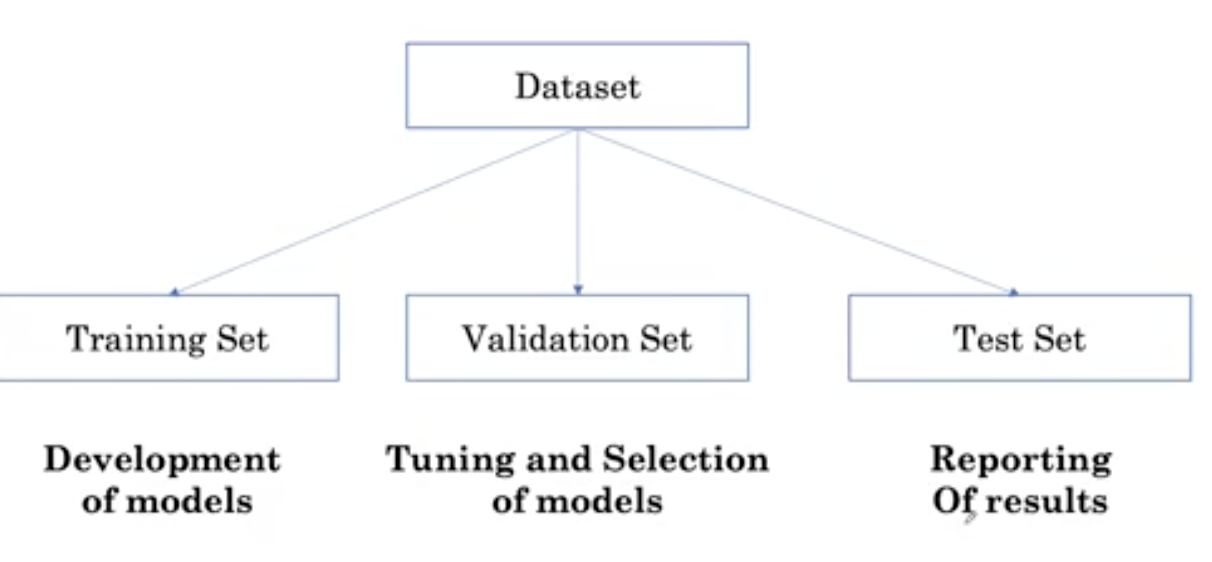
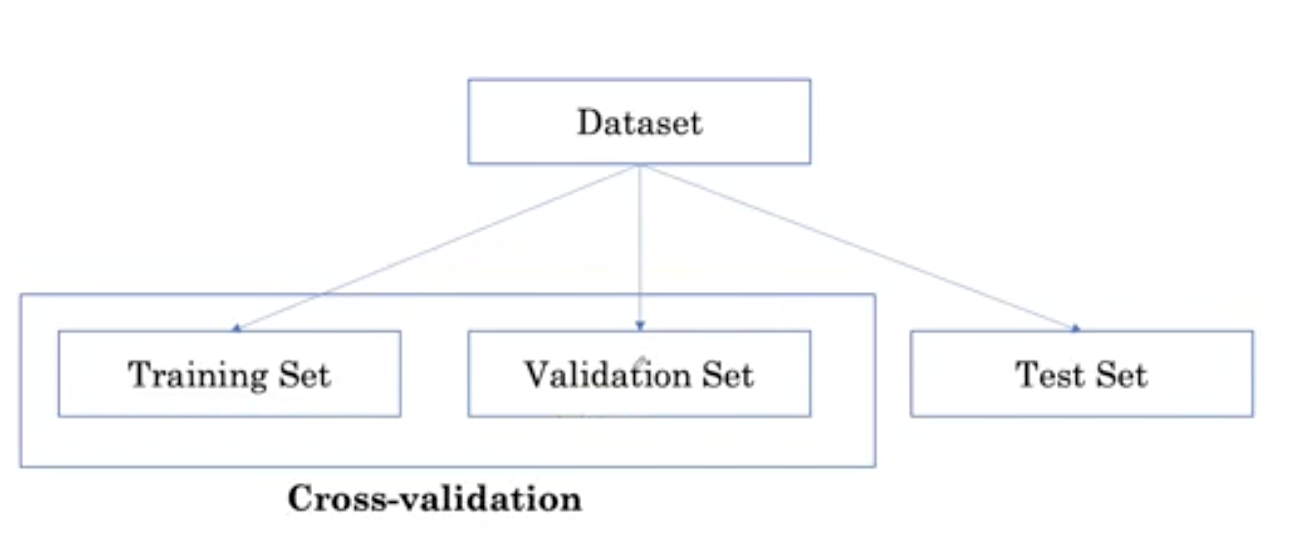
Sometimes, in order to reduce the variability in model performance estimation, a method called cross validation can be used multiple times to separate the training set from the validation set.
These sets sometimes have different names. For example, the verification set can be called adjustment set or depth set, the training set can be called development set, and the test set can be called invalid set, which is even easier to confuse the verification set.
For our purposes, we will adhere to terms such as training, validation, and test sets.
We will discuss three challenges in constructing these data sets in a medical context.
- The first challenge relates to how we make these test sets independent
- The second challenge concerns how we sample them
- The third challenge involves how we set up the ground truth
Let's talk about patient overlap first. Suppose a patient comes for two X-rays, one in June and one in November. Twice, they wore necklaces when taking x-rays.
One of their x-rays was sampled as part of the training set and the other as part of the test.
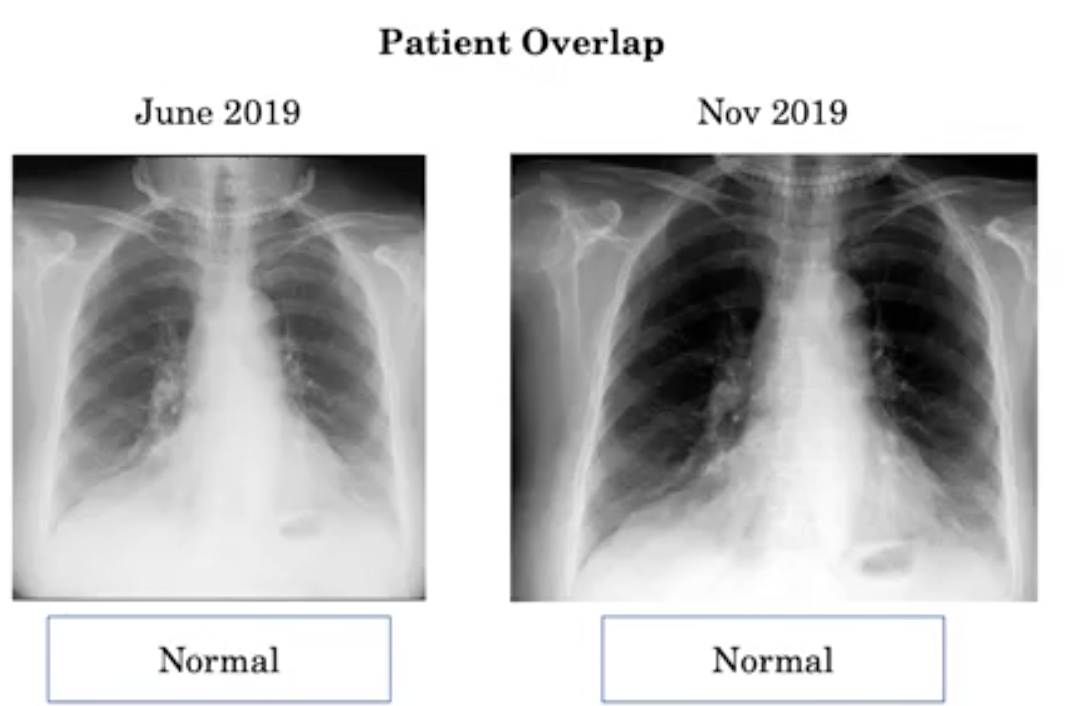
We trained our depth learning model and found that it correctly predicted the x-rays in the test set: normal images.
The problem is that when the model sees a patient wearing a necklace, it actually remembers the necklace around his neck.
This is not an assumption that the deep learning model can inadvertently remember training data, and the model can remember rare or unique training data aspects of patients, such as necklaces.
This can help it get the right answer when testing the same patient. This will cause the performance of the test set to be too optimistic, and we will think that our model is better than the actual one.
Build training set and test set through patients
In order to solve this problem in our dataset, we can ensure that the patient's X-ray appears in only one dataset.

Now, we put the data of the same patient in the training set. If the model remembers the necklace on the patient, it will not help it achieve higher performance in the test set because it can't see the same patient. Let's see how this works for all patients.
When we use the traditional method (dividing the image into different sets) to segment a data set, the image is randomly assigned to one of the sets.
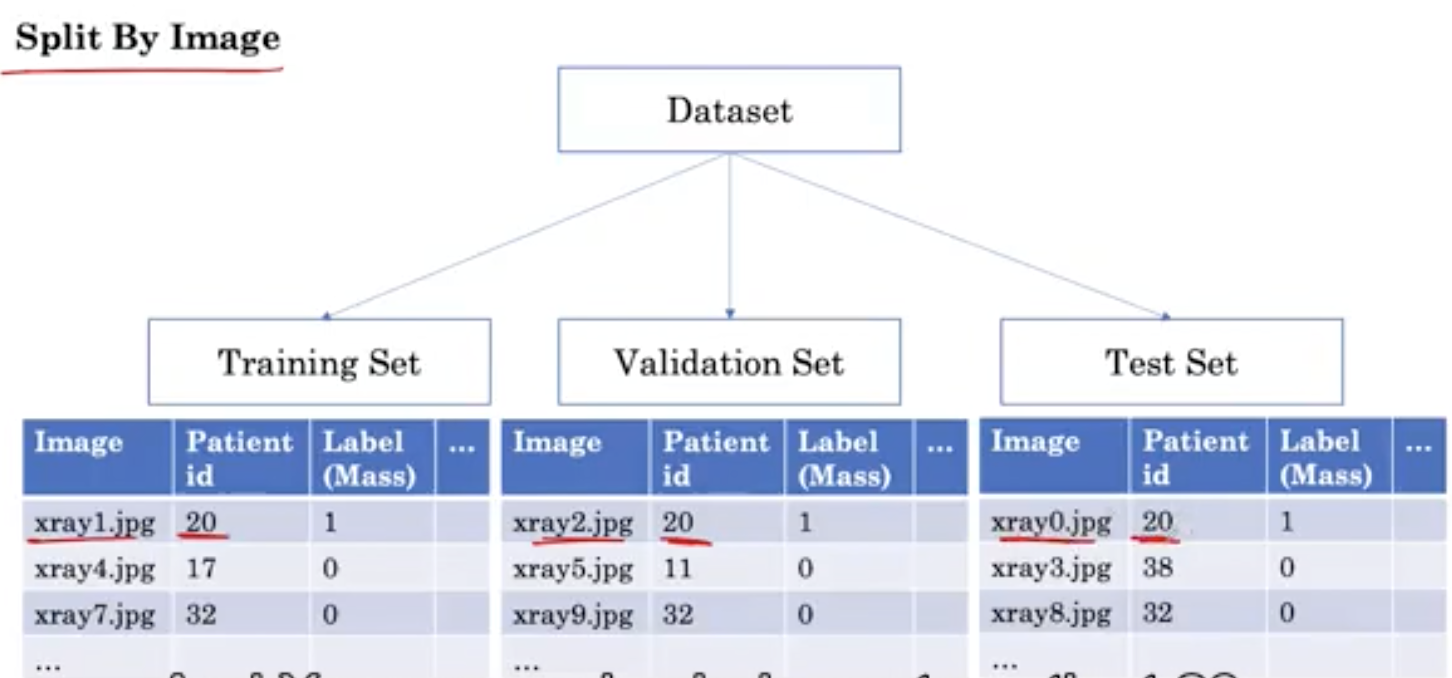
Please note that in this way, we get X-rays from different groups belonging to the same patient. For example, patient 20, xray1 Jpg is part of the training. Xray2.jpg also belongs to patient 20 and is part of the validation. And xray0 Jpg also belongs to patient 20, which is part of the test set.
This is the problem of patient overlap. In contrast, when we split the dataset by patient, all X-rays belonging to the same patient are in the same group.
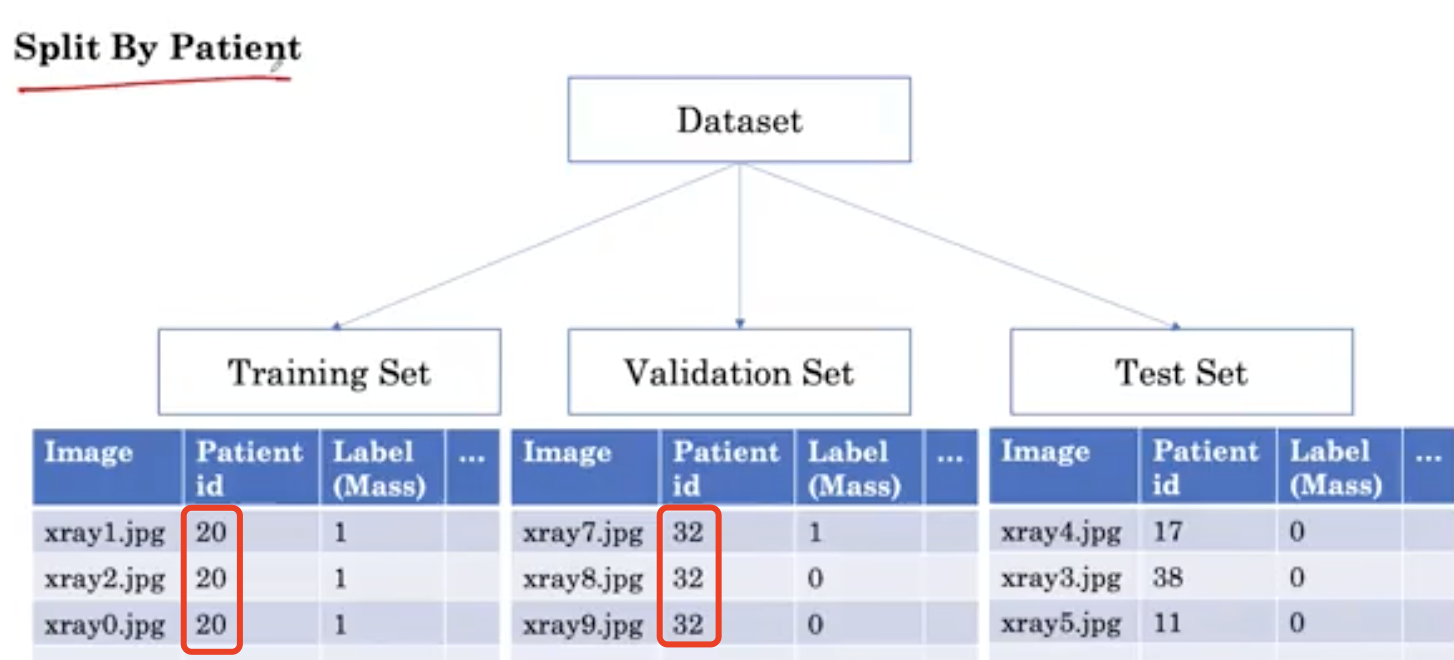
By dividing the data set by patients, we can ensure that there is no patient overlap between the two groups. This covers our solution to the first challenge.
Homework interpretation
Job file: AI4M_C1_W1_lecture_ex_04
If you know about chest-xray8 this data set, you will know that a patient may contain multiple images.
Patient overlap in medical data is a very common problem in machine learning, which is called data leakage.
To determine the overlap of patients in this week's assignment, you not only need to check whether the patient ID appears in both the training set and the test set.
You should also check for patient overlap in the training set and validation set, which is what you will do.
The following is a simple example of how to check and delete patient overlap in training and validation sets.
tips: there is no csv file of training set in the code file I gave. Please download it yourself.
Through 'valid small CSV 'file, you can view the structure of the dataset.
valid_df = pd.read_csv("nih/valid-small.csv")
print(f'There are {valid_df.shape[0]} rows and {valid_df.shape[1]} columns in the validation dataframe')
valid_df.head()

Next, extract the PatientId of train and valid
# Extract patient id's for the training set ids_train = train_df.PatientId.values # Extract patient id's for the validation set ids_valid = valid_df.PatientId.values
Sort ID S using set()
ids_train_set = set(ids_train)
print(f'There are {len(ids_train_set)} unique Patient IDs in the training set')
# Create a "set" datastructure of the validation set id's to identify unique id's
ids_valid_set = set(ids_valid)
print(f'There are {len(ids_valid_set)} unique Patient IDs in the validation set')
+ There are 928 unique Patient IDs in the training set - There are 97 unique Patient IDs in the validation set
The set() function creates an unordered set of non repeating elements, which can be used for relationship testing, delete duplicate data, and calculate intersection, difference, union, etc.
Then, by finding the intersection of sets, we can see whether there are overlapping patients
# Identify patient overlap by looking at the intersection between the sets
patient_overlap = list(ids_train_set.intersection(ids_valid_set))
n_overlap = len(patient_overlap)
print(f'There are {n_overlap} Patient IDs in both the training and validation sets')
print('')
print(f'These patients are in both the training and validation datasets:')
print(f'{patient_overlap}')
+ There are 11 Patient IDs in both the training and validation sets - These patients are in both the training and validation datasets: - [20290, 27618, 9925, 10888, 22764, 19981, 18253, 4461, 28208, 8760, 7482]
Thus, we calculate how many patients overlap in the training set and the verification set, and the overlapping patient ID s.
Next, we will delete them in the training set or verification set. We choose to delete the verification set, or you can choose to delete the training set.
The method is to find those row indexes of overlapping patientids, and then delete the row.
train_overlap_idxs.extend(train_df.index[train_df['PatientId'] == patient_overlap[idx]].tolist()) valid_overlap_idxs.extend(valid_df.index[valid_df['PatientId'] == patient_overlap[idx]].tolist()) valid_df.drop(valid_overlap_idxs, inplace=True)
Congratulations!
You have solved the first challenge of data set!
Homework interpretation only introduces some key points, and you need to do your homework for a deeper understanding.
Welcome to the next content~~~
The article continues to update, and can focus on the latest development of WeChat official account [medical image AI], a official account of the frontier technology in medical image processing. Stick to practice, take you to do projects, play competitions and write papers. All original articles provide theoretical explanations, experimental codes and experimental data. Only through practice can we grow faster, pay attention to us, learn and progress together~
I'm Tina. I'll see you in the next blog~
Work during the day and write at night
If you think it's well written, finally, please praise, comment and collect. Or triple click
