preface
(7.3, 3 lessons short, do your best!)
This article is the learning notes for the eighth lecture of the algorithm class.
3-2 section 2 of Chapter V: hash table and bloom filter
(as usual, the shortest learning time is still challenged this time, and it is expected to be less than 3 times the time)
(the difficulty of this course rises sharply. In order to simplify the course content, we don't talk about hash algorithm this time. We just need to understand that hash algorithm can map any data structure to the target memory space as evenly as possible)
Learning objectives
- Learning hash ideas
- This paper focuses on the implementation of a special hash table bloom filter.
- Learn the application scenario of hash table
- I hope to have an overall understanding of the concept of hash table through this lesson
Hashtable
- Solve the way to quickly obtain the index of stored information
- Reviewing the array structure, the time complexity of array fetching according to the index is very low
- Hash operation to map any data into an array subscript (dimensionality reduction to integer number) (key operation)
- High speed data access
- It is a structure with a strong sense of design
- Complete high-speed data access
Hash operation
- Mapping data dimensionality reduction
- Dimensionality reduction will lose information and overlap information. Therefore, during hash operation, two different data may be mapped to the same coordinate (called hash conflict)
- For example, a conflict caused by a simplified hash rule (index=n%size)
- Hash conflict is that multiple elements map to the same coordinate. This conflict is inevitable (but it is expected to avoid or avoid conflict)
- Hash conflict avoidance scheme (conflict handling)
Conflict handling
There are four ways to design conflict rules:
- Open addressing
- double hashing
- Establish public overflow area
- Chained address method (zipper method and self-designed hash table are recommended to deal with conflicts)
Open addressing
When an address is used (conflicting), the data is attempted to be mapped to the free address behind the address. There are two rules for trying to map: linear or exponential. Among them, linear selection attempts to map with equal spacing, while exponential is power exponential. (linearity is called linear detection method, and power exponent is called quadratic hashing, because the exponent of 2 is often used as spacing) and the use of these mapping rules is very flexible. Generally speaking, simple rules will be selected.
But both of them try to map to the idle address in the rear.
double hashing
In case of conflict, try to use another set of hash rules to map the address. If it fails again, change another set. This way to use other hash functions is re hashing.
(however, the mapping provided by this method is limited because the prepared hash rules are limited. Therefore, although this method can greatly reduce the conflict rate, it needs to be used with the remaining three rules.)
(therefore, it is not recommended to design a hash table by yourself)
Public overflow area
In case of conflict, the new data is stored in the public overflow area. This part of the public overflow area can be stored in any suitable data structure, such as building a hash table or a red black tree.
This method differs from other methods in that it gives conflicting data to additional space.
Chain address method
In the chained address method, each location of the hash table stores the head node of the linked list (in case of conflict, the linked list is extended). Due to the use of linked list structure, it is actually equivalent to re dimension upgrading to a certain extent.
Expansion hash table
When hash conflicts occur too frequently in a hash table, it is necessary to expand the capacity of the hash table (or if you think you want to expand the capacity, expand the capacity). Generally, the capacity of the hash table is doubled.
The time complexity of the hash table is the average time complexity o (1). The principle is that when the current size of the hash table is n, assuming that it reaches the current size through capacity expansion, the number of capacity expansion is n. therefore, the average time complexity of each element is 1.
The specific operations performed during capacity expansion are to map the old data to the new space, and then overwrite the old space with the new space
Design a simple hash table
(in the hash table designed below, there is a problem. Only the data is accessed, but the stored data is not deleted. I didn't talk about it in this class, so I skip consideration.)
Core operations of hash table:
- When inserting, if there is no element in the current position, insert it; Otherwise, the conflict handling rules are executed.
- When searching, if there is an element in the current position and it is equal to the element to be searched, return; Otherwise, look in the public overflow area
- During capacity expansion, the data in the old table is stored in the new area, and the elements processed by the conflict rules are also tried to be stored in the new area
(take zipper method as an example)
class MyHashTable {
private Node [] data ;
private int size ;
private int nowDataLen;
public MyHashTable () {
data = new Node [16];
size = data.length;
nowDataLen = 0;
}
public MyHashTable (int len) {
data = new Node [len];
size = data.length;
nowDataLen = 0;
}
private int hash_func(String str) { //Custom hash rules
char [] c = str.toCharArray();
int seed = 131,hash =0;
for(int i=0;i<c.length;i++) {
hash = hash*seed + c[i];
}
return hash & 0x7fffffff;
}
public void expand() {
int n = size*2;
MyHashTable ht = new MyHashTable(n);
for(int i = 0;i < size;i++) {
Node node = data[i];
if(node!=null) {
node= node.next;
while( node !=null) {
ht.insert(node.data);
node= node.next;
}
}
}
data = ht.data;
size = data.length;
}
public void insert(String str) {
Node wantFind = find(str);
if(wantFind != null) return;
int key = hash_func(str);
int index = key % size;
if(data[index] == null)
data[index] = new Node();
data[index].insertNext(new Node(str,null));
nowDataLen ++;
if(nowDataLen>size*3) //The user-defined rule is to expand the capacity once the load reaches 3 times
expand();
}
public boolean contains(String str) {
Node wantFind = find(str);
if(wantFind == null)
return false;
return true;
}
private Node find(String str) {
if(str == null) return null;
int key = hash_func(str);
int index = key % size;
Node wantSet = data[index];
if(wantSet==null){
return null;
}else{
while(wantSet!=null){
if(str.equals(wantSet.data))
return wantSet;
wantSet = wantSet.next;
}
}
return null;
}
}
class Node{
public String data;
public Node next;
public Node() {}
public Node(String data,Node next){
this.data = data;
this.next = next;
}
public void removeNext (){
if(next == null)return;
Node p = next;
next = p.next;
}
public void insertNext (Node newNode){
newNode .next = next;
next = newNode;
}
}
summary
There are two key points in designing a hash table:
- Design hash rules (different hash functions are applicable for different data and different situations) (but they all expect to achieve the maximum space utilization)
- Design conflict handling (similarly, different conflict rules apply to different situations)
There are four ways to design conflict rules:
- Open addressing
- double hashing
- Establish public overflow area
- Chained address method (zipper method and self-designed hash table are recommended to deal with conflicts)
Both open addressing method and re hashing method are carried out within the scope of the original data to reduce the probability of conflict. The establishment of public overflow area is to hand over the prominent contents to other rules for processing. The chain address method is to upgrade the dimension again to solve the conflict caused by dimensionality reduction.
To sum up:
Hash table is a set of data storage structure with strong sense of design, which is based on the nature of array and uses hash idea for address mapping to realize the sharing time performance of o (1). In the process of use, it needs to cooperate with conflict rules and expansion rules to avoid hash conflict.
Bloom filter
Using hash rules: ensure whether a certain data to be judged has appeared.
Comparison hash table
The hash table is used to judge whether a stored value exists. The hash table must ensure that certain data exists or does not exist, and can obtain the stored content. For the address conflict caused by dimensionality reduction, the hash table needs to design conflict rules and expand the capacity according to the situation. To sum up:
The storage space of the hash table is related to the number of elements.
The bloom filter is used to judge whether a certain data does not exist. Therefore, it allows address conflicts caused by hash operations and does not need to obtain stored values. Therefore, it is simpler to implement, and there is no need to expand the capacity, but it needs to be emptied (if it is not clear, the capacity must be expanded, otherwise the filtering performance will be degraded). To sum up:
The storage space of Bloom filter is independent of the number of elements.
Application scenario example
When the crawler code obtains information from the web address, it does not expect to obtain information from the same web address, so it needs a rule to avoid the passing web address.
If the hash table is used, it can be judged by storing the URL, but with the development of web pages, the information of URL becomes richer and richer. Continuing to use the hash table will cause a lot of space overhead. The requirement is only to avoid duplication, and there is actually no requirement for the stored content.
The bloom filter ensures that the determined URLs are all URLs that have not passed, and the bloom filter does not store specific URLs, which greatly reduces the use of space. Although the accuracy is not as good as the hash table, some URLs will be skipped in case of conflict, but this loss is usually acceptable.
principle
Open up a storage space and store only binary (compared with the hash table, the hash table needs to store the appropriate data structure). When filtering, use a variety of different hash rules (such as 3 kinds) for dimensionality reduction mapping, and set the value in the storage space mapped by each rule to 1 (compared with the hash table, the hash table stores the data in the mapped storage space). Before setting, as long as the address of a rule mapping is not 1, it is considered that the data has not appeared.
Advantages and disadvantages of analysis:
- Excellent: low space demand. The more complex the information is filtered, the smaller the space required compared with the hash scheme.
- Bad: with the increase of the amount of filtered data, the higher the probability of misjudgment.
(from another point of view, it is obviously possible for Bloom filter to use only one hash rule. When misjudgment occurs, there is a hash conflict.)
(unlike the hash table, which requires data storage, the bloom filter only needs to ensure that the data appears for the first time, so hash conflicts can be allowed, but it is still expected to reduce the impact of hash conflicts.)
(therefore, the probability of misjudgment is lower for each additional set of hash rules)
(however, the size of the storage space is limited, so the higher the utilization rate of the space, the higher the misjudgment rate. Assuming that the space is fully utilized, it will be 100% misjudged.)
Code implementation (omitted)
(there is no capacity expansion part in the bloon filter designed below, so it is a filter used for limited times)
(I forgot if I didn't write the description)
summary
Bloom filters are often used in big data scenarios (URLs) and scenarios with high information security (original data cannot be held)
To sum up:
Bloom filter is a data structure designed based on Hash idea to store data occurrence, which also has good design.
Classic examples
Basic - encapsulation of hash structure
leecode-705. Design hash set
Source: https://leetcode-cn.com/problems/design-hashset/
Design a hash set without using any built-in hash table library.
Implement the MyHashSet class:
- void add(key) inserts the value key into the hash set.
- bool contains(key) Returns whether the value key exists in the hash set.
- void remove(key) deletes the given value key from the hash set. If there is no such value in the hash set, nothing is done.
Example:
Input: ["MyHashSet", "add", "add", "contains", "contains", "add", "contains", "remove", "contains"] [[], [1], [2], [1], [3], [2], [2], [2], [2]] Output: [null, null, null, true, false, null, true, null, false] Explanation: MyHashSet myHashSet = new MyHashSet(); myHashSet.add(1); // set = [1] myHashSet.add(2); // set = [1, 2] myHashSet.contains(1); // Return True myHashSet.contains(3); // Return False, (not found) myHashSet.add(2); // set = [1, 2] myHashSet.contains(2); // Return True myHashSet.remove(2); // set = [1] myHashSet.contains(2); // Returns False, (removed)
Tips:
- 0 <= key <= 10^6
- add, remove, and contains can be called up to 10 ^ 4 times.
Problem solving ideas
This question is to review the hash table with an example.
Zipper method is used to deal with conflict and element deletion.
(later, when referring to the solution, I learned three sets of better problem-solving ideas, source: https://leetcode-cn.com/problems/design-hashset/solution/yi-ti-san-jie-jian-dan-shu-zu-lian-biao-nj3dg/ )
(additional solution 1: simple array)
Use an array containing all possible numbers to store information. The array value is the subscript.
It is quite rude. It declares a Boolean array boolean[] nodes = new boolean[1000009] with a size of 1000009;
This idea is similar to bloom filter, the core is single hash, and ensures absolutely no conflict (because there is no dimensionality reduction). In this case, all numbers are stored.
(based on the requirements of the topic: 0 < = key < = 106)
(code omitted)
(additional solution 2: linked list hash table)
Use a linked list array containing all possible numbers to store information. The array value is the subscript. Also quite rough, set the linked list size to 10009
(based on a maximum of 10 ^ 4 calls to add, remove, and contain.)
This solution is to design a simple hash table, but it is much better than me. The key performance optimization is to maximize the discreteness of space in the function getIndex and the initial space setting division.
(additional solution 3: bucket array)
An Integer type array containing all the numbers is used to store information. According to the 32-bit characteristics of Integer type, all possible types are encapsulated in a group of 32 bits, so divided.
Since the data range is 0 < = key < = 10 ^ 6, the maximum number of int s we need will not exceed 40000. (if you think so, it can actually be less)
(code omitted)
Sample code
(basic solution, design simple hash table, and use linked list to deal with element conflict)
(after I finish solving, I find that there is a slight gap between the examples written and the concept part, which is a little more complicated, but it does not affect the problem-solving)
class MyHashSet {
private Node [] data ;
private int size ;
/** Initialize your data structure here. */
public MyHashSet() {
data = new Node [100];
size = data.length;
}
public void add(int key) {
int index = key % size;
Node wantSet = data[index];
if(wantSet==null){
data[index] = new Node(key,null);
}else{
while(wantSet!=null){
if(wantSet.key == key)
return;
if(wantSet.next==null) {
wantSet.next = new Node(key,null);
return;
}
wantSet = wantSet.next;
}
}
}
public void remove(int key) {
int index = key %size;
Node wantRmeove = data[index];
if(wantRmeove==null){
}else{
Node dummyHead = new Node(0,null);
dummyHead.next = wantRmeove;
if( wantRmeove.key ==key ){
dummyHead.removeNext();
data[index] = dummyHead.next;
return;
}
while(dummyHead!=null&&dummyHead.next!=null){
if(dummyHead.next.key == key){
dummyHead.removeNext();
}
dummyHead = dummyHead.next;
}
}
}
/** Returns true if this set contains the specified element */
public boolean contains(int key) {
Node wantFind = findSet(key);
if(wantFind == null)
return false;
return true;
// int index = key %size;
// Node wantSet = data.get(index);
// if(wantSet==null){
// return false;
// }else{
// while(wantSet!=null){
// if(wantSet.key == key)
// return true;
// wantSet = wantSet.next;
// }
// return false;
// }
}
//The above code can be simplified a little and can be replaced by the following function (but I only simplified one)
private Node findSet(int key) {
int index = key % size;
Node wantSet = data[index];
if(wantSet==null){
return null;
}else{
while(wantSet!=null){
if(wantSet.key == key)
return wantSet;
wantSet = wantSet.next;
}
}
return null;
}
}
class Node{
public int key;
public Node next;
public Node(int key,Node next){
this.key = key;
this.next = next;
}
public void removeNext (){
if(next == null)return;
Node p = next;
next = p.next;
}
}
(linked list method)
class MyHashSet {
// Because the "linked list" is used, this value can be very small
Node[] nodes = new Node[10009];
public void add(int key) {
// Get the location of the hash bucket according to the key
int idx = getIndex(key);
// Judge whether the linked list already exists
Node loc = nodes[idx], tmp = loc;
if (loc != null) {
Node prev = null;
while (tmp != null) {
if (tmp.key == key) {
return;
}
prev = tmp;
tmp = tmp.next;
}
tmp = prev;
}
Node node = new Node(key);
// Head insertion
// node.next = loc;
// nodes[idx] = node;
// Tail interpolation
if (tmp != null) {
tmp.next = node;
} else {
nodes[idx] = node;
}
}
public void remove(int key) {
int idx = getIndex(key);
Node loc = nodes[idx];
if (loc != null) {
Node prev = null;
while (loc != null) {
if (loc.key == key) {
if (prev != null) {
prev.next = loc.next;
} else {
nodes[idx] = loc.next;
}
return;
}
prev = loc;
loc = loc.next;
}
}
}
public boolean contains(int key) {
int idx = getIndex(key);
Node loc = nodes[idx];
if (loc != null) {
while (loc != null) {
if (loc.key == key) {
return true;
}
loc = loc.next;
}
}
return false;
}
static class Node {
private int key;
private Node next;
private Node(int key) {
this.key = key;
}
}
int getIndex(int key) {
// Because the length of nodes is only 10009, the corresponding decimal system is 10011100011001 (the total length is 32 bits, and the other high bits are 0)
// In order to make the hash high bit corresponding to the key also participate in the operation, the hashCode is shifted to the right XOR here
// So that the high-order randomness and low-order randomness of hashCode can be reflected in the low 16 bits
int hash = Integer.hashCode(key);
hash ^= (hash >>> 16);
return hash % nodes.length;
}
}
Author: AC_OIer
Link: https://leetcode-cn.com/problems/design-hashset/solution/yi-ti-san-jie-jian-dan-shu-zu-lian-biao-nj3dg/
Source: force buckle( LeetCode)
The copyright belongs to the author. For commercial reprint, please contact the author for authorization. For non-commercial reprint, please indicate the source.
leecode-706. Design hash mapping
Source: https://leetcode-cn.com/problems/design-hashmap/
Design a hash map without using any built-in hash table library.
Implement MyHashMap class:
- MyHashMap() initializes the object with an empty map
- void put(int key, int value) inserts a key value pair (key, value) into the HashMap. If the key already exists in the map, update its corresponding value.
- int get(int key) returns the value mapped by a specific key; If the mapping does not contain a key, return - 1.
- void remove(key) if there is a key mapping in the mapping, remove the key and its corresponding value.
Example:
Input: ["MyHashMap", "put", "put", "get", "get", "put", "get", "remove", "get"] [[], [1, 1], [2, 2], [1], [3], [2, 1], [2], [2], [2]] Output: [null, null, null, 1, -1, null, 1, null, -1] Explanation: MyHashMap myHashMap = new MyHashMap(); myHashMap.put(1, 1); // myHashMap is now [[1,1]] myHashMap.put(2, 2); // myHashMap is now [[1,1], [2,2]] myHashMap.get(1); // Return 1. myHashMap is now [[1,1], [2,2]] myHashMap.get(3); // Return - 1 (not found). myHashMap is now [[1,1], [2,2]] myHashMap.put(2, 1); // myHashMap is now [[1,1], [2,1]] (update existing values) myHashMap.get(2); // Return 1. myHashMap is now [[1,1], [2,1]] myHashMap.remove(2); // Delete the data with key 2. myHashMap is now [[1,1]] myHashMap.get(2); // Return - 1 (not found), myHashMap is now [[1,1]]
Tips:
- 0 <= key, value <= 106
- The put, get, and remove methods can be called up to 104 times
Problem solving ideas
This question is similar to the previous question. You can refer to the idea of the previous question. The change you need to make is to change the stored elements into key value pairs, and take the key value as the search condition.
(key value pairs need to be encapsulated in a class designed by ourselves)
(code omitted)
Application - Application of hash idea
leecode - interview question 16.25 LRU cache
Source: https://leetcode-cn.com/problems/lru-cache-lcci/
Design and build a least recently used cache that deletes the least recently used items. The cache should map from key to value (allowing you to insert and retrieve the value corresponding to a specific key) and specify the maximum capacity at initialization. When the cache is full, it should delete the least recently used items.
It should support the following operations: get data and write data put.
- Get data (key) - if the key exists in the cache, get the value of the key (always positive), otherwise return - 1.
- Write data put(key, value) - if the key does not exist, write its data value. When the cache capacity reaches the maximum, it should delete the least recently used data value before writing new data, so as to make room for new data values.
Example:
LRUCache cache = new LRUCache( 2 /* Cache capacity */ ); cache.put(1, 1); cache.put(2, 2); cache.get(1); // Return 1 cache.put(3, 3); // This operation will invalidate key 2 cache.get(2); // Return - 1 (not found) cache.put(4, 4); // This operation will invalidate key 1 cache.get(1); // Return - 1 (not found) cache.get(3); // Return 3 cache.get(4); // Return 4
Problem solving ideas
First, learn about LRU. LRU is a data exchange strategy. Choose what to store and give up according to certain rules. This rule is called LRU cache strategy.
The current rules are:
- When you need to subtract an element, delete an element from the beginning
- When an element is accessed, it is moved to the end
- When an element is added, an element is added to the end. If the total amount exceeds the space, element subtraction is performed
So far, I first thought that the stored elements should be a queue, which needs to be implemented with a linked list to facilitate the movement of elements
The second problem to consider is how to query elements conveniently and quickly?
Considering that the index with array structure is needed quickly, we should think of the content related to hash, and then combined with the linked list, so this problem will be solved with the hash linked list.
Hash linked list: the underlying data structure is a linked list, but it also has a hash table for querying nodes.
In addition, in order to move any node, we need to use a two-way linked list to obtain the front and back nodes of any node for easy splicing.
(this Hash list has to be made by yourself)
(but in order to simplify the production, I use HashMap to implement this hash table with linked list.)
In the production of linked list, in order to facilitate the implementation of subtraction and addition, you need to hold the head and tail. Three methods are prepared for this: delete the header, remove specific elements, and insert the tail (set a virtual header and virtual tail for easy insertion and deletion)
(operations in the hash table are required for both deletion and addition)
(it should be noted that when the key s are the same, the action of re assignment is equivalent to using, so the logic of accessing the element needs to be executed once)
(however, this topic focuses on the knowledge of linked lists and the application of the contents learned in the course)
Sample code
class LRUCache {
private HashMap <Integer,Node> nodeMap ;
private int size ;
private Node linkNodeHead;
private Node linkNodeEnd;
private int linkNodeLen;
public LRUCache(int capacity) {
nodeMap = new HashMap <Integer,Node> (capacity);
size = capacity;
linkNodeHead = new Node();
linkNodeHead.key =100;
linkNodeEnd = new Node();
linkNodeEnd.key = -200;
linkNodeLen = 0;
linkNodeHead.next = linkNodeEnd;
linkNodeEnd.previous = linkNodeHead;
}
public int get(int key) {
Node wantGet = nodeMap.get(key);
//System.out.println("g"+key);
if(wantGet==null) {
return -1;
}else{
wantGet.removeNode();
//System.out.println("g--:"+wantGet.key);
linkNodeHead.insertNext(wantGet);
return wantGet.value;
}
}
public void put(int key, int value) {
Node wantGet = nodeMap.get(key);
if(wantGet!=null){
wantGet.value = value;
nodeMap.put(key,wantGet);
get(key);
return;
}
if(linkNodeLen>= size ){
int deleteKey = linkNodeEnd.previous.key;
nodeMap.remove(deleteKey );
//System.out.println("d-:"+linkNodeEnd.previous.key);
linkNodeEnd.previous.removeNode();
//System.out.println("d---:"+linkNodeEnd.previous.key);
}else{
linkNodeLen++;
}
Node wantSet = new Node();
wantSet.key = key;
wantSet.value = value;
nodeMap.put(key,wantSet);
linkNodeHead.insertNext(wantSet);
// if(linkNodeLen == 2){
// System.out.println("n--:"+linkNodeEnd.previous.key);
// }
}
}
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache obj = new LRUCache(capacity);
* int param_1 = obj.get(key);
* obj.put(key,value);
*/
class Node {
int key;
int value;
Node next;
Node previous;
public Node(){
}
public void removeNode(){
if(previous!=null){
previous.next = next;
}
if(next!=null){
next.previous = previous;
}
previous = null;
next = null;
}
public void insertNext(Node set){
if(next!=null)
next.previous = set;
set.next = next;
set.previous = this;
next = set;
}
}
(happy)
Execution time: 26 ms , At all Java Defeated in submission 100.00% User Memory consumption: 46.4 MB , At all Java Defeated in submission 69.67% User
Leecode-535. Encryption and decryption of tinyurl
Link: https://leetcode-cn.com/problems/encode-and-decode-tinyurl
TinyURL is a URL simplification service, for example, when you enter a URL https://leetcode.com/problems/design-tinyurl When, it will return a simplified URL http://tinyurl.com/4e9iAk.
Requirements: design a method for encrypting encode and decrypting decode of TinyURL. There is no limit to how your encryption and decryption algorithm is designed and operated. You only need to ensure that a URL can be encrypted into a TinyURL, and the TinyURL can be restored to the original URL by decryption.
Problem solving ideas
This problem is to realize the mapping of a short URL to the original URL, and use the hash table to manage the key value pairs. But we need to solve a problem, how to generate a short URL.
Therefore, the conversion of the original URL to a short URL needs to be understood as the need to design a hash operation.
The original hash operation generates an integer number, which can be understood as hexadecimal, while the string to be generated this time can be understood as hexadecimal (case and number have 62 changes in one character position)
But! This problem does not require data to be stored in a certain space for data management, so this problem is actually a problem of compression algorithm. This algorithm cannot allow conflict, which is inconsistent with the hash rules. The hash rules should not conflict as much as possible. (although the logic of the encryption algorithm should not conflict as much as possible)
Therefore, from the perspective of doing questions, if we can maximize the possibility of storing content with limited space, so that it is larger than the test scope of the test questions
Therefore, the proposed scheme is to count with base 62 and allocate a space for each URL
Sample code
public class Codec {
String alphabet = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ";
HashMap<String, String> map = new HashMap<>();
Random rand = new Random();
String key = getRand();
public String getRand() {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 6; i++) {
sb.append(alphabet.charAt(rand.nextInt(62)));
}
return sb.toString();
}
public String encode(String longUrl) {
while (map.containsKey(key)) {
key = getRand();
}
map.put(key, longUrl);
return "http://tinyurl.com/" + key;
}
public String decode(String shortUrl) {
return map.get(shortUrl.replace("http://tinyurl.com/", ""));
}
}
Author: LeetCode
Link: https://leetcode-cn.com/problems/encode-and-decode-tinyurl/solution/tinyurlde-jia-mi-yu-jie-mi-by-leetcode/
Source: force buckle( LeetCode)
The copyright belongs to the author. For commercial reprint, please contact the author for authorization. For non-commercial reprint, please indicate the source.
leecode-187. Repetitive DNA sequence
Link: https://leetcode-cn.com/problems/repeated-dna-sequences
All DNA consists of A series of nucleotides abbreviated as' A ',' C ',' G 'and'T', such as "ACGAATTCCG". When studying DNA, identifying repetitive sequences in DNA can sometimes be very helpful.
Write a function to find all target substrings. The length of the target substring is 10 and appears more than once in the DNA string s.
Example 1:
Input: s = "AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT" Output:["AAAAACCCCC","CCCCCAAAAA"]
Problem solving ideas
The expected content of this question is to obtain the number of occurrences of character substrings. Therefore, you only need to use the hash table to constantly judge whether it already exists during storage. If it already exists, add 1 to the counter. When the count result is greater than 1 for the first time, it is stored in the result set.
(this problem is solved with a ready-made hash table, HashMap)
The substring of the string is generated by traversing the total string.
(code omitted)
leecode-318. Maximum word length product
Link: https://leetcode-cn.com/problems/maximum-product-of-word-lengths
Given a string array words, find the maximum value of length(word[i]) * length(word[j]), and the two words do not contain common letters. You can think that each word contains only lowercase letters. If there are no such two words, 0 is returned.
Example 1: input: ["abcw","baz","foo","bar","xtfn","abcdef"] output: 16 explain: These two words are "abcw", "xtfn". Example 2: input: ["a","ab","abc","d","cd","bcd","abcd"] output: 4 explain: These two words are "ab", "cd".
Problem solving ideas
This question can only be exhaustive, but the exhaustive objects need to meet each other first without any repeated letters.
The idea of this question is to judge the word group without repeated letters. A letter should be mapped to an array of length 26. Then use another word to try to pass the filter condition. If it passes, calculate the product, and the passing rule is that all characters of another word cannot encounter the coordinates set to 1.
(code omitted)
Thinking practice
The following content has nothing to do with course learning. It is used to practice the thinking model. Those who are interested can solve it.
leecode-240. Search two-dimensional matrix II
Link: https://leetcode-cn.com/problems/search-a-2d-matrix-ii
Write an efficient algorithm to search a target value target in m x n matrix. The matrix has the following characteristics:
- The elements of each row are arranged in ascending order from left to right.
- The elements of each column are arranged in ascending order from top to bottom.
For example: 1 ,4 ,7 ,11,15 2 ,5 ,8 ,12,19 3 ,6 ,9 ,16,22 10,13,14,17,24 18,21,23,26,30
Problem solving ideas
Firstly, grasp the characteristics of this matrix: horizontal and vertical increase. Therefore, you can grasp the points in the upper right corner and the lower left corner first.
Secondly, the rectangle of any size intercepted from the rectangle meets the characteristics of the matrix.
According to these two points, a recursive query rule can be designed. Two pointers are prepared in the query process, starting asynchronously from the top right and bottom left respectively (they can also be synchronized, and the two do not conflict)
- For the pointer starting from the upper right corner, if the target value is smaller than the value where the pointer is located, you want to move one grid to the left, and if it is larger than the value, you want to move one grid down
- For the pointer starting from the lower left corner, if the target value is greater than the value of the pointer, move it one grid to the right,
If it is smaller than the value, move it up one grid
Either of these two pointers realizes that the target value is equal to the value, and ends the recursion to complete the query.
(one pointer is OK, but two pointers can make the performance more average)
(code omitted)
Leecode-979. Allocate coins in a binary tree
Link: https://leetcode-cn.com/problems/distribute-coins-in-binary-tree
Given the root node of a binary tree with N nodes, each node in the tree corresponds to node There are four coins and a total of N coins.
In a move, we can select two adjacent nodes, and then move a coin from one node to another. (the move can be from parent node to child node, or from child node to parent node.).
Returns the number of moves required to make only one coin on each node.
Example 4:
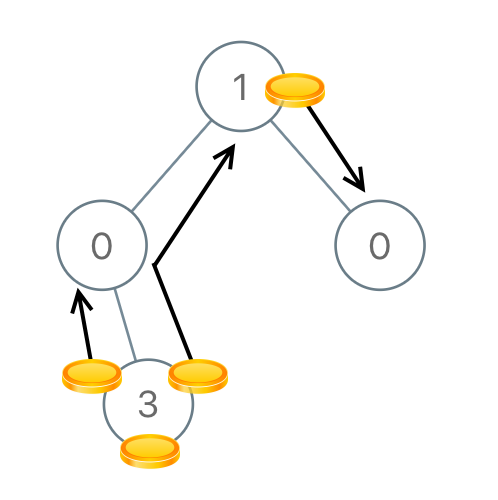
Input:[1,0,0,null,3] Output: 4
Problem solving ideas
This problem needs to pay attention to a problem condition. The total number of nodes and coins are equal, both of which are N.
Find the minimum number of times a coin moves. In order to achieve this result, the movement of the coin must be one-way (because if it is two-way, it is better to move only the difference).
Then consider a small area. When a sub tree has 5 nodes and only 3 coins, it should provide at least difference coins (2) from the outside. These coins must pass through the parent node of the sub tree (conversely, it is necessary to output difference coins).
Finally, according to this rule, you can count the number of times each node needs to provide or receive coins from its parent node. The sum of these times is the answer to this question.
(code omitted)
Leecode-430. Flat multilevel bidirectional linked list
Link: https://leetcode-cn.com/problems/flatten-a-multilevel-doubly-linked-list
In the multi-level bidirectional linked list, in addition to the pointer to the next node and the previous node, it also has a sub linked list pointer, which may point to a separate bidirectional linked list. These sub lists may also have one or more of their own sub items, and so on to generate multi-level data structures, as shown in the following example.
Give you the head node at the first level of the list. Please flatten the list so that all nodes appear in the single level double linked list.
Example of original linked list:
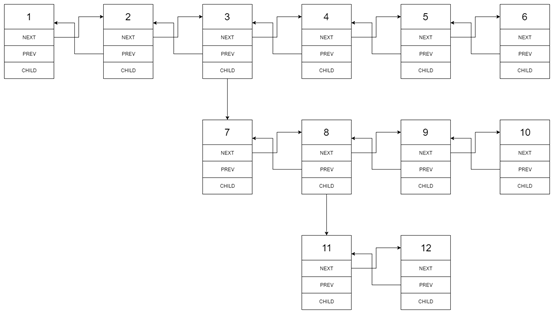
Linked list of results:

Problem solving ideas
The requirement of this problem is to convert a multi-level linked list into a single-level linked list.
Therefore, this problem needs to traverse the linked list. When a branch occurs, the subsequent linked list needs to be connected to the end of the branch linked list.
Therefore, a function is designed. The input is the head node of the linked list, and the return value is the tail node of the linked list (or the head of the sub linked list). When there is a branch, enter the head node of the branch into the function, then find the tail node of the returned linked list, and connect the trunk to the tail node.
(simple recursive function, but the processing of pointer field is cumbersome and easy to write wrong)
Sample code
/*
// Definition for a Node.
class Node {
public int val;
public Node prev;
public Node next;
public Node child;
};
*/
class Solution {
public Node flatten(Node head) {
Node p = head,q,k;
while(p!=null){
if(p.child!=null){
q = p.next;
k = flatten(p.child);
p.child = null;
p.next = k;
k.prev =p;
while(k.next!=null)k= k.next;
k.next = q;
if(q!=null)q.prev = k;
}
p = p.next;
}
return head;
}
}
leecode 863. All nodes with distance K in binary tree
Link: https://leetcode-cn.com/problems/all-nodes-distance-k-in-binary-tree
Given a binary tree (with root node), a target node, and an integer value K.
Returns the list of values of all nodes with target distance K to the target node. The answers can be returned in any order.
Example 1:
Input: root = [3,5,1,6,2,0,8,null,null,7,4], target = 5, K = 2 Output:[7,4,1] Explanation: The calculated node is a node with a distance of 2 from the target node (value of 5), The values are 7, 4, and 1, respectively Note that the entered "root" and "target" It's actually a node in the tree. The above input only describes the serialization of these objects.
Tips:
- The given tree is not empty.
- Each node in the tree has a unique value of 0 < = node val <= 500 .
- The target node target is the node on the tree.
- 0 <= K <= 1000.
Problem solving ideas
First of all, the target node is needed to consider the multi division problem
(thinking needs to be structurally changed to simplify complex problems)
(there are two ways of structured thinking in this topic)
(the first method is to discuss downward query first, and then upward query.)
(the second method is to assume that K is 1 and the conjecture distance of topology is, and then gradually increase K to find the law)
Think about it first:
When the distance is 1, you need to find 1 downward and 1 upward; When the distance is 2, you need to find 2 down, 2 up, 1 up, and then 1 down ...... Distance is K When, look up N Then look down( K-N),N The value of is 0~K.
Therefore, two functions are required, one is only responsible for finding all nodes with a downward (K-N) distance, and the other is responsible for finding N-level parent nodes upward.
(it should be noted that if you reverse up and down, you must change a subtree, otherwise duplicate paths will appear.)
The final steps are:
- Prepare the function to find the node below the target node. Recursive search needs to be performed downward. The depth of recursion is distance K
- Find the node above the target node. A rule needs to be prepared
- First, find the node with distance n upward, then change a subtree for the corresponding node, find the K-N node downward, and store the found node in the return set
- Then make the value of N from 0 to K (including 0 is equivalent to only looking down. When n is 0, there is no need to replace the subtree).
(the method I use to solve the problem is to first implement method 2 to understand the expansion of the model, and then use method 1 to design the way to find nodes. This problem has nothing to do with the course).
(there are many solutions to this problem. If you are interested, you can design a different solution)
(the solution I designed is as follows:)
- Prepare a function to traverse the binary tree. During the traversal, always record and prepare the current node. When the target node is finally found, trace back. Each layer is successively stored in the starting array, only k are stored, and record whether the subtree is left or right.
- Prepare a class to meet the encapsulation conditions required by the above array: including nodes and left and right subtrees
- Prepare a search function. The input parameters are node and depth. When the conditions are met to obtain the node of the target depth, the corresponding node value is returned, and the returned value is stored in the result set
- Traverse the starting array, select the search depth according to the subscript, and select the root node of another subtree as the input parameter according to the left and right subtree marks
- Loop, which returns the result set at the end of the loop
Sample code
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
private int k;
private int len;
private Node [] startArr;
private ArrayList <Integer> res;
public List<Integer> distanceK(TreeNode root, TreeNode target, int k) {
//int wantVal = target.val;
len = 0;
this.k = k;
startArr = new Node [k+1];
res = new ArrayList <Integer> ();
if(!findTarget(root,target)){
//System.out.println("---");
return res;
}
//System.out.println(len);
for(int i=0;i<len;i++){
TreeNode start = startArr[i].node;
if(i==0||i==k)
findDeep(start,k-i);
else{
if(startArr[i].isLeft)
start = start.right;
else
start = start.left;
findDeep(start,k-i-1);
}
}
return res;
}
private void findDeep(TreeNode root,int deep){
if(root == null) return;
if(deep <= 0){
res.add(root.val);
return;
}
deep--;
findDeep(root.left,deep);
findDeep(root.right,deep);
}
private Boolean findTarget (TreeNode root, TreeNode target){
int wantVal = target.val;
if(root.val == wantVal){
//In itself, true here is meaningless
startArr[len++] = new Node(root,true);
return true;
}
//It can only come from one branch
if(root.left!=null){
if(findTarget(root.left,target)){
if(len<k+1)
startArr[len++] = new Node(root,true);
return true;
}
}
if(root.right!=null){
if(findTarget(root.right,target)){
if(len<k+1)
startArr[len++] = new Node(root,false);
return true;
}
}
return false;
}
}
class Node{
TreeNode node;
Boolean isLeft;
public Node(TreeNode node,Boolean isLeft){
this.node = node;
this.isLeft = isLeft;
}
}
(nice, fast)
Execution time: 13 ms , At all Java Defeated in submission 100.00% User Memory consumption: 38.7 MB , At all Java Defeated in submission 22.00% User
epilogue
It takes about 2h to complete the basic part with the video and 0.5h to complete the notes
It takes about 4h to complete the exercises with the video, and 9h to complete the problem-solving ideas and codes
The total video duration is 5H, so this time it is 15.5H, three times the time
Obviously, it takes a long time to solve the problem. I have skipped half the code of the problem. Therefore, I still need to continue to practice.
I simplified the learning steps to 4 steps and thought I had completed the learning task with high quality.
But in the process, I tried to break away from the current learning model and try other learning strategies. Finally, I found that the learning efficiency is almost proportional to my thinking time, and video helps to improve the thinking efficiency. Therefore, we will continue to follow the current 4-step learning method.
(in addition, the reason why it takes a long time in the problem-solving stage is that the thinking is not comprehensive and the phased development depends too much on the debugging function. This may be due to the lack of IQ. It is expected to be improved through training)
ε ≡ ٩ (๑>₃<) ۶ Wholeheartedly learn