[source code analysis] deep learning distributed training framework horovod (9) - start on spark
0x00 summary
Horovod is an easy-to-use high-performance distributed training framework released by Uber in 2017, which has been widely used in the industry.
This series will lead you to understand horovod through source code analysis. These articles introduce how horovod runs on spark. This is the ninth article, which introduces how to start horovod on spark.
Other articles in this series are as follows:
[source code analysis] deep learning distributed training framework Horovod - (1) basic knowledge
[source code analysis] deep learning distributed training framework horovod (5) - Fusion Framework
[source code analysis] deep learning distributed training framework horovod (8) - on spark
0x01 overall architecture diagram
First of all, we still need to offer the architecture diagram, so that we can follow the diagram.
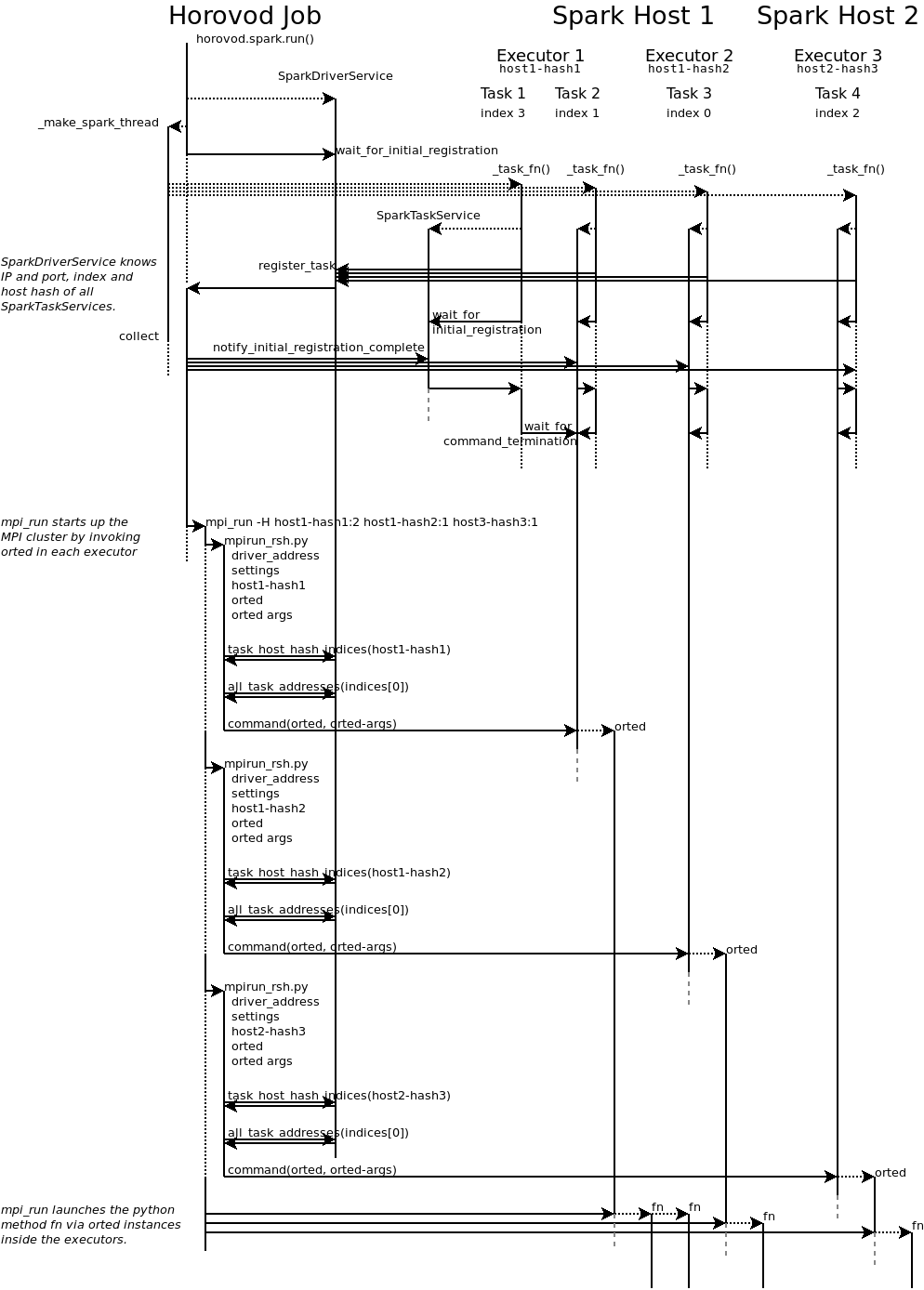
In general, the overall logic of Horovod on Spark is divided into the following stages:
- Start SparkDriverService service and use_ make_spark_thread starts Spark task, and horovod will wait for the start to end;
- Multithreading starts spark task s in the spark executor. One SparkTaskService runs in each task. The SparkTaskService will register with the SparkDriverTask in the host process and wait for the next step to run the start instruction;
- After Horovod receives the information about the end of all tasks, it notifies each task to enter the next stage;
- Horovod calls mpi_run (also using mpirun_rsh.py) starts the p orted process on each spark executor to start the MPI cluster;
- orted runs the training code on each executor;
Let's take a look at how to start.
0x02 phase I: Horovod start
The main logic of this part is to start the SparkDriverService service and use_ make_spark_thread starts Spark task, and horovod will wait for the start to end.
2.1 Driver service: SparkDriverService
SparkDriverService inherits driver_ service. Basic driverservice, so a socket server is started inside it for network interaction.
Horovod uses SparkDriverService to interact with Spark executor (through the SparkTaskService running in it), such as collecting information, asking spark to start training job, etc. This is an RPC mechanism.
For specific functions of SparkDriverService, please refer to various requests processed internally, such as
- CodeRequest: SparkTaskService will be used to request user code;
- TaskHostHashIndicesRequest: get the task host address;
- TaskIndexByRankRequest: Get task index from rank;
- SetLocalRankToRankRequest: get rank information from local rank;
- WaitForTaskShutdownRequest: wait for shutdown;
It is similar to the HorovodRunDriverService described earlier.
Where, its member variable_ fn is the training function. In the future, when SparkTaskService requests code, it will send it through CodeResponse_ fn send it back directly. This solves the code release problem.
class SparkDriverService(driver_service.BasicDriverService):
NAME = 'driver service'
def __init__(self, initial_np, num_proc, fn, args, kwargs, key, nics):
super(SparkDriverService, self).__init__(num_proc,
SparkDriverService.NAME,
key, nics)
self._initial_np = initial_np
self._fn = fn # Save user code
self._args = args # User parameters
self._kwargs = kwargs
self._key = key
self._nics = nics # Network card information
self._ranks_to_indices = {}
self._spark_job_failed = False
self._lock = threading.Lock()
self._task_shutdown = threading.Event()
def _handle(self, req, client_address):
if isinstance(req, TaskHostHashIndicesRequest): # Get task host address
return TaskHostHashIndicesResponse(self._task_host_hash_indices[req.host_hash])
if isinstance(req, SetLocalRankToRankRequest): # Get rank information from local rank
self._lock.acquire()
try:
# get index for host and local_rank
indices = self._task_host_hash_indices[req.host]
index = indices[req.local_rank]
values = list(self._ranks_to_indices.values())
prev_pos = values.index(index) if index in values else None
if prev_pos is not None:
prev_rank = list(self._ranks_to_indices.keys())[prev_pos]
del self._ranks_to_indices[prev_rank]
# memorize rank's index
self._ranks_to_indices[req.rank] = index
finally:
self._lock.release()
return SetLocalRankToRankResponse(index)
if isinstance(req, TaskIndexByRankRequest): # Get task index from rank
self._lock.acquire()
try:
return TaskIndexByRankResponse(self._ranks_to_indices[req.rank])
finally:
self._lock.release()
if isinstance(req, CodeRequest): # SparkTaskService will be used to request user code
return CodeResponse(self._fn, self._args, self._kwargs)
if isinstance(req, WaitForTaskShutdownRequest): # Wait for the end of the task
self._task_shutdown.wait()
return network.AckResponse()
return super(SparkDriverService, self)._handle(req, client_address)
2.2 start spark task:_ make_ spark_ thread
In horovod spark. In run_ make_spark_thread establishes a thread. The key codes here are:
mapper = _make_mapper(driver.addresses(), settings, use_gloo, is_elastic) result = procs.mapPartitionsWithIndex(mapper).collect()
The code mappartitions with index will cause Spark to run the mapper function among multiple executors and get the running results.
Settings are created num_ Proc contains Spark tasks. Each task will run mapper (_task_fn), and the external run function will wait for these execution results. In fact, if you need to use RDD, you may use foreachPartition, so that each node will hold a partition of RDD in memory.
def _make_spark_thread(spark_context, spark_job_group, driver, result_queue,
settings, use_gloo, is_elastic):
"""Creates `settings.num_proc` Spark tasks in a parallel thread."""
def run_spark():
"""Creates `settings.num_proc` Spark tasks, each executing `_task_fn` and waits for them to terminate."""
try:
spark_context.setJobGroup(spark_job_group, "Horovod Spark Run", interruptOnCancel=True)
procs = spark_context.range(0, numSlices=settings.max_np if settings.elastic else settings.num_proc)
# We assume that folks caring about security will enable Spark RPC encryption,
# thus ensuring that key that is passed here remains secret.
mapper = _make_mapper(driver.addresses(), settings, use_gloo, is_elastic)
# Make Spark run the mapper function among multiple executors and get the running results
result = procs.mapPartitionsWithIndex(mapper).collect()
result_queue.put(result)
except:
driver.notify_spark_job_failed()
raise
spark_thread = in_thread(target=run_spark, daemon=False)
return spark_thread
2.3 wait for spark task to start and finish
After the spark task is started, the horovod main process will call and wait for all tasks to be started.
# wait for all tasks to register, notify them and initiate task-to-task address registration _notify_and_register_task_addresses(driver, settings)
That is, in the run function, when_ make_ spark_ After the thread, the horovod main process calls_ notify_and_register_task_addresses, which calls driver wait_ for_ initial_ Registration (settings. Start_timeout) for overall waiting.
The waiting content is: wait for all num_proc tasks to register. When all spark thread s are ready, the main horovod process will continue to run.
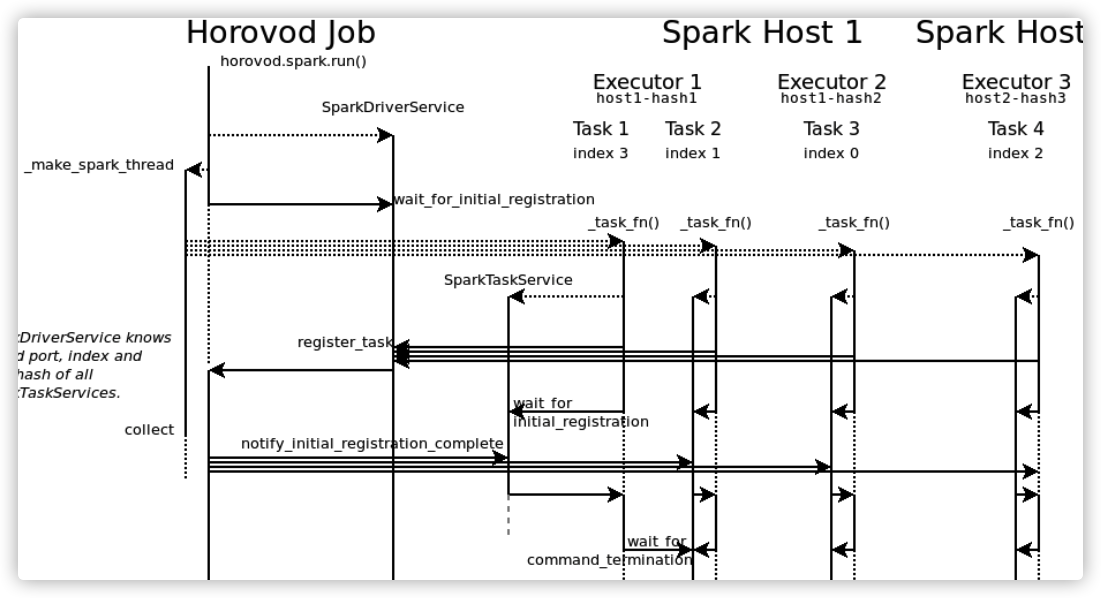
2.3.1 _notify_and_register_task_addresses
In the horovod main process, the_ notify_and_register_task_addresses to wait for these spark task s to register, thus calling driver wait_ for_ initial_ Registration (settings. Start_timeout) for overall waiting.
Note that after sending the registration request at the same time, spark task also calls task wait_ for_ initial_ Registration waits for horovod to notify the start of the next phase.
In the main process of horovod_ notify_and_register_task_addresses are also complicated:
- Call driver wait_ for_ initial_ Registration: wait for task to register. You need to wait for num_proc task;
- Using notify_and_register registers tasks and notifies each task to start the next step;
The specific codes are as follows:
def _notify_and_register_task_addresses(driver, settings, notify=True):
# wait for num_proc tasks to register
# Wait for task to register. You need to wait for num_proc tasks
driver.wait_for_initial_registration(settings.start_timeout)
def notify_and_register(index): # Register tasks and notify each task to start the next step
task_client = task_service.SparkTaskClient(index,
driver.task_addresses_for_driver(index),
settings.key, settings.verbose)
if notify:
task_client.notify_initial_registration_complete()
next_task_index = (index + 1) % settings.num_proc
next_task_addresses = driver.all_task_addresses(next_task_index)
task_to_task_addresses = task_client.get_task_addresses_for_task(next_task_index, next_task_addresses)
driver.register_task_to_task_addresses(next_task_index, task_to_task_addresses)
for index in driver.task_indices():
in_thread(notify_and_register, (index,)) #Start task in thread
driver.wait_for_task_to_task_address_updates(settings.start_timeout)
We can only look at the first step "waiting for registration".
2.3.2 driver.wait_for_initial_registration
Here, sparkdriverservice first waits for all spark executor s to register.
In class BasicDriverService(network.BasicService): there is the following code. You can see that only all_ num_ After the proc registration is completed, when all spark thread s are ready, the main horovod process will continue to run.
The key here is: while len (self._all_task_addresses) < self_ num_proc is waiting for self_ all_ task_ The number of addresses reached_ num_proc.
class BasicDriverService(network.BasicService):
def wait_for_initial_registration(self, timeout):
self._wait_cond.acquire()
try:
# Wait for self_ all_ task_ The number of addresses reached_ num_proc
while len(self._all_task_addresses) < self._num_proc:
self._wait_cond.wait(timeout.remaining())
timeout.check_time_out_for('tasks to start')
finally:
self._wait_cond.release()
2.4 waiting
For the waiting code, we need to make a special description. See the figure for details.
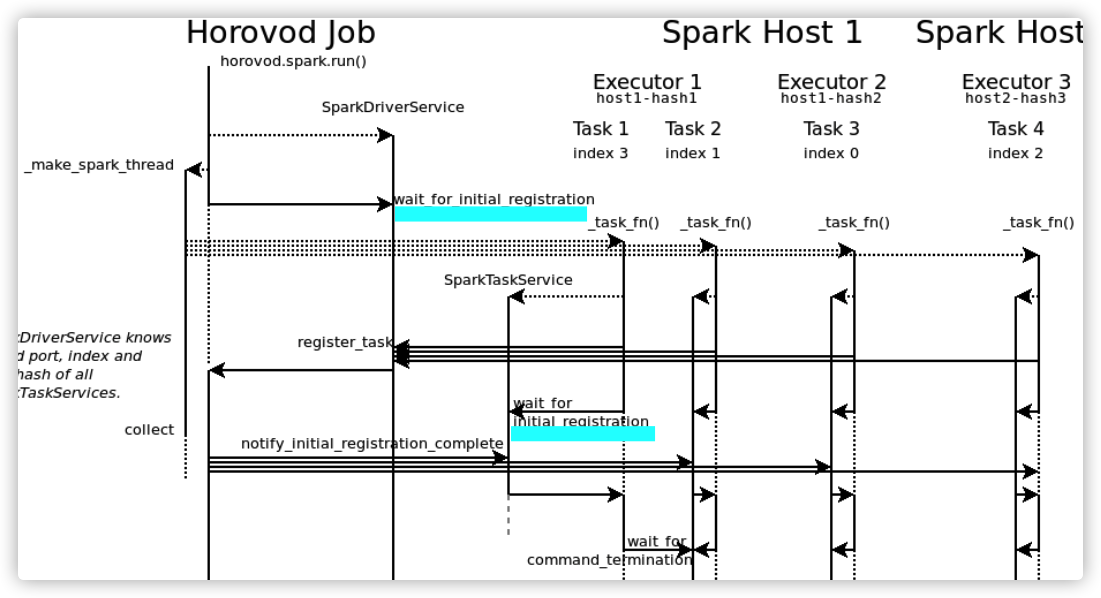
Here are two sets of wait_for_initial_registration. It can be considered as two sets of barrier s.
namely:
- barrier 1: sparkdriverservice waits for all sparktaskservices to be ready;
- Barrier 2: all sparktaskservces need to run together, so sparktaskservces are waiting for barrier 2. Sparkdriverservice will notify these sparktaskservces to launch together;
2.3.1 Barrier 1 in Driver
In the run function, when_ make_ spark_ After the thread, the horovod main process calls_ notify_and_register_task_addresses, which calls driver wait_ for_ initial_ Registration (settings. Start_timeout) for overall waiting.
The waiting content is: wait for all num_proc tasks to register. When all spark thread s are ready, the main horovod process will continue to run. The key here is:
while len(self._all_task_addresses) < self._num_proc
Just wait for self_ all_ task_ The number of addresses reached_ num_proc.
def wait_for_initial_registration(self, timeout):
self._wait_cond.acquire()
try:
while len(self._all_task_addresses) < self._num_proc:
self._wait_cond.wait(timeout.remaining())
timeout.check_time_out_for('tasks to start')
finally:
self._wait_cond.release()
In BasicDriverService, if you receive a registration request from spark executor, you can process it. The most important things here are:
self._all_task_addresses[req.index] = req.task_addresses
When all spark executor s are registered, we wait for success.
2.3.2 Barrier 2 in task
Each spark thread is_ task_ Running in FN means running in spark task. It can also be seen here that it is an overall process of spark task:
- First call register_task;
- Next, call task wait_ for_ initial_ registration(settings.start_timeout) ;
- Then call wait_. for_ command_ Termination to wait for the end;
task.wait_for_initial_registration will wait for self_ initial_ registration_ The condition of complete = true is to wait for register_task registration completed.
Each Spark Executor has a SparkTaskService, so each spark task has its own_ initial_registration_complete.
hovorod. The run main process will notify each SparkTaskService one by one_ initial_registration_complete.
That is to say, if a SparkTaskService is ready, it will notify the owner of the SparkTaskService_ initial_registration_complete. In this way, the SparkTaskService can be officially run.
2.3.3 overall waiting process
The overall waiting process is shown in the figure. The number is the execution sequence:
- Sparkdriverservice calls driver wait_ for_ initial_ Registration to wait for the registration of sparktaskservice, which is barrier 1;
- Sparktaskservice 1 registers, and then sparktaskservice 1 calls task itself wait_ for_ initial_ Registration waits for horovod to notify the start of the next phase, which is barrier 2;
- Sparktaskservice 2 registers, and then sparktaskservice 2 calls task itself wait_ for_ initial_ Registration waits for horovod to notify the start of the next phase, which is barrier 2;
- hovorod. After the run main process finds that all tasks are registered, barrier 1 waits for the end and will notify each SparkTaskService one by one_ initial_registration_complete. Only after 4 is completed can two sparktaskservces continue to execute 5 and 6;
- Sparktaskservice 1 waits for barrier 2 and continues to execute;
- Sparktaskservice 2 waits for the completion of barrier 2 and continues to execute;
SparkTaskSerivce 1 SparkTaskSerivce 2 SparkDriverSerivce
+ + +
| | |
| | |
| | |
| | | 1
| | |
| | |
| | v
| |
| | +--------------------------------------+
| | | barrier 1 |
| | 2 | |
| 3 +-------> | |
| | | |
+-----------------------------------> | driver.wait_for_initial_registration |
| | | |
| | | |
| | | |
| | +--------------------+-----------------+
| | |
| | |
+-----------+----------------------+ | 4 |
|barrier 2 | <---------------------------------+
| | | |
|task.wait_for_initial_registration| | |
| | | |
+-----------+----------------------+ | |
| | |
| +-------------+----------------------+ |
| | barrier 2 | 4 |
| 6 | +<------+
| | task.wait_for_initial_registration | |
| | | |
| +-------------+----------------------+ |
| | |
| | |
| | 5 |
| | |
v v v
Next, we will introduce the task startup content and the subsequent work of driver in detail.
0x03 phase II: Spark Task start
In this stage, we will introduce the startup process of Spark Task in detail.
The main functions of this part are: multithreading starts spark tasks in spark executor, and each spark task will run_ task_fn function_ task_fn function will run a SparkTaskService, SparkTaskService will register with SparkDriverTask in the main process of hovorod, and wait for the instruction to start in the next step;
At this time, the program (not the training program, but the SparkTaskService) has been running inside the spark Executor. Let's see how to start and run SparkTaskService in spark Executor.
3.1 specific spark start logic:_ task_fn
Horovod passes through the thread_ make_mapper to make Spark run_ task_fn.
def _make_mapper(driver_addresses, settings, use_gloo, is_elastic):
def _mapper(index, _):
yield _task_fn(index, driver_addresses, key, settings, use_gloo, is_elastic)
return _mapper
_ task_fn is used to register horovod and enter spark task. That is, start a SparkTaskService in each spark task (executor).
It must be noted that these sparktaskservices run in spark executor and interact with SparkDriverService in horovod through the network.
As you can see_ task_ The overall logic of FN is:
- Start SparkTaskService;
- Via driver_service.SparkDriverClient.register_task to register with the Driver in horovod;
- Through task wait_ for_ initial_ Registration (settings. Start_timeout) to wait for the start indication of the next start;
- If the next step starts, call task wait_ for_ command_ Termination() wait for the end;
The details are as follows:
def _task_fn(index, driver_addresses, key, settings, use_gloo, is_elastic):
settings.key = key
hosthash = host_hash(salt='{}-{}'.format(index, time.time()) if is_elastic else None)
os.environ['HOROVOD_HOSTNAME'] = hosthash
# Start the SparkTaskService. The SparkTaskService itself includes a socket server that can interact with the driver
task = task_service.SparkTaskService(index, settings.key, settings.nics,...)
try:
driver_client = driver_service.SparkDriverClient(driver_addresses, settings.key, settings.verbose)
# Register with Driver in horovod
driver_client.register_task(index, task.addresses(), hosthash)
# It's still running in spark task, but it's not SparkTaskService, so it's just doing assistance work, and finally waiting quietly
if not is_elastic:
# Wait for the start indication of the next start
task.wait_for_initial_registration(settings.start_timeout)
task_indices_on_this_host = driver_client.task_host_hash_indices(hosthash)
local_rank_zero_index = task_indices_on_this_host[0]
else:
local_rank_zero_index = None
if is_elastic:
...... # The following articles will introduce
elif use_gloo or index == local_rank_zero_index:
# Either Gloo or first task with MPI.
# Use Gloo or the first task of MPI to make this task operate
task.wait_for_command_start(settings.start_timeout)
# Wait for the end
task.wait_for_command_termination()
else:
# The other tasks with MPI need to wait for the first task to finish.
# Let other tasks wait for the end of the first task
first_task_addresses = driver_client.all_task_addresses(local_rank_zero_index)
first_task_client = \
task_service.SparkTaskClient(local_rank_zero_index,
first_task_addresses, settings.key,
settings.verbose)
# Call task wait_ for_ command_ Termination() wait for the end
first_task_client.wait_for_command_termination()
return task.fn_result()
finally:
task.shutdown()
3.2 SparkTaskService
Re emphasize the following codes:
task = task_service.SparkTaskService(index, settings.key, settings.nics,...)
Each_ task_fn defines a SparkTaskService, that is, each Spark Executor will generate one (or more) sparktaskservices to run and function in spark task s.
3.2.1 SparkTaskService definition
The definition of SparkTaskService is as follows. Because it inherits BasicTaskService, a socket server will eventually be started inside it to interact with SparkDriverService in horovod:
class SparkTaskService(task_service.BasicTaskService):
NAME_FORMAT = 'task service #%d'
def __init__(self, index, key, nics, minimum_command_lifetime_s, verbose=0):
# on a Spark cluster we need our train function to see the Spark worker environment
# this includes PYTHONPATH, HADOOP_TOKEN_FILE_LOCATION and _HOROVOD_SECRET_KEY
env = os.environ.copy()
# we inject the secret key here
env[secret.HOROVOD_SECRET_KEY] = codec.dumps_base64(key)
# we also need to provide the current working dir to mpirun_exec_fn.py
env['HOROVOD_SPARK_WORK_DIR'] = os.getcwd()
super(SparkTaskService, self).__init__(SparkTaskService.NAME_FORMAT % index,
index, key, nics, env, verbose)
self._key = key
self._minimum_command_lifetime_s = minimum_command_lifetime_s
self._minimum_command_lifetime = None
3.2.2 basic functions
The basic functions of SparkTaskService are as follows.
- _ run_command will be used to start the training job in spark;
- _ handle will process GetTaskToTaskAddressesRequest to obtain the task address, and will also process ResourcesRequest to return resources;
- _ get_resources will return spark resources;
- wait_for_command_termination will wait for the end of command execution;
The specific codes are as follows:
def _run_command(self, command, env, event,
stdout=None, stderr=None, index=None,
prefix_output_with_timestamp=False):
# Start the training job in spark
super(SparkTaskService, self)._run_command(command, env, event,
stdout, stderr, index,
prefix_output_with_timestamp)
if self._minimum_command_lifetime_s is not None:
self._minimum_command_lifetime = timeout.Timeout(self._minimum_command_lifetime_s,
message='Just measuring runtime')
def _handle(self, req, client_address):
# Return resource
if isinstance(req, ResourcesRequest):
return ResourcesResponse(self._get_resources())
# Get task address
if isinstance(req, GetTaskToTaskAddressesRequest):
next_task_index = req.task_index
next_task_addresses = req.all_task_addresses
# We request interface matching to weed out all the NAT'ed interfaces.
next_task_client = \
SparkTaskClient(next_task_index, next_task_addresses,
self._key, self._verbose,
match_intf=True)
return GetTaskToTaskAddressesResponse(next_task_client.addresses())
return super(SparkTaskService, self)._handle(req, client_address)
def _get_resources(self):
# Return spark resource
if LooseVersion(pyspark.__version__) >= LooseVersion('3.0.0'):
task_context = pyspark.TaskContext.get()
if task_context:
return task_context.resources()
else:
print("Not running inside Spark worker, no resources available")
return dict()
def wait_for_command_termination(self):
"""
Waits for command termination. Ensures this method takes at least
self._minimum_command_lifetime_s seconds to return after command started.
"""
try:
# Wait for the end of command execution
return super(SparkTaskService, self).wait_for_command_termination()
finally:
# command terminated, make sure this method takes at least
# self._minimum_command_lifetime_s seconds after command started
# the client that started the command needs some time to connect again
# to wait for the result (see horovod.spark.driver.rsh).
if self._minimum_command_lifetime is not None:
time.sleep(self._minimum_command_lifetime.remaining())
3.3 registering tasks
The next step is to register the task with the Driver.
driver_client.register_task(index, task.addresses(), hosthash)
3.3.1 send registration request
The registration is completed as follows. Here we call network PY_ The send function carries out network interaction through socket, spark executor and horovod driver:
class BasicDriverClient(network.BasicClient):
def register_task(self, index, task_addresses, host_hash):
self._send(RegisterTaskRequest(index, task_addresses, host_hash))
3.3.2 Driver handling
Let's take a look at the Driver running in Horovod (see the next section in advance).
In the basic driver service, if a registertaskerequest request is received, it will be processed. The most important things here are:
self._all_task_addresses[req.index] = req.task_addresses
So, self_ all_ task_ The number of addresses increases.
As we mentioned earlier, horovod is driving wait_ for_ initial_ The key to waiting for registration is:
while len(self._all_task_addresses) < self._num_proc
If self_ all_ task_ The number of addresses has reached_ num_proc,driver. wait_ for_ initial_ The registration is over and the implementation is smooth.
The specific code for handling registertaskerequest is as follows. There are various member variables in BasicDriverService to maintain various required information. We [original] above [source code analysis] deep learning distributed training framework horovod (4) - Network Foundation & Driver It has been explained in detail in_ The registertaskerequest processing of the handle function is used to update these member variables:
class BasicDriverService(network.BasicService):
def _handle(self, req, client_address):
if isinstance(req, RegisterTaskRequest):
self._wait_cond.acquire()
try:
self._all_task_addresses[req.index] = req.task_addresses
# Just use source address for service for fast probing.
self._task_addresses_for_driver[req.index] = \
self._filter_by_ip(req.task_addresses, client_address[0])
# Remove host hash earlier registered under this index.
if req.index in self._task_index_host_hash:
earlier_host_hash = self._task_index_host_hash[req.index]
if earlier_host_hash != req.host_hash:
self._task_host_hash_indices[earlier_host_hash].remove(req.index)
# Make index -> host hash map.
self._task_index_host_hash[req.index] = req.host_hash
# Make host hash -> indices map.
if req.host_hash not in self._task_host_hash_indices:
self._task_host_hash_indices[req.host_hash] = []
self._task_host_hash_indices[req.host_hash].append(req.index)
# TODO: this sorting is a problem in elastic horovod
self._task_host_hash_indices[req.host_hash].sort()
finally:
self._wait_cond.notify_all()
self._wait_cond.release()
return network.AckResponse()
3.4 the task waits for the next notification
As mentioned earlier, when Spark task sends a registration request to the driver, Spark task passes task wait_ for_ initial_ Registration (settings. Start_timeout) to wait for the start indication of the next start. The driver thinks that you have completed the registration of one scene and can start to move on to the next step.
task.wait_for_initial_registration will wait for self_ initial_ registration_ The condition of complete = true is to wait for register_task registration completed.
class BasicTaskService(network.BasicService):
def wait_for_initial_registration(self, timeout):
self._wait_cond.acquire()
try:
while not self._initial_registration_complete:
self._wait_cond.wait(timeout.remaining())
timeout.check_time_out_for('tasks to start')
finally:
self._wait_cond.release()
Each Spark Executor has a SparkTaskService, so each spark task has its own_ initial_registration_complete.
hovorod. The run main process will notify each SparkTaskService one by one_ initial_registration_complete. That is to say, if a SparkTaskService is ready, it will notify the owner of the SparkTaskService_ initial_registration_complete.
hovorod. The run main process completes this step by sending NotifyInitialRegistrationCompleteRequest.
def notify_initial_registration_complete(self):
self._send(NotifyInitialRegistrationCompleteRequest())
BasicTaskService is waiting for NotifyInitialRegistrationCompleteRequest. If it receives it, it will be set to True so that it can wait_for_initial_registration will wait for the end.
if isinstance(req, NotifyInitialRegistrationCompleteRequest):
self._wait_cond.acquire()
try:
self._initial_registration_complete = True
finally:
self._wait_cond.notify_all()
self._wait_cond.release()
return network.AckResponse()
This means that after the thread is registered in horovod, even if the spark thread is started successfully.
+-------------------------------------+ +----------------------------------------------------+ | Horovod Main thread | | Spark Executor | | | | _task_fn | | | | + | | | | | | | | | | | | | | v | | +-------------------------------+ | | +---------------------+------------------------+ | | | SparkDriverService | | | | SparkTaskService | | | | | | | | + | | | | | | 1 register | | | | | | | self._all_task_addresses <----------------------------------------+ | | | | | | | | | | | | | + | | | | | | | | | | | | | | | | | | | | 3 | | | | | | | | | | | | | | | 2 | | | | v | | | | | | | | | self._wait_cond.notify_all() | | | | | | | | | + | | | | v | | | | | | | | | +---------+---------------------------+ | | | | | | | | | | | | | | | | | | | | | task.wait_for_initial_registration | | | | | | | | | | | | | | | | | | | | | +-------------------------------------+ | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | v | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | +-------------------------------+ | | +----------------------------------------------+ | +-------------------------------------+ +----------------------------------------------------+
Mobile phones are as follows:

0x04 stage 3: Driver notifies task of successful registration
The function of this stage is: after Horovod receives the completion information of all tasks, it notifies each task to enter the next stage.
4.1 _notify_and_register_task_addresses
Mentioned earlier. In the horovod main process, the_ notify_and_register_task_addresses to wait for these spark task s to register, thus calling driver wait_ for_ initial_ Registration (settings. Start_timeout) for overall waiting.
Note that after sending the registration request at the same time, spark task also calls task wait_ for_ initial_ Registration waits for horovod to notify the start of the next phase.
And_ notify_and_register_task_addresses is also complicated:
- Call driver wait_ for_ initial_ Registration: wait for the task to register; (this step has been completed)
- Using notify_and_register registers tasks and notifies each task to start the next step; (let's move on to the next two steps)
- Using driver wait_ for_ task_ to_ task_ address_ Update again, confirm that all tasks are OK;
def _notify_and_register_task_addresses(driver, settings, notify=True):
# wait for num_proc tasks to register
driver.wait_for_initial_registration(settings.start_timeout)
def notify_and_register(index):
# Register tasks and notify each task to start the next step
task_client = task_service.SparkTaskClient(index,
driver.task_addresses_for_driver(index),
settings.key, settings.verbose)
if notify:
task_client.notify_initial_registration_complete()
next_task_index = (index + 1) % settings.num_proc
next_task_addresses = driver.all_task_addresses(next_task_index)
task_to_task_addresses = task_client.get_task_addresses_for_task(next_task_index, next_task_addresses)
driver.register_task_to_task_addresses(next_task_index, task_to_task_addresses)
for index in driver.task_indices():
in_thread(notify_and_register, (index,)) # Register tasks and notify each task to start the next step
# Confirm again that all task s are OK
driver.wait_for_task_to_task_address_updates(settings.start_timeout)
4.2 notify_and_register
You can see notify_ and_ The function of register is:
- Call task_client.notify_initial_registration_complete() notifies spark that the task registration is successful, which makes all waiting tasks wait_ for_ initial_ Run the next phase together with the spark executor of registration.
- Call Driver register_ task_ to_ task_ Addresses (next_task_index, task_to_task_addresses) to let the Driver complete the registration.
def wait_for_task_to_task_address_updates(self, timeout):
self._wait_cond.acquire()
try:
while len(self._task_addresses_for_tasks) < self._initial_np:
self.check_for_spark_job_failure()
self._wait_cond.wait(timeout.remaining())
timeout.check_time_out_for('Spark tasks to update task-to-task addresses')
finally:
self._wait_cond.release()
4.3 wait_for_task_to_task_address_updates
Here you will confirm again that all spark task s are OK.
def wait_for_task_to_task_address_updates(self, timeout):
self._wait_cond.acquire()
try:
while len(self._task_addresses_for_tasks) < self._initial_np:
self.check_for_spark_job_failure()
self._wait_cond.wait(timeout.remaining())
timeout.check_time_out_for('Spark tasks to update task-to-task addresses')
finally:
self._wait_cond.release()
4.4 waiting for In Task
In Spark task, if the next start instruction is received, wait will be called_ for_ command_ Wait for termination.
In fact, this step means that the logical task of spark executor itself is over, because in the future, SparkTaskService will complete the action independently, which is responsible for starting the training code. Since_ task_fn's logical task is over, just wait quietly.
4.4.1 wait_for_command_termination
In horovod master / horovod / spark / task / task_ service. py
def wait_for_command_termination(self):
"""
Waits for command termination. Ensures this method takes at least
self._minimum_command_lifetime_s seconds to return after command started.
"""
try:
return super(SparkTaskService, self).wait_for_command_termination()
finally:
# command terminated, make sure this method takes at least
# self._minimum_command_lifetime_s seconds after command started
# the client that started the command needs some time to connect again
# to wait for the result (see horovod.spark.driver.rsh).
if self._minimum_command_lifetime is not None:
time.sleep(self._minimum_command_lifetime.remaining())
In horovod master / horovod / Runner / common / service / task_ service. As you can see in py, wait for the thread where the training code is located to end.
def wait_for_command_termination(self):
self._command_thread.join() # It will be explained soon
4.4.2 _command_thread
Right here_ command_thread for a brief description.
When the SparkTaskService processes the RunCommandRequest, the thread of the running Command is assigned as_ command_thread.
class BasicTaskService(network.BasicService):
def _handle(self, req, client_address):
if isinstance(req, RunCommandRequest): # Run command request
self._wait_cond.acquire()
try:
if self._command_thread is None:
if self._command_env:
env = self._command_env.copy()
self._add_envs(env, req.env)
req.env = env
self._command_abort = threading.Event()
self._command_stdout = Pipe() if req.capture_stdout else None
self._command_stderr = Pipe() if req.capture_stderr else None
# Configure various parameter information
args = (req.command, req.env, self._command_abort,
self._command_stdout, self._command_stderr,
self._index,
req.prefix_output_with_timestamp)
# Start a new thread to run the command
self._command_thread = in_thread(self._run_command, args)
finally:
self._wait_cond.notify_all()
self._wait_cond.release()
return network.AckResponse()
The logic is as follows:
+-------------------------------------+ +----------------------------------------------------+ | Horovod Main thread | | Spark Executor | | | | _task_fn | | | | + | | | | | | | | | | | | | | v | | +-------------------------------+ | | +---------------------+------------------------+ | | | SparkDriverService | | | | SparkTaskService | | | | | | | | + | | | | | | 1 register | | | | | | | self._all_task_addresses <----------------------------------------+ | | | | | | | | | | | | | + | | | | | | | | | | | | | | | | | | | | 3 | | | | | | | | | | | | | | | 2 | | | | v | | | | | | | | | self._wait_cond.notify_all() | | | | | | | | | + | | | | v | | | | | | + + + +---------+---------------------------+ | | | | | 4 | RegistrationComplete | | | | | | | +-----------------+-------------+--+---> | task.wait_for_initial_registration | | | | | | | | | | | | | | | | | | | | | +---------+---------------------------+ | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | 5 | | | | | | | | | | | | | | | | | | | | | | | | | | | | | v | | | | | | | | | wait_for_command_termination | | | | | | 6 | RunCommand | | + | | | | | | | | | | | | | | +-----------------------------------------------> | 7 | | | | | | | | | v | | | | v | | | | self._command_thread.join() | | | | | | | | | | | | | | | | | | | | | | | | | | | +-------------------------------+ | | +----------------------------------------------+ | +-------------------------------------+ +----------------------------------------------------+
Mobile phones are as follows:

So far, the first stage is completed. Let's continue with the next one. Please look forward to it.
0x05 summary
In general, the overall logic of Horovod on Spark is divided into the following stages:
- Start SparkDriverService service and use_ make_spark_thread starts Spark task, and horovod will wait for the start to end;
- Multithreading starts spark task s in the spark executor. One SparkTaskService runs in each task. The SparkTaskService will register with the SparkDriverTask in the host process and wait for the next step to run the start instruction;
- After Horovod receives the information about the end of all tasks, it notifies each task to enter the next stage;
- Horovod calls mpi_run (also using mpirun_rsh.py) starts p orted on each spark executor to start the MPI cluster;
- orted runs the training code on each executor;
This paper introduces the first three stages, namely the start-up stage. The next two phases are described below. Please look forward to them.
0xEE personal information
★★★★★★★ thinking about life and technology ★★★★★★
Wechat public account: Rossi's thinking
If you want to get the news push of personal articles in time, or want to see the technical materials recommended by yourself, please pay attention.
