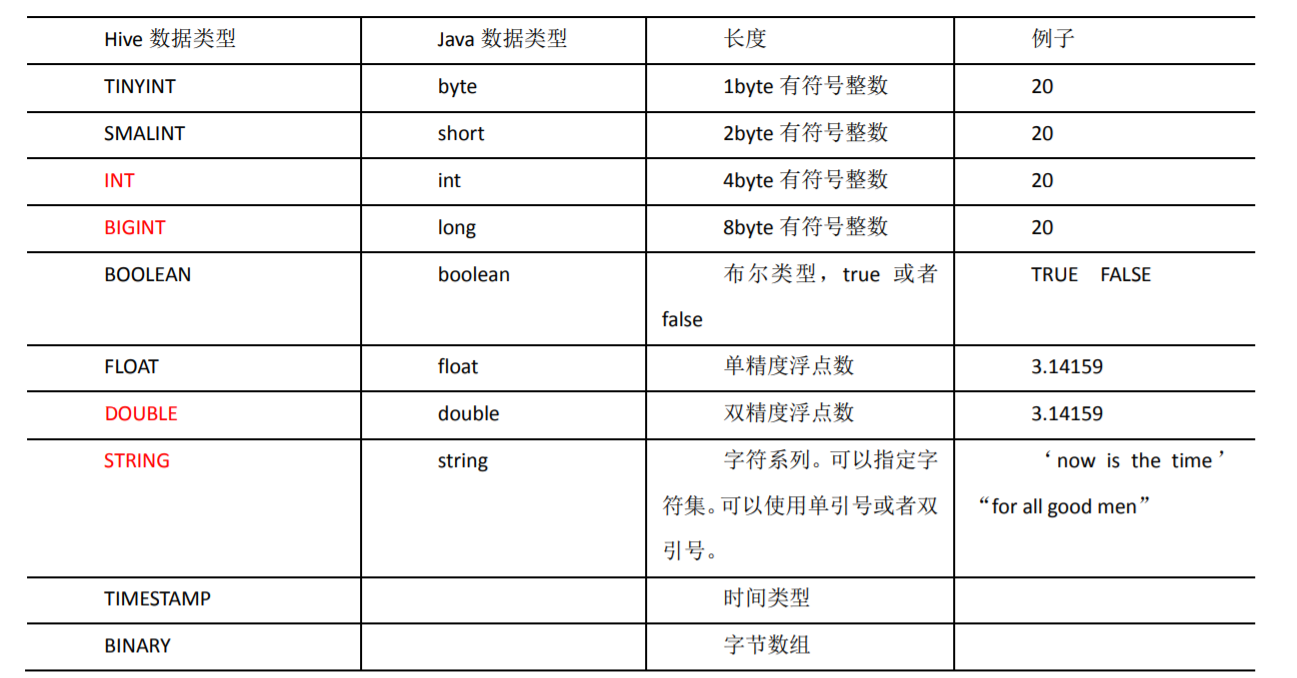
Hive data type
1. Basic data type
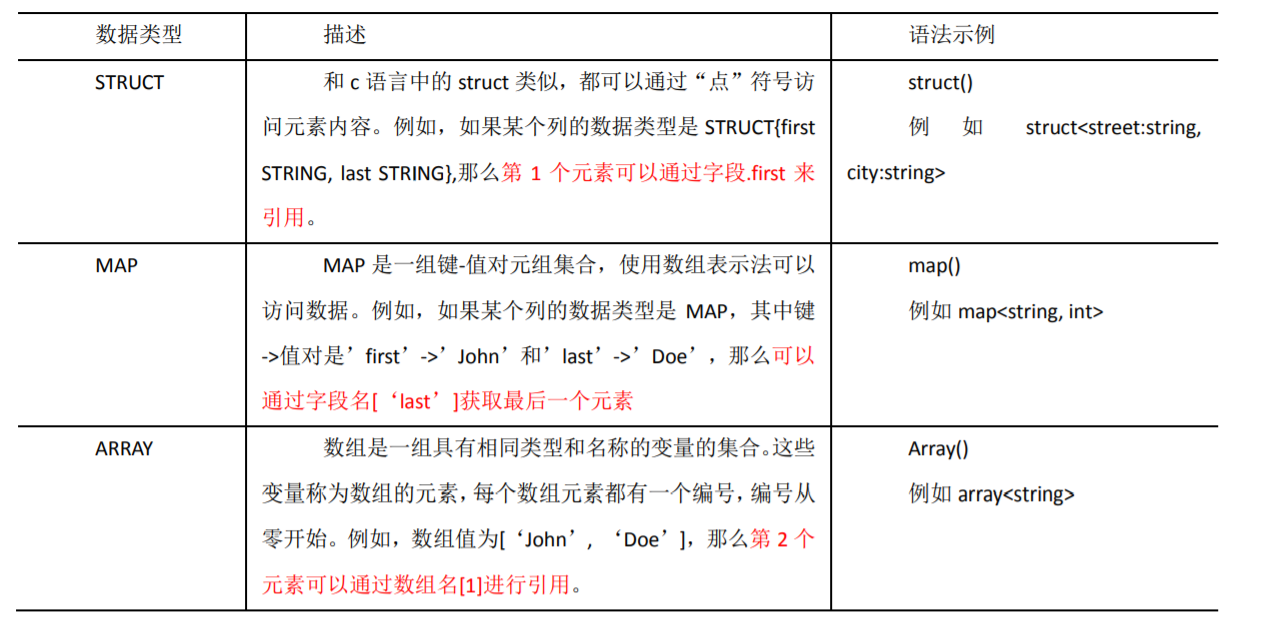
2. Collection data type
Case practice
(1) Assuming that a table has the following row, we use JSON format to represent its data structure. The format accessed under Hive is
{
"name": "songsong",
"friends": ["bingbing" , "lili"] , //List Array,
"children": { //Key value Map,
"xiao song": 18 ,
"xiaoxiao song": 19
}
"address": { //Struct ure,
"street": "hui long guan",
"city": "beijing"
}
}
(2) Based on the above data structure, we create corresponding tables in Hive and import data. Create the local test file test txt
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing
(3) Create test table test on Hive
create table test( name string, friends array<string>, children map<string, int>, address struct<street:string, city:string> ) row format delimited fields terminated by ',' collection items terminated by '_' map keys terminated by ':' lines terminated by '\n';
Field interpretation:
- Column separator: row format delimited fields terminated by ','
- Separator of map structure and ARRAY (data segmentation symbol): collection items terminated by ''
- Separator between key and value in MAP: map keys terminated by ':
- Line separator: lines terminated by '\ n';
(4) Import text data into the test table;
load data local inpath '/opt/module/hive/datas/test.txt' into table test;
(5) Access the data in the three collection columns. The following are the access methods of ARRAY, MAP and structure
select friends[1],children['xiao song'],address.city from test where name="songsong";

3. Type conversion
1) Implicit type conversion rules are as follows
(1)Any integer type can be implicitly converted to a broader type, such as TINYINT Can be converted to INT,INT Can be converted to BIGINT. (2)All integer types FLOAT and STRING Types can be implicitly converted to DOUBLE (3)TINYIN,SMALLINT,INT Can be converted to FLOAT (4)BOLLEAN Type cannot be converted to any other type
2) The CAST operation display can be used for data type conversion
For example, CAST('1 'AS INT) will convert string' 1 'to integer 1; If the cast fails, such as CAST('X 'AS INT), the expression returns NULL
Database related operations
1. Create database
CREATE DATABASE [IF NOT EXISTS] database_name [COMMENT database_comment] [LOCATION hdfs_path] [WITH DBPROPERTIES (property_name=property_value,...)];
2. Query database
1) Display database
show databases;
2) View database details
desc database [extended] db_hive; extended: detailed information
3) Switch current database
use database_name;
3. Modify database
Users can use the alter database command to set key value pair property values for the dbproperties of a database to describe the property information of the database.
For example: alter database db_hive set dbproperties('createtime'='20220122');

4. Delete database
1) Delete empty database
drop database database_name;
2) If the deleted database does not exist, it is best to use if exists to judge whether the database exists
drop database if exists database_name;
3) If the database is not empty, you can use the cascade command to forcibly delete it
drop database database_name cascade;
Table related operations
1. Table building
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION hdfs_path] [TBLPROPERTIES (property_name=property_value, ...)] [AS select_statement]
(1)CREATE TABLE Create a table with the specified name. If a table with the same name already exists, an exception is thrown; Users can use IF NOT EXISTS Option to ignore this exception. (2)EXTERNAL Keyword allows users to create an external table. While creating the table, you can specify a path to the actual data( LOCATION),When deleting a table, the metadata and data of the internal table will be deleted together, while the external table only deletes the metadata and does not delete the data. (3)COMMENT Add comments to tables and columns (4)PARTITIONED BY Create partition table (5)CLUSTERED BY Create bucket table (6)SORTED BY Not commonly used. Sort one or more columns in the bucket separately (7)ROW FORMAT DELIMITED [FIELDS TERMINATED BY char][COLLECTION ITEMS TERMINATED BY char][MAP KEYS TERMINATED BY char][LINES TERMINATED BY char] SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value,property_name=property_value, ...)] Users can customize when creating tables SerDe Or use your own SerDe,If not specified ROW FORMAT perhaps ROW FORMAT DELIMITED,Will use its own SerDe. When creating a table, you also need to specify columns for the table. When you specify the columns of the table, you will also specify columns Custom SerDe,Hive adopt SerDe Determine the data of the specific column of the table. SerDe yes Serialize/Deserilize For short, hive use Serde Sequence and deserialize row objects. (8)STORED AS Specify storage file type, common storage file type, common storage file type: SEQUENCEFILE(Binary sequence file),TEXTFILE(text),RCFILE(Column storage format file) If the file data is plain text, you can use STORED AS TEXTFILE,If data needs to be compressed, use STORED AS SEQUENCEFILE (9)LOCATION Specify the table in HDFS Storage location on (10)AS Followed by a query statement to create a table based on the query results (11)LIKE Allows users to copy existing table structures without copying data
2. Management table
Theory: the tables created by default are so-called management tables, which are sometimes called internal standards. Because of this table, hive controls (more or less) the life cycle of the data. Hive will store the data of these tables in hive by default metastore. warehouse. Under the subdirectory of the directory defined by dir (/ user / hive / warehouse)
When we delete a management table, Hive will also delete the data in the table. Management tables are not suitable for sharing data with other tools.
(1) Normal create table
create table if not exists student( id int, name string ) row format delimited fields terminated by '\t' stored as textfile location '/user/hive/warehouse/student';
(2) Create a table based on the query results (the query results are added to the newly created table)
create table if not exists student2 as select id,name from student;
(3) Create a table based on an existing table structure
create table if not exists student3 like student;
(4) Type of query table
desc formatted database_name;
3. External table
Theory: because the table is an external table, Hive doesn't think it has the data completely. Deleting the table will not delete the data, but the metadata information describing the table will be deleted.
Usage scenario analysis: regularly flow the website log of the mobile phone into the HDFS file text every day. Do a lot of statistical analysis based on the external table (original log table). The intermediate table and result table used are stored in the internal standard, and the data enters the internal standard through SELECT+INSERT.
4. Conversion between management table and external table
(1) Type of query table
desc formatted database_name;
(2) Modify the internal table student2 to an external table
alter table student2 set tblproperties('EXTERNAL'='TRUE');
(3) Modify the external table student2 to the internal table
alter table student2 set tblproperties('EXTERNAL'='FALSE');
5. Rename table
ALTER TABLE table_name RENAME TO new_table_name
6. Add / modify / replace column information
(1) Modify column
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment][FIRST|AFTER column_name]
(2) Add and replace columns
ALTER TABLE table_name ADD|REPALCE COLUMNS (col_name data_type[COMMENT col_comment],...) Note: ADD Yes means a new field is added, and the field position is after all columns(partition Before column) REPLACE It means to replace all fields in the table
7. Delete table
drop table table_name;
DML data operation
1. Data import
1) Loading data into a table
load data [local] inpath 'Data path' [overwrite] into table student [partition (partcol1=val1,...)];
- load data: indicates loading data
- Local: indicates loading data from local to hive; Otherwise, load the hive flag from HDFS
- inpath: indicates the loaded path
- Overwrite: it means to overwrite the existing data in the table; otherwise, it means to append
- into table: indicates which table to load
- student: represents a specific table
- Partition: indicates to upload to the specified partition
2) Insert data into a table through a query statement (insert)
① Create a table first
create table student_par(id int, name string) row format delimited fields terminated by '\t';
② Basic insert data
insert into table student_par values(1,'wangwu'),(2,'zhaoliu');
③ Basic mode insertion (based on the query results of a single table)
insert overwrite table student_par select id, name from student where month='201709';
Insert into: insert into a table or partition by appending data. The original data will not be deleted
insert overwrite: it will overwrite the existing data in the table
Note: insert does not support inserting partial fields
④ Multi table (multi partition) insertion mode (based on query results of multiple tables)
from student insert overwrite table student partition(month='201707') select id, name where month='201709' insert overwrite table student partition(month='201706') select id, name where month='201709';
3) Create tables and load data in query statements (As Select)
create table if not exists student3 as select id,name from student;
4) When creating a table, specify the load data path through Location
① Upload data to hdfs
hive (default)> dfs -mkdir /student; hive (default)> dfs -put /opt/module/datas/student.txt /student;
② Create a table and specify the location on hdfs
hive (default)> create external table if not exists student5( id int, name string ) row format delimited fields terminated by '\t' location '/student;
5) The Import data is specified in the Hive table
export first, and then import the data
hive (default)> import table student2 from '/user/hive/warehouse/export/student';
2. Data export
1) Insert export
① Export query results to local
insert overwrite local directory '/opt/module/hive/data/export/student' select * from student;
② Format and export query results to local
insert overwrite local directory '/opt/module/hive/data/export/student1' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' select * from student;
③ Export the query results to HDFS (no local)
insert overwrite directory '/user/yingzi/student2' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' select * from student;
2) Hadoop command export to local
dfs -get /user/hive/warehouse/student/student.txt /opt/module/data/export/student3.txt;
3) Hive Shell command export
Basic syntax: hive -f/-e execute statement or script > file
[yingzi@hadoop102 hive]$ bin/hive -e 'select * from default.student;' > /opt/module/hive/data/export/student4.txt;
4) Export to HDFS
export table default.student to '/user/hive/warehouse/export/student';
5) Clear the data in the table (Truncate)
Note: Truncate can only delete management tables, not data sets in external tables
truncate table database_name;
xt;
3) Hive Shell command export
Basic syntax: hive -f/-e execute statement or script > file
[yingzi@hadoop102 hive]$ bin/hive -e 'select * from default.student;' > /opt/module/hive/data/export/student4.txt;
4) Export to HDFS
export table default.student to '/user/hive/warehouse/export/student';
5) Clear the data in the table (Truncate)
Note: Truncate can only delete management tables, not data sets in external tables
truncate table database_name;