Introduction to the sketch framework
Scratch is a fast and high-level screen capture and Web Capture framework developed by Python language, which is used to capture web sites and extract structured data from pages.
Trapdoor of the scratch frame:
https://scrapy.org
Operation principle of sketch framework

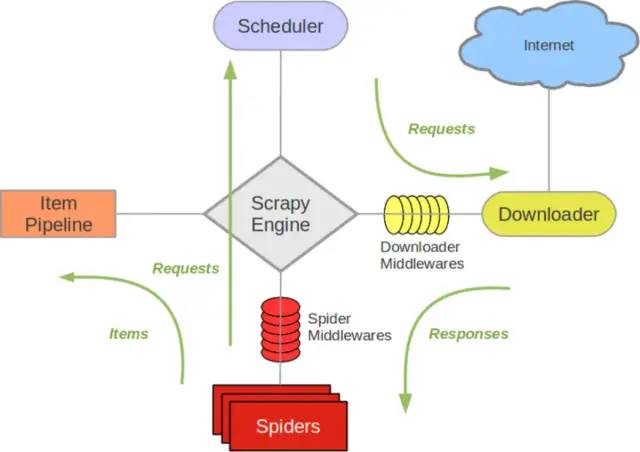
Scratch engine: communication between losers Spider, ItemPipeline, Downloader and Scheduler, signal and data transmission, etc.
Scheduler: it is responsible for receiving the Request sent by the lead stroke, sorting and arranging in a certain way, joining the queue, and returning it to the engine when needed by the engine.
Downloader: responsible for downloading all Requests sent by the scratch engine, and returning the Responses obtained to the scratch engine, which will be handed over to Spider for processing.
Spider (crawler): it is responsible for processing all Responses, analyzing and extracting data from them, obtaining the data required by the Item field, submitting the URL to be followed up to the engine and entering the scheduler again.
Item pipeline: it is responsible for processing the items obtained in the Spider and performing post-processing (detailed analysis, filtering, storage, etc.).
Downloader middleware: you can regard it as a component that can customize and expand the download function.
Spider middleware: you can understand it as a functional component that can customize the expansion and operation of the intermediate communication between the engine and the spider (such as Responses entering the spider and Requests leaving the spider)
Making a Scrapy crawler requires a total of 4 steps:
- New project (scratch startproject XXX): create a new crawler project
- Clear goal (write items.py): clear the goal you want to capture
- Making spiders (spiders/xxspider.py): making spiders starts crawling web pages
- Stored content (pipelines.py): Design pipelines to store crawled content
Today, let's take the little sister of station B as an example to personally experience the power of scratch!
Create spider project

First, let's take a look at the common commands of scratch:
scrapy startproject entry name # Create a crawler project or project scrapy genspider Crawler name domain name # Create a crawler spider class under the project scrapy runspider Crawler file #Run a crawler spider class scrapy list # View how many crawlers there are in the current project scrapy crawl Reptile name # Specify the run crawl information by name scrapy shell url/file name # Use the shell to enter the scene interactive environment
The first step is to create a scratch project, enter the directory you specify, and use the command:
scrapy startproject entry name # Create a crawler project or project
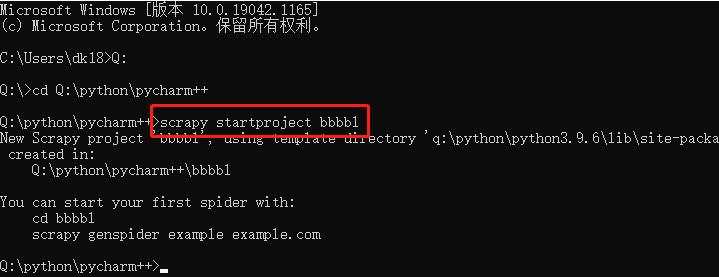
At this point, you can see that there is an additional folder called bbbbl in this directory

After we create the project, it will be prompted, so we will continue to operate according to its prompts.
You can start your first spider with:` `cd BliBli` `scrapy genspider example example.com
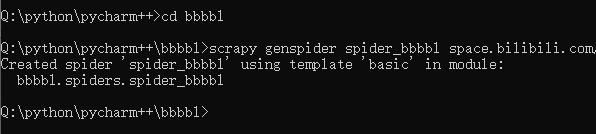
When you follow the above operation, you will find that spiders will appear in the spiders folder_ bbbl. Py this file. This is our crawler file.
Back_ earch.bilibili.com_ Is the target website we want to climb
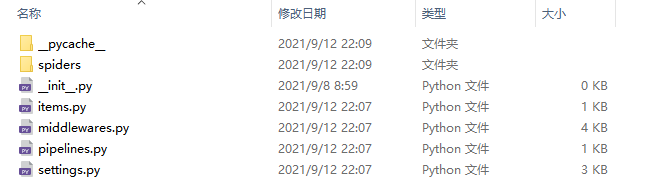
BliBli
|- BliBli
| |- __init__.py
| |- __pycache__.
| |- items.py # Item definition, which defines the data structure to be fetched
| |- middlewares.py # Define the implementation of Spider, Dowmloader and Middleware
| |- pipelines.py # It defines the implementation of the Item Pipeline, that is, the data pipeline
| |- settings.py # It defines the global configuration of the project
| |__ spiders # It contains the implementation of each Spider, and each Spider has a file
|- __init__.py
|- spider_bl.py # Crawler implementation
|- __pycache__
|- scrapy.cfg # The configuration file during the deployment of the sweep defines the path of the configuration file and the deployment related information content.
Target determination

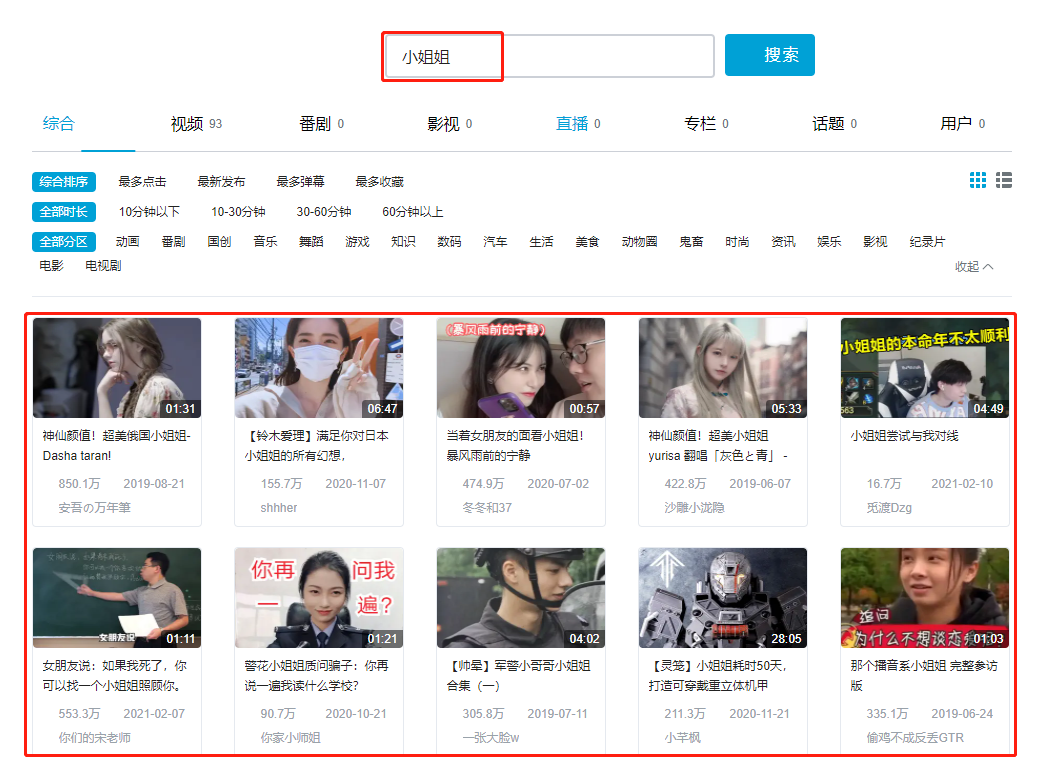
Next, we open station B to search for 'little sister' as follows. Our task today is simple,
Video title, video link, video playback duration, video playback volume, video release time, video author, cover picture and video link
Web page analysis

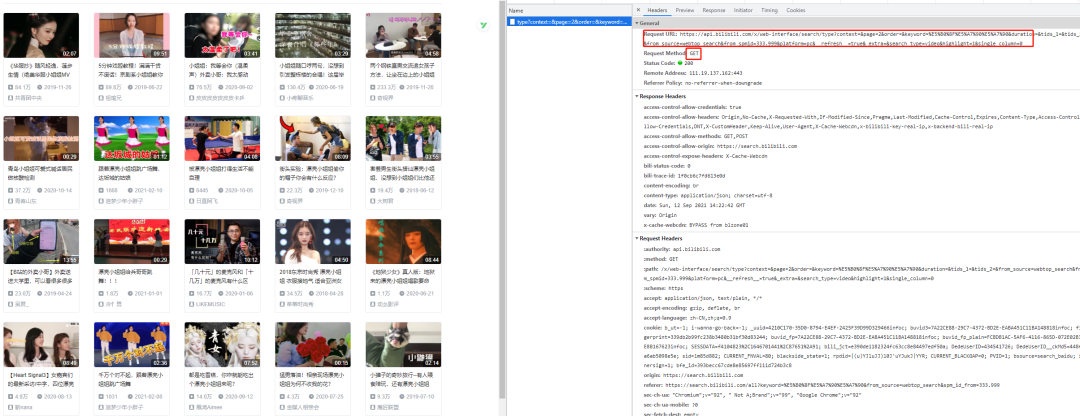
We open the web page analysis, which is a get request
Paging is controlled by the parameter page. All data exists in a json format data set
Our goal is to get the data in the result list
Request send

Set the item template and define the information we want to get
# Video title
title_video = scrapy.Field()
# Video duration
time_video = scrapy.Field()
# Playback volume
num_video = scrapy.Field()
# Release time
date_rls = scrapy.Field()
# author
author = scrapy.Field()
# pictures linking
link_pic = scrapy.Field()
# Video address
link_video = scrapy.Field()
Then we created the spider_ The specific implementation of our crawler function is written in bl.py file
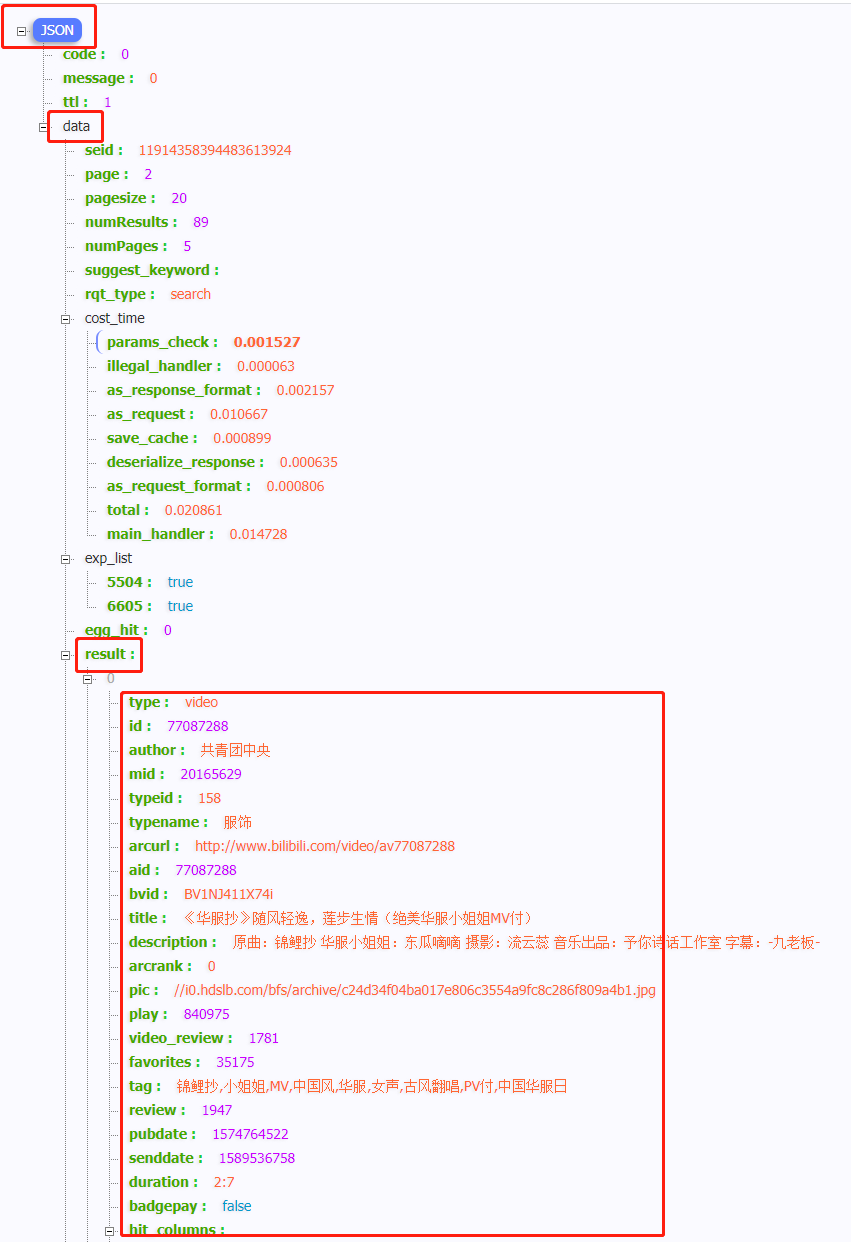
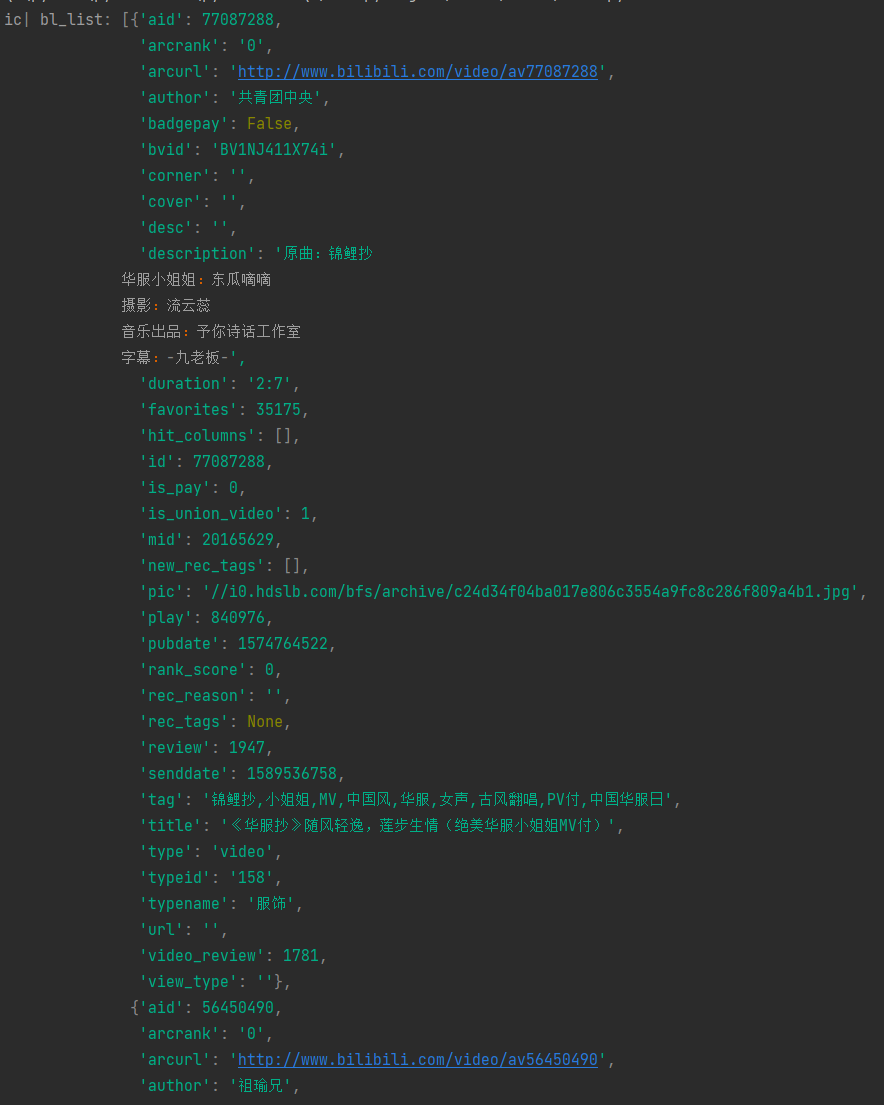
bl_list = response.json()['data']['result'] ic(bl_list)
The results are as follows:
Next, we extract the data we need:
for bl in bl_list:
# Video title
item['title_video'] = bl['title']
# Video duration
item['time_video'] = bl['duration']
# Video playback volume
item['num_video'] =bl['video_review']
# Release time
date_rls = bl['pubdate']
item['date_rls'] = time.strftime('%Y-%m-%d %H:%M', time.localtime(date_rls))
# Video author
item['author'] = bl['author']
# pictures linking
link_pic = bl['pic']
item['link_pic'] = 'https:'+link_pic
# Video link
item['link_video'] = bl['arcurl']
'''
{'author': 'Central Committee of the Communist Youth League',
'date_rls': '2019-11-26 18:35',
'link_pic': 'https://i0.hdslb.com/bfs/archive/c24d34f04ba017e806c3554a9fc8c286f809a4b1.jpg',
'link_video': 'http://www.bilibili.com/video/av77087288',
'num_video': 1781,
'time_video': '2:7',
'title_video': '<Copy of Huafu: light and easy with the wind, lotus steps generate love (beautiful Huafu little sister) MV (paid)'}
Excel Data saved successfully!
{'author': 'Brother Zu Yu',
'date_rls': '2019-06-22 18:06',
'link_pic': 'https://i0.hdslb.com/bfs/archive/784607de4c3397af15838123a2fde8c1d301fb42.jpg',
'link_video': 'http://www.bilibili.com/video/av56450490',
'num_video': 5307,
'time_video': '9:51',
'title_video': '5 Minute drama tutorial! Full of dry goods, no nonsense! The little sister of Beijing Opera Department teaches you how to get started quickly~Collect quickly~(There is a singing demonstration inside)'}
Excel Data saved successfully!
{'author': 'Pika ping pong',
'date_rls': '2020-09-02 16:36',
'link_pic': 'https://i1.hdslb.com/bfs/archive/39600c112ea656788740838d53df36fc3fe29e1f.jpg',
'link_video': 'http://www.bilibili.com/video/av754474482',
'num_video': 1148,
'time_video': '3:41',
'title_video': 'Little sister: I'll wait for you (gentle voice) takeout brother: I'm so moved!'}
Excel Data saved successfully!
{'author': 'Little pain talking about music',
'date_rls': '2020-06-19 17:47',
'link_pic': 'https://i1.hdslb.com/bfs/archive/d5bc2336899759fc5bc3cd3742f76d2846609fbd.jpg',
'link_video': 'http://www.bilibili.com/video/av668575442',
'num_video': 814,
'time_video': '3:29',
'title_video': 'The little sister hummed a few words casually. Unexpectedly, it triggered the chorus of the whole building! This graduate is terrible!'}
Excel Data saved successfully!
{'author': 'Singular horizon',
'date_rls': '2019-11-26 10:39',
'link_pic': 'https://i0.hdslb.com/bfs/archive/d0c1937e9dbccf2c639be865763e41df78f0bed5.jpg',
'link_video': 'http://www.bilibili.com/video/av77065062',
'num_video': 1583,
'time_video': '4:58',
'title_video': 'Two straight men of iron and steel exchanged ways to chase girls, which made the lady sitting beside laugh'}
'''
Let's print it in pipeline now. No problem. We'll save it locally
When we want to save the data as a file, we don't need any additional code, just execute the following code:
scrapy crawl spider Reptile name -o xxx.json #Save as JSON file scrapy crawl spider Reptile name -o xxx.jl or jsonlines #One row of json is output for each Item scrapy crawl spider Reptile name -o xxx.csv #Save as csv file scrapy crawl spider Reptile name -o xxx.xml #Save as xml file
If you want to save a file in what format, you only need to modify the suffix. I won't cite them one by one here.
We save it here in json format
class BbbblPipeline:
def process_item(self, item, spider):
# Save file locally
with open('./B Station little sister.json', 'a+', encoding='utf-8') as f:
lines = json.dumps(dict(item), ensure_ascii=False) + '\n'
f.write(lines)
return item
settings.py find the following fields and uncomment them
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
"User-Agent" : str(UserAgent().random),
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'BliBli.pipelines.BbbblPipeline': 300,
}
Run the program with the following command: you can see that a json file is generated
scrapy crawl spider_bbbbl
Open the file and you can see that we have successfully obtained the data we want

Save data Excel

We use openpyxl to save the data into excel for later data analysis. First, we use pipeline Py defines a function of ExcelPipeline,
# name
ws.append(['Video title', 'Video duration', 'Video playback volume', 'Release time', 'Video author', 'pictures linking', 'Video link'])
# storage
line = [item['title_video'], item['time_video'], item['num_video'], item['date_rls'], item['author'], item['link_pic'],item['link_video']]
ws.append(line)
wb.save('../B Station little sister.xlsx')
Then turn on the switch of this channel in settings, and the resources will be downloaded.
ITEM_PIPELINES = {
'bbbbl.pipelines.BbbblPipeline': 300,
'bbbbl.pipelines.ExcelPipeline': 301,
}
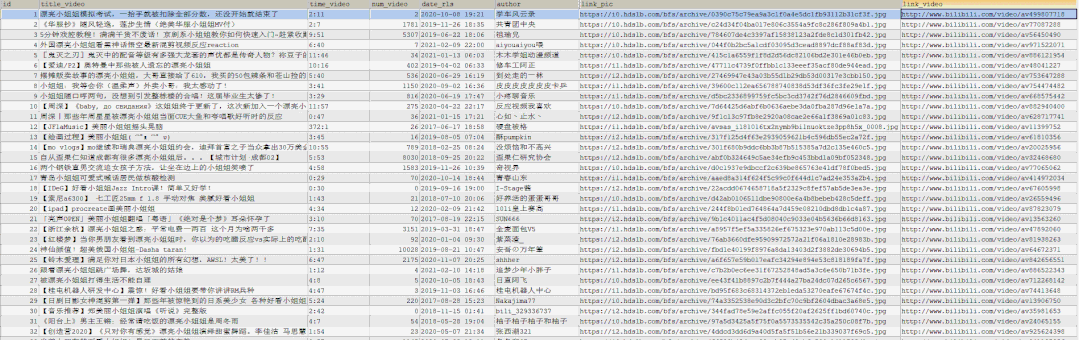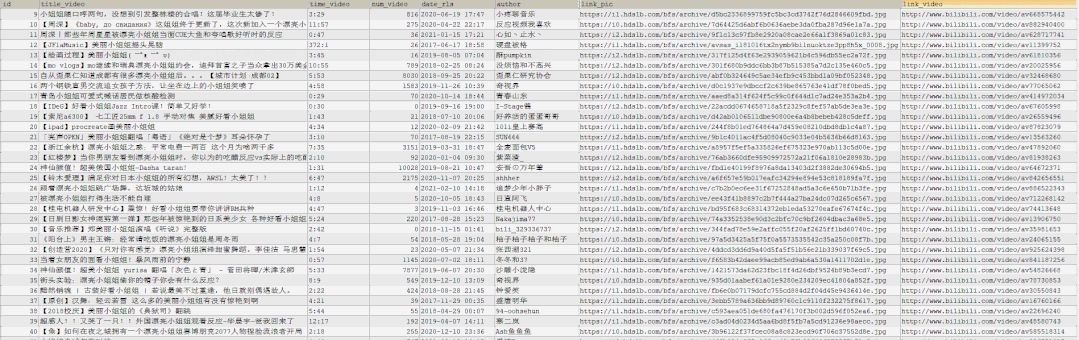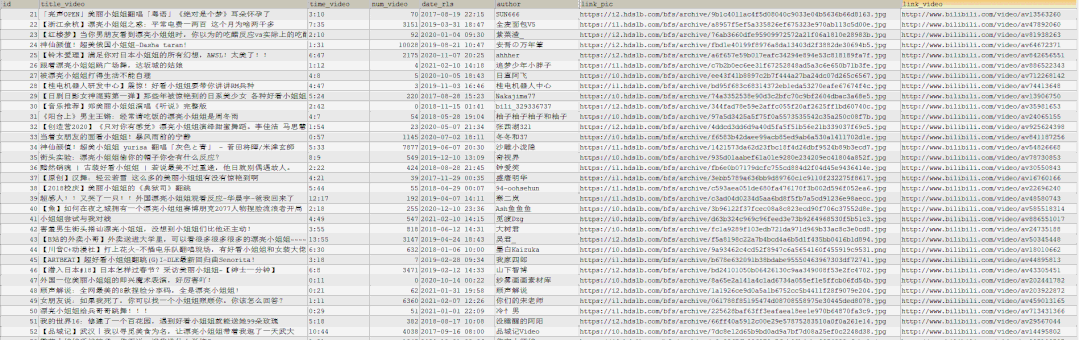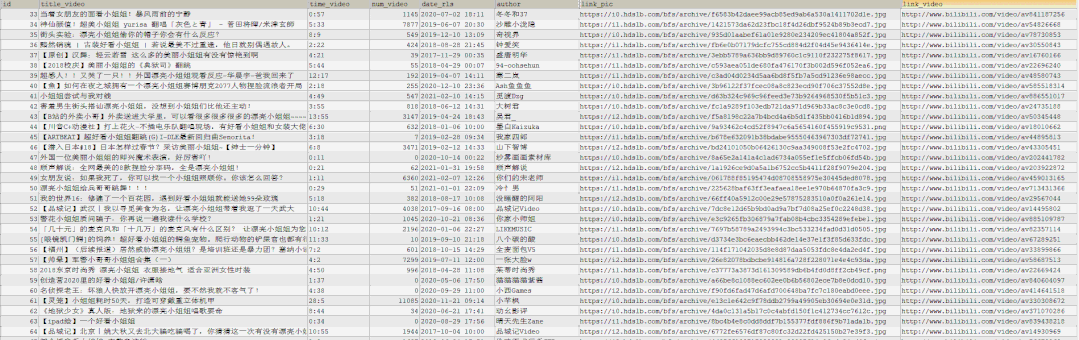
The results are as follows. We will find an excel file in the "Scene" directory where we downloaded the data
You can see that all the data has been successfully downloaded to excel

Save data Mysql

I have shared the latest mysql8 Download and installation of 0 and handling of common problems. For those who have not yet installed, you can refer to it
Python operation MySQL (Part 1)! A text to take you to understand!
Python operation MySQL (Part 2)! A text to take you to understand!
It is similar to the way of saving excel. The difference is that Mysql should configure parameters such as Mysql port, user and password in addition to configuring Pipeline in setting
# Configure Mysql MYSQL_HOST = 'localhost' MYSQL_DATABASE = 'BLBL' MYSQL_USER = 'root' MYSQL_PASSWORD = '211314' MYSQL_PORT = 3306
In addition, we need pipeline Py defines a class of MysqlPipeline
Then write Sql in it and execute it.
# Sql create table command
sql = '''
CREATE TABLE bbbbl3
(id int primary key auto_increment
, title_video VARCHAR(200) NOT NULL
, time_video VARCHAR(100)
, num_video INTEGER
, date_rls VARCHAR(100)
, author VARCHAR(100)
, link_pic VARCHAR(1000)
, link_video VARCHAR(1000)
);
'''
# Execute table creation Sql
cursor.execute(sql)
# insert data
value = (item["title_video"], item["time_video"], item["num_video"], item["date_rls"], item["author"], item["link_pic"], item["link_video"])
# Perform operations
sql = "insert into bbbbl3(title_video,time_video,num_video,date_rls,author,link_pic,link_video) value (%s,%s,%s,%s,%s,%s,%s)"
# Submit data
self.db.commit()
# close database
self.db.close()
The Mysql visualization tool I use is Sqlyog,
The query statement after execution is shown as follows:
pictures saving

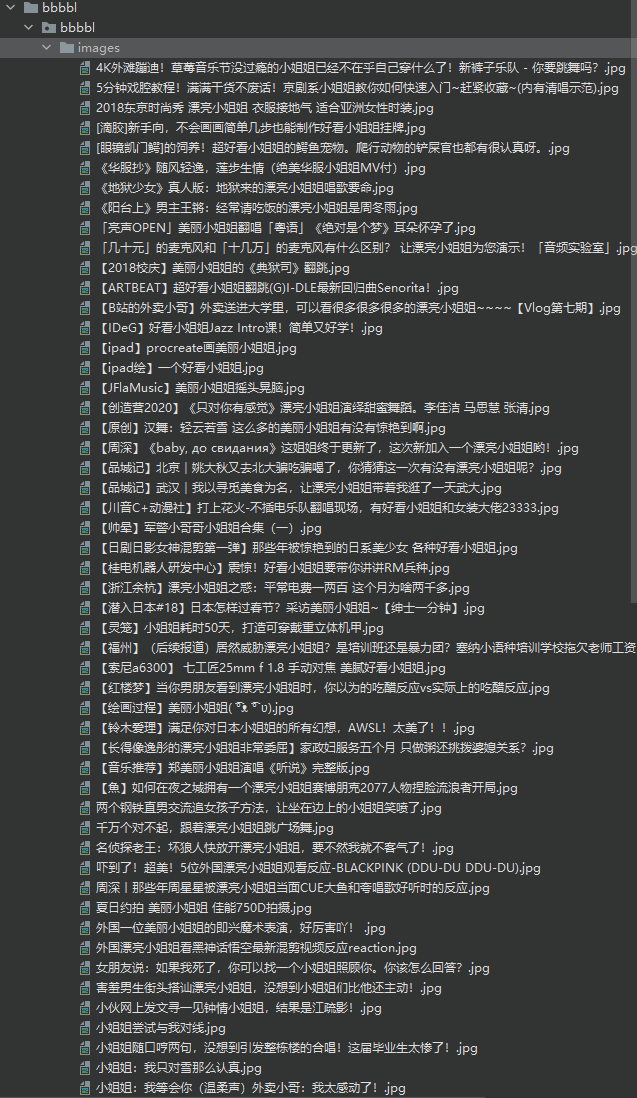
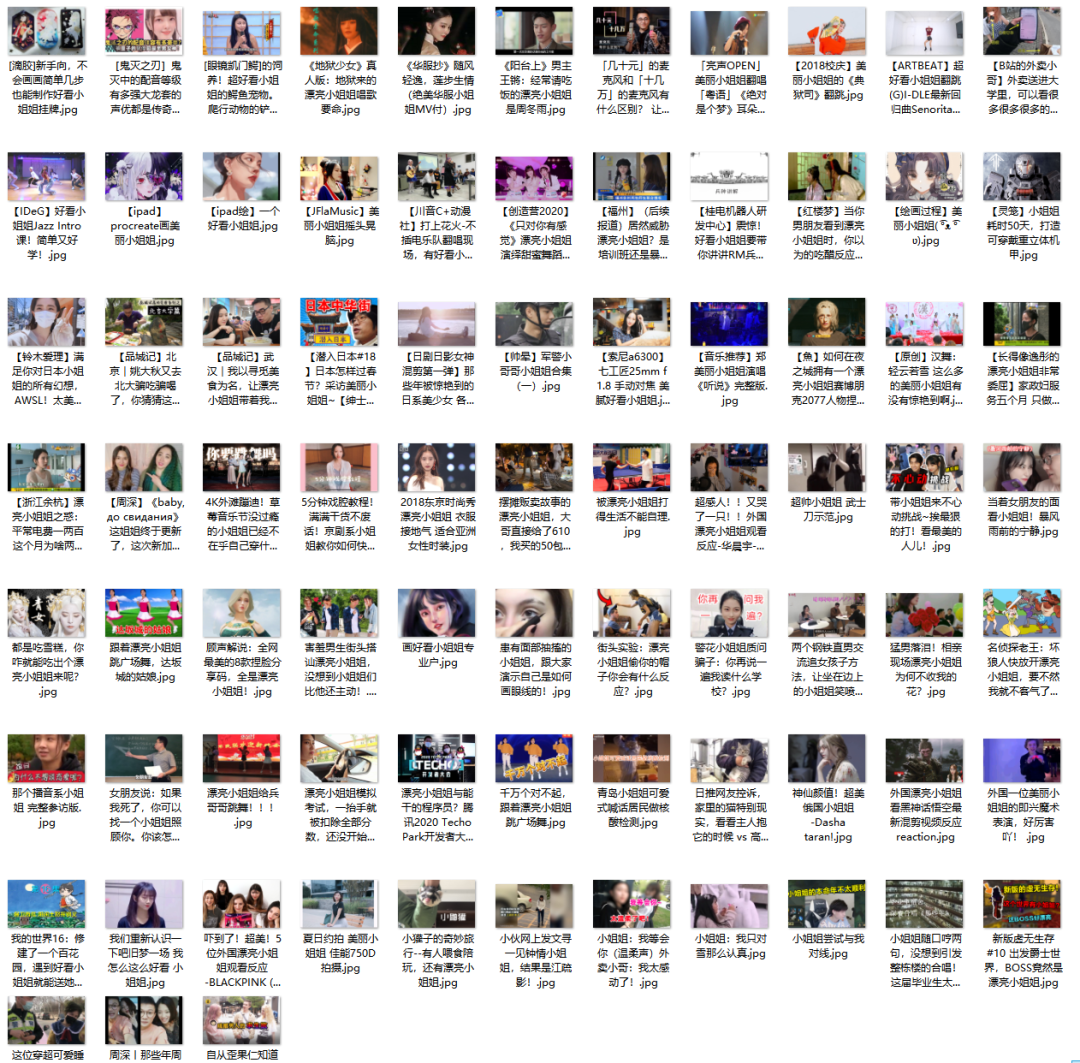
The link of the little sister on the cover has been obtained. The next thing we need to do is download these young sisters to my Marxism folder
# Save picture to local
with open('images/{}.jpg'.format(item['title_video']), 'wb') as f:
req = requests.get(item['link_pic'])
f.write(req.content)
time.sleep(random.random() * 4)
In order to prevent being crawled back by the website, a delay processing is added
The results are as follows:
Learning Resource Recommendation
Learning resources are the guarantee of learning quality and speed, so it is also very important for us to find high-quality learning resources. The learning resources listed below are good resources regardless of ranking:
I hope everyone can stick to it and learn Python. Get the QR code at the end of the article
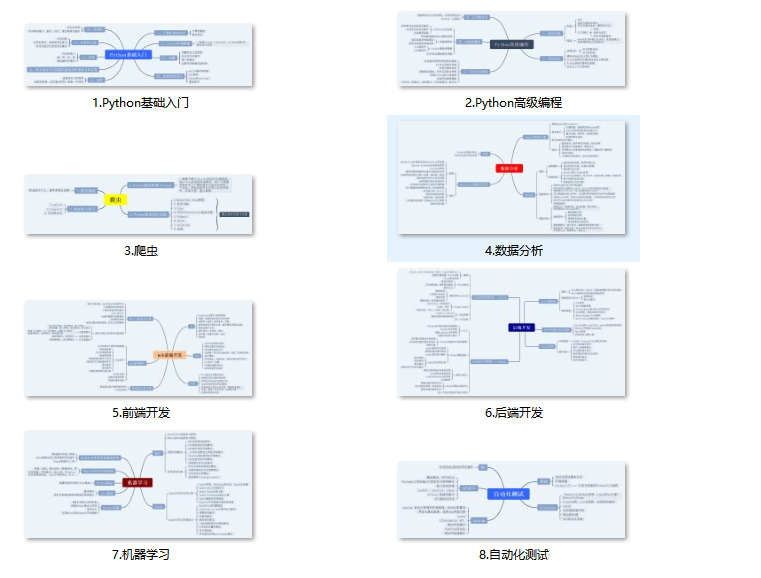
👉 Python learning route summary
The technical points in all directions of Python are sorted out to form a summary of knowledge points in various fields. Its use is that you can find corresponding learning resources according to the above knowledge points to ensure that you can learn more comprehensively
## 👉 Python essential development tools 👈
## 👉 Excellent Python learning books 👈
When I learn a certain foundation and have my own understanding ability, I will read some books or handwritten notes compiled by my predecessors. These notes record their understanding of some technical points in detail. These understandings are unique and can learn different ideas
Warm tip: the space is limited. The folder has been packaged. The way to obtain it is at the end of the text
👉 Python learning video 600 collection 👈
Watching zero basic learning video is the quickest and most effective way to learn. It's still easy to get started with the teacher's ideas in the video from basic to in-depth.
## 👉 Actual combat cases 👈
Optical theory is useless. We should learn to knock together and practice, so as to apply what we have learned to practice. At this time, we can make some practical cases to learn
## 👉 100 Python exercises 👈
Check learning results

## 👉 Interview questions 👈
##Summary (get)
What I want to say is that there is nothing wrong with learning programming and mastering technology. Far from IT, at least in the next five to ten years, IT will still be a hot industry, so the top priority programming technology is naturally promising, such as artificial intelligence, big data, Internet of things, driverless driving, etc., which all need programming technology. Under the wheel of the rapid development of society, some people will inevitably fall behind. If you don't want to do something that everyone can do all the time, if you don't want to be easily eliminated by society, learn a skill and improve yourself!
This complete set of Python learning materials (including environment, python tool cracking video installation tutorial and installation package) has been uploaded to CSDN official website. Friends can scan CSDN official authentication QR code below via wechat * * [free access]**
