
0. Introduction
I like the minimalist network structure of CenterNet very much. CenterNet only realizes the detection and classification of targets through FCN (full convolution) method, without complex operations such as anchor and nms. It is efficient and accurate. At the same time, the simple modification of this structure can be applied to human pose estimation and 3D target detection.
Some of the latter are applied to other tasks according to the CenterNet structure and have achieved good results, such as face detection CenterFace and target tracking CenterTrack and FairMot. These contents will be supplemented after the author's study. A summary and comparison of CenterNet like structures should be made later. Interested readers can continue to pay attention to them.
Now I want to introduce the of writing this blog post. When studying CenterNet, I saw the comparison between CenterNet and YoloV3, which surpassed both speed and accuracy. In fact, the author is a little skeptical about this conclusion.
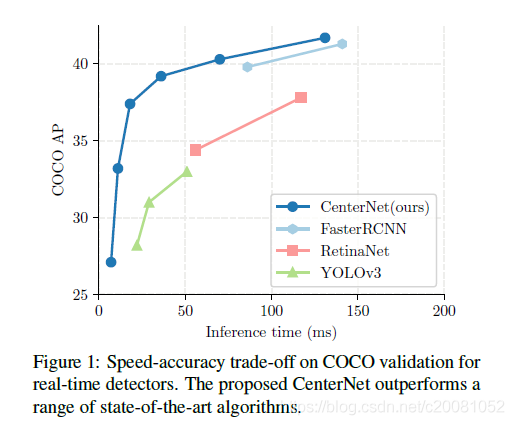
YoloV3 network is characterized by high speed and low precision. It is often used in actual detection projects to realize real-time detection and identification. Compared with two-stage fast RCNN, it has speed advantages, and compared with one stage SSD (Single Shot Detection) and RetinaNet, it has speed and accuracy advantages.
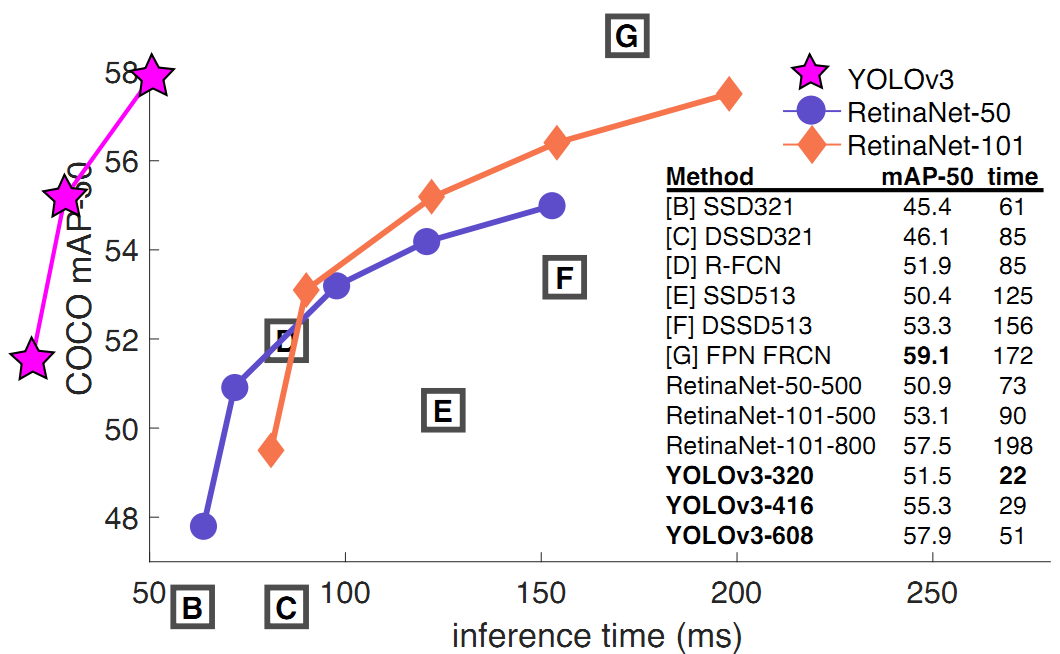
Therefore, the author still has some doubts about CenterNet's improvement of YoloV3 speed. YoloV3 can be said to be the most commonly used and best used target detection algorithm in the industry. If it is true, as stated in the conclusion of CenterNet's paper, CenterNet also has the characteristics of simple structure and convenient use (ignoring DCN first, it is only a matter of time to deploy comprehensive support), It will certainly replace YoloV3.
In view of the above situation, the author intends to do a comparative experiment to test the accuracy and speed of CenterNet and YoloV3 under the same hardware and environment. In fact, in order to simplify the experiment, only the speed comparison of CenterNet and YoloV3 under the same size is tested here. The accuracy is subject to the content of the article.
1. Experimental conditions
In order for readers to recognize and easily reproduce the author's results, the hardware and environment of the experiment are listed here:
- System: Ubuntu 18.04.4 LTS
- CPU: Intel® Core™ i5-9400F CPU @ 2.90GHz × 6
- GPU: GeForce RTX 2060 SUPER/PCIe/SSE2
- Cuda: 10.1
- Pytorch: 1.5.0
Experiment reference:
CenterNet: https://github.com/xingyizhou/CenterNet
YoloV3: https://github.com/ultralytics/yolov3
2. Experimental process
1.U version YoloV3
1. Maximum side retraction 320
Run: ~ / yolov3$
python detect.py --weights weights/yolov3-spp-ultralytics.pt --img-size 320 --cfg cfg/yolov3-spp.cfg --source data/samples/
Results: the average time of the model was 12 Ms
Model Summary: 225 layers, 6.29987e+07 parameters, 6.29987e+07 gradients image 1/10 data/samples/16004479832_a748d55f21_k.jpg: 256x320 4 persons, 2 dogs, Done. (0.011s) image 2/10 data/samples/17790319373_bd19b24cfc_k.jpg: 192x320 9 persons, 2 cars, 3 motorcycles, 1 trucks, Done. (0.013s) image 3/10 data/samples/18124840932_e42b3e377c_k.jpg: 256x320 3 persons, 2 boats, Done. (0.012s) image 4/10 data/samples/19064748793_bb942deea1_k.jpg: 256x320 14 cars, Done. (0.011s) image 5/10 data/samples/24274813513_0cfd2ce6d0_k.jpg: 256x320 11 persons, 1 cars, Done. (0.013s) image 6/10 data/samples/33823288584_1d21cf0a26_k.jpg: 256x320 9 persons, 7 bicycles, 1 backpacks, Done. (0.011s) image 7/10 data/samples/33887522274_eebd074106_k.jpg: 256x320 4 persons, 1 cars, 1 buss, 1 trucks, Done. (0.011s) image 8/10 data/samples/34501842524_3c858b3080_k.jpg: 256x320 3 cars, 2 stop signs, Done. (0.011s) image 9/10 data/samples/bus.jpg: 320x256 4 persons, 1 buss, 1 handbags, Done. (0.011s) image 10/10 data/samples/zidane.jpg: 192x320 3 persons, 3 ties, Done. (0.010s)
2. Maximum side zoom 512
Run: ~ / yolov3$
python detect.py --weights weights/yolov3-spp-ultralytics.pt --img-size 512 --cfg cfg/yolov3-spp.cfg --source data/samples/
Output: the average time of the model is 20ms
Using CUDA device0 _CudaDeviceProperties(name='GeForce RTX 2060 SUPER', total_memory=7979MB) Model Summary: 225 layers, 6.29987e+07 parameters, 6.29987e+07 gradients image 1/10 data/samples/16004479832_a748d55f21_k.jpg: 384x512 4 persons, 2 dogs, Done. (0.018s) image 2/10 data/samples/17790319373_bd19b24cfc_k.jpg: 320x512 9 persons, 4 cars, 2 motorcycles, 1 trucks, 1 benchs, 1 chairs, Done. (0.019s) image 3/10 data/samples/18124840932_e42b3e377c_k.jpg: 384x512 3 persons, 3 boats, 1 birds, Done. (0.018s) image 4/10 data/samples/19064748793_bb942deea1_k.jpg: 384x512 4 persons, 18 cars, 2 traffic lights, Done. (0.019s) image 5/10 data/samples/24274813513_0cfd2ce6d0_k.jpg: 384x512 13 persons, 1 trucks, Done. (0.020s) image 6/10 data/samples/33823288584_1d21cf0a26_k.jpg: 384x512 16 persons, 6 bicycles, 2 backpacks, 1 bottles, 1 cell phones, Done. (0.020s) image 7/10 data/samples/33887522274_eebd074106_k.jpg: 384x512 3 persons, 1 cars, 1 buss, Done. (0.020s) image 8/10 data/samples/34501842524_3c858b3080_k.jpg: 384x512 3 cars, 1 stop signs, Done. (0.020s) image 9/10 data/samples/bus.jpg: 512x384 4 persons, 1 buss, 1 stop signs, 1 ties, 1 skateboards, Done. (0.018s) image 10/10 data/samples/zidane.jpg: 320x512 3 persons, 2 ties, Done. (0.015s)
3. Maximum side shrinkage 800
Run: ~ / yolov3$
python detect.py --weights weights/yolov3-spp-ultralytics.pt --img-size 800 --cfg cfg/yolov3-spp.cfg --source data/samples/
Output: the average time of the model is 40ms
Model Summary: 225 layers, 6.29987e+07 parameters, 6.29987e+07 gradients image 1/10 data/samples/16004479832_a748d55f21_k.jpg: 544x800 7 persons, 2 dogs, 1 handbags, Done. (0.041s) image 2/10 data/samples/17790319373_bd19b24cfc_k.jpg: 480x800 10 persons, 8 cars, 1 motorcycles, 2 trucks, 1 chairs, Done. (0.040s) image 3/10 data/samples/18124840932_e42b3e377c_k.jpg: 544x800 3 persons, 4 boats, Done. (0.045s) image 4/10 data/samples/19064748793_bb942deea1_k.jpg: 544x800 6 persons, 27 cars, 1 buss, 1 trucks, 6 traffic lights, Done. (0.045s) image 5/10 data/samples/24274813513_0cfd2ce6d0_k.jpg: 544x800 14 persons, 2 cars, 1 trucks, 1 ties, Done. (0.047s) image 6/10 data/samples/33823288584_1d21cf0a26_k.jpg: 544x800 21 persons, 11 bicycles, 1 backpacks, 2 handbags, 4 bottles, 1 cell phones, Done. (0.038s) image 7/10 data/samples/33887522274_eebd074106_k.jpg: 608x800 6 persons, 1 cars, 1 buss, Done. (0.038s) image 8/10 data/samples/34501842524_3c858b3080_k.jpg: 544x800 4 cars, 1 trucks, 2 stop signs, Done. (0.037s) image 9/10 data/samples/bus.jpg: 800x608 4 persons, 1 bicycles, 1 buss, 1 ties, Done. (0.039s) image 10/10 data/samples/zidane.jpg: 480x800 3 persons, 2 ties, Done. (0.029s)
4. Maximum side zoom 1024
Run: ~ / yolov3$
python detect.py --weights weights/yolov3-spp-ultralytics.pt --img-size 1024 --cfg cfg/yolov3-spp.cfg --source data/samples/
Results: the average time of the model was 50 ms
Model Summary: 225 layers, 6.29987e+07 parameters, 6.29987e+07 gradients image 1/10 data/samples/16004479832_a748d55f21_k.jpg: 704x1024 5 persons, 1 dogs, 1 handbags, Done. (0.054s) image 2/10 data/samples/17790319373_bd19b24cfc_k.jpg: 576x1024 13 persons, 5 cars, 1 motorcycles, 2 trucks, 1 umbrellas, 1 chairs, Done. (0.049s) image 3/10 data/samples/18124840932_e42b3e377c_k.jpg: 704x1024 3 persons, 6 boats, 4 birds, Done. (0.049s) image 4/10 data/samples/19064748793_bb942deea1_k.jpg: 704x1024 10 persons, 24 cars, 1 buss, 2 trucks, 7 traffic lights, Done. (0.051s) image 5/10 data/samples/24274813513_0cfd2ce6d0_k.jpg: 704x1024 14 persons, 1 cars, 1 trucks, 2 handbags, 2 ties, Done. (0.048s) image 6/10 data/samples/33823288584_1d21cf0a26_k.jpg: 704x1024 25 persons, 8 bicycles, 1 backpacks, 1 handbags, 1 kites, 2 bottles, 1 cell phones, Done. (0.051s) image 7/10 data/samples/33887522274_eebd074106_k.jpg: 768x1024 5 persons, 1 cars, 1 buss, Done. (0.052s) image 8/10 data/samples/34501842524_3c858b3080_k.jpg: 704x1024 4 cars, 1 trucks, 1 stop signs, Done. (0.048s) image 9/10 data/samples/bus.jpg: 1024x768 3 persons, 1 bicycles, 1 buss, 1 cell phones, Done. (0.054s) image 10/10 data/samples/zidane.jpg: 576x1024 1 persons, 3 ties, Done. (0.042s) Results saved to /home/song/yolov3/output Done. (0.943s) avg time (0.094s)
YoloV3 output photos
2.CenterNet
1. Maximum side retraction 320
Run: ~ / CenterNet/src$
python demo.py ctdet --demo ../data/samples --load_model ../models/ctdet_coco_dla_2x.pth --input_h 256 --input_w 320
Results: the average time of the model was 16ms
Creating model... loaded ../models/ctdet_coco_dla_2x.pth, epoch 230 torch.Size([1, 3, 256, 320]) /opt/conda/conda-bld/pytorch_1587428398394/work/aten/src/ATen/native/BinaryOps.cpp:81: UserWarning: Integer division of tensors using div or / is deprecated, and in a future release div will perform true division as in Python 3. Use true_divide or floor_divide (// in Python) instead. tot 0.202s |load 0.005s |pre 0.003s |net 0.191s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 256, 320]) tot 0.059s |load 0.031s |pre 0.009s |net 0.016s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 256, 320]) tot 0.027s |load 0.010s |pre 0.002s |net 0.012s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 256, 320]) tot 0.052s |load 0.022s |pre 0.008s |net 0.018s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 256, 320]) tot 0.053s |load 0.021s |pre 0.009s |net 0.019s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 256, 320]) tot 0.057s |load 0.028s |pre 0.008s |net 0.017s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 256, 320]) tot 0.036s |load 0.008s |pre 0.005s |net 0.019s |dec 0.001s |post 0.003s |merge 0.000s | torch.Size([1, 3, 256, 320]) tot 0.053s |load 0.027s |pre 0.006s |net 0.016s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 256, 320]) tot 0.044s |load 0.017s |pre 0.005s |net 0.019s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 256, 320]) tot 0.028s |load 0.009s |pre 0.003s |net 0.012s |dec 0.002s |post 0.002s |merge 0.000s |
2. Maximum side zoom 512
Run: ~ / CenterNet/src$
python demo.py ctdet --demo ../data/samples --load_model ../models/ctdet_coco_dla_2x.pth --input_h 384 --input_w 512
Output: the average time of the model is 20ms
loaded ../models/ctdet_coco_dla_2x.pth, epoch 230 torch.Size([1, 3, 384, 512]) /opt/conda/conda-bld/pytorch_1587428398394/work/aten/src/ATen/native/BinaryOps.cpp:81: UserWarning: Integer division of tensors using div or / is deprecated, and in a future release div will perform true division as in Python 3. Use true_divide or floor_divide (// in Python) instead. tot 0.206s |load 0.005s |pre 0.006s |net 0.193s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 384, 512]) tot 0.041s |load 0.012s |pre 0.007s |net 0.019s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 384, 512]) tot 0.031s |load 0.005s |pre 0.005s |net 0.019s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 384, 512]) tot 0.060s |load 0.018s |pre 0.016s |net 0.022s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 384, 512]) tot 0.046s |load 0.009s |pre 0.010s |net 0.023s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 384, 512]) tot 0.055s |load 0.018s |pre 0.014s |net 0.018s |dec 0.002s |post 0.002s |merge 0.000s | torch.Size([1, 3, 384, 512]) tot 0.059s |load 0.021s |pre 0.015s |net 0.019s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 384, 512]) tot 0.037s |load 0.008s |pre 0.007s |net 0.018s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 384, 512]) tot 0.070s |load 0.038s |pre 0.009s |net 0.020s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 384, 512]) tot 0.062s |load 0.027s |pre 0.014s |net 0.019s |dec 0.001s |post 0.002s |merge 0.000s |
3. Maximum side shrinkage 800
Run: ~ / CenterNet/src$
python demo.py ctdet --demo ../data/samples --load_model ../models/ctdet_coco_dla_2x.pth --input_h 544 --input_w 800
Results: the average time of the model was 41 Ms
Creating model... loaded ../models/ctdet_coco_dla_2x.pth, epoch 230 torch.Size([1, 3, 544, 800]) /opt/conda/conda-bld/pytorch_1587428398394/work/aten/src/ATen/native/BinaryOps.cpp:81: UserWarning: Integer division of tensors using div or / is deprecated, and in a future release div will perform true division as in Python 3. Use true_divide or floor_divide (// in Python) instead. tot 0.234s |load 0.005s |pre 0.015s |net 0.211s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 544, 800]) tot 0.105s |load 0.031s |pre 0.027s |net 0.044s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 544, 800]) tot 0.092s |load 0.023s |pre 0.023s |net 0.042s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 544, 800]) tot 0.073s |load 0.009s |pre 0.021s |net 0.040s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 544, 800]) tot 0.091s |load 0.021s |pre 0.026s |net 0.040s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 544, 800]) tot 0.085s |load 0.019s |pre 0.022s |net 0.042s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 544, 800]) tot 0.091s |load 0.021s |pre 0.026s |net 0.040s |dec 0.002s |post 0.002s |merge 0.000s | torch.Size([1, 3, 544, 800]) tot 0.085s |load 0.017s |pre 0.022s |net 0.042s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 544, 800]) tot 0.098s |load 0.033s |pre 0.020s |net 0.040s |dec 0.003s |post 0.002s |merge 0.000s | torch.Size([1, 3, 544, 800]) tot 0.074s |load 0.011s |pre 0.020s |net 0.040s |dec 0.001s |post 0.002s |merge 0.000s |
4. Maximum side zoom 1024
Run: ~ / CenterNet/src$
python demo.py ctdet --demo ../data/samples --load_model ../models/ctdet_coco_dla_2x.pth --input_h 704 --input_w 1024
Results: the average time of the model was 53 Ms
loaded ../models/ctdet_coco_dla_2x.pth, epoch 230 torch.Size([1, 3, 704, 1024]) /opt/conda/conda-bld/pytorch_1587428398394/work/aten/src/ATen/native/BinaryOps.cpp:81: UserWarning: Integer division of tensors using div or / is deprecated, and in a future release div will perform true division as in Python 3. Use true_divide or floor_divide (// in Python) instead. tot 0.260s |load 0.005s |pre 0.025s |net 0.227s |dec 0.002s |post 0.002s |merge 0.000s | torch.Size([1, 3, 704, 1024]) tot 0.100s |load 0.007s |pre 0.027s |net 0.063s |dec 0.002s |post 0.002s |merge 0.000s | torch.Size([1, 3, 704, 1024]) tot 0.112s |load 0.014s |pre 0.034s |net 0.060s |dec 0.002s |post 0.002s |merge 0.000s | torch.Size([1, 3, 704, 1024]) tot 0.117s |load 0.022s |pre 0.029s |net 0.062s |dec 0.002s |post 0.002s |merge 0.000s | torch.Size([1, 3, 704, 1024]) tot 0.119s |load 0.021s |pre 0.033s |net 0.061s |dec 0.002s |post 0.002s |merge 0.000s | torch.Size([1, 3, 704, 1024]) tot 0.090s |load 0.007s |pre 0.018s |net 0.061s |dec 0.002s |post 0.002s |merge 0.000s | torch.Size([1, 3, 704, 1024]) tot 0.108s |load 0.020s |pre 0.033s |net 0.051s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 704, 1024]) tot 0.078s |load 0.007s |pre 0.018s |net 0.051s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 704, 1024]) tot 0.116s |load 0.036s |pre 0.025s |net 0.050s |dec 0.002s |post 0.002s |merge 0.000s | torch.Size([1, 3, 704, 1024]) tot 0.082s |load 0.006s |pre 0.020s |net 0.051s |dec 0.003s |post 0.002s |merge 0.000s |

3. Supplementary experiment
After further studying the implementation of the two codes, the author found a problem in the experiment. He only compared the speed of model reasoning, although he could see the efficiency of model reasoning. However, in the actual application scenario, the pre-processing and post-processing also take some time, so the author adds an overall time-consuming comparison in 640 / 1280 size to illustrate the speed difference in practical application.
1.U version YoloV3
1. Maximum side retraction 640
Run: ~ / yolov3$
python detect.py --weights weights/yolov3-spp-ultralytics.pt --img-size 640 --cfg cfg/yolov3-spp.cfg --source data/samples/
Results: the average time of the model was 26 MS and the overall average time was 64 Ms
Model Summary: 225 layers, 6.29987e+07 parameters, 6.29987e+07 gradients image 1/10 data/samples/16004479832_a748d55f21_k.jpg: 448x640 5 persons, 2 dogs, Done. (0.028s) image 2/10 data/samples/17790319373_bd19b24cfc_k.jpg: 384x640 12 persons, 6 cars, 3 motorcycles, 1 trucks, 1 chairs, Done. (0.026s) image 3/10 data/samples/18124840932_e42b3e377c_k.jpg: 448x640 3 persons, 4 boats, Done. (0.025s) image 4/10 data/samples/19064748793_bb942deea1_k.jpg: 448x640 8 persons, 22 cars, 1 buss, 1 trucks, 3 traffic lights, 1 clocks, Done. (0.028s) image 5/10 data/samples/24274813513_0cfd2ce6d0_k.jpg: 448x640 14 persons, 1 cars, 1 trucks, Done. (0.026s) image 6/10 data/samples/33823288584_1d21cf0a26_k.jpg: 448x640 19 persons, 6 bicycles, 1 backpacks, 2 bottles, 1 cell phones, Done. (0.028s) image 7/10 data/samples/33887522274_eebd074106_k.jpg: 512x640 5 persons, 1 cars, 1 buss, Done. (0.025s) image 8/10 data/samples/34501842524_3c858b3080_k.jpg: 448x640 5 cars, 1 trucks, 2 stop signs, Done. (0.024s) image 9/10 data/samples/bus.jpg: 640x512 4 persons, 1 buss, Done. (0.025s) image 10/10 data/samples/zidane.jpg: 384x640 3 persons, 2 ties, Done. (0.021s) Results saved to /home/song/yolov3/output Done. (0.638s) avg time (0.064s)
2. Maximum side shrinkage 1280
Run: ~ / yolov3$
python detect.py --weights weights/yolov3-spp-ultralytics.pt --img-size 1280 --cfg cfg/yolov3-spp.cfg --source data/samples/
Results: the average time of the model was 78 MS and the overall average time was 124 Ms
Model Summary: 225 layers, 6.29987e+07 parameters, 6.29987e+07 gradients image 1/10 data/samples/16004479832_a748d55f21_k.jpg: 896x1280 4 persons, 3 dogs, 1 backpacks, Done. (0.085s) image 2/10 data/samples/17790319373_bd19b24cfc_k.jpg: 704x1280 16 persons, 10 cars, 1 motorcycles, 1 buss, 1 trucks, 1 umbrellas, 1 chairs, Done. (0.061s) image 3/10 data/samples/18124840932_e42b3e377c_k.jpg: 896x1280 5 persons, 3 boats, 3 birds, Done. (0.075s) image 4/10 data/samples/19064748793_bb942deea1_k.jpg: 896x1280 11 persons, 27 cars, 1 buss, 5 trucks, 7 traffic lights, 1 remotes, Done. (0.075s) image 5/10 data/samples/24274813513_0cfd2ce6d0_k.jpg: 896x1280 14 persons, 2 cars, 1 trucks, 5 handbags, 7 ties, Done. (0.074s) image 6/10 data/samples/33823288584_1d21cf0a26_k.jpg: 832x1280 27 persons, 10 bicycles, 2 backpacks, 3 handbags, 1 kites, 2 bottles, 1 cell phones, Done. (0.070s) image 7/10 data/samples/33887522274_eebd074106_k.jpg: 960x1280 5 persons, 1 cars, 1 buss, Done. (0.079s) image 8/10 data/samples/34501842524_3c858b3080_k.jpg: 896x1280 5 cars, 1 trucks, 1 stop signs, 1 benchs, Done. (0.075s) image 9/10 data/samples/bus.jpg: 1280x960 4 persons, 1 bicycles, 1 ties, 1 cups, Done. (0.078s) image 10/10 data/samples/zidane.jpg: 768x1280 2 ties, Done. (0.062s) Results saved to /home/song/yolov3/output Done. (1.236s) avg time (0.124s)
2.CenterNet
1. Maximum side retraction 640
Run: ~ / CenterNet/src$
python demo.py ctdet --demo ../data/samples --load_model ../models/ctdet_coco_dla_2x.pth --input_h 448 --input_w 640
Results: the average time of the model was 27 ms and the overall average time was 50 ms
Creating model... loaded ../models/ctdet_coco_dla_2x.pth, epoch 230 torch.Size([1, 3, 448, 640]) /opt/conda/conda-bld/pytorch_1587428398394/work/aten/src/ATen/native/BinaryOps.cpp:81: UserWarning: Integer division of tensors using div or / is deprecated, and in a future release div will perform true division as in Python 3. Use true_divide or floor_divide (// in Python) instead. tot 0.223s |load 0.005s |pre 0.010s |net 0.206s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 448, 640]) tot 0.079s |load 0.026s |pre 0.021s |net 0.029s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 448, 640]) tot 0.074s |load 0.023s |pre 0.018s |net 0.029s |dec 0.002s |post 0.002s |merge 0.000s | torch.Size([1, 3, 448, 640]) tot 0.044s |load 0.005s |pre 0.007s |net 0.029s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 448, 640]) tot 0.043s |load 0.005s |pre 0.006s |net 0.029s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 448, 640]) tot 0.044s |load 0.006s |pre 0.006s |net 0.029s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 448, 640]) tot 0.042s |load 0.004s |pre 0.007s |net 0.028s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 448, 640]) tot 0.047s |load 0.006s |pre 0.007s |net 0.032s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 448, 640]) tot 0.043s |load 0.009s |pre 0.008s |net 0.024s |dec 0.001s |post 0.002s |merge 0.000s | torch.Size([1, 3, 448, 640]) tot 0.040s |load 0.006s |pre 0.007s |net 0.024s |dec 0.001s |post 0.002s |merge 0.000s |
2. Maximum side shrinkage 1280
Run: ~ / CenterNet/src$
python demo.py ctdet --demo ../data/samples --load_model ../models/ctdet_coco_dla_2x.pth --input_h 896 --input_w 1280
Results: the average time of the model was 78 MS and the overall average time was 115 Ms
loaded ../models/ctdet_coco_dla_2x.pth, epoch 230 torch.Size([1, 3, 896, 1280]) /opt/conda/conda-bld/pytorch_1587428398394/work/aten/src/ATen/native/BinaryOps.cpp:81: UserWarning: Integer division of tensors using div or / is deprecated, and in a future release div will perform true division as in Python 3. Use true_divide or floor_divide (// in Python) instead. tot 0.302s |load 0.005s |pre 0.039s |net 0.254s |dec 0.003s |post 0.002s |merge 0.000s | torch.Size([1, 3, 896, 1280]) tot 0.137s |load 0.007s |pre 0.041s |net 0.085s |dec 0.002s |post 0.002s |merge 0.000s | torch.Size([1, 3, 896, 1280]) tot 0.114s |load 0.005s |pre 0.027s |net 0.077s |dec 0.002s |post 0.002s |merge 0.000s | torch.Size([1, 3, 896, 1280]) tot 0.160s |load 0.023s |pre 0.057s |net 0.076s |dec 0.002s |post 0.002s |merge 0.000s | torch.Size([1, 3, 896, 1280]) tot 0.114s |load 0.004s |pre 0.025s |net 0.080s |dec 0.002s |post 0.002s |merge 0.000s | torch.Size([1, 3, 896, 1280]) tot 0.113s |load 0.006s |pre 0.026s |net 0.076s |dec 0.002s |post 0.002s |merge 0.000s | torch.Size([1, 3, 896, 1280]) tot 0.111s |load 0.004s |pre 0.025s |net 0.077s |dec 0.002s |post 0.002s |merge 0.000s | torch.Size([1, 3, 896, 1280]) tot 0.126s |load 0.014s |pre 0.029s |net 0.079s |dec 0.002s |post 0.002s |merge 0.000s | torch.Size([1, 3, 896, 1280]) tot 0.125s |load 0.010s |pre 0.031s |net 0.080s |dec 0.002s |post 0.002s |merge 0.000s | torch.Size([1, 3, 896, 1280]) tot 0.114s |load 0.006s |pre 0.026s |net 0.078s |dec 0.002s |post 0.002s |merge 0.000s |
4. Experimental summary
CenterNet vs YoloV3 speed model reasoning time consuming
Model \ size | 320 | 512 | 800 | 1024 |
|---|---|---|---|---|
YoloV3-spp-ultralytics | 12ms | 20ms | 40ms | 50ms |
CenterNet-DLA-34 | 16ms | 20ms | 41ms | 53ms |
CenterNet vs YoloV3 speed model reasoning / overall time consuming
Models \ dimensions | 640 model | 640 overall | 1280 model | 1280 overall |
|---|---|---|---|---|
YoloV3-spp-ultralytics | 26ms | 64ms | 77ms | 124ms |
CenterNet-DLA-34 | 27ms | 50ms | 78ms | 115ms |
CenterNet vs YoloV3 speed model size / memory consumption
Models \ resources | Model volume | 1280 size memory usage |
|---|---|---|
YoloV3-spp-ultralytics | 252.3 MB (252297867 bytes) | 1.7G |
CenterNet-DLA-34 | 80.9 MB (80911783 bytes) | 1.2G |
Speed and resource basis, the author's personal test results, welcome to reproduce and question
Models \ dimensions | 512 |
|---|---|
YoloV3 | 32.7 map |
YoloV3-spp | 35.6 map |
YoloV3-spp-ultralytics | 42.6 map |
CenterNet-DLA-34 | 37.4 map |
Accuracy basis:
1.https://github.com/ultralytics/yolov3
2.https://github.com/xingyizhou/CenterNet
The conclusions are as follows:
As for the author's query part, "the author still has some doubts about the improvement of CenterNet's speed for YoloV3", the experimental results partially prove the correctness of the author's doubt.
In terms of model reasoning speed, CenterNet-DLA-34 takes more time than yolov3 spp version at different scales (1% - 3%), which is slightly inconsistent with the paper. However, if the processing time is also taken into account, the time consumption of CenterNet-DLA-34 is significantly lower than that of yolov3 spp version at different scales, with an increase of about 5% - 10%.
In terms of model size and memory occupation, the effect of CenterNet-DLA-34 is more obvious than that of yolov3 spp, the volume is reduced to about 25% of yolov3 spp, and the memory occupation of reasoning GPU is also reduced to about 70%. This is considered to be the advantage brought by Anchor Free method.
From the table CenterNet vs YoloV3x coco accuracy, it can be seen that under the same scale, CenterNet is significantly improved by 5 percentage points compared with the original YoloV3 and 2 percentage points compared with YoloV3 spp, but there is still a deficiency of 5 percentage points compared with YoloV3 spp ultralytics (U version YoloV3 spp). Of course, this premise is that these data are accurate and reliable. I tend to believe this result, but I can't be responsible for this result. To sum up, CenterNet has improved significantly compared with the original version of YoloV3, but the improvement of YoloV3 spp is not obvious, which is also lower than that of YoloV3 spp in version U.
To sum up, CenterNet is a pioneering work. It unifies the process of key points and target detection. It has simple structure and convenient use. The author loves this network very much and applies it to practical scenes. The speed and accuracy are improved compared with YoloV3 and even YoloV3 spp, Except that the deployment will be slightly more difficult (mainly because the current reasoning framework support of DCN is not friendly, but there are solutions).
CenterNet can replace YoloV3 by virtue of its simple structure, convenient use, high speed, high precision and less memory. Although YoloV4 has also come out, the author thinks that while YoloV4 improves the accuracy, the overall complexity and time-consuming of the model also increases. YoloV4 completely replaces YoloV3, which is not realistic (if readers are interested in the effect of YoloV4 compared with YoloV3, they can comment. If there are many interested friends, the author can update one).
Finally, to the conclusion of this paper, CenterNet has obvious advantages over YoloV3, and it is recommended to try to replace it.