1, List
Common API
Underlying implementation
List is an ordered data structure (sorted according to the added sequence). Redis uses quicklist (double ended linked list) and ziplist as the bottom implementation of list.
You can improve data access efficiency by setting the maximum capacity of each ziplost and the data compression range of quicklist.
// A single ziplost node can store up to 8kb. If it exceeds 8kb, it will be split and the data will be stored in a new ziplost node // Note that the number in the configuration is not the actual size, so it should be configured according to the corresponding relationship- 1=4kb, -2=8kb, -3 =16kb.. list-max-ziplist-size -2 // 0 means that all nodes are not compressed, 1 means that one node goes back from the head node, one node goes forward from the tail node without compression, and all other nodes are compressed, 2, 3, 4 and so on list-compress-depth 1
Consideration: why not use linked list?
1. The prve and next nodes of the linked list occupy a large space, each of which needs 4 bytes. In this way, if there is not a lot of data stored in the list, it will waste space in price comparison;
2. The storage of elements in the linked list is not continuous, which will form more memory fragments.
To sum up, redis uses a compact zip list to implement list
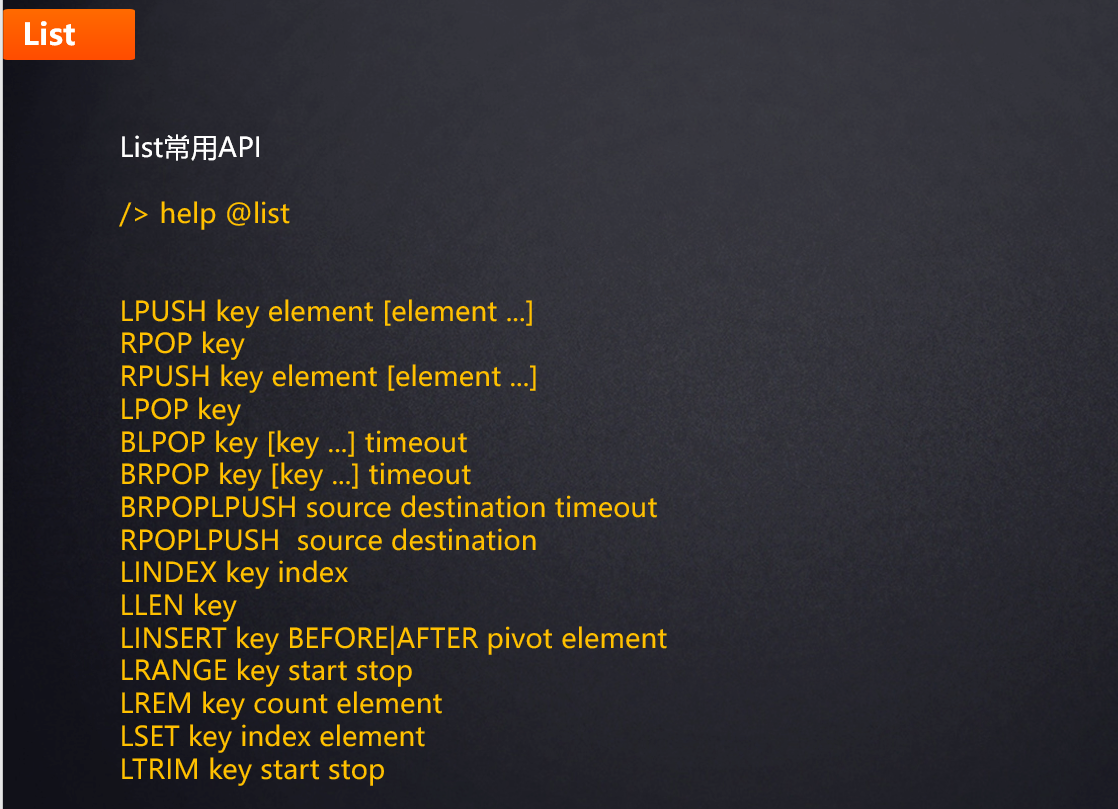
ziplist bottom design
- zlbytes: indicates the size of the data stored in the ziplost;
- zltail: index position of tail node;
- zlen: number of elements;
- zlend: indicates the end of data;
- entry1~entryN: represents the elements in the ziplost.
Let's take another look at the structure of each Entry:
- prerawlen: information about the previous element. If it is less than 254 bytes, it means that the current data is small, and only 1 byte is allocated for storage; If it is greater than 254, 4 more bytes need to be allocated;
- len: information such as the type of the current element;
- data: the value of the current element
Think: why doesn't Redis directly use ziplost to store all data? Why introduce quicklist?
If we have a large number of elements, deleting elements will cost performance, because space assignment needs to be reallocated after deletion (similar to array deletion and modification).
quicklist
Redis introduces quicklist to associate multiple zip lists.
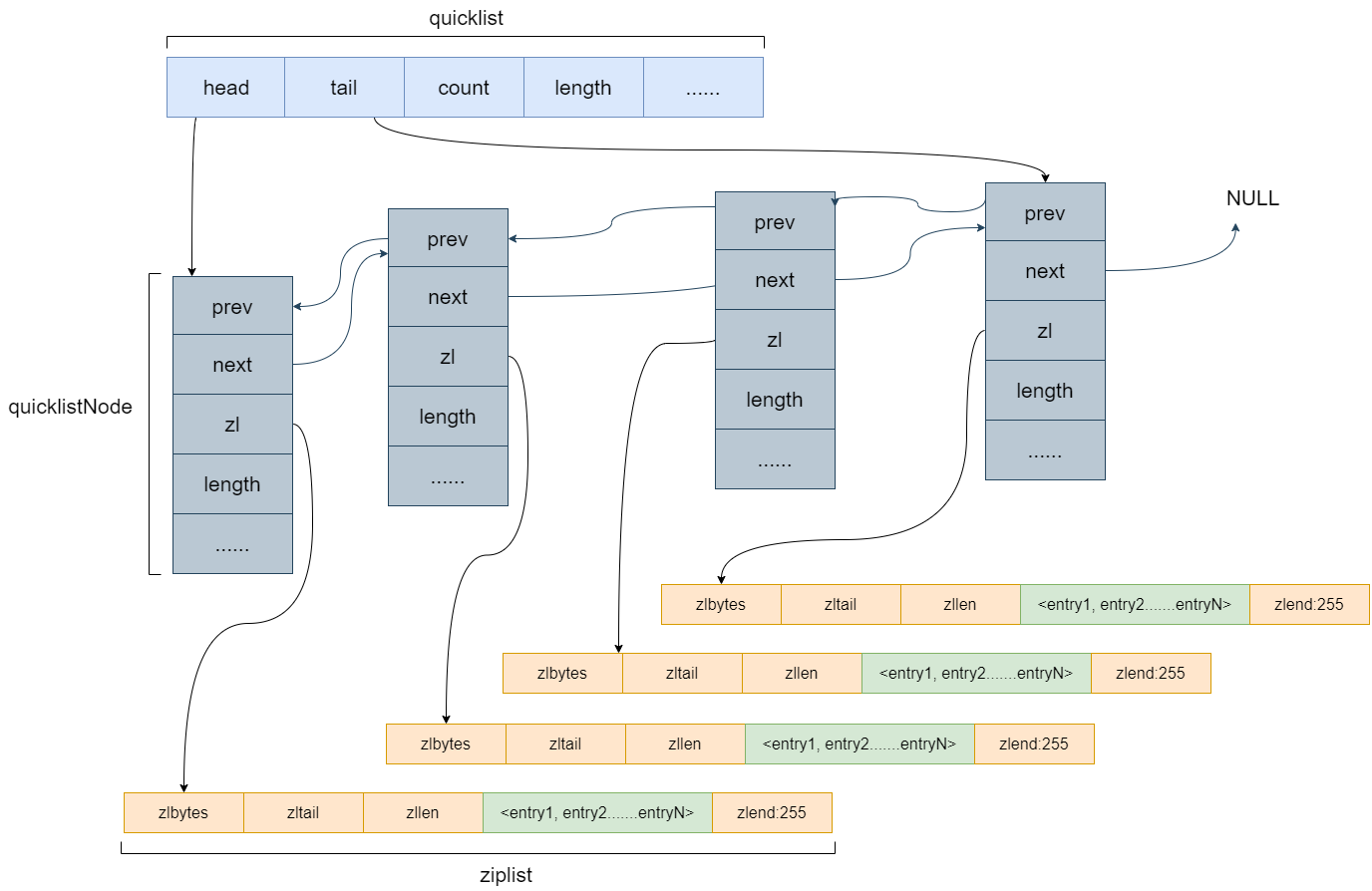
- Head: associate the head node and point to the ziplost of the tail node;
- Tail: associated tail node, pointing to the ziplost of the head node;
- count :
- quicklistNode: a quicklist node;
Now, instead of maintaining all data in a ziplost, each data has a separate ziplost storage. In this way, to add or delete elements, you only need to maintain the linked list in the quicklist.
At this time, the maximum storage value of each ziplost is 8kb by default. If it exceeds 8kb, you need to regenerate a new ziplost for storage. This value can also be configured by itself:
Note that the number in the configuration is not the actual size and should be configured according to the corresponding relationship- 1=4kb, -2=8kb, -3 =16kb…
list-max-ziplist-size -2
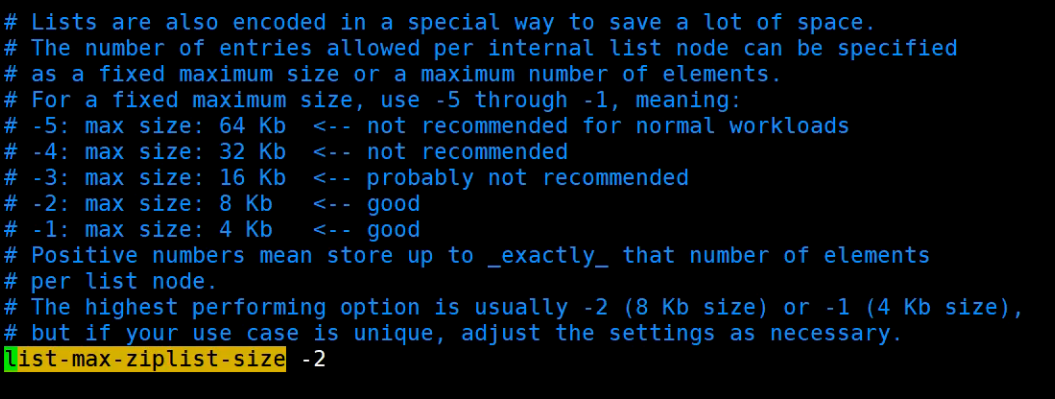
data compression
In hot spot data, the data of head node and tail node may need to be accessed frequently, but for some elements in the middle, the access may not be so frequent. We can compress the elements in the middle
// 0 means that all nodes are not compressed, 1 means that one node goes back from the head node, one node goes forward from the tail node without compression, and all other nodes are compressed, 2, 3, 4 and so on list-compress-depth 1
2, Hash
Common API
Underlying implementation
The bottom layer of the Hash data structure is implemented as a dictionary (dict), which is also the data structure used by RedisBb to store K-V. when the amount of data is relatively small or a single element is relatively small, the bottom layer is stored with ziplist. The threshold values of data size and number of elements can be set through the following parameters.
// If the number of ziplost elements exceeds 512, it will be encoded as hashtable hash-max-ziplist-entries 512 // When the size of a single element exceeds 64 byte s, it will be changed to hashtable encoding hash-max-ziplist-value 64

hashtable storage is used when the number of elements or the value of a single element exceeds a certain threshold

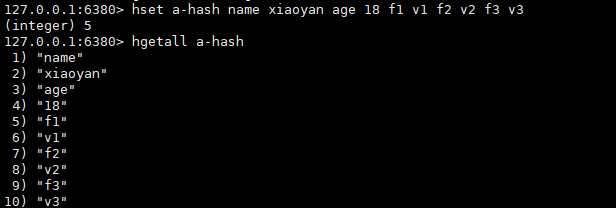
We can verify that whenever the data element is less than 512 and the value of each element is less than 64byte, the data structure should be ziplost (ordered).

Let's insert another element with a higher value ratio:
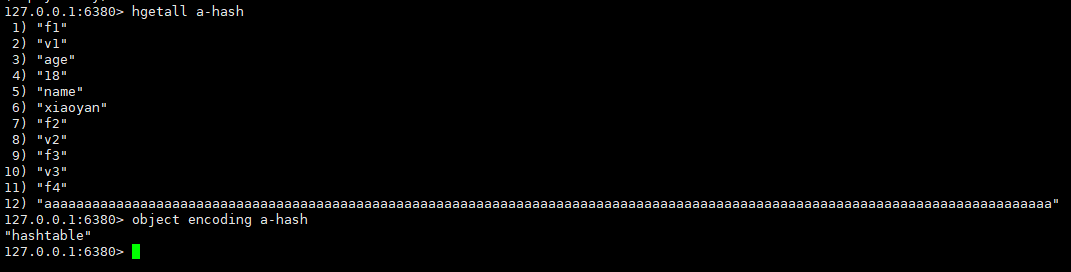
It is found that the underlying code has become hashtable l
3, Set
Common API
smembers a-set: view all elements in the set.
smembers a-set 1) "1" 2) "3" 3) "4" 4) "5" 5) "9" 6) "10"
Underlying implementation
Set is an unordered, automatically de duplicated and automatically sorted set data type. The underlying implementation of the set data structure is a dictionary (dict) with null value. When the data can be represented by shaping, the set will be encoded as an intset data structure.
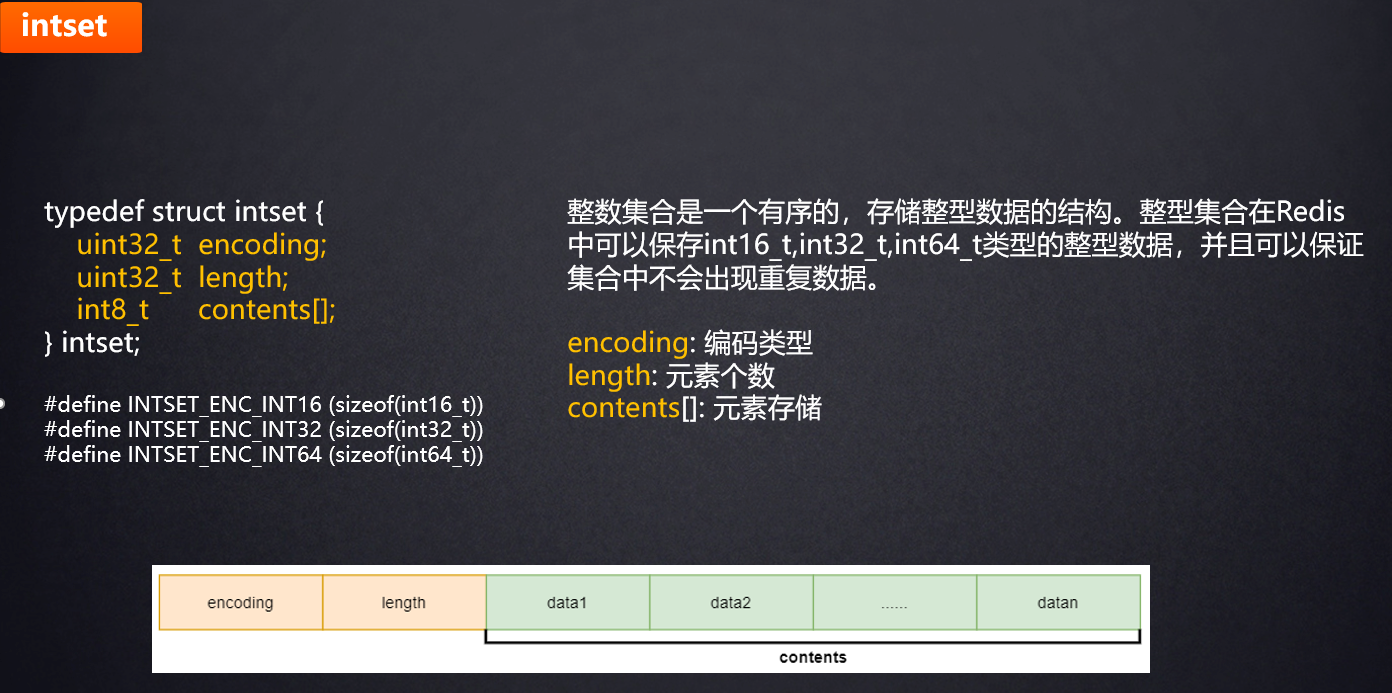
When any of the two conditions are met, Set will use hashtable to store data.
- 1. The number of elements is greater than set Max intset entries;
set-max-intset-entries 512 // The maximum number of elements that intset can store. If it exceeds, it is encoded with hashtable
- 2. The element cannot be expressed as an integer
The elements in the Set will be automatically de duplicated and sorted (when all are integers)
127.0.0.1:6380> sadd a-set 1 3 5 10 9 4 4 4 127.0.0.1:6380> smembers a-set 1) "1" 2) "3" 3) "4" 4) "5" 5) "9" 6) "10"
Set storage
Let's check the a-set code just set:

As you can see, intset storage is used at this time.
Let's add an a element and check again:
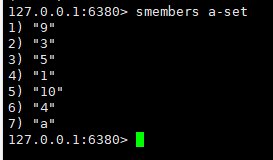
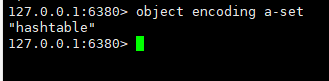
It is found that the element a has disrupted the original order. Because we can't use intset to store this a, let's look at the underlying code and find that it has been transformed from intset to hashtable.
4, Set
Common API
127.0.0.1:6380> zadd a-zset 100 a 200 b 150 c (integer) 3 127.0.0.1:6380> zrange a-zset (error) ERR wrong number of arguments for 'zrange' command 127.0.0.1:6380> zrange a-zset 0 -1 1) "a" 2) "c" 3) "b" 127.0.0.1:6380> zrange a-zset 0 -1 withscores 1) "a" 2) "100" 3) "c" 4) "150" 5) "b" 6) "200" 127.0.0.1:6380>
zset will automatically sort by score!
Underlying implementation
ZSet is an ordered and automatically de duplicated set data type. The bottom layer of ZSet data structure is implemented as dictionary (dict) + skip list. When there is little data, it is stored in ziplost coding structure.

When the following conditions are met, skip list skip coding will be used:
zset-max-ziplist-entries 128 // If the number of elements exceeds 128, it will be encoded with skiplist zset-max-ziplist-value 64 // If the size of a single element exceeds 64 byte s, it will be encoded with skiplist
ZSet automatically sorts by score
zset will automatically sort by score!
127.0.0.1:6380> zrange a-zset 0 -1 withscores 1) "a" 2) "100" 3) "c" 4) "150" 5) "b" 6) "200"
ZSet storage
Let's look at the zset code above:

Found ziplist When the data is small, it is stored using ziplist.
We now add a very large element (larger than 64byte) to verify whether it will be encoded with a hop table:
Zset data structure

5, Skip list
1. Generation background
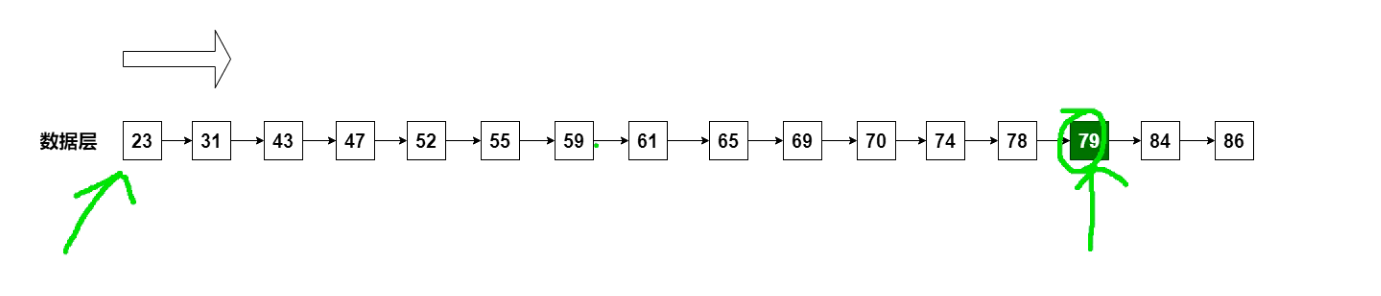
If we use a linked list to store data, if we want to query a certain data, we need to find the header node first, and then traverse in turn to find the element. The time complexity is O(n).
We can consider adding an index layer to the linked list to optimize the query:

With this index layer, if we want to query 79 elements, we can query from the index layer first. So we can find 79 between 78 and 84. In this way, you only need to query about half of the elements to find the target value.
So is there room for optimization? We wonder if the index layer interval can be a little larger and the layer can be a little more?
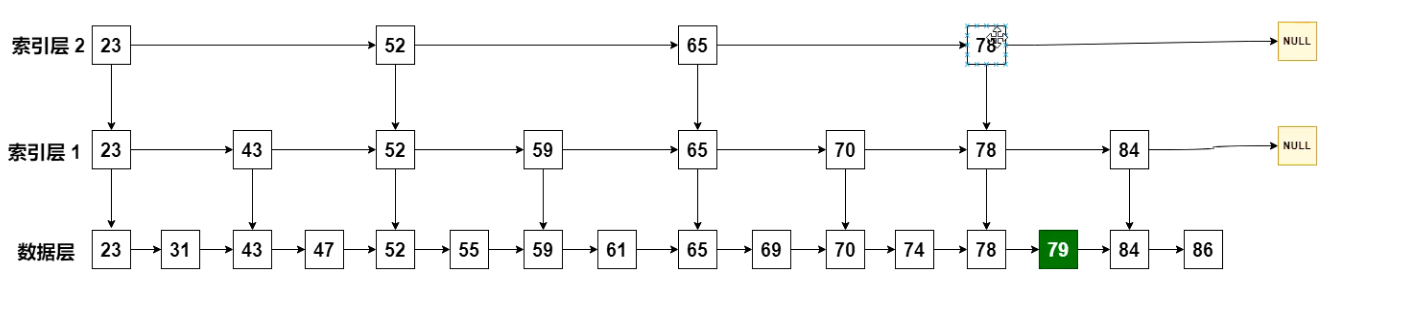
Now we have a two-tier index. To query 79, first query 78 of index layer 2 and find that there are no other elements behind it. Go to 78 in index layer 1 successively, and then continue to query backward. Found 84, and then went to the data layer to find 79
In this way, the number of queries can be reduced.
We continue to optimize and add another layer of index:
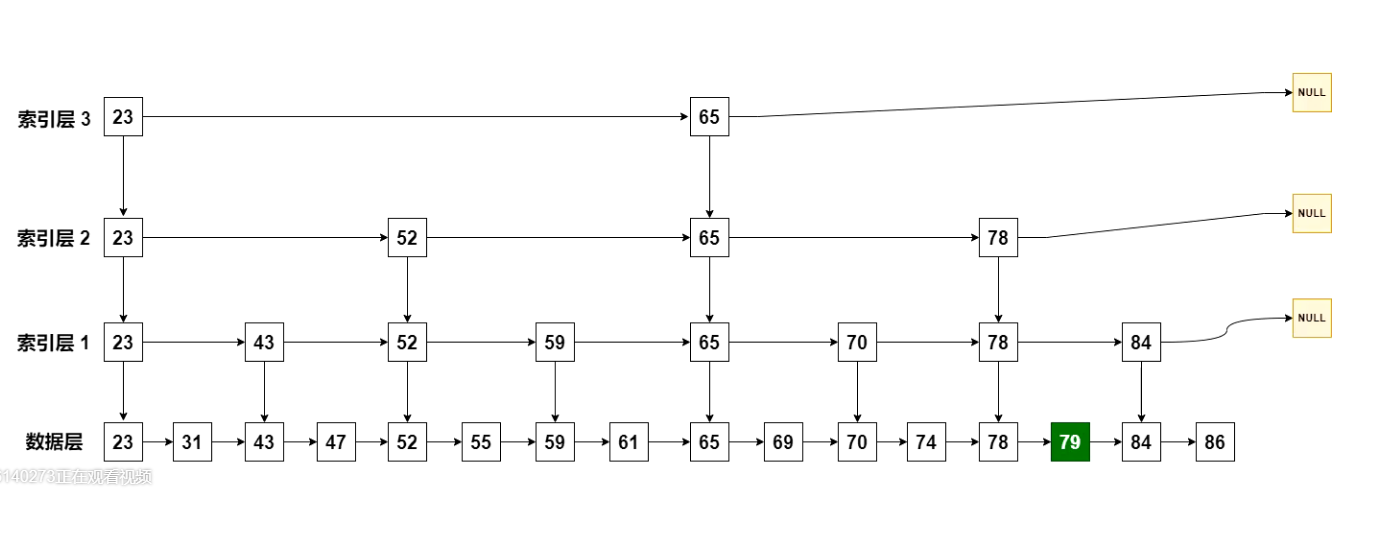
Half a query at a time is a bit similar to half a search. In this way, the number of queries is reduced.
Let's calculate the query complexity at this time:
data item : Number of searches ------------------------------------ index 1 : N / 2^1 index 2 : N / 2^2 index 3 : N / 2^3 .... index k : N / 2^k If we set the top-level index, the data will be divided into two ends, then N / 2^k = 2, Namely: 2^k = N /2 k = log N
This is the skip list. An index is added to the array to exchange space for time.
In fact, the bottom layer of Redis does not directly use the jump table, but makes some modifications to it.
Implementation of table hopping in Redis
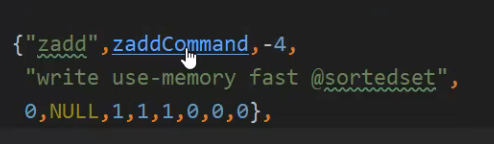
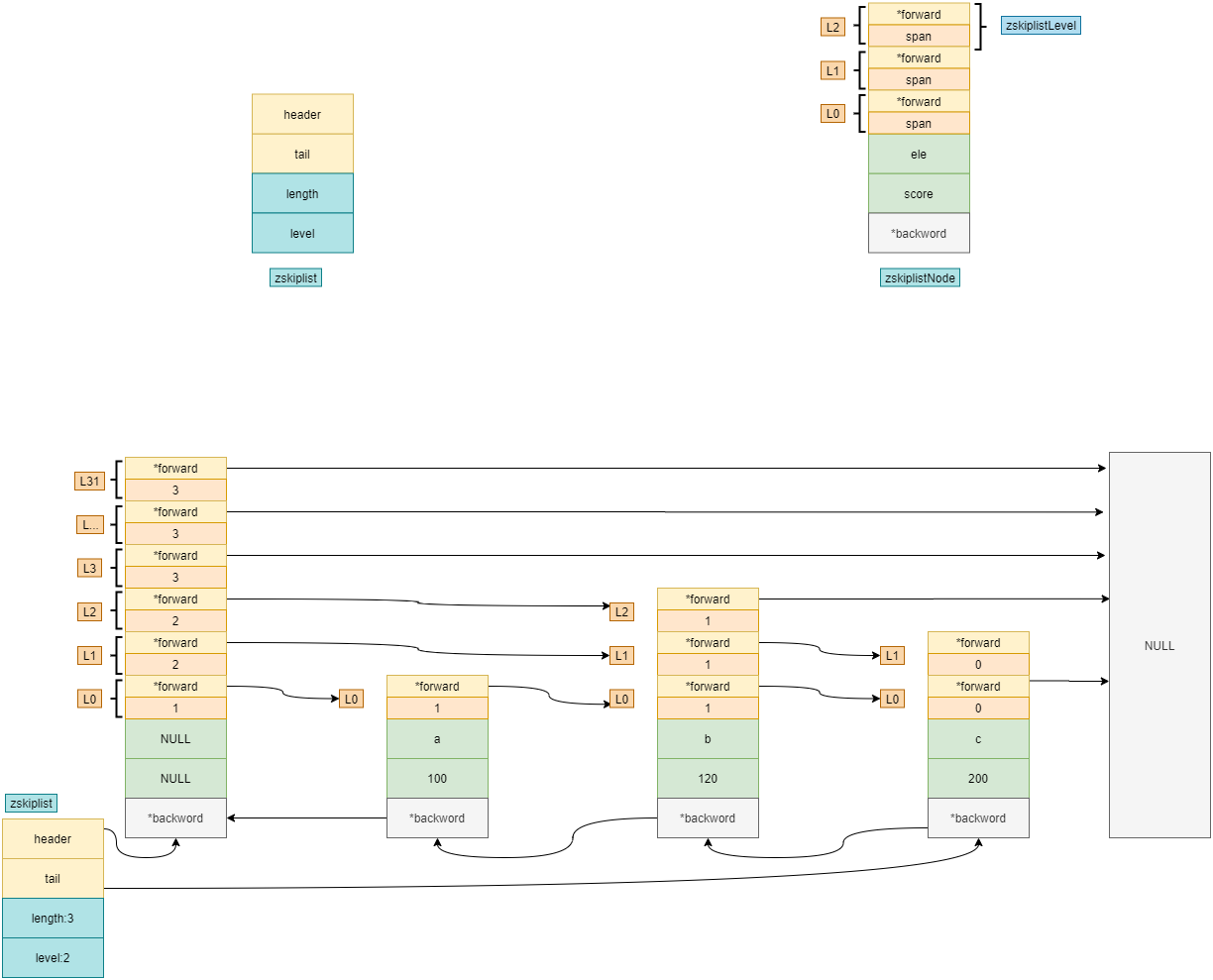
Note that zskipplist records information related to the index:
- header: pointer to index layer;
- Tail: point to the tail node;
- length: number of elements;
- level: layer height, because it needs to be traversed from top to bottom, and the number of the highest layer needs to be obtained.
- The back work pointer is used for traversal from front to back:
127.0.0.1:6380> ZREVRANGE a-zset 0 -1 withscores 1) "b" 2) "200" 3) "c" 4) "150" 5) "a" 6) "100" 127.0.0.1:6380>
Data insertion
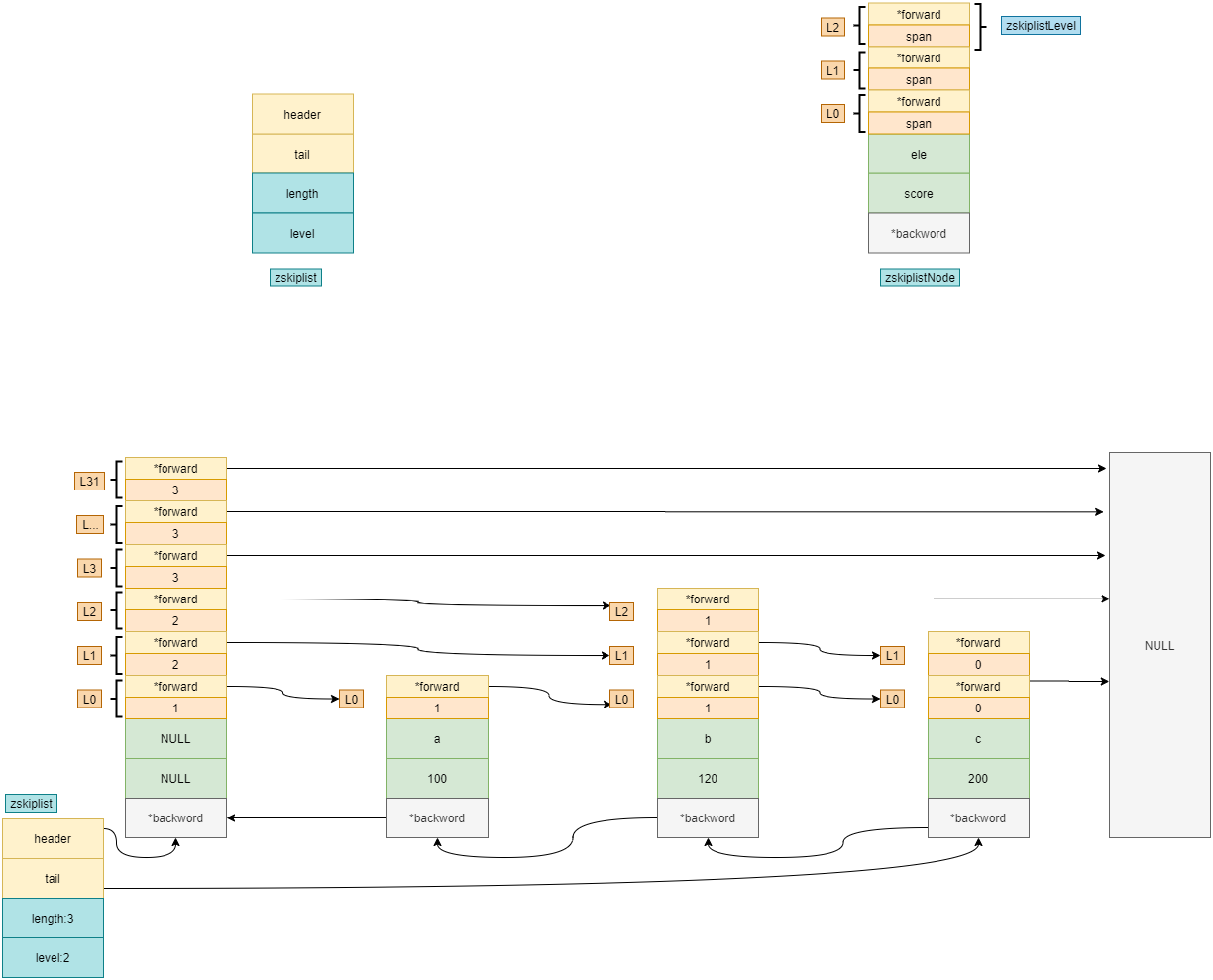
If you already have the following elements
127.0.0.1:6380> zrange b-zset 0 -1 withscores 1) "a" 2) "100" 3) "b" 4) "120" 5) "c" 6) "200"
Its hop table in Redis is shown in the figure:
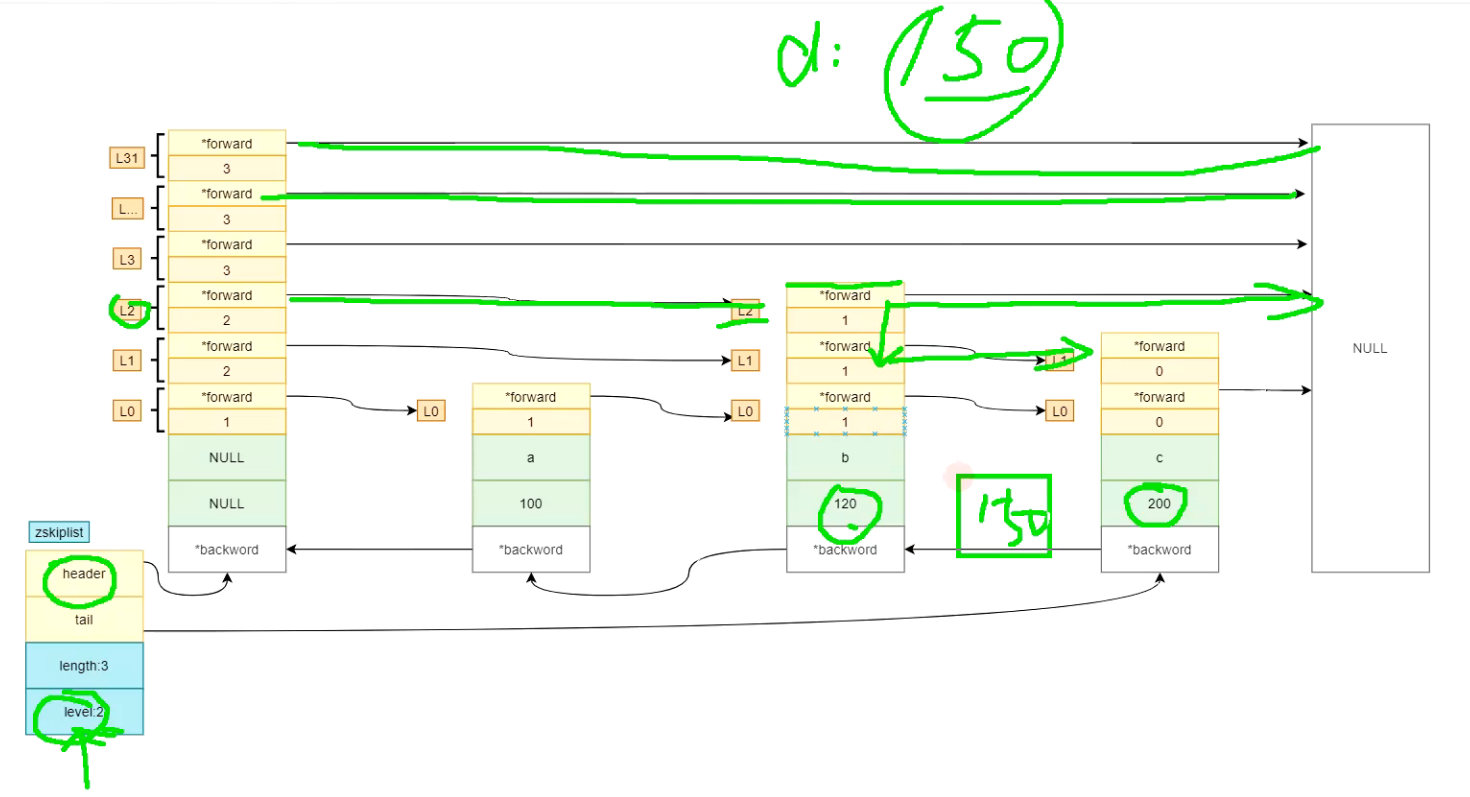
We now want to add an element: 150 d. here is the addition rule:
1. Now find L2 from the first element NULL according to the level in zskiplist;
2. Find the real L2 element according to the pointer of L2 in NULL, and it is found to be b 120;
3. Judge whether the data 150 to be inserted is greater than 120. If so, continue to look down;
4. Find the rightmost NULL, indicating that you want to find L1;
5. Find the L1 pointer on node b, continue to look down, and find the element c connected with L1;
6. If it is found that the 150 to be inserted is less than 200, the element 150 d should be inserted here.
Source code implementation
1. Find the position to insert;
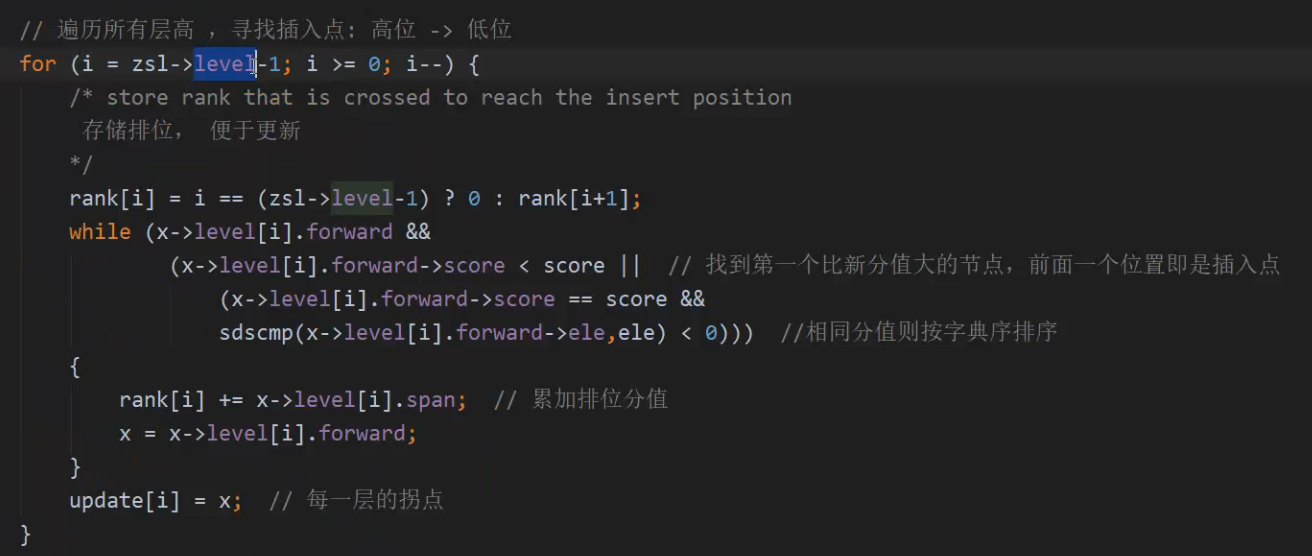
2. Create a new node and add it to the hop table;
6, Use of jump table in Geo
GeoHash is a geolocation coding method. Invented by Gustavo Niemeyer and G.M. Morton in 2008, it encodes geographical location into a short string of letters and numbers. It is a hierarchical spatial data structure, which subdivides the space into grid shaped buckets. This is one of the many applications of the so-called z-order curve, usually the spatial filling curve.
Common API
1. Command view
127.0.0.1:6380> help @geo GEOADD key [NX|XX] [CH] longitude latitude member [longitude latitude member ...] summary: Add one or more geospatial items in the geospatial index represented using a sorted set since: 3.2.0 GEODIST key member1 member2 [m|km|ft|mi] summary: Returns the distance between two members of a geospatial index since: 3.2.0 GEOHASH key member [member ...] summary: Returns members of a geospatial index as standard geohash strings since: 3.2.0 GEOPOS key member [member ...] summary: Returns longitude and latitude of members of a geospatial index since: 3.2.0 GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count [ANY]] [ASC|DESC] [STORE key] [STOREDIST key] summary: Query a sorted set representing a geospatial index to fetch members matching a given maximum distance from a point since: 3.2.0 GEORADIUSBYMEMBER key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count [ANY]] [ASC|DESC] [STORE key] [STOREDIST key] summary: Query a sorted set representing a geospatial index to fetch members matching a given maximum distance from a member since: 3.2.0 GEOSEARCH key [FROMMEMBER member] [FROMLONLAT longitude latitude] [BYRADIUS radius m|km|ft|mi] [BYBOX width height m|km|ft|mi] [ASC|DESC] [COUNT count [ANY]] [WITHCOORD] [WITHDIST] [WITHHASH] summary: Query a sorted set representing a geospatial index to fetch members inside an area of a box or a circle. since: 6.2 GEOSEARCHSTORE destination source [FROMMEMBER member] [FROMLONLAT longitude latitude] [BYRADIUS radius m|km|ft|mi] [BYBOX width height m|km|ft|mi] [ASC|DESC] [COUNT count [ANY]] [WITHCOORD] [WITHDIST] [WITHHASH] [STOREDIST] summary: Query a sorted set representing a geospatial index to fetch members inside an area of a box or a circle, and store the result in another key. since: 6.2 127.0.0.1:6380>
Map function practice
If we want to implement a function now, after inputting our own location, we can use geo to view the surrounding places;
1. We first search "pick up coordinate address" in Baidu, and then enter the website http://api.map.baidu.com/lbsapi/getpoint/ ;
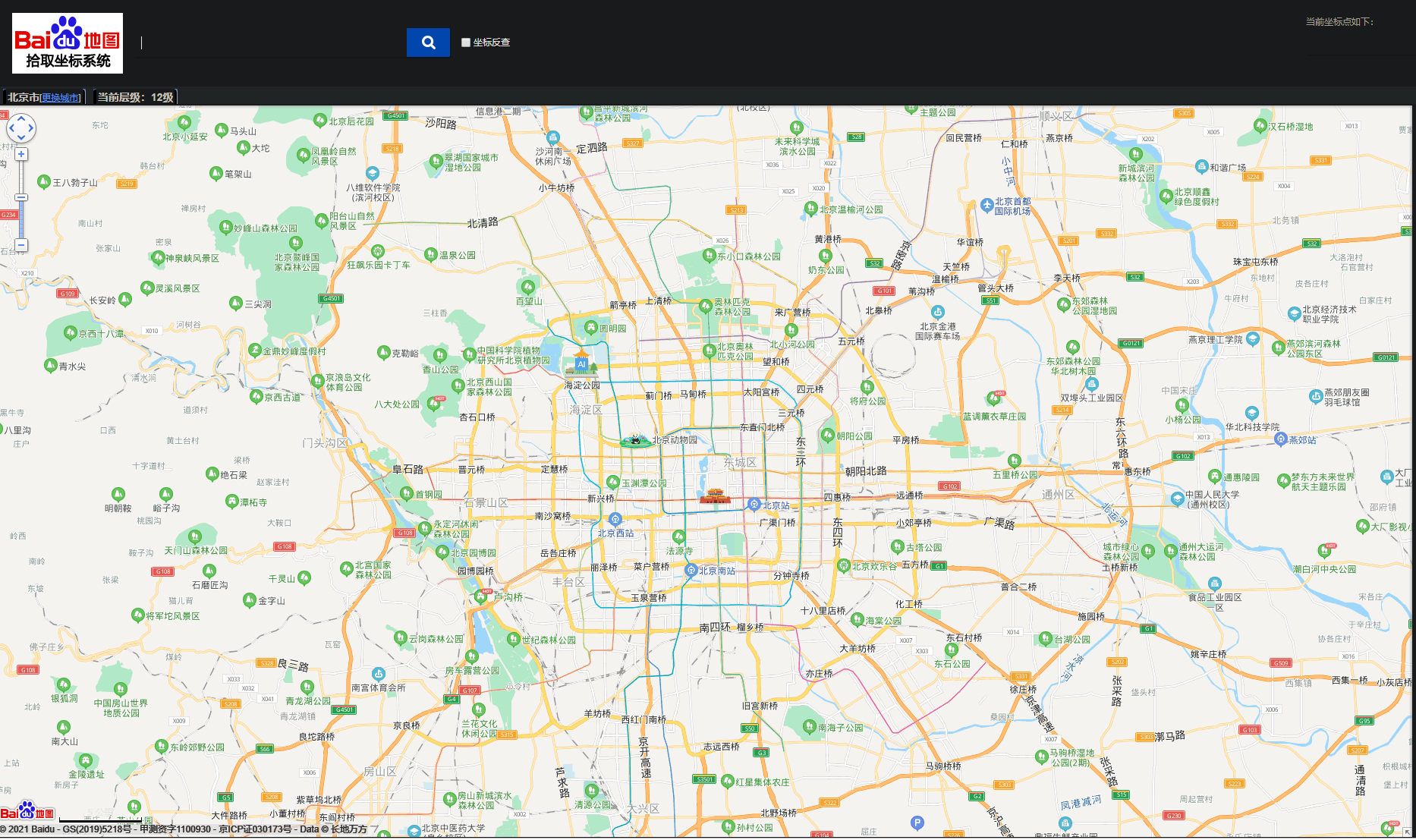
2. We click the location to obtain the longitude and latitude of some locations and add them to redis:
// 116.400739,39.918672 -> 116.400739 39.918672 geoadd locations 116.400739 39.918672 gugong geoadd locations 116.344972 39.947884 beijingzoos geoadd locations 116.303578 39.990794 haidianpark
3. Check the distance between the Forbidden City and Beijing Zoo:

Insert code snippet 127 here.0.0.1:6380> GEODIST locations gugong beijingzoos km "5.7602" 127.0.0.1:6380>
It can be seen that the giant deer between them is 5.7 kilometers.
Take another look at the distance from the Forbidden City to Haidian Park:
127.0.0.1:6380> GEODIST locations gugong haidianpark km "11.5315" 127.0.0.1:6380>
4. Location query
- Longitude and latitude radius query:
longitude, latitude, radius
GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count [ANY]] [ASC|DESC] [STORE key] [STOREDIST key] summary: Query a sorted set representing a geospatial index to fetch members matching a given maximum distance from a point since: 3.2.0

- Query of radius x km from a certain place
GEORADIUSBYMEMBER key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count [ANY]] [ASC|DESC] [STORE key] [STOREDIST key] summary: Query a sorted set representing a geospatial index to fetch members matching a given maximum distance from a member since: 3.2.0

Let's check the location 15km around the Forbidden City:
127.0.0.1:6380> GEORADIUSBYMEMBER locations gugong 15 km 1) "gugong" 2) "beijingzoos" 3) "haidianpark"
It can be seen that all the locations within the radius of 15 kilometers of the Forbidden City have been successfully queried.
We only check the place 6 kilometers away from the Forbidden City:
127.0.0.1:6380> GEORADIUSBYMEMBER locations gugong 6 km 1) "gugong" 2) "beijingzoos"
You can only find the Beijing Zoo.
GEO underlying implementation
Let's take a look at the data structure of locations:
It is found that GEO is stored using zset.
Let's look at the underlying coding format:

It is implemented using ziplost, because the amount of data is small now. If the amount of data is large, it should be converted into hashtable storage.
GeoHash longitude and latitude coding
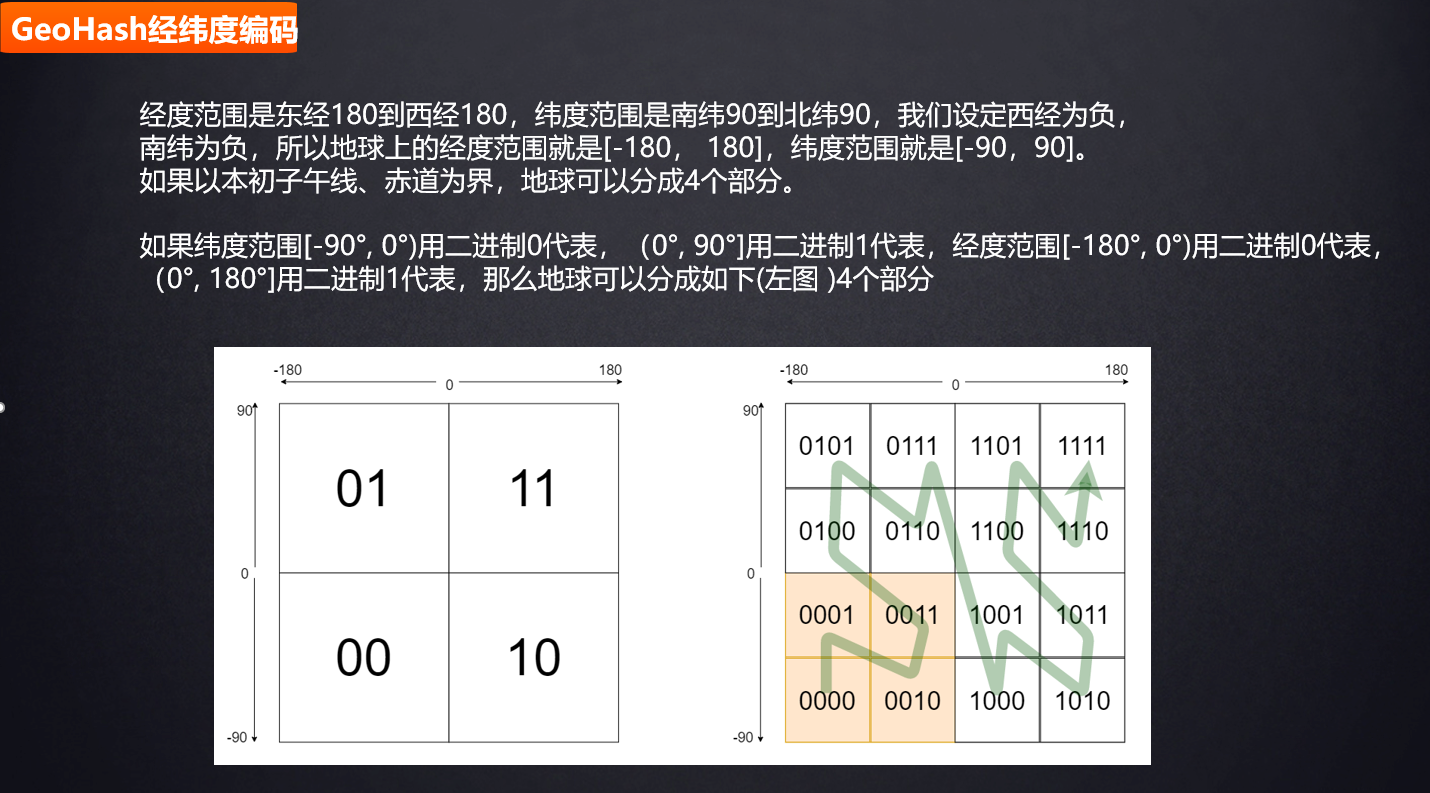

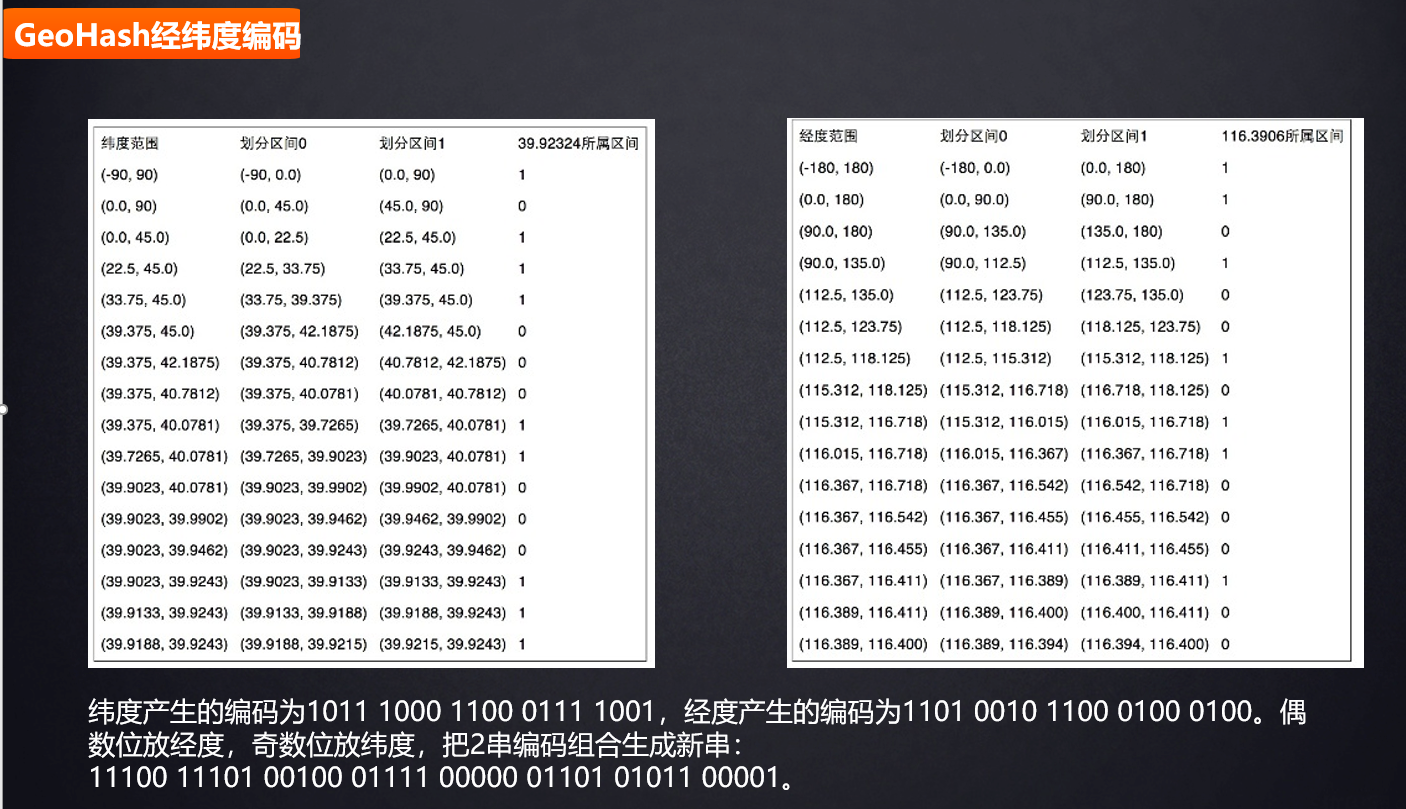

GeoHash advantages and disadvantages

*Interview questions
1. What are the advantages and disadvantages of String and Hash?
For example, there are data:
user: id: 100 name: nangua age:18 ...
What are the advantages and disadvantages of using String and Hash storage for this structure?
1. Use String storage
user:id 100 user:name nangua user:age 18 ......
Disadvantages:
It is obvious that multiple keys are needed to store an object, and SDS is used to store keys. More keys naturally require more storage space.
Secondly, we know that the underlying String is stored using dict (Dictionary).
When we add a new data, we need hash (key) - > arr []. In this way, if there is a lot of data, the data will soon become very large. When data elements increase to a certain extent, rehash needs to be expanded.
Therefore, if String is used for storage, it may also bring frequent rehash.
advantage:
You can set the expiration time for each attribute.
2. Using hash storage
advantage:
The advantage of using hash is that only one key will be used
Then fields such as name and age will be stored in the internal small hashtable. In this way, storage can reduce external frequent rehash.
Disadvantages:
As we know, only the key of the most layer can set the expiration time. If we use hash storage, we cannot accurately set the expiration of a field of the object.