0. Introduction
The data synchronization from mysql to es involves the data synchronization of parent-child tables. It is hereby recorded for subsequent reference
For details on synchronizing mysql to es, please refer to my previous blog:
Elastic actual combat: through canal1 1.5 realize mysql8 0 data increment / full synchronization to elasticsearch7 x
1. Environment
canal 1.1.5 elasticsearch7.13 mysql 8.0
2. Basic type array synchronization
The relevant configuration is actually Official documents There are examples in, and the following is also implemented based on these examples
This method is based on the data in the array, such as List,List, etc
2.1 sql configuration description
sql supports multi table Association and free combination, but there are certain restrictions:
1. The main table cannot be a subquery statement
2. Only left outer join can be used, that is, the leftmost table must be the main table
3. If the associated slave table is a subquery, there cannot be multiple tables
4. There cannot be a where query condition in the main sql (there can be a where condition in the sub query from the table, but it is not recommended, which may cause inconsistency in data synchronization, such as modifying the field content in the where condition)
5. Association conditions only allow '=' operations of primary and foreign keys, and other constant judgments are not allowed, such as on a.role_id=b.id and b.statues=1
6. The association condition must have a field in the main query statement, such as on a.role_id=b.id where a.role_id or b.id must appear in the main select statement
7. The mapping attribute of Elastic Search will correspond to the query value of sql one by one (select * is not supported), such as select a.id as_ id, a.name, a.email as _ Email from user, where name will be mapped to the name field of es mapping_ Email will be mapped to the of mapping_ email field, where the alias (if any) is used as the final mapping field Here_ ID can be filled in the configuration file_ id: _id mapping
2.2 configuration steps
es mappings (some fields have been eliminated)
{
"service_comment_driver" : {
"mappings" : {
"properties" : {
"id" : {
"type" : "keyword"
},
"avg" : {
"type" : "double"
},
"comment" : {
"type" : "text"
},
"createTime" : {
"type" : "date"
},
"labels" : {
"type" : "text",
"analyzer" : "ik_smart"
}
}
}
}
}
1,sql
Associate the sub table data through left join, and the fields to be queried through group_concat functions are spliced together, group_ The concat function is used to connect the values in the same group generated by group by, return a string result, and separate different lines with the symbol specified by separator
select
t.id as _id,
t.avg as avg,
t.create_time as createTime,
t.comment as comment,
l.labels
from
t_service_comment_driver t
left join
(select bussiness_id,group_concat(label order by id desc separator ';') as labels from t_service_comment_label
where type=0 group by bussiness_id) l
on
t.id = l.bussiness_id
2. Add configuration to adapter configuration file
objFields:
labels: array:; # Array attribute, array:; The representative field is represented by; Separated
The configuration file in the overall Canadian adapter / conf / ES7: comment yml
dataSourceKey: duola_bussness # The key here is the same as the above application The data sources configured in YML are consistent
outerAdapterKey: esKey # Similar to the above application Outeradapters configured in YML Key always
destination: example # The default is example, which is the same as application The instance configured in YML is consistent
groupId:
esMapping:
_index: service_comment_driver
_type: _doc
_id: _id
sql: "select
t.id as _id,
t.avg as avg,
t.create_time as createTime,
t.comment as comment,
l.labels
from
t_service_comment_driver t
left join
(select bussiness_id,group_concat(label order by id desc separator ';') as labels from t_service_comment_label
where type=0 group by bussiness_id) l
on t.id = l.bussiness_id"
objFields:
labels: array:; # Array or object attribute, array:; Represented by; The field is marked with; Separated
#etlCondition: "where t.create_time>='{0}'"
commitBatch: 3000
3. Start adapter
./bin/startup.sh
4. Modify the data in the corresponding database table, and then view the log
cat logs/adapter/adapter.log
It is found that there is already updated data

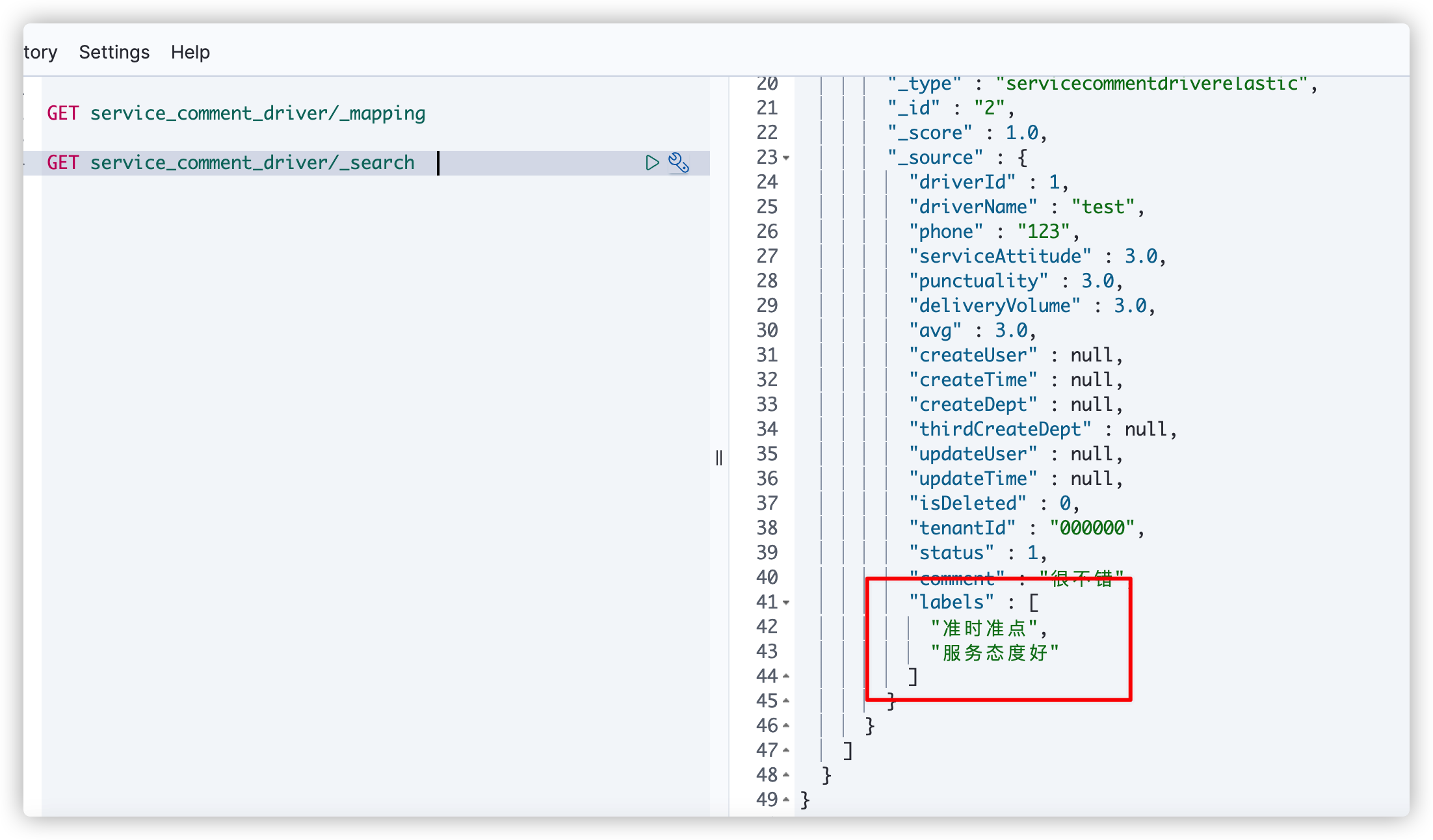
5. View data in es
GET service_comment_driver/_search
It is found that the data in labels has been updated synchronously and is in the form of array. After modifying the sub table data, it will also be updated synchronously
2.3 common error reports
1. Unknown column '_v._id' in 'where clause'
The in the configuration file_ ID mapping adjusted to_ ID is enough. Note that the alias in sql should be_ id.
_id: _id
sql
select t.id as _id ...
3. Object array synchronization
3.1 ideas
This method is for the data in the array that is a user-defined object, such as list < Object >
In contrast, the structure in es is list < nested >
There is no official example to support this type of synchronization, but observing the official documents, you will find that the official provides an object-oriented field synchronization
objFields: <field>: object
Although the official description of this type is more targeted at one-to-one json strings, you might as well try to see if you can support json arrays
Object in canal is a recognized json string, so our idea is to convert the sub table data into json string, and then use object
3.2 configuration steps
1,es mapping
{
"service_comment_owner" : {
"mappings" : {
"properties" : {
"avg" : {
"type" : "double"
},
"comment" : {
"type" : "text"
},
"createTime" : {
"type" : "date"
},
"id" : {
"type" : "keyword"
},
"labels" : {
"type" : "nested",
"properties" : {
"id" : {
"type" : "long"
},
"label" : {
"type" : "text",
"analyzer" : "ik_smart"
},
"type" : {
"type" : "integer"
}
}
}
}
}
}
}
2,sql
select
t.id as _id,
t.avg as avg,
t.create_time as createTime,
t.comment as comment,
CONCAT('[',l.labels,']') as labels
from
t_service_comment_owner t
left join
(select bussiness_id,group_concat(json_object('id',id,'type',type,'label',label)) as labels from t_service_comment_label where type=1 group by bussiness_id) l
on
t.id=l.bussiness_id
3. adapter profile
objFields:
labels: object
4. Overall profile
dataSourceKey: duola_bussness # The key here is the same as the above application The data sources configured in YML are consistent
outerAdapterKey: esKey # Similar to the above application Outeradapters configured in YML Key always
destination: example # The default is example, which is the same as application The instance configured in YML is consistent
groupId:
esMapping:
_index: service_comment_owner
_type: _doc
_id: _id
sql: "select
t.id as _id,
t.avg as avg,
t.create_time as createTime,
t.comment as comment,
CONCAT('[',l.labels,']') as labels
from
t_service_comment_owner t
left join
(select bussiness_id,group_concat(json_object('id',id,'type',type,'label',label)) as labels from t_service_comment_label where type=1 group by bussiness_id) l
on
t.id=l.bussiness_id"
#etlCondition: "where t.update_time>='{0}'"
commitBatch: 3000
objFields:
labels: object # Array or object properties
5. Start adapter
./bin/startup.sh
6. Modify the data in the corresponding database table, and then view the log. You will find that there is data output in the log
cat logs/adapter/adapter.log
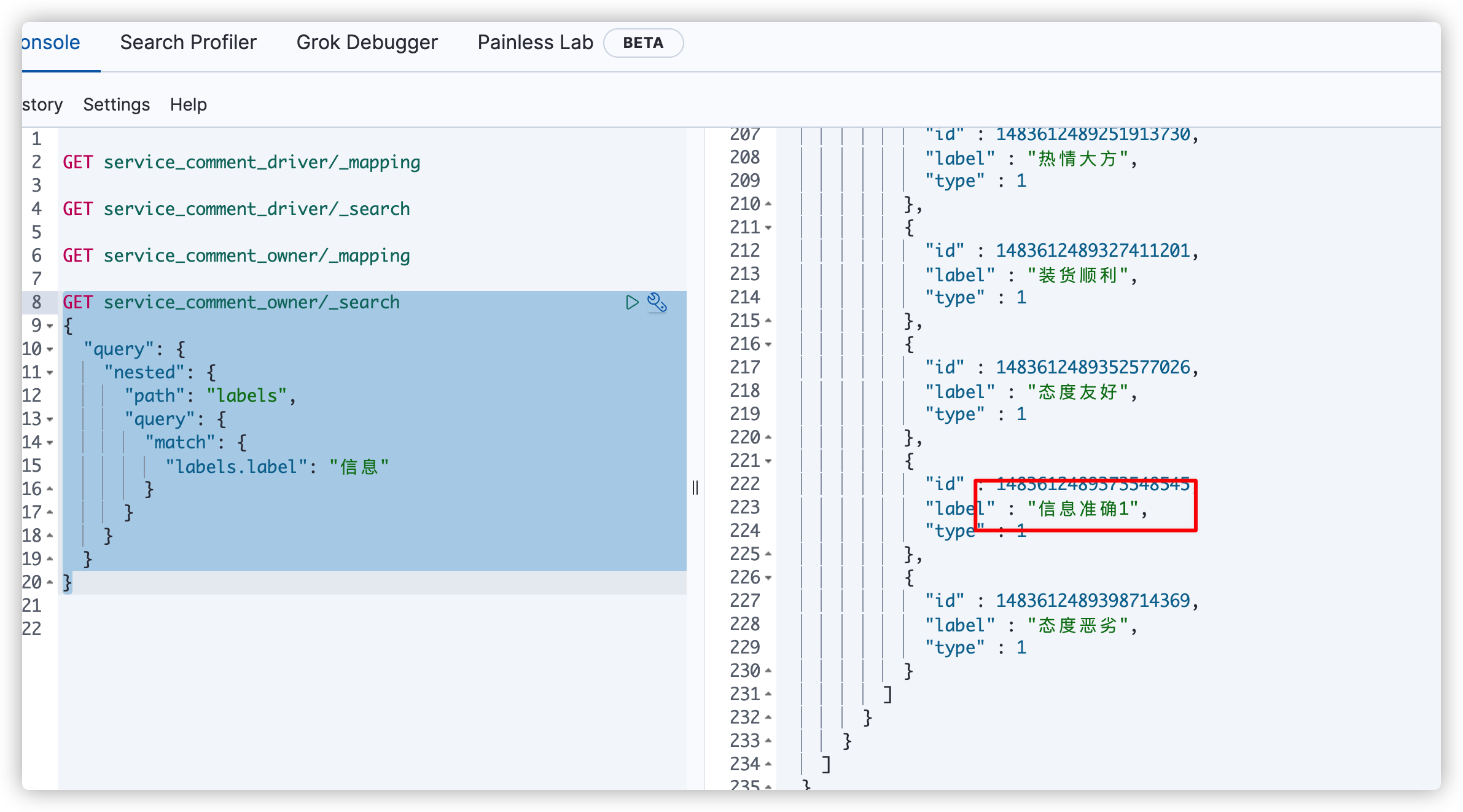
7. Query index data. Note that because it is a nested structure, nested query is used
GET service_comment_owner/_search
{
"query": {
"nested": {
"path": "labels",
"query": {
"match": {
"labels.label": "information"
}
}
}
}
}
You will find that the information just modified has been updated
3.3 common error reports
1. RuntimeException: com.alibaba.fastjson.JSONException: not close json text, token : ,
This error is caused by the lack of necessary symbols in json recognition, because our above practice is to convert the object-oriented array into a json array. The json array needs to have [] symbols. Just add these two symbols
CONCAT('[',l.labels,']')
4. join data synchronization
4.1 join type application scenarios
The so-called join type refers to the join data type in es, which is applicable to the following scenarios
1. Data of parent-child table structure
2. The child table data is significantly more than the parent table data
The join type cannot be used like a table connection in a relational database, whether it is a has_child or has_ Both parent queries will have a serious negative impact on the query performance of the index and trigger global orders. Therefore, the join type cannot be used when the parent-child table structure is encountered. Consider the above two methods first, and then consider when the child table data is much higher than the parent table data.
4.2 configuration steps
(since there is no application demand, the following configuration instructions are given according to the official documents and will be continuously updated later)
1,es mappings
{
"mappings":{
"_doc":{
"properties":{
"id": {
"type": "long"
},
"name": {
"type": "text"
},
"email": {
"type": "text"
},
"order_id": {
"type": "long"
},
"order_serial": {
"type": "text"
},
"order_time": {
"type": "date"
},
"customer_order":{
"type":"join",
"relations":{
"customer":"order"
}
}
}
}
}
}
2,adapter/es7/customer.yml
esMapping:
_index: customer
_type: _doc
_id: id
relations:
customer_order:
name: customer
sql: "select t.id, t.name, t.email from customer t"
3,adapter/es7/order.yml profile
esMapping:
_index: customer
_type: _doc
_id: _id
relations:
customer_order:
name: order
parent: customer_id
sql: "select concat('oid_', t.id) as _id,
t.customer_id,
t.id as order_id,
t.serial_code as order_serial,
t.c_time as order_time
from biz_order t"
skips:
- customer_id
4. Start service
./bin/startup.sh