introduce
How many data types does Redis have? (note that the data type is not a data structure)
There are eight types in total: String, Hash, Set, List, Zset, Hyperloglog, Geo and Streams.
1. Why put data in memory?
- Faster memory, 10W QPS
- Reduce computing time and reduce database pressure
2. If the data structure in memory is used as the cache, why not use HashMap or Memcached?
- Richer data types
- Support multiple programming languages
- Rich functions: persistence mechanism, memory elimination strategy, transaction, publish and subscribe, pipeline, LUA
- Support cluster and distributed
3. What is the difference between Memcached and redis?
Memcached can only store KV, has no persistence mechanism, does not support master-slave replication, and is multi-threaded.
IDS has 16 libraries (0-15) by default, which can be found in the configuration file redis Conf.
databases 16
The maximum length limit of Redis Key is 512M, which is different. Some are limited by length and some by number.
String
introduce
The most basic and commonly used data type is String. The get and set commands are String operation commands. Redis strings are called binary safe strings.
String can store three types: int (integer), float (single precision floating point number) and string (string).
Operation command
Here are some of its operation commands
# Save value (if you set the same key multiple times, the old value will be directly overwritten) set jack 2673 # Value get jack # View all keys keys * # Get the total number of keys (use with caution due to the large amount of data in the production environment) dbsize # Check if the key exists exists jack # Delete key del jack tonny # Rename key rename jack tonny # View type type jack # Gets the characters in the specified range getrange jack 0 1 # Get value length strlen jack # String append append jack good # Set multiple values (batch operation, atomicity) mset jack 2673 tonny 2674 # Get multiple values mget jack tonny # Set the value. If the key exists, it will not succeed setnx jack shuaige # Based on this, the distributed lock is realized set key value [expiration EX seconds|PX milliseconds][NX|XX] # (integer) the value is incremented (if the value does not exist, it will get 1) incr jack incrby jack 100 # (integer) value decrement decr jack decrby jack 100 # Floating point increment set mf 2.6 incrbyfloat mf 7.3
Application scenario
1. Cache
String type, which is the most commonly used, can cache some hot data, such as home page news, which can significantly improve the access speed of hot data and reduce the pressure on DB.
2. Distributed data sharing
String type, because Redis is a distributed independent service that can be shared among multiple applications.
For example: distributed Session
<dependency> <groupId>org.springframework.session</groupId> <artifactId>spring-session-data-redis</artifactId> </dependency>
3. Distributed lock
Refer to introduction to several common distributed lock writing methods
4. Global ID
INT type, INCRBY, using atomicity
incrby userid 1000
(for the scenario of dividing tables and databases, take one paragraph at a time)
5. Counter
INT type, INCR method
For example, the number of articles read, the number of microblog likes, and a certain delay are allowed. First write to Redis, and then synchronize to the database regularly
6. Current limiting
INT type, INCR method
Take the visitor's IP and other information as the key. The count is increased once for each visit. If it exceeds the number, false is returned.
Hash
introduce
Now there is a teacher table
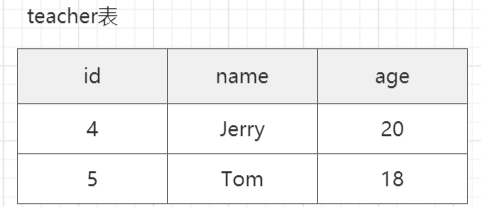
If we still store it through String type, the Teacher entity class should be serialized during storage, and then only stored as value; When modifying, you also need to take out the value for deserialization. For example, change the age to 21, then serialize it, and then save it. It is very cumbersome and increases the cost.
We need to obtain and modify a value separately. At this time, we can implement it through key layering, as shown in the following table:
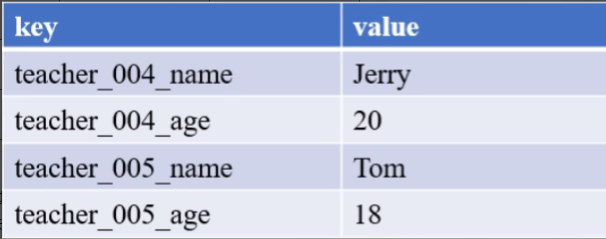
However, there will be many keys, and the keys are also very long and occupy space. Is there a better way to use our Hash type at this time, as shown in the following two tables:
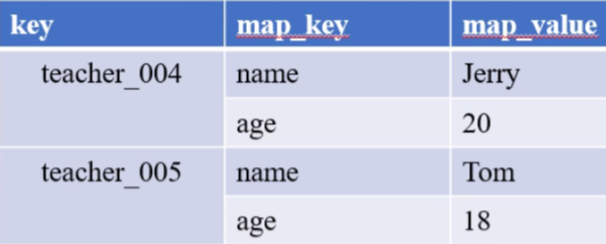

This is also convenient for centralized management. The granularity of the division is different. You can consider which storage method to choose according to the actual scenario, the expiration time of the key and the flexibility.
Hash is used to store multiple unordered key value pairs. The maximum storage quantity is 2 ^ 32-1 (about 4 billion).
advantage:
- Gather all relevant values into one Key to save memory space
- Use only one Key to reduce Key conflicts
- When you need to obtain values in batch, you only need to use one command to reduce the consumption of memory / IO/CPU
Disadvantages:
- Field cannot set the expiration time separately
- The problem of data volume distribution needs to be considered (when there are too many field s, it cannot be distributed to multiple nodes)
Operation command
# Setting, batch setting value hset h1 f 6 hset h1 e 5 hmset h1 a 1 b 2 c 3 d 4 # Value hget h1 a # Batch value hmget h1 a b c d # Get all field s hkeys h1 # Gets the values of all field s hvals h1 # Returns all fields and values in the hash table hgetall h1 # Delete field hdel h1 a # Gets the number of fields in the hash table hlen h1
Application scenario
Hash can do whatever String can do. Add another scenario, shopping cart:
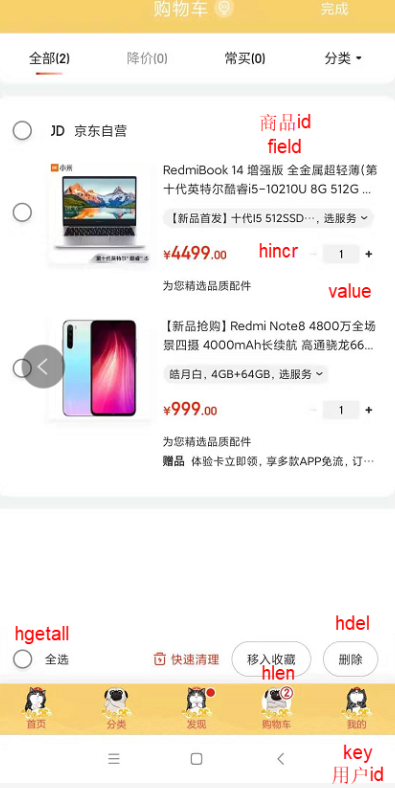
key: user id; field: Commodity id; value: commodity quantity;
+1: hincr;
-1: hdecr;
Delete: hincrby key field -1;
Select all: hgetall;
Number of commodities: hlen;
List
introduce
Store ordered strings (from left to right). Elements can be repeated. The maximum storage quantity is 2 ^ 32-1 (about 4 billion).
Next, draw a picture to demonstrate how to enter the queue and exit the queue
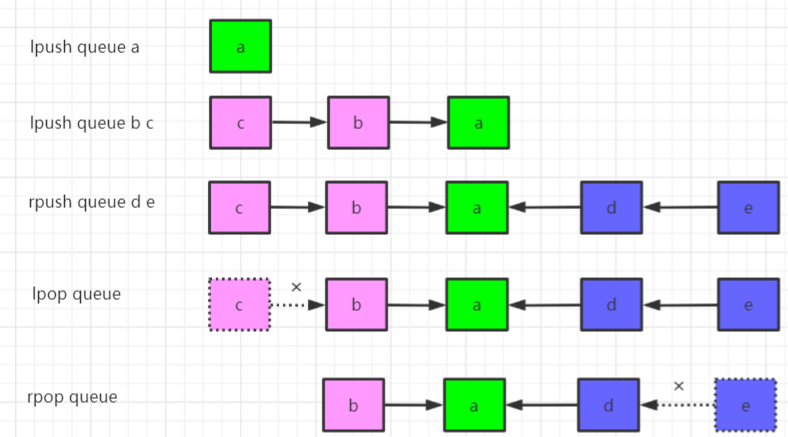
Operation command
# Push left lpush queue a lpush queue b c # Right push rpush queue d e # The left removes and returns the first element of the list lpop queue # The right removes and returns the first element of the list rpop queue # Get elements in the list by index lindex queue 0 # Returns the elements within the specified interval in the list lrange queue 0 -1
Application scenario
1. List
For example, the user's message list, the website's announcement list, the activity list, the blog's article list, the comment list, and so on, take out a page through LRANGE and display it in order.
2. Queue / stack
List can also be used as a queue / stack in a distributed environment.
Queue: first in first out, rpush and blpop
Stack: first in, last out, rpush and brpop
Here are two blocked pop-up operations: blpop/brpop. You can set the timeout (unit: seconds).
blpop: blpop key1 timeout,Move out and get the first element of the list. If there is no element in the list, the list will be blocked until the waiting timeout or pop-up element is found. brpop: brpop key1 timeout,Move out and get the last element of the list. If there are no elements in the list, the list will be blocked until the waiting timeout or pop-up elements are found.
Set
introduce
Set stores unordered sets of String type. The maximum storage quantity is 2 ^ 32-1 (about 4 billion).
As shown in the figure below:
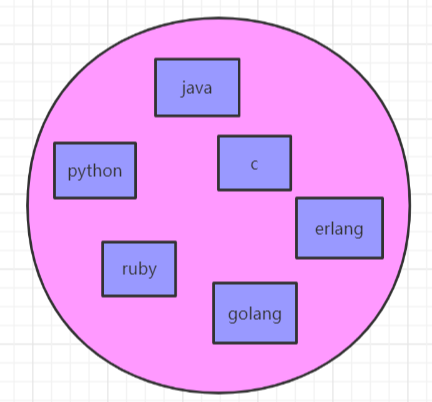
Operation command
# Add one or more elements sadd myset a b c d e f g # Get all elements smembers myset # Number of statistical elements scard myset # Get an element at random srandmember myset # Pop up an element at random spop myset # Remove one or more elements srem myset d e f # Check whether the element exists sismember myset a # Get difference set sdiff set1 set2 # Get intersection sinter set1 set2 # Get Union sunion set1 set2
Application scenario
1. Draw
Random get element: spop myset
2. Like, sign in, punch in

Let's take Weibo as an example. Suppose the ID of this Weibo is t1001 and the user ID is u6001,
Use dianzan:t1001 to maintain all praise users of t1001 microblog.
Like this microblog: sadd dianzan:t1001 u6001
Cancel likes: srem dianzan:t1001 u6001
Like or not: sismember dianzan:t1001 u6001
All users who like: smembers dianzan:t1001
Number of likes: scar dianzan: t1001
It is much simpler than relational database.
3. Commodity label
Use tags:i8001 to maintain all labels of goods.
sadd tags:i8001 the picture is clear and delicate
sadd tags:i8001 true color clear display
sadd tags:i8001 extremely smooth
4. Commodity screening

Huawei P40 is online, supporting national brands and adding them to various labels.
sadd brand:huawei p40
sadd os:android p40
sadd screensize:6.0-6.24 p40
When buying, the brand is Huawei, the operating system is Android, and the screen size is between 6.0-6.24. Take the intersection:
sinter brand:huawei os:android screensize:6.0-6.24
ZSet
introduce
sorted set stores ordered elements. Each element has a score, which is sorted from small to large. When the scores are the same, they are sorted according to the ASCII code of the key.
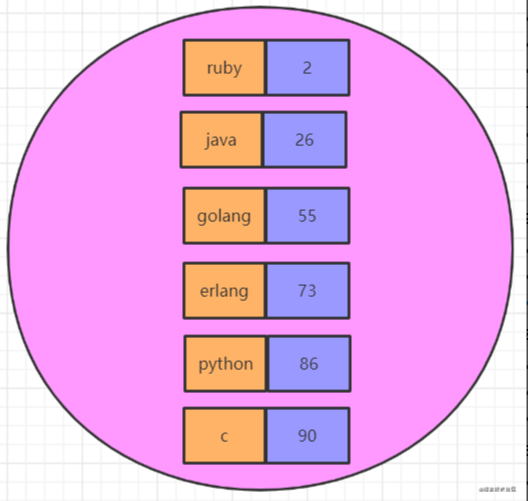
Operation command
# Add element zadd myzset 10 java 20 php 30 ruby 40 cpp 50 python # Get all elements zrange myset 0 -1 withscores zrevrange myzset 0 -1 withscores # Get elements according to score interval zrangebyscore myzset 20 30 # Remove elements (or delete according to score rank) zrem myzset php cpp # Number of statistical elements zcard myzset # Score increase zincrby myzset 5 python # Count the number according to the score min and max zcount myzset 20 60 # Get python ranking zrank myzset python # Get element score zscore myzset python
Application scenario
Ranking List
Today is May 23, 2021. Build a zset with the key hotSearch:20210523.
The id of Uncle sheep herding is n1234. Every click: zinc hotsearch: 20210523 1 n1234
Get the top ten hot search rankings: zrevrange hotsearch: 20210523 0 10 WithCores
Mr. Yuan is unparalleled. Go well all the way, and the children of the Chinese nation will not forget you!
BitMaps
introduce
BitMaps defines position operations on string types. A byte consists of 8 binary bits. As shown in the figure below:

The ASCII code of m is 109, and the corresponding binary data is 0110 1101
Operation command
# Set the string key to k1 and value to mic set k1 mic # Take the seventh bit of k1 and the result is 0 getbit k1 6 # Take the eighth bit of k1 as 0. At this time, the ASCII code is 108 and the corresponding letter is l setbit k1 7 0 # So the value is lic get k1 # Count the number of 1 in binary, a total of 12 bitcount k1 # Gets the location of the first 1 or 0 bitpos k1 1 bitpos k1 1
Application scenario
- Bitop and destkey [key...], logically combine one or more keys and save the results to destkey.
- Bitop or destkey [key...], find the logical or of one or more keys and save the results to destkey.
- Bitop XOR destkey [key...], find logical XOR for one or more keys and save the results to destkey.
- Bitop not destkey: find logical negation for a given key and save the result to destkey.
Online users for seven consecutive days
setbit firstday 0 1 //Set user login with uid of 0 on the first day setbit firstday 1 0 //The user whose uid is 1 on the first day of setting is not logged in setbit firstday 2 1 //Set user login with uid of 2 on the first day ... setbit secondday 0 0 //The user whose uid is 0 the next day is not logged in setbit secondday 1 1 //Set the user login with uid of 1 the next day setbit secondday 2 1 //Set the user login with uid of 2 the next day ... //and so on
Then the online users for seven consecutive days are:
BITOP AND 7_both_online_users firstday secondday thirdday fourthday fifthday sixthday seventhday
You can also apply access statistics, online user statistics, and so on.
Hyperloglog
Hyperloglog provides an imprecise cardinality statistics method to count the number of non repeating elements in a collection, such as the UV of the website, or the daily and monthly activities of the application. There is a certain error.
The Hyperloglog implemented in Redis only needs 12k memory to count 2 ^ 64 data.
public static void main(String[] args) {
Jedis jedis = new Jedis("39.103.144.86", 6379);
float size = 100000;
for (int i = 0; i < size; i++) {
jedis.pfadd("hll", "hll-" + i);
}
long total = jedis.pfcount("hll");
System.out.println(String.format("Number of Statistics: %s", total));
System.out.println(String.format("Correct rate: %s", (total / size)));
System.out.println(String.format("Error rate: %s", 1 - (total / size)));
jedis.close();
}
The source code is:
com/xhj/jedis/HyperLogLogTest.java
Geo
Now there is a need to obtain stores with a radius of less than 1km, so we need to save the longitude and latitude of the stores. If there is a database, one field stores longitude and one field stores dimension. It is complex to calculate the distance. Now it is very convenient for us to store via Redis's Geo.
# Stored latitude and longitude geoadd location 121.445 31.213 shanghai # Take latitude and longitude geopos location shanghai
You can add address location information, obtain address location information, calculate the distance between two locations, obtain the set of geographical locations within the specified range, and so on. The source code is:
com/xhj/jedis/GeoTest.java
public static void main(String[] args) {
Jedis jedis = new Jedis("39.103.144.86", 6379);
Map<String, GeoCoordinate> geoMap = new HashMap<>();
GeoCoordinate coordinate = new GeoCoordinate(121.445, 31.213);
geoMap.put("shanghai", coordinate);
jedis.geoadd("positions", geoMap);
System.out.println(jedis.geopos("positions", "shanghai"));
jedis.close();
}
Streams
Data types introduced by 5.0. The persistent message queue supporting multicast is used to realize the publish and subscribe function, which draws lessons from the design of Kafka.
Application scenario summary
- Cache - improve access speed of hotspot data
- Shared data - the problem of data storage and sharing
- Global ID - generation scheme of distributed global ID (sub database and sub table)
- Distributed lock -- atomic operation guarantee for sharing data between processes
- Online user statistics and counting
- Queue, stack - queue / stack across processes
- Message queue - asynchronous decoupling message mechanism
- Service registration and discovery - service coordination center of RPC communication mechanism (Dubbo supports Redis)
- Shopping Cart
- Sina user message timeline
- Lucky draw logic (gift, forwarding)
- Like, sign in, punch in
- Commodity label
- User (product) attention (recommendation) model
- E-commerce product screening
- Ranking List