Original link: https://blog.cyfan.top/p/c0af86bb.html
As the leader of the front-end revolution, ServiceWorker is known as the front-end black technology without boasting. This article will explain how to skillfully use it to achieve some seemingly unimaginable things.
<!--more-->
This article will be continuously updated from January 8, 2022. Current status: updating
Cause - huge building collapse
On December 20, 2021, at the end of the old year, a JSdelivrSSL certificate error slowly became a hot spot in the v2ex forum.
JSD had been abnormal for some time due to various reasons, so we didn't catch a cold about it Just when people think this is just the annual menstrual pain of JSdelivr, send an issue, and it will be fine after a period of time Official disclosure: JSDelivr had lost their ICP license
It can be seen that in the past few years, when people found the unparalleled effect of JSD on individual domestic acceleration owners, various abuse methods emerged one after another: the drawing bed was popular for a while, nine times out of ten domestic search engine JSdelivr was used as the drawing bed, and even PicGo plug-in produced Github+JSdelivr drawing bed; More aggressively, it directly makes a video bed, and even develops a set of ts slicing m3u8 one-stop service in order to break through the 20M limit of a single file; As a demon, it hosts many scripts and rule sets that break through network censorship; Those who seek death add a lot of political and religious sensitivities. Some even don't deserve to be called religion. They are directly cheating money
jsd doesn't release license terms, but it doesn't stop the process of white whoring army. In the wool army, as long as you are free and public welfare, you must do a good job in the results of being collected and exploded. But the premise of collecting wool is that the sheep are still alive. If the sheep are collected and dead, where will the wool be collected by the kings?
In any case, JSDelivr decided to set the node to NearChina. It is certain that we can't enjoy the pleasure of simultaneous acceleration of both domestic and foreign materials for a long time recently. In other words, jsd has been permanently put in the cold palace in China.
Turning to China, there are not many substitutes for jsd. As early as I wrote Thousand layer routine of drawing bed I try to imagine what we should use when jsd is not available. Finally, I gave a perfect answer - npm drawing bed. The advantages are that there are many images, fast speed, loose license terms, and obvious disadvantages. You need to install node and upload it with a special client.
Then things gradually become complicated. How should we choose a reasonable CDN accelerator.
At this time, I think of the front-end black technology Serviceworker. Yes, in this case, SW is the most ingenious. However, it can automatically select the best CDN in the background, and even use black in black promise Any hit a beautiful parallel punch. After two days of improvement, I finally wrote a set of SW scripts with offline accessibility, backup, CDN optimization and tracking statistics. SW used by this blog
Next, I'll talk about the wonderful use of ServiceWorker from the beginning.
Before Start
What Is The ServiceWorker
The online explanation of SW is vague. Here, I define it as a server in the user's browser, which is powerful enough to be heinous. Yes, you should be able to see this gap in the next two pictures:
In the first picture, the relationship between the user and the server is as straight as a telegraph pole. The server will give back what the user wants.
In the second figure, no matter which server the user sends a request to on the page controlled by ServiceWorker, the process will be captured by SW. SW can simply request the server as if it does not exist and return the content that should be returned [transparent agent]; You can also fabricate and modify the content returned by the current server at will [request modification result]; You can even point the request to another server and return the content that should not be returned by this server [grafting flowers and trees]; Of course, SW can also directly return the files already stored locally, and even return [offline access accessibility] when offline.
Because SW is too powerful for manipulating user pages, it is designed not to make cross domain requests, SW scripts must run under the same domain name, HTTPS conditions, and not to manipulate DOM and BOM. Similarly, SW is specially designed to be completely asynchronous in order to avoid blocking and delay. These points will be described later.
Of course, developers are the most important. In order to facilitate local debugging, the local addresses localhost and 127.0.0.1 are trusted by the browser and are allowed to run serviceworker in a non HTTPS manner.
What Relationship Between ServiceWorker and PWA
When many people see SW, their first reaction is PWA, that is, progressive Web applications. In fact, SW is indeed the core and soul of PWA, but the main role of SW in PWA is to cache files for offline access. The ingenious use of SW is not fully displayed.
SW can be completely separated from PWA. Of course, PWA can not be separated from SW:)
And WorkBox ?
WorkBox is a SW based cache controller developed by Google. Its main purpose is to facilitate the maintenance of PWA. The core is still SW, but it is still not as customized as the original SW(
Why Not WorkBox ?
First of all, there is no need to use PWA for blogs. It is sufficient to have SW as middleware. Meanwhile, WorkBox can only simply cache data and cannot intercept tampering requests. In particular, it can not accurately grasp the cache of each resource, and the degree of customization is not high.
Write your own SW and the pattern will open
Start From Zero
Install / install
First of all, the essence of SW is a JS script. To install it, you must go through an html. After all, JS can only run in the DOM context if you get html.
Peel off the layer by layer bonus, and the installed code is only one line
navigator.serviceWorker.register('/sw.js')Where, / SW JS is where the ServiceWorker script is located. Due to security, you cannot load cross domain SW.
For example, the current page is https://blog.cyfan.top , the following loading locations are allowed
/sw.js https://blog.cyfan.top/sw.js
The following loads are not allowed:
http://blog.cyfan.top/sw.js# non HTTPS https://cyfan.top/sw.js# different domain names are considered as cross domain https://119.91.80.151:59996/sw.js# although it is the same file but not the same domain name, it is regarded as cross domain ./sw.js#It is easy to cause inconsistency in the acquisition path of SW script
Before loading, we'd better judge whether the dom is loaded or not, otherwise installing sw may cause the dom to get stuck
After loading, the register function will return a Promise. Since most front ends are not suitable for asynchronous, we usually use synchronous mode then() and catch() to get whether the load was successful.
In order to judge whether the script can be loaded, we also need to judge whether there is the attribute 'serviceWorker' in navigator.
After SW is installed, the page needs to be refreshed before it can be slaughtered by SW. At the same time, in order to avoid the impact of browser cache, I usually use the method of modifying search to refresh strongly, rather than through the reload function. Similarly, in order to avoid the embarrassment of refreshing just after installation, it is recommended to delay refreshing by one second with setTimeout.
The simple complete installation code is as follows:
<script>
window.addEventListener('load', async () => {
navigator.serviceWorker.register(`/sw.js?time=${new Date().getTime()}`)
.then(async reg => {
//The installation is successful. It is recommended to strongly refresh here to execute SW immediately
if (window.localStorage.getItem('install') != 'true') {
window.localStorage.setItem('install', 'true');
setTimeout(() => {
window.location.search = `?time=${new Date().getTime()}`
}, 1000)
}
}).catch(err => {
//If the installation fails, the error message will be passed by err
})
});
</script>Once refreshed, the world becomes a turtle in a jar of ServiceWorker. Next, it's time to officially launch the SW script.
SW initialization / Installations
First, embarrassingly open an empty cache list:
const CACHE_NAME = 'ICDNCache';//Can be the Cache version number, but this may cause Cache redundancy to accumulate let cachelist = [];
The cachelist is filled with the pre cached web address, such as the error page returned when offline. It is not appropriate to add too many websites here. Please name @ Akilar here.
Here, I suggest caching only the content displayed on the offline page:
let cachelist = [
'/offline.html',
'https://npm.elemecdn.com/chenyfan-os@0.0.0-r6'
];Enable this cache space during sw installation:
self.addEventListener('install', async function (installEvent) {
self.skipWaiting();
installEvent.waitUntil(
caches.open(CACHE_NAME)
.then(function (cache) {
console.log('Opened cache');
return cache.addAll(cachelist);
})
);
});Since SW has no way to access DOM at all, it should not use window for global variables, but self to refer to itself.
The listener addEventListener will listen to install, that is, this code will only run when the script is first installed and updated
The function of skipWaiting is to promote the new version sw to skip the waiting stage and be active directly.
The status of SW (waiting, installing, activating) will be explained in detail later.
installEvent.waitUntil is used to directly end the waiting of the installation process and open the cache space in the background.
cache.addAll will directly get all the URLs in the cachelist and cache them directly to the CacheStorage. If there are too many URLs here, all URLs will be madly requested when the page is loaded (for example, 1k)
Now, SW initialization is complete. Next, I'll talk about how SW captures requests for pages.
Capture request / Fetch Event
Add listener / AddEventListener
self.addEventListener('fetch', async event => {
event.respondWith(handle(event.request))
});
const handle = async(req)=>{
//do something
}The first line is very simple. Bind a listener to listen to the fetch event, that is, the web page obtains a request from the server, which is equivalent to the XMLHTTPRequest on the front end
event.respondWith is to set the returned content, give it to the handle main function for processing, and pass the parameter event Request. This is a Request object, which contains the details of the Request.
Next, let's start actual combat.
All of the following are modified for handle
Transparent Proxy
As the name suggests, the role of this actual script is to all the current traffic of SW agent, but it will not be modified, as if SW does not exist.
const handle = async(req)=>{
return fetch(req)
}The fetch function is equivalent to ajax or XMLHTTPRequest in the front end. It is used to initiate a request and obtain a return value. Because sw cannot access window, ajax or XMLHTTPRequest cannot be used in sw. Meanwhile, fetch is an asynchronous function. Calling it directly will return a Promise.
fetch can only pass the Requset object, which has two parameters (url,[option]). The first parameter is the web address and the second parameter is the content of the Request, such as body or header.
This script is applicable to the replacement script for uninstalling ServiceWorker. Because sw will not actively uninstall when it is unable to pull the new version, it still runs. Just fill in a transparent agent sw.
Since the SW cold start [i.e. after the page is closed, the SW] is in a suspended state and is read from the hard disk, this will cause a slight performance delay of ~ 10ms for the first request.
Tamper request / Edit Requset
For an image, sometimes the server will be abnormal so that you must use the POST protocol to obtain it. At this time, it is most convenient to tamper with it with SW.
const handle = async (req) => {
if ((req.url.split('/'))[2].match('xxx.com')) {
//xxx.com is the domain name of the picture
return fetch(req.url, {
method: "POST"
})
}
return fetch(req)
}Note that in ServiceWorker, the header header cannot modify the referer and origin, so this method cannot bypass the anti theft chain of sina map bed
Tamper response / Edit Response
This example will detect the returned content. If it is html, all "TEST" will be replaced with "ship"
const handle = async (req) => {
const res = await fetch(req)
const resp = res.clone()
if (!!resp.headers.get('content-type')) {
if (resp.headers.get('content-type').includes('text/html')) {
return new Response((await resp.text()).replace(/TEST/g, 'SHIT'), {
headers: resp.headers,
status: resp.status
})
}
}
return resp
}const resp = res.clone() because once the body of the Response is read, the body will be locked and can no longer be read. Clone () can create a copy of the Response for processing.
resp. headers. Get ('content type ') determines whether the response contains text/html by reading the header of the response. If so, read the response in the form of text() asynchronous flow, then replace the response content regularly, and restore the header and response Code.
The returned content must be a Response object, so new Response constructs a new object and returns it directly. Mismatched html headers will directly the transparent proxy intact.
Graft Request To Another Server
unpkg.zhimg.com is unpkg Com. This script will put all unpkg Com traffic is directly intercepted to unpkg zhimg. COM, for CDN acceleration in Chinese mainland.
Since the npm image is fixed in the GET Request mode and there are no other authentication requirements, it is not necessary to restore other Request data.
const handle = async (req) => {
const domain = req.url.split('/')[2];
if (domain.match("unpkg.com")) {
return fetch(req.url.replace("https://unpkg.com", "https://zhimg.unpkg.com"));
}
else {
return fetch(req)
}
}domain.match captures whether the domain name needs to be replaced in the request. After checking it, replace the domain name directly. If there is no match, the transparent agent will go away directly.
Parallel request
Another big black technology in SW is on the stage = > promise Any, this function has two other derived brothers promise all&Promise. race. Now I will briefly introduce these three methods
Promose.all
When all promises in the list are resolved, i.e. successful, this function will return resolve. As long as one returns reject, the whole function will reject.
Promise.all([
fetch('https://unpkg.com/jquery'),
fetch('https://cdn.jsdelivr.net/npm/jquery'),
fetch('https://unpkg.zhimg.com/jquery')
])This function will request three URLs. When each URL is linked, the whole function will return a list:
[Response1,Response2,Response3]
When any fetch fails, that is, reject, the whole promise All functions will reject directly and report an error.
This function can detect network connectivity. Due to parallel processing, it is much more efficient than the previous loop.
This is a test to test the network connectivity at home and abroad.
Promise is not used All code and effect:
const test = async () => {
const url = [
"https://cdn.jsdelivr.net/npm/jquery@3.6.0/package.json",
"https://unpkg.com/jquery@3.6.0/package.json",
"https://unpkg.zhimg.com/jquery@3.6.0/package.json"
]
flag = true
for (var i in url) {
try {
const res = await fetch(url[i])
if (res.status !== 200) {
flag = false
}
}catch(n){
return false
}
}
return flag
}
With a loop, await will block the loop until the next request is completed. If any url cannot be connected for a long time, it will lead to a very long waste of detection time.
const test = () => {
const url = [
"https://cdn.jsdelivr.net/npm/jquery@3.6.0/package.json",
"https://unpkg.com/jquery@3.6.0/package.json",
"https://unpkg.zhimg.com/jquery@3.6.0/package.json"
]
return Promise.all(url.map(url => {
return new Promise((resolve, reject) => {
fetch(url)
.then(res => {
if (res.status == 200) {
resolve(true)
} else {
reject(false)
}
})
.catch(err => {
reject(false)
})
})
}
)).then(res => {
return true
}).catch(err => {
return false
})
}
Promise.all requests all URLs almost instantaneously. The requests are parallel. Each request will not block other requests. The total time spent by the function is the longest request time.
Promise.race
This function is also executed in parallel, but unlike all, as long as any function is completed, it will return immediately, whether it is reject or resolve.
This function is more suitable for requesting some results that do not care at the same time, as long as the access is reached, such as statistics, check-in and other application scenarios.
Promise.any
This function is very useful. Its function is similar to race, but the difference is that any will also detect whether the result is resolve d. After parallel processing, as long as any one returns correctly, it will directly return the fastest request result. The error returned will be ignored directly. reject will be returned unless all requests fail
This is a package that requests jquery at the same time JSON code, which will request from four images at the same time:
const get_json = () => {
return new Promise((resolve, reject) => {
const urllist = [
"https://cdn.jsdelivr.net/npm/jquery@3.6.0/package.json",
"https://unpkg.com/jquery@3.6.0/package.json",
"https://unpkg.zhimg.com/jquery@3.6.0/package.json",
"https://npm.elemecdn.com/jquery@3.6.0/package.json"
]
Promise.any(urllist.map(url => {
fetch(url)
.then(res => {
if (res.status == 200) {
resolve(res)
} else {
reject()
}
}).catch(err => {
reject()
})
}))
})
}
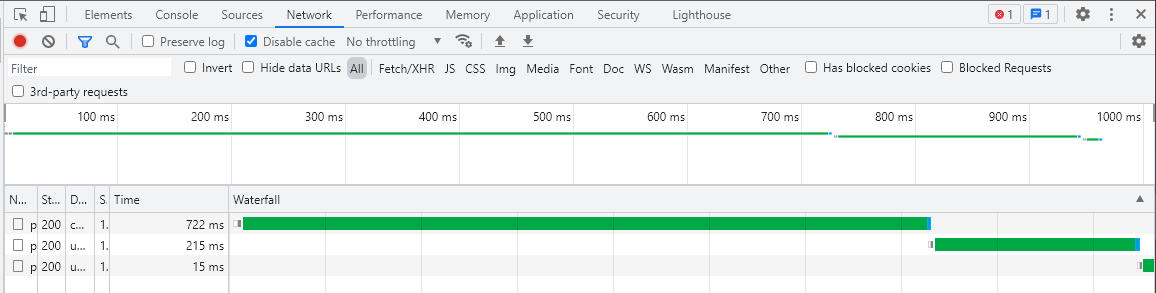
console.log(await(await get_json()).text())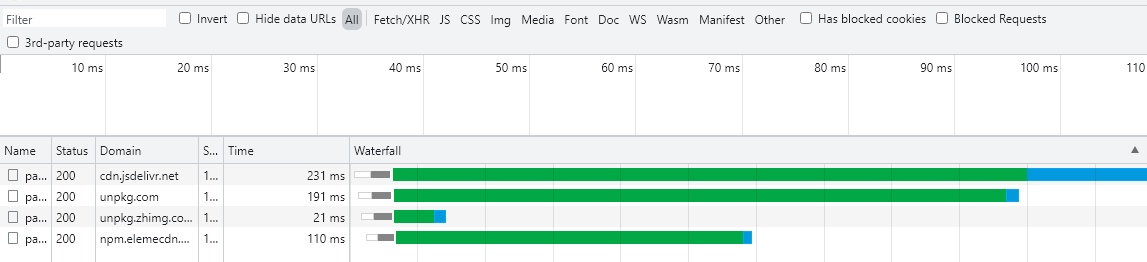
The function will return the data in json up and down in 21ms.
The advantage of this function is that it can judge which image plays the fastest on the user's client, and ensure that the user can reach the maximum speed every time. At the same time, the crash of any mirror station will not have much impact, and the script will automatically pull information from other sources.
This request will not fail unless all sources are blown up.
However, we will additionally find that after knowing that the image returns to the latest version, the remaining requests continue, but are not used.
This will block the number of concurrent threads in the browser and cause additional traffic waste. So we should interrupt the rest of the requests after any of them is completed.
fetch has an abort object. As long as new AbortController() specifies the controller at the beginning and the controller's signal in init, it can be marked as the function to be interrupted, and finally controller Abort() to interrupt.
Then, many students will start to write this:
const get_json = () => {
return new Promise((resolve, reject) => {
const controller = new AbortController();
const urllist = [
"https://cdn.jsdelivr.net/npm/jquery@3.6.0/package.json",
"https://unpkg.com/jquery@3.6.0/package.json",
"https://unpkg.zhimg.com/jquery@3.6.0/package.json",
"https://npm.elemecdn.com/jquery@3.6.0/package.json"
]
Promise.any(urllist.map(url => {
fetch(url,{
signal: controller.signal
})
.then(res => {
if (res.status == 200) {
controller.abort();
resolve(res)
} else {
reject()
}
}).catch(err => {
reject()
})
}))
})
}
console.log(await(await get_json()).text())But soon, you will find that it reports an error: Uncaught DOMException: The user aborted a request, And there is no data output.
Let's look at the Network tab:
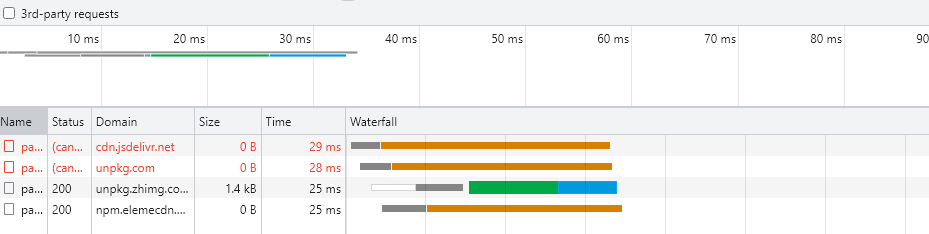
Among them, it is known that it returns the fastest, but it does not return the complete file. The source file is 1.8KB, but it only returns 1.4KB. This also directly leads to the fail of the whole function.
The reason is that the fetch function resolve s the Response immediately after obtaining the Response, but the body does not download it at this time, that is, the return of the fetch is based on the status rather than the Response content. When the fetch has obtained the complete status code, it immediately throws the Response to the next pipeline function, and the status is correct, abort interrupts all requests including this fetch, and the fetch directly does not work properly.
My personal approach is to read the arrayBuffer and block the fetch function until the whole file is downloaded. The function name is PauseProgress
const get_json = () => {
return new Promise((resolve, reject) => {
const controller = new AbortController();
const PauseProgress = async (res) => {
return new Response(await (res).arrayBuffer(), { status: res.status, headers: res.headers });
};
const urllist = [
"https://cdn.jsdelivr.net/npm/jquery@3.6.0/package.json",
"https://unpkg.com/jquery@3.6.0/package.json",
"https://unpkg.zhimg.com/jquery@3.6.0/package.json",
"https://npm.elemecdn.com/jquery@3.6.0/package.json"
]
Promise.any(urllist.map(url => {
fetch(url, {
signal: controller.signal
})
.then(PauseProgress)
.then(res => {
if (res.status == 200) {
controller.abort();
resolve(res)
} else {
reject()
}
}).catch(err => {
reject()
})
}))
})
}
console.log(await(await get_json()).text())
Here, the body of the res is read asynchronously through the arrayBuffer() method, read it as a binary file, create a new Response, restore the state and header, and then throw it to the pipeline function for synchronous processing.
Here, we realize violent concurrency by exchanging traffic for speed. A highly available SW load balancer is also obtained.
This function can be written in SW as follows:
//...
const lfetch = (urllist) => {
return new Promise((resolve, reject) => {
const controller = new AbortController();
const PauseProgress = async (res) => {
return new Response(await (res).arrayBuffer(), { status: res.status, headers: res.headers });
};
Promise.any(urllist.map(url => {
fetch(url, {
signal: controller.signal
})
.then(PauseProgress)
.then(res => {
if (res.status == 200) {
controller.abort();
resolve(res)
} else {
reject()
}
}).catch(err => {
reject()
})
}))
})
}
const handle = async (req) => {
const npm_mirror = [
'https://cdn.jsdelivr.net/npm/',
'https://unpkg.com/',
'https://npm.elemecdn.com/',
'https://unpkg.zhimg.com/'
]
for (var k in npm_mirror) {
if (req.url.match(npm_mirror[k]) && req.url.replace('https://', '').split('/')[0] == npm_mirror[k].replace('https://', '').split('/')[0]) {
return lfetch((() => {
let l = []
for (let i = 0; i < npm_mirror.length; i++) {
l.push(npm_mirror[i] + req.url.split('/')[3])
}
return l
})())
}
}
return fetch(req)
}Cache control / cache
Persistent cache / Cache Persistently
Most of the traffic from CDN is persistent. Therefore, if we directly fill the file into the cache after obtaining it, and then access it directly from the local cache, it will greatly improve the access speed.
const handle = async (req) => {
const cache_url_list = [
/(http:\/\/|https:\/\/)cdn\.jsdelivr\.net/g,
/(http:\/\/|https:\/\/)cdn\.bootcss\.com/g,
/(http:\/\/|https:\/\/)zhimg\.unpkg\.com/g,
/(http:\/\/|https:\/\/)unpkg\.com/g
]
for (var i in cache_url_list) {
if (req.url.match(cache_url_list[i])) {
return caches.match(req).then(function (resp) {
return resp || fetch(req).then(function (res) {
return caches.open(CACHE_NAME).then(function (cache) {
cache.put(req, res.clone());
return res;
});
});
})
}
}
return fetch(req)
}cache_url_list lists all domain names to be matched (including http/https headers to avoid killing other URLs by mistake), and then for starts to traverse the list. If the URL matches, it starts to return to the cache.
cache is similar to key / value. As long as there is a corresponding Request(KEY), the Response(VALUE) of the response can be matched.
caches.match(req) will try to get the value by matching the requested url in the CacheStorage, then throw it to the pipeline synchronization function then, and pass the parameter resp to the value matched by the Cache.
At this time, the pipeline will try to return resp. If resp is null or undefined, i.e. the corresponding cache cannot be obtained, the fetch operation will be executed. After the fetch is successful, the CacheStorage will be open ed and put into the cache. At this time, if the fetch fails, an error will be reported directly and the cache will not be written.
The next time the same URL is obtained, the matching value in the cache will no longer be a blank value. At this time, the fetch does not execute and directly returns to the cache, which greatly improves the speed.
Since the cdn of npm is not persistent for the latest cache, we'd better judge whether the url version ends with @ latest.
const is_latest = (url) => {
return url.replace('https://', '').split('/')[1].split('@')[1] === 'latest'
}
//...
for (var i in cache_url_list) {
if (is_latest(req.url)) { return fetch(req) }
if (req.url.match(cache_url_list[i])) {
return caches.match(req).then(function (resp) {
//...
})
}
}Offline cache / Cache For Offline
For blogs, not all content is invariable. Traditional PWA uses SW update to refresh the cache at the same time, which is not flexible enough. At the same time, there are great loopholes in the version number management of refreshing the cache, and long-time access is easy to cause huge cache redundancy. Therefore, for blog caching, we should ensure that users get the latest version every time, but also ensure that users can see the content of the last version when they are offline.
Therefore, for blogs, the strategy should be to get the latest content first, then update the local cache, and finally return the latest content; When offline, trying to access the latest content will fall back to the cache. If there is no cache, it will fall back to the error page.
Namely:
Online: launch Request => launch fetch => to update Cache => return Response Offline: launch Request => obtain Cache => return Response
const handle = async (req) => {
return fetch(req.url).then(function (res) {
if (!res) { throw 'error' } //1
return caches.open(CACHE_NAME).then(function (cache) {
cache.delete(req);
cache.put(req, res.clone());
return res;
});
}).catch(function (err) {
return caches.match(req).then(function (resp) {
return resp || caches.match(new Request('/offline.html')) //2
})
})
}If (! RES) {throw 'error'} if there is no return value, an error will be thrown directly. It will be captured by the following Catch and returned to the cache or error page
return resp || caches.match(new Request('/offline.html')) returns the content obtained from the cache. If not, it returns the wrong page from the cache. Here is offline HTML should be cached at the beginning
Persistent storage
Since there is no window in SW, we cannot use localStorage and sessionStorage. SW script will lose the original data when all pages are closed or overloaded. Therefore, if we want to use persistent storage, we can only use CacheAPI and IndexdDB.
IndexdDB
This structure table type is similar to SQL and can store JSON objects and data contents, but version update and its operation are very troublesome, so this article will not explain it too much.
CacheAPI
It was originally used to cache responses, but with its own characteristics, we can transform it into a simple Key/Value data table, which can store text / binary, and its scalability is much better than IndexdDB.
self.CACHE_NAME = 'SWHelperCache';
self.db = {
read: (key) => {
return new Promise((resolve, reject) => {
caches.match(new Request(`https://LOCALCACHE/${encodeURIComponent(key)}`)).then(function (res) {
res.text().then(text => resolve(text))
}).catch(() => {
resolve(null)
})
})
},
read_arrayBuffer: (key) => {
return new Promise((resolve, reject) => {
caches.match(new Request(`https://LOCALCACHE/${encodeURIComponent(key)}`)).then(function (res) {
res.arrayBuffer().then(aB => resolve(aB))
}).catch(() => {
resolve(null)
})
})
},
write: (key, value) => {
return new Promise((resolve, reject) => {
caches.open(CACHE_NAME).then(function (cache) {
cache.put(new Request(`https://LOCALCACHE/${encodeURIComponent(key)}`), new Response(value));
resolve()
}).catch(() => {
reject()
})
})
}
}Operation:
Write key, value:
await db.wtite(key,value)
Read key as text:
await db.read(key)
Read key in binary mode:
await db.read_arrayBuffer(key)
Other blob read and delete operations are not described here.
Build Communication with Page and ServiceWorker
be under construction