Image classification on the propeller platform
preface
The plan is to use it on the propeller platform to classify animals and fruits during the winter vacation.
The data set has been established previously: Do image classification on the propeller Platform-1 make the data set based on the propeller
Here, the high-level API of the propeller is used to quickly complete the model networking and training
I use the BIM CodeLab of the propeller, and the environmental information is like this

Import dataset
The data set has been established previously: Do image classification on the propeller Platform-1 make the data set based on the propeller
I put myimagereader Put py in the work folder
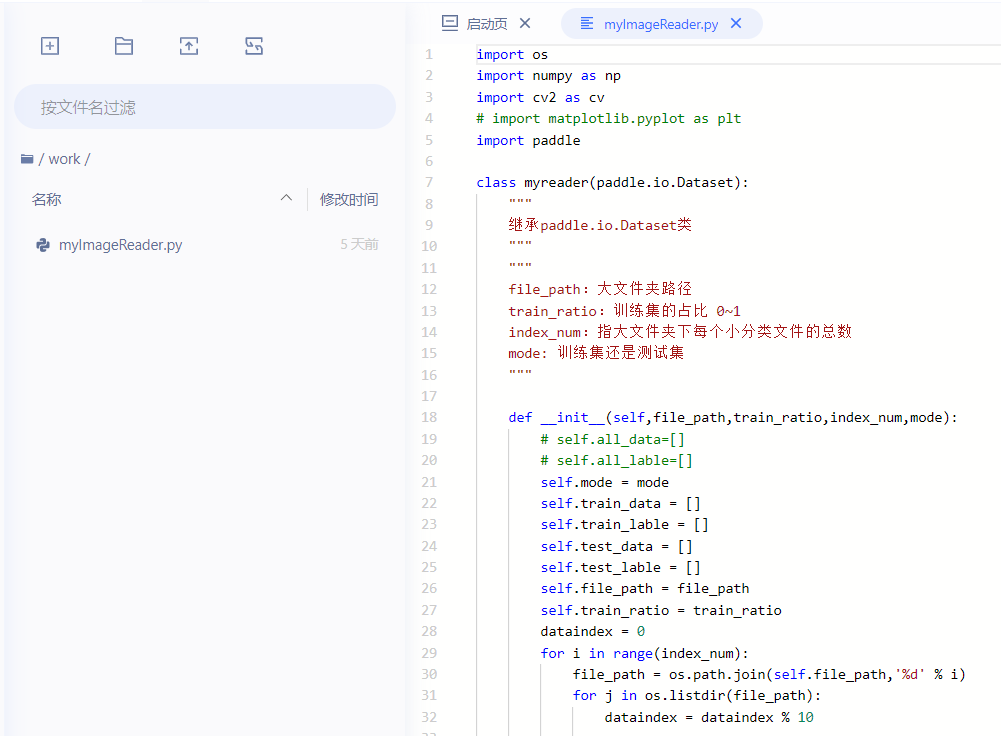
Import myImageReader
from work import myImageReader
Use this to return the defined data set
''' Image file path; The proportion of training sets in the total; Type of reading; ''' train_dataset = myImageReader.myreader(r'animal_fruit',0.7,9,'train')
Then use the pad io. The dataloader method loads the dataset. This method returns an iterator, which will iterate the given datast according to the given order. file paddle.io.DataLoader
The document says return_ In dynamic graph mode, the parameter list must be set to True, and the default is False. Now, the versions above 2.0 of the propeller are in the dynamic graph mode by default (you can search for the dynamic graph and static graph mode of the propeller first). However, in the source code of propeller 2.2, this parameter is True by default, that is, this parameter does not need to be set in dynamic graph mode.
In addition, the parameter places is also mentioned in the source code of 2.2. If it is None, the default location (CPUPlace or CUDAPlace(0)) is used.
''' Set batch The size of the and whether it is disturbed ''' train_loader = paddle.io.DataLoader(train_dataset, batch_size=64, shuffle=True)
Use these to import data sets on the BIM CodeLab of the propeller:
- Import the required modules first:
from work import myImageReader import paddle import matplotlib.pyplot as plt import numpy as np
There may be this warning. It's harmless
If you don't like it, you can add these two lines to ignore the warning:
import warnings
warnings.filterwarnings('ignore')
Then import the data set with the above method
# Import training set train_dataset = myImageReader.myreader(r'animal_fruit',0.7,9,'train') train_loader = paddle.io.DataLoader(train_dataset, batch_size=64, shuffle=True) # Import test set test_dataset = myImageReader.myreader(r'animal_fruit',0.7,9,'test') test_loader = paddle.io.DataLoader(test_dataset, batch_size=64, shuffle=True) # Verify that the read was successful print(train_dataset[1][0]) l = np.array(train_dataset[0][0]) plt.figure(figsize=(2,2)) plt.imshow(l, cmap=plt.cm.binary)
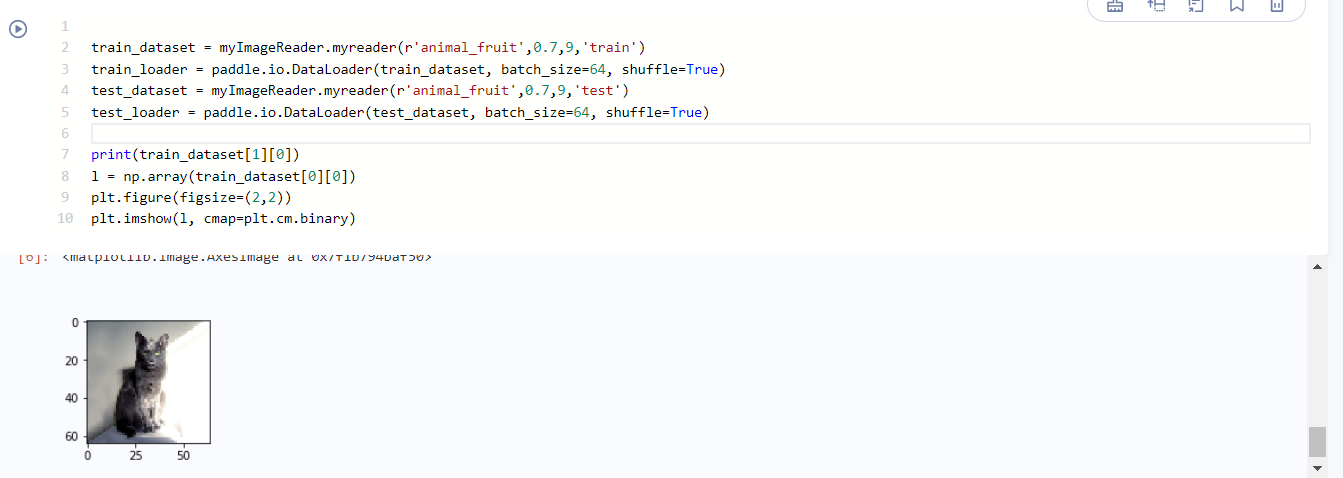
So far, the establishment and reading of the data set are completed.
Sequential networking
The propeller framework supports two networking modes: sequential networking and SubClass networking. Sequential can quickly complete networking. However, when we want to build some complex network structures, we may need SubClass networking. I use sequential to quickly build a simple network.
Sequential document
The network consists of convolution layer, pooling layer, activation function layer and linear transformation layer.
Pay attention to the paddle nn. Conv2d and pad nn. The default input format of maxpool2d is' NCWH ', N is the batch size, C is the number of channels, H is the feature height and W is the feature width. The reading format of my dataset is' NHWC ', so I need to set it.
mnist = paddle.nn.Sequential(
paddle.nn.Conv2D(3,16,(3,3),data_format='NHWC'),
paddle.nn.ReLU(),
paddle.nn.MaxPool2D(2, 2,data_format='NHWC'),
paddle.nn.Conv2D(16,32,(3,3),data_format='NHWC'),
paddle.nn.ReLU(),
paddle.nn.MaxPool2D(2, 2,data_format='NHWC'),
paddle.nn.Conv2D(32,64,(3,3),data_format='NHWC'),
paddle.nn.ReLU(),
paddle.nn.MaxPool2D(2, 2,data_format='NHWC'),
paddle.nn.Flatten(),
paddle.nn.Linear(2304, 128),
paddle.nn.Linear(128, 10),
)
paddle.summary(mnist, (-1, 64, 64,3))
model = paddle.Model(mnist) # Encapsulate the network structure into a Model with Model class
Use the pad The summary () method can see the network structure, as long as you specify the input network model and the input shape. Very easy to use. When building the network, you can write a little and take a look at the network structure, which is convenient to sort out the context.

Training model
First, set the optimizer, loss loss function and metrics to set the accuracy calculation method
model.prepare(optimizer=paddle.optimizer.Adam(parameters=model.parameters()), loss=paddle.nn.CrossEntropyLoss(), metrics=paddle.metric.Accuracy())
Then use the high-level API train_batch() completes the training operation of single batch data.
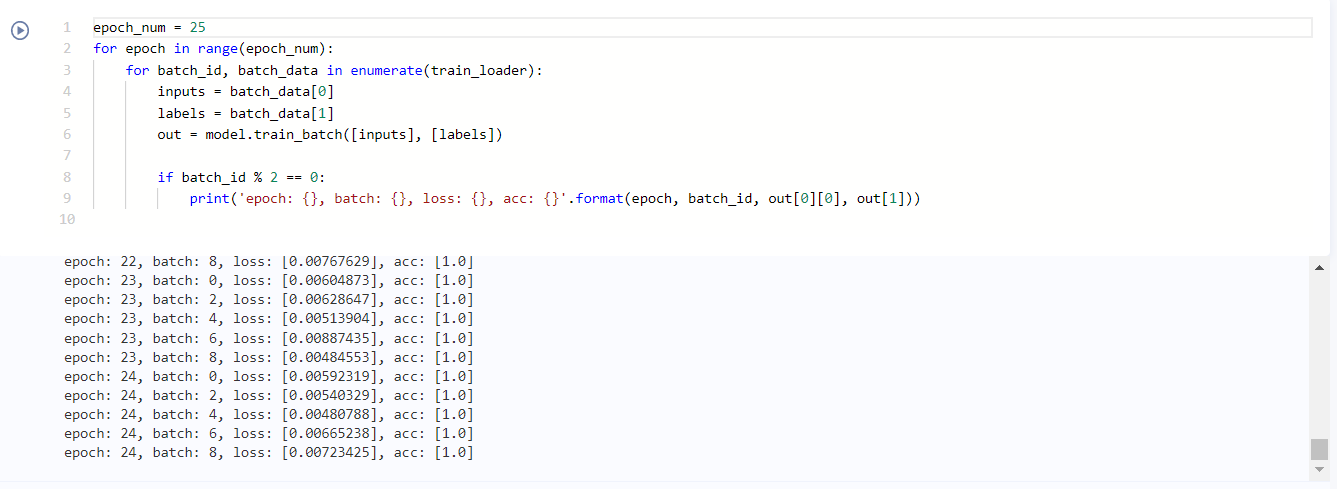
epoch_num = 25 # Set training rounds
for epoch in range(epoch_num):
for batch_id, batch_data in enumerate(train_loader):
inputs = batch_data[0]
labels = batch_data[1]
out = model.train_batch([inputs], [labels])
if batch_id % 2 == 0:
print('epoch: {}, batch: {}, loss: {}, acc: {}'.format(epoch, batch_id, out[0][0], out[1]))
eval_result = model.evaluate(test_dataset, verbose=1)
print('test',eval_result['loss'][0])
print('test acc',eval_result['acc'])
Model evaluation and prediction
- Model evaluation
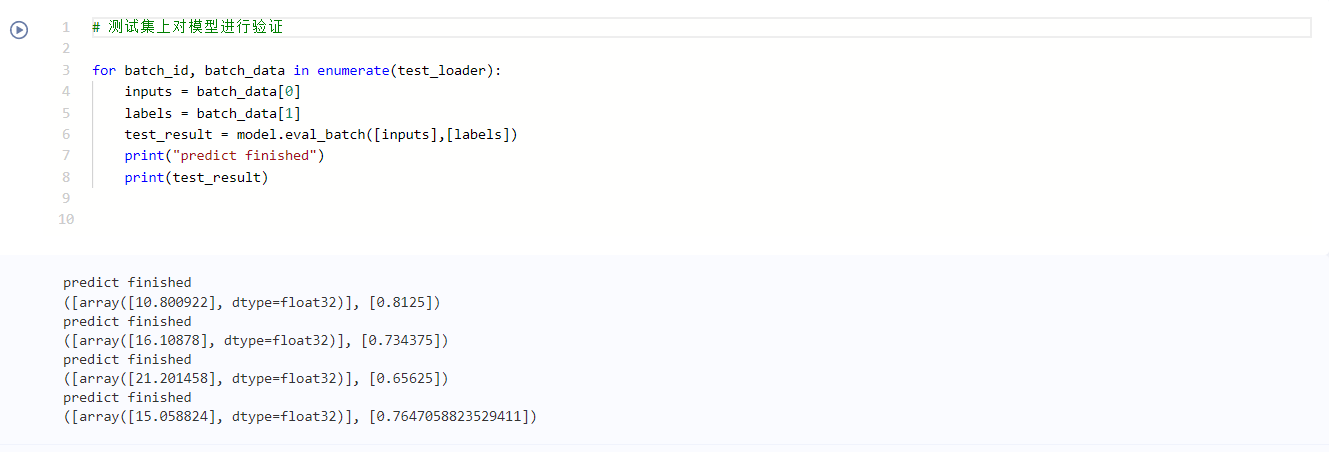
# Use model eval_ Batch verifies the data of a batch in the test set
for batch_id, batch_data in enumerate(test_loader):
inputs = batch_data[0]
labels = batch_data[1]
test_result = model.eval_batch([inputs],[labels])
print("predict finished")
print(test_result)
- model prediction
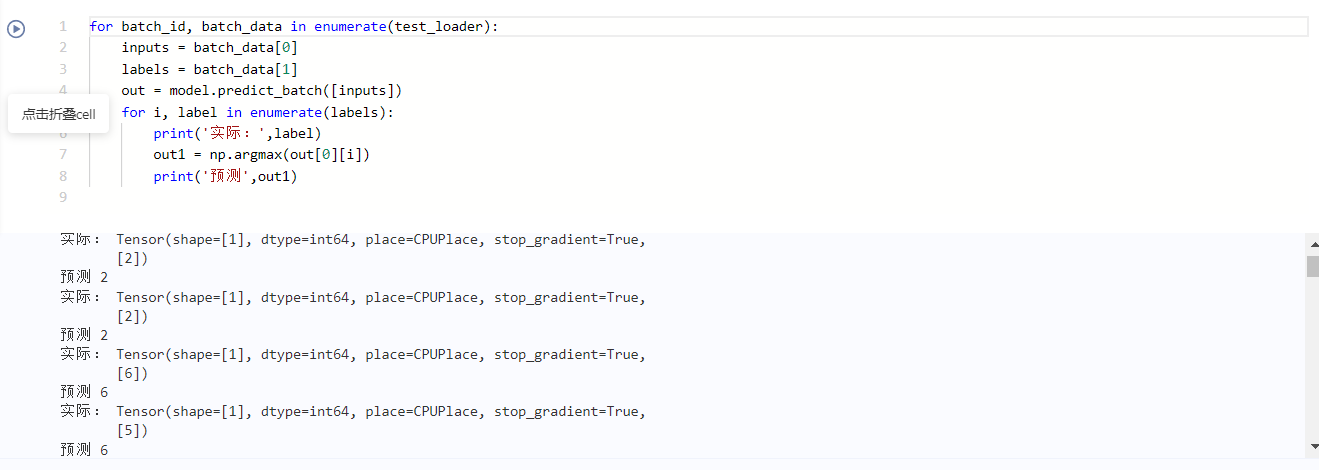
for batch_id, batch_data in enumerate(test_loader):
inputs = batch_data[0]
labels = batch_data[1]
out = model.predict_batch([inputs])
for i, label in enumerate(labels):
print('actual:',label)
out1 = np.argmax(out[0][i])
print('forecast',out1)
Postscript
The environment I use is the CPU version. There will be a probability of memory overflow. Let's see what the problem is later.
The accuracy of the test set is about 73%, and the prediction set is the test set used.
Optimize later.