Write in front
It's not happy for the Chinese New Year. I want to buy new year's products and gifts for my girlfriend. Analyze the price and see what the price is really reduced~
preparation
Drive installation
Before implementing the case, we need to install a Google driver first, because we use selenium to manipulate the Google driver, and then manipulate the browser to achieve automatic operation, simulating human behavior to operate the browser.
Take Google browser as an example. Open the browser to see our own version, and then download the version that is the same as or closest to our own browser version. After downloading, unzip it, and put the unzipped plug-in into our python environment, or together with the code.
Module usage and introduction
- Selenium # pip install selenium. If you enter selenium directly, the latest version will be installed by default. Adding the version number after selenium is to install the corresponding version;
- csv # built-in module, which does not need to be installed. It is used to save data to Excel table;
- Time is a built-in module, which does not need to be installed. The time module is mainly used for delay waiting;
Process analysis
When we visit a website, we need to enter a website address, so the code is written like this.
Import the module first
from selenium import webdriver
The file name or package name should not be named selenium, which will result in failure to import.
Webdriver can be regarded as the driver of the browser. To drive the browser, webdriver must be used to support a variety of browsers.
Instantiate browser objects. I use Google here. I suggest you use Google for convenience.
driver = webdriver.Chrome()
We use get to visit a website and automatically open the website.
driver.get('https://www.jd.com/')
Run it
After opening the website, take buying lipstick as an example.
First, we should search the commodity information through the commodity keywords you want to buy, and use the search results to obtain the information.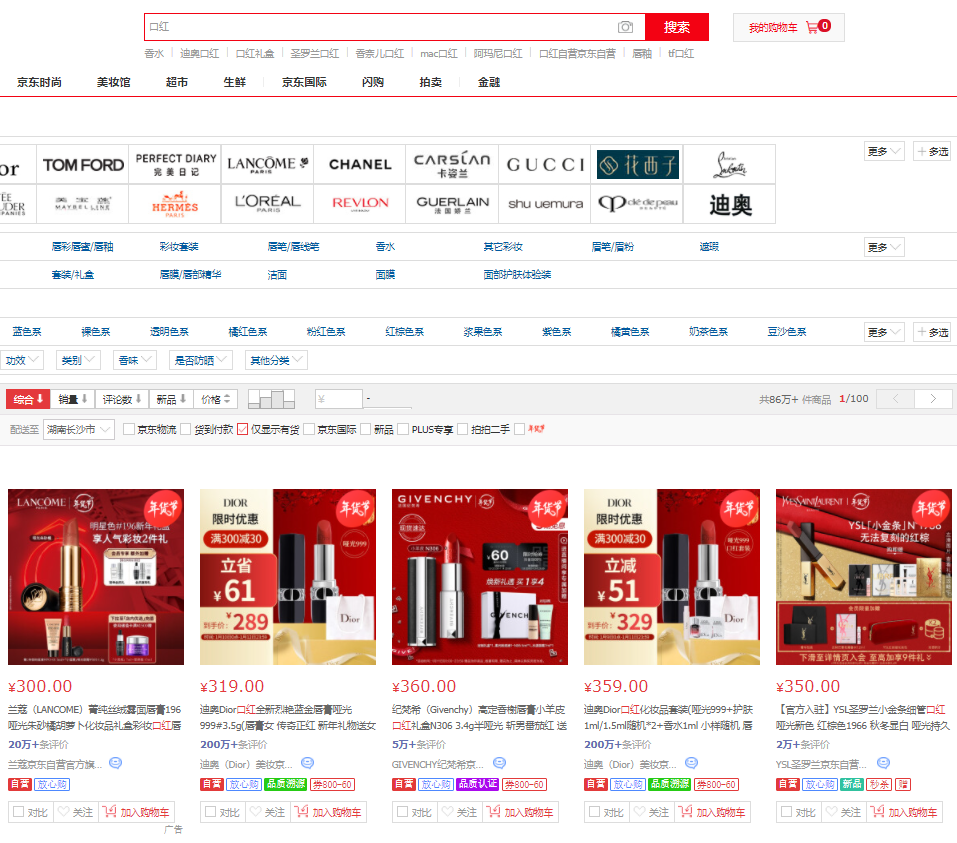
Then we also need to write an input. Right click in the blank and select check.
Select the element panel
Click the arrow button on the left and click the search box. It will directly locate the Search tab.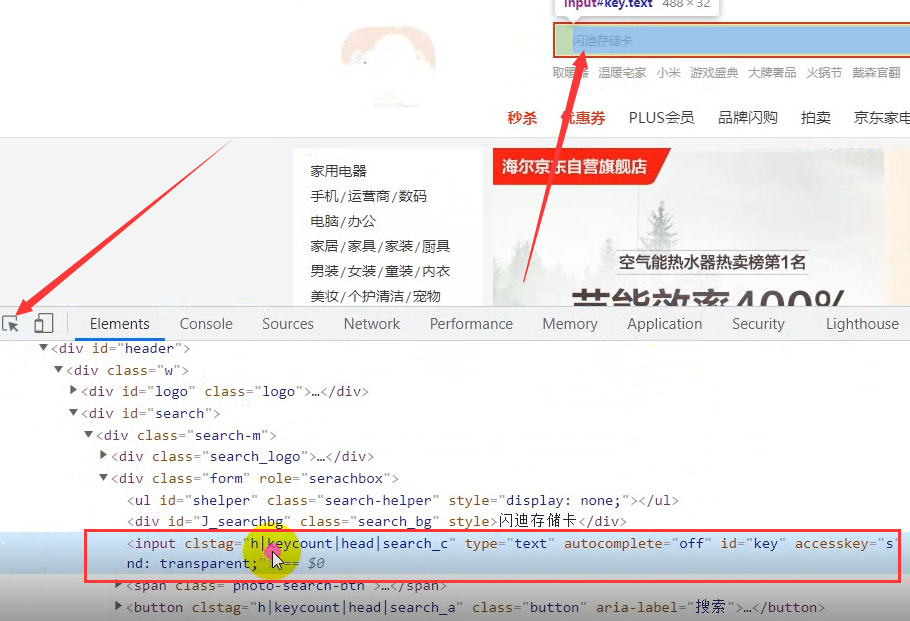
Right click the tab, select copy and select copy selector.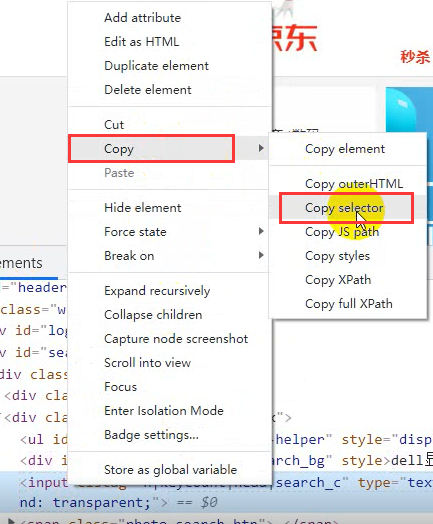
If you are an xpath, copy its xpath.
Then write out what we want to search
driver.find_element_by_css_selector('#key').send_keys('Lipstick')
When it runs again, it will automatically open the browser and enter the target website to search for lipstick.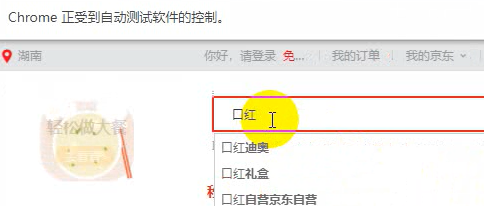
In the same way, find the search button and click.
driver.find_element_by_css_selector('.button').click()
Run again and you'll automatically click search
The page is searched out, so we normally browse the web page to pull down the web page, right? Let's let it pull down automatically.
Import the time module first
import time
Perform page scrolling
def drop_down(): """Perform page scrolling""" # javascript for x in range(1, 12, 2): # for Cycle pull-down times, take 1 3 5 7 9 11, in your continuous pull-down process, The page height will also change; time.sleep(1) j = x / 9 # 1/9 3/9 5/9 9/9 # document.documentElement.scrollTop Specifies the position of the scroll bar # document.documentElement.scrollHeight Gets the maximum height of the browser page js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j driver.execute_script(js) # Execute us JS code
The cycle is written, and then called.
drop_down()
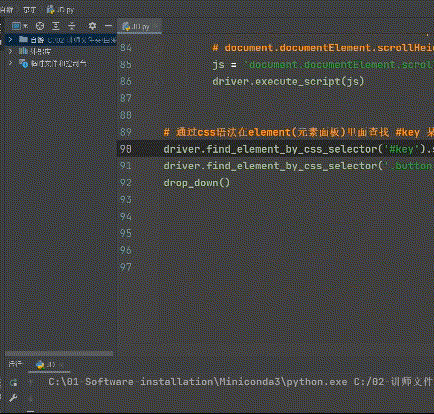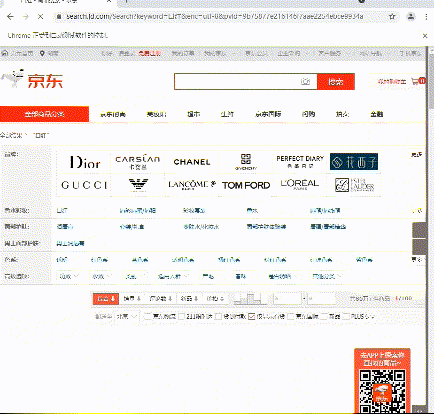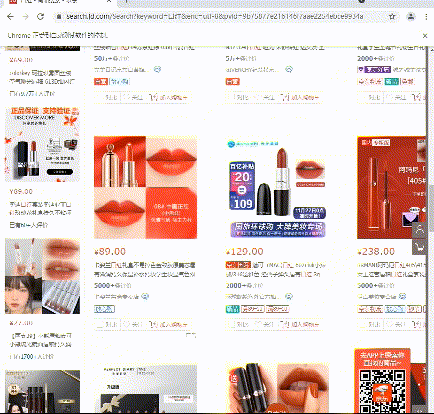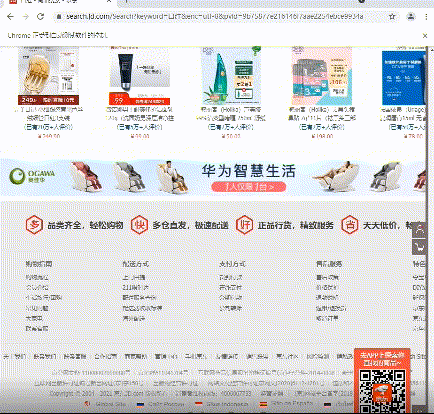
Let's give it another delay
driver.implicitly_wait(10)
This is an implicit wait. Wait for the web page to delay. If the web is bad, the load is very slow.
Implicit waiting does not have to wait ten seconds. After your network is loaded in ten seconds, it will be loaded at any time. If it is not loaded in ten seconds, it will be forced to load.
There is another kind of dead waiting. You wait for a few seconds when you write, which is relatively less humanized.
time.sleep(10)
After loading the data, we need to find the source of commodity data
Price / Title / evaluation / cover / store, etc
Or right click to check. In element, click the small arrow to click the data you want to view.
You can see it all in the li tag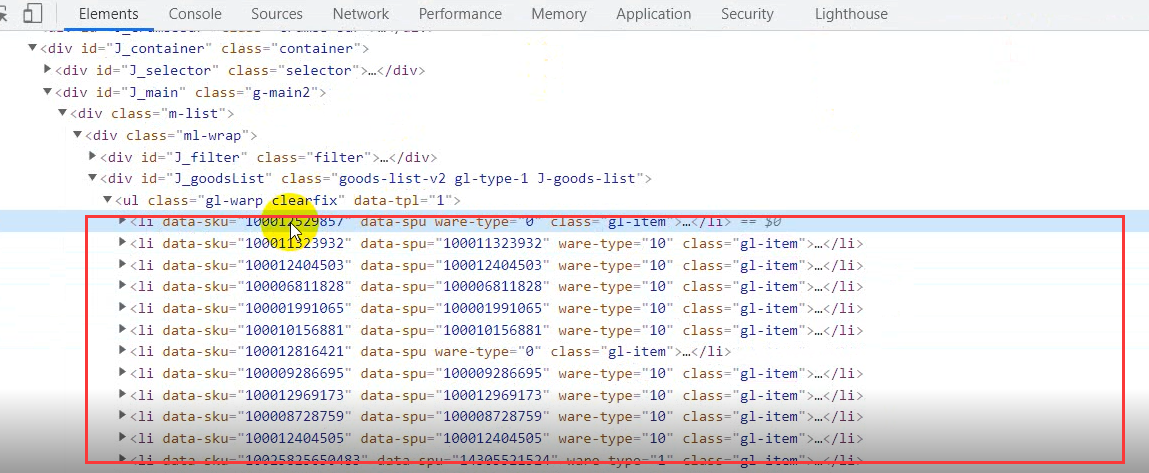
Get all the li tag contents. It's the same. copy directly.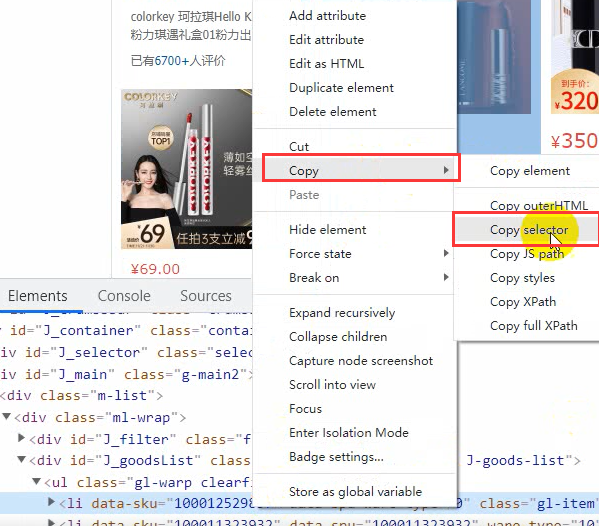
It's in the lower left corner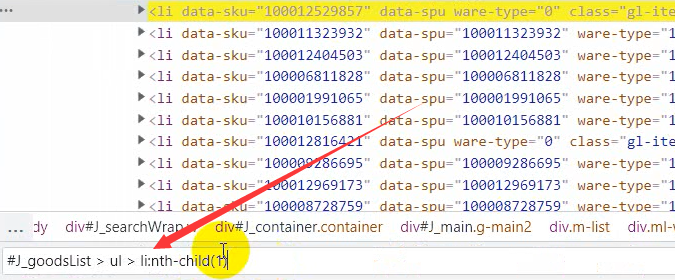
This means that we take the first one, but we want to get all the tags, so the one behind li in the left border box can be deleted.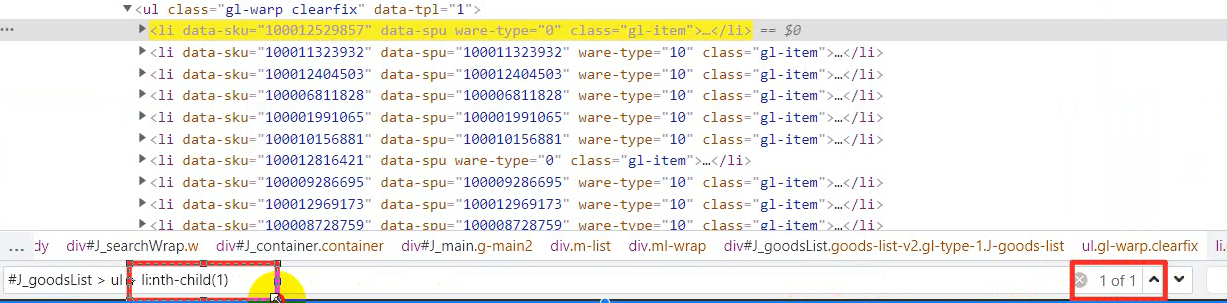
If you don't want to, you can see that here are 60 commodity data and one page is 60.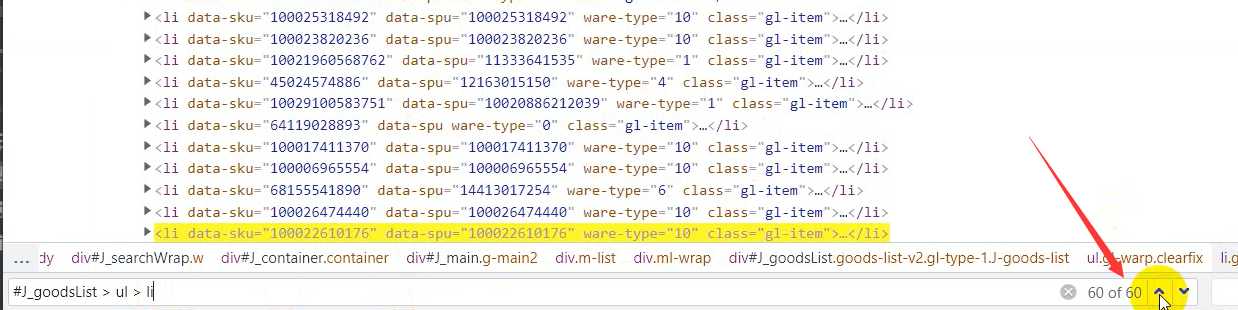
So we copied the rest and received it with lis.
lis = driver.find_elements_by_css_selector('#J_goodsList ul li')
Because we get all the tag data, we have an s more than before
Print it
print(lis)
Return the element < > object in the data list [] list through lis
Traverse it and take out all the elements.
for li in lis: title = li.find_element_by_css_selector('.p-name em').text.replace('\n', '') # Get label text data for item title price = li.find_element_by_css_selector('.p-price strong i').text # Price commit = li.find_element_by_css_selector('.p-commit strong a').text # Comment volume shop_name = li.find_element_by_css_selector('.J_im_icon a').text # Shop name href = li.find_element_by_css_selector('.p-img a').get_attribute('href') # Product details page icons = li.find_elements_by_css_selector('.p-icons i') icon = ','.join([i.text for i in icons]) # List derivation ','.join Concatenate the elements in the list into a string of data with commas dit = { 'Product title': title, 'commodity price': price, 'Comment volume': commit, 'Shop name': shop_name, 'label': icon, 'Product details page': href, } csv_writer.writerow(dit) print(title, price, commit, href, icon, sep=' | ')
Search function
key_world = input('Please enter the product data you want to obtain: ')
The data to be acquired is saved in CSV after being acquired
f = open(f'JD.COM{key_world}Commodity data.csv', mode='a', encoding='utf-8', newline='') csv_writer = csv.DictWriter(f, fieldnames=[ 'Product title', 'commodity price', 'Comment volume', 'Shop name', 'label', 'Product details page', ]) csv_writer.writeheader()
Then write an automatic page turning
for page in range(1, 11): print(f'Crawling to No{page}Data content of the page') time.sleep(1) drop_down() get_shop_info() # Download data driver.find_element_by_css_selector('.pn-next').click() # Click next
Video tutorial
It's not so detailed in the back. If you have something, you can send it directly. You can click below to watch the video directly
Python + selenium collects Jingdong commodity data and saves it in Excel
Complete code
from selenium import webdriver import time import csv def drop_down(): """Perform page scrolling""" for x in range(1, 12, 2): time.sleep(1) j = x / 9 # 1/9 3/9 5/9 9/9 # document.documentElement.scrollTop Specifies the position of the scroll bar # document.documentElement.scrollHeight Gets the maximum height of the browser page js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j driver.execute_script(js) # implement JS code key_world = input('Please enter the product data you want to obtain: ') f = open(f'JD.COM{key_world}Commodity data.csv', mode='a', encoding='utf-8', newline='') csv_writer = csv.DictWriter(f, fieldnames=[ 'Product title', 'commodity price', 'Comment volume', 'Shop name', 'label', 'Product details page', ]) csv_writer.writeheader() # Instantiate a browser object driver = webdriver.Chrome() driver.get('https://www.jd.com/') # Visit a web address open browser open web address # adopt css Grammar in element(Element panel)Look inside #key enter a keyword lipstick for a tag data driver.find_element_by_css_selector('#key').send_keys(key_world) # Locate the input box label driver.find_element_by_css_selector('.button').click() # Find the search button and click # time.sleep(10) # wait for # driver.implicitly_wait(10) # Implicit waiting def get_shop_info(): # Step 1 get all li Label content driver.implicitly_wait(10) lis = driver.find_elements_by_css_selector('#J_goodsList ul li') # Get multiple tags # Return data list [] Elements in the list <> object # print(len(lis)) for li in lis: title = li.find_element_by_css_selector('.p-name em').text.replace('\n', '') # Get label text data for item title price = li.find_element_by_css_selector('.p-price strong i').text # Price commit = li.find_element_by_css_selector('.p-commit strong a').text # Comment volume shop_name = li.find_element_by_css_selector('.J_im_icon a').text # Shop name href = li.find_element_by_css_selector('.p-img a').get_attribute('href') # Product details page icons = li.find_elements_by_css_selector('.p-icons i') icon = ','.join([i.text for i in icons]) # List derivation ','.join Concatenate the elements in the list into a string of data with commas dit = { 'Product title': title, 'commodity price': price, 'Comment volume': commit, 'Shop name': shop_name, 'label': icon, 'Product details page': href, } csv_writer.writerow(dit) print(title, price, commit, href, icon, sep=' | ') # print(href) for page in range(1, 11): print(f'Climbing to the third{page}Data content of the page') time.sleep(1) drop_down() get_shop_info() # Download data driver.find_element_by_css_selector('.pn-next').click() # Click next driver.quit() # Close browser
# Brothers learn python,Sometimes I don't know how to learn or where to start. After mastering some basic grammar or doing two cases, I don't know what to do next or how to learn more advanced knowledge. # So for these big brothers, I have prepared a lot of free video tutorials, PDF E-books, and video source code! # There will be big guys to answer! # All in this group 924040232 # Welcome to join us, discuss and study together!
Effect display


There is no problem with the code. You can try it. If you have any questions, please communicate in the comment area~