Seata distributed transaction framework is widely used in the company, including four distributed transaction modes: AT, TCC, SAGA and XA. In fact, like TX-LCN framework, it can be said to be a variant of 2PC distributed transaction model, and its working principle is also similar. It is worth mentioning that the AT mode of Seata framework can save rollback data, However, the TX-LCN framework is not so intelligent, so most companies now use the Seata framework.
There are too many contents in this blog. You can first look at the theoretical part, and the actual part of the code. You can directly use the last shared source code to run locally, and then understand the simple use.
Seata principle
Official document address
This blog comes from my thinking and summary of the explanation of this framework in the official website documents. I also read many other people's blogs.
http://seata.io/zh-cn/docs/overview/what-is-seata.html
Main components of the Seata framework
The components of Seata and TX-LCN frameworks are easy to be confused. It is best for everyone to understand this part and distinguish the two frameworks.
- TC (Transaction Coordinator) - Transaction Coordinator
Maintain the status of global and branch transactions and drive global transaction commit or rollback. [TM] transaction manager equivalent to TX-LCN. - TM (Transaction Manager) - transaction manager
Define the scope of global transaction: start global transaction, commit or roll back global transaction. It can be understood as the initiator of the transaction.
In my opinion, the reason why the Seata framework regards the transaction initiator as the transaction manager is that the transaction initiator has the ability to create transaction groups and commit or rollback global transactions. - RM (Resource Manager) - Resource Manager
Manage the resources of branch transaction processing, have the ability to register branch transactions with TC and report the status of branch transactions, and drive branch transaction submission or rollback.
Seata workflow
I won't show the schematic diagram of Seata. It can be said that it is the same as the schematic diagram of TX-LCN. If you are interested, you can have a look [explanation of distributed transaction - TX-LNC distributed transaction framework (including LCN, TCC and TXC modes)] This blog.
- The transaction manager initiates a transaction, starts a global transaction with the transaction coordinator, and registers a branch transaction with the transaction coordinator.
- The [transaction manager] calls [resource manager A]. The [resource manager A] registers A new branch transaction with the [Transaction Coordinator]. The [resource manager A] executes the business and returns the execution result to the [transaction manager].
- [resource manager A] calls [Resource Manager B], and [Resource Manager B] registers A new branch transaction with [Transaction Coordinator], and [Resource Manager B] executes the business and returns the execution result to [transaction manager].
- When all branch transactions called by the transaction manager are executed and receive all feedback information, the transaction manager will send a notice to the transaction coordinator indicating that all branch transactions are executed.
- The transaction coordinator sends commit or rollback instructions to all resource managers in turn according to the execution of branch transactions sent by the transaction manager.
- End of distributed transaction.
Global and branch transactions
In the Seata framework, transactions are divided into global transactions and branch transactions. Because of the cooperation of global transaction locks and branch transaction locks, the problems of "dirty read" and "dirty write" in AT mode are solved.
Global transaction
The Seata framework has an annotation @ GlobalTransactional. All methods with this annotation in a system belong to a common global transaction. These methods share a global transaction lock when executing. The same global transaction needs to comply with the read-write isolation mechanism of AT mode.
Branch transaction (local transaction)
In global transactions, there will be methods to call other resource managers. Each method is a branch transaction. The same method belongs to the same branch transaction, and the same branch transaction uses the same branch transaction lock.
AT mode (Automatic Transaction)
This transaction mode is relatively simple to use. We don't need to implement the rollback logic of the transaction by ourselves. We only need to implement the branch transaction logic, and reduce the time occupied by the database connection.
The workflow of AT mode is based on the Seata framework:
- The transaction manager initiates a transaction, starts a global transaction with the transaction coordinator, and registers a branch transaction with the transaction coordinator.
- The [transaction manager] calls [resource manager A]. The [resource manager A] registers A new branch transaction with the [Transaction Coordinator]. The [resource manager A] executes the local transaction SQL, submits the transaction and saves the rollback log, releases the local occupied resources, and returns the execution result to the [transaction manager].
- [resource manager A] calls [Resource Manager B], and [Resource Manager B] registers A new branch transaction with [Transaction Coordinator], and [Resource Manager B] executes the local transaction SQL, submits the transaction and saves the rollback log, releases the occupation of local resources, and returns the execution result to [transaction manager].
- When all branch transactions called by the transaction manager are executed and receive all feedback information, the transaction manager will send a notice to the transaction coordinator indicating that all branch transactions are executed.
- The transaction coordinator sends commit or rollback instructions to all resource managers in turn according to the execution of branch transactions sent by the transaction manager. If the branch transaction receives a commit instruction, only delete the rollback log; If the rollback command is received, execute the rollback log and delete the log. If there is a difference between the current data and the modified data in the rollback log, keep the rollback log and other manual processing.
- End of distributed transaction.
Visible from the process:
- The sql is committed in the branch transaction execution stage, which reduces the time occupied by the database connection, releases the resources of local transactions, and improves the transaction execution efficiency.
- The rollback log is kept in the branch transaction execution stage, so that developers do not care about the logic of transaction failure rollback. If the transaction fails, the framework directly executes the records of the corresponding branch transaction in the corresponding rollback log table for transaction rollback.
Rollback log details
{
// Branch id
"branchId": 641789253,
"undoItems": [{
// Modified information
"afterImage": {
"rows": [{
"fields": [{
"name": "id",
"type": 4,
"value": 1
}, {
"name": "name",
"type": 12,
"value": "GTS"
}, {
"name": "since",
"type": 12,
"value": "2014"
}]
}],
"tableName": "product"
},
// Information before modification
"beforeImage": {
"rows": [{
"fields": [{
"name": "id",
"type": 4,
"value": 1
}, {
"name": "name",
"type": 12,
"value": "TXC"
}, {
"name": "since",
"type": 12,
"value": "2014"
}]
}],
// Database table name
"tableName": "product"
},
// sql execution type
"sqlType": "UPDATE"
}],
// Global transaction id
"xid": "xid:xxx"
}
The rollback log saves the data before and after modification, which is used for the automatic rollback operation. During the rollback operation, the rollback log will be determined jointly according to the branch transaction id and the global transaction id, and the modified information in the rollback log will be compared with the current data information in the database. If there is a difference, it indicates that the data has been modified, then the rollback fails, Keep the rollback log and wait for manual processing.
Write isolation
In order to prevent "dirty write" in AT mode, a [write isolation] mechanism is added.
principle
- Two different threads (thread A and thread B) enter the same branch transaction to execute the same business. At this time, it is necessary to ensure that the two threads do not have dirty writing. The two threads belong to the same global transaction.
- Thread A obtains the local transaction lock first and executes the business, but does not commit the transaction.
- Thread A registers branch transactions, obtains the global transaction lock, and submits local transactions.
- Thread A releases the local lock, but other services are not executed, and the global transaction lock is still not released.
- After the local transaction lock is released, thread B can execute the business and will not commit the transaction after execution.
- Thread B registers branch transactions, but the global lock is still occupied by thread A, an exception will be thrown and the retry mechanism will be enabled. If the retry timeout still does not get the global transaction lock, thread B will execute the rollback operation and the overall transaction of thread B will end.
- Thread A executes all services, submits them successfully, and releases the global lock.
- Thread B retries successfully to obtain the global lock, submits the executed services, and releases the global lock after all services are executed and submitted successfully.
- Using local transaction locks can reduce the resource occupation of database connections.
If there is no local transaction lock, multiple threads will occupy database connection resources, and OOM may occur when the number reaches the threshold. - Using global transaction lock can ensure that the same business is not operated at the same time, and can ensure the normal submission and rollback of the whole distributed transaction.
If there is no global transaction lock, there will be an error in thread A. when rolling back the transaction, it is found that the data to be rolled back has been modified by thread B, resulting in the failure to roll back the transaction normally.
Read isolation
In order to prevent "dirty reading" in AT mode, the [read isolation] mechanism is added.
principle
Seata agent selects for update. When you want to execute the select for update statement, you will have the following process:
- Obtain the local transaction lock and execute select for update.
- If the method is modified by the @ GlobalTransactional annotation, check whether the global transaction lock can be obtained.
- If the global transaction lock is occupied, roll back the local transaction and retry to go back to the local transaction lock and global lock until the global lock is released and obtained.
It can be seen from the principle that when using select for update for query, it will wait until the global transaction lock is released, just like the write isolation mechanism. This method also avoids dirty reading.
Analysis of official website quotations
The official website said, "the AT mode is based on a relational database that supports local ACID transactions". What is the reason? I've been thinking about this for a long time. Both online and official websites have made brief descriptions, but the descriptions have been brought in one stroke, which makes people who don't understand it still don't understand. I think so:
- The AT pattern is based on a relational database that supports local transactions.
- In order to realize [read isolation] and [write isolation] in AT mode, it is necessary to support databases that cannot automatically submit and execute sql, because these two isolation principles are realized by obtaining the global transaction lock before transaction submission, but databases that do not support local transactions automatically submit after executing sql, which is not applicable to these two isolation, This will not solve the [dirty read] and [dirty write] problems.
Therefore, according to the above two points, I think the distributed transaction database using AT mode must support transactions locally.
Code demonstration
Create database and table information
-- ------------------seata-server Database and table information start------------------------------------ CREATE DATABASE seata-server; SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for branch_table -- ---------------------------- DROP TABLE IF EXISTS `branch_table`; CREATE TABLE `branch_table` ( `branch_id` bigint(20) NOT NULL, `xid` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `transaction_id` bigint(20) NULL DEFAULT NULL, `resource_group_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `resource_id` varchar(256) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `branch_type` varchar(8) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `status` tinyint(4) NULL DEFAULT NULL, `client_id` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `application_data` varchar(2000) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `gmt_create` datetime(6) NULL DEFAULT NULL, `gmt_modified` datetime(6) NULL DEFAULT NULL, PRIMARY KEY (`branch_id`) USING BTREE, INDEX `idx_xid`(`xid`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; -- ---------------------------- -- Table structure for global_table -- ---------------------------- DROP TABLE IF EXISTS `global_table`; CREATE TABLE `global_table` ( `xid` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `transaction_id` bigint(20) NULL DEFAULT NULL, `status` tinyint(4) NOT NULL, `application_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `transaction_service_group` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `transaction_name` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `timeout` int(11) NULL DEFAULT NULL, `begin_time` bigint(20) NULL DEFAULT NULL, `application_data` varchar(2000) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `gmt_create` datetime(0) NULL DEFAULT NULL, `gmt_modified` datetime(0) NULL DEFAULT NULL, PRIMARY KEY (`xid`) USING BTREE, INDEX `idx_gmt_modified_status`(`gmt_modified`, `status`) USING BTREE, INDEX `idx_transaction_id`(`transaction_id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; -- ---------------------------- -- Table structure for lock_table -- ---------------------------- DROP TABLE IF EXISTS `lock_table`; CREATE TABLE `lock_table` ( `row_key` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `xid` varchar(96) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `transaction_id` bigint(20) NULL DEFAULT NULL, `branch_id` bigint(20) NOT NULL, `resource_id` varchar(256) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `table_name` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `pk` varchar(36) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `gmt_create` datetime(0) NULL DEFAULT NULL, `gmt_modified` datetime(0) NULL DEFAULT NULL, PRIMARY KEY (`row_key`) USING BTREE, INDEX `idx_branch_id`(`branch_id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; SET FOREIGN_KEY_CHECKS = 1; -- ------------------seata-server Database and table information end-------------------------------------- -- ------------------seata-tm Database and table information start-------------------------------------- CREATE DATABASE seata-tm; SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for tm -- ---------------------------- DROP TABLE IF EXISTS `tm`; CREATE TABLE `tm` ( `id` int(16) NOT NULL AUTO_INCREMENT, `name` varchar(16) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 40 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; -- ---------------------------- -- Table structure for undo_log -- ---------------------------- DROP TABLE IF EXISTS `undo_log`; CREATE TABLE `undo_log` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `branch_id` bigint(20) NOT NULL, `xid` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `context` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `rollback_info` longblob NOT NULL, `log_status` int(11) NOT NULL, `log_created` datetime(0) NOT NULL, `log_modified` datetime(0) NOT NULL, `ext` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, UNIQUE INDEX `ux_undo_log`(`xid`, `branch_id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 47 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; SET FOREIGN_KEY_CHECKS = 1; -- ------------------seata-tm Database and table information end-------------------------------------- -- ------------------seata-rm-one Database and table information start-------------------------------------- CREATE DATABASE seata-rm-one; SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for rm_one -- ---------------------------- DROP TABLE IF EXISTS `rm_one`; CREATE TABLE `rm_one` ( `id` int(16) NOT NULL AUTO_INCREMENT, `name` varchar(16) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 35 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; -- ---------------------------- -- Table structure for undo_log -- ---------------------------- DROP TABLE IF EXISTS `undo_log`; CREATE TABLE `undo_log` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `branch_id` bigint(20) NOT NULL, `xid` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `context` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `rollback_info` longblob NOT NULL, `log_status` int(11) NOT NULL, `log_created` datetime(0) NOT NULL, `log_modified` datetime(0) NOT NULL, `ext` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, UNIQUE INDEX `ux_undo_log`(`xid`, `branch_id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 55 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; SET FOREIGN_KEY_CHECKS = 1; -- ------------------seata-rm-one Database and table information end-------------------------------------- -- ------------------seata-rm-two Database and table information start-------------------------------------- CREATE DATABASE seata-rm-two; SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for rm_two -- ---------------------------- DROP TABLE IF EXISTS `rm_two`; CREATE TABLE `rm_two` ( `id` int(16) NOT NULL AUTO_INCREMENT, `name` varchar(16) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 31 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; -- ---------------------------- -- Table structure for undo_log -- ---------------------------- DROP TABLE IF EXISTS `undo_log`; CREATE TABLE `undo_log` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `branch_id` bigint(20) NOT NULL, `xid` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `context` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `rollback_info` longblob NOT NULL, `log_status` int(11) NOT NULL, `log_created` datetime(0) NOT NULL, `log_modified` datetime(0) NOT NULL, `ext` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, UNIQUE INDEX `ux_undo_log`(`xid`, `branch_id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 41 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; SET FOREIGN_KEY_CHECKS = 1; -- ------------------seata-rm-two Database and table information end--------------------------------------
New Eureka server project
eureka is the basis of our actual Seate. TC, TM and RM must register into eureka server.
For the project construction of eureka, you can see [the way to build complete components of Spring Cloud Eureka] This blog has a detailed explanation.
Configure TC Transaction Coordinator
To put it bluntly, the transaction coordinator is a service program provided by the Seata framework, a management platform like RabbitMQ.
Download Seata server
Just select the latest version
http://seata.io/zh-cn/blog/download.html
Configure Seata server
After downloading and decompressing, open the following directory:
Open registry The conf file modifies the configuration, and the file is finally modified as:
registry {
# file ,nacos ,eureka,redis,zk,consul,etcd3,sofa
# modify
type = "eureka"
nacos {
serverAddr = "localhost"
namespace = ""
cluster = "default"
}
# modify
eureka {
# Address of Eureka server
serviceUrl = "http://euk-server-one.com:7900/eureka/"
# Register the service name of Eureka server
application = "seata-server"
# Weight, not required
weight = "1"
}
redis {
serverAddr = "localhost:6379"
db = "0"
}
zk {
cluster = "default"
serverAddr = "127.0.0.1:2181"
session.timeout = 6000
connect.timeout = 2000
}
consul {
cluster = "default"
serverAddr = "127.0.0.1:8500"
}
etcd3 {
cluster = "default"
serverAddr = "http://localhost:2379"
}
sofa {
serverAddr = "127.0.0.1:9603"
application = "default"
region = "DEFAULT_ZONE"
datacenter = "DefaultDataCenter"
cluster = "default"
group = "SEATA_GROUP"
addressWaitTime = "3000"
}
file {
name = "file.conf"
}
}
# Configuration center
# If type=file, from local file Get configuration parameters from conf, config File is loaded only when type=file Configuration parameters in conf
config {
# file,nacos ,apollo,zk,consul,etcd3
type = "file"
nacos {
serverAddr = "localhost"
namespace = ""
}
consul {
serverAddr = "127.0.0.1:8500"
}
apollo {
app.id = "seata-server"
apollo.meta = "http://192.168.1.204:8801"
}
zk {
serverAddr = "127.0.0.1:2181"
session.timeout = 6000
connect.timeout = 2000
}
etcd3 {
serverAddr = "http://localhost:2379"
}
# View the contents of the name attribute value file
file {
name = "file.conf"
}
}
Open file The conf file modifies the configuration, and the file is finally modified as:
service {
#transaction service group mapping
#Modify point 1
vgroup_mapping.my_tx_group = "seata-server"
disableGlobalTransaction = true
}
## transaction log store, only used in seata-server
store {
## store mode: file,db
# modify
mode = "db"
## file store property
file {
## store location dir
dir = "sessionStore"
}
## database store property
#modify
db {
datasource = "druid"
db-type = "mysql"
# A new database driver is required
driver-class-name = "com.mysql.cj.jdbc.Driver"
# Configure database link information
url = "jdbc:mysql://127.0.0.1:3306/seata-server?useUnicode=true&useSSL=false&characterEncoding=utf8&serverTimezone=Asia/Shanghai"
user = "root"
password = "wk3515134"
}
}
Database driver storage address:
I will attach the code warehouse address at the back of the blog, which is the same as the screenshot location.
Start Seata server
Perform the following procedure:
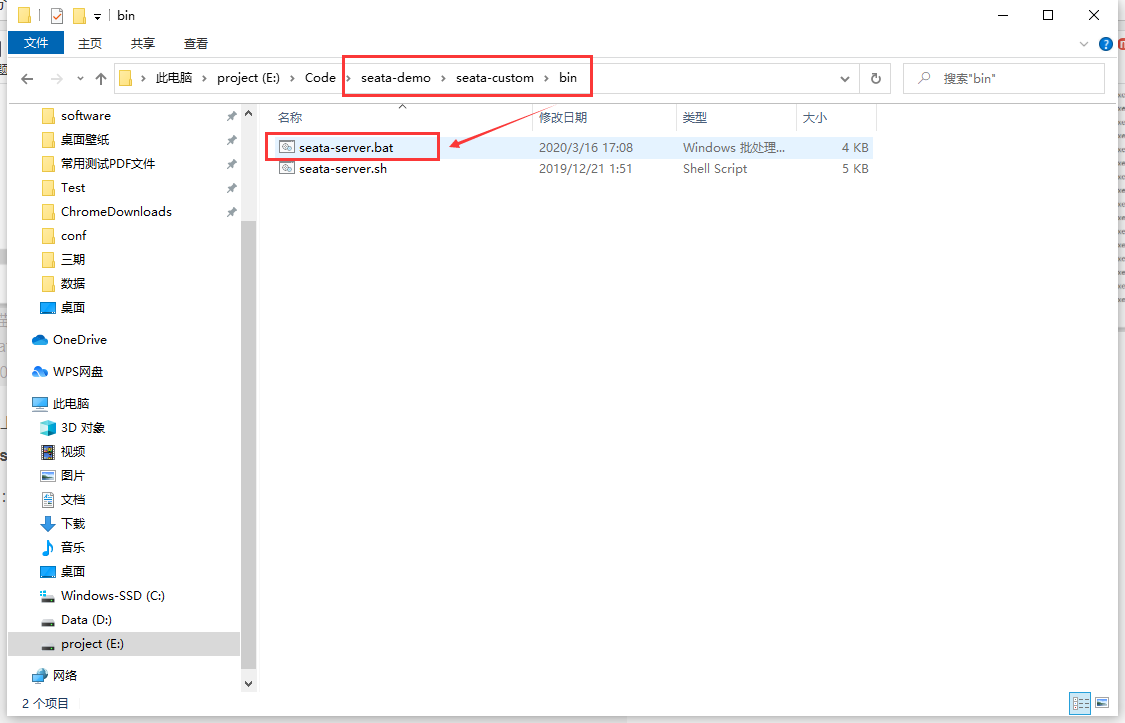
Create TM transaction manager (Seata TM)
Create an empty Spring Boot project
Add dependency
<!-- Entity class Data Annotation required dependencies -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- allow web Access required dependencies -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- eureka Client required dependencies -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- mysql:MyBatis Correlation dependency -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.0.0</version>
</dependency>
<!-- mysql:mysql drive -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!-- mysql:Alibaba database connection pool -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.12</version>
</dependency>
<!-- seata Required dependencies -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-seata</artifactId>
<version>2.2.0.RELEASE</version>
</dependency>
Note that there was a problem with the spring boot version when introducing TM dependencies. You can always connect to the TC. You can add these dependencies and configure them yourself first. If not, look at the Seata actual combat source code I attached at the end.
Modify the configuration file (application.yml)
There are four main steps in the configuration file:
- Configure boot port
- Configure the transaction grouping information, which is the same as the file of Seata server Vgroup of conf configuration file_ mapping. my_ tx_ The group attribute has the same value.
- Configure database connection information
- Configure the Eureka server address to be registered
- Configure the mapper scan path of the project
server:
port: 1001
spring:
cloud:
alibaba:
seata:
tx-service-group: my_tx_group
application:
name: seata-tm
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/seata-tm?characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: root
password: wk3515134
dbcp2:
initial-size: 5
min-idle: 5
max-total: 5
max-wait-millis: 200
validation-query: SELECT 1
test-while-idle: true
test-on-borrow: false
test-on-return: false
mybatis:
mapper-locations:
- classpath:mapper/*.xml
eureka:
client:
service-url:
defaultZone: http://euk-server-one.com:7900/eureka/
Start class add Bean
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
Create test Controller class (TmController)
The methods in this class are the starting point of the whole distributed transaction.
Note the @ GlobalTransactional annotation, combined with the theoretical part of AT mode I explained above.
@RestController
public class TmController {
@Autowired
TmService tmService;
@GetMapping("/tm")
@GlobalTransactional(rollbackFor = Exception.class)
public String tm() throws InterruptedException {
tmService.tm();
// TimeUnit.MINUTES.sleep(1);
// System.out.println(1/0);
return "success";
}
}
Create test Service class (TmService)
Add the logic of using restTemplate to call the distributed system in the service class.
I won't explain the Mapper class and entity class in detail. You don't need to write it yourself.
/**
* @author yueyi2019
*/
@Service
public class TmService {
@Autowired
TmDao mapper;
public String tm() {
Tm o = new Tm();
o.setId(1);
o.setName("tm");
mapper.insertSelective(o);
rm1();
rm2();
return "";
}
@Autowired
private RestTemplate restTemplate;
private void rm1() {
restTemplate.getForEntity("http://seata-rm-one/rm1", null);
}
private void rm2() {
restTemplate.getForEntity("http://seata-rm-two/rm2", null);
}
}
Add conf file
registry. The conf file is actually the registry when configuring TC Conf file, file The conf file contains the retry information of undo log, TM retry times and rm. If these two files are not added, TM will fail to register in TC until it times out.
Add the following files under the resources path of the code:
Add registry conf
registry {
# file ,nacos ,eureka,redis,zk,consul,etcd3,sofa
type = "eureka"
nacos {
serverAddr = "localhost"
namespace = ""
cluster = "default"
}
eureka {
serviceUrl = "http://euk-server-one.com:7900/eureka/"
# Modification point
application = "seata-server"
weight = "1"
}
redis {
serverAddr = "localhost:6379"
db = "0"
}
zk {
cluster = "default"
serverAddr = "127.0.0.1:2181"
session.timeout = 6000
connect.timeout = 2000
}
consul {
cluster = "default"
serverAddr = "127.0.0.1:8500"
}
etcd3 {
cluster = "default"
serverAddr = "http://localhost:2379"
}
sofa {
serverAddr = "127.0.0.1:9603"
application = "default"
region = "DEFAULT_ZONE"
datacenter = "DefaultDataCenter"
cluster = "default"
group = "SEATA_GROUP"
addressWaitTime = "3000"
}
file {
name = "file.conf"
}
}
config {
# file,nacos ,apollo,zk,consul,etcd3
type = "file"
nacos {
serverAddr = "localhost"
namespace = ""
}
consul {
serverAddr = "127.0.0.1:8500"
}
apollo {
app.id = "seata-server"
apollo.meta = "http://192.168.1.204:8801"
}
zk {
serverAddr = "127.0.0.1:2181"
session.timeout = 6000
connect.timeout = 2000
}
etcd3 {
serverAddr = "http://localhost:2379"
}
file {
name = "file.conf"
}
}
Add Filey conf
service {
vgroup_mapping.my_tx_group="seata-server"
disableGlobalTransaction = false
}
client {
rm {
async.commit.buffer.limit = 10000
lock {
retry.internal = 10
retry.times = 30
retry.policy.branch-rollback-on-conflict = true
}
report.retry.count = 5
table.meta.check.enable = false
report.success.enable = true
}
tm {
commit.retry.count = 5
rollback.retry.count = 5
}
undo {
data.validation = true
log.serialization = "jackson"
log.table = "undo_log"
}
log {
exceptionRate = 100
}
support {
# auto proxy the DataSource bean
spring.datasource.autoproxy = false
}
}
Create RM Resource Manager (RM one, RM two)
The creation process of RM one and RM two projects is the same, the port of the configuration file cannot be the same, and the code logic can also be written on demand.
Create an empty Spring Boot project
Add dependency
RM also needs seata, jdbc, Eureka client and other dependencies. The content is the same as the added TM dependency.
Modify profile
In addition to port information and database connection information, other contents can use TM.
Start class add Bean
Same as TM configuration
Create test Controller classes (RmOneController, RmTwoController)
Just follow the creation process when writing projects. As an AT mode RM, there are no special requirements.
Add conf file
The file can directly use the registry configured in TM Conf file and file Conf file
Code execution test
Distributed transaction executed successfully
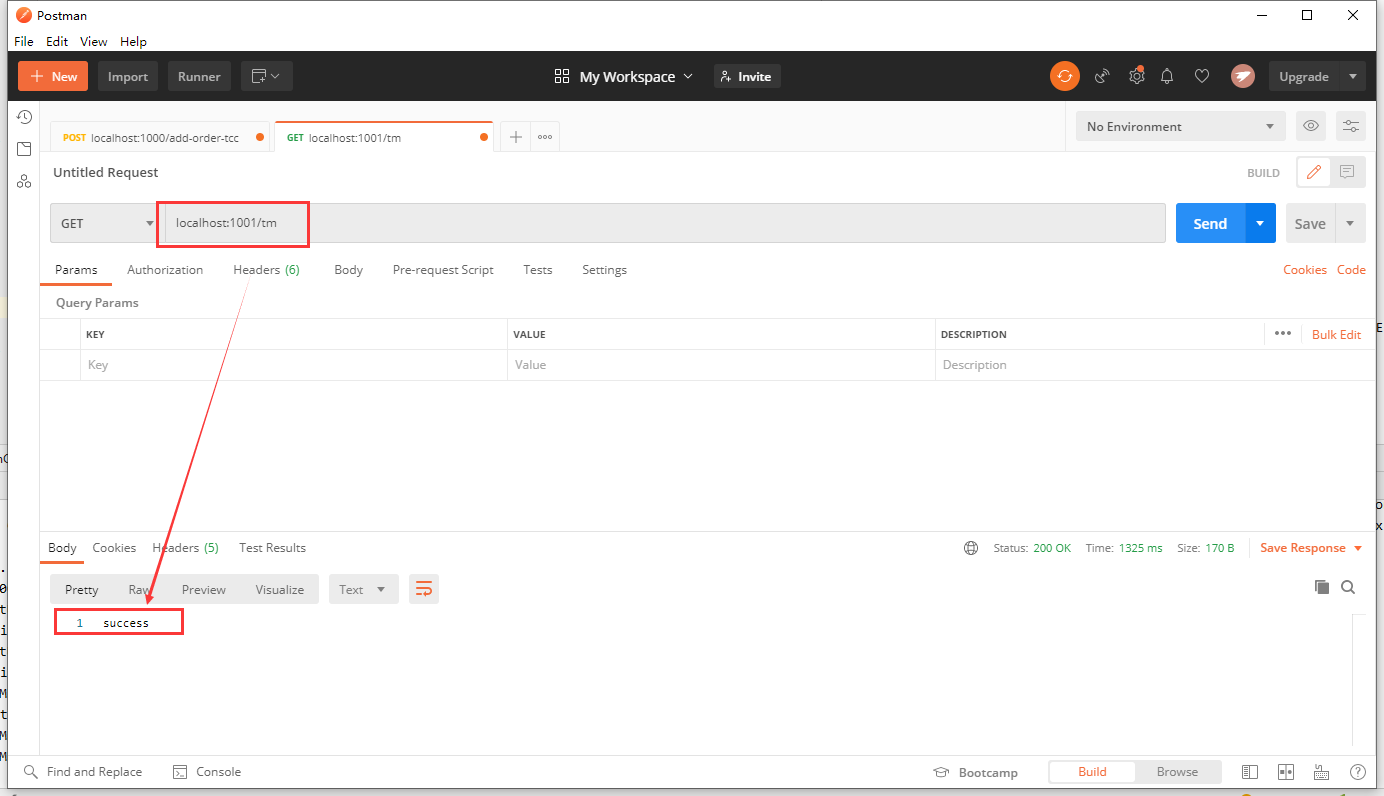
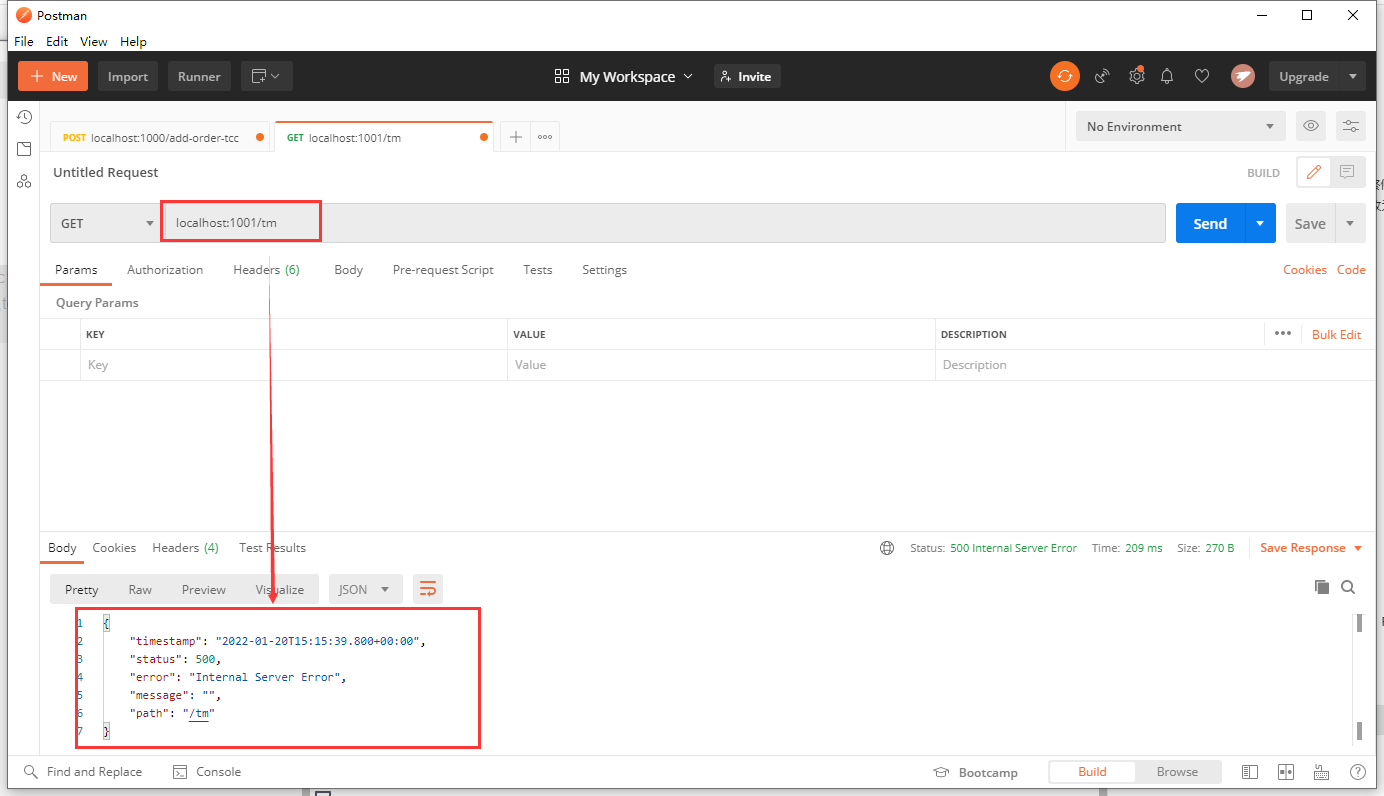
Distributed transaction execution failed
Add an exception to any business.
Finally, it will be found that the information in the table does not change after an error is reported.
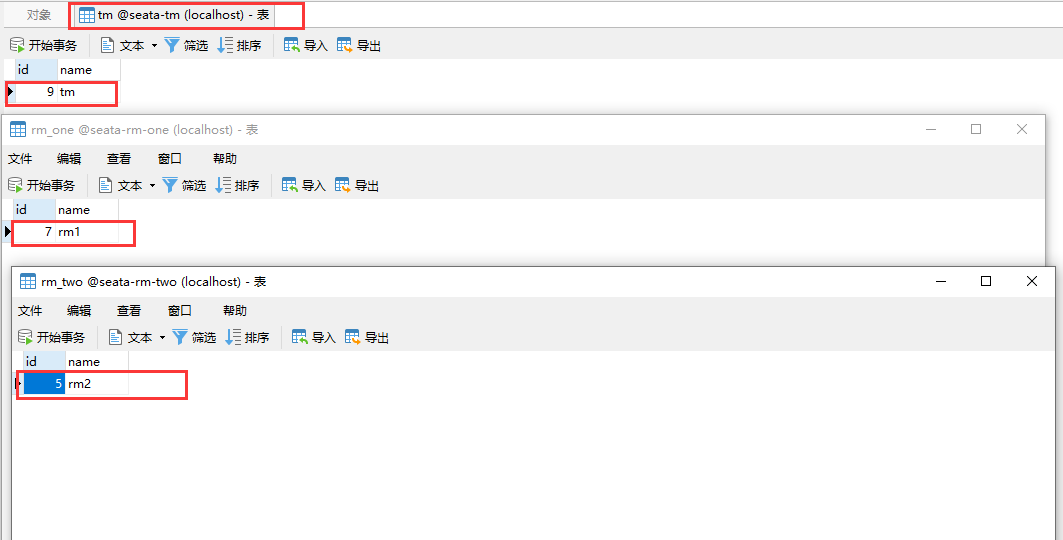
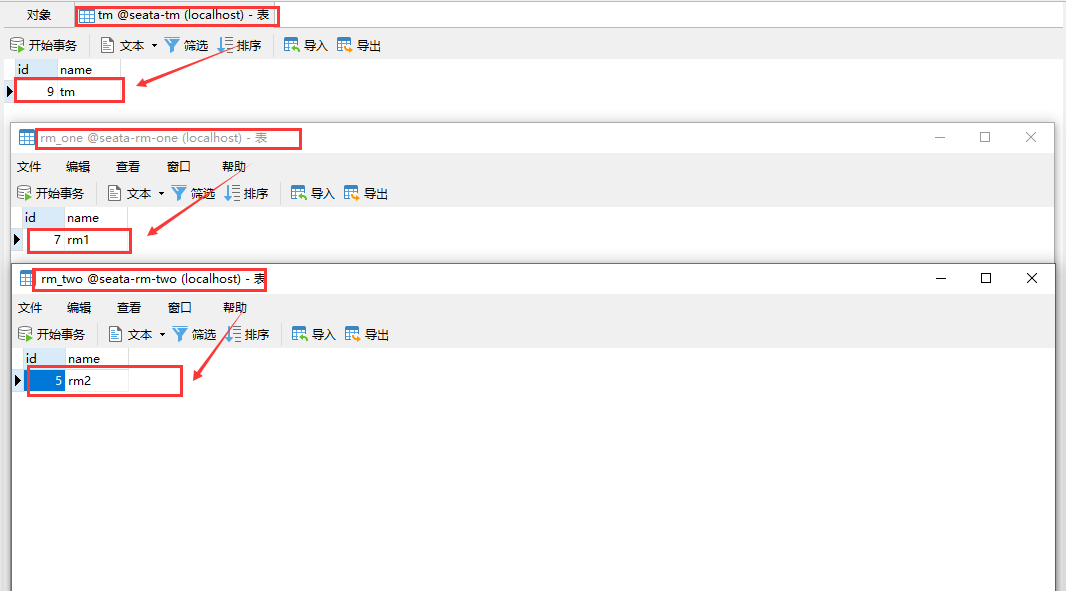
Test the role of other tables in the database
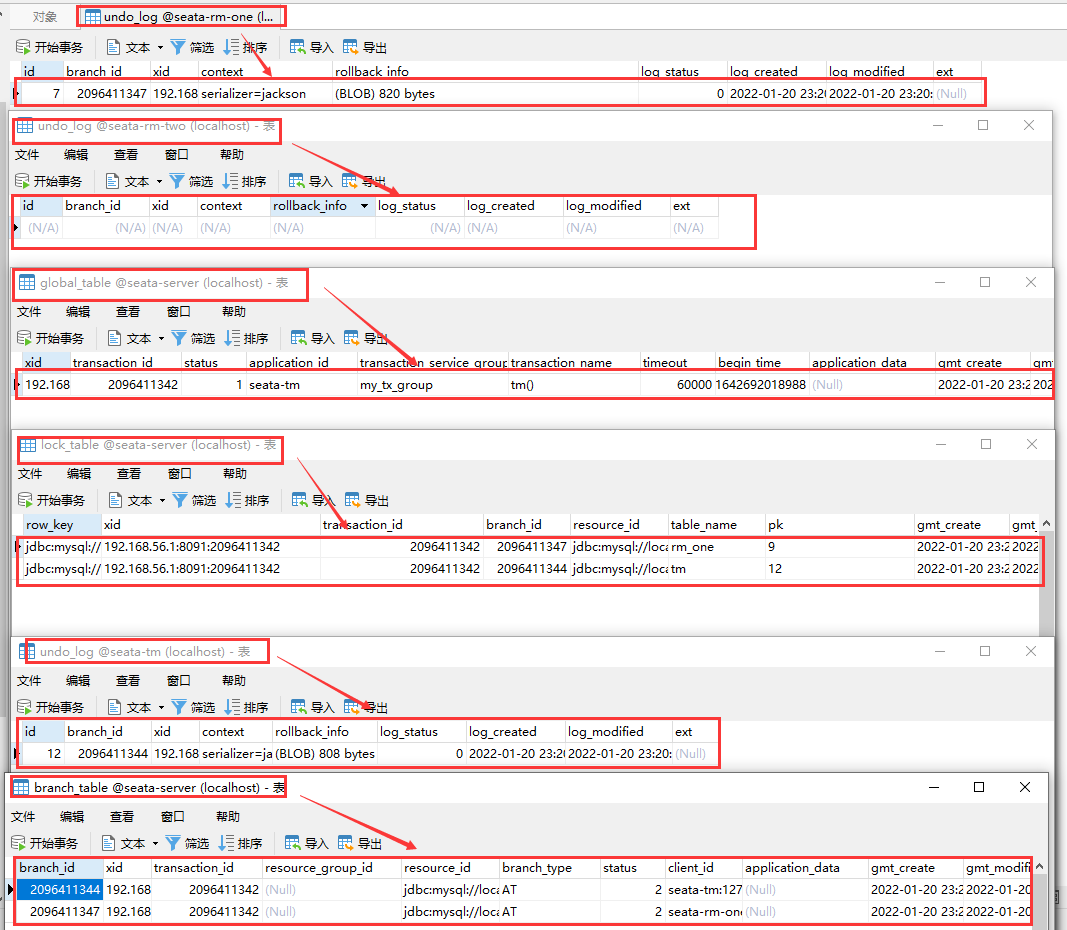
Make a breakpoint in Debug mode.
It can be seen that from top to bottom in the screenshot are:
- RM one rollback log table.
- RM two rolls back the log table (because RM two is not executed, there is no log).
- Global transaction table of Seata server.
- In the branch transaction lock table of Seata server, two branch transaction locks are occupied by RM one and tm respectively.
- tm rollback log table.
- The branch transaction table of Seata server indicates that there are two branch transactions under the global transaction to execute tm and RM one tasks respectively.
TCC mode (Try Cancel Confirm)
The main process of TCC mode is similar to that of AT mode. In the process, it can be seen that TCC mode is not as convenient as AT mode.
TCC mode workflow:
- The transaction manager initiates a transaction, starts a global transaction with the transaction coordinator, and registers a branch transaction with the transaction coordinator.
- The [transaction manager] calls [resource manager A]. The [resource manager A] registers A new branch transaction with the [Transaction Coordinator]. The [resource manager A] calls the try method to execute the local transaction and commit the transaction, releases the locally occupied resources, and returns the execution result to the [transaction manager].
- The [transaction manager] calls [Resource Manager B]. The [Resource Manager B] registers a new branch transaction with the [Transaction Coordinator]. The [Resource Manager B] calls the try method to execute the local transaction and commit the transaction, releases the locally occupied resources, and returns the execution result to the [transaction manager].
- After the [transaction manager] receives the results returned by all the [resource manager] executing local transactions, it will send a rollback or submission request to the [Transaction Coordinator] according to the results. If it is a rollback request, it will call the cancel method of each [resource manager], and if it is a submission request, it will call the confirm method.
In the process, if the rollback log is not kept when executing sql, the logic of the try, cancel and confirm methods of the TCC mode must be implemented by the developers themselves. The TCC mode of the framework only provides us with a mechanism for distributed transaction callback cancel and confirm. The logic after the callback is implemented by ourselves.
TCC mode exception
Empty rollback problem
The scenario of this problem is that when the try method execution times out, TC has sent a rollback instruction, that is, cancel starts to execute before the try method is executed. If this problem occurs, it will cause data inconsistency.
Scenario simulation
Scenario simulation:
- The try method subtracts the number a by 1.
- If the cancel method indicates that the try fails, add 1 to the number a.
- The confirm method indicates that the try is successful and the logic is executed after success (generally do nothing).
Imagine if try cancel s before it is finished. What are the consequences? a adds 1 directly without subtraction. If this happens in the transfer business, we can see the importance of this problem.
Solution
Add a transaction control table, add a new record when executing a try, update the execution status after executing cancel or confirm, and save the current execution status of branch transactions under each global transaction. You can use 1, 2 and 3 to represent try, cancel and confirm respectively. In this way, before executing cancel, you can query the current status according to the current global transaction id and branch transaction id, Only the try state agrees to execute the cancel method. Otherwise, the logic in the cancel method body will not be executed.
I have a simple design for this table field:
- global_tx_id (global transaction id)
- branch_tx_id (branch transaction id)
- state (transaction execution status, identification bit: number, enumeration type)
Idempotent problem
The scenario of this problem is that because the Seata framework has a retry mechanism, it will execute cancel and confirm multiple times.
Idempotent interpretation
[idempotent] that is, if I execute the try method once, the corresponding cancel or confirm method will be executed once. In this way, there will be a return. One operation corresponds to another operation, which is [idempotent]. If a try operation corresponds to other cancel operations multiple times, it violates idempotency.
Solution
The same as the solution of empty rollback problem, a transaction control table with the current transaction status can solve the problem.
Suspension problem
The scenario of this problem is that the try method has very complex business logic and is always blocked. When the timeout threshold of TM has been reached, the rollback command will be executed. After the rollback, the try method blocking ends and the subsequent logic of the try method will continue to be executed, that is, cancel is executed before try.
Solution
Based on the solutions of [empty rollback problem] and [idempotent problem], a new data will be added to the [transaction control table] only when the try is executed. However, when the [suspension problem] cancels, the [transaction control table] does not have the execution status of the current transaction. Therefore, when we execute the cancel method, if we find that the current transaction is not stored in the table, It means that a suspension problem occurs, so the business logic in the cancel method is not executed, and finally a new piece of data in the cancel status is added to enter the transaction control table.
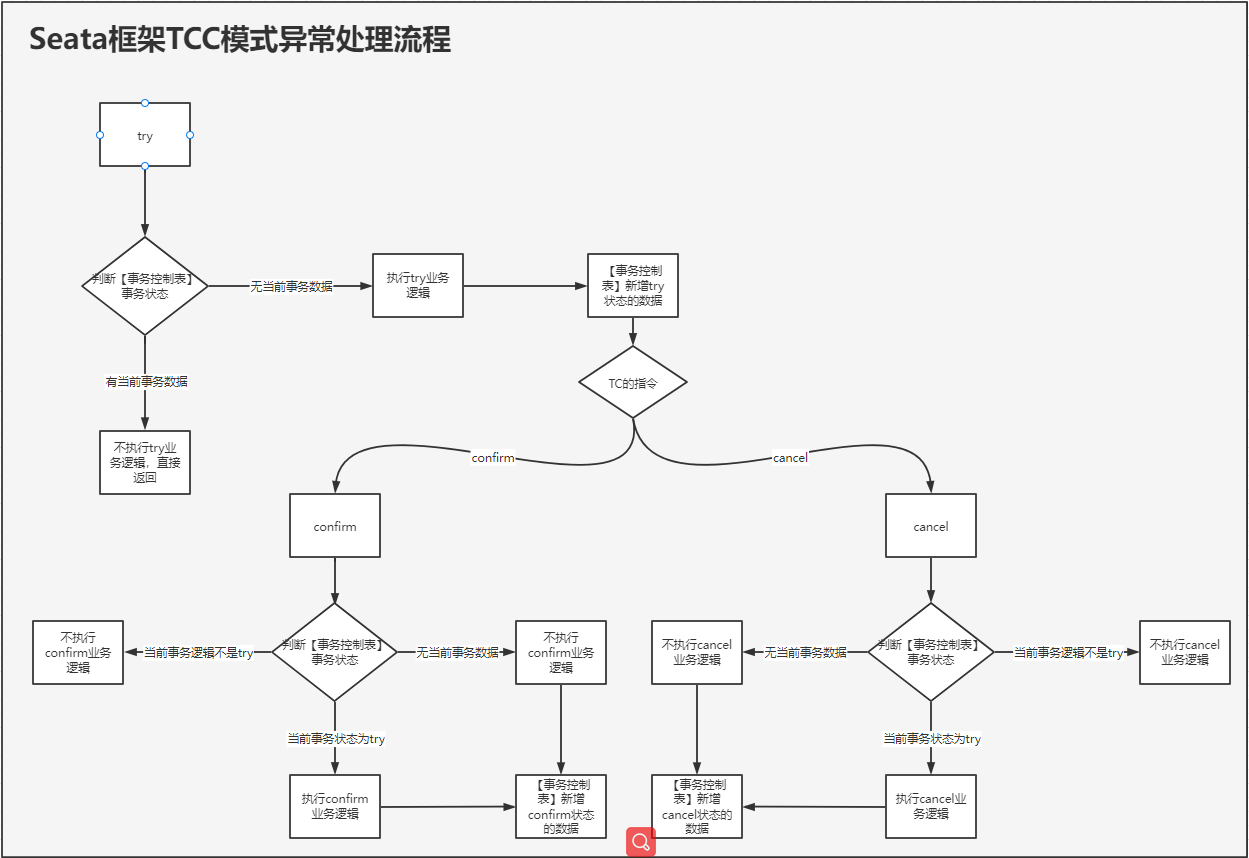
TCC mode exception summary
These three exceptions can be perfectly solved according to a [transaction control table]. Next, I will add an exception handling logic diagram drawn by myself:
Analysis of official website quotations
The TCC mode does not depend on the transaction support of the underlying data resources
- Because the TCC mode of the framework does not support automatic rollback and commit, and all business logic is implemented by developers, it supports any distributed transaction.
- There is no read isolation and write isolation mechanism in the TCC mode, and the official is also smart. We won't write or say no, because TCC supports databases that don't support transactions, such as the MyIsam engine of Mysql. This basically can't control the submission of transactions and realize isolation.
- Because try, confirm and cancel are logic written by developers themselves, they can support whatever they write. TCC mode is the first choice for scenarios that are simply business oriented and do not operate the database, as well as scenarios that do not support local transactions.
The so-called TCC mode refers to the support of bringing custom branch transactions into the management of global transactions
Corresponding to Article 3 of the previous quote, the user-defined distributed transaction is the advantage of TCC mode and the disadvantage of TCC mode.
Code demonstration
Based on the AT mode code, the TCC mode actual combat code is written
TM transaction manager (Seata TM)
Add TCC test method (TmController) to Controller test class
@Autowired
private TmInterface tmInterface;
@GetMapping("/tm-tcc")
@GlobalTransactional(rollbackFor = Exception.class)
public String tmTcc() throws InterruptedException {
tmInterface.tm(null);
return "success";
}
Note the global transaction annotation of the method
Added TCC test Service interface class (TmInterface)
@LocalTCC
public interface TmInterface {
@TwoPhaseBusinessAction(name = "tmTccAction" ,
commitMethod = "tmCommit" ,
rollbackMethod = "tmRollback")
public String tm(BusinessActionContext businessActionContext);
public boolean tmCommit(BusinessActionContext businessActionContext);
public boolean tmRollback(BusinessActionContext businessActionContext);
}
- Note the @ LocalTCC annotation of the class.
- tm method, as a try method, adds TwoPhaseBusinessAction annotation on tm(), in which the name attribute value can be filled in as needed without requirements; The value of the commitMethod attribute is the name of the method to be called after the TC sends the confirm instruction; The value of the rollbackMethod attribute is the name of the method to be called after the TC sends the cancel instruction.
New TCC test Service implementation class (TmInterface)
@Component
public class TmInterfaceImpl implements TmInterface {
@Override
@Transactional
public String tm(BusinessActionContext businessActionContext) {
// Query is a transaction record table, xxxx
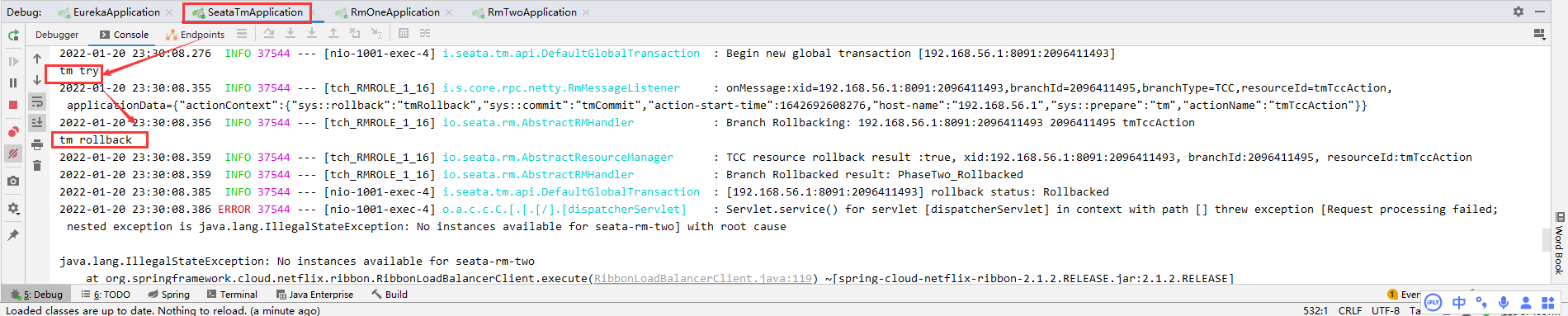
System.out.println("tm try");
rm1();
rm2();
return null;
}
@Override
@Transactional
public boolean tmCommit(BusinessActionContext businessActionContext) {
System.out.println("tm confirm");
return true;
}
@Override
@Transactional
public boolean tmRollback(BusinessActionContext businessActionContext) {
System.out.println("tm rollback");
return true;
}
@Autowired
private RestTemplate restTemplate;
private void rm1() {
restTemplate.getForEntity("http://seata-rm-one/rm1-tcc", null);
}
private void rm2() {
restTemplate.getForEntity("http://seata-rm-two/rm2-tcc", null);
}
}
Use RestTemplate to call methods of other services.
RM Resource Manager (RM one, RM two)
Controller test class addition method
@Autowired
private RmOneInterface rmOneInterface;
@GetMapping("/rm1-tcc")
@GlobalTransactional(rollbackFor = Exception.class)
public String oneTcc(){
rmOneInterface.rm1(null);
return "success";
}
Note the @ GlobalTransactional annotation
Add TCC mode test Service interface class
@LocalTCC
public interface RmOneInterface {
@TwoPhaseBusinessAction(name = "tmTccAction" , commitMethod = "tmCommit" ,rollbackMethod = "tmRollback")
public String rm1(BusinessActionContext businessActionContext);
public boolean tmCommit(BusinessActionContext businessActionContext);
public boolean tmRollback(BusinessActionContext businessActionContext);
}
The interface class configuration is the same as that of TM
Added TCC mode test Service implementation class
@Component
public class RmOneInterfaceImpl implements RmOneInterface {
@Override
@Transactional
public String rm1(BusinessActionContext businessActionContext) {
System.out.println("rm1 try");
return null;
}
@Override
@Transactional
public boolean tmCommit(BusinessActionContext businessActionContext) {
System.out.println("rm1 confirm");
return true;
}
@Override
@Transactional
public boolean tmRollback(BusinessActionContext businessActionContext) {
System.out.println("rm1 rollback");
return true;
}
}
It is the same as the implementation class configuration of TM
Code execution test
Distributed transaction executed successfully
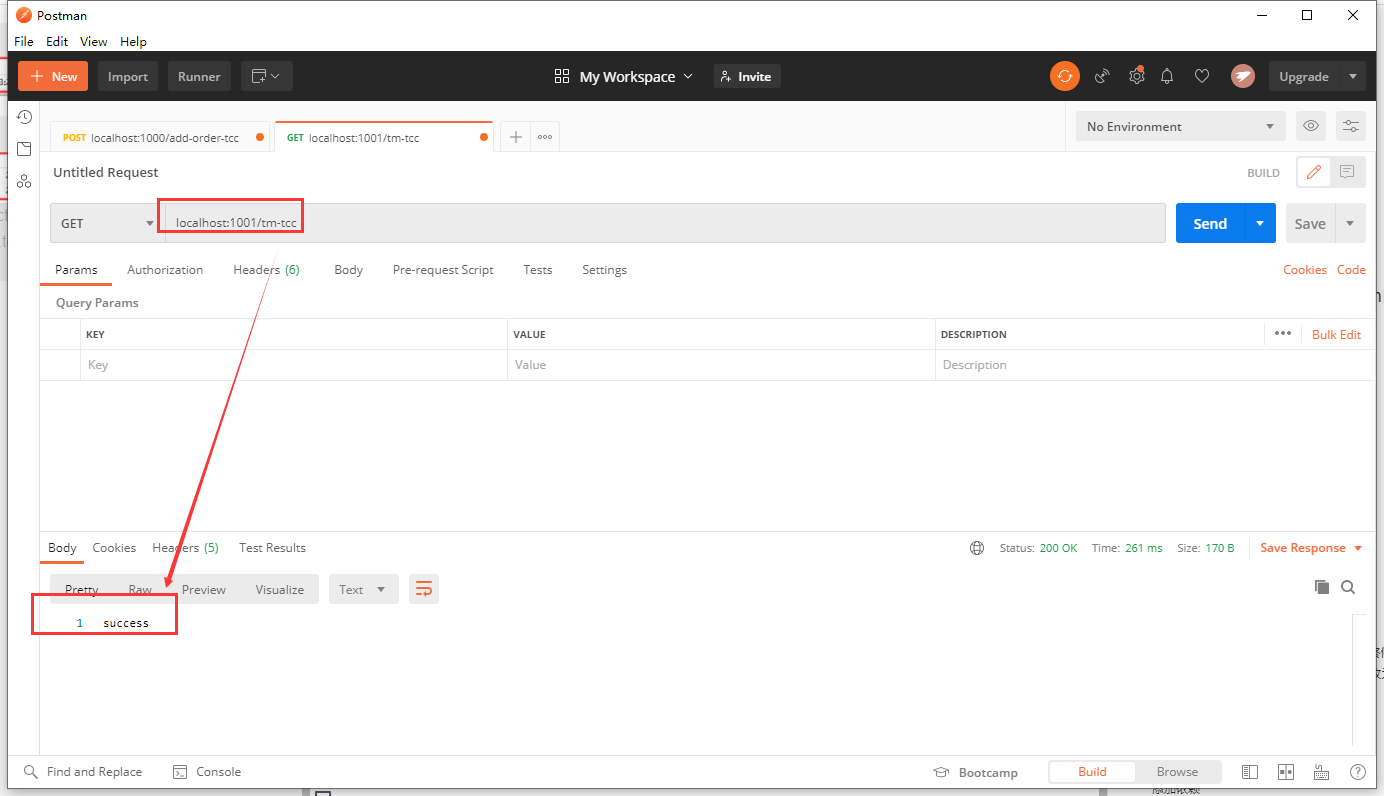



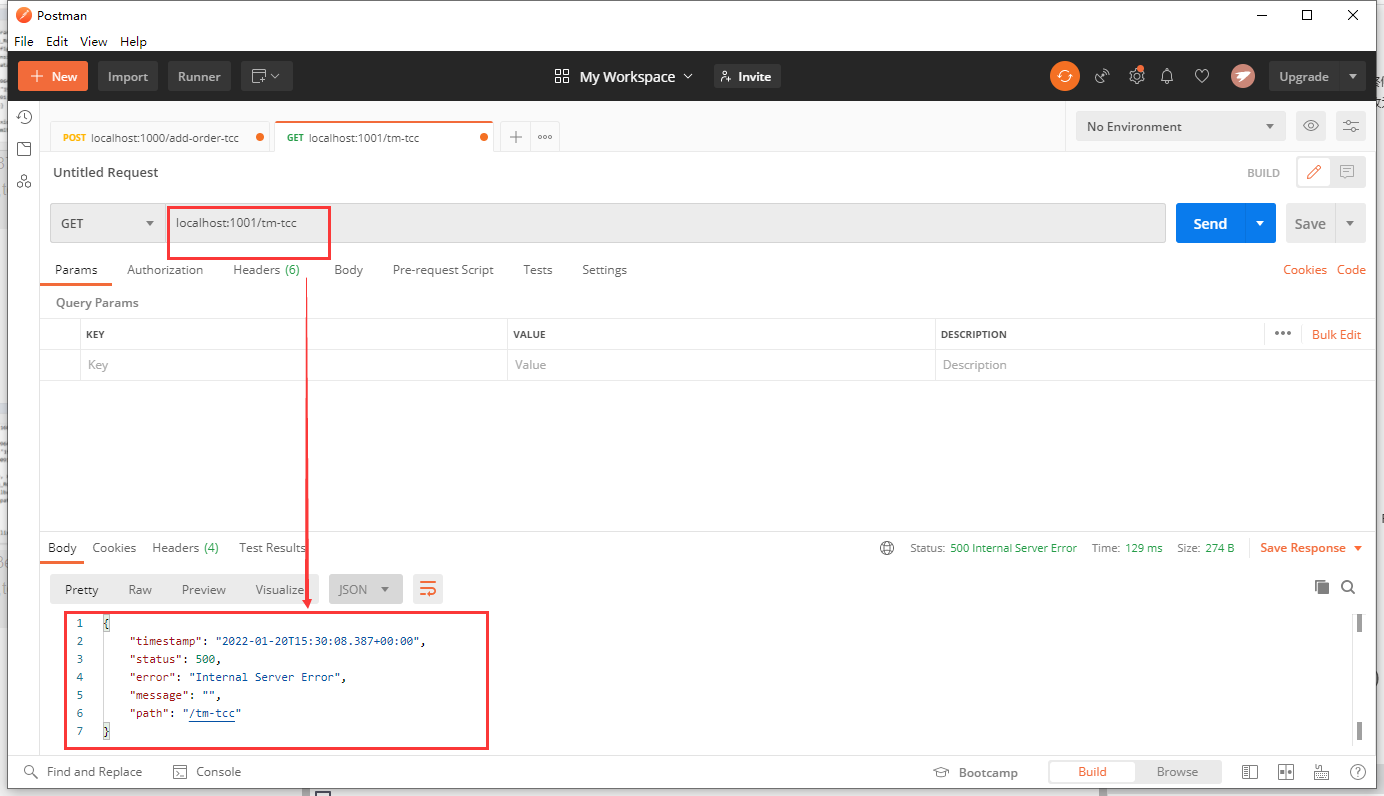
Distributed transaction execution failed
Shut down the RM two system.