With the development of mobile Internet and the impact of popular fields such as machine learning, more and more people know and begin to learn python. Whether you are a professional or a non professional, Python is undoubtedly the first language for you to enter the computer world. Its syntax is very concise and the written program is easy to understand. This is also Python's consistent philosophy of "simplicity and elegance". On the basis of ensuring the readability of the code, try to complete your idea with as little code as possible.
So, to what extent can we learn Python, we can start looking for a job. As we all know, practice is the only standard to test here. Of course, to what extent can we learn to find a job depends on the needs of the market. After all, enterprises recruit you to work, not to study with pay.
So today, we'll try to climb the recruitment information about Python on the drop-down hook to see what kind of talents the market needs.
Web page structure analysis
Open the home page of dragnet, enter the keyword "Python", then press F12 to open the web page debugging panel, switch to the "Network" tab, select "XHR" for the filtering conditions, click search when everything is ready, and carefully observe the web page's Network request data.
From these requests, we can roughly guess that the data seems to be from jobs / position Ajax JSON interface.
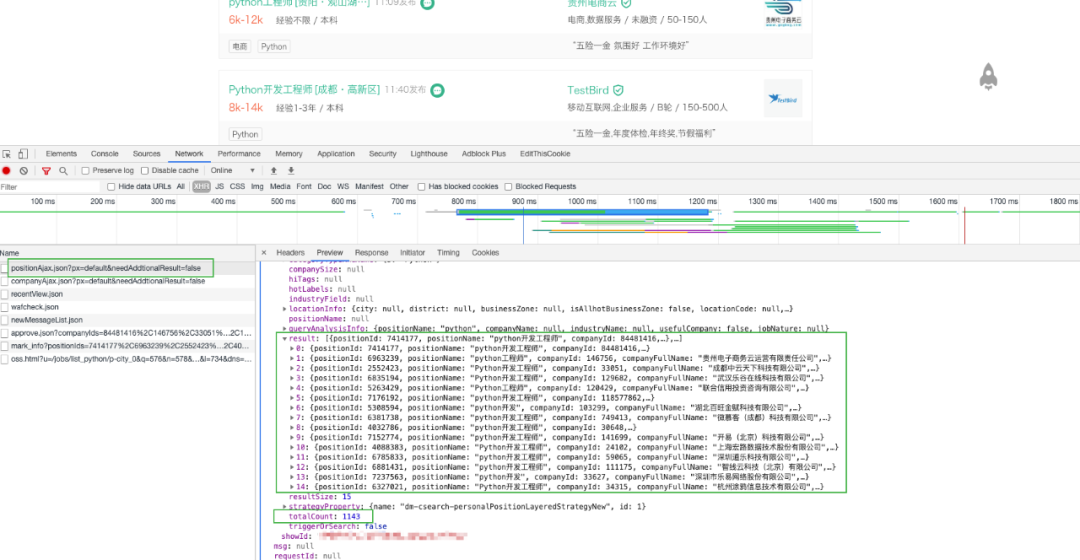
Don't worry. Let's verify it. Clear the network request record and try turning the page. When clicking on the second page, the request is recorded as follows.
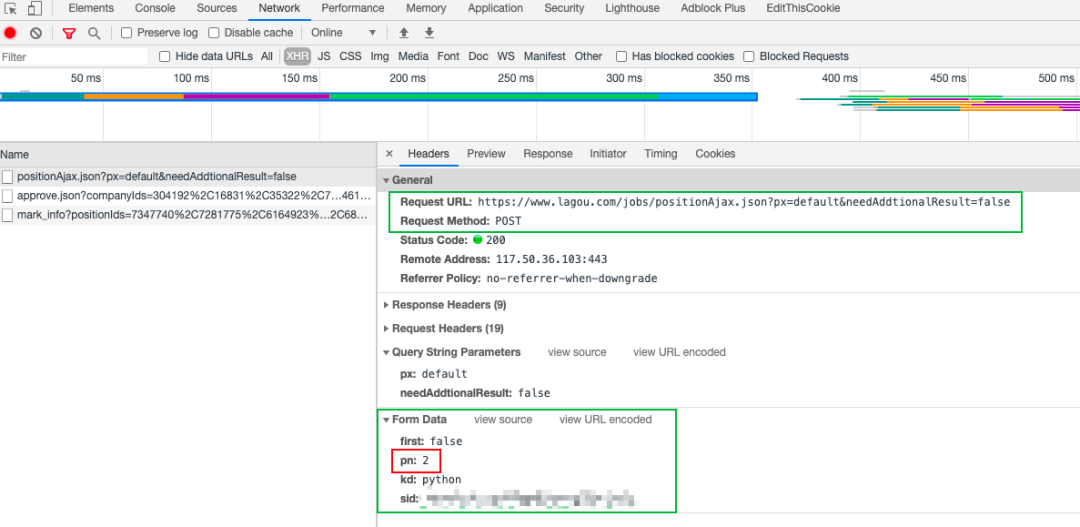
It can be seen that these data are obtained through POST request, and pn in Form Data is the current page number. Well, after web page analysis, you can write crawlers to pull data. Your crawler code might look like this.
url = 'https://www.lagou.com/jobs/positionAjax.json?px=new&needAddtionalResult=false'
headers = """
accept: application/json, text/javascript, */*; q=0.01
origin: https://www.lagou.com
referer: https://www.lagou.com/jobs/list_python?px=new&city=%E5%85%A8%E5%9B%BD
user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36
"""
headers_dict = headers_to_dict(headers)
def get_data_from_cloud(page):
params = {
'first': 'false',
'pn': page,
'kd': 'python'
}
response = requests.post(url, data=params, headers=headers_dict, timeout=3)
result = response.text
write_file(result)
for i in range(76):
get_data_from_cloud(i + 1)
After the program is written, you press the run button with an excited heart and trembling hands. Happily waiting to receive the data, but the result data you get is likely to be like this.
{"success":true,"msg":null,"code":0,"content":{"showId":"8302f64","hrInfoMap":{"6851017":{"userId":621208...
{"status":false,"msg":"You operate too often,Please visit again later","clientIp":"xxx.yyy.zzz.aaa","state":2402}
...
Don't doubt, that's what I got. This is because dragnet has made an anti crawler mechanism. The corresponding solution is not to climb frequently. After obtaining data, pause appropriately every time. For example, sleep for 3 seconds between two requests, and then add cookie information when requesting data. The improved crawler procedure is as follows:
home_url = 'https://www.lagou.com/jobs/list_python?px=new&city=%E5%85%A8%E5%9B%BD'
url = 'https://www.lagou.com/jobs/positionAjax.json?px=new&needAddtionalResult=false'
headers = """
accept: application/json, text/javascript, */*; q=0.01
origin: https://www.lagou.com
referer: https://www.lagou.com/jobs/list_python?px=new&city=%E5%85%A8%E5%9B%BD
user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36
"""
headers_dict = string_util.headers_to_dict(headers)
def get_data_from_cloud(page):
params = {
'first': 'false',
'pn': page,
'kd': 'python'
}
s = requests.Session() # Create a session object
s.get(home_url, headers=headers_dict, timeout=3) # Send a get request with the session object to get the cookie
cookie = s.cookies
response = requests.post(url, data=params, headers=headers_dict, cookies=cookie, timeout=3)
result = response.text
write_file(result)
def get_data():
for i in range(76):
page = i + 1
get_data_from_cloud(page)
time.sleep(5)
Not surprisingly, you can get all the data now, a total of 1131.
Data cleaning
Above, we stored the obtained json data in data Txt file, which is inconvenient for our subsequent data analysis operation. We are going to use pandas to analyze the data, so we need to format the data.
The process is not difficult, but a little cumbersome. The specific process is as follows:
def get_data_from_file():
with open('data.txt') as f:
data = []
for line in f.readlines():
result = json.loads(line)
result_list = result['content']['positionResult']['result']
for item in result_list:
dict = {
'city': item['city'],
'industryField': item['industryField'],
'education': item['education'],
'workYear': item['workYear'],
'salary': item['salary'],
'firstType': item['firstType'],
'secondType': item['secondType'],
'thirdType': item['thirdType'],
# list
'skillLables': ','.join(item['skillLables']),
'companyLabelList': ','.join(item['companyLabelList'])
}
data.append(dict)
return data
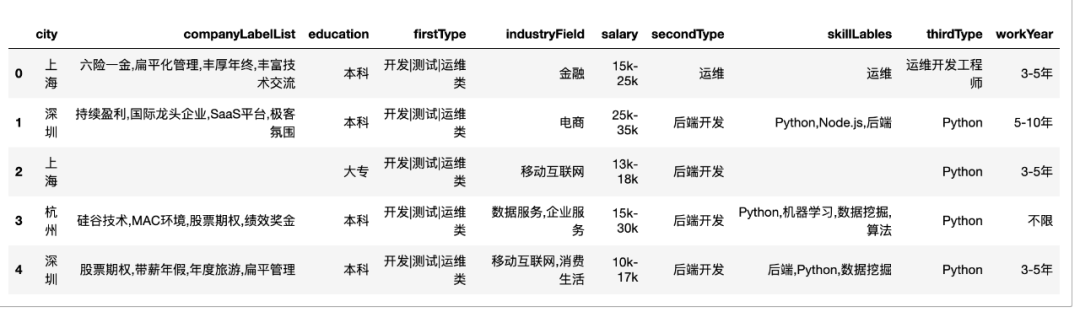
data = get_data_from_file()
data = pd.DataFrame(data)
data.head(15)
Data analysis
Obtaining and cleaning data is only our means, not our purpose. Our ultimate goal is to mine the needs of the employer through the obtained recruitment data, and take this as the goal to continuously improve our skill map.
city
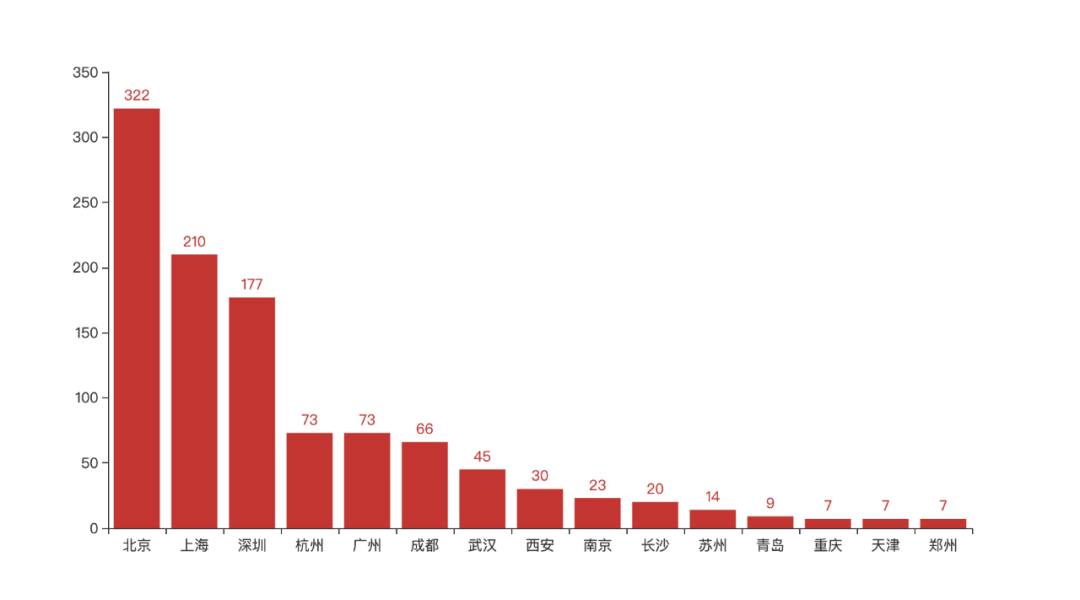
Let's first look at which cities have the greatest recruitment demand. Here we only take the city data of Top15.
top = 15
citys_value_counts = data['city'].value_counts()
citys = list(citys_value_counts.head(top).index)
city_counts = list(citys_value_counts.head(top))
bar = (
Bar()
.add_xaxis(citys)
.add_yaxis("", city_counts)
)
bar.render_notebook()
pie = (
Pie()
.add("", [list(z) for z in zip(citys, city_counts)])
.set_global_opts(title_opts=opts.TitleOpts(title=""))
.set_global_opts(legend_opts=opts.LegendOpts(is_show=False))
)
pie.render_notebook()
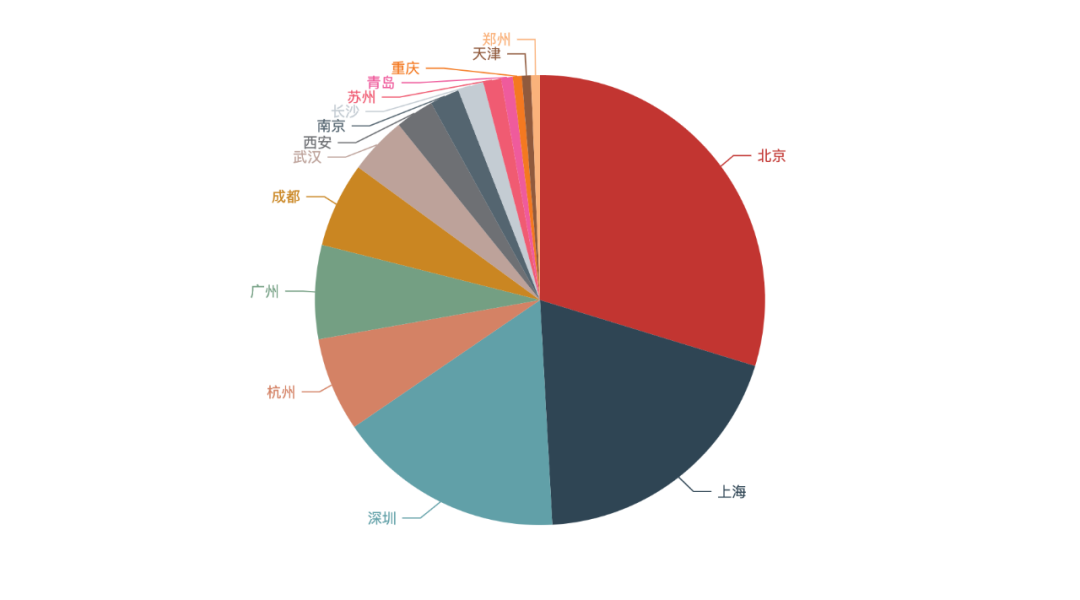
As can be seen from the above figure, Beijing basically accounts for more than a quarter of the recruitment, followed by Shanghai, Shenzhen and Hangzhou. In terms of demand alone, Guangzhou has been replaced by Hangzhou in the four first tier cities.
This explains why we want to develop in first tier cities from the side.
education
eduction_value_counts = data['education'].value_counts()
eduction = list(eduction_value_counts.index)
eduction_counts = list(eduction_value_counts)
pie = (
Pie()
.add("", [list(z) for z in zip(eduction, eduction_counts)])
.set_global_opts(title_opts=opts.TitleOpts(title=""))
.set_global_opts(legend_opts=opts.LegendOpts(is_show=False))
)
pie.render_notebook()
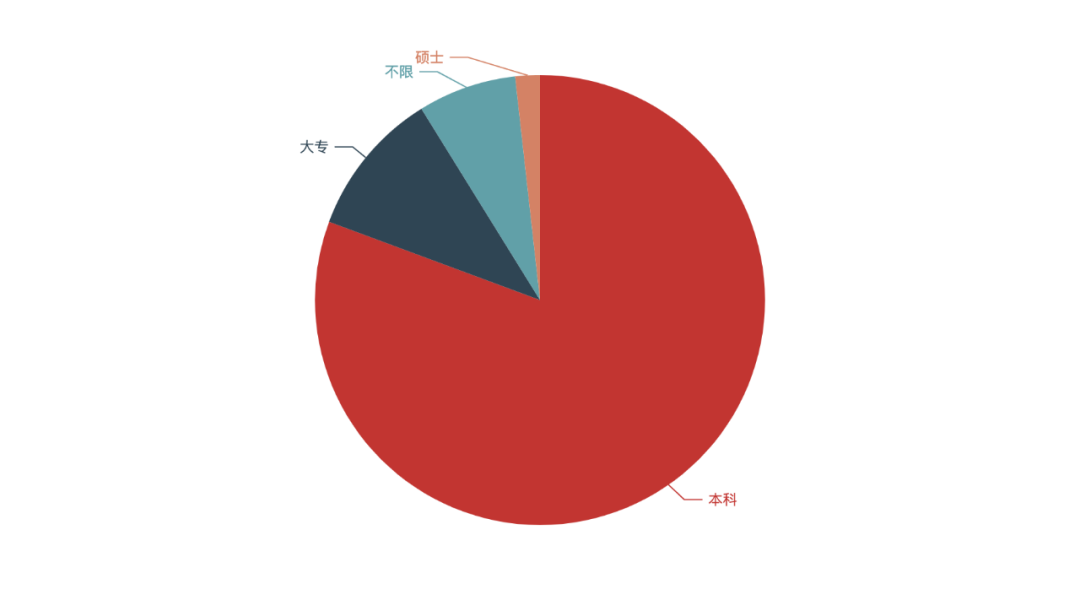
It seems that most companies require at least a bachelor's degree. It has to be said that in today's society, bachelor's degree has basically become the minimum requirement for looking for a job (except those with particularly strong ability).
Working years
work_year_value_counts = data['workYear'].value_counts()
work_year = list(work_year_value_counts.index)
work_year_counts = list(work_year_value_counts)
bar = (
Bar()
.add_xaxis(work_year)
.add_yaxis("", work_year_counts)
)
bar.render_notebook()
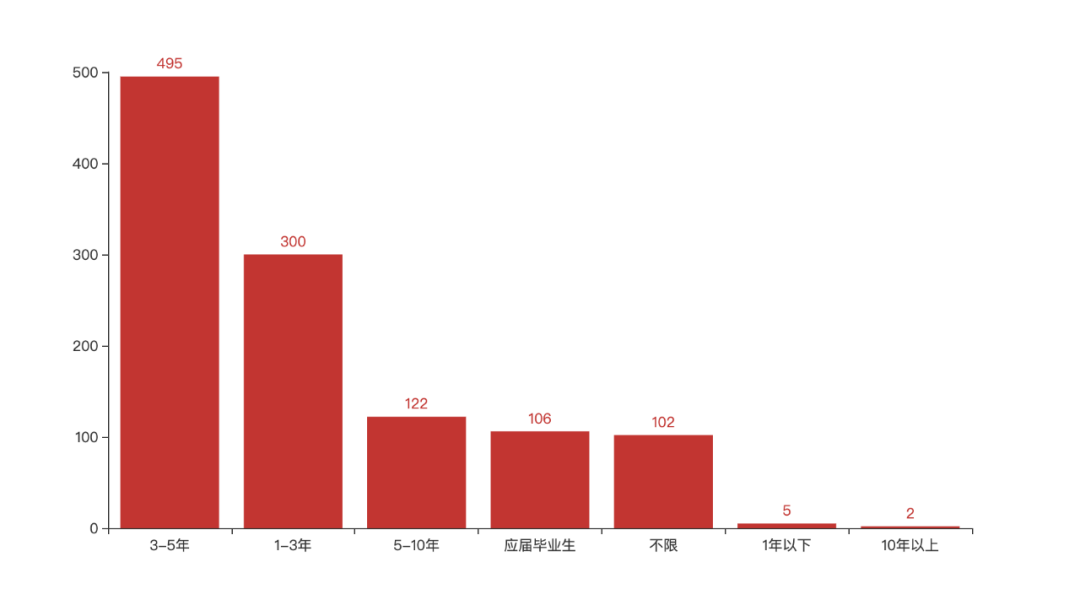
Intermediate engineers with 3-5 years are in greatest demand, followed by junior engineers with 1-3 years. In fact, this is also in line with the market law, because the work frequency of senior engineers is far lower than that of junior and intermediate engineers, and the demand of a company for senior engineers is far lower than that of junior and intermediate engineers.
industry
Let's take a look at what industries these recruiters belong to. Because the industry data is not very regular, it is necessary to cut each record separately according to.
industrys = list(data['industryField'])
industry_list = [i for item in industrys for i in item.split(',') ]
industry_series = pd.Series(data=industry_list)
industry_value_counts = industry_series.value_counts()
industrys = list(industry_value_counts.head(top).index)
industry_counts = list(industry_value_counts.head(top))
pie = (
Pie()
.add("", [list(z) for z in zip(industrys, industry_counts)])
.set_global_opts(title_opts=opts.TitleOpts(title=""))
.set_global_opts(legend_opts=opts.LegendOpts(is_show=False))
)
pie.render_notebook()
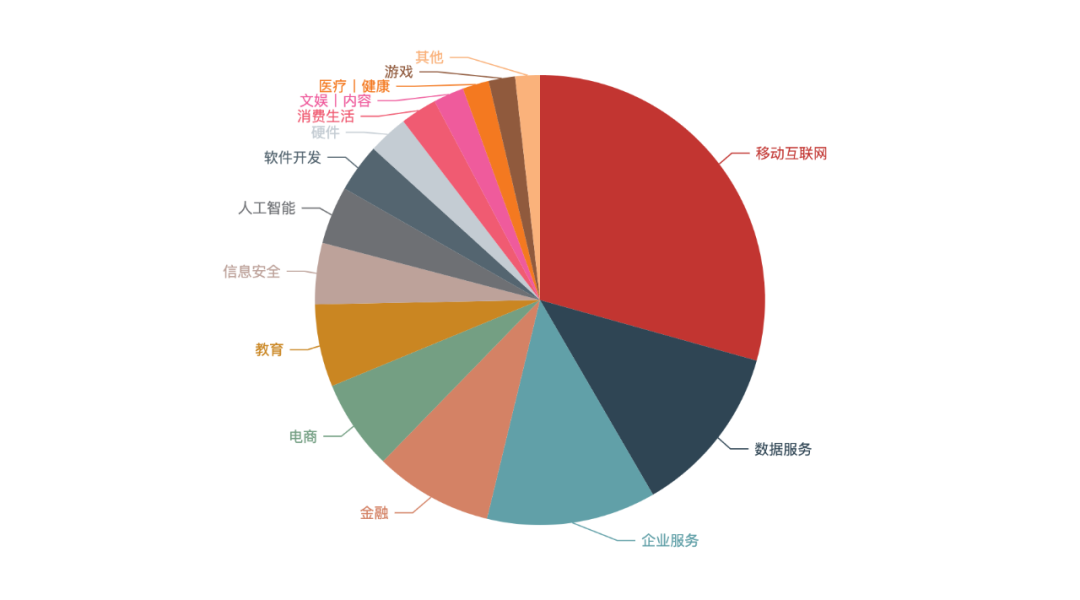
The mobile Internet industry accounts for more than a quarter of the demand, which is consistent with our understanding of the general environment.
Skill requirements
Let's take a look at the skills required by the recruiter.
word_data = data['skillLables'].str.split(',').apply(pd.Series)
word_data = word_data.replace(np.nan, '')
text = word_data.to_string(header=False, index=False)
wc = WordCloud(font_path='/System/Library/Fonts/PingFang.ttc', background_color="white", scale=2.5,
contour_color="lightblue", ).generate(text)
wordcloud = WordCloud(background_color='white', scale=1.5).generate(text)
plt.figure(figsize=(16, 9))
plt.imshow(wc)
plt.axis('off')
plt.show()

In addition to Python, the most common are backend, MySQL, crawler, full stack, algorithm, etc.
salary
Next, let's look at the salary conditions given by major companies.
salary_value_counts = data['salary'].value_counts()
top = 15
salary = list(salary_value_counts.head(top).index)
salary_counts = list(salary_value_counts.head(top))
bar = (
Bar()
.add_xaxis(salary)
.add_yaxis("", salary_counts)
.set_global_opts(xaxis_opts=opts.AxisOpts(name_rotate=0,name="salary",axislabel_opts={"rotate":45}))
)
bar.render_notebook()
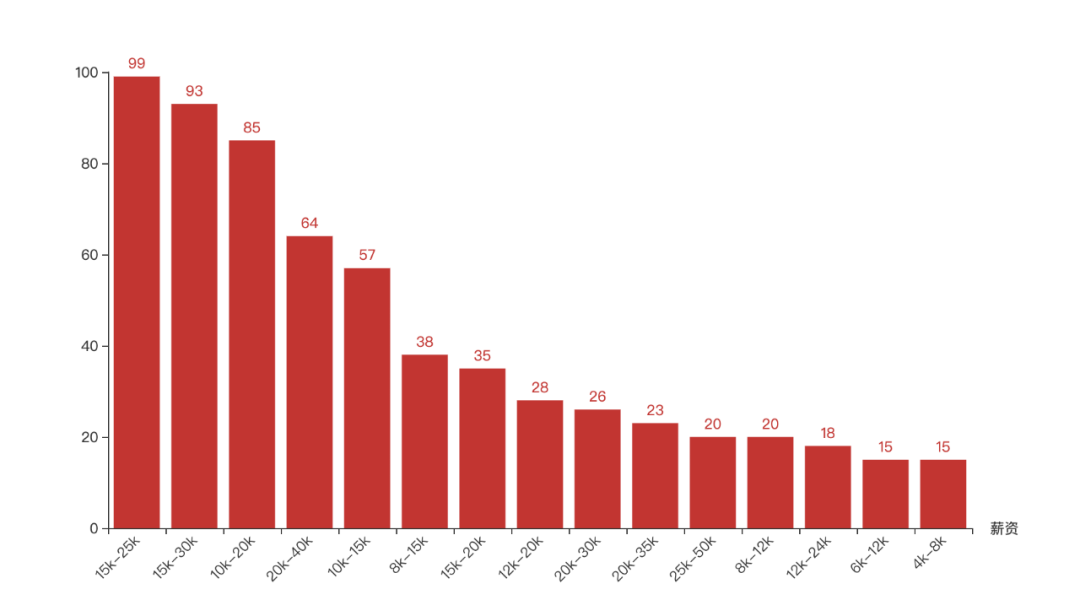
The salary given by most companies is still very considerable, basically between 20K-35K. As long as you have qualified technology, it is difficult to find a job with satisfactory salary.
welfare
Finally, let's take a look at the extra benefits offered by the company.
word_data = data['companyLabelList'].str.split(',').apply(pd.Series)
word_data = word_data.replace(np.nan, '')
text = word_data.to_string(header=False, index=False)
wc = WordCloud(font_path='/System/Library/Fonts/PingFang.ttc', background_color="white", scale=2.5,
contour_color="lightblue", ).generate(text)
plt.figure(figsize=(16, 9))
plt.imshow(wc)
plt.axis('off')
plt.show()

Double salary at the end of the year, performance bonus and flat management. Are well-known benefits, of which flat management is the characteristic of Internet companies. Unlike state-owned enterprises or other entity enterprises, the concept of superior and subordinate is relatively heavy.
summary
Today, we captured 1300 + recruitment data about Python from dragnet. After analyzing these data, we draw the following conclusions:
As for academic qualifications, you'd better graduate from a bachelor's degree. There is a large demand for engineers with 1-5 years of working experience in the market. The city with the largest demand is Beishang Shenzhen Hangzhou. The industry with the largest demand is still the mobile Internet, and most companies give good remuneration.