catalogue
Multi table structure design of elastic search
spring data elasticsearch practice
preface
The last article completed the construction of elasticsearch and elasticsearch head. This chapter will be brought into spring boot for development and integration. Spring boot provides a lot of convenience for java data interaction. The spring data module integrates most of the data storage in the market.
Build environment
First, log in to the spring official website to find the spring data component. You can see the version requirements. You can refer to the table to select the corresponding version
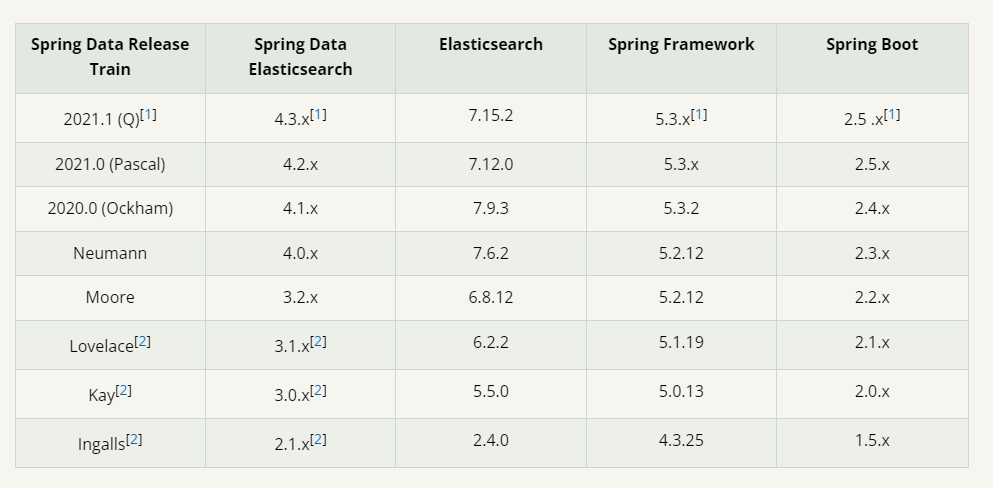
Version 7.10.0 of elasticsearch was previously installed here.
Then add it to our project pom file
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
</dependency>First, in our yml configuration file, add
elasticsearch:
rest:
username: elastic
password: elastic
uris: ['127.0.0.1:9200']Here is the account and password connected under port 9200. uris is an array item, which means that we can configure a cluster.
Then we need to create a configuration class under the spring boot project
This is the configuration used in this actual battle
@Slf4j
@Data
@Component
@ConfigurationProperties(prefix = "spring.elasticsearch.rest")
public class ElasticSearchConfig extends AbstractElasticsearchConfiguration {
/**
* user name
**/
private String username;
/**
* password
**/
private String password;
/**
* Host address
**/
private List<String> uris;
@Override
@Bean("elasticsearchClient")
public RestHighLevelClient elasticsearchClient() {
if (CollectionUtils.isEmpty(uris)) {
log.error("elasticsearch Address is empty");
throw new RuntimeException("elasticsearch Configuration address is empty");
}
HttpHost[] httpHosts = this.createHosts();
//voucher
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(username, password));
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(
RestClient.builder(httpHosts)
.setHttpClientConfigCallback(httpAsyncClientBuilder ->
httpAsyncClientBuilder.setDefaultCredentialsProvider(credentialsProvider)
.setKeepAliveStrategy((response,context) -> TimeUnit.MINUTES.toMillis(3)))
.setRequestConfigCallback(requestConfigBuilder -> requestConfigBuilder.setConnectTimeout(10000)
.setSocketTimeout(30000))
);
return restHighLevelClient;
}
private HttpHost[] createHosts() {
HttpHost[] httpHosts = new HttpHost[uris.size()];
for (int i = 0; i < uris.size(); i++) {
String hostStr = uris.get(i);
String[] split = hostStr.split(":");
httpHosts[i] = new HttpHost(split[0], Integer.parseInt(split[1]));
}
return httpHosts;
}
}First increase
@Data @Component @ConfigurationProperties(prefix = "spring.elasticsearch.rest")
These three annotations declare the class as configuration, and then declare several member variables, which are mainly read from the previous yml file, including account, password and service address.
Class inherits AbstractElasticsearchConfiguration, which is a rest advanced client recommended in spring data. We need to implement the abstract method elastasearchclient. At the same time, build this method into a bean, which can be used elsewhere.
There is another way to write it on the official website
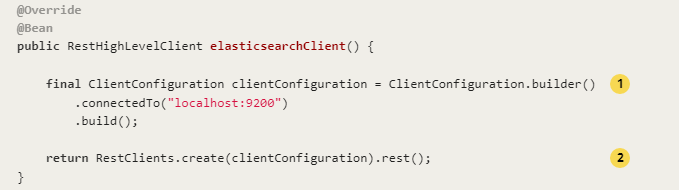
If you need to add a custom configuration, you can refer to the following

Class header, connection timeout parameters, authorized access, ssl connection, etc. are configured above,
The of the official website is realized by building a configuration item ClientConfiguration.
Another method is used in actual combat, using RestClient Builder method. (note that one is RestClient and the other is RestClients. The official website uses RestClients under org.springframework.data.elasticsearch.client. My other way of writing is RestClient under org.elasticsearch.client).
In order to be compatible with the cluster environment, we need to create a method that can output an array parameter. Here, I designed a method to convert the uris in the prototype configuration file. In the configuration class, the authorized account, password, connection timeout, and client connection holding time are set.
Here, a simple and available elasticsearchRestClient is completed.
Then we build our entity object, which is our orm layer.
Multi table structure design of elastic search
The main business environment of our actual combat this time is a forum, in which the entities that will appear are posts, comments and likes
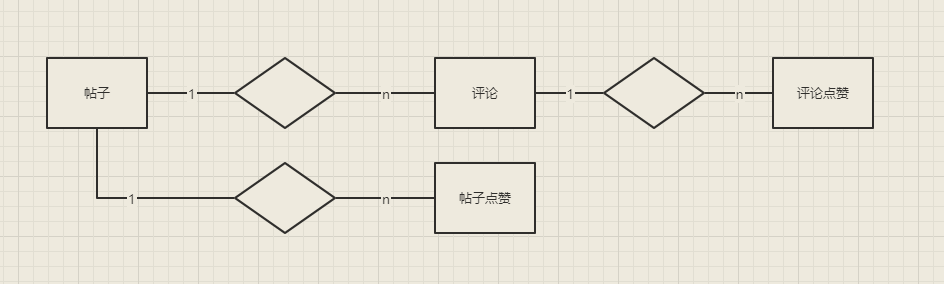
It can be seen that it is a multi-level one to many structure.
Elastic search is a non relational database. Its search advantage lies in the query of single table, and the association of multiple tables is not its strength. Therefore, when designing elastic search, we should pay attention to using a single table as much as possible, even if it is a certain amount of data redundancy. However, there are often some uncontrollable factors in the actual development, so we have to design a multi table association structure.
In elastic search, there are generally two solutions for the association structure of multiple tables: 1 nested 2 parent-child documents. Before we design the multi table structure, let's first understand the data structures of elasticsearch. The first is object. The storage structure of elasticsearch is json. In essence, the expansion of multiple tables is a redundancy of data. Expand the original single table structure horizontally to enrich its ability of single data type.
This is how object types are introduced on the official website

That is, when storing and retrieving in elasticsearch, the keys of this nested object will be spliced together. That is, you need to bring the complete key path when searching.
As you can understand, nested is a special object type, which is generated to solve the object of array type. We give examples

In the figure above, the two internal fields first and last are parsed into arrays, which leads to a problem. When we search for a person whose first is John and last is White, we can't search in theory, but actually there will be query results. This is because the two fields hit the information in the two arrays respectively, but lose the relationship between the two fields. At this time, change the user type to nested, and the user will be stored as a hidden document structure instead of being parsed into a simple key value as before.
This is the so-called nested type, which is suitable for array types. At the same time, it is necessary to maintain the structure of the array data independently.
The following describes the parent child type, which is also called the join type in the new version of elastic search. Commonly known as parent-child documents.
As the name suggests, a parent-child document has a parent document and a child document

You can see that there is a special type of field, the type is join, and there is a key value pair, which is the name of the parent and child respectively
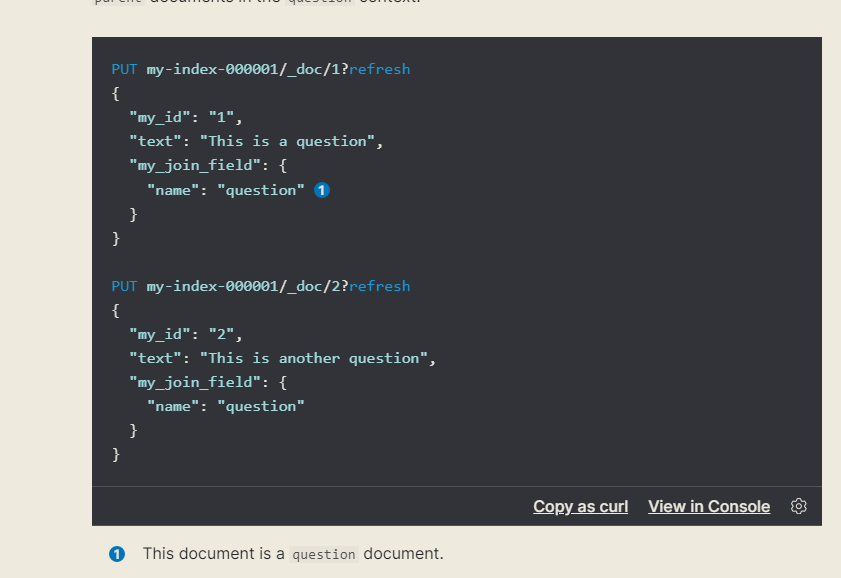
Here, the value of the join field is the parent document question, which indicates that this is a parent document.
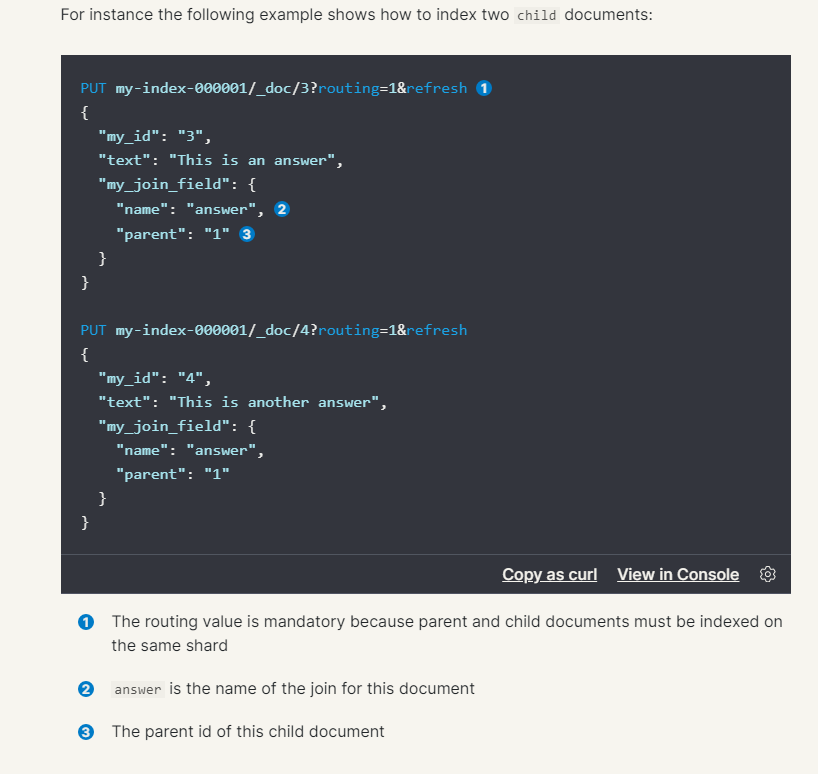
The sub document is added here. You can see that the value on the join type field is answer. Note that there is a parent field whose value is the parent document corresponding to the child document.
Here are some rules for parent-child documents.
- Only one field of join type is allowed in each index
- Parent documents and child documents must be stored in the same partition, which can ensure that they can be routed the same when the child document is queried, deleted and updated.
If there are parent-child documents, there are grandchildren routing, that is, multi-level routing.
for example
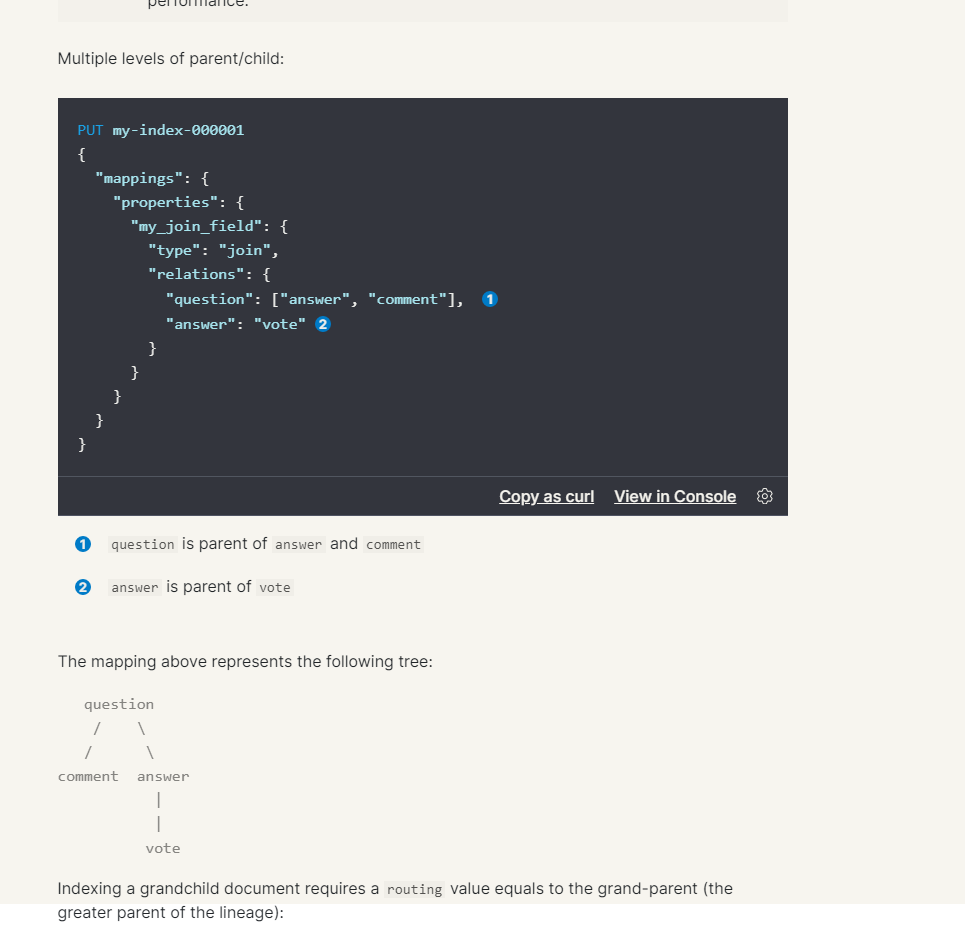
Multiple levels can be configured in the join type field. It should be understood that both single-layer father and son and multi-layer father and son need to be on the same piece. Here we simply expand the concept of fragmentation.
The index that stores data in elastic search is equivalent to the table in mysql. Documents are stored in the index. In fact, the index is composed of multiple fragments. Fragments save part of the data of an index and are an expanded unit. A smallest index has one fragment.
Here we need to introduce a concept of routing. When storing a document, elastic search needs to know which partition the document needs to exist in. The value of the slice number is pushed down by the formula
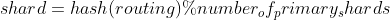
number_of_primarys_shards is the number of master partitions. Master partitions can be understood as the role of master and slave nodes in our cluster. This is a fixed value. routing is a variable. The default is_ id, or a custom value. The final segment number is 0 to the number of main segments minus one.
So what happens if the shard s of parent-child documents are different?
When creating, updating and deleting a child document, elasticsearch needs to specify the id of the parent document, that is, it will limit fragmentation by default. If it is not a consistent partition, it will operate on another partition in the default request, resulting in an error.
After completing the explanation of nested documents and parent-child documents, we begin the actual combat of spring data elasticsearch.
spring data elasticsearch practice
Students who have used spring data jpa should know that spring data jpa can create entity objects and map them to the database during service startup through forward engineering. Spring data elasticsearch is OK.
Here we give an example
@Data
@Document(indexName = "forum_post")
public class ForumPostES {
/**
* Topic id
**/
@Id
@Field(type = FieldType.Long, name = "post_id")
private Long postId;
/**
* title
**/
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String title;
/**
* The title keyword keyword type can be de aggregated
**/
@Field(type = FieldType.Keyword, name = "title_keyword")
private String titleKeyword;
/**
* content
**/
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String content;
/**
* Content without word segmentation
**/
@Field(type = FieldType.Keyword, value = "content_keyword",ignoreAbove = 256)
private String contentKeyword;
/**
* Section id
**/
@Field(type = FieldType.Integer, name = "plate_id")
private Integer plateId;
/**
* Chinese name of section
**/
@Field(type = FieldType.Keyword, name = "plate_name_cn")
private String plateNameCn;
/**
* English name of section
**/
@Field(type = FieldType.Keyword, name = "plate_name_en")
private String plateNameEn;
/**
* Content type
**/
@Field(type = FieldType.Short, name = "content_type")
private Short contentType;
/**
* Posting date
**/
@Field(type = FieldType.Keyword, name = "gmt_created")
private String gmtCreated;
/**
* Reply date
**/
@Field(type = FieldType.Keyword, name = "gmt_reply")
private String gmtReply;
/**
* Top or not
**/
@Field(type = FieldType.Boolean, name = "is_top")
private Boolean isTop;
/**
* Archive
**/
@Field(type = FieldType.Boolean, name = "is_archive")
private Boolean isArchive;
/**
* Top date
**/
@Field(type = FieldType.Keyword, name = "gmt_top")
private String gmtTop;
/**
* Operator
**/
@Field(type = FieldType.Keyword, name = "created_by")
private String createdBy;
/**
* user name
**/
@Field(type = FieldType.Text, analyzer = "ik_max_word", name = "username", searchAnalyzer = "ik_smart")
private String userName;
/**
* User name does not separate words
**/
@Field(type = FieldType.Keyword, name = "username_keyword")
private String userNameKeyword;
/**
* head portrait
**/
@Field(type = FieldType.Keyword, name = "head_icon")
private String headIcon;
/**
* Views
**/
@Field(type = FieldType.Integer, name = "read_count")
private Integer readCount;
/**
* Comment volume
**/
@Field(type = FieldType.Integer, name = "reply_count")
private Integer replyCount;
/**
* Praise quantity
**/
@Field(type = FieldType.Integer, name = "like_count")
private Integer likeCount;
/**
* Language type
**/
@Field(type = FieldType.Short)
private Short languageType;
@JoinTypeRelations(
relations = {
@JoinTypeRelation(parent = "forum_post", children = {"forum_post_like", "forum_reply", "forum_reply_like"})
}
)
private JoinField<Long> post_join;
/**
* Comment id
**/
@Field(type = FieldType.Long, name = "reply_id")
private Long replyId;
/**
* Topic like id
**/
@Field(type = FieldType.Long, name = "post_like_id")
private Long postLikeId;
/**
* Type to search
**/
@Field(type = FieldType.Short, name = "search_type")
private Short searchType;
/**
* Reply like id
**/
@Field(type = FieldType.Long, name = "reply_like_id")
private Long replyLikeId;
}The annotations used are explained here
- @Document declares an index, which is defined in the index name of elasticsearch. The number of slices can be set. By default, the index can be created into elasticsearch when the program starts. You can set the createIndex parameter to false so that it will not be created at startup
- @Id declares the primary key in the index
- @Field declares the mapped data type, alias, and can define the used word breaker. For example, text will use participle by default, while keyword will not
- @JoinRelationType defines a join type in which parent-child markers can be set
After defining the entity class, you can create a repository, create an interface and inherit ElasticsearchRepository.
This class can provide the most basic methods of jpa. li
@NoRepositoryBean
public interface CrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> S save(S var1);
<S extends T> Iterable<S> saveAll(Iterable<S> var1);
Optional<T> findById(ID var1);
boolean existsById(ID var1);
Iterable<T> findAll();
Iterable<T> findAllById(Iterable<ID> var1);
long count();
void deleteById(ID var1);
void delete(T var1);
void deleteAll(Iterable<? extends T> var1);
void deleteAll();
}For example, these simple additions, deletions, modifications and queries.
For orm framework like mybatis, it provides a way to write sql directly when dealing with complex sql queries. spring data
The repository of elasticsearch can only provide a simple api. In some complex cases, we need to use RestHighLevelClient to perform some complex operations
In this actual combat project, I designed it like this
First, I uniformly encapsulate a method for requesting elasticsearch, and obtain the results by passing in the searchrequest parameter
@Autowired
private RestHighLevelClient elasticsearchClient;
/**
* @description Encapsulate a unified query return
* @author zhou
* @create 2021/9/9 13:47
* @param searchRequest Query request
* @return org.elasticsearch.action.search.SearchResponse
**/
@Override
@Retryable(value = ServiceException.class,backoff = @Backoff(delay = 500),recover = "recover")
public SearchResponse getSearchResponse(SearchRequest searchRequest){
SearchResponse searchResponse;
log.info("Try to connect");
log.info("Query parameters:[{}]",searchRequest.source().toString());
try {
searchResponse = elasticsearchClient.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
log.error("ES Service connection exception");
throw new ServiceException(ErrorEnum.ELASTIC_SEARCH);
}
return searchResponse;
}Because the query of elasticsearch is diverse and complex, there will be many points to expand. Here is a copy of the code I used in the project
@Override
public Page<ForumPostES> queryPostPage(ForumPostQuery forumPostQuery) {
SearchRequest searchRequest = new SearchRequest("forum_post");
//Construct pager
PageRequest pageRequest = PageRequest.of(forumPostQuery.getPageNum() - 1, forumPostQuery.getPageSize());
//Construct query criteria
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//Field filtering
String[] exclude = {"reply_id", "post_like_id", "reply_like_id"};
String[] include = {};
sourceBuilder.fetchSource(include, exclude);
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//Query topics only
boolQueryBuilder.must(QueryBuilders.termQuery("search_type", SearchTypeEnum.POST.getCode()));
//Non Archive
boolQueryBuilder.must(QueryBuilders.termQuery("is_archive", false));
if (null != forumPostQuery.getPlateId()) {
//Section id
boolQueryBuilder.must(QueryBuilders.termQuery("plate_id", forumPostQuery.getPlateId()));
}
if (!CollectionUtils.isEmpty(forumPostQuery.getLanguageTypeList())) {
//language
boolQueryBuilder.must(QueryBuilders.termsQuery("language_type", forumPostQuery.getLanguageTypeList()));
}
if (StringUtils.isNotBlank(forumPostQuery.getKeyword())) {
String keyword = forumPostQuery.getKeyword().toLowerCase();
//Word segmentation search
BoolQueryBuilder keywordBuilder = QueryBuilders.boolQuery();
keywordBuilder.should(QueryBuilders.matchPhraseQuery("title", keyword).boost(6));
keywordBuilder.should(QueryBuilders.wildcardQuery("title.keyword", "*" + keyword + "*").boost(6));
keywordBuilder.should(QueryBuilders.matchPhraseQuery("username", keyword).boost(4));
keywordBuilder.should(QueryBuilders.wildcardQuery("username_keyword", "*" + keyword + "*").boost(4));
keywordBuilder.should(QueryBuilders.matchPhraseQuery("content", keyword).boost(6));
keywordBuilder.should(QueryBuilders.wildcardQuery("content_keyword", "*" + keyword + "*").boost(4));
boolQueryBuilder.must(keywordBuilder);
}
if (null != forumPostQuery.getWithMe()) {
//Related to me
QueryBuilder queryBuilder = this.getChild(forumPostQuery.getWithMe(), forumPostQuery.getAccount());
if (null != queryBuilder) {
boolQueryBuilder.must(queryBuilder);
}
}
//Condition query
sourceBuilder.query(boolQueryBuilder);
//Highlight
//sourceBuilder.highlighter(highlightBuilder);
//paging
int from = pageRequest.getPageNumber() * pageRequest.getPageSize();
sourceBuilder.from(from).size(pageRequest.getPageSize());
//sort
sourceBuilder.sort("is_top", SortOrder.DESC);
sourceBuilder.sort("gmt_top",SortOrder.DESC);
sourceBuilder.sort("_score", SortOrder.DESC);
if (null != forumPostQuery.getSortType()) {
//dynamic order
this.getOrder(forumPostQuery.getSortType(), sourceBuilder);
sourceBuilder.sort("gmt_created", SortOrder.DESC);
}
searchRequest.source(sourceBuilder);
sourceBuilder.collapse(new CollapseBuilder("post_id"));
SearchResponse searchResponse = elasticsearchDao.getSearchResponse(searchRequest);
List<ForumPostES> forumPostESList = new ArrayList<>(pageRequest.getPageSize());
//boolean hasKeyword = StringUtils.isNotBlank(forumPostQuery.getKeyword());
for (SearchHit hit : searchResponse.getHits().getHits()) {
JSONObject jsonObject = JSONObject.parseObject(hit.getSourceAsString());
ForumPostES forumPostES = JSON.toJavaObject(jsonObject, ForumPostES.class);
forumPostESList.add(forumPostES);
}
return new PageImpl<ForumPostES>(forumPostESList, pageRequest, searchResponse.getHits().getTotalHits().value);
}- First, specify the index we want to query through SearchRequest
- If paging is required, a PageRequest is constructed. (note that elasticsearch has deep paging problems that need to be solved through scroll, and those with a small number of pages do not need to be considered.) set from and size in the subsequent SearchSourceBuilder to specify the start record and the size of each page.
- Construct a SearchSourceBuilder as a query, and use the builder mode
- The fetchSource of the query can be used to realize the projection operation and filter fields in mysql
- Through querybuilders Boolquery() creates a Boolean query. You can use must,should,mustNot, which is the and, or, we use in mysql=
- termQuery refers to the exact query, that is, the query in mysql=
- matchPhraseQuery refers to phrase query
- wildcardQuery refers to fuzzy query, and wildcards can be used*
- The parent-child query needs to construct JoinQueryBuilders. The query sub document uses hasChildQuery, and the query parent document uses hasParentQuery
- Sort uses the sort method of SearchSourceBuilder to specify the fields to sort
- collapse is similar to the distinct implementation of mysql, which realizes the corresponding de duplication of fields
Here is a simple demonstration of the query api of elasticsearch, which can solve most query problems.
At this point, the integration of spring # boot # elasticsearch is completed.