Python wechat ordering applet course video
https://edu.csdn.net/course/detail/36074
Python actual combat quantitative transaction financial management system
https://edu.csdn.net/course/detail/35475
Before starting
Consider a few questions first:
- Q1: how to expand minefree areas?
- Q2: how to calculate the prompt number of the grid?
- Q3: how to represent the status of mine sweeping game?
A1: you can use recursive functions or stacks.
A2: the general practice is to count the number of mines around when a grid needs to be opened. If there is a convenient two-dimensional convolution function to call, this will be a more concise method:
[1001001001101000000001001]★[111101111]=[1221233331131212322110110]
\begin{bmatrix} 1 & 0 & 0 & 1 & 0\ 0 & 1 & 0 & 0 & 1\ 1 & 0 & 1 & 0 & 0\ 0 & 0 & 0 & 0 & 0\ 0 & 1 & 0 & 0 & 1 \end{bmatrix}\bigstar \begin{bmatrix} 1 & 1 & 1\ 1 & 0 & 1\ 1 & 1 & 1 \end{bmatrix}= \begin{bmatrix} 1 & 2 & 2 & 1 & 2\ 3 & 3 & 3 & 3 & 1\ 1 & 3 & 1 & 2 & 1\ 2 & 3 & 2 & 2 & 1\ 1 & 0 & 1 & 1 & 0 \end{bmatrix}
Use ★ \ bigstar to represent two-dimensional convolution operation. 5 to the left of the equal sign × 5 matrix shows the distribution of lightning, with a value of 1 indicating that there is lightning and a value of 0 indicating that there is no lightning; 3 to the left of the equal sign × 3 matrix is the convolution kernel (or filter, feature extractor) for solving the surrounding ray number; The matrix to the right of the equal sign is the surrounding ray number of all lattices.
The code is also very simple to implement:
from scipy import signal import numpy as np state\_mine = np.array([[1,0,0,1,0],[0,1,0,0,1],[1,0,1,0,0],[0,0,0,0,0],[0,1,0,0,1]]) KERNAL = np.array([[1,1,1],[1,0,1],[1,1,1]]) state\_num = signal.convolve2d(state\_mine, KERNAL, 'same')
A3: for players, the game state is not completely observed, that is, it is necessary to distinguish between the observation state and the environment state. The environmental state includes the lightning distribution matrix and the prompt number matrix (i.e. the one mentioned in the above formula); The observation state is the environment state partially visible to the player. It is necessary to partially shield the mine distribution matrix according to the open state of the grid. The observation state does not include the mine distribution matrix, because the game ends once it touches the mine, so all non terminating states in the game are mine free.
So for a size M × NM \times N minesweeping game, the environmental state can be expressed as M × N × Tensor of 2M \times N \times 2: Channel 1 is the thunder distribution matrix, and channel 2 is the prompt number matrix; The observation state can be expressed as # M × N × Tensor of 2M \times N \times 2: Channel 1 is the matrix indicating the grid open state (value 1 is open and value 0 is not open), and this matrix multiplies the element of the prompt number matrix to complete the partial shielding of the environmental state as the second channel. For numpy For array, element multiplication is easy:
observe\_num = state\_num * state\_open
The game state in the following figure is illustrated as an example:
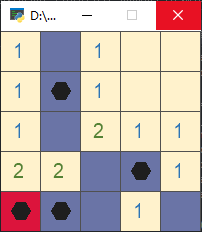
The environmental status is:
[1111]×[1110010100112112220111211]
\begin{bmatrix} & & & & \ & 1 & & & \ & & & & \ & & & 1 & \ 1 & 1 & & & \end{bmatrix}\times \begin{bmatrix} 1 & 1 & 1 & 0 & 0\ 1 & 0 & 1 & 0 & 0\ 1 & 1 & 2 & 1 & 1\ 2 & 2 & 2 & 0 & 1\ 1 & 1 & 2 & 1 & 1 \end{bmatrix}
The observation status is:
[1010010100102112200110010]×[11111111111111111]
\begin{bmatrix} 1 & 0 & 1 & 0 & 0\ 1 & 0 & 1 & 0 & 0\ 1 & 0 & 2 & 1 & 1\ 2 & 2 & 0 & 0 & 1\ 1 & 0 & 0 & 1 & 0 \end{bmatrix}\times \begin{bmatrix} 1 & & 1 & 1 & 1\ 1 & & 1 & 1 & 1\ 1 & & 1 & 1 & 1\ 1 & 1 & & & 1\ 1 & & & 1 & \end{bmatrix}
But this representation is not unique. For example, we can divide the prompt number matrix into 9 channels to represent the prompt numbers of 0 ~ 8 respectively. Then the observation state becomes M × N × Tensor of 10M \times N \times 10:
[1111]×[111111111]×[111]×[]×⋯×[]×[11111111111111111]
\begin{bmatrix} & & & 1 & 1\ & & & 1 & 1\ & & & & \ & & & & \ & & & & \end{bmatrix}\times \begin{bmatrix} 1 & & 1 & & \ 1 & & 1 & & \ 1 & & & 1 & 1\ & & & & 1\ & & & 1 & \end{bmatrix}\times \begin{bmatrix} & & & & \ & & & & \ & & 1 & & \ 1 & 1 & & & \ & & & & \end{bmatrix}\times \begin{bmatrix} & & & & \ & & & & \ & & & & \ & & & & \ & & & & \end{bmatrix}\times \cdots \times \begin{bmatrix} & & & & \ & & & & \ & & & & \ & & & & \ & & & & \end{bmatrix}\times \begin{bmatrix} 1 & & 1 & 1 & 1\ 1 & & 1 & 1 & 1\ 1 & & 1 & 1 & 1\ 1 & 1 & & & 1\ 1 & & & 1 & \end{bmatrix}
The design of state space is flexible, and the only evaluation criterion is the performance of the complete learning system. If the above multi-channel state space design is adopted, the subsequent learning tasks can be carried out conveniently by using convolutional neural network. You can also expand the tensor matrix into a one-dimensional vector and then process it with a fully connected neural network. The subsequent implementation of this paper will adopt M × N × State space representation of 2M \times N \times 2.
Step 1: create a new file
In order to run pytorch, I created an environment management operation named pytorch 1. 0 using anaconda 1, and openAI gym is installed in this environment, so I came to the directory: D: \ Anaconda \ envs \ pytorch1 1 \ lib \ site packages \ gym \ envs \ user, create a new file__ init__.py and MineSweeper_env.py.
Step 2: write the file MineSweeper_env.py
A standard gym env class contains three methods: reset(), step(action), and render().
- reset() is used to initialize the environment;
- step(action) has four return values: state, reward, done, and info. Therefore, we need to complete all the logic of the minesweeping game in this function;
- render() is used to visualize the environment. I didn't find the native method rendering of gym on the Internet, which can display text (if you know, please leave a message, thank you!), Therefore, a large number of characters are displayed by pyglet + dynamic variable name. The specific methods can be seen Reinforcement learning practice | display string of custom Gym environment.
MineSweeper_ env. The overall code of Py is as follows:
import gym
import random
import time
import numpy as np
from scipy import signal # Two dimensional convolution
import pyglet # display text
from gym.envs.classic\_control import rendering
class DrawText: # Used to display text in rendering
def \_\_init\_\_(self, label:pyglet.text.Label):
self.label=label
def render(self):
self.label.draw()
class MineSweeperEnv(gym.Env):
def \_\_init\_\_(self):
self.MINE\_NUM = 20
self.ROW, self.COL = 12, 12
self.SIZE = 40
WIDTH = self.COL * self.SIZE
HEIGHT = self.ROW * self.SIZE
self.viewer = rendering.Viewer(WIDTH, HEIGHT)
self.state\_mine = None
self.state\_num = None
self.state\_open = None
self.gameOver = False
def reset(self):
# Initialization: mine status
MINE\_NUM = self.MINE\_NUM
self.state\_mine = np.zeros(self.ROW * self.COL)
self.state\_mine[:MINE\_NUM] = 1
random.shuffle(self.state\_mine)
self.state\_mine = self.state\_mine.reshape(self.ROW, self.COL)
# Initialization: prompt number
KERNAL = np.array([[1,1,1], [1,0,1], [1,1,1]])
self.state\_num = signal.convolve2d(self.state\_mine, KERNAL, 'same')
# Initialization: open state
self.state\_open = np.zeros((self.ROW, self.COL))
# Initialization: is the game over
self.gameOver = False
def getRoundSet(self, x, y):
roundSet = []
for i in range(x-1, x+2):
for j in range(y-1, y+2):
if 0 <= i < self.ROW and 0 <= j < self.COL and (i, j) != (x, y):
roundSet.append((i, j))
return roundSet
def step(self, action):
# Execute action
x, y = action
# If open, the number is not 0
if self.state\_num[x, y] >= 1:
self.state\_open[x, y] = 1
# If the opening number is 0, the minefree area will be expanded
if self.state\_num[x, y] == 0:
stack = []
stack.append((x, y))
while len(stack):
row, col = stack.pop()
self.state\_open[row, col] = 1
for one in self.getRoundSet(row, col):
# Exclude open cells
if self.state\_open[one] == 1:
continue
if self.state\_num[one] >= 1:
self.state\_open[one] = 1
else:
stack.append(one)
# Win or lose / get rewards
done, reward = False, 0
# If thunder is turned on, the game fails
if self.state\_mine[x, y] == 1:
self.state\_open[x, y] = 1
self.gameOver = True
done, reward = True, -1
# If the number of remaining unopened squares = thunder number, you will win
if ROW*COL - self.state\_open.sum() == self.MINE\_NUM:
self.gameOver = True
done, reward = True, 1
# Report (maintain the standard format of gym step)
info = {}
# Observation state
observe\_num = self.state\_num * self.state\_open
observe = [observe\_num, self.state\_open]
return observe, reward, done, info
def render(self, mode='human'):
ROW, COL, SIZE = self.ROW, self.COL, self.SIZE
# Draw a square
for i in range(ROW):
for j in range(COL):
X, Y = j*SIZE, (ROW-i-1)*SIZE
tile = rendering.make\_polygon([(X,Y), (X+SIZE,Y), (X+SIZE,Y+SIZE), (X,Y+SIZE)], filled=True)
if self.state\_open[i,j] == 0:
tile.set\_color(106/255,116/255,166/255)
if self.state\_open[i,j] == 1 and self.state\_mine[i,j] == 0:
tile.set\_color(255/255,242/255,204/255)
if self.state\_open[i,j] == 1 and self.state\_mine[i,j] == 1:
tile.set\_color(220/255,20/255,60/255)
self.viewer.add\_geom(tile)
# Draw a dividing line
WIDTH = COL*SIZE
HEIGHT = ROW*SIZE
for i in range(ROW+1):
line = rendering.Line((0, i*SIZE), (WIDTH, i*SIZE))
line.set\_color(80/255, 80/255, 80/255)
self.viewer.add\_geom(line)
for j in range(COL+1):
line = rendering.Line((j*SIZE, 0), (j*SIZE, HEIGHT))
line.set\_color(80/255, 80/255, 80/255)
self.viewer.add\_geom(line)
# Draw numbers
for i in range(ROW):
for j in range(COL):
exec('label\_{}\_{} = {}'.format(i, j, None))
names = locals()
NUM = int(self.state\_num[i,j])
COLOR = (255, 255, 255, 255)
if NUM == 1:
COLOR = (46, 117, 182, 255)
elif NUM == 2:
COLOR = (84, 130, 53, 255)
elif NUM == 3:
COLOR = (192, 0, 0, 255)
elif NUM == 4:
COLOR = (112, 48, 160, 255)
elif NUM == 5:
COLOR = (132, 60, 12, 255)
elif NUM == 6:
COLOR = (191, 144, 0, 255)
elif NUM == 7:
COLOR = (32, 56, 100, 255)
elif NUM == 8:
COLOR = (13, 13, 13, 255)
names['label\_' + str(i) + '\_' + str(j)] = pyglet.text.Label('{}'.format(NUM), font\_size=15,
x=(j+0.32)*SIZE, y=(ROW-i-1+0.23)*SIZE, anchor\_x='left', anchor\_y='bottom',
color=COLOR)
label = names['label\_{}\_{}'.format(i, j)]
label.draw()
if self.state\_mine[i,j] == 0 and self.state\_open[i,j] == 1 and self.state\_num[i,j] >= 1:
self.viewer.add\_geom(DrawText(label))
# Draw thunder
if self.gameOver == True:
if self.state\_mine[i,j] == 1:
mine = rendering.make\_circle(10, 6, filled=True)
mine.set\_color(30/255, 30/255, 30/255)
translation = rendering.Transform(translation=((j+0.5)*SIZE, (ROW-i-1+0.5)*SIZE))
mine.add\_attr(translation)
self.viewer.add\_geom(mine)
return self.viewer.render(return\_rgb\_array=mode == 'rgb\_array')
# Test code: perform actions with random strategy
if \_\_name\_\_ == '\_\_main\_\_':
MineSweeper = MineSweeperEnv()
ROW, COL = MineSweeper.ROW, MineSweeper.COL
MineSweeper.reset()
MineSweeper.render()
while MineSweeper.gameOver is not True:
while True:
rand = random.choice(range(ROW*COL))
x, y = rand//ROW, rand%ROW
if MineSweeper.state\_open[x, y] == 0:
action = (x, y)
break
state, reward, done, info = MineSweeper.step(action)
MineSweeper.render()
time.sleep(0.5)
Run the file directly and execute the test code (execute the action with random strategy):
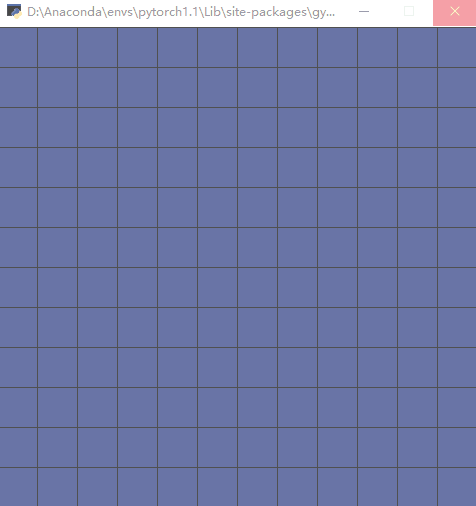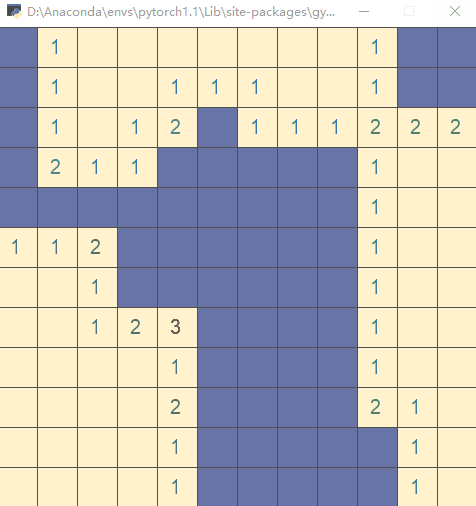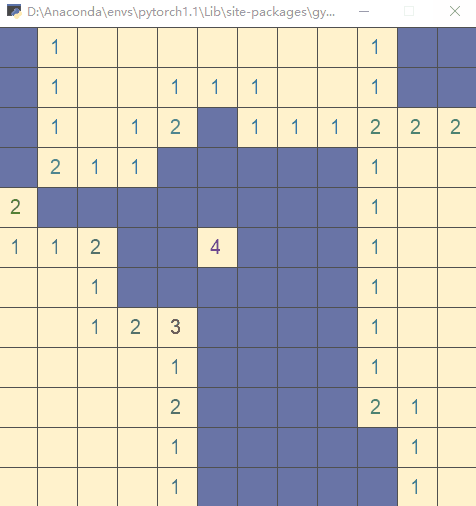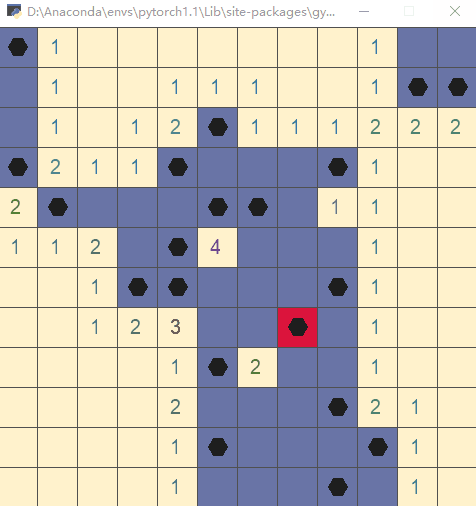
Step 3: write__ init__.py
In__ init__.py, add:
from gym.envs.user.MineSweeper\_env import MineSweeperEnv
Step 4: register environment
Go to the directory: D: \ Anaconda \ envs \ pytorch1 1 \ lib \ site packages \ gym, open__ init__.py, add code:
register( id="MineSweeperEnv-v0", entry\_point="gym.envs.user:MineSweeperEnv", max\_episode\_steps=200, )
Step 5: Test Environment
In the same conda environment, enter the code:
import gym
env = gym.make('MineSweeperEnv-v0')env.reset()env.render()
If no error is reported, the gym environment registration is successful.