
Introduction to the sketch framework
Scratch is a fast and high-level screen capture and Web Capture framework developed by Python language, which is used to capture web sites and extract structured data from pages.
Its functions are as follows:
-
Scrapy is an application framework implemented in Python for crawling website data and extracting structural data.
-
Scrapy is often used in a series of programs, including data mining, information processing or storing historical data.
-
Usually, we can simply implement a crawler through the Scrapy framework to grab the content or pictures of the specified website.
scrapy Portal of frame: https://scrapy.org
How the scratch framework works
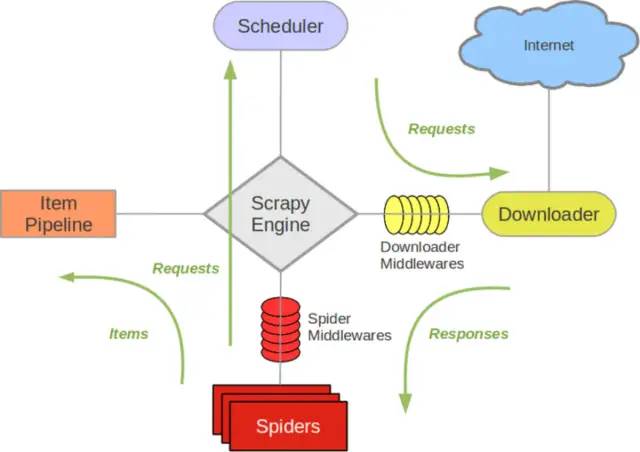
Scratch engine: communication between losers Spider, ItemPipeline, Downloader and Scheduler, signal and data transmission, etc.
Scheduler: it is responsible for receiving the Request sent by the lead stroke, sorting and arranging in a certain way, joining the queue, and returning it to the engine when needed by the engine.
Downloader: responsible for downloading all Requests sent by the scratch engine, and returning the Responses obtained to the scratch engine, which will be handed over to Spider for processing.
Spider (crawler): it is responsible for processing all Responses, analyzing and extracting data from them, obtaining the data required by the Item field, submitting the URL to be followed up to the engine and entering the scheduler again.
Item pipeline: it is responsible for processing the items obtained in the Spider and performing post-processing (detailed analysis, filtering, storage, etc.).
Downloader middleware: you can regard it as a component that can customize and extend the download function.
Spider middleware: you can understand it as a functional component that can customize the expansion and operation of the intermediate communication between the engine and the spider (such as Responses entering the spider and Requests leaving the spider)
I don't know if you remember that when we write about crawlers, we usually divide them into three functions.
#Get web page information def get_html(): pass #Parsing web pages def parse_html(): pass #Save data def save_data(): pass
These three functions basically do not say who calls who. Finally, these functions can only be called through the main function.
Obviously, our scratch framework is the same principle, but it saves the functions of these three parts in different files and calls them through the scratch engine.

When we write the code and run it with scratch, the following dialogue will appear.
Engine: brother Meng, spicy? Boring, reptiles!
Spider: OK, brother, I've wanted to do it for a long time. Will you climb xxx website today?
Engine: no problem, send the entry URL!
Spider: Well, the URL of the portal is: https://www.xxx.com
Engine: scheduler brother, I have requests here. Please help me sort and join the team.
Scheduler: Engine brother, this is the requests I handled
Engine: downloader brother, please help me download this requests request according to the settings of the download middleware
Downloader: OK, this is the downloaded content. (if it fails: sorry, the request download fails, and then the engine tells the scheduler that the request download fails. You can record it and we'll download it later.)
Engine: brother crawler, this is a good thing to download. The downloader has been processed according to the download middleware. Please handle it yourself.
Spider: brother engine, my data has been processed. Here are two results. This is the URL I need to follow up, and this is the item data I obtained.
Engine: brother pipe, I have an item here. Please help me deal with it.
Engine: scheduler brother, this is the URL that needs to be followed up. Please help me deal with it. (then start the cycle from step 4 until all the information is obtained)
Making a Scrapy crawler requires a total of 4 steps:

New project (scratch startproject XXX): create a new crawler project
Clear goal (write items.py): clear the goal you want to capture
Making spiders (spiders/xxspider.py): making spiders starts crawling web pages
Stored content (pipelines.py): Design pipelines to store crawled content
Today, let's take the little sister of station B as an example to personally experience the power of drama!
First, let's take a look at the common commands of scratch:
scrapy startproject entry name #Create a crawler project or project scrapy genspider Reptile name domain name #Create a crawler spider class under the project scrapy runspider Crawler file #Run a crawler spider class scrapy list #View how many crawlers are in the current project scrapy crawl Reptile name #Specify the run crawl information by name scrapy shell url/file name #Use the shell to enter the script interactive environment
1. First, we create a scratch project, enter the directory you specify, and use the command:
scrapy startproject entry name #Create a crawler project or project
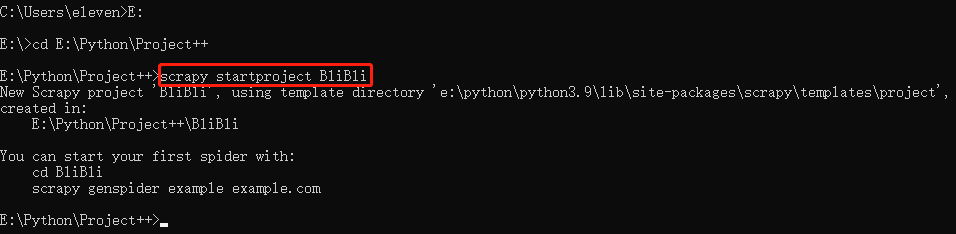
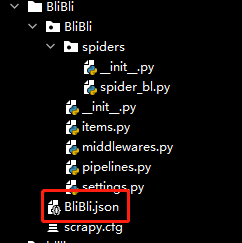
At this point, you can see that there is an additional folder called BliBli under this directory

2. When we finish creating the project, it will be prompted, so we will continue to operate according to its prompts.
You can start your first spider with: cd BliBli scrapy genspider example example.com

When you follow the above operation, you will find that spiders will appear in the spiders folder_ Bl.py this file. This is our crawler file.
Back https://search.bilibili.com/ Is the target website we want to climb
BliBli |- BliBli | |- __init__.py | |- __pycache__. | |- items.py # Item definition, which defines the data structure to be fetched | |- middlewares.py # Define the implementation of Spider, Dowmloader and Middleware | |- pipelines.py # It defines the implementation of the Item Pipeline, that is, the data pipeline | |- settings.py # It defines the global configuration of the project | |__ spiders # It contains the implementation of each Spider, and each Spider has a file
|- __init__.py
|—— spider_bl.py # crawler implementation
|- __pycache__
|—— scrapy. The configuration file of CFG # sweep deployment defines the path of the configuration file and the deployment related information content.
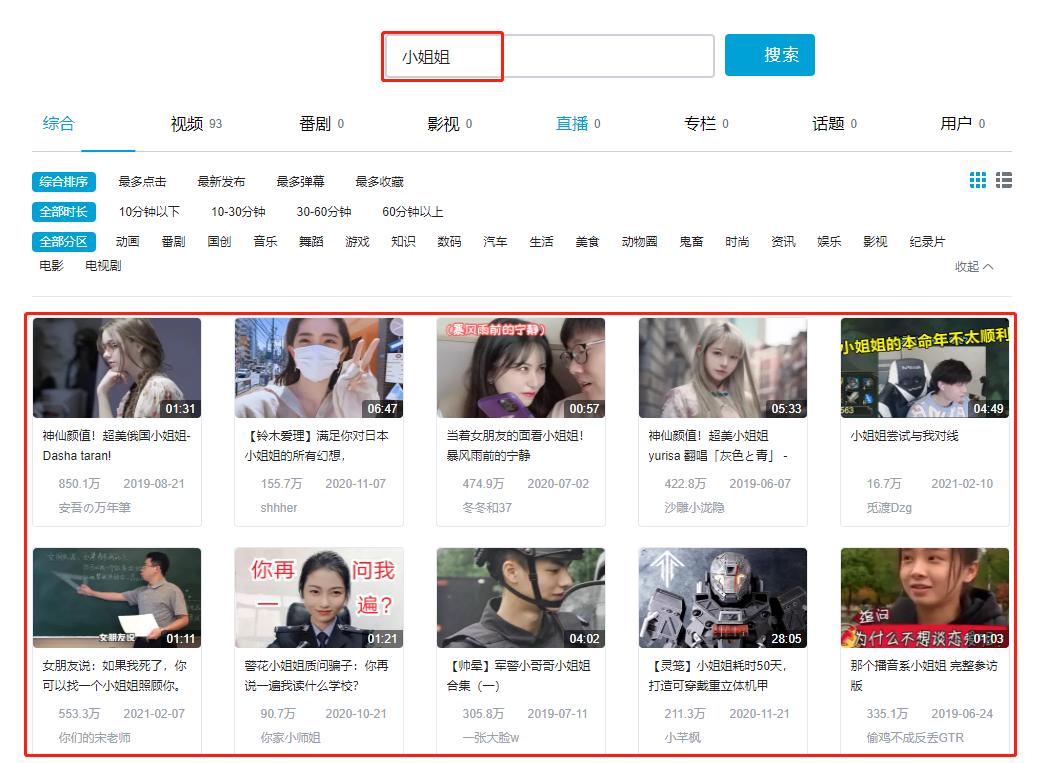
3. Next, we open station B to search 'little sister' as follows as an entry-level crapy tutorial Our task today is very simple. Just climb the video link, title and up master
4. Set the item template and define the information we want to obtain Just like the model class defined in java
# Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class BlibliItem(scrapy.Item): # define the fields for your item here like: title = scrapy.Field() #Video title url = scrapy.Field() #Video link author = scrapy.Field() #Video up master
5. Then we created the spider_ The specific implementation of our crawler function is written in bl.py file
import scrapy
from BliBli.items import BlibliItem
class SpiderBlSpider(scrapy.Spider):
name = 'spider_bl'
allowed_domains = ['https://search.bilibili.com']
start_urls = ['https://search.bilibili.com/all?keyword=%E5%B0%8F%E5%A7%90%E5%A7%90&from_source=web_search']
#Define crawler method
def parse(self, response):
#Instantiate item object
item = BlibliItem()
lis = response.xpath('//*[@id="all-list"]/div[1]/div[2]/ul/li')
for items in lis:
item['title'] = items.xpath('./a/@title').get()
item['url'] = items.xpath('./a/@href').get()
item['author'] = items.xpath('./div/div[3]/span[4]/a/text()').get()
yield item
6. Let's print it in pipeline now. No problem. We'll save it locally
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import json
class BlibliPipeline:
def process_item(self, item, spider):
print(item['title'])
print(item['url'])
print(item['author'])
#Save file locally
with open('./BliBli.json', 'a+', encoding='utf-8') as f:
lines = json.dumps(dict(item), ensure_ascii=False) + '\n'
f.write(lines)
return item
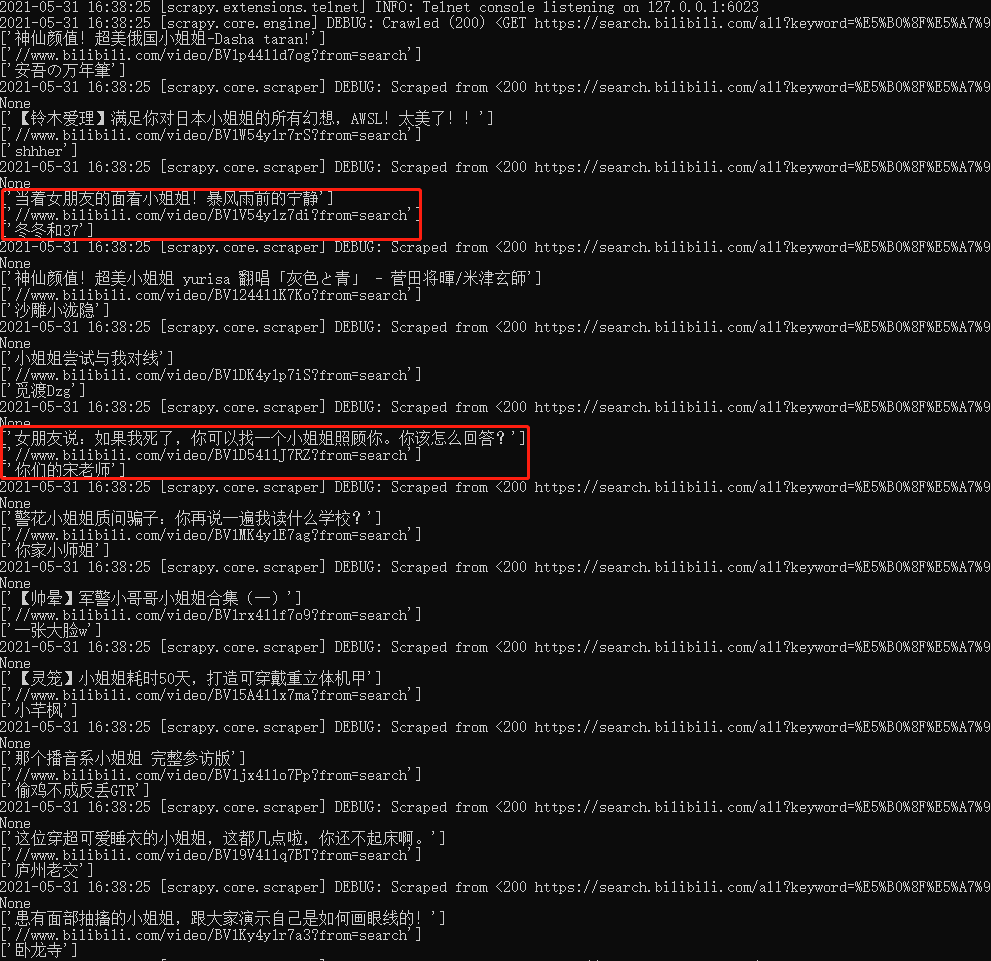
7. settings.py find the following fields and uncomment them.
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
"User-Agent" : str(UserAgent().random),
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'BliBli.pipelines.BlibliPipeline': 300,
}
Run the program with the following command:
scrapy crawl spider_bl
You can see that a json file is generated
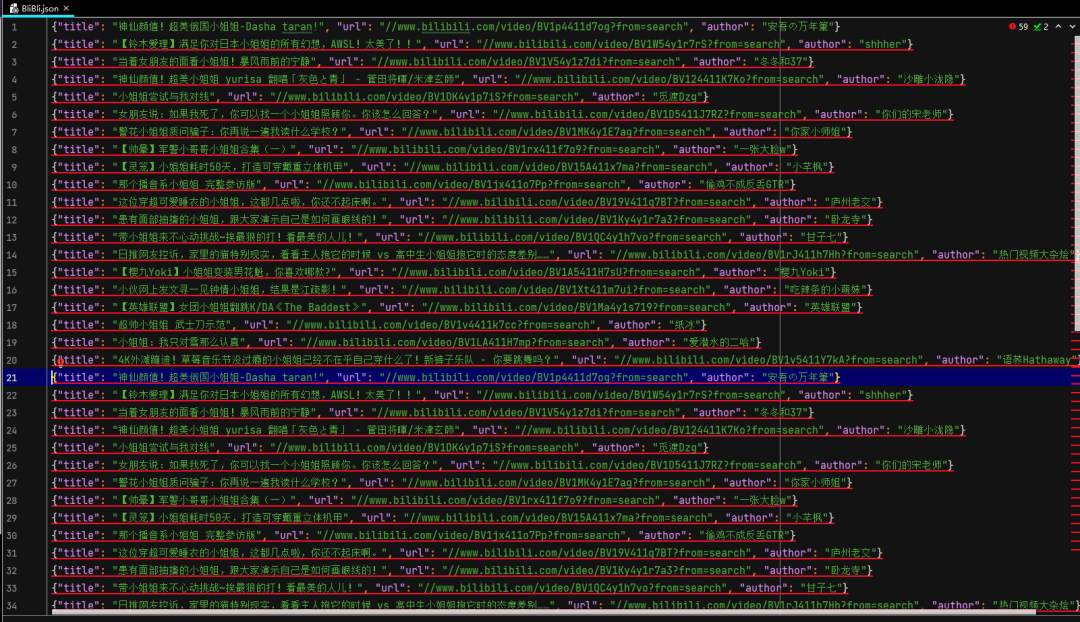
Open the file and you can see that we have successfully obtained the data we want
So how to get multiple pages of data? Next period decomposition~