Now it seems very popular to use Python crawlers for data collection. Let's also learn about Python crawlers. Well, take a look at the python technology roadmap in Uncle Long's blog. It's very good. It all includes.... Wait, is there something missing?
Carefully read the technology roadmap again... There seems to be no mention of xml, xslt and only xpath?
Why does Lao Gu suddenly care about xml and xslt? That's because he has encountered such wonderful flowers in his previous collection career... Give an instance page https://www.govinfo.gov/content/pkg/BILLS-117hr3237ih/xml/BILLS-117hr3237ih.xml , the historical case information in an American legal service website, this page... It looks like html. Open the console in the browser to view the elements. Well, it's html, but once you view the source file, you'll look pale... This is the xml information with xslt style!!!
In order that the collection will not be blocked by xml sites in the future, we should first learn the basics and continue after learning xml well. After all, html is relatively easy to parse. We can basically implement etree, dom, xpath and even css selector. Although the page I gave is relatively simple, the xml is relatively standard, and it is easy to extract information, but... This is not the content of HTML! You have to do it in xml! What's more, Lao Gu has encountered xml content that can get the expected results correctly only after a series of complex combinations in xslt! Therefore, in Gu's mind, xml and xslt must take precedence over crawler learning.
-----------------------------------
Post knowledge source first https://docs.python.org/zh-cn/3/library/xml.html , in this article, we mentioned six sub modules of xml. Let's look at them one by one and sort out what we use first. The with namespace will not be discussed for the time being. (aside from the topic, Gu has always believed that the most important thing in programming is the idea, followed by the understanding of the tools, language and environment used. You only need to know what packages are in the language, what each package can do, and how to realize the idea with these things, so you can start programming. The specific implementation is actually a mechanical labor.)
1,xml.etree.ElementTree: ElementTree API, a simple and lightweight XML processor
import xml.etree.ElementTree as ET
# Load xml from the document and get ElementTree, that is, XmlDocument
tree = ET.parse('xml_file.xml')
# Get the root Node (Element), i.e. Node, from the ElementTree object
root = tree.getroot()
# Load the xml using a string and get the root node (Element) directly
root = ET.fromstring(xml_doc_string)
# Use ET.tostring to output the specified Element object as an xml string document, that is, node OuterXML
xml_str = ET.tostring(root)
# Element.tag gets the tag name of the specified element, that is, NodeName
print(root.tag)
# Elment.attrib gets the attribute dictionary of the specified Element, that is, Attributes
print(root.attrib)
# If the Element object is traversed, the child node of the current Element is obtained, which is equivalent to node ChildNodes
for e in root:
print(e.tag)
# Element can be directly treated as a list. Any word node can be superimposed and directly indexed with numbers
root[0] # Returns the first child node of root
root[0][0] # Returns the first child node of the first child node of root
# Element can use the iter method to iterate over an element with a specified name in all descendants (not limited to children)
print([n.tag for n in root.iter('item')])
# Element.findall() finds only the elements with the specified label in the immediate child elements of the current element.
# Element.find() finds the first child with a specific label,
# Then you can use element Textaccess the text content of the element.
# Element.get access to the attributes of the element:
# The text attribute of Element is to obtain the text content of the current node (excluding child nodes), that is, InnerText
print(root.text)
# Element's findall() can support xpath, and it is the current node without path modification. If path modification is added, the current node must be declared first, that is, the content with path in xpath must be start
print([n.tag for n in root.findall('.//item')])
# ElementTree.SubElement can add child nodes
ET.SubElement(root,newNodeName,{Attribute dictionary})ElementTree After reading, there are several summaries 1,xpath For simple xpath,Not all xpath Support, e.g[name()="item"],In addition to text comparison([.]),Attribute comparison([@])Compare with child nodes([tag])It seems that there are few supported functions, and only one is known at present last() 2,because * As a wildcard, add the first point, ET Regular is not supported xpath 3,text It is only the current node text and does not contain child node text. Although this is a good one, it is not used to it for the time being
2,xml.dom: DOM API definition
After watching for a long time.... This is a base class without any implementation method. Skip. Looking at the description of this document as a whole, it is the same set of things as the browser DOM. It should be very convenient for people who are used to js to use it
3,xml.dom.minidom: minimal DOM implementation
After looking at this part, I found a very simple content. There is nothing to look at except parse and a parseString
Combine XML DOM: the part defined by the DOM API is basically determined. This minidom is a DOM implementation of js long ago. It doesn't say that there is no new gadget such as querySelector. Even getElementById is not implemented, only getelementsbyxxx. Then it is tested with parseString. If the returned html is not standard, it can't be parsed and can't be used as an HTML parser
4,xml.dom.pulldom: supports building partial DOM trees
I don't understand this part for the time being. Pull the parser??? What's this for? After looking at several examples in this section, the general feeling is to support some dom events? Forget it. For collection, you can parse js, xml/xslt and html, but you don't need event support. Skip.
5,xml.sax: SAX2 base class and convenience function
What the hell is this... Direct a = XML sax. Parsestring ('< R / >') actually prompts missing 1 required positive argument: 'handler'. Do you need to provide a handle yourself? Parser? Baidu Baidu...
https://www.cnblogs.com/hongfei/p/python-xml-sax.html , this article provides an example, um... Uh huh... Uh huh... I see. sax is a parsing method that includes partial xsd, partial xslt and serialization structure. We need to provide parsing format (similar to xsd), data reading (similar to xslt) and structured serialization. The specific structured serialization is realized by rewriting the definition of handler. Well, these are very good, but when we collect, Most of the time, you don't look at the specific content of xml, and the reading is also parsed with the xslt specified by xml itself. Therefore, you'd better skip it
6,xml.parsers.expat: expat parser binding
Uh huh.... The first feeling is like a simplified version of sax? Anyway, this is not helpful for collection.
------------------------------
After reading the above introduction about xml, only etree is more suitable for c#, vb's xml processing? In short, first, let's see how python uses xslt to parse xml. We have to continue Baidu. There is no relevant content in this xml package... dizzy
https://www.cnblogs.com/gooseeker/p/5501716.html
Oh, roar...
You have to install a new python package, lxml, okay....
------------------------------
Or with https://www.govinfo.gov/content/pkg/BILLS-117hr3237ih/xml/BILLS-117hr3237ih.xml Take this page as an example. Its xslt style has been given in the declaration. The xslt address is https://www.govinfo.gov/content/pkg/BILLS-117hr3237ih/xml/billres.xsl
Do a simple test to try our first capture and xslt parsing. Take your time. This process is a long process. It's a process of trial and error. In addition, I also advise current students to learn to read tips and learn Baidu, so as to truly self-study and improve themselves. Don't ask and answer so simple questions.
# The first step is to collect our target content. The address is as follows
# https://www.govinfo.gov/content/pkg/BILLS-117hr3237ih/xml/BILLS-117hr3237ih.xml
from urllib import request
xml_doc = request.urlopen('https://www.govinfo.gov/content/pkg/BILLS-117hr3237ih/xml/BILLS-117hr3237ih.xml')
print(xml_doc)
The first step was wrong. Hey, hey, as expected, HTTPError: Forbidden
Why? Because the default request header information is missing too much when using python collection, many websites have basic identification of the request header information. At least, the agent information needs to be looked at. If it starts with php, including spider or bot, or java -, it is directly rejected. Although I didn't look at the default request header in python, However, it is estimated that there is no browser information, so the second step is to forge a user agent
from urllib import request
req = request.Request('https://www.govinfo.gov/content/pkg/BILLS-117hr3237ih/xml/BILLS-117hr3237ih.xml')
req.encoding = 'utf-8'
req.add_header('user-agent', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3870.400 QQBrowser/10.8.4405.400')
xml_str = request.urlopen(req).read()
print(xml_str)It's really easy to collect data in c# python. In the past, Gu used to collect data in c# the collection class alone. He wrote nearly 2000 lines to support various situations. I don't know urllib We will discuss the extent to which the request can achieve later to see the results of this collection..

Well, the collection succeeded.... Here's the question. Is the collected content a string? Is there an additional modifier b on the front edge of the hair?
After several twists and turns, it was found that the regular support was not friendly when the repair character b was used. etree was used to parse this variable and directly report an error. It always prompted that the first row and the first column were not < angle brackets, which was tmd outrageous. Later, I thought, I took it out character by character and reorganized it to make it without b modification
print([n for n in xml_str])
As a result, when traversing this string.... Hmmm. . . It's all numbers, oh! c# byte [] type! This directly shows me as a string and makes me misunderstand.... Plus b modification, it is a binary string! Come on, you know why, it's easy later. I'll decode it directly
xml_str = xml_str.decode(encoding='utf-8') print(xml_str)
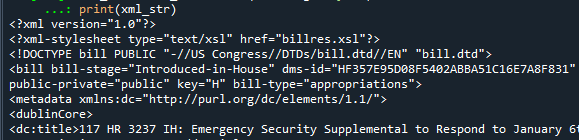
Hey, is that right... This is the xml text content we really collected
Then, the collected content is converted into xml
import lxml.etree as ET xml_doc = ET.XML(xml_str) print(xml_doc)
Um... Is an Element object
print(ET.tostring(xml_doc))
Looks like lxml Etree and XML etree. ElementTree is very similar, except that xpath and xslt support are strengthened, others seem to be similar to XML etree. Elementtrees are consistent. Well, everyone has seen ElementTree before. Blessed are the students who have transferred from c# or vb. They don't have to look at lxml Etree
As it happens, this is a relatively complete xml document. Let's try what xpath can do
....
....
....
xpath doesn't seem to be enhanced? In a rage again, open the definition file and see {site packages \ lxml\_ elementpath. py
Extract the content
if signature == "@-":
# [@attribute] predicate
if signature == "@-='":
# [@attribute='value']
if signature == "-" and not re.match(r"-?\d+$", predicate[0]):
# [tag]
if signature == ".='" or (signature == "-='" and not re.match(r"-?\d+$", predicate[0])):
# [.='value'] or [tag='value']
if signature == "-" or signature == "-()" or signature == "-()-":
# [index] or [last()] or [last()-index]
raise SyntaxError("invalid predicate")
????? What about the agreed enhancement? Isn't that all? Not xpath2 0,xpath1.0 also has many functions and methods. As a result, these packages of python are simply supported by their own XPath, which is not a real XPath at all!!! Forget it, I'm too naive... Continue to collect xml....
print(re.findall('<\?xml[:-]stylesheet.*?href="([^"]+)',xml_str))Since it is an xml file, let's check whether the file specifies an xslt style file. If so, we need to take down the style file and parse the xml itself as xslt
xslt_url = re.sub(r'(?<=[/\\])[^/\\]+$',re.findall('<\?xml[:-]stylesheet.*?href="([^"]+)',xml_str)[0],req.full_url)
print(xslt_url)HMM, then continue to collect this xslt file
req = request.Request(xslt_url)
req.encoding = 'utf-8'
req.add_header('user-agent', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3870.400 QQBrowser/10.8.4405.400')
xsl_str = request.urlopen(req).read()
xsl_str = xsl_str.decode(encoding='utf-8')
xslt_doc = ET.XML(xsl_str)
print(xslt_doc)Good, another normal xml document. Now, try to make it xslt
xsl_parse = ET.XSLT(xslt_doc)
It's an expected error again, but I haven't seen the error prompt. Let's take a look at XSLT parseError: cannot resolve URI string://__STRING__XSLT__/billres-details.xsl

Soga, this xslt file also include s other xslt files. As a result, the collected files are incomplete and not physically saved, so the file cannot be found at the relative address. Then, modify xslt directly_ The relevant content data in str is good, and the xslt is newly generated_ doc
xsl_str = re.sub('(<xsl:include href=")([^"]+)("/>)',r'\1'+re.sub(r'(?<=[/\\])[^/\\]+$','',req.full_url)+r'\2\3',xsl_str)
xslt_doc = ET.XML(xsl_str)
print(xslt_doc)
xsl_parse = ET.XSLT(xslt_doc)An error is also reported: XSLT parseError: cannot resolve URI https://www.govinfo.gov/content/pkg/BILLS-117hr3237ih/xml/billres-details.xsl

Hmmmm..... The URI cannot be resolved. It is the same as the error just now, except that the address is different, Hmmm Well, if it's not in the same folder, he can't load it automatically. In another way, download the relevant xslt files into the same folder, and then try loading again. Hmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmm.... It's hard to learn a new language.
OK, let's reset the code to just get the xml content. The code is as follows
import lxml.etree as ET
from urllib import request
req = request.Request('https://www.govinfo.gov/content/pkg/BILLS-117hr3237ih/xml/BILLS-117hr3237ih.xml')
req.encoding = 'utf-8'
req.add_header('user-agent', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3870.400 QQBrowser/10.8.4405.400')
xml_str = request.urlopen(req).read()
xml_str = xml_str.decode(encoding='utf-8')
xml_doc = ET.XML(xml_str)
Then, use regular to obtain all xslt files from xml. Well, record the uri address of the xml to calculate the location of the xslt file. Otherwise, you won't be able to collect it
base_url = re.sub(r'(?<=[/\\])[^/\\]+$','',req.full_url)
xslt_url = re.findall('<\?xml[:-]stylesheet.*?href="([^"]+)',xml_str)
xslt_first = xslt_url[0]Because we are not sure whether there are other xslt files nested in xslt, we use an array to represent the xslt file and record the xslt entry file
if os.path.exists(r'D:\\work\\Log\\' + xslt_first)==False: # If the entry xslt file does not exist
while len(xslt_url)>0: # If the list of xlst files to be collected is not empty
fn = xslt_url.pop(0) # Assign fn to the current collection xslt file name and remove it from the list
url = base_url + fn # Calculate the real uri of xslt
req_xslt = request.Request(url)
req_xslt.encoding = 'utf-8'
req_xslt.add_header('user-agent', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3870.400 QQBrowser/10.8.4405.400')
xsl_str = request.urlopen(req_xslt).read()
xsl_str = xsl_str.decode(encoding='utf-8') # Get xslt file contents
f = open(r'D:\\work\\Log\\'+fn,'w+',encoding='utf-8') # Open files with the same name in the temporary folder as overwrite write
f.write(xsl_str) # Write xslt information
f.close()
xslt_url += re.findall(r'(?<=xsl:include href=")([^"]+)',xsl_str) # If other xslt files are introduced into the current xslt file, they will be added to the list to be downloadedUh huh. In this way, we downloaded three xslt files. In addition to the one that reported an error before, we also added a table xsl
For the last step, let's do a magic trick to turn xml into html~~~~
xslt_doc = ET.parse(r'D:\\work\\Log\\' + xslt_first) xsl_parse = ET.XSLT(xslt_doc) result = xsl_parse(xml_doc) print(result)
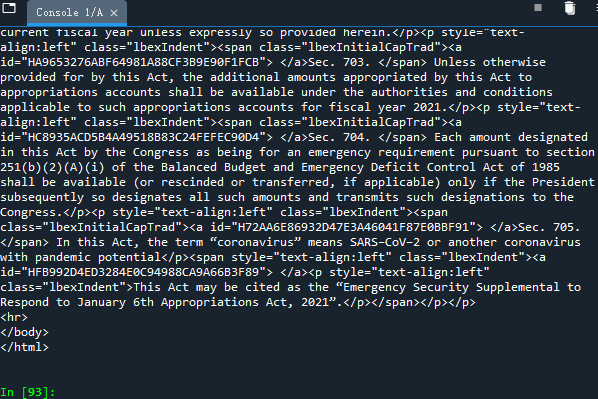
so, our first collection attempt, xml and xslt parsing attempt, and file reading and writing attempt are completed. Congratulations.
---------------------------------
Postscript: this blog post is difficult to give birth, because Lao Gu usually works normally and takes time to study. I hope you can put forward some opinions.
Notice: the next article encapsulates a collection class to inherit the collected information, forge header information, etc., and prepare for formal collection.