preface
1. Introduction of hash table and hash function
Just like this problem, with a 26 int array, you can hash map each character.
The hash function is: f(char) = char -'a '; The hash table is the int [26];
This simple hash function handles the conversion from key to index, and it is also a simple one-to-one correspondence.
The more complex problem usually makes different key mappings into the same index, which is hash conflict.
What we need to deal with is to solve the hash conflict.
2. Hash table
The implementation of hash table reflects the classical idea in the field of algorithm design: space for time.
Hash table is a balance between time and space
Because the two extremes of a hash table are
Infinite space: the search complexity corresponding to O(1);
Space of O(1): search complexity corresponding to O(n);
So the design of hash function is very important. It is hoped that the hash function can map the "key" to the "index" as evenly as possible.
1, Design
1. Design of general and general hash function
Common hash functions: conversion to shaping
Follow:
- Consistency: the same key corresponds to the same hash map
- Efficiency: efficient and convenient calculation
- Uniformity: uniform distribution of Hashi value (taking mold)
generality:
- A small range of positive integers is used directly
- Offset a small range of negative integers (offset to positive integers)
- Large integer: modulo
- Floating point number: convert to integer.
- String: convert to integer.
- For compound types (such as dates): convert to string processing
Modulus of large integer:
Simple model: uneven distribution and not using all information. Usually, a module is a prime number, not a composite number. According to the size of the data scale, the selection of prime numbers is also being studied. That is, the probability of hash conflict caused by different prime modulus.
Floating point number:
In the computer, 32-bit and 64 bit binary storage are used, and then re parsed into floating-point numbers. Then it is the same that we directly use this binary as an integer to map. Similarly, large integers can be used to take the module.
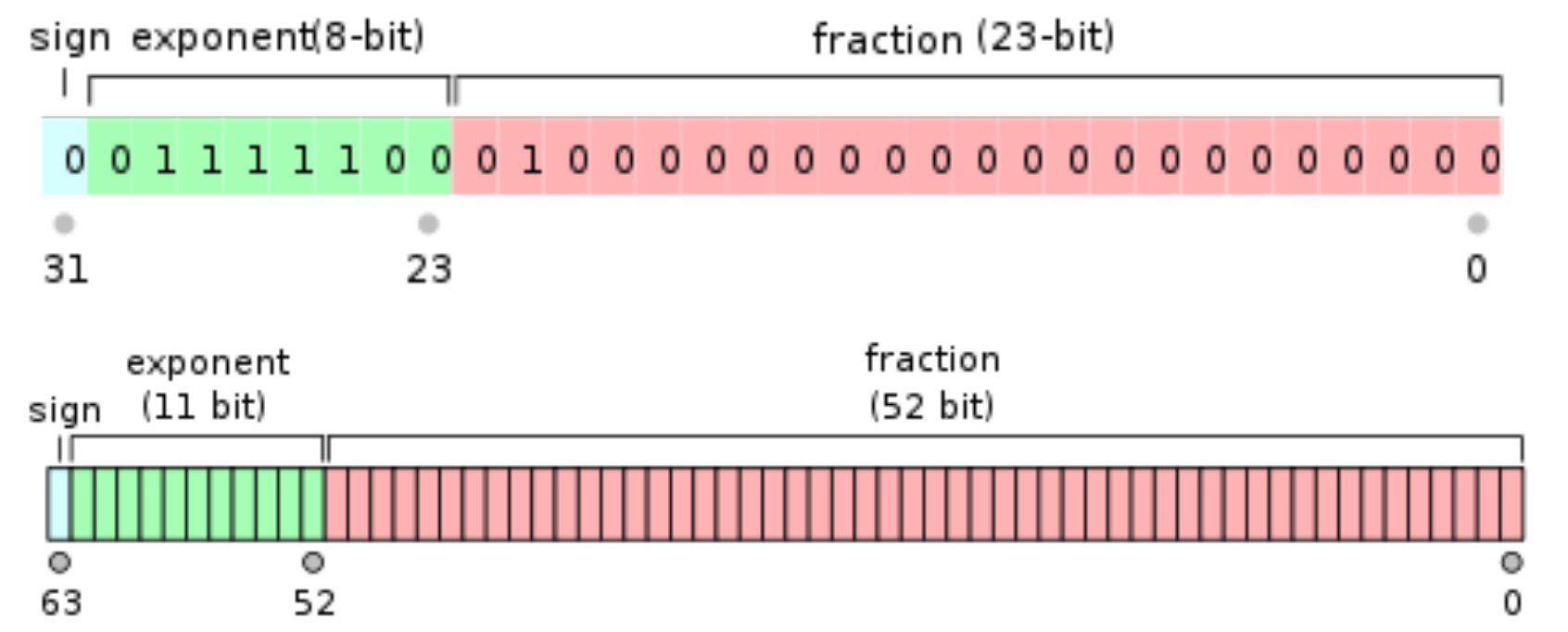
Where string:
If the string represents decimal: convert it to decimal integer
A string represents a letter, which is converted into an integer according to hexadecimal 26 (or greater).
As shown in the following figure: M represents the prime modulus and the size of the hash table. B represents the hexadecimal number determined according to the string.
The hash function is optimized downward, which simplifies the operation and avoids overflow by taking multiple modules (at the same time, the result will not be affected, that is, the result of multiple modules is the same as that of the last module, but avoids intermediate overflow)

2. Default hash function
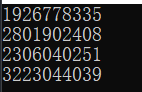
There is a default hash function object class in C + +. In "functional".
We can use its hash function to print out the corresponding mapping.
#include <functional>
#include <string>
int main() {
std::hash<int> hash_int;
std::hash<double> hash_double;
std::hash<std::string> hash_string;
int a = 42;
std::cout << hash_int(a) << std::endl;
int b = -42;
std::cout << hash_int(b) << std::endl;
double c = 3.1415926;
std::cout << hash_double(c) << std::endl;
std::string d = "temp";
std::cout << hash_string(d) << std::endl;
return 0;
}
2, Hash conflict
1. Chain address method. (seperate chaining )
The hash table is an array of M size (M is the modulus value).
Store the linked list in the corresponding position and hang its conflicting value on the linked list.
Of course, some are implemented using tree map. That is, each location stores a red black tree. (tree maps are generally implemented by red black trees)
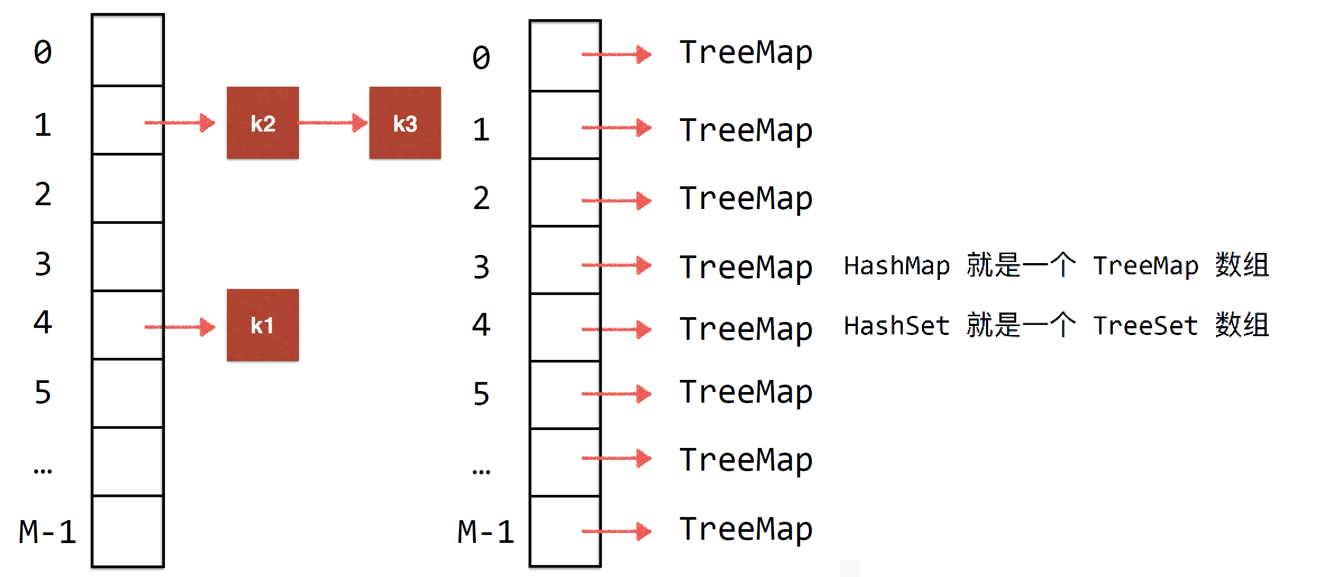
Time complexity: the hash table is M large, with N data. And, the data stored in each address is n/m. obtain:
If stored in a linked list: O(n/m) / / traverse the linked list
If the balanced tree is used to store: O(log(n/m)) / / traverse the tree
However, in extreme cases (the hash function is not set properly), all data have hash conflicts, and all n have a location. Then the time complexity becomes O(n) and O(log(n));
There is an attack method in information security that uses this mechanism: hash collision attack: by understanding the calculation method of hash value, design a set of data to realize hash conflict of all data, deteriorate the time complexity of hash table and slow down the running speed of the system.
1.1 realization
a key:
- The application is an array of map s
- The number calculated by hash is modified to a positive number through bit and, which can be used as an index
- Constructors can call each other
- Get the pointer operation of the map to reduce the consumption of multiple hash calculations. You can also use references.
template<typename Key, typename Value>
class HashTable {
private:
int M;
int size;
map<Key, Value> *hashTable; //Array of map s
int hash(Key key) {
return (hashCode(key) & 0x7fffffff) % M; //Negative to positive
}
int hashCode(Key key) { //hash function in C + +
std::hash<Key> key_hash;
return key_hash(key);
}
public:
HashTable(int M) {
this->M = M;
size = 0;
hashTable = new map<Key, Value>[M];
}
HashTable() {
this->M = 97;
new(this)HashTable(M); //Call constructor
}
int getSize() {
return size;
}
void add(Key key, Value value) {
map<Key, Value> *my_map = &hashTable[hash(key)]; //Pointer so that the hash operation is performed only once.
if (my_map->count(key)) {
my_map->find(key)->second= value;
}
else {
my_map->insert(make_pair(key, value));
size++;
}
}
Value *remove(Key key) {
Value temp;
map<Key, Value> *my_map = &hashTable[hash(key)];
if (my_map->count(key))
{
temp = my_map->find(key)->second;
my_map->erase(key);
size--;
}
return &temp; //Note that there is a problem here
//You'd better change it to new and delete it after use. Try not to pass values and pass local variable pointers.
//Or create a value at the place where it is called, and then transform the function into a value pointer, and directly copy the data there. You don't have to return a value
}
bool contains(Key key) {
return hashTable[hash(key)].count(key);
}
Value *get(Key key) {
return &(hashTable[hash(key)])[key]; //Address. In case value is a large data structure
}
void set(Key key, Value value) {
map<Key, Value> &my_map = hashTable[hash(key)]; //Reference, so that the hash operation is performed only once.
if (!my_map.count(key)) {
throw to_string(key) + " doesn't exist";
}
//assert(my_map.count(key)!=0);
my_map.find(key)->second = value;
}
};
1.2 test
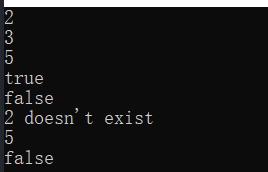
void main()
{
HashTable<int, int> temp;
temp.add(1, 2);
cout << *(temp.get(1)) << endl;
temp.add(1, 3);
cout << *(temp.get(1)) << endl;
temp.set(1, 5);
cout << *(temp.get(1)) << endl;
cout << boolalpha << temp.contains(1) << endl;
cout << boolalpha << temp.contains(2) << endl;
try {
temp.set(2, 5); }
catch (const string msg){
cerr << msg << endl; }
//int *mm = (temp.remove(1));
//cout<< (void*)mm << endl;
cout << *(temp.remove(1)) << endl;
cout << boolalpha << temp.contains(1) << endl;
}
2. Dynamic space optimization of hash table
The time complexity of the above hash table is strongly related to the hash table size M, so the time complexity of hash table 0 (1) can be truly realized by modifying the hash table capacity.
That is, set the upper and lower boundaries. When n / M > = uppertol, that is, the ratio of data volume to hash table size exceeds the upper bound, the capacity will be expanded.
When n / M < lowertol, that is, the ratio of data volume to hash table size is less than the lower bound, the volume is reduced.
reference resources
Template class and template function design