reference material
Operating environment
- Windows10
- JDK8
- IDEA 2021.6 professional
- Hadoop3.1.3
- CentOS7
- Three Hadoop fully distributed cluster nodes
1, Preparing the HDFS Java API environment
1.1 preparing Hadoop environment in windows system
Hadoop3.1.3 official download address: Click download , download and unzip.
hadoop is mainly written based on Linux. This winutil Exe is mainly used to simulate the directory environment under Linux system. Therefore, when hadoop runs under windows, it needs this auxiliary program to run
Download these environment software to the bin folder of hadoop Directory: Click download
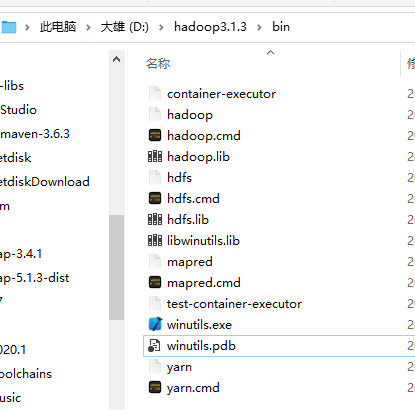
After that, configure Hadoop environment variables, just like in Linux environment, first configure HADOOP_HOME, reconfigure the system variable PATH
For graphical operation, right-click the computer, click properties, and then click Advanced system settings and environment variables
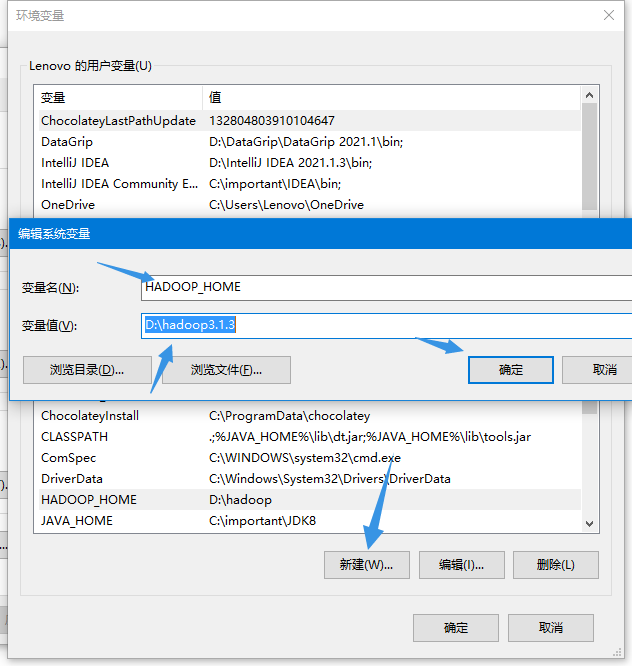
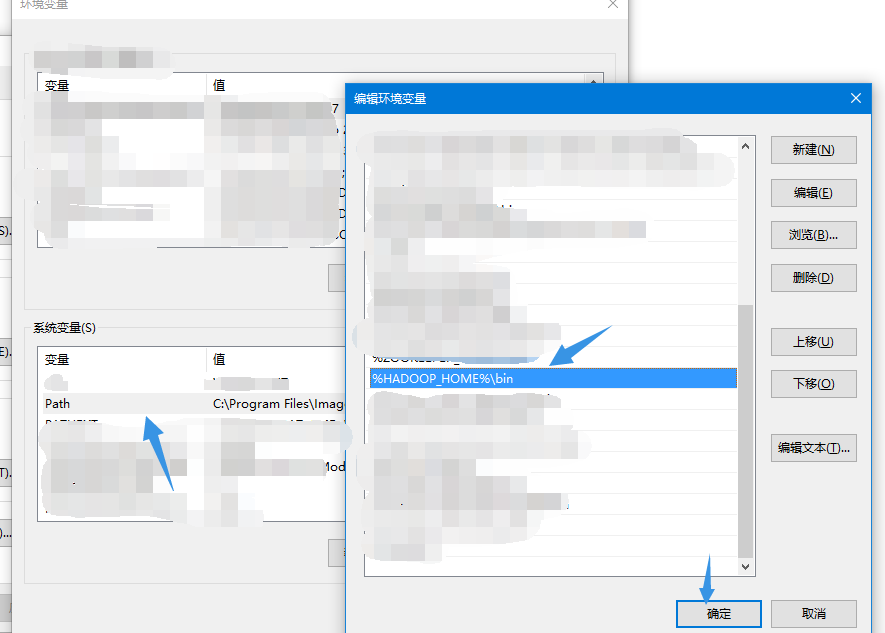
After configuration, view the version in cmd
hadoop version

Configuration completed
1.2 connect the local machine to the cluster node
1.2.1 domain name mapping
Configure domain name mapping locally so that you can directly connect to the corresponding ID through the host name
Configure domain name mapping for windows 10 at:
C:\WINDOWS\System32\drivers\etc\
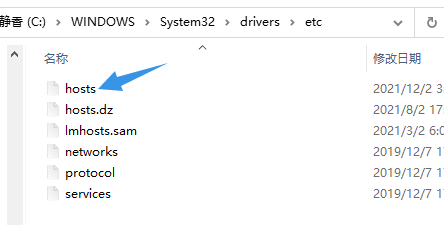
hosts configuration:
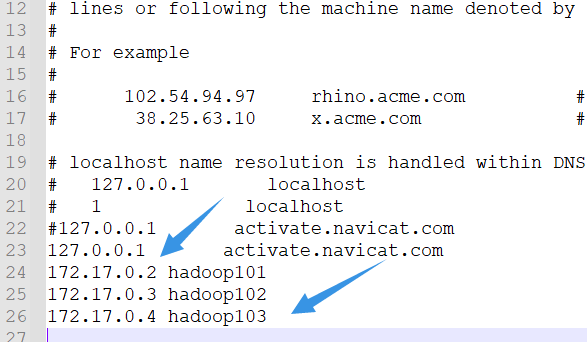
As shown in the figure: configure in the form of IP + space + host name
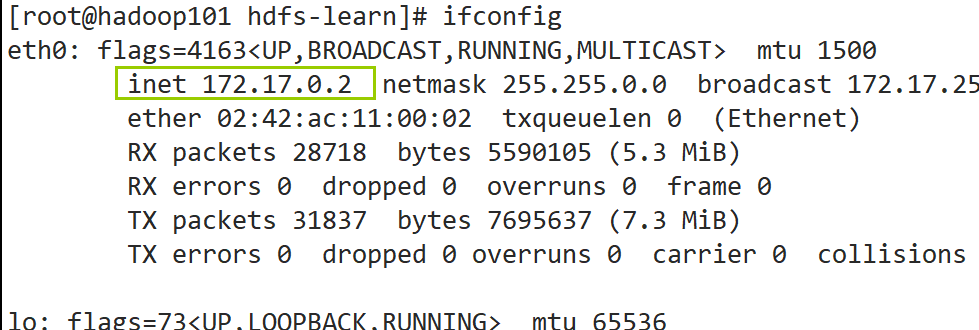
If it is a virtual machine of this machine, you can view it through commands in the virtual machine
ifconfig
Among the displayed information, select the information starting with eth. For example, eth33 in Vmware and eth0 in docker container
1.2.2 routing and forwarding
Since the author uses the docker container to build three nodes in the virtual machine, there are:
- The virtual machine is connected to the docker container in itself
- This function is connected to the virtual machine
To connect the local machine directly to the docker container in the virtual machine, you need to forward the domain name. Please refer to this blog post: Docker | use the host to ping the docker container in the virtual machine | route and forward
After the configuration is completed, you can ping the cluster node directly on the host, so that you can connect the HDFS of the cluster in the local program later.

1.3 creating Maven project using IDEA
Project structure:
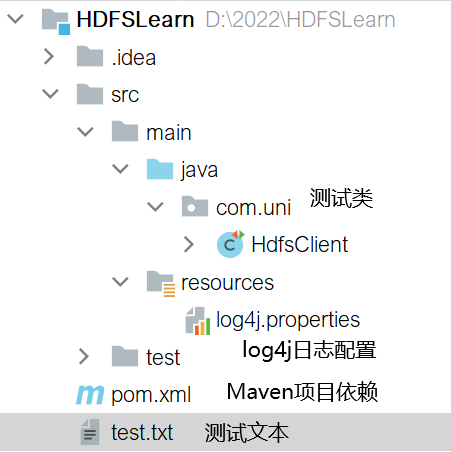
pom.xml to configure Maven project dependencies
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.uni</groupId>
<artifactId>HDFSLearn</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>
</project>
log4j.properties configure the output information of the log4j log file
log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
So far, the IDEA project has been built.
2, HDFS Java API operation case
2.1 creating folders
org. apache. hadoop. fs. Related methods in the file system source code:
public static boolean mkdirs(FileSystem fs, Path dir, FsPermission permission) public abstract boolean mkdirs(Path f, FsPermission permission) throws IOException public boolean mkdirs(Path f) throws IOException
Parameter Description:
| parameter | describe |
|---|---|
| Path f | File directory created by HDFS |
| FsPermission permission | The permission level of the current user |
Test code:
public class HdfsClient {
private static Configuration configuration;
private static String HDFS_PATH = "hdfs://Hadoop 101:8020 "; / / HDFS connection address
private static String HDFS_USER = "root"; // HDFS connection object
private static FileSystem fs; // HDFS file operation object
/* Creating connections in singleton mode**/
static { configuration = new Configuration(); }
public FileSystem getFileSystem(){
try{
if(fs == null)
fs = FileSystem.get(new URI(HDFS_PATH), configuration, HDFS_USER);
} catch (Exception e) {
e.printStackTrace();
}
return fs;
}
@Test
public void testMkdir() throws IOException{
FileSystem fs = getFileSystem();
fs.mkdirs(new Path("/uni/testMkdir/"));
fs.close();
}
}
2.2 uploading files
org. apache. hadoop. fs. Related methods in the file system source code:
public void copyFromLocalFile(Path src, Path dst) public void moveFromLocalFile(Path[] srcs, Path dst) public void copyFromLocalFile(boolean delSrc, Path src, Path dst) public void copyFromLocalFile(boolean delSrc, boolean overwrite,Path[] srcs, Path dst) public void copyFromLocalFile(boolean delSrc, boolean overwrite,Path src, Path dst)
Parameter Description:
| parameter | describe |
|---|---|
| boolean delSrc | Delete the original data where the HDFS path is located |
| boolean overwrite | Allow to overwrite the original content |
| Path src / []srcs | Local data path |
| Path dst | HDFS destination path |
Test code:
@Test
public void testCopyFromLocalFile() throws IOException{
FileSystem fs = getFileSystem();
Path localFile = new Path("test.txt");
Path distPath = new Path("/uni/testMkdir");
fs.copyFromLocalFile(localFile, distPath);
fs.close();
}
2.3 downloading files
org. apache. hadoop. fs. Related methods in the file system source code:
public void copyToLocalFile(boolean delSrc, Path src, Path dst) public void copyToLocalFile(boolean delSrc, Path src, Path dst,boolean useRawLocalFileSystem) throws IOException public void copyToLocalFile(Path src, Path dst) throws IOException
Parameter Description:
| parameter | describe |
|---|---|
| boolean delSrc | Delete the original data where the local path is located |
| boolean overwrite | Allow to overwrite the original content |
| Path src / []srcs | Local data path |
| Path dst | HDFS destination path |
| boolean useRawLocalFileSystem | Whether to enable local file verification (crc cyclic redundancy check) |
2.4 deleting files
org. apache. hadoop. fs. Related methods in the file system source code:
public boolean delete(Path f) throws IOException public abstract boolean delete(Path f, boolean recursive) throws IOException public boolean deleteOnExit(Path f) throws IOException public void deleteSnapshot(Path path, String snapshotName)
Parameter Description:
| parameter | describe |
|---|---|
| Path f | Path address to delete |
| boolean recursive | Indicates whether to delete recursively |
| Path dst | HDFS destination path |
| boolean useRawLocalFileSystem | Whether to enable local file verification (crc cyclic redundancy check) |
Test code:
@Test
public void testDelete(){
FileSystem fs = getFileSystem();
try{
fs.delete(new Path("/uni/testMkdir/test.txt"),true);
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
2.5 renaming and moving of documents
org. apache. hadoop. fs. Related methods in the file system source code:
public abstract boolean rename(Path src, Path dst) throws IOException
Test method:
@Test
public void testMove(){
FileSystem fs = getFileSystem();
try{
fs.rename(new Path("/uni/testMkdir"),new Path("/uni/MyDir"));
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
fs.close();
}
2.6 obtaining HDFS file information
org. apache. hadoop. fs. Related methods in the file system source code:
public RemoteIterator<LocatedFileStatus> listFiles(final Path f, final boolean recursive)
Test method:
Get HDFS file information
@Test
public void testDetail() throws IOException {
FileSystem fs = getFileSystem();
// Get all file information
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println("===========" + fileStatus.getPath() +"=========");
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getLen());
System.out.println(fileStatus.getModificationTime());
System.out.println(fileStatus.getReplication());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPath().getName());
}
fs.close();
}
Get block information of HDFS file:
@Test
public void testDetail() throws IOException {
FileSystem fs = getFileSystem();
// Get all file information
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));
}
fs.close();
}
2.7 judgment of documents and folders
@Test
public void testFile() throws IOException {
FileSystem fs = getFileSystem();
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for (FileStatus status : listStatus) {
if(status.isFile())
System.out.println("file:" + status.getPath().getName());
else
System.out.println("catalogue:" + status.getPath().getName());
}
fs.close();
}
2.8 HDFS - API configuration parameter priority
2.8.1 passing the configuration file
hdfs-site.xml
You can use the hadoop configuration file HDFS site XML is placed in the resources folder in the project, so that the API will execute according to this configuration.
2.8.2 through Configuration object
In addition to creating files, you can also set parameters by configuring the Configuration object
This class is from the package org apache. hadoop. Conf
Example: set the number of partitions to 2
Configuration configuration = new Configuration();
configuration.set("dfs.replication", 2);
2.8.3 priority issues
The priority from high to low is:
Configuration of API program > configuration file under Project Resource File > HDFS site in cluster XML > HDFS default in cluster xml