1, Weather and time classification
Competition address: https://www.datafountain.cn/competitions/555

1. Competition background
In the automatic driving scene, weather and time (dawn, morning, afternoon, dusk and night) will affect the accuracy of the sensor. For example, rainy days and night will greatly affect the accuracy of the visual sensor. The purpose of this competition is to classify the weather and time of the photos taken, so as to use different automatic driving strategies in different weather and time.
2. Competition task
The data set of this competition is provided by cloud measurement data. The competition data set contains 3000 pictures collected by the dash cam in the real scene, including 2600 pictures with weather and time category labels in the training set and 400 pictures without labels in the test set. Participants need to train on the training set based on Oneflow framework to classify the weather and time of photos in the test set.
3. Data introduction
The data set of this competition contains 2600 manually marked weather and time tags.
- Weather category: cloudy, sunny, rainy, snowy and foggy
- Time: Dawn, morning, afternoon, dusk and night

Cloudy afternoon

Rainy morning
4. Data description
The dataset contains two folders, anno and image. The anno folder contains 2600 label json files, and the image folder contains 3000 JPEG encoded photos taken by the dash cam. The picture tag serializes and saves the dictionary in json format:
| Listing | Value range | effect |
|---|---|---|
| Period | Dawn, morning, afternoon, dusk, night | Picture shooting time |
| Weather | Cloudy, sunny, rainy, snowy and foggy days | Picture weather |
5. Submission requirements
After training the data set with Oneflow framework and reasoning the test set pictures,
1. Serialize and save the target detection and recognition results of the test set pictures in json files consistent with the format of the training set, upload them to the competition platform, and the competition platform will automatically evaluate the returned results.
2. Attach your own model github warehouse link to the comments at the time of submission
6. Submission examples
{
"annotations": [
{
"filename": "test_images\00008.jpg",
"period": "Morning",
"weather": "Cloudy"
}]
}
7. Problem solving ideas
Generally speaking, the task can be divided into two parts: one is to predict the time and the other is to predict the weather, as follows:
- Generation of forecast time and weather data label list
- Data set partition
- Data balance (data is very uneven)
- Forecast separately
- Consolidated forecast results
2, Dataset preparation
1. Data download
# Direct download, super fast !wget https://awscdn.datafountain.cn/cometition_data2/Files/BDCI2021/555/train_dataset.zip !wget https://awscdn.datafountain.cn/cometition_data2/Files/BDCI2021/555/test_dataset.zip !wget https://awscdn.datafountain.cn/cometition_data2/Files/BDCI2021/555/submit_example.json
2. Data decompression
# Decompress data set !unzip -qoa test_dataset.zip !unzip -qoa train_dataset.zip
3. Make labels according to time
Note: Although the data describes the time * * Period as dawn, morning, afternoon, dusk and night * *, it is found that there are only four categories after traversal....., Therefore, make labels as follows
# Label modification
%cd ~
import json
import os
train = {}
with open('train.json', 'r') as f:
train = json.load(f)
period_list = {'Dawn': 0, 'Dusk': 1, 'Morning': 2, 'Afternoon': 3}
f_period=open('train_period.txt','w')
for item in train["annotations"]:
label = period_list[item['period']]
file_name=os.path.join(item['filename'].split('\\')[0], item['filename'].split('\\')[1])
f_period.write(file_name +' '+ str(label) +'\n')
f_period.close()
print("write in train_period.txt Done!!!")
/home/aistudio write in train_period.txt Done!!!
4. Data set division and data balance
# Data analysis
%cd ~
import pandas as pd
from matplotlib import pyplot as plt
%matplotlib inline
data=pd.read_csv('train_period.txt', header=None, sep=' ')
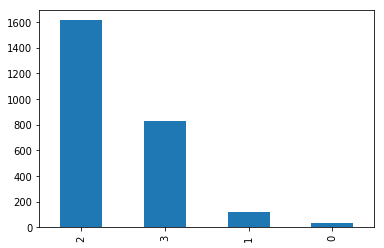
print(data[1].value_counts())
data[1].value_counts().plot(kind="bar")
/home/aistudio 2 1613 3 829 1 124 0 34 Name: 1, dtype: int64 <matplotlib.axes._subplots.AxesSubplot at 0x7feffe438b50>
# Division of training set and test set
import pandas as pd
import os
from sklearn.model_selection import train_test_split
def split_dataset(data_file):
# Show different invocation methods
data = pd.read_csv(data_file, header=None, sep=' ')
train_dataset, eval_dataset = train_test_split(data, test_size=0.2, random_state=42)
print(f'train dataset len: {train_dataset.size}')
print(f'eval dataset len: {eval_dataset.size}')
train_filename='train_' + data_file.split('.')[0]+'.txt'
eval_filename='eval_' + data_file.split('.')[0]+'.txt'
train_dataset.to_csv(train_filename, index=None, header=None, sep=' ')
eval_dataset.to_csv(eval_filename, index=None, header=None, sep=' ')
data_file='train_period.txt'
split_dataset(data_file)
train dataset len: 4160 eval dataset len: 1040
# You need to restart the notebook after updating pip or installing the package !pip install -U scikit-learn # For data equalization !pip install -U imblearn
# Data balance
import pandas as pd
from collections import Counter
from imblearn.over_sampling import SMOTE
import numpy as np
def upsampleing(filename):
print(50 * '*')
data = pd.read_csv(filename, header=None, sep=' ')
print(data[1].value_counts())
# View the sample size of each label
print(Counter(data[1]))
print(50 * '*')
# Data balance
X = np.array(data[0].index.tolist()).reshape(-1, 1)
y = data[1]
ros = SMOTE(random_state=0)
X_resampled, y_resampled = ros.fit_resample(X, y)
print(Counter(y_resampled))
print(len(y_resampled))
print(50 * '*')
img_list=[]
for i in range(len(X_resampled)):
img_list.append(data.loc[X_resampled[i]][0].tolist()[0])
dict_weather={'0':img_list, '1':y_resampled.values}
newdata=pd.DataFrame(dict_weather)
print(len(newdata))
new_filename=filename.split('.')[0]+'_imblearn'+'.txt'
newdata.to_csv(new_filename, header=None, index=None, sep=' ')
filename='train_train_period.txt'
upsampleing(filename)
filename='eval_train_period.txt'
upsampleing(filename)
**************************************************
2 1304
3 653
1 95
0 28
Name: 1, dtype: int64
Counter({2: 1304, 3: 653, 1: 95, 0: 28})
**************************************************
Counter({2: 1304, 3: 1304, 1: 1304, 0: 1304})
5216
**************************************************
5216
**************************************************
2 309
3 176
1 29
0 6
Name: 1, dtype: int64
Counter({2: 309, 3: 176, 1: 29, 0: 6})
**************************************************
Counter({2: 309, 3: 309, 1: 309, 0: 309})
1236
**************************************************
1236
5. Make labels according to weather
import json
import os
train = {}
with open('train.json', 'r') as f:
train = json.load(f)
weather_list = {'Cloudy': 0, 'Rainy': 1, 'Sunny': 2}
f_weather=open('train_weather.txt','w')
for item in train["annotations"]:
label = weather_list[item['weather']]
file_name=os.path.join(item['filename'].split('\\')[0], item['filename'].split('\\')[1])
f_weather.write(file_name +' '+ str(label) +'\n')
f_weather.close()
print("write in train_weather.txt Done!!!")
write in train_weather.txt Done!!!
6. Data set division and balance
import pandas as pd
from matplotlib import pyplot as plt
data=pd.read_csv('train_weather.txt', header=None, sep=' ')
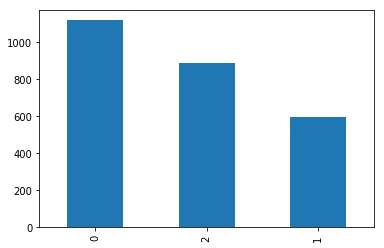
print(data[1].value_counts())
data[1].value_counts().plot(kind="bar")
0 1119 2 886 1 595 Name: 1, dtype: int64 <matplotlib.axes._subplots.AxesSubplot at 0x7feffe82d190>
# Division of training set and test set
import pandas as pd
import os
from sklearn.model_selection import train_test_split
def split_dataset(data_file):
# Show different calling methods
data = pd.read_csv(data_file, header=None, sep=' ')
train_dataset, eval_dataset = train_test_split(data, test_size=0.2, random_state=42)
print(f'train dataset len: {train_dataset.size}')
print(f'eval dataset len: {eval_dataset.size}')
train_filename='train_' + data_file.split('.')[0]+'.txt'
eval_filename='eval_' + data_file.split('.')[0]+'.txt'
train_dataset.to_csv(train_filename, index=None, header=None, sep=' ')
eval_dataset.to_csv(eval_filename, index=None, header=None, sep=' ')
data_file='train_weather.txt'
split_dataset(data_file)
train dataset len: 4160 eval dataset len: 1040
# Data balance
import pandas as pd
from collections import Counter
from imblearn.over_sampling import SMOTE
import numpy as np
def upsampleing(filename):
print(50 * '*')
data = pd.read_csv(filename, header=None, sep=' ')
print(data[1].value_counts())
# View the sample size of each label
print(Counter(data[1]))
print(50 * '*')
# Data balance
X = np.array(data[0].index.tolist()).reshape(-1, 1)
y = data[1]
ros = SMOTE(random_state=0)
X_resampled, y_resampled = ros.fit_resample(X, y)
print(Counter(y_resampled))
print(len(y_resampled))
print(50 * '*')
img_list=[]
for i in range(len(X_resampled)):
img_list.append(data.loc[X_resampled[i]][0].tolist()[0])
dict_weather={'0':img_list, '1':y_resampled.values}
newdata=pd.DataFrame(dict_weather)
print(len(newdata))
new_filename=filename.split('.')[0]+'_imblearn'+'.txt'
newdata.to_csv(new_filename, header=None, index=None, sep=' ')
filename='train_train_weather.txt'
upsampleing(filename)
filename='eval_train_weather.txt'
upsampleing(filename)
**************************************************
0 892
2 715
1 473
Name: 1, dtype: int64
Counter({0: 892, 2: 715, 1: 473})
**************************************************
Counter({0: 892, 2: 892, 1: 892})
2676
**************************************************
2676
**************************************************
0 227
2 171
1 122
Name: 1, dtype: int64
Counter({0: 227, 2: 171, 1: 122})
**************************************************
Counter({0: 227, 2: 227, 1: 227})
681
**************************************************
681
3, Environmental preparation
PaddleClas, a propeller image recognition kit, is a tool set for image recognition tasks prepared by the propeller for Industry and academia to help users train better visual models and application landing. This plan uses the end-to-end PaddleClas image classification suite to quickly complete the classification. This time, the PaddleClas framework is used to complete the competition.
# git download PaddleClas !git clone https://gitee.com/paddlepaddle/PaddleClas.git --depth=1
fatal: destination path 'PaddleClas' already exists and is not an empty directory.
# install %cd ~/PaddleClas/ !pip install -U pip !pip install -r requirements.txt !pip install -e ./ %cd ~
4, Model training and evaluation
1. Time training
Paddleclas / ppcls / configs / Imagenet / visiontransformer / vit_ small_ patch16_ Modified based on 224.yaml
# global configs
Global:
checkpoints: null
pretrained_model: null
output_dir: ./output/
device: gpu
save_interval: 1
eval_during_train: True
eval_interval: 1
epochs: 120
print_batch_step: 10
use_visualdl: False
# used for static mode and model export
image_shape: [3, 224, 224]
save_inference_dir: ./inference
# model architecture
Arch:
name: ViT_small_patch16_224
class_num: 1000
# loss function config for traing/eval process
Loss:
Train:
- CELoss:
weight: 1.0
Eval:
- CELoss:
weight: 1.0
Optimizer:
name: Momentum
momentum: 0.9
lr:
name: Piecewise
learning_rate: 0.1
decay_epochs: [30, 60, 90]
values: [0.1, 0.01, 0.001, 0.0001]
regularizer:
name: 'L2'
coeff: 0.0001
# data loader for train and eval
DataLoader:
Train:
dataset:
name: ImageNetDataset
image_root: ./dataset/ILSVRC2012/
cls_label_path: ./dataset/ILSVRC2012/train_list.txt
transform_ops:
- DecodeImage:
to_rgb: True
channel_first: False
- RandCropImage:
size: 224
- RandFlipImage:
flip_code: 1
- NormalizeImage:
scale: 1.0/255.0
mean: [0.5, 0.5, 0.5]
std: [0.5, 0.5, 0.5]
order: ''
sampler:
name: DistributedBatchSampler
batch_size: 64
drop_last: False
shuffle: True
loader:
num_workers: 4
use_shared_memory: True
Eval:
dataset:
name: ImageNetDataset
image_root: ./dataset/ILSVRC2012/
cls_label_path: ./dataset/ILSVRC2012/val_list.txt
transform_ops:
- DecodeImage:
to_rgb: True
channel_first: False
- ResizeImage:
resize_short: 256
- CropImage:
size: 224
- NormalizeImage:
scale: 1.0/255.0
mean: [0.5, 0.5, 0.5]
std: [0.5, 0.5, 0.5]
order: ''
sampler:
name: DistributedBatchSampler
batch_size: 64
drop_last: False
shuffle: False
loader:
num_workers: 4
use_shared_memory: True
Infer:
infer_imgs: docs/images/whl/demo.jpg
batch_size: 10
transforms:
- DecodeImage:
to_rgb: True
channel_first: False
- ResizeImage:
resize_short: 256
- CropImage:
size: 224
- NormalizeImage:
scale: 1.0/255.0
mean: [0.5, 0.5, 0.5]
std: [0.5, 0.5, 0.5]
order: ''
- ToCHWImage:
PostProcess:
name: Topk
topk: 5
class_id_map_file: ppcls/utils/imagenet1k_label_list.txt
Metric:
Train:
- TopkAcc:
topk: [1, 5]
Eval:
- TopkAcc:
topk: [1, 5]
# Overlay configuration %cd ~ !cp -f ~/ViT_small_patch16_224.yaml ~/ppcls/configs/ImageNet/VisionTransformer/ViT_small_patch16_224.yaml
/home/aistudio
# Start training
%cd ~/PaddleClas/
!python3 tools/train.py \
-c ./ppcls/configs/ImageNet/VisionTransformer/ViT_base_patch16_224.yaml \
-o Arch.pretrained=True \
-o Global.pretrained_model=./output/ViT_base_patch16_224/epoch_21 \
-o Global.device=gpu
/home/aistudio/PaddleClas
# Model evaluation
%cd ~/PaddleClas/
!python tools/eval.py \
-c ./ppcls/configs/ImageNet/VisionTransformer/ViT_base_patch16_224.yaml \
-o Global.pretrained_model=./output/ViT_base_patch16_224/best_model
2. Weather training
The configuration file is: * * paddleclas / ppcls / configurations / Imagenet / visiontransformer / vit_ base_ patch16_ 224_ weather. yaml**
# global configs
Global:
checkpoints: null
pretrained_model: null
output_dir: ./output_weather/
device: gpu
save_interval: 1
eval_during_train: True
eval_interval: 1
epochs: 120
print_batch_step: 10
use_visualdl: False
# used for static mode and model export
image_shape: [3, 224, 224]
save_inference_dir: ./inference_weather
# model architecture
Arch:
name: ViT_base_patch16_224
class_num: 3
# loss function config for traing/eval process
Loss:
Train:
- CELoss:
weight: 1.0
Eval:
- CELoss:
weight: 1.0
Optimizer:
name: Momentum
momentum: 0.9
lr:
name: Piecewise
learning_rate: 0.01
decay_epochs: [10, 22, 30]
values: [0.01, 0.001, 0.0001, 0.00001]
regularizer:
name: 'L2'
coeff: 0.0001
# data loader for train and eval
DataLoader:
Train:
dataset:
name: ImageNetDataset
image_root: /home/aistudio
cls_label_path: /home/aistudio/train_train_weather_imblearn.txt
transform_ops:
- DecodeImage:
to_rgb: True
channel_first: False
- RandCropImage:
size: 224
- RandFlipImage:
flip_code: 1
- NormalizeImage:
scale: 1.0/255.0
mean: [0.5, 0.5, 0.5]
std: [0.5, 0.5, 0.5]
order: ''
sampler:
name: DistributedBatchSampler
batch_size: 160
drop_last: False
shuffle: True
loader:
num_workers: 4
use_shared_memory: True
Eval:
dataset:
name: ImageNetDataset
image_root: /home/aistudio/
cls_label_path: /home/aistudio/eval_train_weather_imblearn.txt
transform_ops:
- DecodeImage:
to_rgb: True
channel_first: False
- ResizeImage:
resize_short: 256
- CropImage:
size: 224
- NormalizeImage:
scale: 1.0/255.0
mean: [0.5, 0.5, 0.5]
std: [0.5, 0.5, 0.5]
order: ''
sampler:
name: DistributedBatchSampler
batch_size: 128
drop_last: False
shuffle: False
loader:
num_workers: 4
use_shared_memory: True
Infer:
infer_imgs: docs/images/whl/demo.jpg
batch_size: 10
transforms:
- DecodeImage:
to_rgb: True
channel_first: False
- ResizeImage:
resize_short: 256
- CropImage:
size: 224
- NormalizeImage:
scale: 1.0/255.0
mean: [0.5, 0.5, 0.5]
std: [0.5, 0.5, 0.5]
order: ''
- ToCHWImage:
PostProcess:
name: Topk
topk: 5
class_id_map_file: ppcls/utils/imagenet1k_label_list.txt
Metric:
Train:
- TopkAcc:
topk: [1, 2]
Eval:
- TopkAcc:
topk: [1, 2]
# Overlay configuration %cd ~ !cp -f ~/ViT_small_patch16_224_weather.yaml ~/ppcls/configs/ImageNet/VisionTransformer/ViT_small_patch16_224_weather.yaml
# model training
%cd ~/PaddleClas/
!python3 tools/train.py \
-c ./ppcls/configs/ImageNet/VisionTransformer/ViT_base_patch16_224_weather.yaml \
-o Arch.pretrained=True \
-o Global.device=gpu
# Model evaluation
%cd ~/PaddleClas/
!python tools/eval.py \
-c ./ppcls/configs/ImageNet/VisionTransformer/ViT_base_patch16_224_weather.yaml \
-o Global.pretrained_model=./output_weather/ViT_base_patch16_224/best_model
5, Forecast
1. Time model export
# Model export %cd ~/PaddleClas/ !python tools/export_model.py -c ./ppcls/configs/ImageNet/VisionTransformer/ViT_base_patch16_224.yaml -o Global.pretrained_model=./output/ViT_base_patch16_224/best_model
2. Start forecasting
Edit PaddleClas/deploy/python/predict_cls.py to output the forecast results to a file in the submission format.
def main(config):
cls_predictor = ClsPredictor(config)
image_list = get_image_list(config["Global"]["infer_imgs"])
batch_imgs = []
batch_names = []
cnt = 0
# Save to file
f=open('/home/aistudio/result.txt', 'w')
for idx, img_path in enumerate(image_list):
img = cv2.imread(img_path)
if img is None:
logger.warning(
"Image file failed to read and has been skipped. The path: {}".
format(img_path))
else:
img = img[:, :, ::-1]
batch_imgs.append(img)
img_name = os.path.basename(img_path)
batch_names.append(img_name)
cnt += 1
if cnt % config["Global"]["batch_size"] == 0 or (idx + 1
) == len(image_list):
if len(batch_imgs) == 0:
continue
batch_results = cls_predictor.predict(batch_imgs)
for number, result_dict in enumerate(batch_results):
filename = batch_names[number]
clas_ids = result_dict["class_ids"]
scores_str = "[{}]".format(", ".join("{:.2f}".format(
r) for r in result_dict["scores"]))
label_names = result_dict["label_names"]
f.write("{} {}\n".format(filename, clas_ids[0]))
print("{}:\tclass id(s): {}, score(s): {}, label_name(s): {}".
format(filename, clas_ids, scores_str, label_names))
batch_imgs = []
batch_names = []
if cls_predictor.benchmark:
cls_predictor.auto_logger.report()
return
# Overwrite forecast file !cp -f ~/predict_cls.py ~/deploy/python/predict_cls.py
# Start prediction %cd /home/aistudio/PaddleClas/deploy !python3 python/predict_cls.py -c configs/inference_cls.yaml -o Global.infer_imgs=/home/aistudio/test_images -o Global.inference_model_dir=../inference/ -o PostProcess.Topk.class_id_map_file=None
%cd ~ !mv result.txt result_period.txt
/home/aistudio mv: cannot stat 'result.txt': No such file or directory
3. Weather model export
# Model export %cd ~/PaddleClas/ !python tools/export_model.py -c ./ppcls/configs/ImageNet/VisionTransformer/ViT_base_patch16_224_weather.yaml -o Global.pretrained_model=./output_weather/ViT_base_patch16_224/best_model
4. Weather forecast
# Start prediction %cd /home/aistudio/PaddleClas/deploy !python3 python/predict_cls.py -c configs/inference_cls.yaml -o Global.infer_imgs=/home/aistudio/test_images -o Global.inference_model_dir=../inference_weather/ -o PostProcess.Topk.class_id_map_file=None
%cd ~ !mv result.txt result_weather.txt
/home/aistudio
6, Merge and submit
1. Consolidation of forecast results
period_list = { 0:'Dawn', 1:'Dusk', 2:'Morning', 3:'Afternoon'}
weather_list = {0:'Cloudy', 1:'Rainy', 2:'Sunny'}
import pandas as pd
import json
data_period= pd.read_csv('result_period.txt', header=None, sep=' ')
data_weather= pd.read_csv('result_weather.txt', header=None, sep=' ')
annotations_list=[]
for i in range(len(data_period)):
temp={}
temp["filename"]="test_images"+"\\"+data_weather.loc[i][0]
temp["period"]=period_list[data_period.loc[i][1]]
temp["weather"]=weather_list[data_weather.loc[i][1]]
annotations_list.append(temp)
myresult={}
myresult["annotations"]=annotations_list
with open('result.json','w') as f:
json.dump(myresult, f)
ather"]=weather_list[data_weather.loc[i][1]]
annotations_list.append(temp)
myresult={}
myresult["annotations"]=annotations_list
with open('result.json','w') as f:
json.dump(myresult, f)
print("Results generated")
Results generated
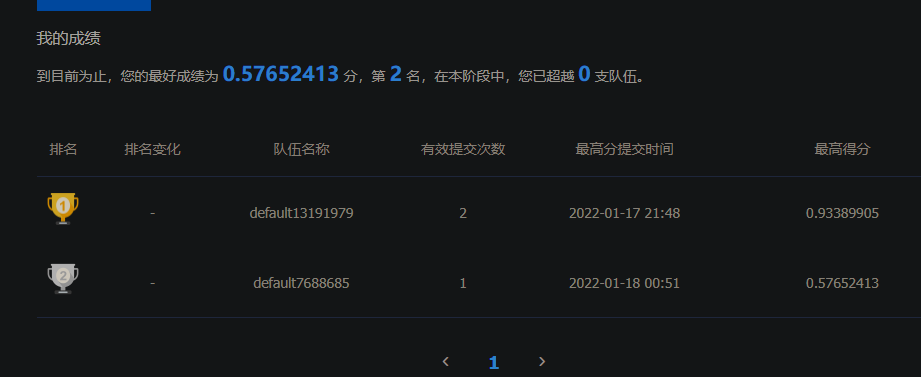
2. Submit and obtain results
Download result JSON and submit to get results
3. Other precautions
When generating the version, you will be prompted that there are invalid soft links that cannot be saved. You can run the following code to clean up under the terminal PaddleClas.
for a in `find . -type l`
do
stat -L $a >/dev/null 2>/dev/null
if [ $? -gt 0 ]
then
rm $a
fi
done