1, Foreword
In SparseArray detailed explanation and source code analysis, we are familiar with the basic usage, characteristics and implementation principle of SparseArray. There is also an equally important data structure ArrayMap in the toolkit of the Android SDK. Its purpose is to replace HashMap when the amount of data is small, such as hundreds, so as to improve the efficiency of memory use.
If you are interested in the implementation of HashMap, you can take a look at the detailed explanation and source code analysis of HashMap, and this article will learn about the use and implementation principle of ArrayMap.
2, Analysis of source code
1. demo and its brief analysis
Before analyzing the code, you should also look at a demo, and then analyze the implementation principle through the demo.
ArrayMap<String,String> arrayMap = new ArrayMap<>();
arrayMap.put(null,"Brother Zhang");
arrayMap.put("abcd","A eldest brother");
arrayMap.put("aabb","Brother Ba");
arrayMap.put("aacc","Brother Niu");
arrayMap.put("aadd","Brother Niu");
arrayMap.put("abcd","B eldest brother");
Set<ArrayMap.Entry<String,String>> sets = arrayMap.entrySet();
for (ArrayMap.Entry<String,String> set : sets) {
Log.d(TAG, "arrayMapSample: key = " + set.getKey() + ";value = " + set.getValue());
}
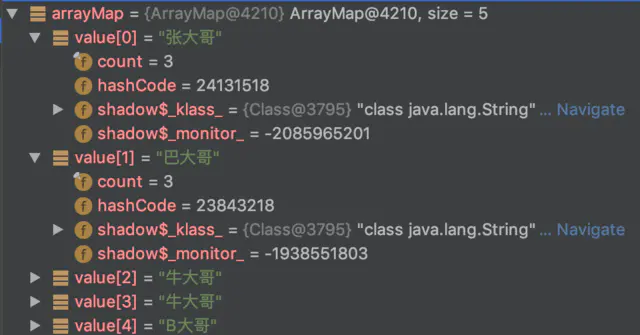
In the code, 6 key values are actually inserted, but only 5 are output. The key with "abcd" is repeated and overwritten. In addition, it should be noted that null keys are allowed to be inserted. The following is the result of its output.
arrayMapSample: key = null;value = brother Zhang arrayMapSample: key = aabb;value = brother BA arrayMapSample: key = aacc;value = brother Niu arrayMapSample: key = aadd;value = brother Niu arraymapsample: key = ABCD; Value = brother B
Through the Debug function of Android Studio, you can also simply observe its storage in memory.
2. Source code analysis
Let's take a brief look at the class diagram structure of ArrayMap.
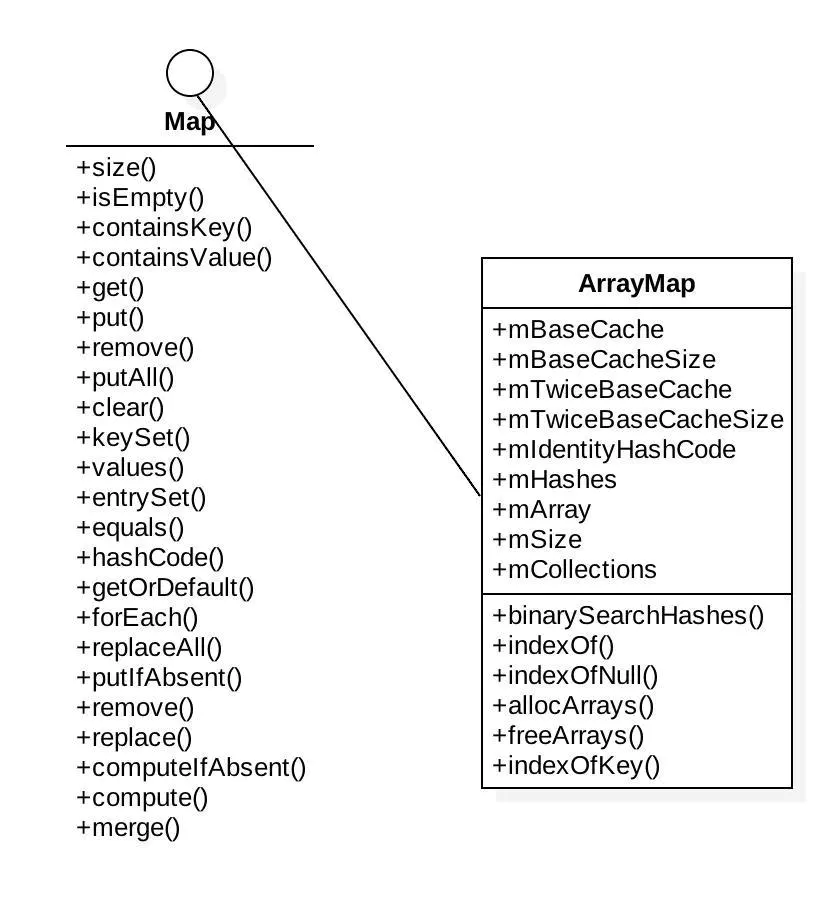
Unlike HashMap, it directly implements the self interface map. Similarly, key values are stored in different ways. ArrayMap directly stores all key values through an array. Among them, mHashes stores the hash code of the key at the index, while mmarray stores the key at the index < < 1 of the hash code and the value at the index < < 1 + 1. Simply put, key is stored in even numbers and value is stored in adjacent odd numbers.
- Initialization of ArrayMap
/**
* Create a new empty ArrayMap. The default capacity of an array map is 0, and
* will grow once items are added to it.
*/
public ArrayMap() {
this(0, false);
}
/**
* Create a new ArrayMap with a given initial capacity.
*/
public ArrayMap(int capacity) {
this(capacity, false);
}
/** {@hide} */
public ArrayMap(int capacity, boolean identityHashCode) {
mIdentityHashCode = identityHashCode;
// If this is immutable, use the sentinal EMPTY_IMMUTABLE_INTS
// instance instead of the usual EmptyArray.INT. The reference
// is checked later to see if the array is allowed to grow.
if (capacity < 0) {
mHashes = EMPTY_IMMUTABLE_INTS;
mArray = EmptyArray.OBJECT;
} else if (capacity == 0) {
mHashes = EmptyArray.INT;
mArray = EmptyArray.OBJECT;
} else {
allocArrays(capacity);
}
mSize = 0;
}
There are three overloaded versions of the construction method of ArrayMap listed above. Generally, we use the default construction method, that is, the default capacity is 0. We need to wait until the element is inserted. Another parameter in the constructor, identityHashCode, controls whether the hashCode is generated by the System class or by object hashCode() returns.
In fact, there is not much difference between the two implementations, because the System class is finally implemented through object hashCode(). It mainly deals with null in a special way. For example, it is always 0. In the put() method of ArrayMap, if the key is null, its hashCode is also regarded as 0. Therefore, the identityHashCode here is true or false.
- Insert element (put)
public V put(K key, V value) {
final int osize = mSize;
// 1. Calculate the hash code and obtain the index
final int hash;
int index;
if (key == null) {
// If it is empty, take 0 directly
hash = 0;
index = indexOfNull();
} else {
// Otherwise, take object hashCode()
hash = mIdentityHashCode ? System.identityHashCode(key) : key.hashCode();
index = indexOf(key, hash);
}
// 2. If the index is greater than or equal to 0, it indicates that the same hash code and the same key exist before, so it is directly overwritten
if (index >= 0) {
index = (index<<1) + 1;
final V old = (V)mArray[index];
mArray[index] = value;
return old;
}
// 3. If it is not found, the above indexOf() or indexOfNull() will return a negative number, which is obtained by inverting the position index to be inserted, so inverting here again becomes the position to be inserted
index = ~index;
// 4. Judge whether capacity expansion is required
if (osize >= mHashes.length) {
final int n = osize >= (BASE_SIZE*2) ? (osize+(osize>>1))
: (osize >= BASE_SIZE ? (BASE_SIZE*2) : BASE_SIZE);
if (DEBUG) Log.d(TAG, "put: grow from " + mHashes.length + " to " + n);
final int[] ohashes = mHashes;
final Object[] oarray = mArray;
// 5. Apply for new space
allocArrays(n);
if (CONCURRENT_MODIFICATION_EXCEPTIONS && osize != mSize) {
throw new ConcurrentModificationException();
}
if (mHashes.length > 0) {
if (DEBUG) Log.d(TAG, "put: copy 0-" + osize + " to 0");
// Copy data to a new array
System.arraycopy(ohashes, 0, mHashes, 0, ohashes.length);
System.arraycopy(oarray, 0, mArray, 0, oarray.length);
}
// 6. Release the old array
freeArrays(ohashes, oarray, osize);
}
if (index < osize) {
// 7. If the index is within the current size, you need to move the data from index to index + 1 to make room for the position of index
if (DEBUG) Log.d(TAG, "put: move " + index + "-" + (osize-index)
+ " to " + (index+1));
System.arraycopy(mHashes, index, mHashes, index + 1, osize - index);
System.arraycopy(mArray, index << 1, mArray, (index + 1) << 1, (mSize - index) << 1);
}
if (CONCURRENT_MODIFICATION_EXCEPTIONS) {
if (osize != mSize || index >= mHashes.length) {
throw new ConcurrentModificationException();
}
}
// 8. Insert hash, key and code respectively according to the calculated index
mHashes[index] = hash;
mArray[index<<1] = key;
mArray[(index<<1)+1] = value;
mSize++;
return null;
}
The put method calls several other internal methods, among which the expansion and how to release space and apply for new space are actually not important from the algorithm layer. As long as you know that the expansion will cause data replication, which will affect the efficiency.
The implementation of indexOfNull() method and indexOf() method, which are closely related to the algorithm. Since the implementation of the two methods is basically the same, only the implementation of indexOf() is analyzed here.
int indexOf(Object key, int hash) {
final int N = mSize;
// Important fast case: if nothing is in here, nothing to look for.
if (N == 0) {
return ~0;
}
int index = binarySearchHashes(mHashes, N, hash);
// If the hash code wasn't found, then we have no entry for this key.
if (index < 0) {
return index;
}
// If the key at the returned index matches, that's what we want.
if (key.equals(mArray[index<<1])) {
return index;
}
// Search for a matching key after the index.
int end;
for (end = index + 1; end < N && mHashes[end] == hash; end++) {
if (key.equals(mArray[end << 1])) return end;
}
// Search for a matching key before the index.
for (int i = index - 1; i >= 0 && mHashes[i] == hash; i--) {
if (key.equals(mArray[i << 1])) return i;
}
// Key not found -- return negative value indicating where a
// new entry for this key should go. We use the end of the
// hash chain to reduce the number of array entries that will
// need to be copied when inserting.
return ~end;
}
In fact, its original notes are very detailed. The detailed steps are as follows:
-
(1) If the current table is empty, ~ 0 will be returned directly. Note that it is not 0, but the maximum negative number.
-
(2) Perform a binary search in the mHashs array to find the index of the hash.
-
(3) If index < 0, it means it is not found.
-
(4) If index > = 0, and the key at the corresponding index < < 1 in the mmarray is the same as the key to be found, it is considered to be the same key, indicating that it has been found.
-
(5) If the key s are different, it means that the hash code s are the same. Search backward and forward respectively. If found, return. If it is not found, the inverse of end is the index position to be inserted.
Looking back at the put() method, the specific implementation of the put() method is described in detail in the source code. Those interested can read it in detail. The following conclusions are drawn from the put method:
-
(1) The mhashs array holds all hash code s in ascending order.
-
(2) Determine the storage location of key and value in the mmarrays array by the index value of hash code in the mHashs array. Generally speaking, they are index < < 1 and index < < 1 + 1. Simply put, index * 2 and index * 2 + 1.
-
(3) hashCode must have conflicts. How do you solve them here? This is determined by steps 3 and 7 above. Step 3 is to get the position of the index that should be inserted, and step 7 is to if index < osize, it means that the same hashCode value must already exist in the original marays, then move all the data back one bit, so as to insert multiple identical hash code s in mHashs, which must be connected together, and insert new key s and values in marays, Finally, the hash conflict can be solved.
The above conclusion may still make people feel a little dizzy. Then take a look at the figure below, and you will understand it.
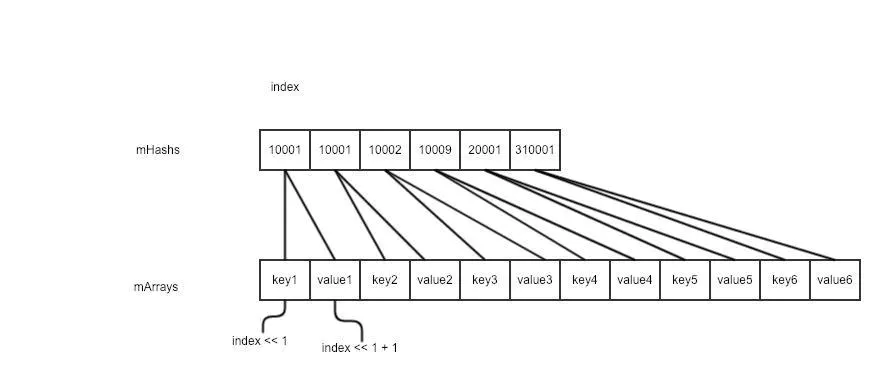
The above figure shows that the hash code is the same when index == 0 and index == 1, indicating that the hash code of key1 and key2 is the same, that is, there is a hash conflict. So, as mentioned above, the solution here is to store two copies of hash code and one copy of key value respectively.
- get() method
public V get(Object key) {
final int index = indexOfKey(key);
return index >= 0 ? (V)mArray[(index<<1)+1] : null;
}
The index is mainly calculated through indexOfKey(), and the implementation of indexOfKey() is to call indexOfNull() and indexOf(), and its specific implementation has been analyzed above. If index > = 0 is returned here, it means that it must be found. According to the previous rules, index < < 1 + 1 is the value to be obtained in mmarray.
- remove() method
public V remove(Object key) {
final int index = indexOfKey(key);
if (index >= 0) {
return removeAt(index);
}
return null;
}
First, calculate the index through indexOfKey() to determine whether it exists. If it exists, further call removeAt() to delete the corresponding hash code and key value.
public V removeAt(int index) {
final Object old = mArray[(index << 1) + 1];
final int osize = mSize;
final int nsize;
// If the size is less than or equal to 1, the array length will be 0 after removal. In order to compress memory, mHashs and maarray are directly set as empty arrays
if (osize <= 1) {
// Now empty.
if (DEBUG) Log.d(TAG, "remove: shrink from " + mHashes.length + " to 0");
final int[] ohashes = mHashes;
final Object[] oarray = mArray;
mHashes = EmptyArray.INT;
mArray = EmptyArray.OBJECT;
freeArrays(ohashes, oarray, osize);
nsize = 0;
} else {
// If size > 1, set size - 1 first
nsize = osize - 1;
if (mHashes.length > (BASE_SIZE*2) && mSize < mHashes.length/3) {
// If the above conditions are met, data compression is required.
// Shrunk enough to reduce size of arrays. We don't allow it to
// shrink smaller than (BASE_SIZE*2) to avoid flapping between
// that and BASE_SIZE.
final int n = osize > (BASE_SIZE*2) ? (osize + (osize>>1)) : (BASE_SIZE*2);
if (DEBUG) Log.d(TAG, "remove: shrink from " + mHashes.length + " to " + n);
final int[] ohashes = mHashes;
final Object[] oarray = mArray;
allocArrays(n);
if (CONCURRENT_MODIFICATION_EXCEPTIONS && osize != mSize) {
throw new ConcurrentModificationException();
}
if (index > 0) {
if (DEBUG) Log.d(TAG, "remove: copy from 0-" + index + " to 0");
System.arraycopy(ohashes, 0, mHashes, 0, index);
System.arraycopy(oarray, 0, mArray, 0, index << 1);
}
if (index < nsize) {
if (DEBUG) Log.d(TAG, "remove: copy from " + (index+1) + "-" + nsize
+ " to " + index);
System.arraycopy(ohashes, index + 1, mHashes, index, nsize - index);
System.arraycopy(oarray, (index + 1) << 1, mArray, index << 1,
(nsize - index) << 1);
}
} else {
if (index < nsize) {
// If the index is within size, move the data forward one bit
if (DEBUG) Log.d(TAG, "remove: move " + (index+1) + "-" + nsize
+ " to " + index);
System.arraycopy(mHashes, index + 1, mHashes, index, nsize - index);
System.arraycopy(mArray, (index + 1) << 1, mArray, index << 1,
(nsize - index) << 1);
}
// Then set the last bit data to null
mArray[nsize << 1] = null;
mArray[(nsize << 1) + 1] = null;
}
}
if (CONCURRENT_MODIFICATION_EXCEPTIONS && osize != mSize) {
throw new ConcurrentModificationException();
}
mSize = nsize;
return (V)old;
}
Generally, to delete a data, you only need to move the data behind the index one bit to the index direction, and then delete the last digit. If the condition in the current array reaches mHashs, the length is greater than base_ If the size is 2 and the actual size is less than 1 / 3 of its length, the data must be compressed. The compressed space is at least base_ Size of size2.
3, Summary
The implementation of put() method and remvoeAt() method are more important in ArrayMap. These two methods basically realize all the important features of ArrayMap. Here again as a summary of the full text.
-
The mHashs array saves all hash codes in ascending order. When searching for data, you can find the index corresponding to the hash code by bisection. This is why its get() is slower than HashMap.
-
Determine the storage location of key and value in the mmarrays array by the index value of hash code in the mHashs array. Generally speaking, they are index < < 1 and index < < 1 + 1. Simply put, index * 2 and index * 2 + 1.
-
hashCode must have conflicts. How do you solve them here? Simply put, multiple hash code s are stored adjacent to each other in mHashs, and their index es are used to calculate the storage location of key values in mmarray.
-
During the remove operation, data compression may occur under certain conditions, so as to save the use of memory.
Finally, thank you for reading this article. Limited by the author's limited level, if there are errors or questions, you are welcome to leave a message for discussion. If my sharing can help you, please remember to give me a favor and encourage me to continue writing. Thank you.
PS: about me

I am a handsome Android siege lion with 6 years of development experience. Remember to praise after reading, form a habit and pay attention to this programmer who likes to write dry goods.
In addition, it took two years to sort out and collect the PDF of the complete test site for the interview of Android front-line manufacturers, and the [Full Version] has been updated in my website [Github] , if you have interview and advanced needs, you can refer to it. If it is helpful to you, you can click Star!
Address: [https://github.com/733gh/xiongfan]