Welcome to "Python from zero to one", where I will share about 200 Python series articles, take you to learn and play, and see the interesting world of Python. All articles will be explained in combination with cases, codes and the author's experience. I really want to share my nearly ten years of programming experience with you. I hope it will be helpful to you. Please forgive me for the shortcomings in the article. The overall framework of Python series includes 10 basic grammars, 30 web crawlers, 10 visual analysis, 20 machine learning, 20 big data analysis, 30 image recognition, 40 artificial intelligence, 20 Python security and 10 other skills. Your attention, praise and forwarding are the greatest support for xiuzhang. Knowledge is priceless and people are affectionate. I hope we can all be happy and grow together on the road of life.
The previous article described Selenium's basic technology, including basic introduction, element positioning, common methods and attributes, mouse operation, keyboard operation and navigation control. This paper will conduct in-depth analysis combined with specific examples. Through three crawlers based on Selenium technology, we will climb Wikipedia, Baidu Encyclopedia and Interactive Encyclopedia message box, and learn and use them from practical application. Basic articles, hope to help you.
Online encyclopedia is a dynamic, free, freely accessible and editable multilingual encyclopedia based on Wiki technology 0 knowledge base system. It is an open and largest user generated knowledge base in the Internet, and has the advantages of wide coverage of knowledge, high degree of structure, fast information update speed and good openness. The three widely used online encyclopedias include Wikipedia, Baidu Encyclopedia and Interactive Encyclopedia.
Download address:
Previous appreciation:
Part I basic grammar
- [Python from zero to one] one Why should we learn Python and basic syntax
- [Python from zero to one] two Conditional statements, circular statements and functions based on grammar
- [Python from zero to one] three Syntax based file operation, CSV file reading and writing and object-oriented
Part II web crawler
- [Python from zero to one] four Introduction to web crawler and regular expression blog case
- [Python from zero to one] five Detailed explanation of the basic grammar of the web crawler beautiful soup
- [Python from zero to one] six Detailed explanation of the top 250 movie of BeautifulSoup crawling watercress
- [Python from zero to one] seven Web crawler Requests crawls Douban movie TOP250 and CSV storage
- [Python from zero to one] eight Basic knowledge and operation of MySQL database
- [Python from zero to one] nine Detailed explanation of Selenium basic technology of web crawler (positioning elements, common methods, keyboard and mouse operation)
- [Python from zero to one] ten Selenium crawls online encyclopedia knowledge in ten thousand words (necessary skills for NLP corpus construction)
The author's new "Na Zhang AI security house" will focus on Python and security technology, and mainly share articles such as Web penetration, system security, artificial intelligence, big data analysis, image recognition, malicious code detection, CVE reproduction, threat intelligence analysis, etc. Although the author is a technical white, I will ensure that every article will be written carefully. I hope these basic articles will help you and make progress with you on the Python and security road.
I Three online encyclopedias
With the rapid development of the Internet and big data, we need to mine valuable information from massive information. In the process of collecting these massive information, it usually involves the capture and construction of bottom-level data, such as multi-source knowledge base fusion, knowledge map construction, computing engine construction, etc. Among them, representative knowledge map applications include Knowledge Graph of Google, Graph Search launched by Facebook, baidu Zhixin of Baidu, Sogou zhicube of Sogou, etc. The technologies of these applications may be different, but the same thing is that they all use online encyclopedia knowledge such as Wikipedia, Baidu Encyclopedia and Interactive Encyclopedia in the construction process. So this chapter will teach you to crawl these three online encyclopedias respectively.
Encyclopedia refers to the general term of knowledge of astronomy, geography, nature, humanities, religion, belief, literature and other disciplines. It can be comprehensive and include relevant contents in all fields; It can also be professional oriented. Next, we will introduce three common online encyclopedias, which are one of the important corpora for information extraction research.
1.Wikipedia
“Wikipedia is a free online encyclopedia with the aim to allow anyone to edit articles.” This is the official introduction of Wikipedia. Wikipedia is a multilingual encyclopedia collaboration project based on Wiki technology, an online encyclopedia written in multiple languages. The word "Wikipedia" comes from the new mixed word "Wikipedia" created by the core technology "wiki" of the website and "Encyclopedia", which can be edited by anyone.
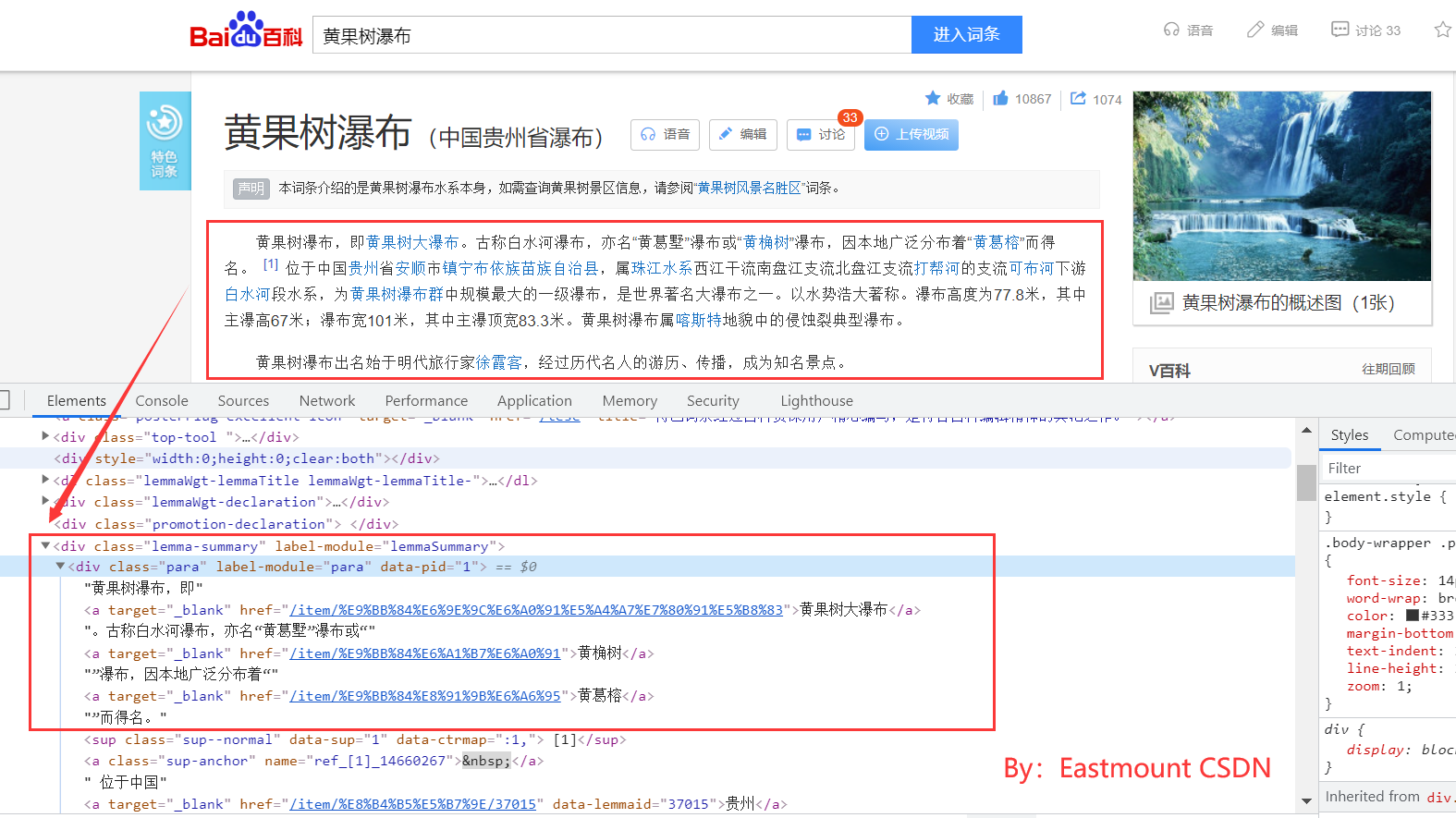
Among all online encyclopedias, Wikipedia has the best accuracy and structure, but Wikipedia mainly focuses on English knowledge and involves little Chinese knowledge. Online encyclopedia pages usually include: Title, Description, InfoBox, Categories, cross language links, etc. The Chinese page information of the entity "Huangguoshu waterfall" in Wikipedia is shown in Figure 1.
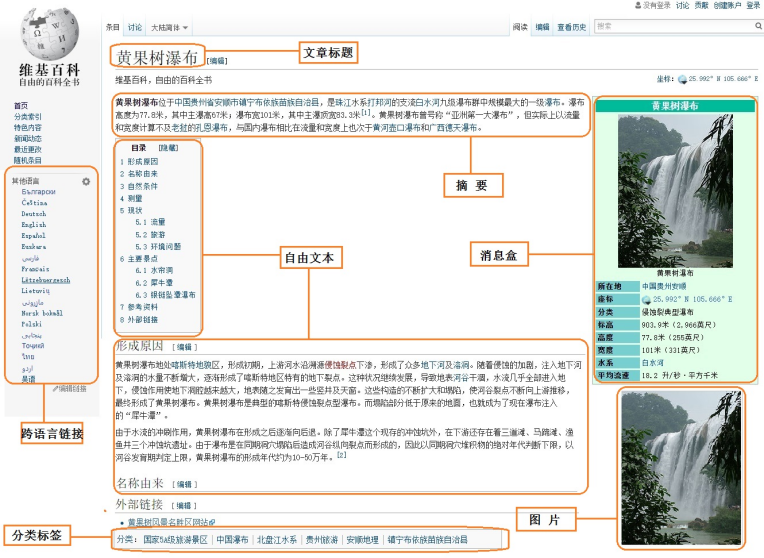
The Wikipedia information shown in Figure 1 mainly includes:
- Article Title: uniquely identifies an article (except for ambiguous pages), that is, it corresponds to an entity and the "Huangguoshu waterfall" in the figure.
- Abstract: it is of great value to describe the whole article or the whole entity through one or two paragraphs of concise information.
- Free Text: Free Text includes full text content and partial text content. The content of this full text is to describe all text information of the whole article, including summary information and information introduction of each part. Part of the text content is part of the text information describing an article, which can be extracted by users.
- Category Label: used to identify the type of the article. As shown in the figure, "Huangguoshu waterfall" includes "national 5A scenic spot", "China waterfall", "Guizhou tourism", etc.
- InfoBox: also known as information module or information box. It presents web page information in a structured form, which is used to describe the attribute and attribute value information of articles or entities. The message box contains a certain number of "attribute attribute value" pairs, which gather the core information of the article to represent the whole web page or entity.
2. Baidu Encyclopedia
Baidu Encyclopedia is an open and free online encyclopedia platform launched by Baidu company. As of April 2017, Baidu Encyclopedia has collected more than 14.32 million entries, and more than 6.1 million netizens have participated in entry editing, covering almost all known knowledge fields. Baidu Encyclopedia aims to create a Chinese information collection platform covering all fields of knowledge. Baidu Encyclopedia emphasizes the participation and dedication of users, fully mobilize the strength of Internet users, gather the minds and wisdom of users, and actively communicate and share. At the same time, Baidu Encyclopedia realizes the combination with Baidu search and Baidu know, and meets the needs of users for information from different levels.
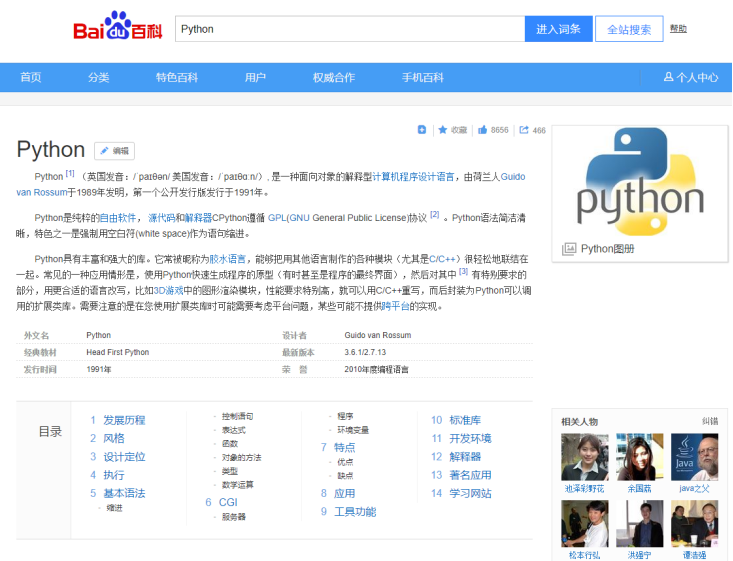
Compared with Wikipedia, Baidu Encyclopedia contains the most Chinese knowledge, but the accuracy is relatively poor. Baidu Encyclopedia page also includes: Title, Description, InfoBox, Categories, cross language links, etc. Figure 2 shows Baidu Encyclopedia's "Python" web page knowledge. The message box of the web page is the middle part and adopts the form of key value pair. For example, the value corresponding to "foreign name" is "Python" and the value corresponding to "classic textbook" is "Head First Python".
3. Interactive Encyclopedia
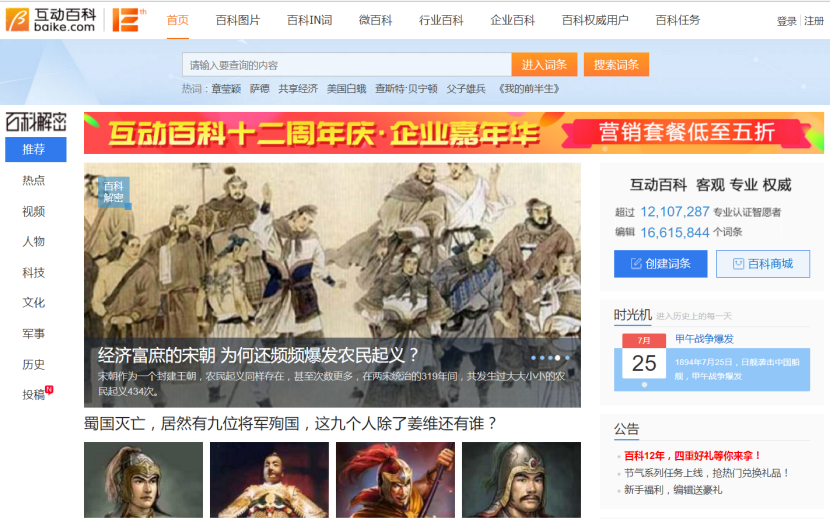
Interactive Encyclopedia (www.baike.com) is the pioneer and leader of Chinese encyclopedia website. It is committed to providing hundreds of millions of Chinese users with massive, comprehensive and timely encyclopedia information free of charge, and continuously improving the way users create, obtain and share information through a new wiki platform. By the end of 2016, Interactive Encyclopedia had developed into an encyclopedia website with 16 million entries, 20 million pictures and 50000 micro encyclopedias jointly built by more than 11 million users. New media covered more than 10 million people and mobile APP users exceeded 20 million.
Compared with Baidu Encyclopedia, Interactive Encyclopedia has higher accuracy, better structure and higher quality of knowledge in professional fields, so researchers usually choose Interactive Encyclopedia as one of the main corpora. Figure 3 shows the home page of the Interactive Encyclopedia.
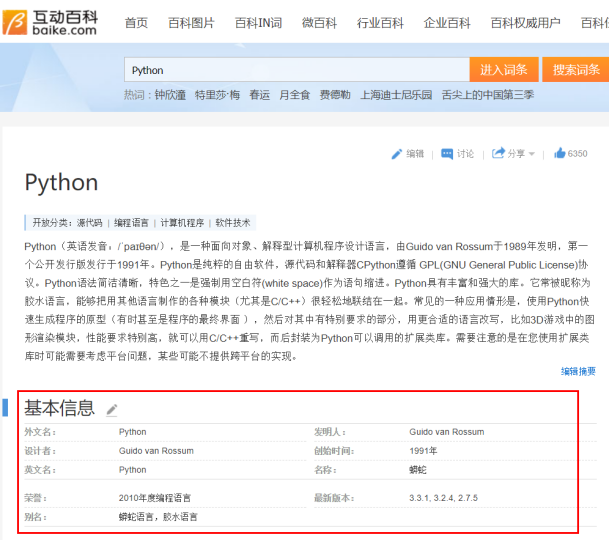
The information of Interactive Encyclopedia is stored in two forms: one is the structured information box in the encyclopedia, and the other is the free text of the encyclopedia text. For entries in Encyclopedia, only a few entries contain structured information boxes, but all entries contain free text. The information box is used to display the entry information in a structured way. A typical example of encyclopedia information box is shown in Figure 4, which shows the InfoBox information of Python in the form of key value pairs. For example, the "designer" of Python is "Guido van Rossum".
The following will explain how Selenium technology crawls the message boxes of the three online encyclopedias. The analysis methods of the three encyclopedias are slightly different. Wikipedia first obtains the links of G20 countries from the list page, and then carries out web page analysis and information crawling in turn; Baidu Encyclopedia calls Selenium for automatic operation, enters the names of various programming languages, and then accesses, locates and crawls; The Interactive Encyclopedia analyzes the link url of the web page, and then goes to different scenic spots for analysis and information capture.
II Selenium crawls Baidu Encyclopedia knowledge
As the largest Chinese online encyclopedia or Chinese knowledge platform, Baidu Encyclopedia provides knowledge from all walks of life for researchers to engage in all aspects of research. Although the accuracy of entries is not the best, it can still provide a good knowledge platform for scholars engaged in data mining, knowledge atlas, natural language processing, big data and other fields.
1. Web page analysis
This section will explain in detail the example of Selenium crawling Baidu Encyclopedia message box. The theme of crawling is 10 national 5A scenic spots, in which the list of scenic spots is defined in the TXT file, and then directional crawling of their message box information. The core steps of web page analysis are as follows:
(1) Call Selenium to automatically search Baidu Encyclopedia keywords
First, call Selenium technology to visit the home page of Baidu Encyclopedia at“ https://baike.baidu.com ”, figure 5 shows the homepage of Baidu Encyclopedia, with a search box at the top. Enter relevant entries such as "Forbidden City", and click "enter entry" to get the details of the entries of the Forbidden City.
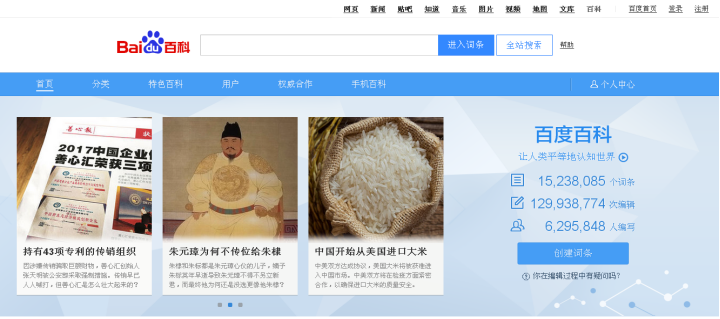
Then, select the "enter entry" button in the browser and right-click the "review element" to view the HTML source code corresponding to the button, as shown in Figure 6. Note that different browsers view web controls or content with different names corresponding to the source code. In the figure, 360 security browser is used, called "review element", Chrome browser is called "check", QQ browser is called "check", etc.
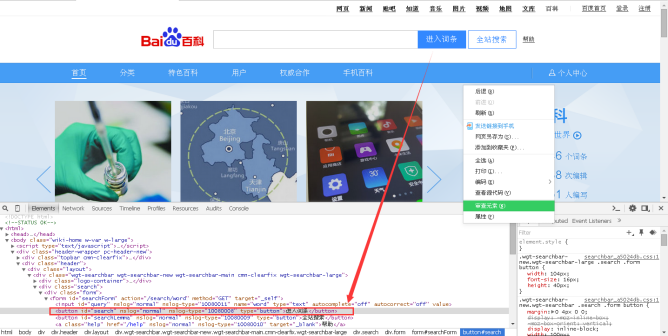
The HTML core code corresponding to "entry" is as follows:
<div class="form"> <form id="searchForm" action="/search/word" method="GET"> <input id="query" nslog="normal" name="word" type="text" autocomplete="off" autocorrect="off" value=""> <button id="search" nslog="normal" type="button"> Enter entry </button> <button id="searchLemma" nslog="normal" type="button"> Total station search </button> <a class="help" href="/help" nslog="normal" target="_blank"> help </a> </form> ... </div>
The Selenium function is called to get the input control of the input box.
- find_element_by_xpath("//form[@id='searchForm']/input")
Then automatically input the "Forbidden City", obtain the button "enter entry" and click it automatically. The method adopted here is to enter the Enter key on the keyboard to access the "Forbidden City" interface. The core code is as follows:
driver.get("http://baike.baidu.com/")
elem_inp=driver.find_element_by_xpath("//form[@id='searchForm']/input")
elem_inp.send_keys(name)
elem_inp.send_keys(Keys.RETURN)
(2) Call Selenium to access the "Forbidden City" page and locate the message box
After the first step is completed, enter the "Forbidden City" page, find the InfoBox part of the middle message box, right-click and click "review element", and the return result is shown in Figure 7.
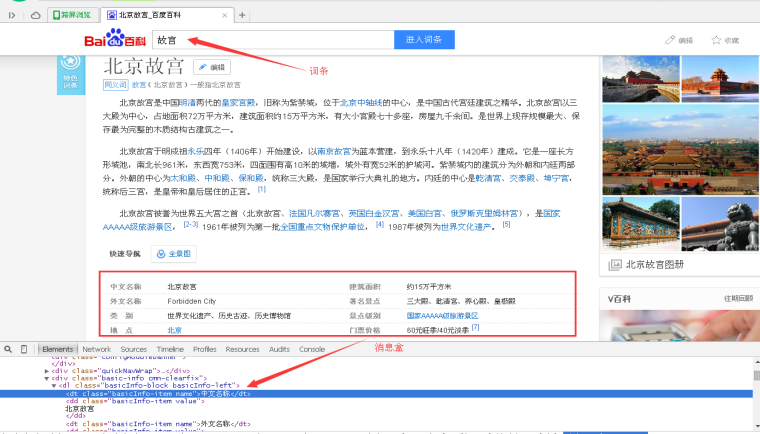
The core code of message box is as follows:
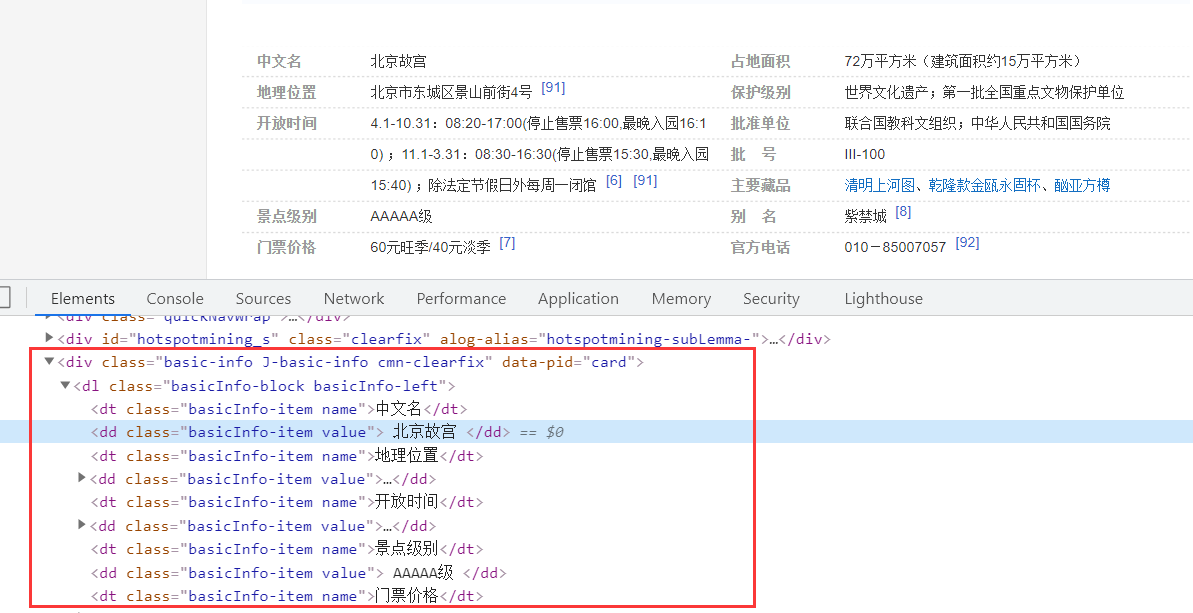
The message box is mainly stored in the form of < attribute - attribute value >, which summarizes the information of the "Forbidden City" entity in detail. For example, the corresponding value of the attribute "Chinese name" is "Beijing Forbidden City", and the corresponding value of the attribute "foreign name" is "Fobidden City". The corresponding HTML source code is as follows.
<div class="basic-info J-basic-info cmn-clearfix"> <dl class="basicInfo-block basicInfo-left"> <dt class="basicInfo-item name">Chinese name</dt> <dd class="basicInfo-item value"> Beijing Forbidden City </dd> <dt class="basicInfo-item name">Foreign language name</dt> <dd class="basicInfo-item value"> Forbidden City </dd> <dt class="basicInfo-item name">class other</dt> <dd class="basicInfo-item value"> World cultural heritage, historical sites and historical museums </dd> </dl> ... <dl class="basicInfo-block basicInfo-right"> <dt class="basicInfo-item name">built-up area</dt> <dd class="basicInfo-item value"> About 150000 square meters </dd> <dt class="basicInfo-item name">Famous scenic spot</dt> <dd class="basicInfo-item value"> Three main halls, Qianqing palace, Yangxin hall and Huangji Hall </dd> </dl> ... </div>
The whole message box is located in the < div class = "basic info j-basic-info CMN Clearfix" > tag, followed by a combination of < DL >, < DT >, < DD >, where the message box div layout includes two < DL >... < / dl > layouts, one is to record the content of the left part of the message box, and the other < DL > records the content of the right part of the message box, Define the attribute and attribute value in each < DL > tag, as shown in Figure 8.
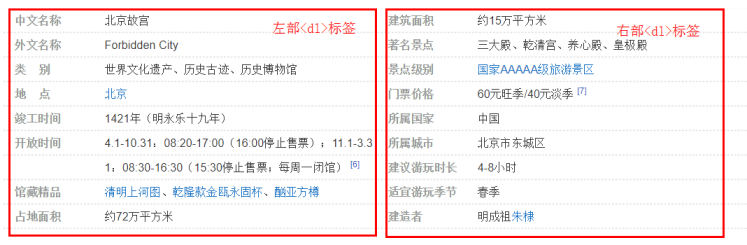
Note: the outermost layer of dt and dd must be wrapped with dl. The < dl > label defines the Definition List, the items in the < dt > label Definition List, and the < dd > label describes the items in the list. This combined label is called a table label, which is similar to the table table combined label.
Next, call find of Selenium extension package_ elements_ by_ The XPath () function locates the attribute and attribute value respectively. The function returns multiple attributes and attribute value sets, and then outputs the located multiple element values through the for loop. The code is as follows:
elem_name=driver.find_elements_by_xpath("//div[@class='basic-info J-basic-info cmn-clearfix']/dl/dt")
elem_value=driver.find_elements_by_xpath("//div[@class='basic-info J-basic-info cmn-clearfix']/dl/dd")
for e in elem_name:
print(e.text)
for e in elem_value:
print(e.text)
At this time, the analysis method of crawling Baidu Encyclopedia national 5A scenic spot using Selenium technology is explained. Here are the complete code and some difficulties.
2. Code implementation
Note that next, we try to define multiple Python files to call each other to implement the crawler function. The complete code consists of two files, namely:
- test10_01_baidu.py: defines the main function and calls getinfo Py file
- getinfo.py: crawl the message box through the getInfobox() function
test10_01_baidu.py
# -*- coding: utf-8 -*-
"""
test10_01_baidu.py
The main function is defined main And call getinfo.py file
By: Eastmount CSDN 2021-06-23
"""
import codecs
import getinfo #Reference module
#Main function
def main():
#Read scenic spot information from file
source = open('data.txt','r',encoding='utf-8')
for name in source:
print(name)
getinfo.getInfobox(name)
print('End Read Files!')
source.close()
if __name__ == '__main__':
main()
Invoke "import getinfo" code in code to import getinfo.py file, after importing, you can call getinfo. in the main function. Py file, and then we call getinfo The getInfobox() function in the. Py file performs the operation of crawling the message box.
getinfo.py
# coding=utf-8
"""
getinfo.py:pick up information
By: Eastmount CSDN 2021-06-23
"""
import os
import codecs
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
#getInfobox function: get the message box of national 5A scenic spots
def getInfobox(name):
try:
#Visit Baidu Encyclopedia and search automatically
driver = webdriver.Firefox()
driver.get("http://baike.baidu.com/")
elem_inp = driver.find_element_by_xpath("//form[@id='searchForm']/input")
elem_inp.send_keys(name)
elem_inp.send_keys(Keys.RETURN)
time.sleep(1)
print(driver.current_url)
print(driver.title)
#Crawling message box InfoBox content
elem_name=driver.find_elements_by_xpath("//div[@class='basic-info J-basic-info cmn-clearfix']/dl/dt")
elem_value=driver.find_elements_by_xpath("//div[@class='basic-info J-basic-info cmn-clearfix']/dl/dd")
"""
for e in elem_name:
print(e.text)
for e in elem_value:
print(e.text)
"""
#Build field pair output
elem_dic = dict(zip(elem_name,elem_value))
for key in elem_dic:
print(key.text,elem_dic[key].text)
time.sleep(5)
return
except Exception as e:
print("Error: ",e)
finally:
print('\n')
driver.close()
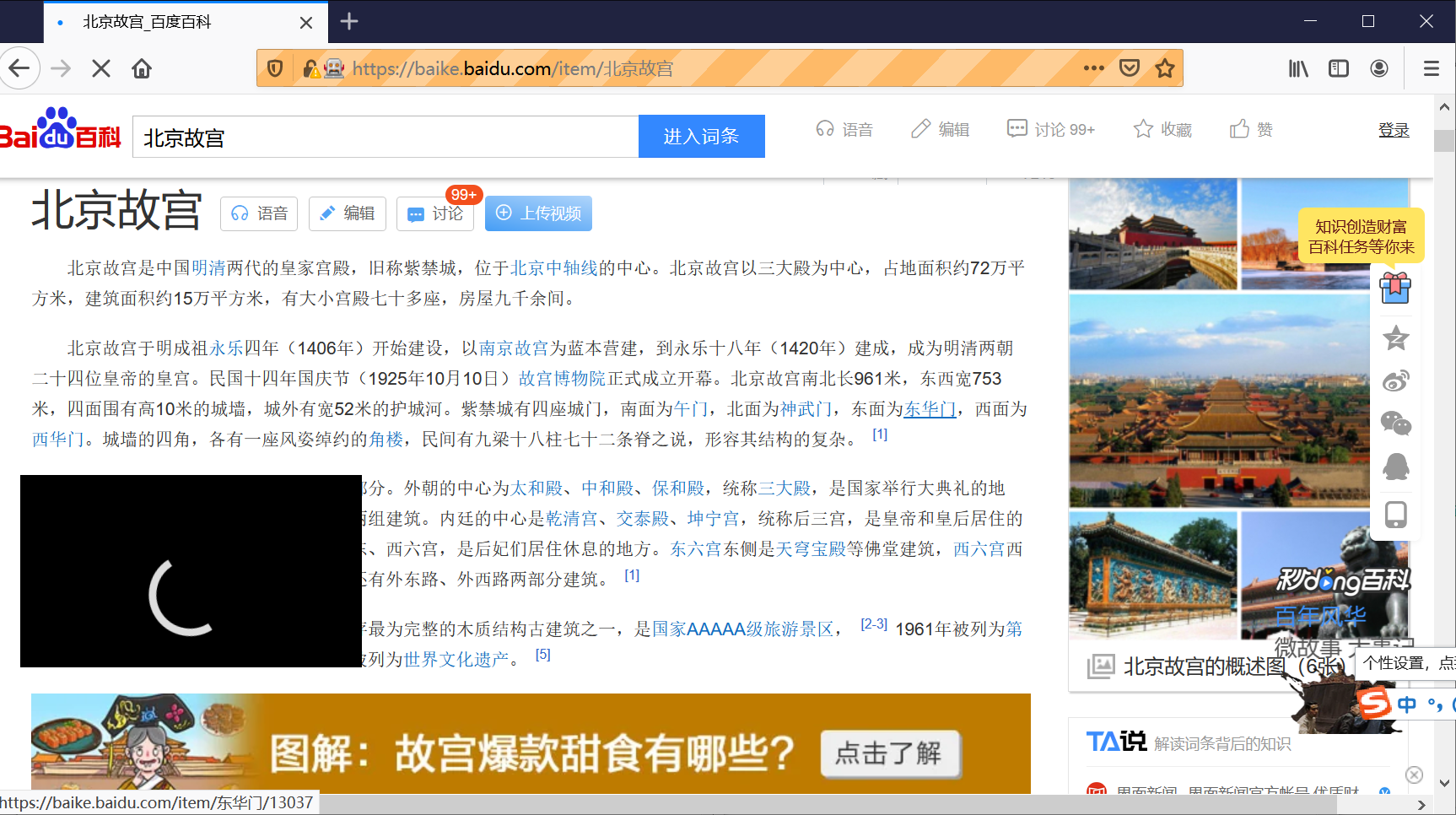
For example, during crawling, Firefox browser will automatically search the "Forbidden City" page, as shown in the following figure:
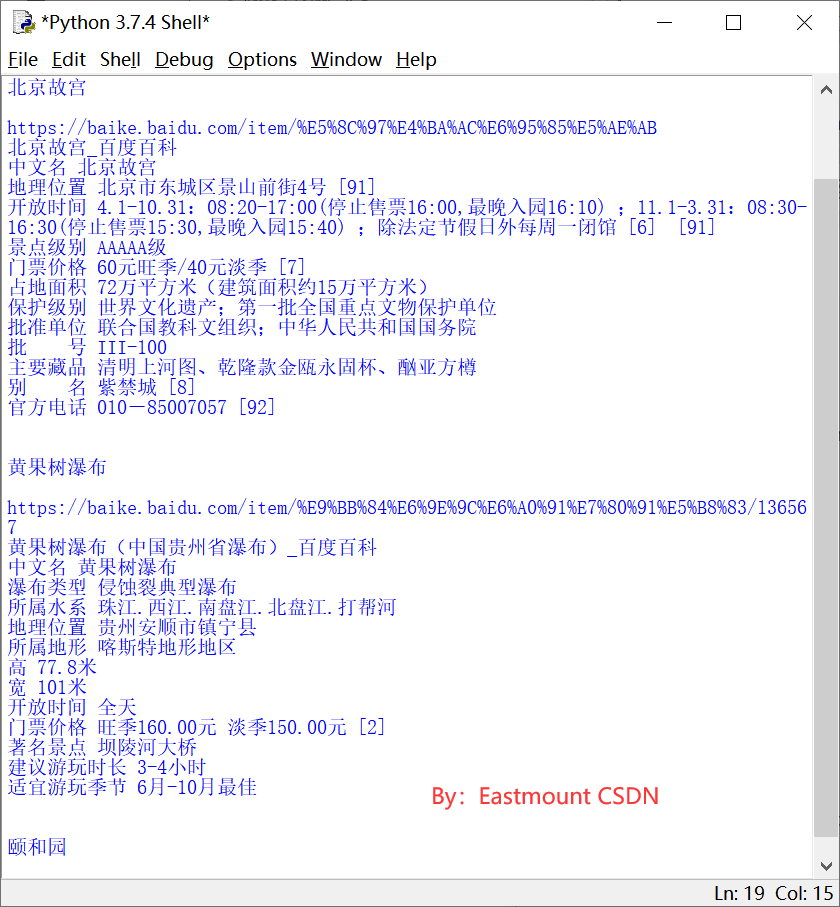
The final output result is shown in the figure below:
The contents are as follows:
https://baike.baidu.com/item / Beijing Forbidden City Beijing Forbidden City_Baidu Encyclopedia https://baike.baidu.com/item/%E5%8C%97%E4%BA%AC%E6%95%85%E5%AE%AB Beijing Forbidden City_Baidu Encyclopedia Chinese Name: Beijing Forbidden City Location: No. 4, jingshanqian street, Dongcheng District, Beijing [91] Opening hours 4.1-10.31: 08:20-17:00(Stop selling tickets 16:00,Latest admission 16:10) ;11.1-3.31: 08:30-16:30(Stop selling tickets 15:30,Latest admission 15:40) ;The museum is closed every Monday except legal holidays [6] [91] Scenic spot level AAAAA level The ticket price is 60 yuan in the peak season/40 Yuan off-season [7] Covering an area of 720000 square meters (construction area of about 150000 square meters) Protection level world cultural heritage; The first batch of national key cultural relics protection units Approved by UNESCO; State Council of the PRC batch number III-100 The main collections are Qingming Shanghe map, Qianlong jin'ou YONGGU cup and YONGYA square bottle other Forbidden City [8] Official Tel: 010-85007057 [92]
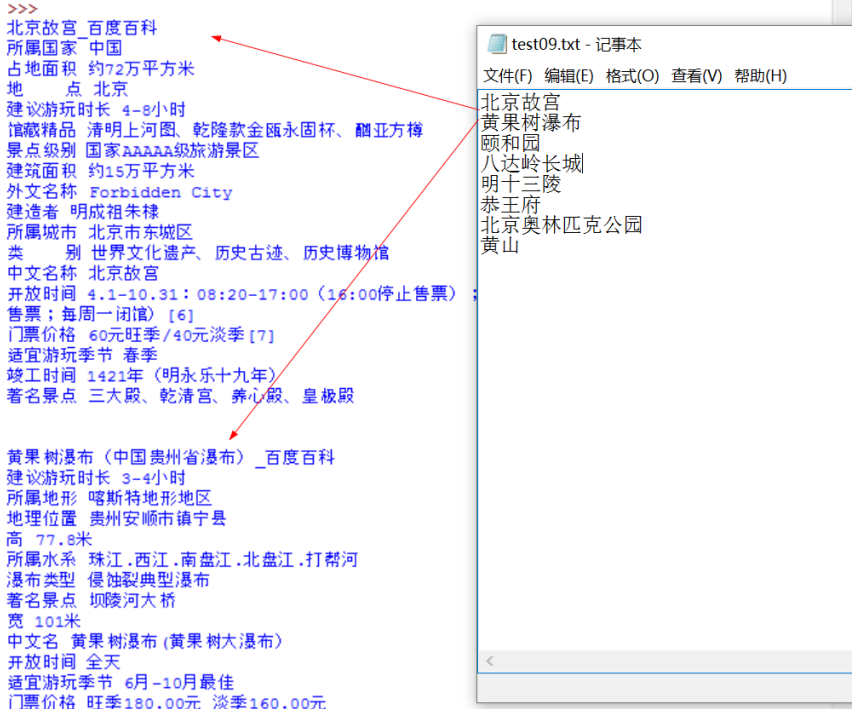
The Python run results are as follows, where data Txt file includes several common scenic spots.
- Beijing Forbidden City
- Huangguoshu Waterfall
- the Summer Palace
- Badaling Great Wall
- Ming Dynasty Tombs
- Prince Gong House
- Beijing Olympic Park
- Mount Huangshan
The above code attributes and attribute values are combined and output through the dictionary, and the core code is as follows:
elem_dic = dict(zip(elem_name,elem_value)) for key in elem_dic: print(key.text,elem_dic[key].text)
At the same time, readers can try to call the local interface free browser PhantomJS for crawling. The calling method is as follows:
webdriver.PhantomJS(executable_path="C:\...\phantomjs.exe")
Course assignment:
- The author teaches you to crawl the message box here. At the same time, the abstract and text of encyclopedia knowledge are also very important. Readers may wish to try to crawl separately. These corpora will become a necessary reserve in your subsequent text mining or NLP fields, such as text classification, entity alignment, entity disambiguation, knowledge map construction, etc.
III Selenium crawls Wikipedia
Online encyclopedia is a user generated data set with the largest amount of data publicly available on the Internet. These data have a certain structure and belong to semi-structured data. The three most famous online encyclopedias include Wikipedia, Baidu Encyclopedia and Interactive Encyclopedia. First, the author will introduce the example of Selenium crawling Wikipedia.
1. Web page analysis
For the first example, the author will explain in detail the first paragraph of summary information of Selenium crawling the group of 20 countries (G20). The specific steps are as follows:
(1) Get country hyperlinks from the G20 list page
The G20 list website is as follows. Wikipedia uses the initials of National English words to sort, such as "Japan", "Italy", "Brazil", etc. each country jumps in the form of hyperlinks.
- https://en.wikipedia.org/wiki/Category:G20_nations
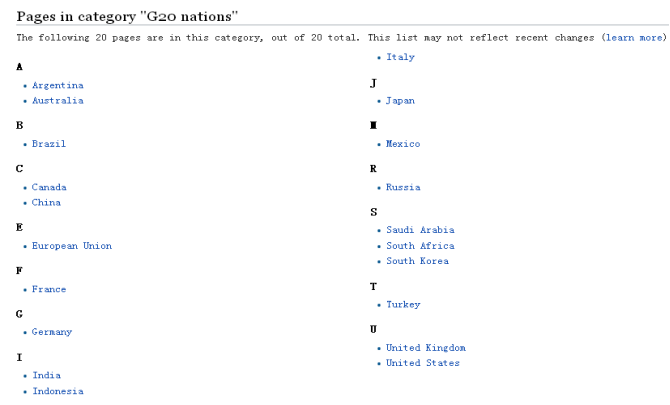
First, you need to get hyperlinks from 20 countries, and then go to specific pages to crawl. Select a country's hyperlink, such as "China", right-click and click the "check" button to obtain the corresponding HTML source code, as shown below.
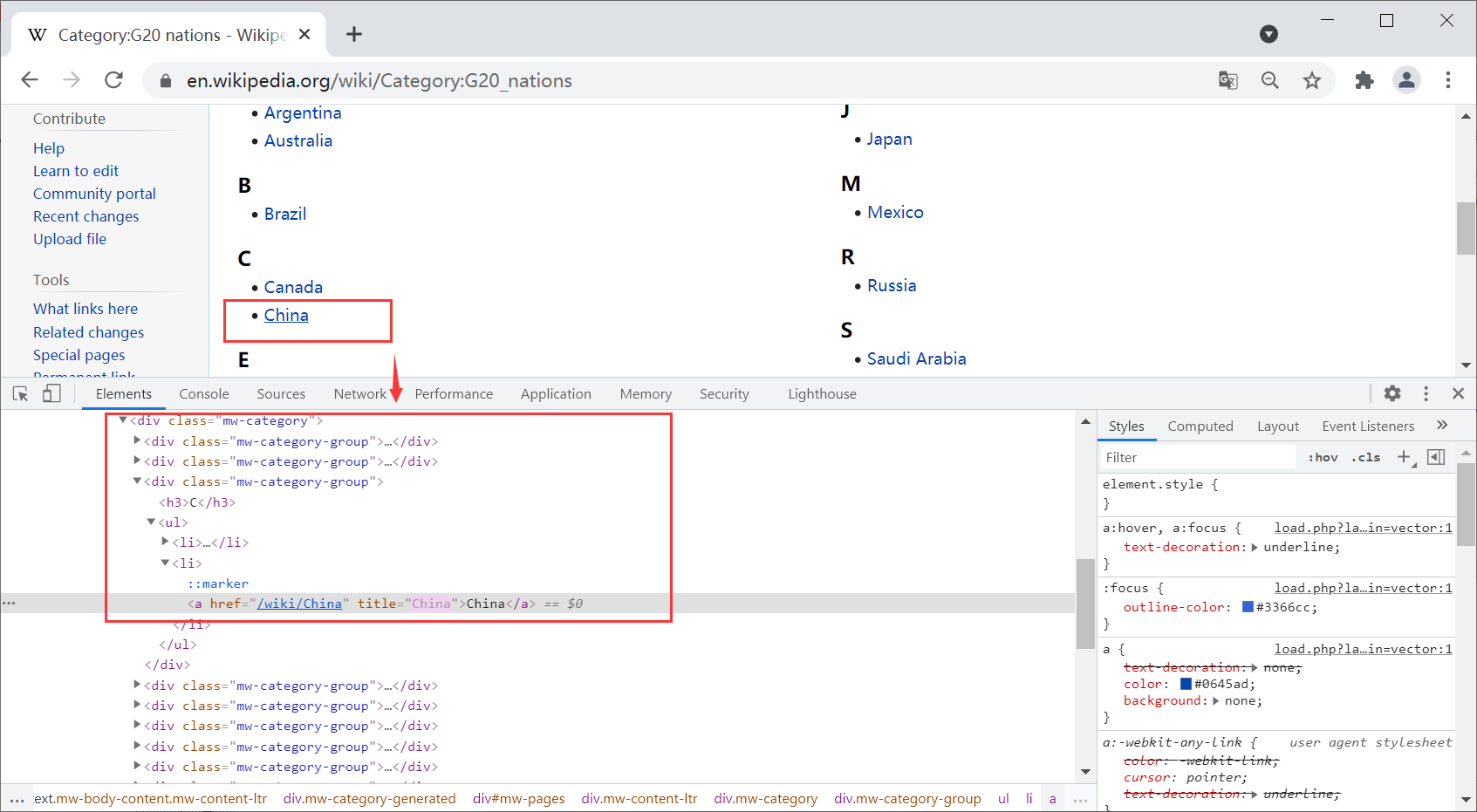
The hyperlink is located under the < UL > < li > < a > node of the < div class = "MW category group" > layout, and the corresponding code is:
<div class="mw-pages"> <div lang="en" dir="ltr" class="mw-content-ltr"> <div class="mw-category"> <div class="mw-category-group"> <h3>C<h3> <ul><li> <a href="/wiki/China" title="China">China</a> </li></ul> </div> <div class="mw-category-group">...</div> <div class="mw-category-group">...</div> ... </div> </div> </div>
Call Selenium's find_ elements_ by_ The XPath () function gets the hyperlink with the node class attribute of "MW category group", which will return multiple elements. The core code of positioning hyperlink is as follows:
driver.get("https://en.wikipedia.org/wiki/Category:G20_nations")
elem=driver.find_elements_by_xpath("//div[@class='mw-category-group']/ul/li/a")
for e in elem:
print(e.text)
print(e.get_attribute("href"))
Function find_elements_by_xpth() first parses the DOM tree structure of HTML, locates to the specified node, and obtains its elements. Then define a for loop to get the content and href attribute of the node in turn, where e.text represents the content of the node. For example, the content between the following nodes is China.
<a href="/wiki/China" title="China">China</a>
Meanwhile, e.get_attribute("href") means to obtain the attribute value corresponding to the node attribute href, that is "/ wiki/China". Similarly, e.get_attribute("title") can obtain the title attribute and get the value "China".
At this time, store the obtained hyperlink in the variable, as shown in the figure below, and then locate each country in turn and obtain the required content.

(2) Call Selenium to locate and crawl the message box of each country's page
Next, start visiting specific pages, such as China“ https://en.wikipedia.org/wiki/China ”, as shown in the figure, you can see the URL, title, summary, content, message box, etc. of the page, the right part of the message box on the way, including the full name of the country, location, etc.
The following describes a web page entity in the form of < attribute - attribute value > pairs, which concisely and accurately summarizes information such as < capital - Beijing >, < population - 1.3 billion people >, etc. Generally, after obtaining these information, preprocessing operation is required before data analysis, which will be explained in detail in the following chapters.
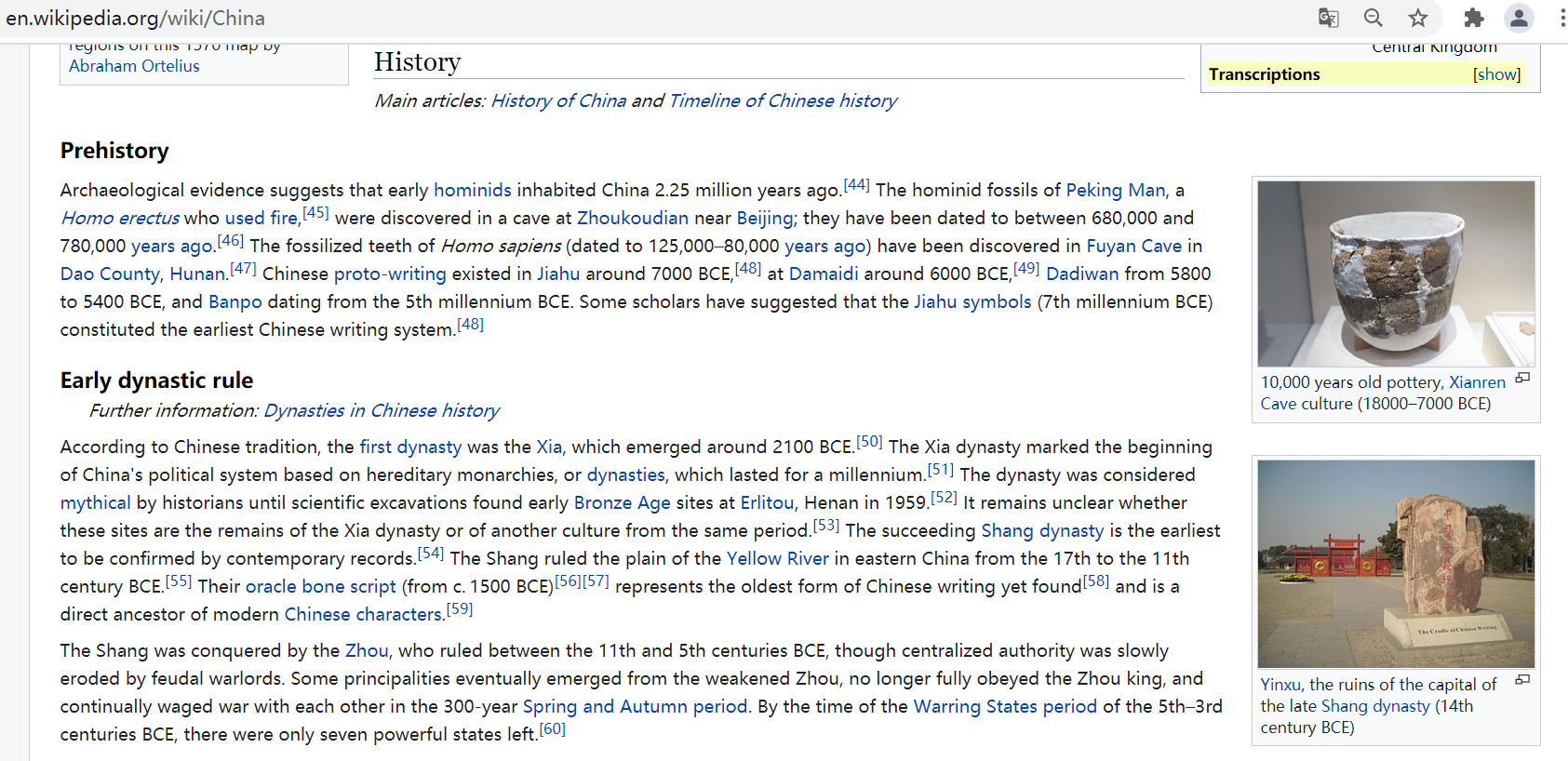
After visiting the page of each country, you need to get the first introduction of each country. The crawler content explained in this section may be relatively simple, but the explanation method is very important, including how to locate nodes and crawl knowledge. The code of the HTML core part corresponding to the details page is as follows:
<div class="mw-parser-output"> <div role="note" class="hatnote navigation-not-searchable">...</div> <div role="note" class="hatnote navigation-not-searchable">...</div> <table class="infobox gegraphy vcard">...</table> <p> <b>China</b> , officially the <b>People's Republic of China</b> .... </p> <p>...</p> <p>...</p> ... </table> </div> </div> </div>
The browser review element method is shown in the figure.
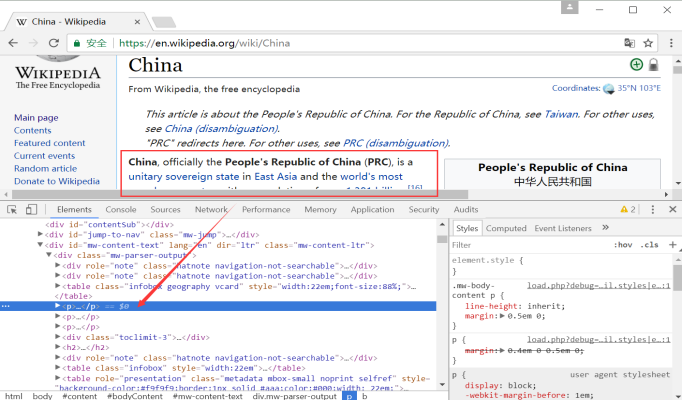
The body content is located under the < div > node with the attribute class "MW parser output". In HTML, the < p > tag represents a paragraph, which is usually used to identify the body, and the < b > tag represents bold. Get the first paragraph, that is, locate the first < p > node. The core code is as follows:
driver.get("https://en.wikipedia.org/wiki/China")
elem=driver.find_element_by_xpath("//div[@class='mw-parser-output']/p[2]").text
print elem
Note that the first paragraph of the text is located in the second < p > paragraph, so you can obtain p[2]. At the same time, if readers want to get the message box from the source code, they need to get the location of the message box and grab the data. The content of the message box (InfoBox) corresponds to the following nodes in HTML, recording the core information of the web page entity.
<table class="infobox gegraphy vcard">...</table>
2. Code implementation
Complete code reference file test10_02.py, as follows:
# coding=utf-8
#By: Eastmount CSDN 2021-06-23
import time
import re
import os
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Firefox()
driver.get("https://en.wikipedia.org/wiki/Category:G20_nations")
elem = driver.find_elements_by_xpath("//div[@class='mw-category-group']/ul/li/a")
name = [] #Country name
urls = [] #Country hyperlink
#Crawl link
for e in elem:
print(e.text)
print(e.get_attribute("href"))
name.append(e.text)
urls.append(e.get_attribute("href"))
print(name)
print(urls)
#Crawling content
for url in urls:
driver.get(url)
elem = driver.find_element_by_xpath("//div[@class='mw-parser-output']/p[1]").text
print(elem)
The crawling information is shown in the figure.

PS: you can simply try this part. It is more recommended to climb Baidu Encyclopedia, Interactive Encyclopedia and Sogou encyclopedia.
IV Selenium crawls Interactive Encyclopedia
Over the past few years, Interactive Encyclopedia has become a quick to understand encyclopedia, but fortunately, the web page structure has not changed.
1. Web page analysis
At present, online encyclopedia has developed into an important corpus source for many researchers engaged in semantic analysis, knowledge map construction, natural language processing, search engine and artificial intelligence. As one of the most popular online encyclopedias, Interactive Encyclopedia provides researchers with strong corpus support.
This section will explain the summary information of the ten most popular programming language pages of a crawling Interactive Encyclopedia, deepen readers' impression of using Selenium crawler technology through this example, and analyze the analysis skills of network data crawling more deeply. Unlike Wikipedia, which first crawls the hyperlinks in the list of terms and then crawls the required information, Baidu Encyclopedia enters the terms into the relevant pages and then crawls them in a directional way, the Interactive Encyclopedia adopts the following methods:
- Set the web page url of different entries, and then go to the detailed interface of the entry for information crawling.
Because there is a certain rule for the hyperlinks corresponding to different entries in the Interactive Encyclopedia Search, that is, the method of "common url + search entry name" is used to jump. Here, we set different entry web pages through this method. The specific steps are as follows:
(1) Call Selenium to analyze the URL and search for interactive encyclopedia entries
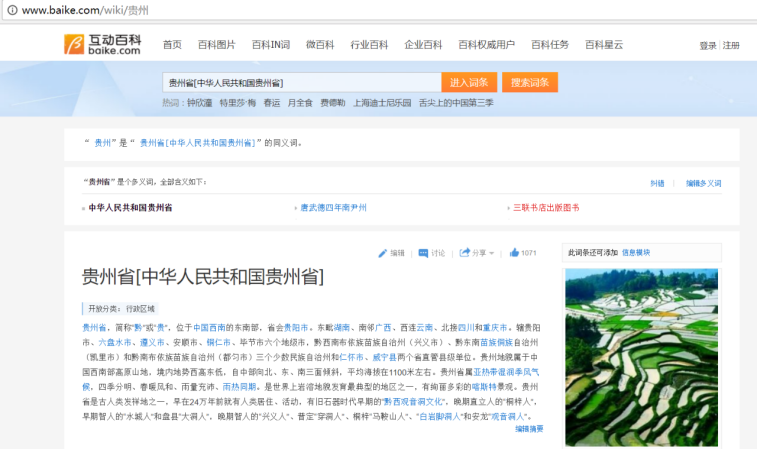
First, we analyze some rules for searching terms in the Interactive Encyclopedia, such as searching for the character "Guizhou", and the corresponding hyperlink is:
- http://www.baike.com/wiki/ Guizhou
The corresponding page is shown in the figure. You can see the hyperlink URL at the top, the entry is "Guizhou", the first paragraph is the summary information of "Guizhou", and the corresponding picture on the right.
Similarly, search the programming language "Python", and the corresponding hyperlink is:
- http://www.baike.com/wiki/Python
A simple rule can be drawn, that is:
- http://www.baike.com/wiki/ Entry
The corresponding knowledge can be searched. For example, the programming language "Java" corresponds to:
- http://www.baike.com/wiki/Java
(2) Access top 10 programming languages and crawl through summary information
In 2016, Github ranked the top 10 most popular programming languages according to the number of PR submitted by each language in the past 12 months: JavaScript, Java, Python, Ruby, PHP, C + +, CSS, c#, C and GO.
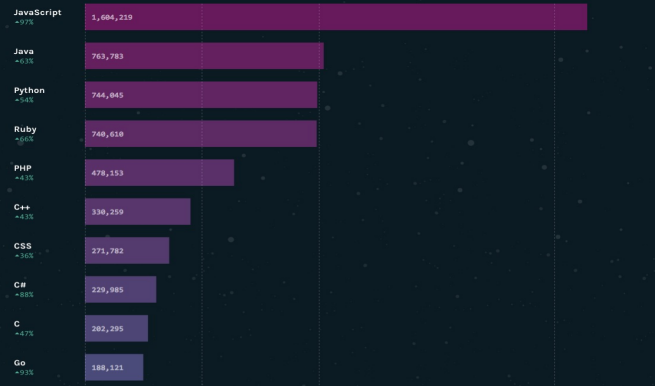
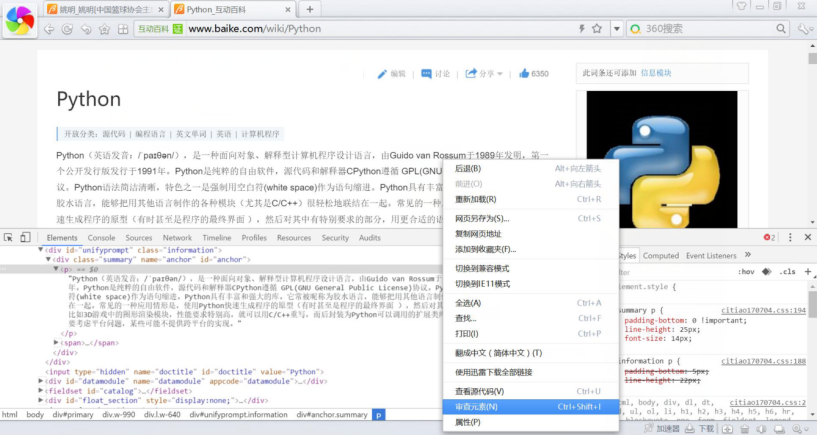
Then, we need to obtain the summary information of these ten languages. Select the summary part in the browser and right-click "review element" to return the results, as shown in the figure. You can see the HTML source code corresponding to the summary part at the bottom.
The content of the new version of "quick encyclopedia" is shown in the figure below:
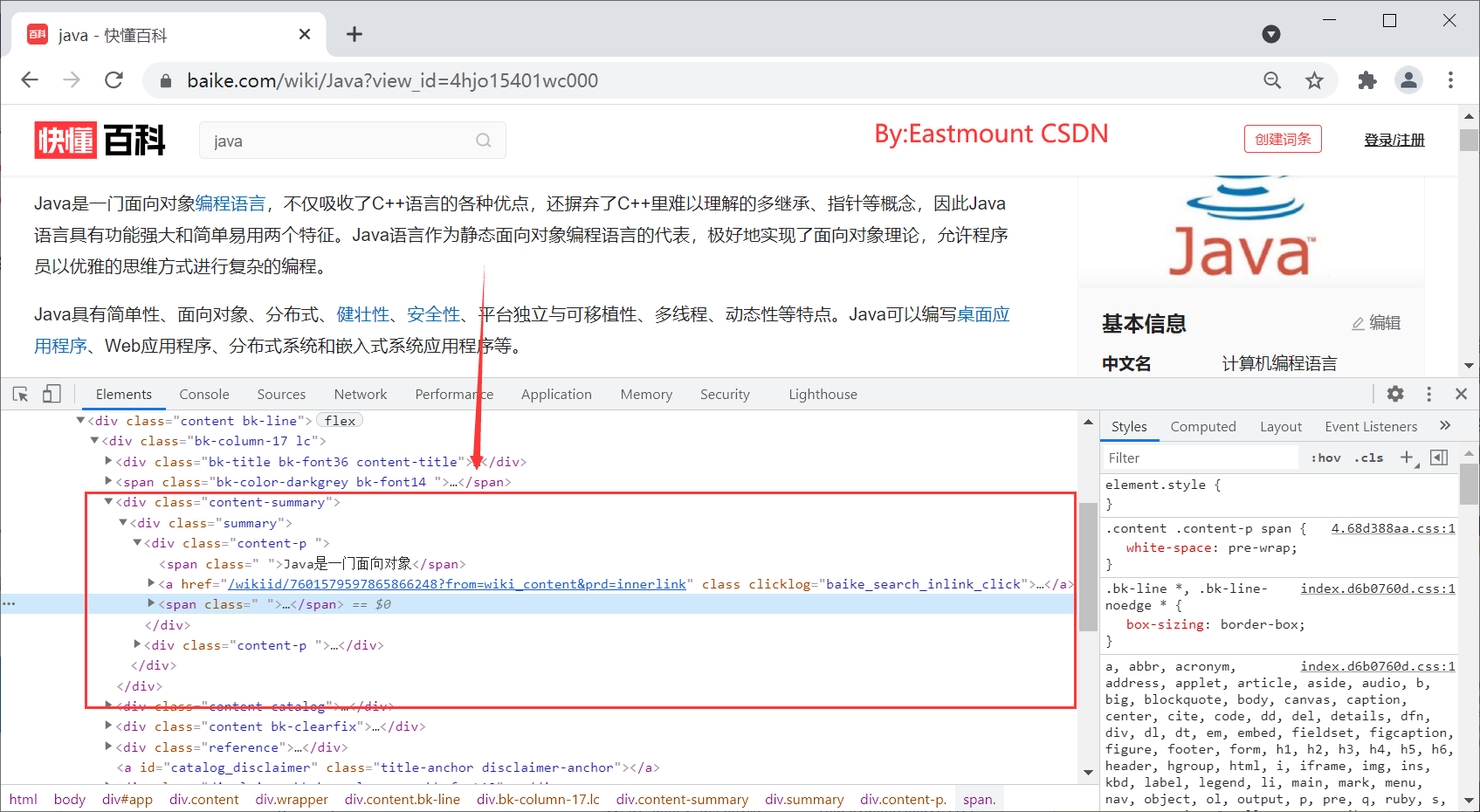
The corresponding HTML core code of "Java" entry summary is as follows:
<div class="summary"> <div class="content-p "> <span class=" ">Java Is an object-oriented</span> <a href="/wikiid/7601579597865866248?from=wiki_content" class="" clicklog="baike_search_inlink_click"> <span class=" ">programing language</span> </a> <span class=" ">,Not only absorbed C++The advantages of language are also abandoned C++It is difficult to understand the concepts of multiple inheritance and pointers in Java Language has two characteristics: powerful function and easy to use. Java As the representative of static object-oriented programming language, language perfectly realizes the object-oriented theory and allows programmers to program complex programs in an elegant way of thinking.</span> </div> <div class="content-p "> <span class=" ">Java Simple, object-oriented, distributed</span> ... </div> </div>
Call Selenium's find_ element_ by_ The XPath () function can obtain the summary paragraph information. The core code is as follows.
driver = webdriver.Firefox()
url = "http://www.baike.com/wiki/" + name
driver.get(url)
elem = driver.find_element_by_xpath("//div[@class='summary']/div/span")
print(elem.text)
The basic steps of this code are:
- First call webdriver Firefox () driver, open Firefox browser.
- Analyze the web page hyperlink and call driver Get (URL) function access.
- Analyze the DOM tree structure of the web page and call driver find_ element_ by_ Xpath().
- As a result, the contents of some websites need to be stored locally, and unwanted contents need to be filtered out.
The following is the complete code and detailed explanation.
2. Code implementation
The complete code is blog10_03.py as shown below, the main function main() calls the getabstract() function to crawl the summary information of the Top10 programming language.
# coding=utf-8
#By: Eastmount CSDN 2021-06-23
import os
import codecs
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Firefox()
#Get summary information
def getAbstract(name):
try:
#New folder and file
basePathDirectory = "Hudong_Coding"
if not os.path.exists(basePathDirectory):
os.makedirs(basePathDirectory)
baiduFile = os.path.join(basePathDirectory,"HudongSpider.txt")
#If the file does not exist, create a new one. If it exists, write it additionally
if not os.path.exists(baiduFile):
info = codecs.open(baiduFile,'w','utf-8')
else:
info = codecs.open(baiduFile,'a','utf-8')
url = "http://www.baike.com/wiki/" + name
print(url)
driver.get(url)
elem = driver.find_elements_by_xpath("//div[@class='summary']/div/span")
content = ""
for e in elem:
content += e.text
print(content)
info.writelines(content+'\r\n')
except Exception as e:
print("Error: ",e)
finally:
print('\n')
info.write('\r\n')
#Main function
def main():
languages = ["JavaScript", "Java", "Python", "Ruby", "PHP",
"C++", "CSS", "C#", "C", "GO"]
print('Start crawling')
for lg in languages:
print(lg)
getAbstract(lg)
print('End crawling')
if __name__ == '__main__':
main()
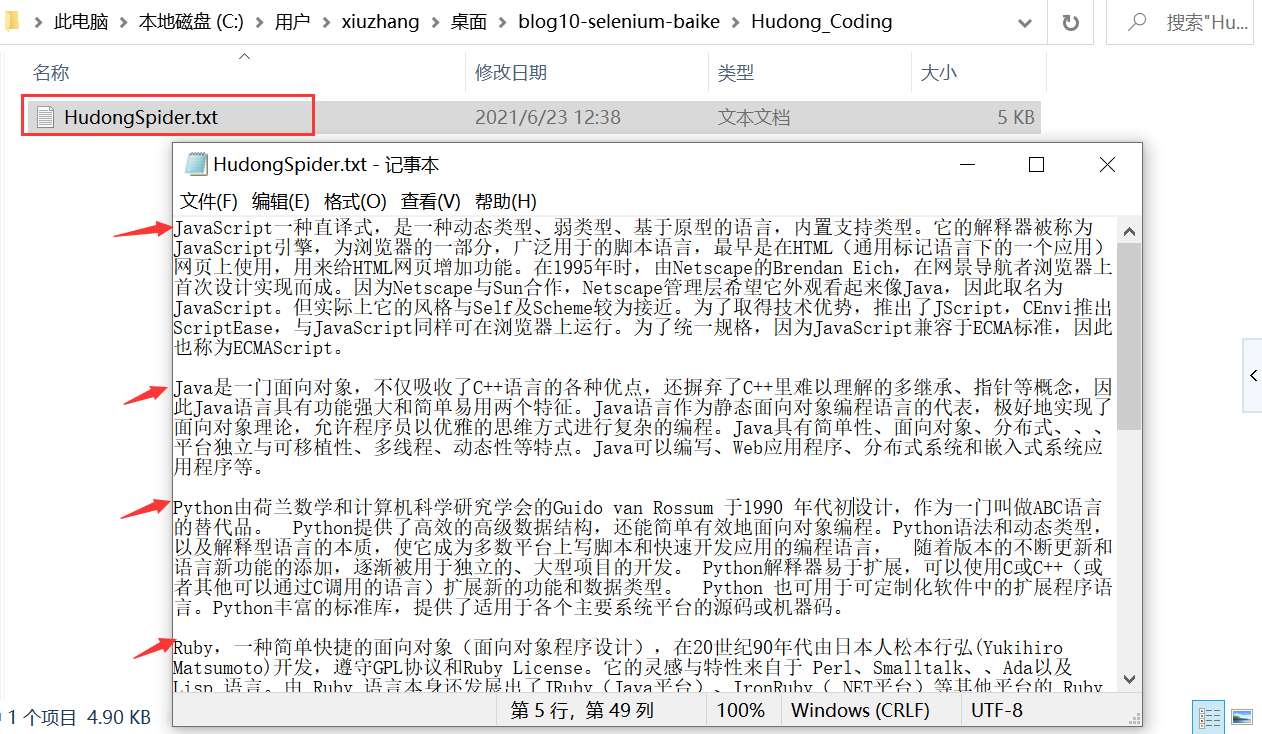
The capture results of "JavaScript" and "Java" programming languages are shown in the figure. This code crawls the summary information of ten popular languages in the Interactive Encyclopedia.
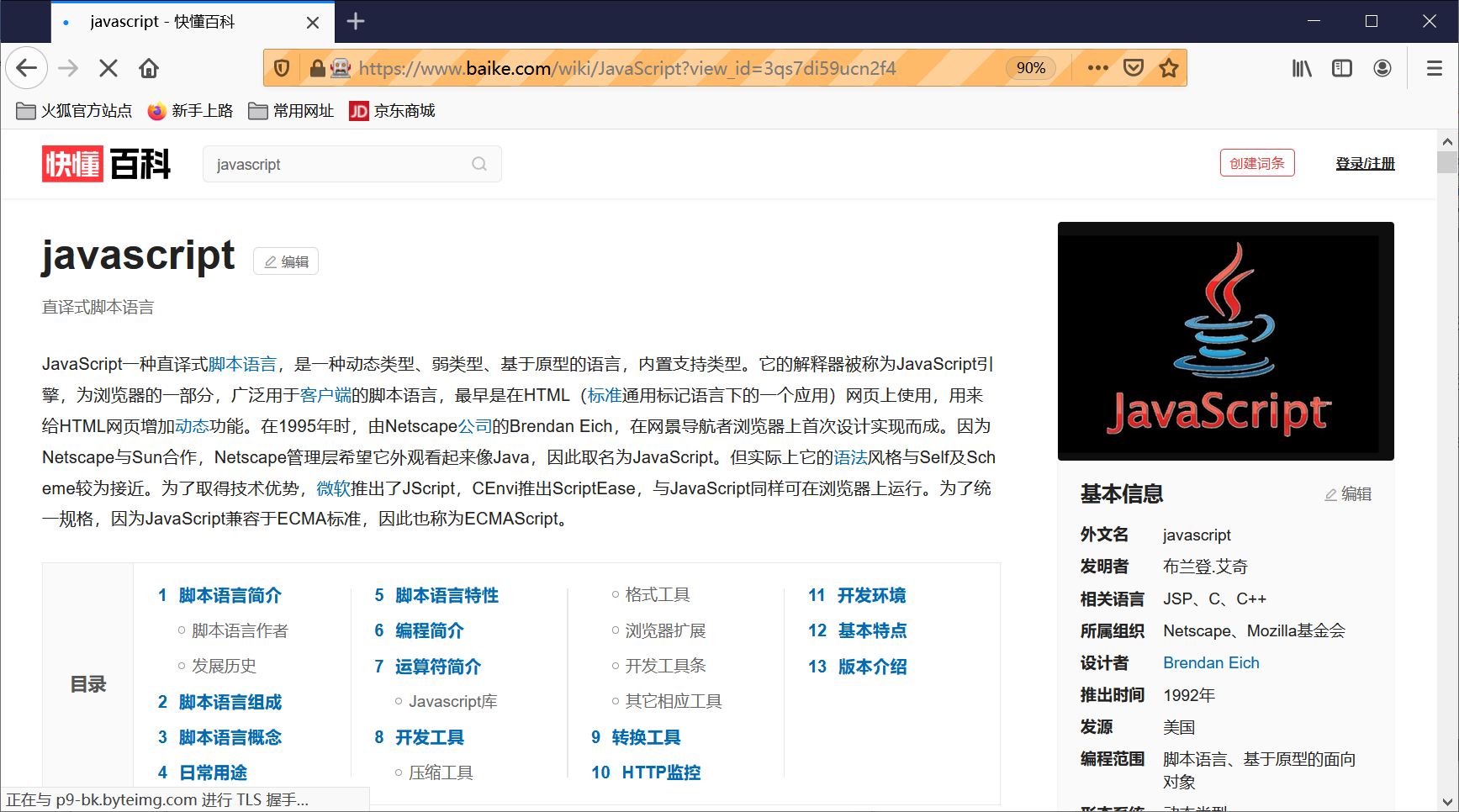
The program successfully captures the summary information of each programming language, as shown in the following figure:

At the same time, the data is stored in the local TXT file, which will effectively provide support for one-step analysis of NLP and text mining.
Here, we have introduced several common encyclopedia data capture methods. I hope you like them.
V Summary of this chapter
Online encyclopedia is widely used in scientific research, knowledge map and search engine construction, data integration of large and small companies, web2 0 knowledge base system, because it is open, dynamic, freely accessible and edited, and has multilingual versions, it is deeply loved by scientific researchers and company developers. Common online encyclopedias include Wikipedia, Baidu Encyclopedia and Interactive Encyclopedia.
Combined with Selenium technology, this paper crawls the paragraph content of Wikipedia, the message box of Baidu Encyclopedia and the summary information of Interactive Encyclopedia respectively, and adopts three analysis methods. It is hoped that readers can master the method of Selenium technology crawling web pages through the cases in this chapter.
- Message box crawling
- Text summary crawling
- Multiple jump modes of web pages
- Web page analysis and crawling core code
- file save
Selenium is more widely used in the field of automated testing. It runs directly in browsers (such as Firefox, Chrome, IE, etc.), just like real user operations, and tests all kinds of developed web pages. It is also a necessary tool in the direction of automated testing. It is hoped that readers can master the crawling method of this technology, especially when the target web page needs to verify login and so on.
Download address of all codes of this series:
Thank the fellow travelers on the way to school. Live up to your meeting and don't forget your original heart. This week's message is filled with emotion ~
(By: the night of June 23, 2021 in Wuhan https://blog.csdn.net/Eastmount )
reference
- [1] Selenium Python document: Directory - Tacey Wong - blog Garden
- [2] Baiju Muthukadan Selenium with Python Selenium Python Bindings 2 documentation
- [3] https://github.com/baijum/selenium-python
- [4] http://blog.csdn.net/Eastmount/article/details/47785123
- [5] Selenium realizes automatic login 163 mailbox and Locating Elements introduction - Eastmount
- [6] Selenium common element positioning methods and operations learning introduction - Eastmount
- [7] "Python Network Data crawling and analysis from introduction to mastery (crawling)" Eastmount
- [8] Yang xiuzhang Research and implementation of entity and attribute alignment method [J] Master's thesis of Beijing University of technology, 2016:15-40
- [9] Xu Pu Research and implementation of knowledge map construction method in tourism field [J] Master's thesis of Beijing University of technology, 2016:7-24
- [10] Hu Fangwei Research on the construction method of Chinese knowledge map based on multiple data sources [J] Doctoral Dissertation of East China University of technology, 2014:25-60
- [11] Yang xiuzhang [python crawler] learning introduction to common element positioning methods and operations in Selenium - CSDN blog [EB/OL] (2016-07-10)[2017-10-14].