Related documents
Pay attention to Xiaobian and receive private letter Xiaobian!
Of course, don't forget a three in a row~~
Yes, we can pay attention to the official account of Xiaobian yo ~ ~
Python log
Hello everyone, I'm bold again!
I'll share games with you every day. I'm sure my friends feel a little bored. Today it brings benefits to you!!
Today we use Python to play a fun program. With the proliferation of users watching the live broadcast, more and more young ladies and sisters are communicating and interacting with fans through the live broadcast. However, the live broadcast interface is always full of all kinds of advertising recommendations and bullet screen information, so I can't focus on appreciating my little sister.
We can get the little sister's live information source through web page analysis, and then watch the little sister's live broadcast through the local video streaming player. It made me feel as if my little sister was by my side. It's beautiful to be able to exercise your Python knowledge and appreciate your little sister. Need source code + UP main Python learning exchange group: 773162165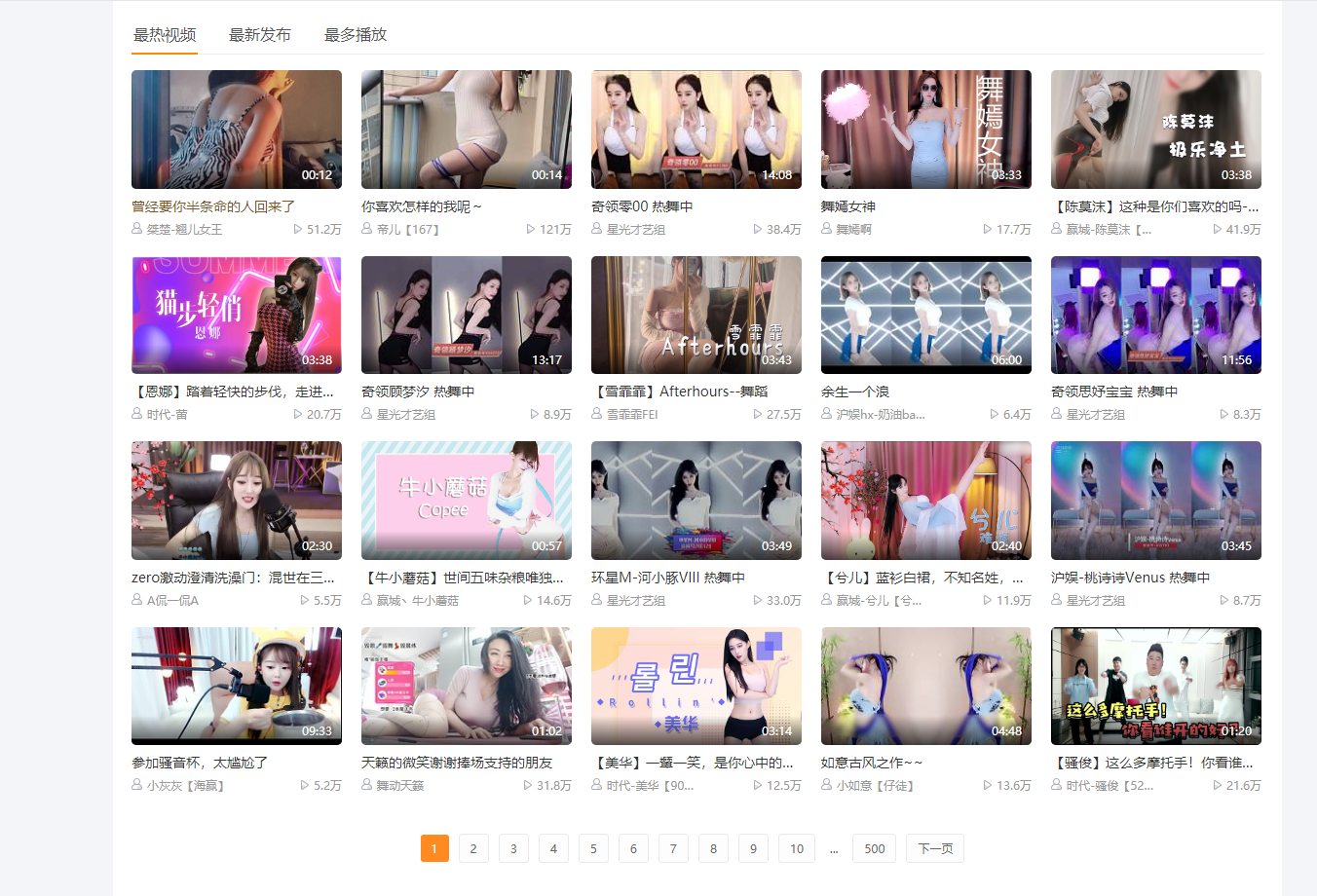
01. Live signal capture
Firstly, we get the live signal source of little sister's live room through the analysis of the live page of station B.
You can open a little sister's live studio of station B at will, as shown in the figure below:
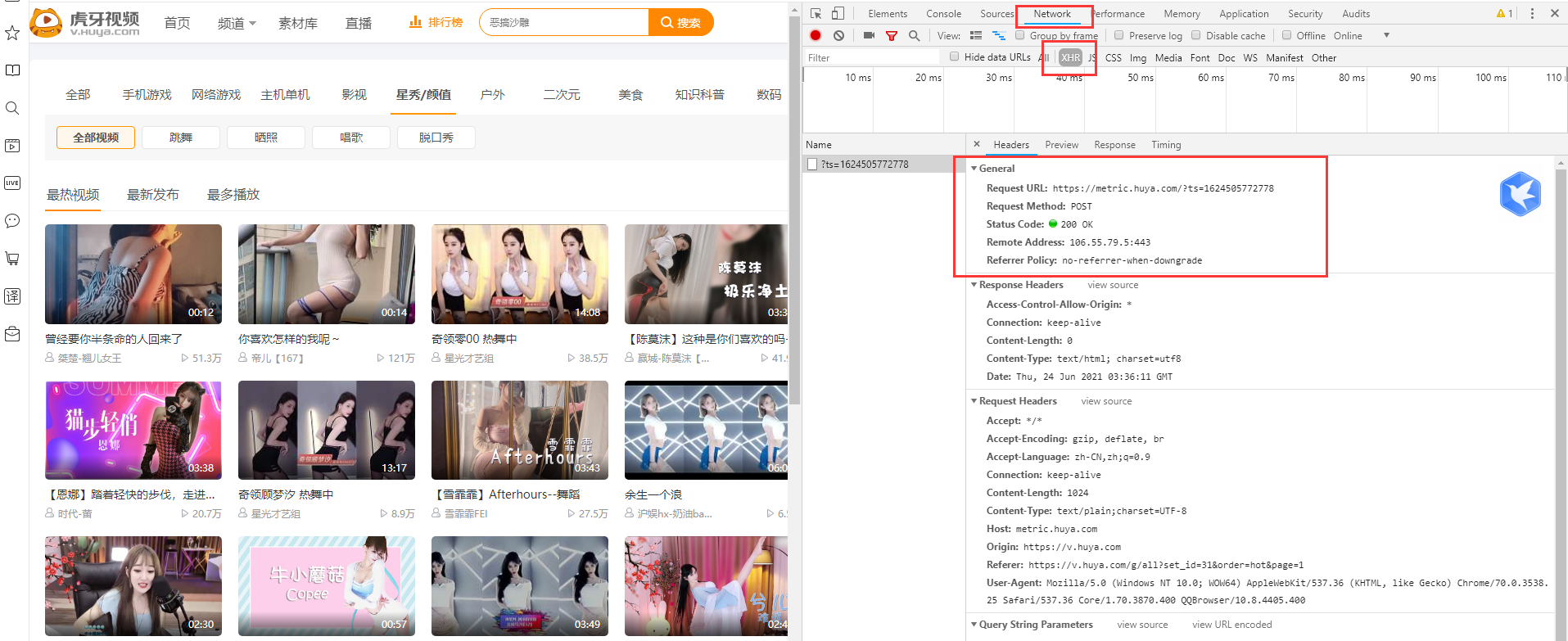
First, open the "developer mode" by pressing "F12", and then click the XHR component under the Network option.
Through browsing, you can find the label content beginning with live. After double clicking, you can get the requested information.
You can see that the Request URL is the signal source of the live broadcast.
# Determine the url address to get the ID of each video
for page in range(5, 11):
print(f'=======================Crawling to No{page}Page data=======================')
url = f'https://v.huya.com/g/all?set_id=31&order=hot&page={page}'
"""
headers What is it?? Request header
What is the function of the request header? hold python The crawler code disguises the browser to send a request to the server (If you don't pretend: The server may not give you data/ The data given to you is wrong..)
What needs to be added to the request header? What's the use of these things?
user-agent: Browser information
cookies: User information, It is often used to detect whether there is a login account VIP data
referer: The anti-theft chain tells the server what we requested url Where did the address come from
host: domain name,Host address
headers It's in the form of a dictionary : Key value pair a key corresponds to a value, and a key is used between the key and the value:Separated values can be any type of key string numeric tuple
"""
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
Program grabbing live signal source
The above method is to obtain the live broadcast signal source manually.
We can also obtain the live broadcast signal source by program.
The interface address of the live broadcast signal source is:
https://liveapi.huya.com/moment/getMomentContent?callback=jQuery112408236898064701803_1620994683221&videoId=485192023&uid=&_=1620994683241
In order to obtain the address of the video source, several parameters need to be passed to the above connection, namely:
The videos we captured can be directly placed in the folder we created:
# Automatically create folders filename = 'video\\'
After capturing the data, we need to parse it:
# Parse data
"""
.*? Wildcards can match any character \d Match a number \d+ Match multiple numbers
The content extracted from the regular expression is in the form of a list
"""
video_ids = re.findall('<a href="/play/(\d+)\.html" class="video-wrap statpid"', response.text)
# print(video_ids)
for index in video_ids:
# The easier it is to get started with the crawler, the more difficult it is to decrypt and find data
# url address of get request? The following list of contents belong to request parameters
index_url = 'https://liveapi.huya.com/moment/getMomentContent'
# params request parameters
# If you post request data form
params = {
# 'callback': 'jQuery112408236898064701803_1620994683221',
'videoId': index,
'uid': '',
'_': '1620994683241',
}
response_1 = requests.get(url=index_url, params=params, headers=headers)
# pprint.pprint(response_1.json())
# How to extract json data content: take values according to key value pairs, and extract values to the right of the colon according to the keys to the left of the colon
video_url = response_1.json()['data']['moment']['videoInfo']['definitions'][-1]['url']
video_title = response_1.json()['data']['moment']['videoInfo']['videoTitle']
Then save the data:
# Save data
# Get binary data content
video_content = requests.get(url=video_url, headers=headers).content
with open(filename + video_title + '.mp4', mode='wb') as f:
f.write(video_content)
print(video_title, video_url)
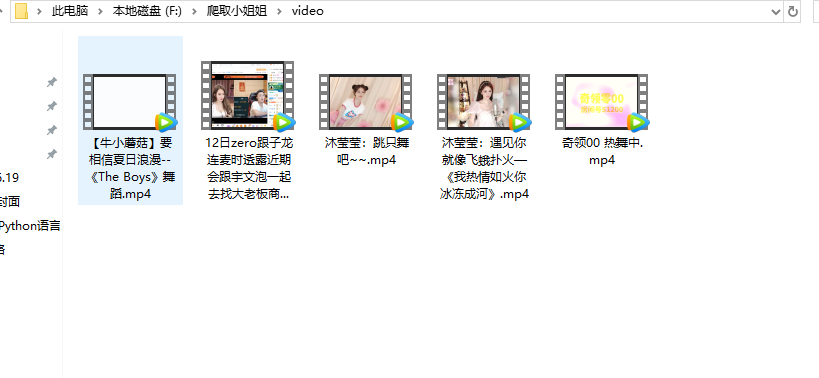
Finally, let's see the effect:
Run the code using Ctrl+shift+F10:

Then open the folder video we created to view the videos we crawled:
Well, today's benefits are given to everyone here. What can you do not understand can be commented below. You need to find the source code to receive the official account. Remember to pay attention to the public number of Xiaobian, ha ~ ~ ().
Many children always encounter some problems and bottlenecks when learning python. They don't have a sense of direction and don't know where to start to improve. For this, I have sorted out some materials and hope to help them. You can add Python learning and communication skirt: 773162165