1. Introduction
According to Hongge's plan, this article continues to introduce WebDriver's element positioning method. This article introduces the penultimate method of positioning: By xpath. The location method of xpath is very powerful. Using this method, you can locate almost any element on the page.
2. What is xpath?
XPath is the abbreviation of XML Path. Since HTML document itself is a standard XML page, we can use the usage of XPath to locate page elements. XPath is the abbreviation of XML and Path. It is mainly used to select nodes in XML documents. Based on the XML tree document structure, XPath language can be used to find the specified node in the whole tree. XPath positioning has more flexibility than CSS positioning. XPath can search forward or backward at a node in the document tree. CSS positioning can only search forward in the document tree, but the positioning speed of XPath is slower than that of CSS.
3. Disadvantages of XPath positioning
With xpath as the positioning method, webdriver will scan all elements of the whole page to locate the elements we need, which is a very time-consuming operation. If xpath is widely used for element positioning in the script, the execution speed of the script may be slightly slow.
4. Common positioning methods (8 kinds)
(1)id
(2)name
(3)class name
(4)tag name
(5)link text
(6)partial link text
(7) xpath (explained today)
(8)css selector
5. Automatic test practice
Take Baidu home page as an example, explain and share various positioning methods of xpath one by one.
5.1 general steps
1. Visit the home page.
2. Navigate to the element through xpath and click.
5.2 positioning with index numbers
Index number positioning, starting with '/ /', the specific format is
xxx.find_element_by_xpath("//Label [x] ")Specific examples:
//form/div[1]: represents the first div under the form / / form / div [last()]: represents the last div under the form / / form / div [last() - 1]: represents the penultimate div under the form
Specific steps:
In the tested Baidu web page, according to the method in 5.2 of the volume I of Hongge (1) find the input box and enter "Beijing Hongge", as shown in the figure below: (2) find the "Baidu click" button, as shown in the figure below: (3) click the "Baidu click" button.
XPath expression:
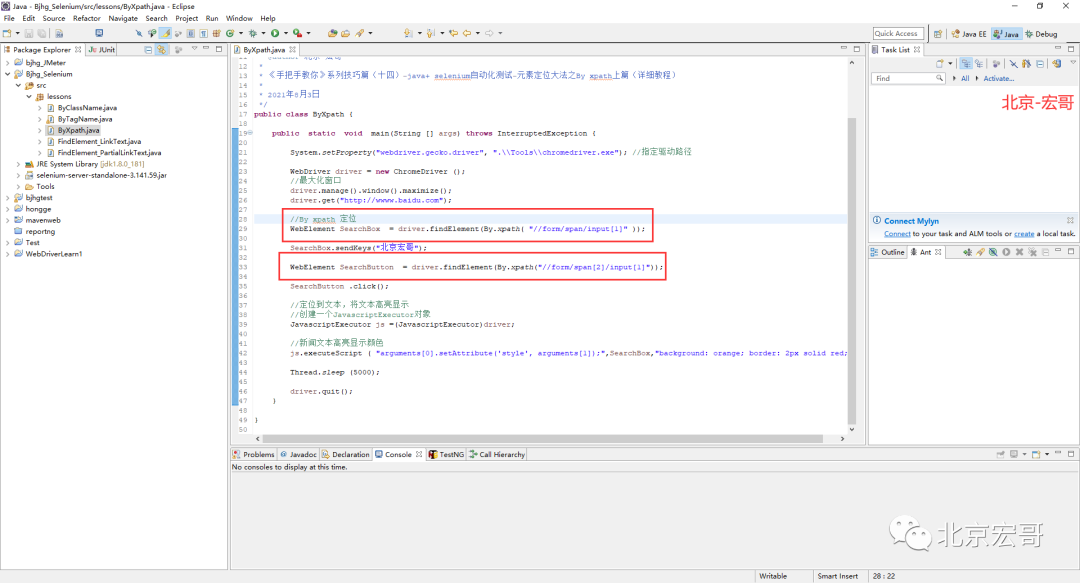
(1)//form/span/input[1] (2)//form/span[2]/input[1]
java positioning statement:
(1)WebElement SearchBox = driver.findElement(By.xpath( "//form/span/input[1]" ));
(2)WebElement SearchButton = driver.findElement(By.xpath("//form/span[2]/input[1]"));
5.2.1 code design
5.2.2 reference code
package lessons;
import org.openqa.selenium.By;import org.openqa.selenium.JavascriptExecutor;import org.openqa.selenium.WebDriver;import org.openqa.selenium.WebElement;import org.openqa.selenium.chrome.ChromeDriver;
/** * @author Beijing - Hongge * * tips of "teach you by hand" (14) - java+ selenium automated testing - By xpath of element positioning method Part I (detailed tutorial) * * August 4, 2021 */public class ByXpath { public static void main(String [] args) throws InterruptedException { System.setProperty("webdriver.gecko.driver", ".\\Tools\\chromedriver.exe"); //Specify the drive path WebDriver driver = new ChromeDriver()// Maximize window driver manage(). window(). maximize(); driver. get(" http://wwww.baidu.com "); / / by XPath locate webelement searchbox = driver.findelement (by. XPath (" / / form / span / input [1] "); searchbox.sendkeys (" Beijing Hongge "); webelement searchbutton = driver.findelement (by. XPath (" / / form / span [2] / input [1] "); searchbutton. Click () ; // Locate the text and highlight it. / / create a JavascriptExecutor object JavascriptExecutor js =(JavascriptExecutor)driver// News text highlight color JS executeScript ( "arguments[0].setAttribute('style', arguments[1]);", SearchBox,"background: orange; border: 2px solid red;"); Thread. sleep (5000); driver. quit(); }
}5.2.3 operation code
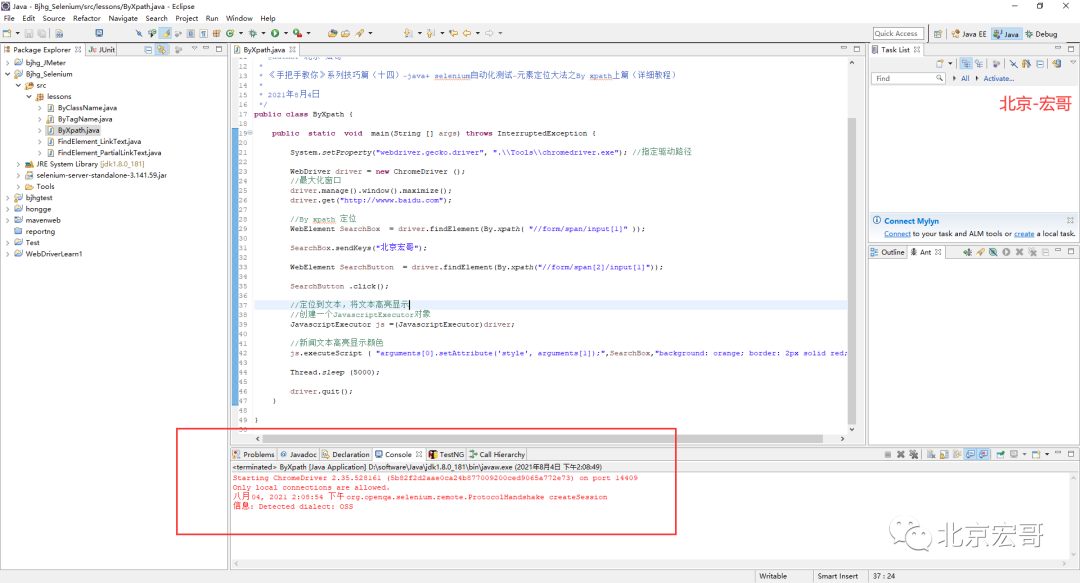
1. Run the code, right-click run as - > java application, and the console will output, as shown in the following figure:
2. After running the code, the action of the browser on the computer side is shown in the following small video:
According to the order in which the element type appears in the page, you can use the sequence number to find the specified page element. The XPath expression of this example means to find the input element in the span that appears second in the page, that is, the button element on the tested page. If you use span/input[1], you will find the fixed output input box and button elements. This is because the page contains two span nodes, and each span node contains an input element. When XPath looks up, it starts looking up each span node as the same actual level, so input[1] can find two elements.
Therefore, when using serial numbers to locate elements on a page, you should pay attention to whether the HTML code of a web page contains multiple code structures with exactly the same level. If you use an XPath expression to locate multiple page elements at the same time, multiple elements will be stored in the List object.
In actual use, if elements are often added or reduced, it is not recommended to use index number positioning, because changes in the page will cause the positioning of XPath expressions using index numbers to fail.
5.3 positioning using page attributes
Label attribute positioning is relatively simple. It also requires that the attribute can be located to a unique element. If there are multiple labels with the same conditions, only the first one is by default. Specific format:
xxx.find_element_by_xpath("//Label [@ attribute = 'attribute value'] ")Attribute judgment conditions: the most common are id, name, class, etc. at present, there are no special restrictions on the category of attributes, as long as an element can be uniquely identified
Specific examples:
xxx.find_element_by_xpath("//A [@ href = '/ industrimall / Hall / industriindex. HTML'] ") XXX. Find_element_by_xpath (" / / input [@ value = 'OK'] ") xxx.find_element_by_xpath("//div[@class = 'submit']/input ")(1) When an attribute is not enough to uniquely distinguish an element, it can also be combined by multiple conditions, for example
xxx..find_element_by_xpath("//input[@type='name' and @name='kw1']")(2) When there are few tag attributes that are not enough to uniquely distinguish elements, but there is a unique text value in the middle of the tag, you can also locate its specific format
xxx.find_element_by_xpath("//Label [contains(text(), 'text value')] ")Specific examples:
xxx.find_element_by_xpath("//iunpt[contains(text(), 'model:'] ")Note: try to copy this text in html to avoid positioning failure due to characters that cannot be distinguished by the naked eye
(3) If other attribute values are too long, you can also use the fuzzy method to locate them. Go directly to the example above
xxx.find_element_by_xpath("//a[contains(@href, 'logout')]")(4) XPath positioning of dynamic properties in web pages, for example, ASP Net application. There are four methods to dynamically generate the id attribute value:
- starts-with example://Input [starts with (@ ID, 'ctrl')] parsing: matching attribute values starting with ctrl - ends-with example://Input [ends with (@ ID, 'userName')] parsing: matching attribute values ending with userName - contains() example://input[contains(@id,'userName')] resolution: match the value containing the userName attribute
Of course, if the above single method cannot complete positioning, combined positioning can also be adopted
("//input[@id='kw1']//input[start-with(@id,'nice']/div[1]/form[3])(5) .// The difference between and / /
//It refers to searching / / the following nodes from the full-text context, and// It refers to searching from the child nodes of the previous node
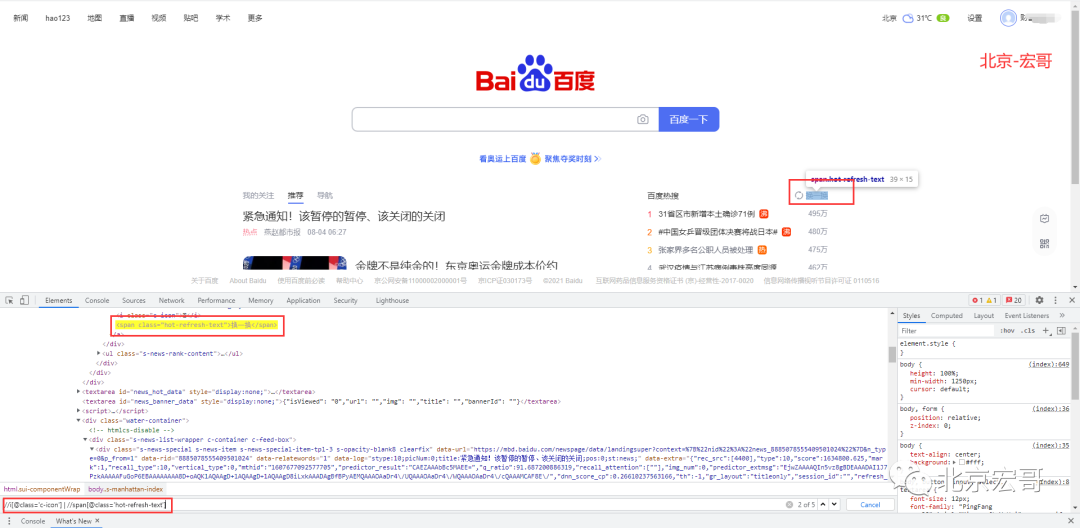
(6) Select several paths|
This symbol is used to write multiple expressions in an xpath, separated by |. Each expression does not interfere with each other, which means that an xpath can match multiple elements with different conditions. For example, as shown in the figure below, xpath can match the i tag element and span tag element that meet the conditions.
//i[@class='c-icon'] | //span[@class='hot-refresh-text']
Specific steps:
In the tested Baidu web page, according to the method in 5.2 in the volume I of Hongge (1) find the input box and enter "Beijing Hongge", (2) find the "Baidu click" button, (3) click the "Baidu click" button. Because the id of the relative path in the volume up has been used by brother Hong, here brother Hong uses other attributes.
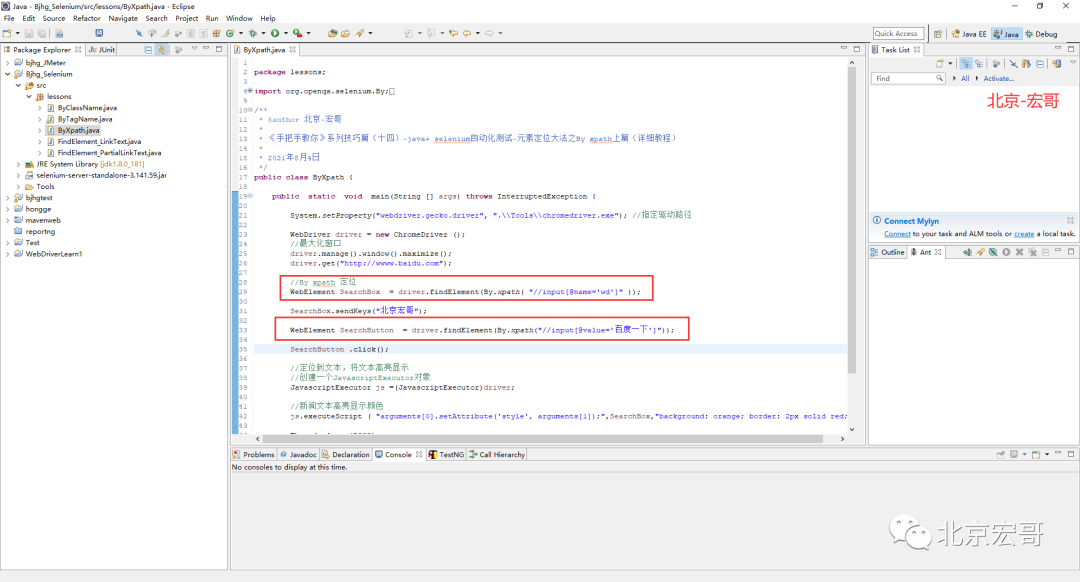
XPath expression:
(1)//input[@name='wd'] (2)//input[@value = 'Baidu once']
java positioning statement:
(1)WebElement searchBox = driver.findElement(By.xpath( "//input[@name='wd']" ));
(2)WebElement SearchButton = driver.findElement(By.xpath("//input[@value = 'Baidu'] ");5.3.1 code design
5.3.2 reference code
package lessons;
import org.openqa.selenium.By;import org.openqa.selenium.JavascriptExecutor;import org.openqa.selenium.WebDriver;import org.openqa.selenium.WebElement;import org.openqa.selenium.chrome.ChromeDriver;
/** * @author Beijing - Hongge * * tips of "teach you by hand" (14) - java+ selenium automated testing - By xpath of element positioning method Part I (detailed tutorial) * * August 4, 2021 */public class ByXpath { public static void main(String [] args) throws InterruptedException { System.setProperty("webdriver.gecko.driver", ".\\Tools\\chromedriver.exe"); //Specify the drive path WebDriver driver = new ChromeDriver()// Maximize window driver manage(). window(). maximize(); driver. get(" http://wwww.baidu.com "); / / by XPath locate webelement searchbox = driver.findelement (by. XPath (" / / input [@ name ='wd '] "); searchbox.sendkeys (" Beijing Hongge "); webelement searchbutton = driver.findelement (by. XPath (" / / input [@ value =' Baidu '] "); searchbutton. Click () ; // Locate the text and highlight it. / / create a JavascriptExecutor object JavascriptExecutor js =(JavascriptExecutor)driver// News text highlight color JS executeScript ( "arguments[0].setAttribute('style', arguments[1]);", SearchBox,"background: orange; border: 2px solid red;"); Thread. sleep (5000); driver. quit(); }
}5.3.3 operation code
1. Run the code, right-click run as - > java application, and the console will output, as shown in the following figure:
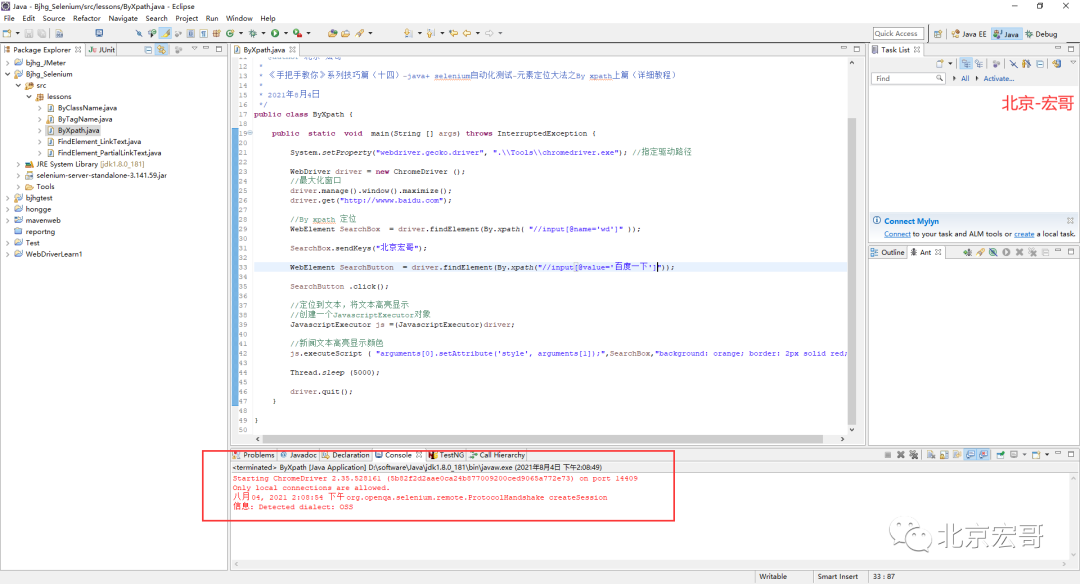
2. After running the code, the action of the browser on the computer side is shown in the following small video:
When locating page elements, you will encounter various web pages with complex structures, and often you can't locate them by ID, name, etc. If you don't want to use the way to locate the path, and you can't figure out what sequence number to use to locate the element, it is recommended to use the attribute value to locate the element.
The elements of the tested web pages generally contain a variety of attribute values, and many attribute values are unique. Therefore, it is highly recommended to use relative path combined with attribute value positioning to write XPath positioning expression. Based on this positioning method, most page element positioning problems can be solved.
5.4 element positioning using the Axis of XPath
The Aixs method can be used to locate according to the relative position of elements in the document book. First find a relatively well positioned element, and then locate it according to the element and the relative position to be positioned, which can solve the problem that some elements are difficult to locate.
5.4.1 shaft diagram
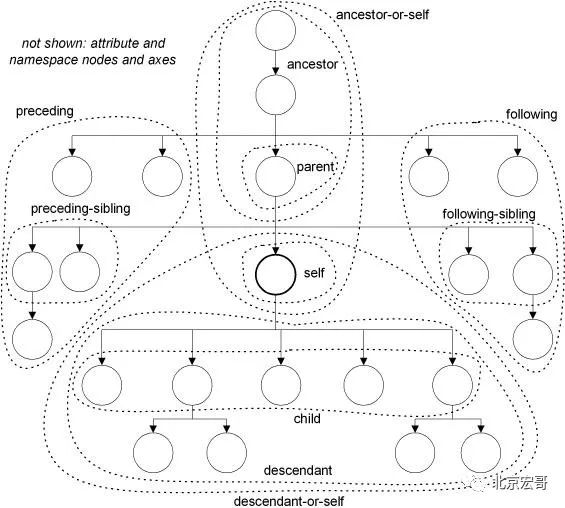
5.4.2 common keywords of XPath
Common keywords used in XPath are as follows:
| XPath} axis keyword | Axis meaning | Instance | Expression interpretation |
| ancestor | Select all ancestors (parent, grandfather, etc.) of the current node | //img[@alt='div2-img2']/ancestor::div | Find the picture whose alt attribute value is div2 img, and find its parent div page element based on the picture position. |
| ancestor-or-self | Select all ancestors (parents, grandfathers, etc.) of the current node and the current node itself | //img[@alt='div2-img2']/ ancestor-or-self::* | Find the image with the alt attribute value of div2 img, and find all its parent elements, including itself, based on the image location. |
| attribute | Select all the attributes of the current node | //img[@alt='div2-img2']/ attribute::* | Find the picture with alt attribute value of div2 img and return all attribute nodes under this node |
| child | Selects all child elements of the current node. | //div[@id='div1']/child::img | Find the div page element whose ID attribute is div1, and find the img page element in its lower node based on the div location |
| descendant | Select all descendant elements (children, grandchildren, etc.) of the current node. | //div[@name='div2']/ descendant::img | Find the element whose name attribute value is div2, and find the img page elements in all its subordinate nodes based on the div location. |
| descendant-or-self | Select all descendant elements (children, grandchildren, etc.) of the current node and the current node itself. | //div[@name='div2']/ descendant::div | Find the element whose name attribute value is div2, and find the div page elements in all its subordinate nodes (including itself) based on the div location. It's actually itself. |
| following | Select all nodes in the document after the end tag of the current node. | //div[@id='div1']/ following::img | Find the div page whose ID attribute value is div1, and find the img page element in the node behind it based on the Div |
| parent | Select the parent node of the current node. | //img[@alt='div2-img2']/ parent::div | Find the picture with the alt attribute value of div2 img, and find the div page element at its upper level based on the picture position. |
| preceding | Select all nodes in front of the current node | //img[@alt='div2-img2']/preceding::div | Find the photo page element whose alt attribute value is div2-img2, and find the div page element in the node in front of it based on the position of the picture. |
| preceding-sibling | Select all siblings before the current node. | //img[@alt='div2-img2']/ preceding-sibling::a[1] | Find the photo page element with the alt attribute value of div2-img2, and find the second link page element in the peer node in front of it based on the location of the picture |
| self | Select the current node. |
5.4.3 application method
Axis Name: node test [predicate]
For example:
//form/div[last()-1]/ancestor::div[@class='modal-content']
5.4.4 practice
1.descendant means to take all descendant elements of the current node. Hongge demonstrates and locates the "Baidu click" button on baidu home page, as shown in the following figure:
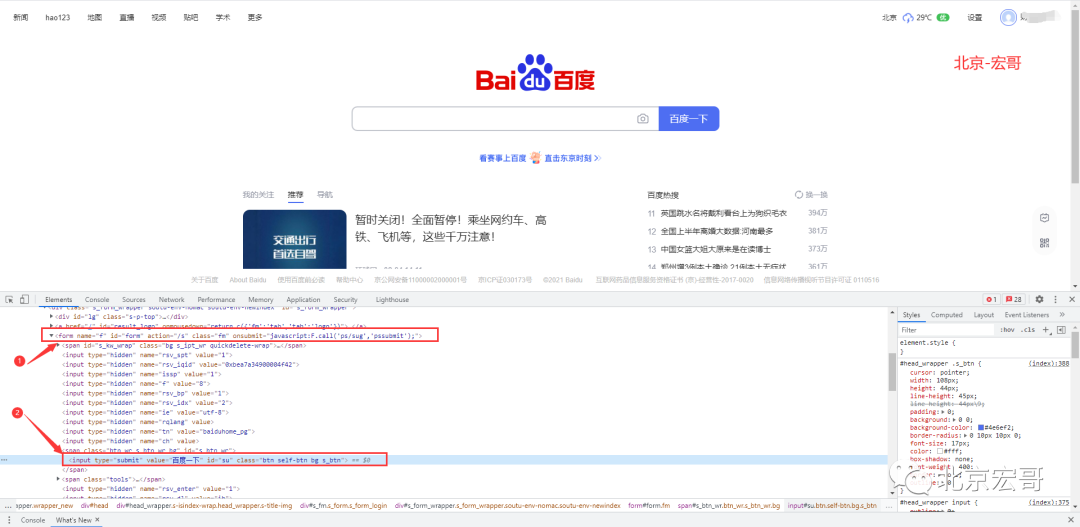
You can see that the parent element of the input tag is the span tag, and the parent element of the span tag is the form tag, so you can locate the form tag first, and then use the descendant to locate the input tag
The xpath path is as follows:
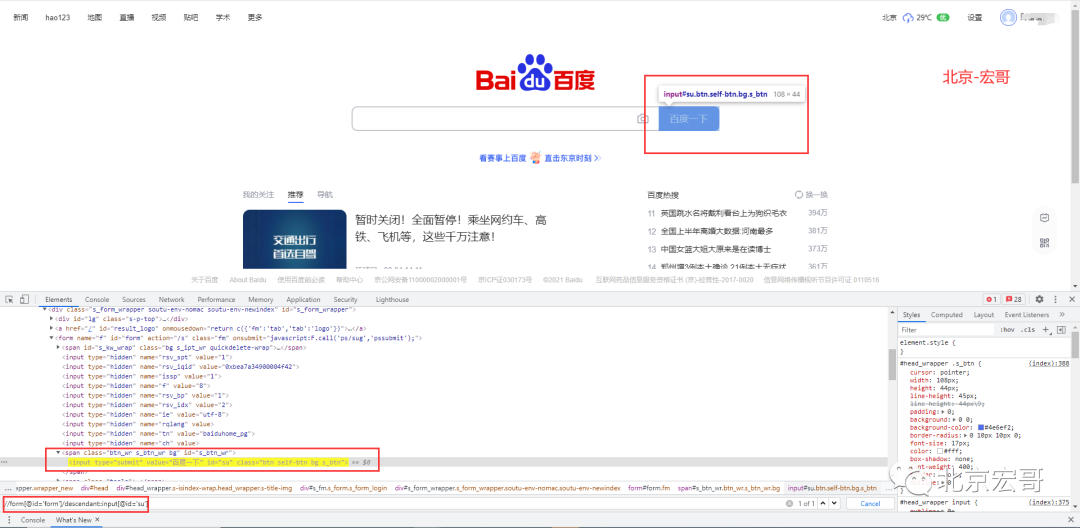
//Positioning idea: / / (1) form[@id='form '] means to find the < form > tag with ID attribute of' form ', / / (2) descendant::input means to find all descendant < input > tags of < form > tag, / / (3) then accurately locate the < input > tag with ID attribute of' Su 'through [@ id='su'] xpath= "//form[@id='form']/descendant::input[@id='su']"
Put the path on the browser console, press Ctrl+F, and then enter the xpath path. Check that the tag is located (you can verify whether the written xpath path is correct before executing the program)
2.following means to select all nodes after the end tag of the current node
Note that "after the tag is finished" is mentioned here, so when positioning with this axis, you should see the hierarchical relationship between the target tag and the auxiliary positioning tag. Therefore, in the above example, you can't locate the tag by combining the tag with following, because the tag is inside the tag;

Analysis: the upper level of the input tag is a span tag. There is also a span tag on this span tag, which can be located through it (span)
//Positioning idea: / / (1) span[@id='s_kw_wrap '] indicates that the ID attribute is s_ kw_ The < span > tag of wrap, / / (2) following::input[@id='su '] represents all input tags after finding the < span > end tag (i.e. < / span >), / / (3) then accurately locate the < input > tag with ID attribute' Su 'through [@ id='su'] xpath= "//span[@id='s_kw_wrap']/following::input[@id='su']"
According to the above method, Hongge verifies again and successfully locates the "Baidu" button, as shown in the following figure:
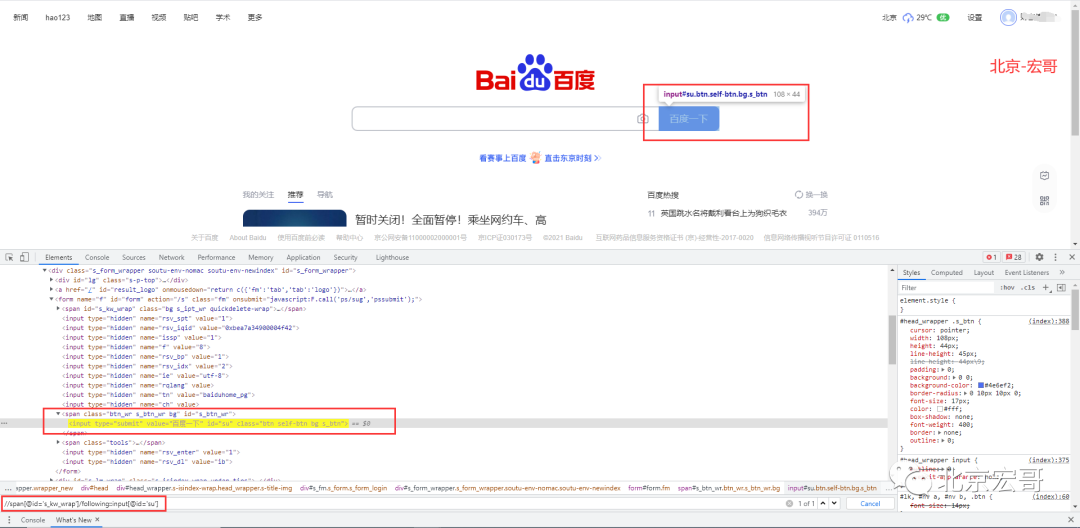
3.parent can specify the direct parent node of the current node to find
For example, if the parent node is a div, it can be written as parent::div. if the element to be found is not a direct parent element, you can not use parent. You can use ancestor to represent nodes such as parents and grandparents. Child:: represents direct child node elements. Following sibling only identifies the sibling node after the end tag of the current node, but does not contain other child nodes;
with https://www.guru99.com/ Take this website as an example, as shown in the figure below:
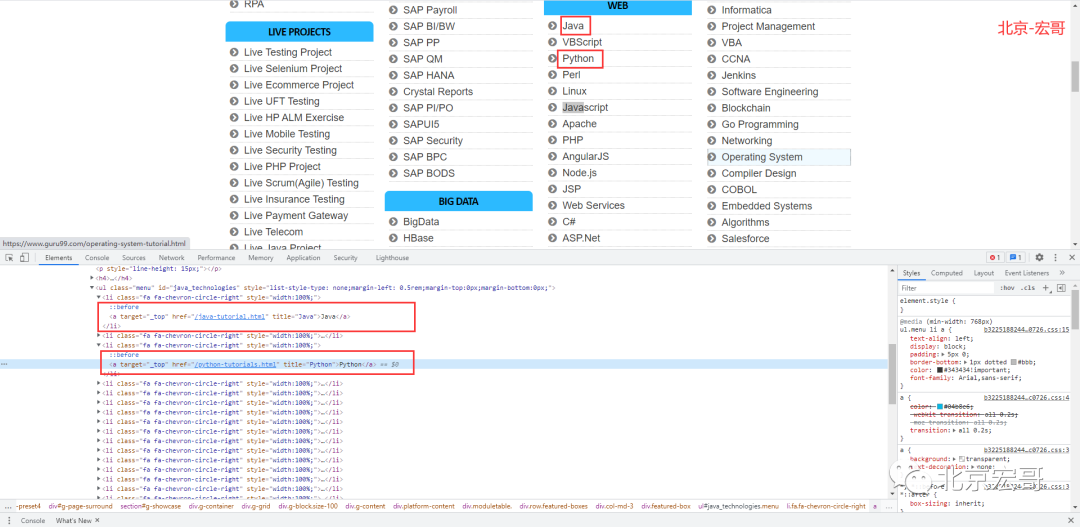
To locate python in a web page:
//Positioning ideas: / / (1) locate Java first, then find the parent node li of Java, / / (2) then find the brother node of Li, that is, the Li tag containing Python, / / (3) then find the child node of Li, that is, the a tag xpath="//a[text()='Java']/parent::li/following-sibling::li/child::a[text()='Python']" //perhaps xpath="//a[text()='Java']/parent::li/following-sibling::li[2]/a"
Brother Hong doesn't do verification here. If you are interested or don't believe in children's shoes, you can verify it yourself according to brother Hong's method.
6. Summary
Well, the first two xpath positioning methods shared today are relatively simple, and the third one is more difficult, but it's just like that after slowly accumulating experience for a long time. This is the end of brother Hong's sharing today. There are some more in the back. Please look forward to it.
7. Expansion
① Xpath location extension
Use to locate the parent node through the child node
.. Represents the parent node;.. / Grandpa node
//span[contains(text(),'1.jpg')]/..
② Xpath also supports Boolean positioning
Xpath = //input[@id='kw1' and @name='wd']
Yes and, of course, or:
Xpath = //input[@id='kw1' or @name='wd']
Well, that's all for sharing and explaining today. Next, I'll continue to look at other positioning methods of xpath with brother Hong.
The following is the supporting information. For the friends doing [software testing], it should be the most comprehensive and complete war preparation warehouse. This warehouse has also accompanied me through the most difficult journey. I hope it can also help you!
Finally, it can be in the official account: programmer Hao! Get a 216 page interview document of Software Test Engineer for free. And the corresponding video learning tutorials for free!, It includes basic knowledge, Linux essentials, Shell, Internet program principles, Mysql database, special topics of packet capture tools, interface test tools, test advanced Python programming, Web automation test, APP automation test, interface automation test, advanced continuous test integration, test architecture, development test framework, performance test, security test, etc.
If my blog is helpful to you and you like my blog content, please click "like", "comment" and "collect" for three times! Friends who like software testing can join our testing technology exchange group: 310357728 (there are various software testing resources and technical discussions)
