From today on, we officially enter the study of STL.
Today we will focus on three classes -- string vector and list
catalogue
Common structure description of string class
1. Common construction classes
3. Access and traversal of string class objects
4. Modification of string class object
5. string class nonmember function
Simulation Implementation of string class
Common structure description of vector
1. vector definition (construction) class
2. The part of vector similar to string
Simulation Implementation of vector
Introduction to the usage of list
Simulation Implementation of list (highlight)
Before the introduction, we can first understand what is STL? How many versions does it have? And its advantages and disadvantages.
Introduction to STL

STL version
As of today, it is believed that there are four versions of STL:
Original version (HP version)
The original version completed by Alexander Stepanov and Meng Lee in HP Labs is in the spirit of open source. They declare that anyone is allowed to use, copy, modify, disseminate and commercially use these codes without paying. The only condition is that it needs to be used as open source as the original version. HP version - the ancestor of all STL implementation versions.
P. J. version
Developed by P. J. Plauger and inherited from HP version, it is adopted by Windows Visual C + + and cannot be disclosed or modified. Defects: low readability and strange symbol naming.
RW version
Developed by Rouge Wage and inherited from HP version, it is adopted by C+ + Builder and cannot be disclosed or modified, with general readability.
SGI version
Developed by Silicon Graphics Computer Systems, Inc. and inherited from HP version. Adopted by GCC(Linux), it has good portability and can be published, modified or even sold. From the perspective of naming style and programming style, it is very readable. We will read part of the source code when learning STL later. This version is the main reference.
Six components of STL:
Imitative function; Algorithm; Iterator; Space configurator; Containers; Adapter.
Defects of STL: (understand)
1. The update of STL library is too slow. This is serious Tucao, the last edition is reliable C++98, and make complaints about C++03 in the middle. It has been 13 years since C++11 came out, and STL was further updated.
2. STL does not support thread safety at present. In the concurrent environment, we need to lock ourselves. And the granularity of the lock is relatively large.
3. STL's extreme pursuit of efficiency leads to internal complexity. Such as type extraction and iterator extraction.
4. The use of STL will cause code inflation. For example, using vector/vector/vector will generate multiple copies of code. Of course, this is caused by the template syntax itself
Today, we will learn about three of these classes -- string class, vector class and list class.
string class
introduce
Let's talk about its usage first, and then explain its simulation implementation.
First, let's briefly introduce the string class: (understand)
1. String is a class representing character sequence
2. The standard string class provides support for such objects. Its interface is similar to that of the standard character container, but it adds a design feature specially used to operate single byte character strings.
3. The string class uses char (that is, as its character type, it uses its default char_traits and allocator type) (for more information about templates, see basic_string).
4. The string class is basic_ An instance of the string template class, which uses char to instantiate basic_ String template class with char_traits and allocator as basic_ The default parameter of string (based on more template information, please refer to basic_string).
5. Note that this class processes bytes independently of the encoding used: if it is used to process sequences of multi byte or variable length characters (such as UTF-8), all members of this class (such as length or size) and its iterators will still operate according to bytes (rather than actually encoded characters).
Common structure description of string class
1. Common construction classes
We can visit relevant websites to see:
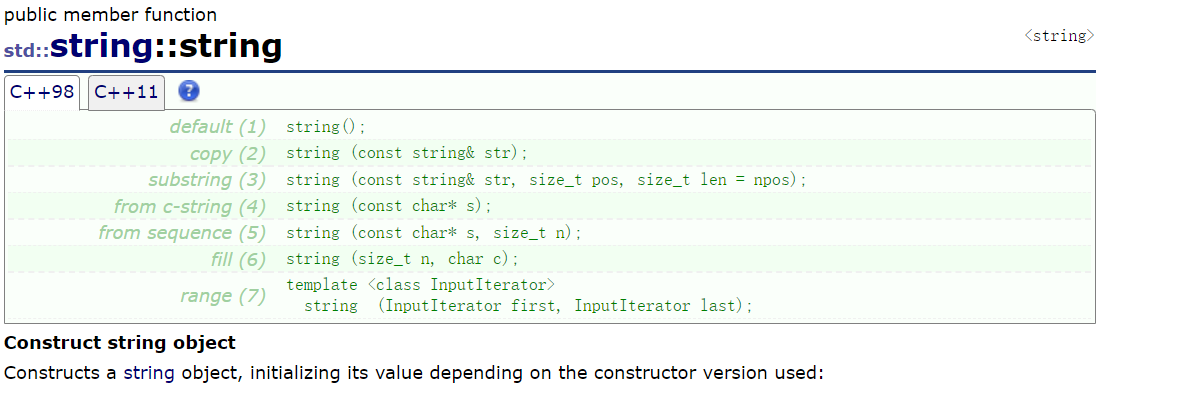
Box ~ ~ you can see that so many functions can be used as constructors.
Let's introduce some common:
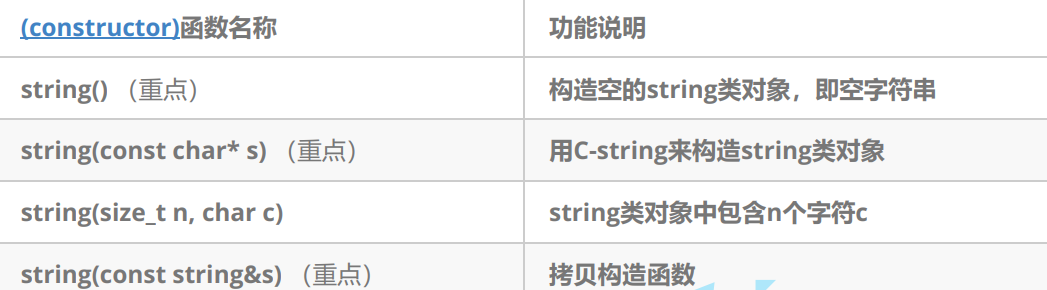
Let's focus on the following:
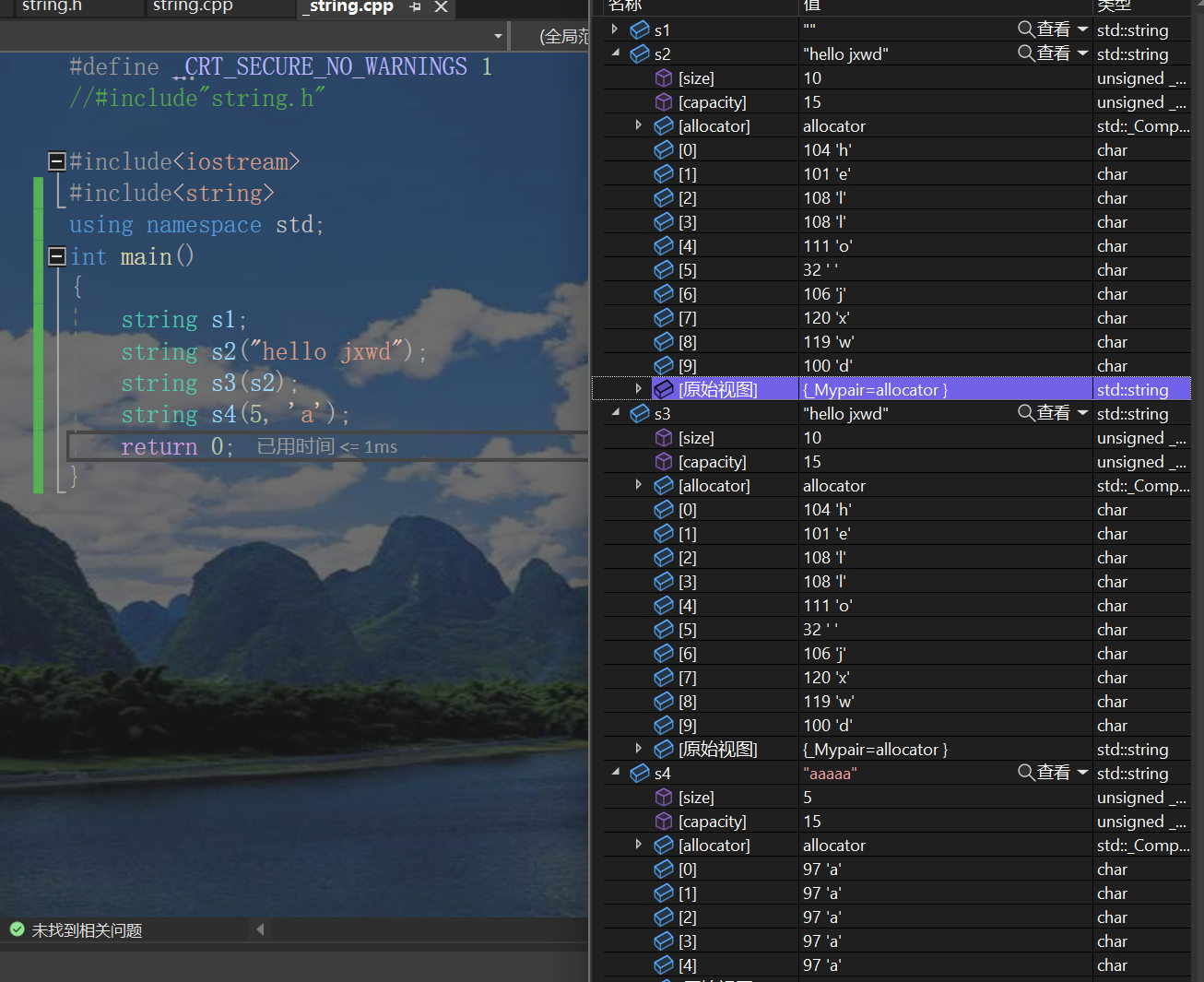
Like the above writing methods, they are all OK.
Note that it hides' \ 0 ', which is invisible even when the user is in mode.
In fact, the assignment operation can also be used directly. The compiler will optimize it to call the constructor once and then call the copy construction again.
2. Capacity operation class

As you can see, there are many more.
Let's introduce the following and give examples
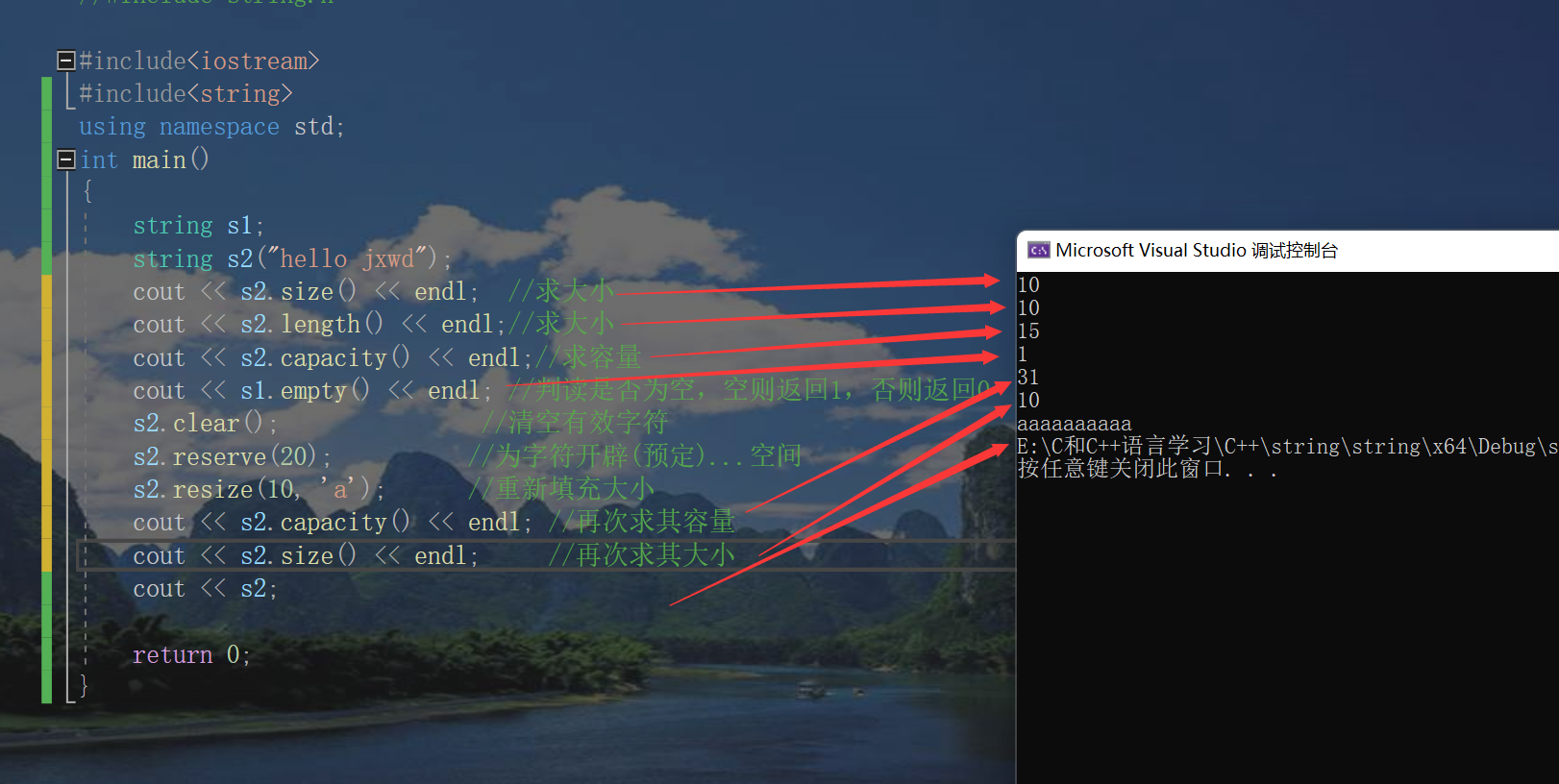
be careful:
1. The underlying implementation principles of size() and length() methods are exactly the same. The reason for introducing size() is to keep consistent with the interfaces of other containers. Generally, size() is basically used.
2. clear() just clears the valid characters in the string without changing the size of the underlying space.
3. Both resize (size_t n) and resize(size_t n, char c) change the number of valid characters in the string to N. the difference is that when the number of characters increases: resize(n) fills the extra element space with 0, and resize(size_t n, char c) fills the extra element space with C. Note: when resizing the number of elements, increasing the number of elements may change the size of the underlying capacity. If reducing the number of elements, the total size of the underlying space will remain unchanged.
4. reserve(size_t res_arg=0): reserve space for string without changing the number of valid elements. When the parameter of reserve is less than
When the total size of the underlying space of string is, the reserver will not change the capacity.
3. Access and traversal of string class objects

 Let's mainly introduce the above:
Let's mainly introduce the above:
The above eight are iterators that return forward, reverse and constant values.
The following is accomplished by overloading the function with the operator.
When it comes to this access, we introduce three common traversal access methods:
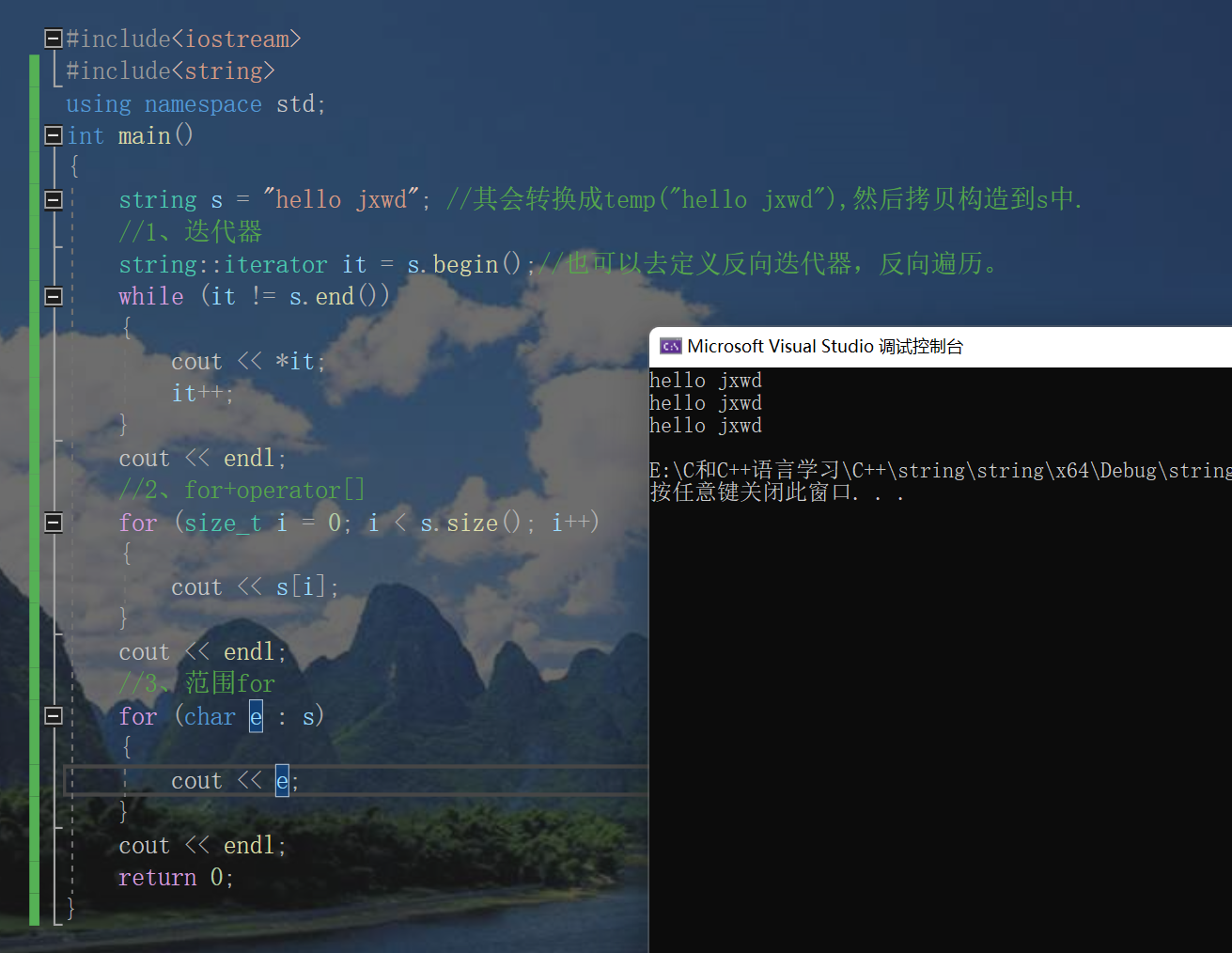
#include<iostream>
#include<string>
using namespace std;
int main()
{
string s = "hello jxwd"; //It will be converted to temp("hello jxwd") and then copied into s
//1. Iterator
string::iterator it = s.begin();//You can also define reverse iterators and reverse traversal.
while (it != s.end())
{
cout << *it;
it++;
}
cout << endl;
//2,for+operator[]
for (size_t i = 0; i < s.size(); i++)
{
cout << s[i];
}
cout << endl;
//3. Range for
for (char e : s)
{
cout << e;
}
cout << endl;
return 0;
}4. Modification of string class object



As for what the function is, it has been clearly written above.
Let's now use these functions to give several examples:
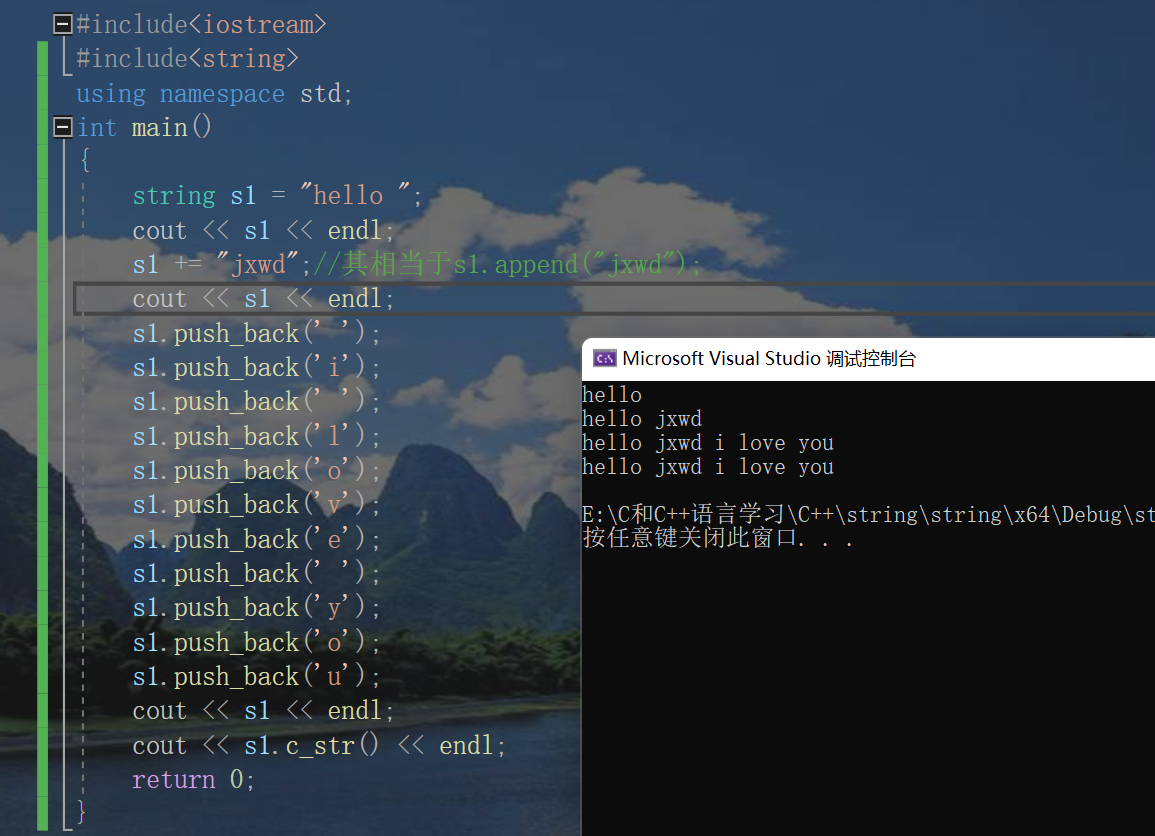
#include<iostream>
#include<string>
using namespace std;
int main()
{
string s1 = "hello ";
cout << s1 << endl;
s1 += "jxwd";//It is equivalent to S1 append("jxwd");
cout << s1 << endl;
s1.push_back(' ');
s1.push_back('i');
s1.push_back(' ');
s1.push_back('l');
s1.push_back('o');
s1.push_back('v');
s1.push_back('e');
s1.push_back(' ');
s1.push_back('y');
s1.push_back('o');
s1.push_back('u');
cout << s1 << endl;
cout << s1.c_str() << endl;
return 0;
}Let's move on to substr interface:

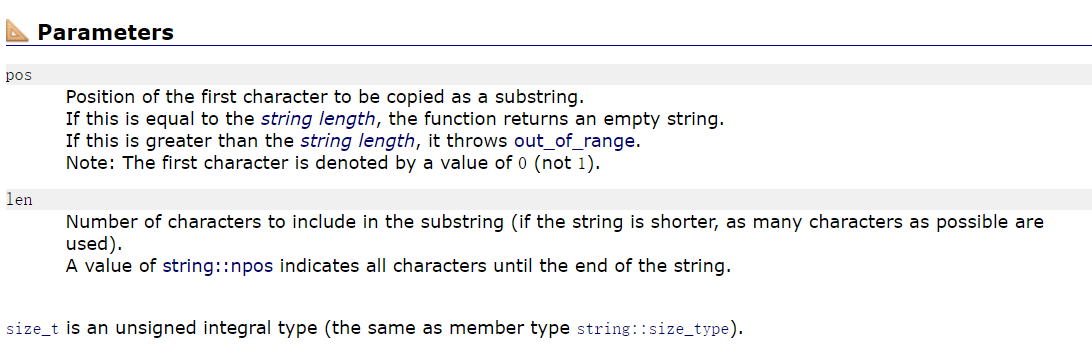
Through the index of the above literature, we can until substr starts from pos and ends with len characters backward, and the return value is the string in the middle.
Notice that the npos here is size_ - 1 of type T, that is, it is the largest number.
Let's talk about the find interface again:
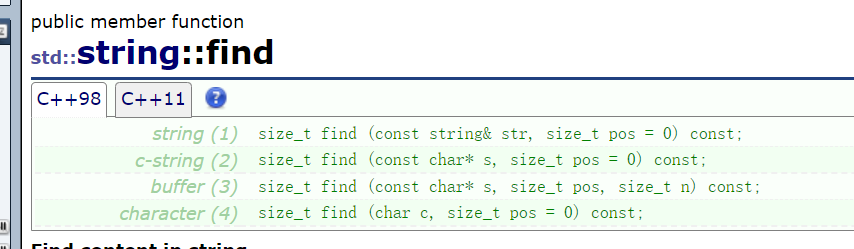
It can be seen that there are four overload forms, and each represents a different meaning.
rfind has the same meaning as find, which is mainly from the back.
Let's link substr and find interfaces together to take an example:
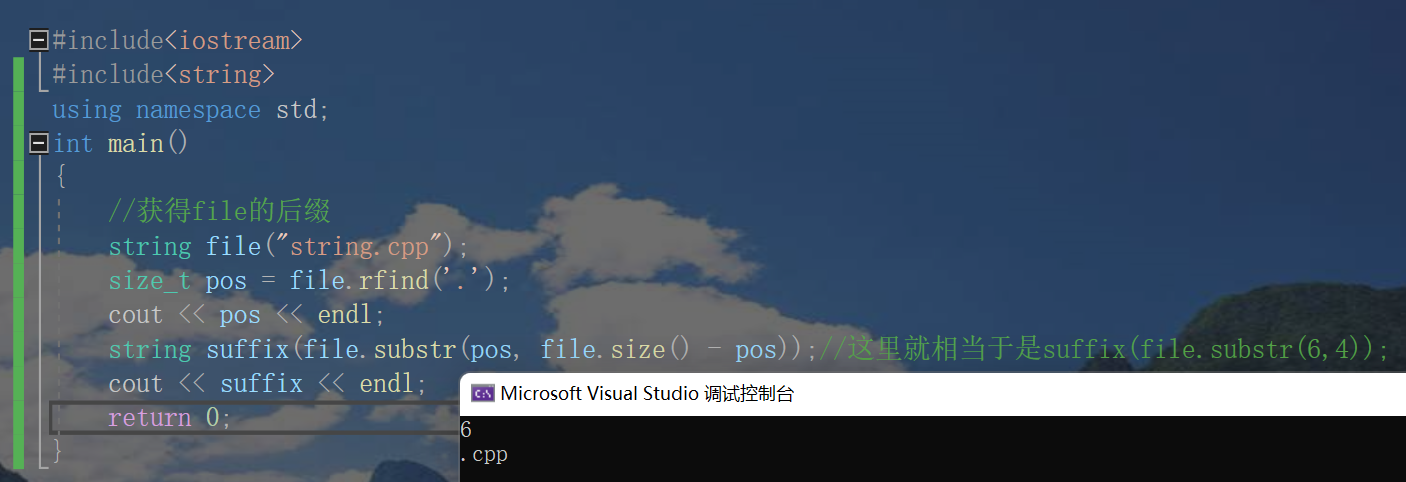
#include<iostream>
#include<string>
using namespace std;
int main()
{
//Get the suffix of file
string file("string.cpp");
size_t pos = file.rfind('.');
cout << pos << endl;
string suffix(file.substr(pos, file.size() - pos));//This is equivalent to suffix(file.substr(6,4));
cout << suffix << endl;
return 0;
}Let's take another example of the combination of find and substr:
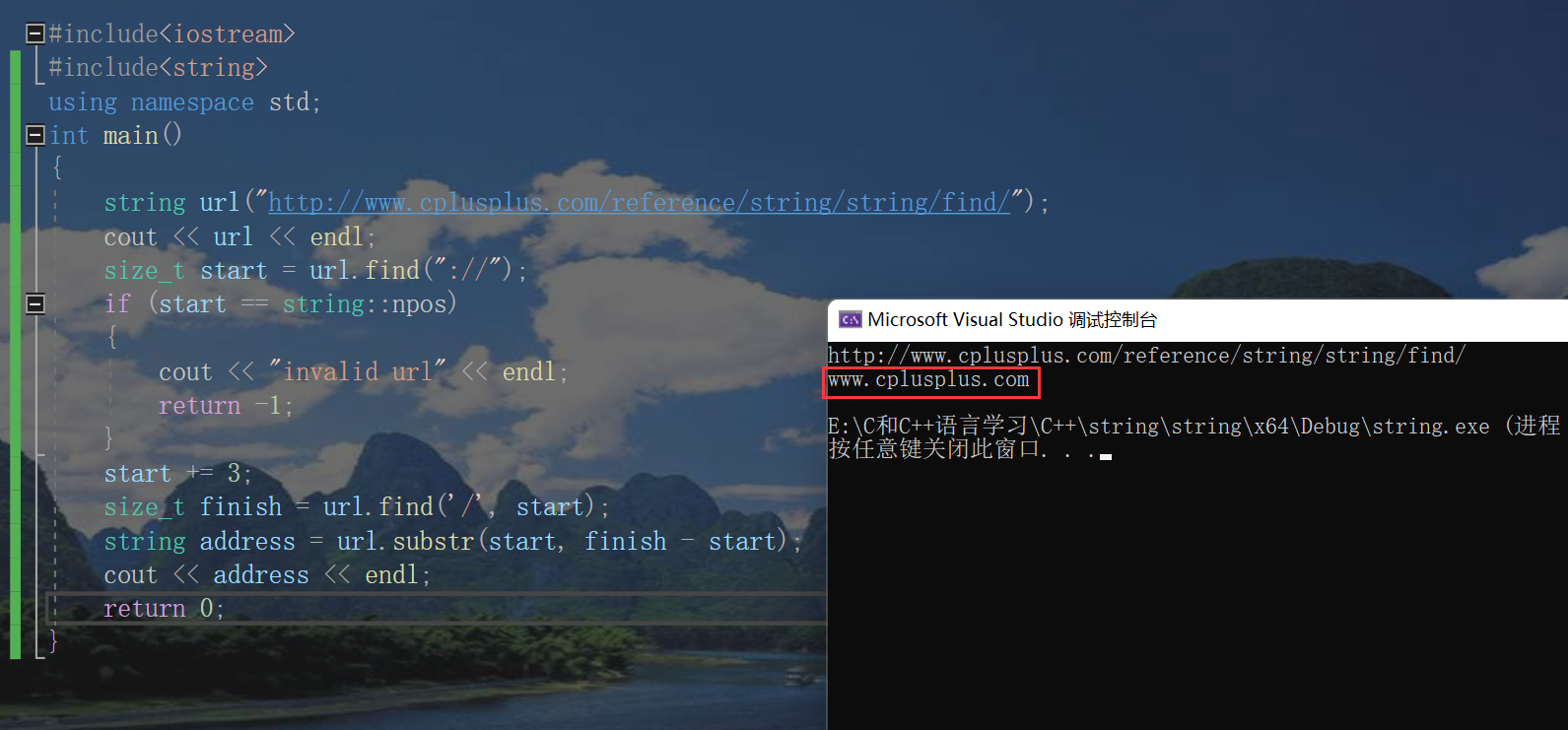
Notice such an interface and the four overloaded forms of find above,
In other words, our find here can specify to start from a certain location or a certain range. (Note: if not found, - 1 will be returned)
You can find strings, strings of type C, and single characters.
#include<iostream>
#include<string>
using namespace std;
int main()
{
//Print out the domain name of the link below
string url("http://www.cplusplus.com/reference/string/string/find/");
cout << url << endl;
size_t start = url.find("://"); / / first find: / /, find and return: the subscript of the location. If not found, return npos
if (start == string::npos)
{
cout << "invalid url" << endl;
return -1;
}
start += 3; //Offset it back three positions
size_t finish = url.find('/', start); //Start at the start position and look back for '/'
string address = url.substr(start, finish - start); //Intercept the string between finish and start
cout << address << endl;
return 0;
}
Delete and insert:


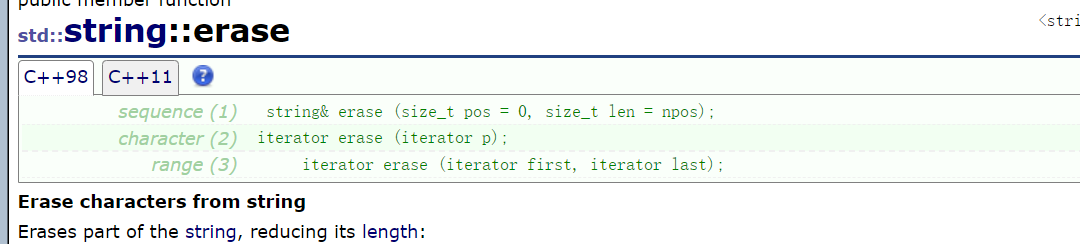
I don't think the author needs to give too many examples of both. It has been said clearly in the literature.
5. string class nonmember function

In fact, we don't need to give too many examples. I believe you can use them more or less. We will specifically talk about its principle in the later simulation implementation.
Simulation Implementation of string class
In fact, the introduction in the form of blog is still relatively stiff, but it does not hinder the ability to make it clear.
It's a long section.
Next, the author will patiently explain for you bit by bit.
#include<iostream>
#include<string.h>
#include<assert.h>
namespace jxwd
{
class string
{
/*string(const string& s)
:_str(new char[strlen(s._str+1)])
{
strcpy(_str, s._str);
}*///Traditional writing
//string& operator=(const string& s)
//{
/*if (this != &s)
{
delete[] _str;
_str = new char[strlen(s._str) + 1];
strcpy(_str, s._str);
}
return *this;*///Traditional writing
//}
public:
typedef char* iterator;
typedef const char* const_iterator;
iterator begin() //Define iterators
{
return _str; //Readable and writable
}
iterator end() //Similarly, define the iterator returned by the end() function. Here, we use pointers to implement it
{ //Notice that it returns the next position of the last element
return _str + _size;
}
const_iterator begin() const
{
return _str; //Readable version only
}
const_iterator end() const
{
return _str + _size;
}
string(const char* str = "", size_t capacity = 1,size_t size = 0) //Constructor
{
_str = new char[strlen(str) + 1]; //Create such a large space first
if (capacity > strlen(str))_capacity = capacity; //If the existing capacity is smaller than it, the existing capacity is expanded to the new capacity size
else _capacity = strlen(str); //(it depends on how big the capacity you pass on)
_size = _capacity;
strcpy(_str, str); //In their own development_ In str, copy the contents of str.
}
~string() //Destructor
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
void swap(string& s) //Self created swap function
{
std::swap(_str, s._str);
std::swap(_size,s._size);
std::swap(_capacity, s._capacity);
}
string(const string& s) //The copy constructor is called when the class is created
:_str(nullptr) //Initialize three member variables, the object pointed to by this pointer
,_size(0)
,_capacity(0)
{
string tmp(s._str); //Call its constructor
std::swap(_str, tmp._str); //You can directly swap(tmp);
std::swap(_size,tmp._size); //Exchange all three quantities
std::swap(_capacity,tmp._capacity);
}
string& operator=(string s)
{
std::swap(_str, s._str); //Directly call the swap function in the library to exchange the contents of variables
return *this; //You can directly swap(s). In this case, jxwd::swap is called
}//The modern address will change / / return * this
char& operator[](size_t i) //Operator overload, overload [] operator / / readable and writable
{
assert(i < _size);
return _str[i];
}
const char& operator[](size_t i) const //Operator overload, overload [] operator / / read only
{
assert(i < _size);
return _str[i];
}
const char* c_str() const //c_str function, which returns its array
{
return _str;
}
size_t size() const //Returns the size of an array element
{
return _size;
}
void reserve(size_t n) //reserve function, used to reset the space
{
if (n > _capacity) //Open space and expand capacity. If n >_ Capacity is developed, otherwise it should be ignored
{
char* tmp = new char[n + 1]; //Dynamically open n+1 (the last one is used to store '\ 0')
strncpy(tmp, _str,_size); //Copy the original_ In str_ Copy all data to tmp.
delete[] _str; //Destroy the original_ str
_str = tmp; //Let_ str points to tmp
_capacity = n; //_ capacity is assigned to n
}
}
void resize(size_t n , char val = '\0')
{ //Open space + initialization, and may expand capacity
if (n < _size)
{
_size = n;
_str[_size] = '\0'; //Note that you need to put '\ 0' in the last position
}
else
{
if (n > _capacity)
{
reserve(n);
}
for (size_t i = _size; i < n; i++)
{
_str[i] = val;
}
_str[n] = '\0';
_size = n;
}
}
void push_back(char ch) //Tail insertion
{
if (_size == _capacity) //If the space is insufficient, the capacity will be expanded automatically
{
reserve(_capacity == 0 ? 4 : _capacity*2);
}
_str[_size] = ch; //Assign the last position to ch
_str[_size + 1] = '\0'; //Then assign the next position to '\ 0'
_size++; //Let_ size increases by itself. Because push_ One more element after back
}
void append(const char* str) //This is to add a string after it
{
size_t len = _size + strlen(str);
if (len > _capacity) //First calculate whether to expand the capacity
{
reserve(len);
}
strcpy(_str + _size, str); //Then copy STR to_ str+_size location
_size = len; //Reassign_ Value of size
}
string& insert(size_t pos, char ch) //Inserting ch in pos is much like inserting a sequential table
{
assert(pos <= _size); //Assert first to determine whether it can be inserted
if (_size == _capacity)
{
reserve(_capacity * 2); //Calculate whether capacity expansion is required
}
size_t end = _size + 1; //Calculate new capacity size
while (end > pos)
{
_str[end] = _str[end - 1]; //Insertion of simulation sequence table
end--;
}
_str[pos] = ch;
_size++;
return *this;
}
string& insert(size_t pos, const char* str) //With the above composition overload, insert a string
{
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len); //As above, the assertion asserts that space is opened when space is opened
}
char* end = _str + _size + len; //Mark the address of the tail
while (end >= _str + pos) //Similarly, move backward to make len space
{
*(end + 1) = *end;
end--;
}
strncpy(_str + pos, str, len); //Copy in the same way
_size += len; //_ size recalculation
}
string& erase(size_t pos,size_t len = npos) //Similarly, it is equivalent to the tail deletion of the sequence table
{
size_t leftLen = _size - pos; //If len defaults, it is deleted from the pos position
if (len > leftLen) //If len > leftlen is even larger, delete it all
{
_str[pos] = '\0'; //Attention '\ 0'
_size = pos;
}
else
{ //otherwise
strcpy(_str + pos, _str + pos + len); //Directly connect the following elements with '\ 0' and copy them to the front position
_size -= len; //Recalculate_ size
}
}
string& operator+=(char ch) //Overload + =. If you add a character, it is mainly to call push_back
{
push_back(ch);
return *this;
}
string& operator+=(const char* str) //If + = a string, append is called
{
append(str);
return *this;
}
size_t find(char ch, size_t pos = 0) //The find function mainly traverses the search one by one. If it is found, it returns the subscript. Otherwise, it returns npos
{ //This is the missing character
for (size_t i = pos; i < _size; i++)
{
if (_str[i] == ch)
{
return i;
}
}
return npos;
}
size_t find(const char* str, size_t pos = 0)
{
const char* ret = strstr(_str, str); //This is to find the string and call the strstr function directly
if (ret)
{
return ret - _str;
}
else
{
return npos;
}
}
void clear() //Clear all data
{
_size = 0;
_str[_size] = '\0';
}
std::istream& getline(std::istream& cin, string& s) //getline function, which mainly obtains the information of one line
{
s.clear(); //The first is to know all the data,
char ch;
ch = cin.get();
while (ch != '\n') //Then get character by character until '\ n' is obtained
{
s += ch;
ch = cin.get();
}
return cin; //Definition requires return of input stream
}
private: //Its private class is defined here
char* _str; //Since it is a string, we define an array
size_t _size; //And define its capacity and the number of elements
size_t _capacity;
static const size_t npos; //Define a static variable npos. We will see that it is defined externally and defined as - 1
};
//Next is operator overloading
inline bool operator<(const string& s1, const string& s2) //Overloading of relational operators
{
return strcmp(s1.c_str(), s2.c_str()) < 0; //Call strcmp function directly
}
inline bool operator>(const string& s1, const string& s2) //The following directly reuses the above
{
return !(s1 <= s2);
}
inline bool operator==(const string& s1, const string& s2) //ditto
{
return strcmp(s1.c_str(), s2.c_str()) == 0;
}
inline bool operator<=(const string& s1, const string& s2)
{
return s1 < s2 || s1 == s2;
}
inline bool operator>=(const string& s1, const string& s2)
{
return!(s1 < s2);
}
inline bool operator!=(const string& s1, const string& s2)
{
return !(s1 == s2);
}
std::ostream& operator<<(std::ostream& cout, string& s) //Output a string
{
for (auto ch : s) //Output one by one until all the s contents are output (the output will be stopped in case of space, Tab and carriage return)
{
cout << ch;
}
return cout;
}
std::istream& operator>>(std::istream& cin, string& s) //Enter a string
{
s.clear();
char ch;
ch = cin.get(); //Call CIN Get() function
while (ch != ' ' && ch != '\n') //Enter one by one until you encounter spaces, line breaks, or tabs
{
s += ch;
ch = cin.get();
}
return cin;
}
const size_t string::npos = -1; //Define the static variable as - 1 (because it is size_t, it is a very large number)
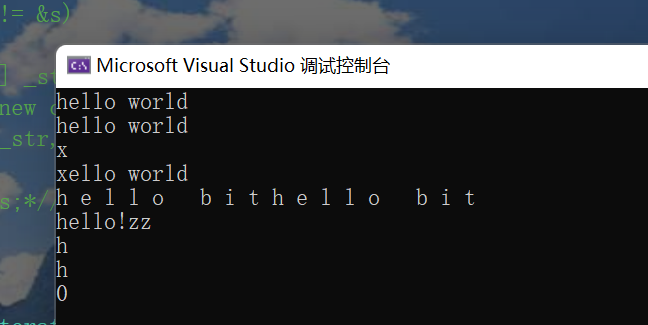
}You can copy it to the local ide.
We can test.
For example: (test case:)
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<string.h>
#include<assert.h>
namespace jxwd
{
void test_string1()
{
string s1("hello world");
string s2(s1);
std::cout << s1.c_str() << std::endl;
std::cout << s2.c_str() << std::endl;
string s3("hello bit");
s1 = s3;
std::swap(s1, s3);//Low efficiency
}
void test_string2()
{
string s1("hello world");
s1[0] = 'x';
std::cout << s1[0] << std::endl;
std::cout << s1.c_str() << std::endl;
}
void test_string3()
{
string s1("hello bit");
string::iterator it = s1.begin();
while (it != s1.end())
{
std::cout << *it << " ";
it++;
}
for (auto ch : s1)//Will be replaced by iterators, which are supported by iterators
{
std::cout << ch << " ";
}
std::cout << std::endl;
}
void test_string4()
{
string s1("hello");
s1 += '!';
s1.resize(8, 'z');
std::cout << s1.c_str() << std::endl;
s1.resize(1, 's');
std::cout << s1.c_str() << std::endl;
s1.resize(3);
std::cout << s1.c_str() << std::endl;
}
void test_string5()
{
string s1("hello ljx");
std::cout << s1.find("hel") << std::endl;
}
}
using namespace std;
int main()
{
jxwd::test_string1();
jxwd::test_string2();
jxwd::test_string3();
jxwd::test_string4();
jxwd::test_string5();
return 0;
}
We conclude that:
Let's look at vector
Use of vector
In the same way as string, vector is actually the same as string in many places.
Some notes about vector:
1. vector is a sequence container that represents a variable size array.
2. Like arrays, vector also uses continuous storage space to store elements. This means that the elements of vector can be accessed by subscript, which is as efficient as array. But unlike an array, its size can be changed dynamically, and its size will be automatically processed by the container.
3. Essentially, vector uses dynamically allocated arrays to store its elements. When new elements are inserted, the array needs to be resized to increase storage space. This is done by allocating a new array and then moving all the elements to this array. In terms of time, this is a relatively expensive task, because the vector does not reallocate the size every time a new element is added to the container.
4. vector space allocation strategy: vector will allocate some additional space to adapt to possible growth, because the storage space is larger than the actual storage space. Different libraries use different strategies to balance the use and reallocation of space. But in any case, the redistribution should be logarithmically increasing interval size, so that when inserting an element at the end, it is completed in constant time complexity. Therefore, vector takes up more storage space. In order to obtain the ability to manage storage space and grow dynamically in an effective way.
5. Compared with other dynamic sequence containers (deques, lists and forward_lists), vector is more efficient when accessing elements, and it is relatively efficient to add and delete elements at the end. For other deletion and insertion operations that are not at the end, the efficiency is lower. Compared with lists and forward_ Lists unified iterators and references are better
vector is even simpler than string. Because it doesn't need to consider '\ 0' at the end.
For the learning of vector, we do the same with the help of documents.
Common structure description of vector
1. vector definition (construction) class
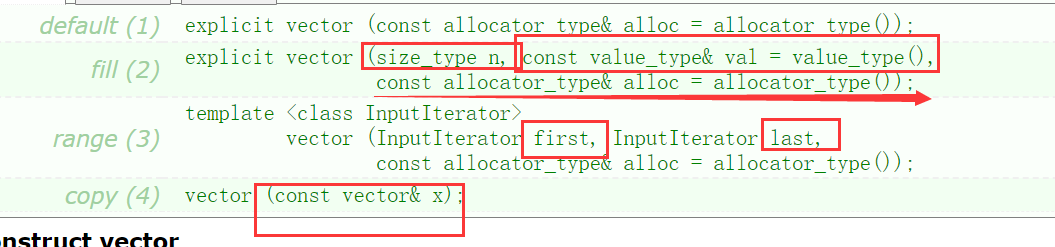
It can be seen that there are many. Let's simplify it according to the specific usage:
We can construct it like this

First: nonparametric structure;
Second: construct and initialize n Vals;
Third: copy structure / / that is, copy in the document
Fourth: construct with iterators.
It should also be noted that:
We can see that a template parameter is required when it is defined. Therefore, we need to add such a template parameter when defining the vector class to form an explicit template conversion, otherwise there will be an error.
Let's give a few examples:
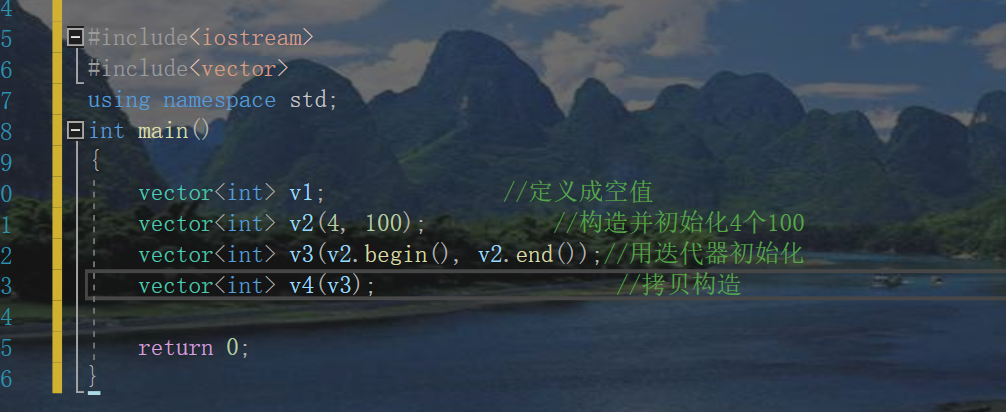 As shown in the figure above. Various methods have been marked.
As shown in the figure above. Various methods have been marked.
2. The part of vector similar to string
As we said before, vector and string have many similarities.
Next, we will compare and learn.
The first is the iterator of both. Same usage:

Thirdly, it is the addition, deletion, query and modification of vector.


I can't see anything different.
Moreover, the space capacity of vector is basically the same as that of string.

The author will not repeat these things. If you encounter problems in the future, you can compare them before the string class, and then we will add if there are specific problems.
3. vector iterator failure.
The main function of iterator is to make the algorithm do not care about the underlying data structure. Its underlying layer is actually a pointer or encapsulates the pointer.
For example, the iterator of vector is the primitive pointer T *. Therefore, the failure of the iterator is actually the destruction of the space pointed to by the corresponding pointer at the bottom of the iterator, and the use of a space that has been released will result in program crash
(that is, if you continue to use the iterator that has expired, the program may crash)
For vector, the operations that may cause its iterator to fail are:
1. The operation that will cause the change of its underlying space may be the failure of the iterator, such as resize, reserve, insert, assign and push_back et al.
They are actually caused by the possible capacity increase of the bottom layer. We mentioned in the simulation implementation of the string class that if calloc is used for capacity expansion, that is, the old space of the underlying principle of vector is released, while it also uses the old space between releases when printing. When operating on the IT iterator, the actual operation is a released space, If it causes the code to crash at runtime, the part of the space pointed to by its iterator is likely to fail.
What's the solution?
Solution: after the above operations are completed, if you want to continue to operate the elements in the vector through the iterator, you just need to re-enter it
Assignment is enough.
2. Delete element at specified position - erase
#include <iostream>
using namespace std;
#include <vector>
int main()
{
int a[] = { 1, 2, 3, 4 };
vector<int> v(a, a + sizeof(a) / sizeof(int));
// Use find to find the iterator where 3 is located
vector<int>::iterator pos = find(v.begin(), v.end(), 3);
// Deleting the data at the pos location will invalidate the pos iterator.
v.erase(pos);
cout << *pos << endl; // This will result in illegal access
return 0;
}After erase deletes the pos position element, the element after the pos position will move forward without changing the underlying space. Theoretically, the iterator should not fail. However, if pos happens to be the last element, pos happens to be the end position after deletion, and the end position has no element, then pos will fail.
Therefore, when you delete an element at any position in the vector, vs considers the position iterator invalid.
Solution to iterator failure: re assign the iterator before use
About the bottom layer:
Let's give a picture to understand: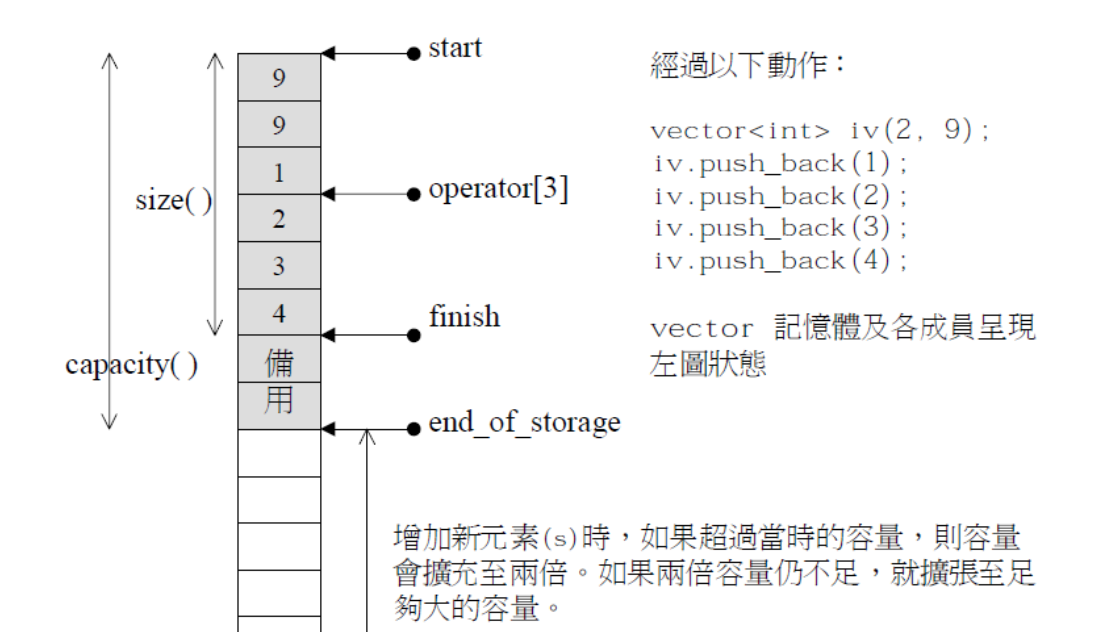
Note: it does not necessarily open up new space directly in the original position. It may be the process of opening up another space, then copying it, and then releasing the old space.
Simulation Implementation of vector
#include<iostream>
#include<assert.h>
using namespace std;
namespace ljx
{
template <class T>
class vector
{
public:
typedef T* iterator; //After defining the iterator, we can see that the bottom layer here is implemented with pointers
typedef const T* const_iterator;
vector() //Constructors, in fact, should have overloaded forms
:_start(nullptr)
, _finish(nullptr)
, _endofstorage(nullptr)
{}
vector(int a, int b) //The overloaded form of constructor is the form of fill
:_start(nullptr)
,_finish(nullptr)
,_endofstorage(nullptr)
{
for (int i = 0; i < a; i++)
this->push_back(b);
}
vector(const vector<T>& v) //Copy construction can also use the method of exchange
{
_start = new T[v.capacity()]; //First, open up space and return the first address to_ start
_finish = _start; //_ finish to_ start
_endofstorage = _start + v.capacity(); //Calculate the capacity of the tail
for (size_t i = 0; i < v.size(); i++)
{
*_finish = v[i];
++_finish;
}
}
/*
vector(const vector<T>& v)
:_start(nullptr)
,_finish(nullptr)
,_endofstorage(nullptr)
{
reserve(v.capacity());
for(const auto e : v)
push_back(e);//Can you adjust it directly?!
}
*/
vector<T>& operator=(const vector<T>& v) //Assignment construction
{
if (this != &v)
{
delete[] _start;
_start = new T[v.capacity()];
memcpy(_start, v._start, sizeof(T) * v.size);
}
return *this;
}
//You can also write:
/*vector<T>& operator=(vector<T> v)
{
::swap(_start, v._start);
::swap(_finish, v._finish);
::swap(_endofstorage, v._endofstorage);//You can synthesize them into a Swap function
return *this;
}*/
//If you want to exchange, it is not recommended to swap directly Because there will be three deep copies
//You can use v1 Swap (V2), which is just a copy of three pointers
void print_vector() const //Print
{
vector v = *this;
vector<int>::const_iterator it = v.begin();
while (it != v.end())
{
cout << *it << " ";
it++;
}
cout << endl;
}
size_t size() const //Returns size, that is, the number of elements
{
return _finish - _start;
}
size_t capacity() const //Returns capacity, that is, capacity size
{
return _endofstorage - _start;
}
void reserve(size_t n) //Redefine space size
{
if (n > capacity())
{
size_t sz = size();
T* tmp = new T[n]; //Re open up space in new areas
if (_start)
{
//memcpy(tmp, _start, sizeof(T) * sz);
for (size_t i = 0; i < sz; i++)
{
tmp[i] = _start[i];//If T is a custom type such as string, it will be processed according to the deep copy of string
} //Note that memcpy cannot be used here Because memcpy corresponds to a shallow copy, it just copies the corresponding address according to binary
delete[] _start;
}
_start = tmp;
_finish = tmp + sz;
_endofstorage = tmp + n;
}
}
const_iterator begin() const //Defines an iterator that returns the first element of the header
{
return _start; //Readable only
}
const_iterator end() const //Defines the iterator that returns the tail
{
return _finish; //Readable only
}
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
} //slightly
void push_back(const T& x) //Tail insertion
{
if (_finish == _endofstorage) //Q: do you want to increase capacity?
{
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcapacity);
}
*_finish = x;
_finish++;
}
T& operator[](size_t i) //Overload [] operator
{
assert(i < size());
return _start[i];
}
T& operator[](size_t i) const //Second version
{
assert(i < size());
return _start[i];
}
void pop_back() //Tail deletion
{
assert(_start < _finish);
--_finish;
}
void insert(iterator pos, const T& x) //insert
{
assert(pos <= _finish);
if (_finish == _endofstorage) //Judge whether to increase capacity
{
size_t n = pos - _start;
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcapacity);
pos = _start + n;
}
iterator end = _finish - 1;
while (end >= pos) //Move backward
{
*(end + 1) = *end;
--end;
}
*pos = x; //Insert in pos position
++_finish;
}
iterator erase(iterator pos) //delete
{
assert(pos < _finish);
iterator it = pos; //Move the back position forward
while (it < _finish)
{
*it = *(it + 1);
++it;
}
--_finish; //Door god who subtracts the last element
return pos;
}
void resize(size_t n,const T& val = T()) //Reopen element space size
{
if (n < this->size())
{
_finish = _start + n; //Q: is it larger than my original size?
}
else
{
if (n > capacity()) //Q: do you want to increase capacity
{
reserve(n);
}
while (_finish < _start + n) //Next, initialize the remaining new elements to val
{
*_finish = val;
++_finish;
}
}
}
private:
iterator _start; //Left pointer
iterator _finish; //Left close right open, right pointer
iterator _endofstorage; //Tail of capacity
};
}We can test:
(let the main function call these two functions)
void test_vector1()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
vector<int>::iterator it = v.begin();
while (it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
}
void test_vector2()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
vector<int>::iterator it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
{
it = v.erase(it);
}
else
{
it++;
}
}
v.print_vector();
}We get:
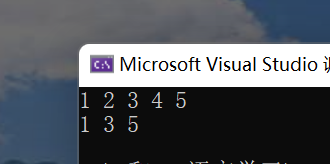
ok. The content about vector will be introduced here for the time being. We will meet again later when we brush the questions.
list class
For the list class, we focus on the simulation implementation of its iterator.
If vector is an array and a sequential list, then list is a linked list.
1. list is a sequential container that can be inserted and deleted at any position within the constant range, and the container can iterate back and forth.
2. The bottom layer of the list is a two-way linked list structure. Each element in the two-way linked list is stored in independent nodes that are not related to each other. In the node, the pointer points to the previous element and the latter element.
3. list and forward_list is very similar: the main difference is forward_list is a single linked list, which can only iterate forward, making it simpler and more efficient.
4. Compared with other sequential containers (array, vector, deque), list usually inserts and removes elements at any position, which is more efficient.
5. Compared with other sequential containers, list and forward_ The biggest drawback of the list is that it does not support random access to any location. For example, to access the sixth element of the list, you must iterate from a known location (such as the head or tail) to that location, which requires linear time overhead; The list also needs some extra space to hold the associated information of each node
To be more precise, our list is a two-way circular linked list.
Introduction to the usage of list
In fact, we can understand the usage of list by looking at the document. Because we already have the basis of the above string and vector.
list constructor

We can see that there are four ways to construct it.
In short, we can use iterator intervals to construct, fill directly, or copy.
For example:
int main(){
std::list<int> l1; // Construct empty l1
std::list<int> l2 (4,100); // Put four elements with a value of 100 in l2
std::list<int> l3 (l2.begin(), l2.end()); // An interval construction with [begin(), end()) of l2 being left closed and right open
make l3
std::list<int> l4 (l3); // Constructing l4 with l3 copy
// Construct l5 with array as iterator interval
int array[] = {16,2,77,29};
std::list<int> l5 (array, array + sizeof(array) / sizeof(int) );
// Print elements in l5 as iterators
for(std::list<int>::iterator it = l5.begin(); it != l5.end(); it++)
std::cout << *it << " ";
std::cout<<endl;
// Traversal of C++11 range for
for(auto& e : l5)
std::cout<< e << " ";
std::cout<<endl;
return 0;
}Then there are two ways to traverse the linked list.
One is to use the displayed iterator to traverse;
Another is to use the range for (essentially an iterator) (as in the above code)
Iterator for list

1. begin and end are forward iterators. Execute + + operation on the iterator, and the iterator moves backward
2. rbegin(end) and rend(begin) are reverse iterators. Execute + + operation on the iterator, and the iterator moves forward
These things are almost the same as string and vector. Just note that they are circular. The idea of this linked list was mentioned in the data structure.
Other member functions
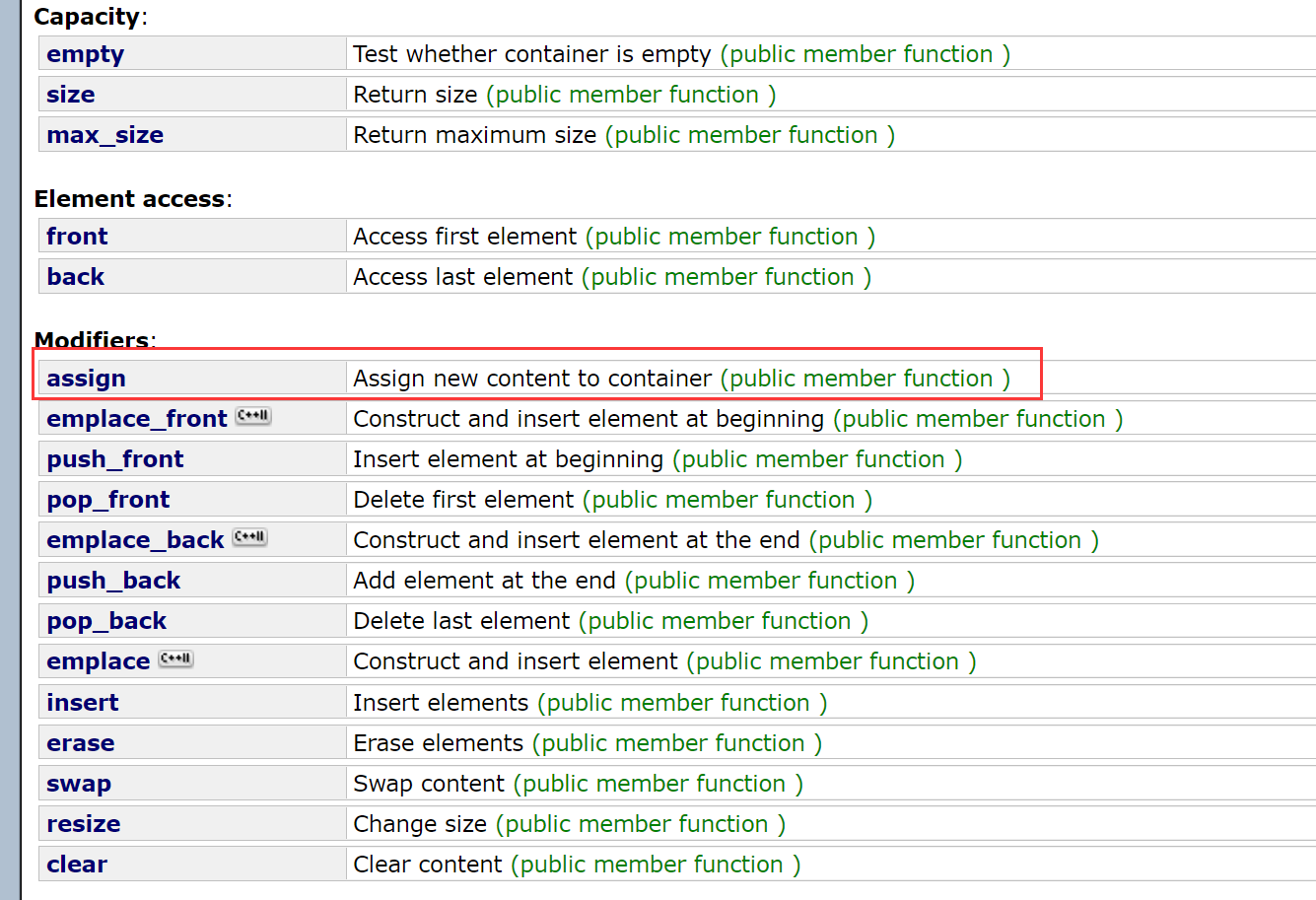
Let's say one here: assign (we'll take the rest in one stroke when simulating the implementation)
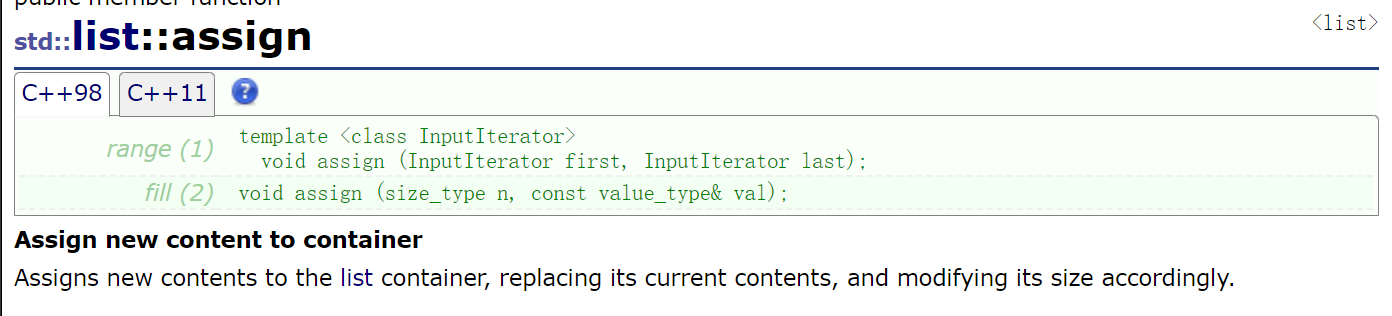
It means to clear the contents of the original linked list first, and then copy the val ues of n Vals into the new linked list.
Let's say again:

For splicing, that is, I can splice list & X into list (that is, the class calling the function)
The latter two are iterators, that is, the range of splicing.
Note: in the list, after using insert, the original iterator will not fail. However, when using erase, the used iterator will fail.
Simulation Implementation of list (highlight)
Before that, we need to put an idea:
Because the address of the bottom layer of the list is not continuous when it is stored, we need to implement + +; --* And other operations, we need to build an iterator class ourselves, encapsulate it, and then use it. This is also the focus of our simulation implementation of list.


Next, we simulate the implementation:
#include<iostream>
#include<assert.h>
namespace jxwd
{
template<class T>
struct _list_node //This structure is used to build nodes (i.e. the nodes of the linked list)
{
T val;
_list_node<T>* _next;
_list_node<T>* _prev;
_list_node(const T& x = T())
:val(x)
,_next(nullptr)
,_prev(nullptr)
{}
};
template <class T ,class Ref ,class Cal> //A class that encapsulates an iterator
struct _list_iterator
{
typedef _list_node<T> node; //Here, I just want to make a shallow copy
typedef _list_iterator<T,Ref,Cal> self; //Therefore, we do not write copy constructs, operator s and destructors here. The compiler can use those generated by default
node* _pnode; //Define a_ The pnode node, which is the underlying implementation of the iterator, is actually a pointer to a linked list node
_list_iterator(node* pnode) //Constructor of iterator class
:_pnode(pnode)
{ }
Ref operator*() //Dereference, return T & type
{
return _pnode->val;
}
Cal operator->() //Overload - > operator, return T*
{
return &_pnode->val;
}
bool operator!=(const self& s) const //The operator is overloaded, and two types of const or no are provided
{
return _pnode != s._pnode;
}
bool operator==(const self& s) const
{
return _pnode == s._pnode;
}
self& operator++() //Overload the pre + +, and return an iterator type
{
_pnode = _pnode->_next;
return *this;
}
//it++ -> it.operator++(&it,0)
//++it ->it.operator++(&it)
self operator++(int) //Overload the postposition + +, return the iterator without + +, and replace the iterator++
{
self tmp(*this);
_pnode = _pnode->_next;
return tmp;
}
self& operator--() //Same as + +
{
_pnode = _pnode->_prev;
return *this;
}
self operator--(int)
{
self tmp(*this);
_pnode = _pnode->_prev;
return tmp;
}
};
template<class T>
class list
{
typedef _list_node<T> node;
public:
typedef _list_iterator<T , T&, T*> iterator; //Rename the encapsulated iterator class to iterator
typedef _list_iterator<T, const T&,const T*> const_iterator;//Same as above, except that the definition requires another const type
iterator begin() //Returns the iterator of the first node
{
return iterator(_head->_next);
}
iterator end() //Returns the iterator of the next position of the last node (i.e. the head node)
{
return iterator(_head);
}
const_iterator begin() const //The second type
{
return const_iterator(_head->_next);
}
const_iterator end() const
{
return const_iterator(_head);
}
list() //Constructor
{
_head = new node;
_head-> _next = _head;
_head-> _prev = _head;
}
~list() //Destructor
{
clear();
delete _head;
_head = nullptr;
}
list(const list<T>& x) //copy construction
{
_head = new node;
_head->_next = _head;
_head->_prev = _head;
for (const auto& e : x)
{
push_back(e);
}
}
//list<int>& operator=(const list<T>& lt)
//{
// if (this != <)
// {
// clear();
// for (const auto& e : lt)
// {
// push_back(e);
// }
// }
// return *this;
//}//Traditional writing
list<T>& operator=(list<T>& lt) //Assignment operator overload
{
::swap(_head, lt._head);
return *this;
}
void clear()
{
iterator it = begin();
while (it != end())
{
it = erase(it);
}
}
void push_back(const T& x)
{
node* newnode = new node(x);
node* tail = _head->_prev;
tail->_next = newnode;
newnode->_prev = tail;
newnode->_next = _head;
_head->_prev = newnode;
//insert(end(),x); // Tail insertion, an idea of time reuse insert()
}
void push_front(const T& x)
{
insert(begin(), x);
}
void pop_back()
{
erase(--end());
}
void pop_front()
{
erase(begin());
}
void insert(iterator pos, const T& x) //Insert before pos
{
assert(pos._pnode);
node* cur = pos._pnode; //Relationship between three nodes
node* prev = cur->_prev;
node* newnode = new node(x);
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = cur;
cur->_prev = newnode;
}
iterator erase(iterator pos) //Delete pos node
{
assert(pos._pnode);
assert(pos != end());
node* prev = pos._pnode->_prev;
node* next = pos._pnode->_next;
delete pos._pnode;
prev->_next = next;
next->_prev = prev;
return iterator(next);
}
bool empty() //Judge whether it is empty
{
return begin() == end();
}
size_t size() //Calculate node number
{
size_t sz = 0;
iterator it = begin();
while (it != end())
{
sz++;
it++;
}
return sz;
}
private:
node* _head; //Define a sentinel position - head node
};
}Our simulation implementation here is mainly for the simulation of iterator encapsulation. We have omitted or omitted other linked list members.
We can test:
namespace jxwd{
void func()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
list<int> llt(lt);
list<int>::iterator it = llt.begin(); //Here is the copy construction of the returned iterator
while (it != llt.end())
{
std::cout << *it << " ";
++it;
}
std::cout << std::endl;
}
void test_list2()
{
list<int> lt;
lt.push_back(10);
lt.push_back(20);
list<int> lt2(lt);
list<int>::iterator it = lt2.begin();
while (it!=lt2.end())
{
std::cout << *it << " ";
it++;
}
}
}We test the above function in the main function and find that the program runs successfully. The following is a screenshot of the operation:
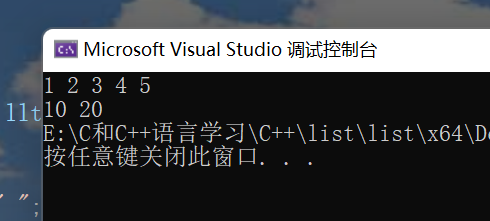
This shows that our simulation is successful.
It is also correct to use the encapsulation simulation of iterators.
Good!!!
As for the comparison between vector and list, it is actually the comparison between linked list and sequential list. If you want to see it, let's go over it again in the next section
Well, let's stop here first. I'll see you next time.
Off duty, off duty~~~~
Remember to pay attention to me!! 😀