catalogue
0 demand analysis
Requirements: table below
| user_id | good_name | goods_type | rk |
| 1 | hadoop | 10 | 1 |
| 1 | hive | 12 | 2 |
| 1 | sqoop | 26 | 3 |
| 1 | hbase | 10 | 4 |
| 1 | spark | 13 | 5 |
| 1 | flink | 26 | 6 |
| 1 | kafka | 14 | 7 |
| 1 | oozie | 10 | 8 |
In the above data, goods_ The type column, assuming that 26 represents advertising, now there is a demand to obtain the natural ranking of non advertising commodity positions under each user's search. If the following effect:
| user_id | good_name | goods_type | rk | naturl_rk |
| 1 | hadoop | 10 | 1 | 1 |
| 1 | hive | 12 | 2 | 2 |
| 1 | sqoop | 26 | 3 | null |
| 1 | hbase | 10 | 4 | 3 |
| 1 | spark | 13 | 5 | 4 |
| 1 | flink | 26 | 6 | null |
| 1 | kafka | 14 | 7 | 5 |
| 1 | oozie | 10 | 8 | 6 |
1 data preparation
(1) Build table
create table window_goods_test ( user_id int, --user id goods_name string, --Trade name goods_type int, --Identify the type of each product, such as advertising and non advertising rk int --For example, the first advertising product is 1, followed by 2, 3 and 4... )ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
(2) Data
vim window_goods_test
1 hadoop 10 1 1 hive 12 2 1 sqoop 26 3 1 hbase 10 4 1 spark 13 5 1 flink 26 6 1 kafka 14 7 1 oozie 10 8
(3) loading data
load data local inpath "/home/centos/dan_test/window_goods_test.txt" into table window_goods_test;
(4) Query data
21/06/25 11:35:33 INFO DAGScheduler: Job 2 finished: processCmd at CliDriver.java:376, took 0.209632 s 1 hadoop 10 1 1 hive 12 2 1 sqoop 26 3 1 hbase 10 4 1 spark 13 5 1 flink 26 6 1 kafka 14 7 1 oozie 10 8 Time taken: 0.818 seconds, Fetched 8 row(s) 21/06/25 11:35:33 INFO CliDriver: Time taken: 0.818 seconds, Fetched 8 row(s)
3 data analysis
analysis
From the result table, you only need to add a column as a row sequence, which is just to add goods_ The type column removes the reordering, so it's easy to think of using window functions to solve the sorting problem row_number() can be solved successfully. So it's easy to write the following SQL:
select
user_id,
goods_name,
goods_type,
rk,
case when goods_type!=26 then row_number() over(partition by user_id order by rk) else null end as naturl_rank
from window_goods_testThe results are as follows:
1 hadoop 10 1 1 1 hive 12 2 2 1 sqoop 26 3 NULL 1 hbase 10 4 4 1 spark 13 5 5 1 flink 26 6 NULL 1 kafka 14 7 7 1 oozie 10 8 8 Time taken: 2.858 seconds, Fetched 8 row(s)
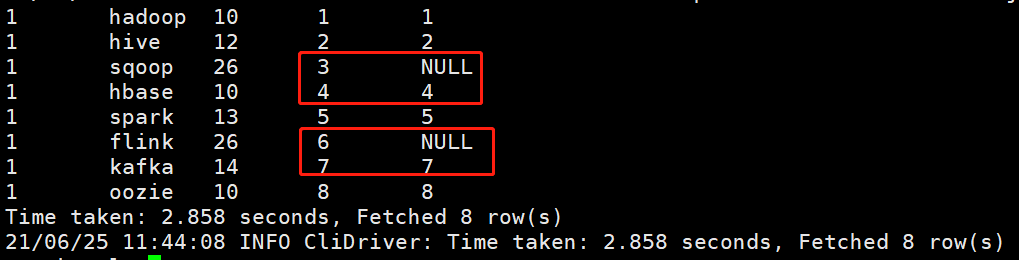 From the results, we can see that it is not natural sorting, and it is not the final target result we want. From the perspective of implementation, there is no problem with logic elimination. What is the problem? The reason is that I don't know the execution principle and sequence of window functions. Let's take a closer look at the execution process of this SQL through the execution plan. The SQL is as follows:
From the results, we can see that it is not natural sorting, and it is not the final target result we want. From the perspective of implementation, there is no problem with logic elimination. What is the problem? The reason is that I don't know the execution principle and sequence of window functions. Let's take a closer look at the execution process of this SQL through the execution plan. The SQL is as follows:
explain select
user_id,
goods_name,
goods_type,
rk,
case when goods_type!=26 then row_number() over(partition by user_id order by rk) else null end as naturl_rank
from window_goods_testThe specific implementation plan is as follows:
== Physical Plan ==
*Project [user_id#67, goods_name#68, goods_type#69, rk#70, CASE WHEN NOT (goods_type#69 = 26) THEN _we0#72 ELSE null END AS naturl_rank#64]
+- Window [row_number() windowspecdefinition(user_id#67, rk#70 ASC NULLS FIRST, ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS _we0#72], [user_id#67], [rk#70 ASC NULLS FIRST]
+- *Sort [user_id#67 ASC NULLS FIRST, rk#70 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(user_id#67, 200)
+- HiveTableScan [user_id#67, goods_name#68, goods_type#69, rk#70], MetastoreRelation default, window_goods_test
Time taken: 0.238 seconds, Fetched 1 row(s)
21/06/25 13:06:24 INFO CliDriver: Time taken: 0.238 seconds, Fetched 1 row(s)

The specific steps are as follows:
(1) Scan table
(2) According to use_id grouping
(3) By user_id and rk are sorted in ascending order
(4) Execute row_number() function for analysis
(5) use case when to judge
It can be seen from the execution plan that case when is executed after the window function, which is different from our common understanding of making conditional judgment first and executing the window function after meeting the conditions.
That is to say, when using window function in case when, execute window function first, and then execute condition judgment.
The data operation flow chart in the above code is as follows:
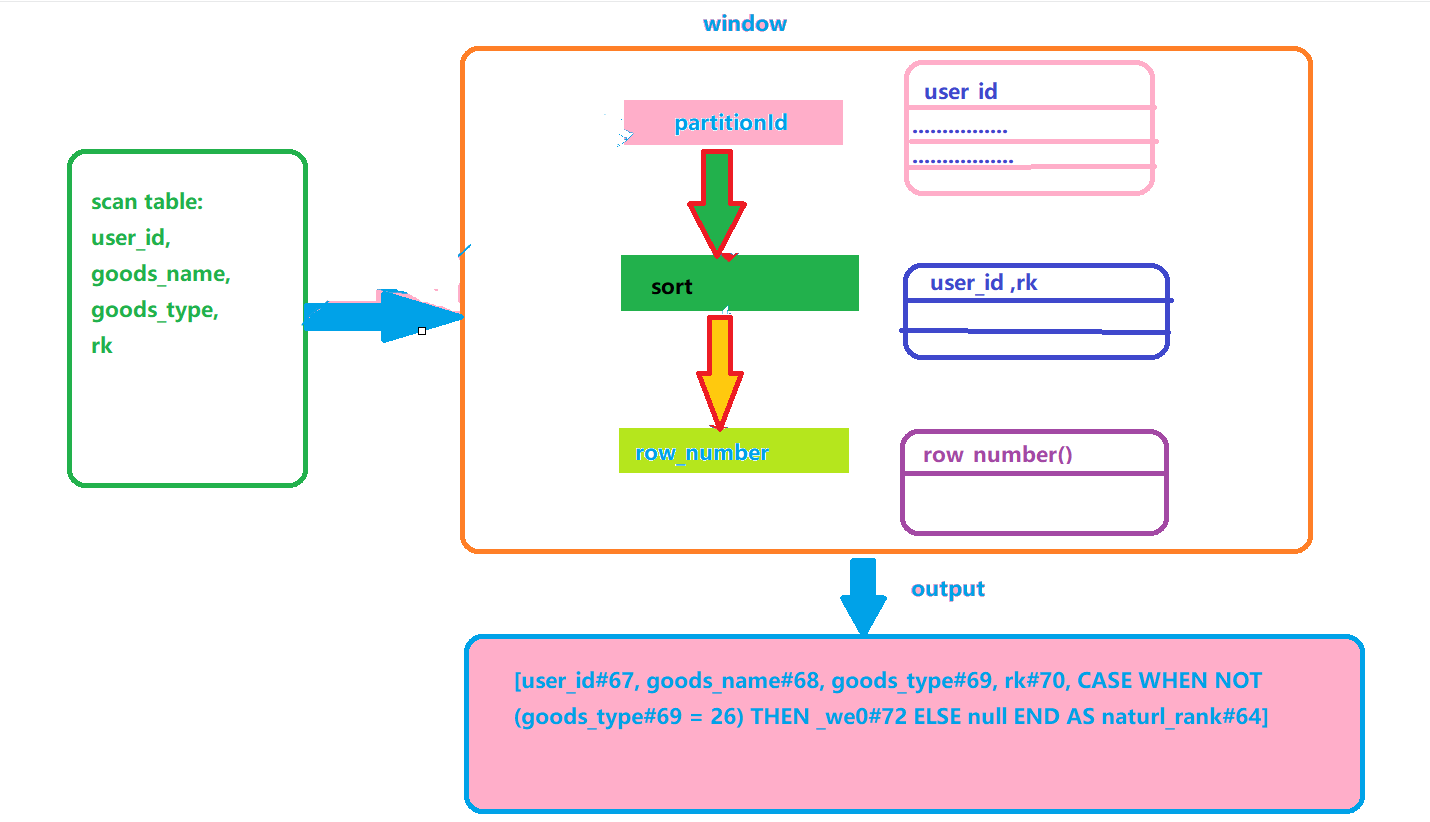
In fact, the above SQL is split into three parts:
Step 1: scan the table to get the result set of select
select
user_id,
goods_name,
goods_type,
rk
from window_goods_test21/06/25 13:49:49 INFO DAGScheduler: Job 9 finished: processCmd at CliDriver.java:376, took 0.039341 s 1 hadoop 10 1 1 hive 12 2 1 sqoop 26 3 1 hbase 10 4 1 spark 13 5 1 flink 26 6 1 kafka 14 7 1 oozie 10 8 Time taken: 0.153 seconds, Fetched 8 row(s) 21/06/25 13:49:49 INFO CliDriver: Time taken: 0.153 seconds, Fetched 8 row(s)
Step 2: execute window function
select
user_id,
goods_name,
goods_type,
rk,
row_number() over(partition by user_id order by rk) as naturl_rank
from window_goods_test21/06/25 13:47:33 INFO DAGScheduler: Job 8 finished: processCmd at CliDriver.java:376, took 0.754508 s 1 hadoop 10 1 1 1 hive 12 2 2 1 sqoop 26 3 3 1 hbase 10 4 4 1 spark 13 5 5 1 flink 26 6 6 1 kafka 14 7 7 1 oozie 10 8 8 Time taken: 1.016 seconds, Fetched 8 row(s) 21/06/25 13:47:33 INFO CliDriver: Time taken: 1.016 seconds, Fetched 8 row(s)
Step 3: execute case when in the result set of step 2
select
user_id,
goods_name,
goods_type,
rk,
case when goods_type!=26 then row_number() over(partition by user_id order by rk) else null end as naturl_rank
from window_goods_testThe transformation result set is as follows:
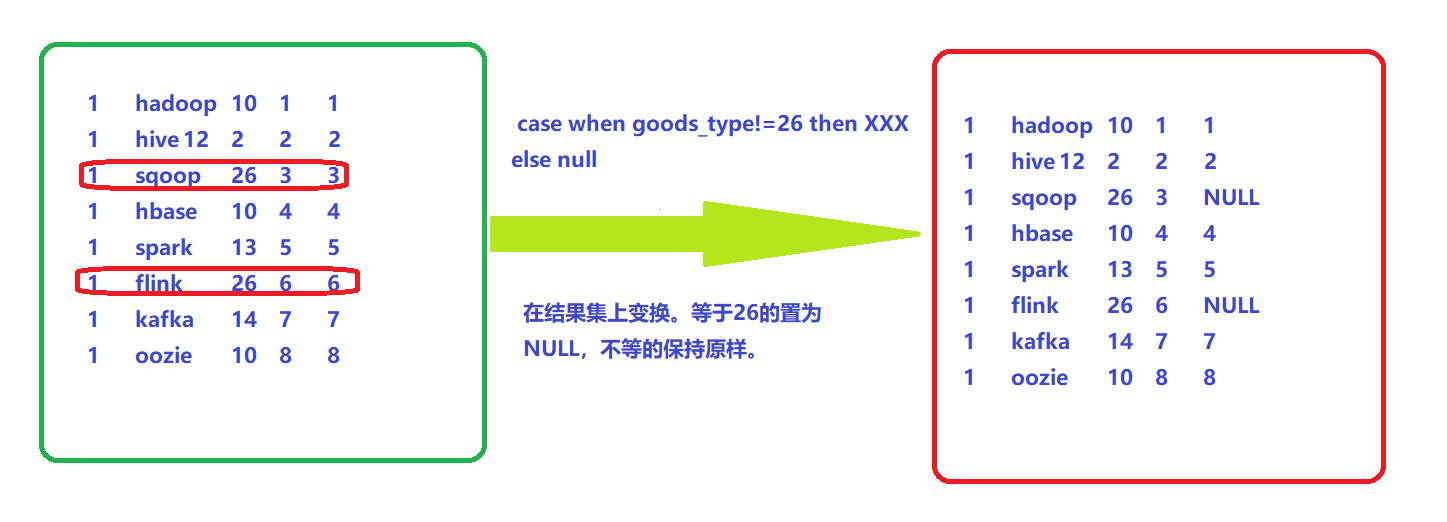
From the above analysis, we can see that to get the correct SQL, we need to filter the data before the window function is executed, rather than after the window function is executed. Therefore, it is conceivable to filter in the where statement first, but it needs to be set to NULL according to the sorting of the result commodity type of 26. Therefore, we use union. The specific SQL is as follows:
select user_id ,goods_name ,goods_type ,rk ,row_number() over(partition by user_id order by rk) as naturl_rank from window_goods_test where goods_type!=26 union all select user_id ,goods_name ,goods_type ,rk ,null as naturl_rank from window_goods_test where goods_type=26
1 hadoop 10 1 1 1 hive 12 2 2 1 hbase 10 4 3 1 spark 13 5 4 1 kafka 14 7 5 1 oozie 10 8 6 1 sqoop 26 3 NULL 1 flink 26 6 NULL Time taken: 1.482 seconds, Fetched 8 row(s) 21/06/25 14:08:14 INFO CliDriver: Time taken: 1.482 seconds, Fetched 8 row(s)
However, the disadvantage here is that you need to scan the table window_goods_test twice. Obviously, it is not the best solution to this problem
Next we give other solutions. In order to filter out the commodities with commodity type of 26, we can first filter the if statement in the partition by group, if goods_type!=26, take the corresponding id for grouping and sorting. If goods_ If type = 26, it will be set as a random number, then it will be grouped and sorted according to the random number, and finally the outer layer will pass through goods_type!=26 filter it out. Here, else in the if statement in the partition by group is not set to NULL, but a random number, because if it is set to NULL, goods_ When the number of type = 26 is large, it will be divided into a group, resulting in data skew. Therefore, rand() function is used. The details are as follows:
select user_id ,goods_name ,goods_type ,rk ,if(goods_type!=26,row_number() over(partition by if(goods_type!=26,user_id,rand()) order by rk),null) naturl_rank from window_goods_test order by rk ------------------------------
Here, in order to get the final result, rk is sorted by order, which is executed after the window function.
The intermediate results obtained are as follows:
select user_id
,goods_name
,goods_type
,rk
,row_number() over(partition by if(goods_type!=26,user_id,rand()) order by rk) naturl_rank
from window_goods_test
order by rk
---------------------------------
1 hadoop 10 1 1
1 hive 12 2 2
1 sqoop 26 3 1
1 hbase 10 4 3
1 spark 13 5 4
1 flink 26 6 1
1 kafka 14 7 5
1 oozie 10 8 6
Time taken: 1.069 seconds, Fetched 8 row(s)
== Physical Plan ==
*Sort [rk#217 ASC NULLS FIRST], true, 0
+- Exchange rangepartitioning(rk#217 ASC NULLS FIRST, 200)
+- *Project [user_id#214, goods_name#215, goods_type#216, rk#217, naturl_rank#211]
+- Window [row_number() windowspecdefinition(_w0#219, rk#217 ASC NULLS FIRST, ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS naturl_rank#211], [_w0#219], [rk#217 ASC NULLS FIRST]
+- *Sort [_w0#219 ASC NULLS FIRST, rk#217 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(_w0#219, 200)
+- *Project [user_id#214, goods_name#215, goods_type#216, rk#217, if (NOT (goods_type#216 = 26)) cast(user_id#214 as double) else rand(-4528861892788372701) AS _w0#219]
+- HiveTableScan [user_id#214, goods_name#215, goods_type#216, rk#217], MetastoreRelation default, window_goods_test
Time taken: 0.187 seconds, Fetched 1 row(s)
21/06/25 14:37:27 INFO CliDriver: Time taken: 0.187 seconds, Fetched 1 row(s)
The final implementation results are as follows:
1 hadoop 10 1 1
1 hive 12 2 2
1 sqoop 26 3 NULL
1 hbase 10 4 3
1 spark 13 5 4
1 flink 26 6 NULL
1 kafka 14 7 5
1 oozie 10 8 6
Time taken: 1.255 seconds, Fetched 8 row(s)
21/06/25 14:14:21 INFO CliDriver: Time taken: 1.255 seconds, Fetched 8 row(s)
explain select user_id
,goods_name
,goods_type
,rk
,if(goods_type!=26,row_number() over(partition by if(goods_type!=26,user_id,rand()) order by rk),null) naturl_rank
from window_goods_test
order by rk
== Physical Plan ==
*Sort [rk#227 ASC NULLS FIRST], true, 0
+- Exchange rangepartitioning(rk#227 ASC NULLS FIRST, 200)
+- *Project [user_id#224, goods_name#225, goods_type#226, rk#227, if (NOT (goods_type#226 = 26)) _we0#230 else null AS naturl_rank#221]
+- Window [row_number() windowspecdefinition(_w0#229, rk#227 ASC NULLS FIRST, ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS _we0#230], [_w0#229], [rk#227 ASC NULLS FIRST]
+- *Sort [_w0#229 ASC NULLS FIRST, rk#227 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(_w0#229, 200)
+- *Project [user_id#224, goods_name#225, goods_type#226, rk#227, if (NOT (goods_type#226 = 26)) cast(user_id#224 as double) else rand(1495282467312192326) AS _w0#229]
+- HiveTableScan [user_id#224, goods_name#225, goods_type#226, rk#227], MetastoreRelation default, window_goods_test
Time taken: 0.186 seconds, Fetched 1 row(s)
21/06/25 14:39:55 INFO CliDriver: Time taken: 0.186 seconds, Fetched 1 row(s)
4 Summary
Enlightenment from this question:
- (1) When a window function is nested in a case when (or if) statement, the execution order of the conditional judgment statement is after the window function
- (2) Conditional judgment statements can be nested in the partition by clause of the window function