In this way, we have basically finished reading the Configuration class. This is a congestion model with a lot of content.
Next, go back to NamesrvController. Under the Configuration class, the FileWatchService class is declared. From the outside, it should be a file reading service. Go in and have a look:
org.apache.rocketmq.srvutil.FileWatchService
public class FileWatchService extends ServiceThread {
public abstract class ServiceThread implements Runnable {
After entering, we found that this class actually inherits ServiceThread, and ServiceThread implements the Runnable interface. It seems that it is actually an asynchronous task.
private static final InternalLogger log = InternalLoggerFactory.getLogger(LoggerName.COMMON_LOGGER_NAME);
private final List<String> watchFiles;
private final List<String> fileCurrentHash;
private final Listener listener;
private static final int WATCH_INTERVAL = 500;
private MessageDigest md = MessageDigest.getInstance("MD5");
First, declare the log, collection and listener. There is also a jdk underlying tool class for summary encryption: MessageDigest. You can see that the md5 encryption algorithm is declared.
Then enter the construction method of FileWatchService:
public FileWatchService(final String[] watchFiles,
final Listener listener) throws Exception {
this.listener = listener;
this.watchFiles = new ArrayList<>();
this.fileCurrentHash = new ArrayList<>();
for (int i = 0; i < watchFiles.length; i++) {
if (StringUtils.isNotEmpty(watchFiles[i]) && new File(watchFiles[i]).exists()) {
this.watchFiles.add(watchFiles[i]);
this.fileCurrentHash.add(hash(watchFiles[i]));
}
}
}
The listener is set in the construction method, and then all the files to be viewed are added to the watchFIles collection. The hash value of the file is added to the fileCurrentHash collection. Next, look
hash(watchFiles[i])
What is done in this method:
private String hash(String filePath) throws IOException, NoSuchAlgorithmException {
Path path = Paths.get(filePath);
md.update(Files.readAllBytes(path));
byte[] hash = md.digest();
return UtilAll.bytes2string(hash);
}
Read all the bytes of the file in the specified file path, and then md5 encrypt them into hash code, and then convert them into string return.
Look at the main method
run()
What has been done in:
for (int i = 0; i < watchFiles.size(); i++) {
String newHash;
try {
newHash = hash(watchFiles.get(i));
} catch (Exception ignored) {
log.warn(this.getServiceName() + " service has exception when calculate the file hash. ", ignored);
continue;
}
if (!newHash.equals(fileCurrentHash.get(i))) {
fileCurrentHash.set(i, newHash);
listener.onChanged(watchFiles.get(i));
}
}
In this for loop, the watchFiles is traversed once, a hash value is retrieved for all files, and the changed files are replaced. Remember the fileCurrentHash collection? The hash codes of all files are stored here. And then called the listener.
onChanged(watchFiles.get(i))
Method, how to implement it, in NamesrvController.
This is FileWatchService. In fact, it is an implementation of the runnable interface. The content is to traverse watchFiles. If the hash code is changed, refresh fileCurrentHash again.
Go back to NamesrvController and continue
Add up to initialization
initialize()
method:
public boolean initialize() {
this.kvConfigManager.load();
this.remotingServer = new NettyRemotingServer(this.nettyServerConfig, this.brokerHousekeepingService);
this.remotingExecutor =
Executors.newFixedThreadPool(nettyServerConfig.getServerWorkerThreads(), new ThreadFactoryImpl("RemotingExecutorThread_"));
this.registerProcessor();
Here is a loading method of kvConfigManager. Go in and have a look:
public void load() {
String content = null;
try {
content = MixAll.file2String(this.namesrvController.getNamesrvConfig().getKvConfigPath());
} catch (IOException e) {
log.warn("Load KV config table exception", e);
}
if (content != null) {
KVConfigSerializeWrapper kvConfigSerializeWrapper =
KVConfigSerializeWrapper.fromJson(content, KVConfigSerializeWrapper.class);
if (null != kvConfigSerializeWrapper) {
this.configTable.putAll(kvConfigSerializeWrapper.getConfigTable());
log.info("load KV config table OK");
}
}
}
Because we have read kvConfigManager, it looks easier here. Read the configuration of the specified path, convert it to string type, convert it from string type to json type, insert it into kvConfigSerializeWrapper, and then insert the configuration table configTable in kvConfigSerializeWrapper into the configuration table in kvConfigManager. See this class:
org.apache.rocketmq.namesrv.kvconfig.KVConfigSerializeWrapper
kvConfig serialization wrapper. There is only one configuration table inside:
private HashMap<String/* Namespace */, HashMap<String/* Key */, String/* Value */>> configTable;
public HashMap<String, HashMap<String, String>> getConfigTable() {
return configTable;
}
public void setConfigTable(HashMap<String, HashMap<String, String>> configTable) {
this.configTable = configTable;
}
You can see that this KVConfig is actually based on Namesapce. I remember Namesapce in RocketMq theory learning. I saw something in the theory in the source code for the first time. In short, the classification of configuration items is based on namespace.
Back to NamesrvController, the next step is to create an actuator (thread pool) and register the processor. Remember that the bottom layer of RocketMq has a feature that the execution method needs to be transmitted to an actuator (the bottom layer of the executor is the thread pool) and a processor (the processor is the specific task). Next, let's take a look at the registered processor
registerProcessor();
What did you do at the bottom
private void registerProcessor() {
if (namesrvConfig.isClusterTest()) {
this.remotingServer.registerDefaultProcessor(new ClusterTestRequestProcessor(this, namesrvConfig.getProductEnvName()),
this.remotingExecutor);
} else {
this.remotingServer.registerDefaultProcessor(new DefaultRequestProcessor(this), this.remotingExecutor);
}
}
First, judge whether it is a cluster test. This switch is written as false, so let's look at the content of else directly
@Override
public void registerDefaultProcessor(NettyRequestProcessor processor, ExecutorService executor) {
this.defaultRequestProcessor = new Pair<NettyRequestProcessor, ExecutorService>(processor, executor);
}
You can see that the DefaultProcessor in remotingServer is initialized
protected Pair<NettyRequestProcessor, ExecutorService> defaultRequestProcessor;
The bottom layer of the processor is the Pair. We have read nettyremoteingserver before.
After registering the processor, there are a series of scheduled tasks. Let's see what they have done:
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
NamesrvController.this.routeInfoManager.scanNotActiveBroker();
}
}, 5, 10, TimeUnit.SECONDS);
The first delayed task is delayed for 5s
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit);
Note that this period does not refer to the time interval, that is, the above 10s. This ten seconds refers to the execution time of the task. Of course, it may not take ten seconds, but it is only executed once within ten seconds. It is executed once in 5 + 10 seconds and twice in 5 + 10 + 10 seconds, that is, the second execution starts in the 15th second and the third execution starts in the 25th second. The interval between the two executions depends on 10 seconds minus the actual execution time. In fact, ten second period can also be understood as the interval between the start times of two tasks.
Next, let's look at the actual implementation
scanNotActiveBroker();
What has been done internally:
public void scanNotActiveBroker() {
Iterator<Entry<String, BrokerLiveInfo>> it = this.brokerLiveTable.entrySet().iterator();
while (it.hasNext()) {
Entry<String, BrokerLiveInfo> next = it.next();
long last = next.getValue().getLastUpdateTimestamp();
if ((last + BROKER_CHANNEL_EXPIRED_TIME) < System.currentTimeMillis()) {
RemotingUtil.closeChannel(next.getValue().getChannel());
it.remove();
log.warn("The broker channel expired, {} {}ms", next.getKey(), BROKER_CHANNEL_EXPIRED_TIME);
this.onChannelDestroy(next.getKey(), next.getValue().getChannel());
}
}
}
Scan the inactive circuit breaker pipeline broker channel. The content is relatively simple. Cycle through the surviving broker table. If more than
BROKER_CHANNEL_EXPIRED_TIME
If the time of is not active (i.e. not updated), it is considered to have expired and the channel corresponding to the broker is destroyed.
private final static long BROKER_CHANNEL_EXPIRED_TIME = 1000 * 60 * 2;
Here, the broker channel expiration time is defined as 2 minutes
Look at the second scheduled task:
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
NamesrvController.this.kvConfigManager.printAllPeriodically();
}
}, 1, 10, TimeUnit.MINUTES);
The content is delayed by 1 second, and the execution period is 10 seconds (the meaning of period has been explained above, and the subsequent period will be written directly without repeated explanation). The execution content is to regularly print all the information of KVConfigManager. That is to print all configurations. I've seen the KVConfigManager class before. All configuration classes divided by namespace are stored inside.
Here's the core code:
{
log.info("configTable SIZE: {}", this.configTable.size());
Iterator<Entry<String, HashMap<String, String>>> it =
this.configTable.entrySet().iterator();
while (it.hasNext()) {
Entry<String, HashMap<String, String>> next = it.next();
Iterator<Entry<String, String>> itSub = next.getValue().entrySet().iterator();
while (itSub.hasNext()) {
Entry<String, String> nextSub = itSub.next();
log.info("configTable NS: {} Key: {} Value: {}", next.getKey(), nextSub.getKey(),
nextSub.getValue());
}
}
}
This is to print all the contents of the configTable, and print the key value.
Next is a method. First look at the comment in front of this method:
// Register a listener to reload SslContext
Register a listener to overload the sslContext. This context is related to the network communication protocol. We have seen it before, but we still don't know if we only look at this line of comments. Therefore, take a look at the code:
Let's review the construction method of FileWatchService class we saw earlier:
public FileWatchService(final String[] watchFiles,
final Listener listener) throws Exception {
Two parameters, a file name string array, and a listener. What we see right away is its use:
fileWatchService = new FileWatchService(
new String[] {
TlsSystemConfig.tlsServerCertPath,
TlsSystemConfig.tlsServerKeyPath,
TlsSystemConfig.tlsServerTrustCertPath
},
new FileWatchService.Listener() {
boolean certChanged, keyChanged = false;
@Override
public void onChanged(String path) {
if (path.equals(TlsSystemConfig.tlsServerTrustCertPath)) {
log.info("The trust certificate changed, reload the ssl context");
reloadServerSslContext();
}
if (path.equals(TlsSystemConfig.tlsServerCertPath)) {
certChanged = true;
}
if (path.equals(TlsSystemConfig.tlsServerKeyPath)) {
keyChanged = true;
}
if (certChanged && keyChanged) {
log.info("The certificate and private key changed, reload the ssl context");
certChanged = keyChanged = false;
reloadServerSslContext();
}
}
Three incoming files, three system level configuration files. Look at the contents of the following three files: tls server certificate file, tls server private key file, and tls server trusted client certificate file. Are documents related to the protocol certificate. Look at the listener. First, we know that the listener listens to the code to be executed if the three files are changed. When the tlsServerTrustCert file is changed, the overload will be triggered immediately; Overloading is also triggered when tlsServerCert and tlsServerKey are changed at the same time. Next, let's look at the overload method
reloadServerSslContext();
What has been done internally:
private void reloadServerSslContext() {
((NettyRemotingServer) remotingServer).loadSslContext();
}
You can see that reload is a call to NettyRemotingServer again
public void loadSslContext()
Method, which we have seen before. In fact, it is to read out the configuration file in the hard disk and insert it into sslContext in the form of properties. At this time
fileWatchService = new FileWatchService(
In fact, it is not "reading documents", but "looking after documents". That is, when some files change, the listener is triggered.
Here, when the ssl certificate related files change, the content of the ssl context is refreshed in real time to the latest certificate file content. It can be understood that when starting NamesrvController, a sentinel is established to watch the configuration file all the time. When there is any change in the configuration file, the global sslContext is updated immediately.
Then there is one
start( )
Method
public void start() throws Exception {
this.remotingServer.start();
if (this.fileWatchService != null) {
this.fileWatchService.start();
}
}
The remote connection server starts and the file monitoring starts. The remote connection here is the connection between the client and the server based on netty. fileWatchService is what we just read. After reading the source code, it is actually monitoring the changes of the configuration file, so it is called file monitoring. Look again
fileWatchService.start( )
What has been done internally:
public void start() {
log.info("Try to start service thread:{} started:{} lastThread:{}", getServiceName(), started.get(), thread);
if (!started.compareAndSet(false, true)) {
return;
}
stopped = false;
this.thread = new Thread(this, getServiceName());
this.thread.setDaemon(isDaemon);
this.thread.start();
}
At first glance, this seems a little confused. Why does the thread thread come out? But in fact, we have read the source code of FileWatchService. This class implements the Runnable interface, so there must be a thread started inside
start()
Method, the content is to start the thread, but before that, there is an action to set the daemon to prevent the thread from being destroyed after one execution.
Here we can actually learn a coding detail of multithreading, which is to set an atomic boolean variable to ensure that the thread will be strictly executed only once.
//Make it able to restart the thread private final AtomicBoolean started = new AtomicBoolean(false);
It can be interrupted or restarted to make the running state of the thread visible.
Next is
shutdown( )
Methods:
public void shutdown() {
this.remotingServer.shutdown();
this.remotingExecutor.shutdown();
this.scheduledExecutorService.shutdown();
if (this.fileWatchService != null) {
this.fileWatchService.shutdown();
}
}
The server is closed, the actuator is closed, the scheduled task is closed, and the file monitoring is closed.
So far, we have read all NamesrvController and its related classes, but in fact, we come in from KVConfig, hahaha, but it doesn't matter, because we will read all classes, and it doesn't matter where we enter.
After reading NamesrvController, make a mark here
org.apache.rocketmq.namesrv.NamesrvController end
Let's summarize from a macro perspective, because there are many internal bottom layers.
NamesrvController consists of four parts: server remote connection, actuator, scheduled task and file monitoring
Next, go back to the starting point: KVConfigManager.
Sorry, KVConfigManager is over, too. Now I see. In fact, our starting point KVConfigManager is a small class, which belongs to the management of global configuration or the kv configuration storage based on namespace as a key, as we said before
private final HashMap<String/* Namespace */, HashMap<String/* Key */, String/* Value */>> configTable =
new HashMap<String, HashMap<String, String>>();
org.apache.rocketmq.namesrv.processor.ClusterTestRequestProcessor
Next, follow the package to find a cluster test request processor. Let's see how to handle cluster requests:
private static final InternalLogger log = InternalLoggerFactory.getLogger(LoggerName.NAMESRV_LOGGER_NAME); private final DefaultMQAdminExt adminExt; private final String productEnvName;
First, declare a log, string type, production environment name, and a DefaultMQAdminExt default mq management extension (we'll call it that temporarily). Then, let's go in and see what's going on inside this management extension:
org.apache.rocketmq.tools.admin.DefaultMQAdminExt
private final DefaultMQAdminExtImpl defaultMQAdminExtImpl; private String adminExtGroup = "admin_ext_group"; private String createTopicKey = TopicValidator.AUTO_CREATE_TOPIC_KEY_TOPIC; private long timeoutMillis = 5000;
After entering, first declare a default mq management extension implementation, timeout, and an enumeration class. The obtained value is the topic of automatically creating topic. Here are two classes, DefaultMQAdminExtImpl and TopicValidator. Let's look at the following:
org.apache.rocketmq.tools.admin.DefaultMQAdminExtImpl
private final InternalLogger log = ClientLogger.getLog(); private final DefaultMQAdminExt defaultMQAdminExt; private ServiceState serviceState = ServiceState.CREATE_JUST; private MQClientInstance mqClientInstance; private RPCHook rpcHook; private long timeoutMillis = 20000; private Random random = new Random();
Let's first look at the statements. Among these statements, we haven't read them. They should be ServiceState and MQClientInstance. Look at ServiceState:
org.apache.rocketmq.common.ServiceState
/** * Service just created,not start */ CREATE_JUST, /** * Service Running */ RUNNING, /** * Service shutdown */ SHUTDOWN_ALREADY, /** * Service Start failure */ START_FAILED;
Is a service status enumeration class, including: just created, running, destroyed, startup failed
org.apache.rocketmq.client.impl.factory.MQClientInstance
MQ client instance. After entering, he first declared:
private final static long LOCK_TIMEOUT_MILLIS = 3000; private final InternalLogger log = ClientLogger.getLog(); private final ClientConfig clientConfig; private final int instanceIndex; private final String clientId; private final long bootTimestamp = System.currentTimeMillis(); private final ConcurrentMap<String/* group */, MQProducerInner> producerTable = new ConcurrentHashMap<String, MQProducerInner>(); private final ConcurrentMap<String/* group */, MQConsumerInner> consumerTable = new ConcurrentHashMap<String, MQConsumerInner>(); private final ConcurrentMap<String/* group */, MQAdminExtInner> adminExtTable = new ConcurrentHashMap<String, MQAdminExtInner>(); private final NettyClientConfig nettyClientConfig; private final MQClientAPIImpl mQClientAPIImpl; private final MQAdminImpl mQAdminImpl;
Because there are too many contents in this MQ client example, I first pull out some declarations, and there are many internal classes that we haven't read, one by one.
org.apache.rocketmq.client.ClientConfig
The first is a client-side general configuration class to see what is equipped in it.
public static final String SEND_MESSAGE_WITH_VIP_CHANNEL_PROPERTY = "com.rocketmq.sendMessageWithVIPChannel";
private String namesrvAddr = NameServerAddressUtils.getNameServerAddresses();
private String clientIP = RemotingUtil.getLocalAddress();
private String instanceName = System.getProperty("rocketmq.client.name", "DEFAULT");
private int clientCallbackExecutorThreads = Runtime.getRuntime().availableProcessors();
protected String namespace;
protected AccessChannel accessChannel = AccessChannel.LOCAL;
The first is a series of declarations (headache). We won't look at the pure string. For example, the first one: send messages using the VIP channel. Look at the second line to get the NameServer address:
org.apache.rocketmq.common.utils.NameServerAddressUtils
This class is not very large. Let's take a look.
public static String getNameServerAddresses() {
return System.getProperty(MixAll.NAMESRV_ADDR_PROPERTY, System.getenv(MixAll.NAMESRV_ADDR_ENV));
}
The nameServer address is actually obtained from the system cache, that is
public static String getProperty(String key, String def)
In fact, this method is used in many places at the bottom of rocketMQ. As I saw earlier, some small variables (such as addresses) are directly stored in the system cache.
public static boolean validateInstanceEndpoint(String endpoint) {
return INST_ENDPOINT_PATTERN.matcher(endpoint).matches();
}
public static String parseInstanceIdFromEndpoint(String endpoint) {
if (StringUtils.isEmpty(endpoint)) {
return null;
}
return endpoint.substring(endpoint.lastIndexOf("/") + 1, endpoint.indexOf('.'));
}
public static String getNameSrvAddrFromNamesrvEndpoint(String nameSrvEndpoint) {
if (StringUtils.isEmpty(nameSrvEndpoint)) {
return null;
}
return nameSrvEndpoint.substring(nameSrvEndpoint.lastIndexOf('/') + 1);
}
This class is not big. Let's take a look at the remaining methods. The first is to verify whether the endpoint string meets the specification. The second is to get the instance id from the endpoint, and the third is to get the address of NameSrv from the namesrvindpoint. However, since the standard format of the endpoint is not clear, this problem is left first and continue to look back.
Returning to ClientConfig, the third line involves a network tool RemotingUtil:
org.apache.rocketmq.remoting.common.RemotingUtil
public static final String OS_NAME = System.getProperty("os.name");
private static final InternalLogger log = InternalLoggerFactory.getLogger(RemotingHelper.ROCKETMQ_REMOTING);
private static boolean isLinuxPlatform = false;
private static boolean isWindowsPlatform = false;
static {
if (OS_NAME != null && OS_NAME.toLowerCase().contains("linux")) {
isLinuxPlatform = true;
}
if (OS_NAME != null && OS_NAME.toLowerCase().contains("windows")) {
isWindowsPlatform = true;
}
}
After entering, the first is a static code block to judge the current environment. I also wrote a test class to see what my local environment is:
@Test
public void test21(){
String OS_NAME = System.getProperty("os.name");
System.out.println(OS_NAME);
// Mac OS X
}
The result shows that it is Mac OS X, which seems to belong to neither linux nor windows. Ha ha, I don't know whether the underlying layer of RocketMq is compatible with mac..
Next look
public static Selector openSelector()
This method
if (isLinuxPlatform()) {
try {
final Class<?> providerClazz = Class.forName("sun.nio.ch.EPollSelectorProvider");
if (providerClazz != null) {
try {
final Method method = providerClazz.getMethod("provider");
if (method != null) {
final SelectorProvider selectorProvider = (SelectorProvider) method.invoke(null);
if (selectorProvider != null) {
result = selectorProvider.openSelector();
}
}
} catch (final Exception e) {
log.warn("Open ePoll Selector for linux platform exception", e);
}
}
} catch (final Exception e) {
// ignore
}
}
The essence is to open a selector and return, but it makes a distinction between linux system and windows system. In the case of linux system, the class reflection mechanism is adopted and the
Of SelectorProvider
AbstractSelector openSelector( )
Method, while windows system
if (result == null) {
result = Selector.open();
}
Just this line, the static method directly called. But let's look at the bottom:
public static Selector open() throws IOException {
return SelectorProvider.provider().openSelector();
}
This open static method is also called
SelectorProvider.provider().openSelector()
Method, the two platforms are essentially the same, so it is not clear why linux systems use reflection mechanism to call.
Next, let's take a look at the original purpose of entering RemotingUtil:
String getLocalAddress()
Get local address:
public static String getLocalAddress() {
try {
// Traversal Network interface to get the first non-loopback and non-private address
Enumeration<NetworkInterface> enumeration = NetworkInterface.getNetworkInterfaces();
ArrayList<String> ipv4Result = new ArrayList<String>();
ArrayList<String> ipv6Result = new ArrayList<String>();
while (enumeration.hasMoreElements()) {
final NetworkInterface networkInterface = enumeration.nextElement();
if (isBridge(networkInterface)) {
continue;
}
final Enumeration<InetAddress> en = networkInterface.getInetAddresses();
while (en.hasMoreElements()) {
final InetAddress address = en.nextElement();
if (!address.isLoopbackAddress()) {
if (address instanceof Inet6Address) {
ipv6Result.add(normalizeHostAddress(address));
} else {
ipv4Result.add(normalizeHostAddress(address));
}
}
}
}
// prefer ipv4
if (!ipv4Result.isEmpty()) {
for (String ip : ipv4Result) {
if (ip.startsWith("127.0") || ip.startsWith("192.168")) {
continue;
}
return ip;
}
return ipv4Result.get(ipv4Result.size() - 1);
} else if (!ipv6Result.isEmpty()) {
return ipv6Result.get(0);
}
//If failed to find,fall back to localhost
final InetAddress localHost = InetAddress.getLocalHost();
return normalizeHostAddress(localHost);
} catch (Exception e) {
log.error("Failed to obtain local address", e);
}
return null;
}
From the beginning, the first is
Enumeration<NetworkInterface> enumeration = NetworkInterface.getNetworkInterfaces();
getNetworkInterfaces( )
This is Java Net package, which returns all interfaces on this machine. The Enumeration contains at least one element that may represent a loopback interface that only supports communication between native entities. You can use getnetworkinterfaces() + getinetaddress() to get all the IP addresses of the node.
Next, traverse all the interface enumeration s of the machine. If
isBridge(networkInterface)
Will skip, so let's see what this isBridge method does
private static boolean isBridge(NetworkInterface networkInterface) {
try {
if (isLinuxPlatform()) {
String interfaceName = networkInterface.getName();
File file = new File("/sys/class/net/" + interfaceName + "/bridge");
return file.exists();
}
You can see that to judge whether it is a bridge, the first condition must be a linux system, and a non linux system must not be a bridge. Then go to the specified path to see if there is a bridge file. It can be seen that if a port is a bridge, there will be a bridge file under the path. Judge whether it is a bridge or not, and judge according to whether the file exists.
Back to RemotingUtil
final Enumeration<InetAddress> en = networkInterface.getInetAddresses();
while (en.hasMoreElements()) {
final InetAddress address = en.nextElement();
if (!address.isLoopbackAddress()) {
if (address instanceof Inet6Address) {
ipv6Result.add(normalizeHostAddress(address));
} else {
ipv4Result.add(normalizeHostAddress(address));
}
}
}
After determining that it is not a bridge, obtain the address information for all non bridge ports on the machine. After filtering the loopback address, store it in the corresponding set according to ipv4 and ipv6. For the virtual loopback interface, you can see: https://baike.baidu.com/item/loopback/2779210?fr=aladdin
Personal understanding is an interface that does not communicate with the outside world (this understanding is not necessarily correct).
Here we can learn how to distinguish between IPv4 and IPv6 network addresses:
if (address instanceof Inet6Address)
The next step is to return the filtered ipv4 or ipv6 address. If not, return the local address.
if (!ipv4Result.isEmpty()) {
for (String ip : ipv4Result) {
if (ip.startsWith("127.0") || ip.startsWith("192.168")) {
continue;
}
return ip;
}
return ipv4Result.get(ipv4Result.size() - 1);
} else if (!ipv6Result.isEmpty()) {
return ipv6Result.get(0);
}
//If failed to find,fall back to localhost
final InetAddress localHost = InetAddress.getLocalHost();
return normalizeHostAddress(localHost);
It can be seen that the priority of returning ipv4 is higher than that of returning ipv6, and the ipv4 address acquisition is the last in the set, and the ipv6 address acquisition is the first in the set. The reason is not clear (or one may be selected randomly).
private int clientCallbackExecutorThreads = Runtime.getRuntime().availableProcessors();
Next is the call
availableProcessors( )
Method returns the number of processors available to the Java virtual machine. This value may change during a specific call to the virtual machine. Therefore, applications that are sensitive to the number of processors available should occasionally poll this property and adjust their resource usage appropriately. Return: the maximum number of processors available for the virtual machine; Never less than one.
As for how to use the number of available threads, we'll see later.
private LanguageCode language = LanguageCode.JAVA;
Take another look at the enumeration class of this language. It records every language.
org.apache.rocketmq.remoting.protocol.LanguageCode
JAVA((byte) 0), CPP((byte) 1), DOTNET((byte) 2), PYTHON((byte) 3), DELPHI((byte) 4), ERLANG((byte) 5), RUBY((byte) 6), OTHER((byte) 7), HTTP((byte) 8), GO((byte) 9), PHP((byte) 10), OMS((byte) 11);
You can see that all storage is byte type. After jdk9, the underlying storage of String is changed from char array to byte array to save space. Here, if we need to save space, we can learn to save data in bytes.
private int mqClientApiTimeout = 3 * 1000;
private int persistConsumerOffsetInterval = 1000 * 5;
private long pullTimeDelayMillsWhenException = 1000;
There are also timeouts that can be seen everywhere. You can also learn from asynchronous processing to improve availability. After all, synchronization is too unreliable. No wonder RocketMq is a ubiquitous actuator (asynchronous thread pool).
public String buildMQClientId() {
StringBuilder sb = new StringBuilder();
sb.append(this.getClientIP());
sb.append("@");
sb.append(this.getInstanceName());
if (!UtilAll.isBlank(this.unitName)) {
sb.append("@");
sb.append(this.unitName);
}
return sb.toString();
}
The next step is to build MQCLientId and string splicing. Client ip + instance name + cell name.
public String withNamespace(String resource) {
return NamespaceUtil.wrapNamespace(this.getNamespace(), resource);
}
public Set<String> withNamespace(Set<String> resourceSet) {
Set<String> resourceWithNamespace = new HashSet<String>();
for (String resource : resourceSet) {
resourceWithNamespace.add(withNamespace(resource));
}
return resourceWithNamespace;
}
The two methods with the same name, which handle collections (the following methods) and single resources (the above methods), essentially package the resource into the namespace configured by the current client. look down
NamespaceUtil.wrapNamespace(this.getNamespace(), resource)
This method:
This tool class is not large. Just pass this class:
org.apache.rocketmq.common.protocol.NamespaceUtil
Look at the first method first
/**
* Unpack namespace from resource, just like:
* (1) MQ_INST_XX%Topic_XXX --> Topic_XXX
* (2) %RETRY%MQ_INST_XX%GID_XXX --> %RETRY%GID_XXX
*
* @param resourceWithNamespace, topic/groupId with namespace.
* @return topic/groupId without namespace.
*/
public static String withoutNamespace(String resourceWithNamespace) {
Starting from the input and output parameters of the method body, you can also understand it. resourceWithNamespace has a namespace to withnamespace does not have a namespace
Obviously, it means string processing, removing namespace
Take another look at the notes. There is an example above, that is, remove the namespace and expose the Topic
StringBuilder stringBuilder = new StringBuilder();
if (isRetryTopic(resourceWithNamespace)) {
stringBuilder.append(MixAll.RETRY_GROUP_TOPIC_PREFIX);
}
if (isDLQTopic(resourceWithNamespace)) {
stringBuilder.append(MixAll.DLQ_GROUP_TOPIC_PREFIX);
}
String resourceWithoutRetryAndDLQ = withOutRetryAndDLQ(resourceWithNamespace);
int index = resourceWithoutRetryAndDLQ.indexOf(NAMESPACE_SEPARATOR);
if (index > 0) {
String resourceWithoutNamespace = resourceWithoutRetryAndDLQ.substring(index + 1);
return stringBuilder.append(resourceWithoutNamespace).toString();
}
return resourceWithNamespace;
It makes some distinctions according to different topics, RetryTopic or DLQTopic
public static String withoutNamespace(String resourceWithNamespace, String namespace) {
The following method is basically the same,
/** * If resource contains the namespace, unpack namespace from resource, just like: * (1) (MQ_INST_XX1%Topic_XXX1, MQ_INST_XX1) --> Topic_XXX1 * (2) (MQ_INST_XX2%Topic_XXX2, NULL) --> MQ_INST_XX2%Topic_XXX2 * (3) (%RETRY%MQ_INST_XX1%GID_XXX1, MQ_INST_XX1) --> %RETRY%GID_XXX1 * (4) (%RETRY%MQ_INST_XX2%GID_XXX2, MQ_INST_XX3) --> %RETRY%MQ_INST_XX2%GID_XXX2 * * @param resourceWithNamespace, topic/groupId with namespace. * @param namespace, namespace to be unpacked. * @return topic/groupId without namespace. */
If the resource path contains a namespace, remove the namespace
public static String wrapNamespace(String namespace, String resourceWithOutNamespace) {
Of course, there are also reverse ones. In addition to removing the namespace from the resource, there is also a namespace package for the resource
if (isRetryTopic(resourceWithOutNamespace)) {
stringBuilder.append(MixAll.RETRY_GROUP_TOPIC_PREFIX);
}
if (isDLQTopic(resourceWithOutNamespace)) {
stringBuilder.append(MixAll.DLQ_GROUP_TOPIC_PREFIX);
}
return stringBuilder.append(namespace).append(NAMESPACE_SEPARATOR).append(resourceWithoutRetryAndDLQ).toString();
Basically the same. It can also be seen here that topics are divided into two categories: RetryTopic and DLQTopic
And the namespace is divided by%
public static final String RETRY_GROUP_TOPIC_PREFIX = "%RETRY%"; public static final String DLQ_GROUP_TOPIC_PREFIX = "%DLQ%";
From the MixAll tool class, this is also accepted.
And the judgment method of RetryTopic DLQTopic:
public static boolean isRetryTopic(String resource) {
return StringUtils.isNotBlank(resource) && resource.startsWith(MixAll.RETRY_GROUP_TOPIC_PREFIX);
}
public static boolean isDLQTopic(String resource) {
return StringUtils.isNotBlank(resource) && resource.startsWith(MixAll.DLQ_GROUP_TOPIC_PREFIX);
}
That is, the resource path is
RetryTopic or DLQTopic
At the beginning.
Summarize the namesapceutil
org.apache.rocketmq.common.protocol.NamespaceUtil
This tool class,
It surrounds the namespace
It provides many splicing and splitting methods
For example, remove the namespace from the resource path
Or package the resource path with a namespace
Go back to the ClientConfig class
public Set<String> withNamespace(Set<String> resourceSet) {
Set<String> resourceWithNamespace = new HashSet<String>();
for (String resource : resourceSet) {
resourceWithNamespace.add(withNamespace(resource));
}
return resourceWithNamespace;
}
public String withoutNamespace(String resource) {
return NamespaceUtil.withoutNamespace(resource, this.getNamespace());
}
public Set<String> withoutNamespace(Set<String> resourceSet) {
Set<String> resourceWithoutNamespace = new HashSet<String>();
for (String resource : resourceSet) {
resourceWithoutNamespace.add(withoutNamespace(resource));
}
return resourceWithoutNamespace;
}
The next few methods are the same
For all resource paths in the resource collection
Do package namespace to namespace and other operations
Continue:
public MessageQueue queueWithNamespace(MessageQueue queue) {
if (StringUtils.isEmpty(this.getNamespace())) {
return queue;
}
return new MessageQueue(withNamespace(queue.getTopic()), queue.getBrokerName(), queue.getQueueId());
}
public Collection<MessageQueue> queuesWithNamespace(Collection<MessageQueue> queues) {
if (StringUtils.isEmpty(this.getNamespace())) {
return queues;
}
Iterator<MessageQueue> iter = queues.iterator();
while (iter.hasNext()) {
MessageQueue queue = iter.next();
queue.setTopic(withNamespace(queue.getTopic()));
}
return queues;
}
Here we come into contact with "message queue" for the first time
Three elements of message queue: Topic, BrokerName and QueueId
Then, the two methods here add NameSpace to the Topic package
We've just finished reading the ClientConfig class and just went through the MessageQueue
org.apache.rocketmq.common.message.MessageQueue
private static final long serialVersionUID = 6191200464116433425L;
private String topic;
private String brokerName;
private int queueId;
public MessageQueue() {
}
public MessageQueue(String topic, String brokerName, int queueId) {
this.topic = topic;
this.brokerName = brokerName;
this.queueId = queueId;
}
The first is the three elements of message queuing
Then there are empty parameter structure and full parameter structure
public String getTopic() {
return topic;
}
public void setTopic(String topic) {
this.topic = topic;
}
public String getBrokerName() {
return brokerName;
}
public void setBrokerName(String brokerName) {
this.brokerName = brokerName;
}
public int getQueueId() {
return queueId;
}
public void setQueueId(int queueId) {
this.queueId = queueId;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((brokerName == null) ? 0 : brokerName.hashCode());
result = prime * result + queueId;
result = prime * result + ((topic == null) ? 0 : topic.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
MessageQueue other = (MessageQueue) obj;
if (brokerName == null) {
if (other.brokerName != null)
return false;
} else if (!brokerName.equals(other.brokerName))
return false;
if (queueId != other.queueId)
return false;
if (topic == null) {
if (other.topic != null)
return false;
} else if (!topic.equals(other.topic))
return false;
return true;
}
@Override
public String toString() {
return "MessageQueue [topic=" + topic + ", brokerName=" + brokerName + ", queueId=" + queueId + "]";
}
Are the methods of the basic pojo class
get set method hashcode equals method
toString method
@Override
public int compareTo(MessageQueue o) {
{
int result = this.topic.compareTo(o.topic);
if (result != 0) {
return result;
}
}
{
int result = this.brokerName.compareTo(o.brokerName);
if (result != 0) {
return result;
}
}
return this.queueId - o.queueId;
}
Then there is a compareTo method..
It is not clear what scenario will use message queue comparison. If implemented internally,
First compare topic, then brokerName, and finally queueId
/**
* Compares two strings lexicographically.
* The comparison is based on the Unicode value of each character in
* the strings. The character sequence represented by this
* {@code String} object is compared lexicographically to the
* character sequence represented by the argument string. The result is
* a negative integer if this {@code String} object
* lexicographically precedes the argument string. The result is a
* positive integer if this {@code String} object lexicographically
* follows the argument string. The result is zero if the strings
* are equal; {@code compareTo} returns {@code 0} exactly when
* the {@link #equals(Object)} method would return {@code true}.
* <p>
* This is the definition of lexicographic ordering. If two strings are
* different, then either they have different characters at some index
* that is a valid index for both strings, or their lengths are different,
* or both. If they have different characters at one or more index
* positions, let <i>k</i> be the smallest such index; then the string
* whose character at position <i>k</i> has the smaller value, as
* determined by using the < operator, lexicographically precedes the
* other string. In this case, {@code compareTo} returns the
* difference of the two character values at position {@code k} in
* the two string -- that is, the value:
* <blockquote><pre>
* this.charAt(k)-anotherString.charAt(k)
* </pre></blockquote>
* If there is no index position at which they differ, then the shorter
* string lexicographically precedes the longer string. In this case,
* {@code compareTo} returns the difference of the lengths of the
* strings -- that is, the value:
* <blockquote><pre>
* this.length()-anotherString.length()
* </pre></blockquote>
*
* @param anotherString the {@code String} to be compared.
* @return the value {@code 0} if the argument string is equal to
* this string; a value less than {@code 0} if this string
* is lexicographically less than the string argument; and a
* value greater than {@code 0} if this string is
* lexicographically greater than the string argument.
*/
For string comparison, see this comment
compareTo method for String type variables
The comparison is based on the dictionary order ratio, that is, the ratio of a < B, and then position by position
So far, both ClientConfig and MessageQueue have been read
Next, we return to MQClientInstance
Seriously, I almost forgot where I came in..
Under clientConfig, three tables and a configuration class are declared, which has been interpreted earlier
private final ConcurrentMap<String/* group */, MQProducerInner> producerTable = new ConcurrentHashMap<String, MQProducerInner>(); private final ConcurrentMap<String/* group */, MQConsumerInner> consumerTable = new ConcurrentHashMap<String, MQConsumerInner>(); private final ConcurrentMap<String/* group */, MQAdminExtInner> adminExtTable = new ConcurrentHashMap<String, MQAdminExtInner>(); private final NettyClientConfig nettyClientConfig;
Next, enter mqclientapimpl
org.apache.rocketmq.client.impl.MQClientAPIImpl
public class MQClientAPIImpl {
private final static InternalLogger log = ClientLogger.getLog();
private static boolean sendSmartMsg =
Boolean.parseBoolean(System.getProperty("org.apache.rocketmq.client.sendSmartMsg", "true"));
static {
System.setProperty(RemotingCommand.REMOTING_VERSION_KEY, Integer.toString(MQVersion.CURRENT_VERSION));
}
Although it is called Impl, this implementation class has no interface..
After entering, there are also some initialization, so I won't look at it
private final RemotingClient remotingClient; private final TopAddressing topAddressing; private final ClientRemotingProcessor clientRemotingProcessor; private String nameSrvAddr = null; private ClientConfig clientConfig;
Take a look at TopAddressing
org.apache.rocketmq.common.namesrv.TopAddressing
private static final InternalLogger log = InternalLoggerFactory.getLogger(LoggerName.COMMON_LOGGER_NAME); private String nsAddr; private String wsAddr; private String unitName;
As you can see, the pojo class consists of three strings
Where ns refers to nameServer
public void createSubscriptionGroup(final String addr, final SubscriptionGroupConfig config,
final long timeoutMillis)
throws RemotingException, MQBrokerException, InterruptedException, MQClientException {
RemotingCommand request = RemotingCommand.createRequestCommand(RequestCode.UPDATE_AND_CREATE_SUBSCRIPTIONGROUP, null);
byte[] body = RemotingSerializable.encode(config);
request.setBody(body);
RemotingCommand response = this.remotingClient.invokeSync(MixAll.brokerVIPChannel(this.clientConfig.isVipChannelEnabled(), addr),
request, timeoutMillis);
assert response != null;
switch (response.getCode()) {
case ResponseCode.SUCCESS: {
return;
}
default:
break;
}
throw new MQClientException(response.getCode(), response.getRemark());
}
Take a look at this method and create the subscription group createSubscriptionGroup
After the assembly request, the VIP channel of the broker is called synchronously
RemotingCommand request = RemotingCommand.createRequestCommand(RequestCode.UPDATE_AND_CREATE_SUBSCRIPTIONGROUP, null);
The writing here is also worth learning from. In our actual business code, assembly requests are
All kinds of get set s are written in a pile, but in fact, for requests that are not often changed
Or it is a relatively fixed request, which can be written in a unified tool
RemotingCommand
Then an enumeration class is used to select what kind of request to create
org.apache.rocketmq.common.protocol.RequestCode
public class RequestCode {
public static final int SEND_MESSAGE = 10;
public static final int PULL_MESSAGE = 11;
public static final int QUERY_MESSAGE = 12;
public static final int QUERY_BROKER_OFFSET = 13;
public static final int QUERY_CONSUMER_OFFSET = 14;
public static final int UPDATE_CONSUMER_OFFSET = 15;
public static final int UPDATE_AND_CREATE_TOPIC = 17;
public static final int GET_ALL_TOPIC_CONFIG = 21;
public static final int GET_TOPIC_CONFIG_LIST = 22;
public static final int GET_TOPIC_NAME_LIST = 23;
public static final int UPDATE_BROKER_CONFIG = 25;
This is an enumeration class. If there is too much content, copy a small part
The following is the creation of the request:
org.apache.rocketmq.broker.processor.AdminBrokerProcessor
@Override
public RemotingCommand processRequest(ChannelHandlerContext ctx,
RemotingCommand request) throws RemotingCommandException {
switch (request.getCode()) {
case RequestCode.UPDATE_AND_CREATE_TOPIC:
return this.updateAndCreateTopic(ctx, request);
case RequestCode.DELETE_TOPIC_IN_BROKER:
return this.deleteTopic(ctx, request);
case RequestCode.GET_ALL_TOPIC_CONFIG:
return this.getAllTopicConfig(ctx, request);
case RequestCode.UPDATE_BROKER_CONFIG:
return this.updateBrokerConfig(ctx, request);
case RequestCode.GET_BROKER_CONFIG:
return this.getBrokerConfig(ctx, request);
case RequestCode.SEARCH_OFFSET_BY_TIMESTAMP:
return this.searchOffsetByTimestamp(ctx, request);
case RequestCode.GET_MAX_OFFSET:
return this.getMaxOffset(ctx, request);
case RequestCode.GET_MIN_OFFSET:
return this.getMinOffset(ctx, request);
There are too many contents and only a small part is copied
Each RequestCode is processed
Return different request commands with one premise
The request is assembled and does not depend on external request parameters
public ClusterAclVersionInfo getBrokerClusterAclInfo(final String addr,
final long timeoutMillis) throws RemotingCommandException, InterruptedException, RemotingTimeoutException,
RemotingSendRequestException, RemotingConnectException, MQBrokerException {
public AclConfig getBrokerClusterConfig(final String addr, final long timeoutMillis) throws RemotingCommandException, InterruptedException, RemotingTimeoutException,
RemotingSendRequestException, RemotingConnectException, MQBrokerException {
The next several methods are to obtain the cluster information of the broker
Take a look at the asynchronous method:
private void sendMessageAsync(
final String addr,
final String brokerName,
final Message msg,
final long timeoutMillis,
final RemotingCommand request,
final SendCallback sendCallback,
final TopicPublishInfo topicPublishInfo,
final MQClientInstance instance,
final int retryTimesWhenSendFailed,
final AtomicInteger times,
final SendMessageContext context,
final DefaultMQProducerImpl producer
) throws InterruptedException, RemotingException {
final long beginStartTime = System.currentTimeMillis();
this.remotingClient.invokeAsync(addr, request, timeoutMillis, new InvokeCallback() {
@Override
public void operationComplete(ResponseFuture responseFuture) {
I won't read more about the input parameters. The method topic is that the remotingClient is called
invokeAsync(addr, request, timeoutMillis, new InvokeCallback( )
method
Look at how asynchronous calls are rewritten internally
operationComplete(ResponseFuture responseFuture)
Method:
if (null == sendCallback && response != null) {
try {
SendResult sendResult = MQClientAPIImpl.this.processSendResponse(brokerName, msg, response, addr);
if (context != null && sendResult != null) {
context.setSendResult(sendResult);
context.getProducer().executeSendMessageHookAfter(context);
}
} catch (Throwable e) {
}
producer.updateFaultItem(brokerName, System.currentTimeMillis() - responseFuture.getBeginTimestamp(), false);
return;
}
After sending the asynchronous request, obtain the result and process the result one step:
processSendResponse(brokerName, msg, response, addr);
Get the return value sendResult
Then insert sendResult into the context of the parameter
producer.updateFaultItem(brokerName, System.currentTimeMillis() - responseFuture.getBeginTimestamp(), false);
After wrapping the request, insert the result into the context
Another interesting operation is this
updateFaultItem
Update error items
public void updateFaultItem(final String brokerName, final long currentLatency, boolean isolation) {
if (this.sendLatencyFaultEnable) {
long duration = computeNotAvailableDuration(isolation ? 30000 : currentLatency);
this.latencyFaultTolerance.updateFaultItem(brokerName, currentLatency, duration);
}
}
private long computeNotAvailableDuration(final long currentLatency) {
for (int i = latencyMax.length - 1; i >= 0; i--) {
if (currentLatency >= latencyMax[i])
return this.notAvailableDuration[i];
}
return 0;
}
First, calculate a duration and interval
This interval refers to how long it has elapsed since the failed item was updated
Look at the computational logic.
You can see that currentLatency is actually the exact interval time
However, the RocketMQ underlying layer does not directly use this interval
Instead, there is a definition of "unavailable time interval"
In other words, this is standardized, not "variable"
private long[] latencyMax = {50L, 100L, 550L, 1000L, 2000L, 3000L, 15000L};
private long[] notAvailableDuration = {0L, 0L, 30000L, 60000L, 120000L, 180000L, 600000L};
You can see that "latency Max" and "unavailable time" notAvailableDuration correspond one-to-one
It is the exact interval currentLatency. Compared with it, it is the "latency Max"
The final interval duration is the "unavailable time" notAvailableDuration corresponding to the subscript
Let's see what we did after determining the latency and unavailable duration:
FaultItem old = this.faultItemTable.get(name);
if (null == old) {
final FaultItem faultItem = new FaultItem(name);
faultItem.setCurrentLatency(currentLatency);
faultItem.setStartTimestamp(System.currentTimeMillis() + notAvailableDuration);
old = this.faultItemTable.putIfAbsent(name, faultItem);
if (old != null) {
old.setCurrentLatency(currentLatency);
old.setStartTimestamp(System.currentTimeMillis() + notAvailableDuration);
}
} else {
old.setCurrentLatency(currentLatency);
old.setStartTimestamp(System.currentTimeMillis() + notAvailableDuration);
}
You can see that the failed item is retrieved from the faultItemTable in the failed item table
Then update the current latency and timestamp
That is to record how long the failure lasted
And update every time you reach a new level
Here we can see why so many levels should be set instead of real-time time. If real-time time is used,
If it fails, keep updating
The memory is fully used to update the failure time, and the performance is naturally low
context.getProducer().executeSendMessageHookAfter(context);
After sending the message asynchronously, execute the post hook method hook of sending the message
try {
SendResult sendResult = MQClientAPIImpl.this.processSendResponse(brokerName, msg, response, addr);
assert sendResult != null;
if (context != null) {
context.setSendResult(sendResult);
context.getProducer().executeSendMessageHookAfter(context);
}
try {
sendCallback.onSuccess(sendResult);
} catch (Throwable e) {
}
producer.updateFaultItem(brokerName, System.currentTimeMillis() - responseFuture.getBeginTimestamp(), false);
} catch (Exception e) {
producer.updateFaultItem(brokerName, System.currentTimeMillis() - responseFuture.getBeginTimestamp(), true);
onExceptionImpl(brokerName, msg, timeoutMillis - cost, request, sendCallback, topicPublishInfo, instance,
retryTimesWhenSendFailed, times, e, context, false, producer);
}
It is cleverly written here. When sendResult is empty
The assert keyword returns an exception. In this case, go to the catch code, update the error item, and then make an exception implementation:
onExceptionImpl( )
producer.updateFaultItem
This method has been read above, which is to update the failure duration and time in the faultTable table table
Next look
onExceptionImpl( )
private void onExceptionImpl(final String brokerName,
final Message msg,
final long timeoutMillis,
final RemotingCommand request,
final SendCallback sendCallback,
final TopicPublishInfo topicPublishInfo,
final MQClientInstance instance,
final int timesTotal,
final AtomicInteger curTimes,
final Exception e,
final SendMessageContext context,
final boolean needRetry,
final DefaultMQProducerImpl producer
) {
int tmp = curTimes.incrementAndGet();
if (needRetry && tmp <= timesTotal) {
String retryBrokerName = brokerName;//by default, it will send to the same broker
if (topicPublishInfo != null) { //select one message queue accordingly, in order to determine which broker to send
MessageQueue mqChosen = producer.selectOneMessageQueue(topicPublishInfo, brokerName);
retryBrokerName = mqChosen.getBrokerName();
}
String addr = instance.findBrokerAddressInPublish(retryBrokerName);
log.info("async send msg by retry {} times. topic={}, brokerAddr={}, brokerName={}", tmp, msg.getTopic(), addr,
retryBrokerName);
try {
request.setOpaque(RemotingCommand.createNewRequestId());
sendMessageAsync(addr, retryBrokerName, msg, timeoutMillis, request, sendCallback, topicPublishInfo, instance,
timesTotal, curTimes, context, producer);
} catch (InterruptedException e1) {
onExceptionImpl(retryBrokerName, msg, timeoutMillis, request, sendCallback, topicPublishInfo, instance, timesTotal, curTimes, e1,
context, false, producer);
} catch (RemotingConnectException e1) {
producer.updateFaultItem(brokerName, 3000, true);
onExceptionImpl(retryBrokerName, msg, timeoutMillis, request, sendCallback, topicPublishInfo, instance, timesTotal, curTimes, e1,
context, true, producer);
} catch (RemotingTooMuchRequestException e1) {
onExceptionImpl(retryBrokerName, msg, timeoutMillis, request, sendCallback, topicPublishInfo, instance, timesTotal, curTimes, e1,
context, false, producer);
} catch (RemotingException e1) {
producer.updateFaultItem(brokerName, 3000, true);
onExceptionImpl(retryBrokerName, msg, timeoutMillis, request, sendCallback, topicPublishInfo, instance, timesTotal, curTimes, e1,
context, true, producer);
}
You can see that the core of this method is retry, and there are different retry strategies for different exceptions.
There are also some exceptions that do not need to be retried again
Retry times + 1 for each call of retry method
The maximum number of retries is also a set timesTotal
Summarize this method, that is, send asynchronously. If there are exceptions
call
onExceptionImpl(retryBrokerName, msg, timeoutMillis, request, sendCallback, topicPublishInfo, instance, timesTotal, curTimes, e1,
context, false, producer);
This method is actually a call to asynchronous sending. These two methods actually form recursion
The condition for the end of recursion is that an exception that does not need to be retried is caught
Or the maximum number of retries has been reached
I'm a little lost in the ocean of code
Review the roles and responsibilities of namesrv and broker
NameServer
NameServer features
NameServer is responsible for maintaining the configuration information and status information of Producer and Consumer, and coordinating the collaborative execution of various roles. Each role of NameServer can learn the overall information of the cluster, and they will report the status to NameServer regularly.
At org apache. rocketmq. namesrv. Many variables are defined in the RouteInfoManager class under the routeinfo package. The cluster status information is stored and maintained through five HashMap variables
private final static long BROKER_CHANNEL_EXPIRED_TIME = 1000 * 60 * 2; private final HashMap<String/* topic */, List<QueueData>> topicQueueTable; private final HashMap<String/* brokerName */, BrokerData> brokerAddrTable; private final HashMap<String/* clusterName */, Set<String/* brokerName */>> clusterAddrTable; private final HashMap<String/* brokerAddr */, BrokerLiveInfo> brokerLiveTable; private final HashMap<String/* brokerAddr */, List<String>/* Filter Server */> filterServerTable;
BROKER_CHANNEL_EXPIRED_TIME defines the reporting timeout of the Broker to the NameServer. The default is two minutes. If it exceeds two minutes, close the connection channel between the Broker and the NameServer and remove the Broker from the brokerLiveTable
HashMap<String/* Topic */, List> topicQueueTable. This variable stores all topics and takes the name of the Topic as the key. value is the message list under this Topic. The length of the list is the number of master brokers
public class QueueData implements Comparable<QueueData> {
private String brokerName;//broker name
private int readQueueNums;//Number of read queue s
private int writeQueueNums;//Number of queue s written
private int perm;
private int topicSynFlag;//Synchronization identification
}
HashMap<String/* brokerName /, BrokerData> brokerAddrTable. Variable stores the data information of the same Broker. Take brokername as the key and brokerdata as the value. The brokerdata class contains the cluster attribute, brokername attribute and brokerAddrs attribute. In a cluster, the same brokername may contain multiple machines (one Master and multiple Slave). Therefore, HashMap is used to store the brokerId and address of these machines in brokerdata
public class BrokerData implements Comparable<BrokerData> {
private String cluster;
private String brokerName;
private HashMap<Long/* brokerId */, String/* broker address */> brokerAddrs;
}
HashMap<String/* clusterName /, Set<String/ brokerName />> clusterAddrTable. This variable stores the corresponding brokername under the cluster
HashMap<String/ brokerAddr */, BrokerLiveInfo> brokerLiveTable. This variable stores the real-time status corresponding to each broker machine, calculates whether the broker update timed out through the last update timestamp, and judges whether the broker is invalid.
class BrokerLiveInfo {
private long lastUpdateTimestamp;
private DataVersion dataVersion;
private Channel channel;
private String haServerAddr;
}
HashMap<String/* brokerAddr /, List/ Filter Server */> filterServerTable. This variable stores the filter server associated with each Broker.
Why not use zookeeper?
Zookeeper is an open-source software for distributed service coordination under apache. It has an election mechanism and can select a slave from the slave to become the master through the election mechanism when the Master goes down. However, in the design of NameServer, none of the masterbrokers has all the Topic information, the message distribution is average, and the significance of the election mechanism is lost. Secondly, NameServer is only used to store the configuration information and metadata information of the cluster. It does not need too complex functions, so we give up the heavyweight zookeeper and choose the lightweight NameServer.
Broker
Broker message store
There are two roles in Broker: CommitLog and ConsumeQueue.
CommitLog: the physical file that actually stores the message
ConsumeQueue: consumption queue. The address offset of the message to be consumed is stored in the queue, which is similar to the index
The CommitLog and ConsumeQueue cooperate to store messages.
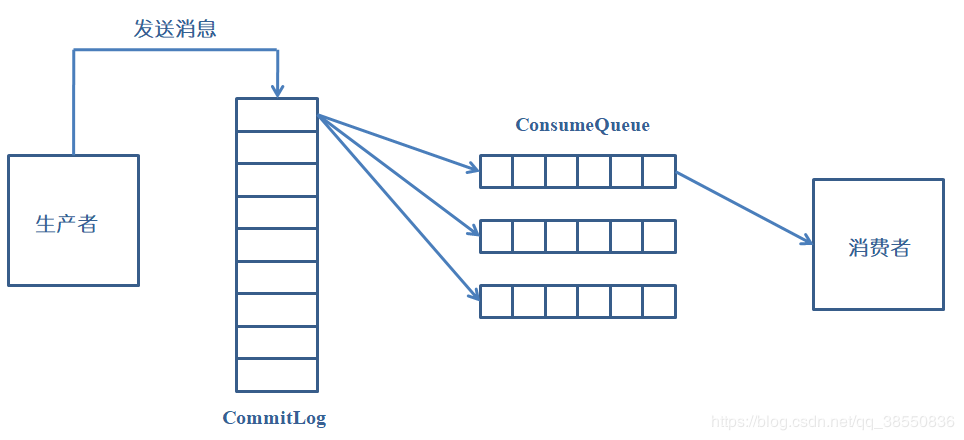
The storage address of the message is configured in the configuration file through storePathRootDir. The storage directory structure under the storage path is as follows
/home
└── rocketmq
├── store-a
│ ├── abort
│ ├── checkpoint
│ ├── commitlog
│ │ └── 00000000000000000000
│ ├── config
│ │ ├── consumerFilter.json
│ │ ├── consumerFilter.json.bak
│ │ ├── consumerOffset.json
│ │ ├── consumerOffset.json.bak
│ │ ├── delayOffset.json
│ │ ├── delayOffset.json.bak
│ │ ├── subscriptionGroup.json
│ │ ├── topics.json
│ │ └── topics.json.bak
│ ├── consumequeue
│ │ ├── OFFSET_MOVED_EVENT
│ │ │ └── 0
│ │ │ └── 00000000000000000000
│ │ ├── OrderTest
│ │ │ ├── 0
│ │ │ │ └── 00000000000000000000
│ │ │ ├── 1
│ │ │ │ └── 00000000000000000000
│ │ │ ├── 2
│ │ │ │ └── 00000000000000000000
│ │ │ └── 3
│ │ │ └── 00000000000000000000
│ ├── index
│ │ └── 20190722164917530
│ └── lock
You can see that there are Commit Log, ConsumeQueue, index, etc. in the storage directory. All Topic information and index files are stored in the ConsumeQueue directory. CommitLog uses sequential writing and random reading to speed up the writing efficiency. Since only 20 bytes of offsets and Tags are stored in consumqueue, it can be stored in memory and the reading speed is very fast.
After reading the message from the producer, the message will be stored to the local disk. RocketMQ provides two storage methods: synchronous disk brushing and asynchronous disk brushing.
Synchronous disk brushing: the synchronous disk brushing mode writes the message from the memory to the disk immediately after the Broker reads the message sent by the producer, and returns the success status. When the producer receives the success status, the message has been written to the disk.
Asynchronous disk brushing: the received information is stored in memory by asynchronous disk brushing, and the success status is returned. When the producer receives the success status, the message is still in memory and not written to the disk. When messages in memory are stacked to the threshold, messages are written to disk in batches.
Broker's HA
The Broker cluster has two roles: master and slave, which are implemented through configuration in the configuration file. The differences between master and slave in Broker cluster are as follows:
The brokerId of the master configuration file is 0; slave is a different value
master supports reading and writing; slave can only read
The producer can only connect with the master to write messages; Consumers can connect to the master or slave to read messages
RocketMQ does not have a mechanism to automatically convert slave to master. Therefore, when the master resource is insufficient or fails, you need to manually modify the configuration file and restart the Broker with the new configuration file
In the Broker group, you need to copy the messages in the master to each slave to achieve the purpose of message synchronization. RocketMQ provides two message replication mechanisms: synchronous replication and asynchronous replication.
Synchronous replication: wait until both master and slave are written successfully before returning to the success status. In this way, if the master fails, the data is easy to recover, but the throughput is low
Asynchronous replication: as long as the master writes successfully, it returns the success status. This method has low latency and high throughput, but if you don't know whether the slave successfully writes to the master, the fault message may be lost
Continue mqclientapimpl
The following is a processSendResponse method
private SendResult processSendResponse(
final String brokerName,
final Message msg,
final RemotingCommand response,
final String addr
) throws MQBrokerException, RemotingCommandException {
SendStatus sendStatus;
switch (response.getCode()) {
case ResponseCode.FLUSH_DISK_TIMEOUT: {
sendStatus = SendStatus.FLUSH_DISK_TIMEOUT;
break;
}
case ResponseCode.FLUSH_SLAVE_TIMEOUT: {
sendStatus = SendStatus.FLUSH_SLAVE_TIMEOUT;
break;
}
case ResponseCode.SLAVE_NOT_AVAILABLE: {
sendStatus = SendStatus.SLAVE_NOT_AVAILABLE;
break;
Process the sent response, that is, process the result.
First, get the sent result from the response
The following code basically completes sendResult:
SendMessageResponseHeader responseHeader =
(SendMessageResponseHeader) response.decodeCommandCustomHeader(SendMessageResponseHeader.class);
//If namespace not null , reset Topic without namespace.
String topic = msg.getTopic();
if (StringUtils.isNotEmpty(this.clientConfig.getNamespace())) {
topic = NamespaceUtil.withoutNamespace(topic, this.clientConfig.getNamespace());
}
MessageQueue messageQueue = new MessageQueue(topic, brokerName, responseHeader.getQueueId());
String uniqMsgId = MessageClientIDSetter.getUniqID(msg);
if (msg instanceof MessageBatch) {
StringBuilder sb = new StringBuilder();
for (Message message : (MessageBatch) msg) {
sb.append(sb.length() == 0 ? "" : ",").append(MessageClientIDSetter.getUniqID(message));
}
uniqMsgId = sb.toString();
}
SendResult sendResult = new SendResult(sendStatus,
uniqMsgId,
responseHeader.getMsgId(), messageQueue, responseHeader.getQueueOffset());
sendResult.setTransactionId(responseHeader.getTransactionId());
String regionId = response.getExtFields().get(MessageConst.PROPERTY_MSG_REGION);
String traceOn = response.getExtFields().get(MessageConst.PROPERTY_TRACE_SWITCH);
if (regionId == null || regionId.isEmpty()) {
regionId = MixAll.DEFAULT_TRACE_REGION_ID;
}
if (traceOn != null && traceOn.equals("false")) {
sendResult.setTraceOn(false);
} else {
sendResult.setTraceOn(true);
}
sendResult.setRegionId(regionId);
return sendResult;
}
Return to DefaultMQAdminExt
After reading the eye bag structure here, I suddenly feel that the current reading is a little wrong
org.apache.rocketmq.tools.admin.DefaultMQAdminExt
Because we've been in the bag of tools
It's a little messy
If you read it like this, the train of thought is too unclear
So let's sort out the ideas. Since it's in the tools package now, let's go through the main classes in this package first
Then sort it out
tools
org.apache.rocketmq.tools.admin.DefaultMQAdminExt
Let's skip the construction method and look at the methods inside the tool class
@Override
public void createTopic(String key, String newTopic, int queueNum) throws MQClientException {
createTopic(key, newTopic, queueNum, 0);
}
@Override
public void createTopic(String key, String newTopic, int queueNum, int topicSysFlag) throws MQClientException {
defaultMQAdminExtImpl.createTopic(key, newTopic, queueNum, topicSysFlag);
}
The first is to create Topic
@Override
public long searchOffset(MessageQueue mq, long timestamp) throws MQClientException {
return defaultMQAdminExtImpl.searchOffset(mq, timestamp);
}
@Override
public long maxOffset(MessageQueue mq) throws MQClientException {
return defaultMQAdminExtImpl.maxOffset(mq);
}
@Override
public long minOffset(MessageQueue mq) throws MQClientException {
return defaultMQAdminExtImpl.minOffset(mq);
}
Search the consumption progress of the message queue, the maximum progress and the minimum progress of the message queue
About offset:
In rocketMQ, offset is used to manage the consumption progress of different consumption groups of each consumption queue. The management of offset is divided into local mode and remote mode. The local mode is stored in the client in the form of text file, while the remote mode is to save the data to the broker. The corresponding data structures are LocalFileOffsetStore and remoteberokeroffsetstore respectively.
By default, when the consumption mode is broadcast mode, offset is stored in local mode, because each message will be consumed by all consumers. Each consumer manages its own consumption progress, and there is no intersection of consumption progress among consumers; When the consumption mode is cluster consumption, the remote mode is used to manage the offset, and the message will be consumed by multiple consumers. The difference is that each consumer is only responsible for consuming part of the consumption queue. Adding or deleting consumers will change the load and easily lead to consumption progress conflict. Therefore, centralized management is required. Meanwhile, RocketMQ also provides an interface for users to implement offset Management (implement the OffsetStore interface).
Update of offset during concurrent consumption
Question: the messages to be consumed pulled by the consumer from the broker are batch (pullBatchSize=32 by default). During concurrent consumption, the offset update is not in order of size. For example, the pulled messages m1 to m10 may be the last consumption. How to ensure the correctness of the submitted offset? The update of m10 offset will not cause m1 to mistakenly believe that consumption has been completed.
After consumption, the batch message consumed by the thread will be deleted from the msgTreeMap, and the first element of the current msgTreeMap will be returned, that is, the offset of the minimum pull batch. The offset updated by the offsetTable will always be the minimum offset value not consumed in the pull batch. That is, when m1 consumption is not completed and m10 consumption is completed, the consumption progress of the current messageQueue updated to the offsetTable is the offset value corresponding to m1.
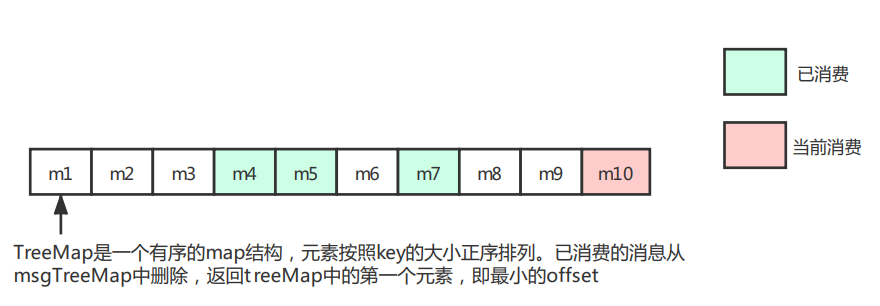
Therefore, the offset stored in the offsetTable may not be the maximum value of the offset actually consumed by the messageQueue, but the consumer pulls the message using the nextBeginOffset returned by the last pull request, not based on the offsetTable. Under normal circumstances, the data will not be pulled repeatedly. In case of downtime and other exceptions, the idempotency needs to be guaranteed through the business process, just like the downtime exception not submitted by the offsetTable. The idempotency of business processes has always been emphasized by rocketMQ.
Here offerset seems to be the secret of sequential consumption (that is, there is a message mark), but it is not sure.
Continue back to DefaultMQAdminExt
@Override
public MessageExt viewMessage(
String offsetMsgId) throws RemotingException, MQBrokerException, InterruptedException, MQClientException {
return defaultMQAdminExtImpl.viewMessage(offsetMsgId);
}
@Override
public QueryResult queryMessage(String topic, String key, int maxNum, long begin, long end)
throws MQClientException, InterruptedException {
return defaultMQAdminExtImpl.queryMessage(topic, key, maxNum, begin, end);
}
public QueryResult queryMessageByUniqKey(String topic, String key, int maxNum, long begin, long end)
throws MQClientException, InterruptedException {
return defaultMQAdminExtImpl.queryMessageByUniqKey(topic, key, maxNum, begin, end);
}
Three ways to find information
Pay attention to the difference between the results
MessageExt is the actual message information
QueryResult contains it
org.apache.rocketmq.common.message.MessageExt
public class MessageExt extends Message {
private static final long serialVersionUID = 5720810158625748049L;
private String brokerName;
private int queueId;
private int storeSize;
private long queueOffset;
private int sysFlag;
private long bornTimestamp;
private SocketAddress bornHost;
private long storeTimestamp;
private SocketAddress storeHost;
private String msgId;
private long commitLogOffset;
private int bodyCRC;
private int reconsumeTimes;
private long preparedTransactionOffset;
org.apache.rocketmq.client.QueryResult
public class QueryResult {
private final long indexLastUpdateTimestamp;
private final List<MessageExt> messageList;