In the article Introduction to PyTorch deep learning practice notes 9-SoftMax classifier Mr. Liu gave an after-school exercise and downloaded kaggle's Otto dataset Do more classification.
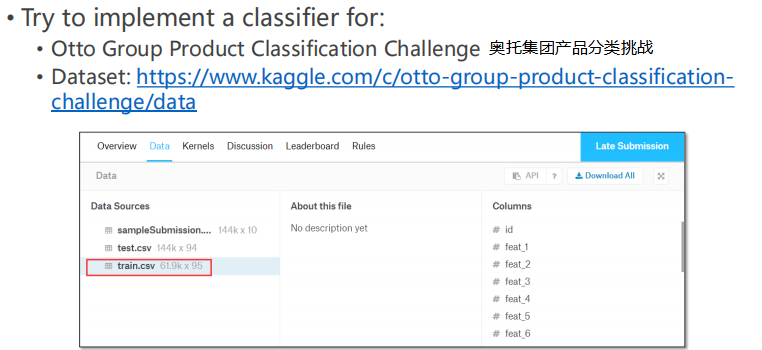
0 Overview
Let's take a look at the background of the official website.
The Otto Group is one of the world's biggest e-commerce companies, with subsidiaries in more than 20 countries, including Crate & Barrel (USA), Otto.de (Germany) and 3 Suisses (France). We are selling millions of products worldwide every day, with several thousand products being added to our product line.
[Otto group is one of the largest e-commerce companies in the world, with subsidiaries in more than 20 countries, including crite & barrel in the United States, Otto.de in Germany and 3 Suisse in France. We sell millions of products worldwide every day, of which thousands of products are added to our product line.]
A consistent analysis of the performance of our products is crucial. However, due to our diverse global infrastructure, many identical products get classified differently. Therefore, the quality of our product analysis depends heavily on the ability to accurately cluster similar products. The better the classification, the more insights we can generate about our product range.
[a consistent analysis of our product performance is crucial. However, due to our diversified global infrastructure, many of the same products are classified differently. Therefore, the quality of our product analysis depends largely on the ability to accurately cluster similar products. The better the classification, the more we know about the product range.]
For this competition, we have provided a dataset with 93 features for more than 200,000 products. The objective is to build a predictive model which is able to distinguish between our main product categories. The winning models will be open sourced.
[in this competition, we provided data sets containing 93 features for more than 200000 products. Our goal is to build a prediction model that can distinguish our main product categories. The winning model will be open source.]
1. Data acquisition
Click the official website link Otto Group Product Classification Challenge | Kaggle Can be downloaded.
2 view data
Read the data first, and then check the data.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#1. Read data
otto_data = pd.read_csv("./otto/train.csv")
otto_data.describe() #8 rows × 94 columns(id feat_1 ... feat_93)
otto_data.shape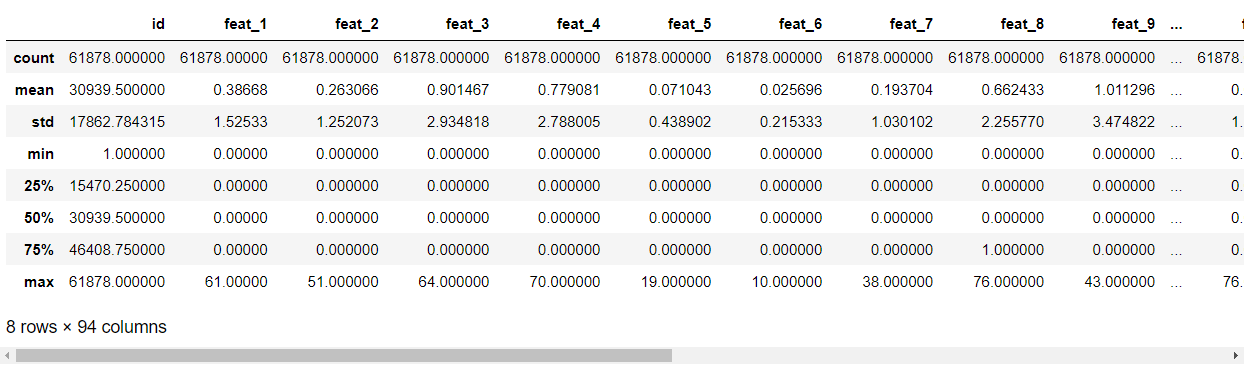
The train dataset has 61878 rows and 95 columns (including the above features and target). The simple description and statistical results of 94 non character features are shown in the figure above.
Since target is a character variable, we draw a picture and show the code as follows:
import seaborn as sns sns.countplot(otto_data["target"]) plt.show()
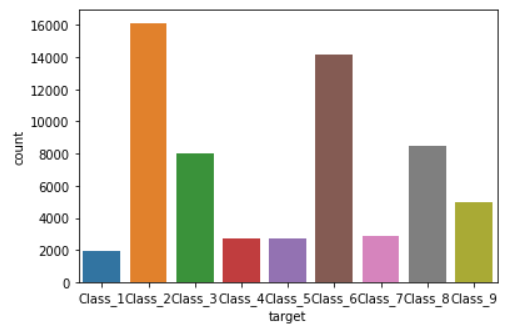
Target has 9 categories in total. Because it is character type, define a function to convert the category label of target into index representation, so as to facilitate the calculation of cross entropy later. The code is as follows:
def target2idx(targets):
target_idx = []
target_labels = ['Class_1', 'Class_2', 'Class_3', 'Class_4', 'Class_5', 'Class_6', 'Class_7', 'Class_8', 'Class_9','Class_10']
for target in targets:
target_idx.append(target_labels.index(target))
return target_idx3 build model
3.1 reading data
import numpy as np
import pandas as pd
from torch.utils.data import Dataset, DataLoader
import torch
import torch.optim as optim
#1. Read data
class OttoDataset(Dataset):
def __init__(self,filepath):
data = pd.read_csv(filepath)
labels = data['target']
self.len = data.shape[0]
self.X_data = torch.tensor(np.array(data)[:,1:-1].astype(float))
self.y_data = target2idx(labels)
def __getitem__(self, index):
return self.X_data[index], self.y_data[index]
def __len__(self):
return self.len
otto_dataset1 = OttoDataset('./otto/train.csv')
otto_dataset2 = OttoDataset('./otto/testn.csv')
train_loader = DataLoader(dataset=otto_dataset1, batch_size=64,
shuffle=True, num_workers=2)
test_loader = DataLoader(dataset=otto_dataset2, batch_size=64,
shuffle=False, num_workers=2)3.2 building models
#2. Build model
class OttoNet(torch.nn.Module):
def __init__(self):
super(OttoNet, self).__init__()
self.linear1 = torch.nn.Linear(93, 64)
self.linear2 = torch.nn.Linear(64, 32)
self.linear3 = torch.nn.Linear(32, 16)
self.linear4 = torch.nn.Linear(16, 9)
self.relu = torch.nn.ReLU()
self.dropout = torch.nn.Dropout(p=0.1)
self.softmax = torch.nn.Softmax(dim=1)
def forward(self, x):
x = x.view(-1,93)
x = self.relu(self.linear1(x))
x = self.relu(self.linear2(x))
x = self.dropout(x)
x = self.relu(self.linear3(x))
x = self.linear4(x)
x = self.softmax(x)
return x
ottomodel = OttoNet()
ottomodelOutput:
OttoNet( (linear1): Linear(in_features=93, out_features=64, bias=True) (linear2): Linear(in_features=64, out_features=32, bias=True) (linear3): Linear(in_features=32, out_features=16, bias=True) (linear4): Linear(in_features=16, out_features=9, bias=True) (relu): ReLU() (dropout): Dropout(p=0.1, inplace=False) (softmax): Softmax(dim=1) )
3.3 construct loss and optimizer
#3.loss and optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(ottomodel.parameters(), lr=0.01, momentum=0.56)
3.4 training model
if __name__ == '__main__':
for epoch in range(10):
running_loss = 0.0
for batch, data in enumerate(train_loader):
inputs, target = data
optimizer.zero_grad()
outputs = ottomodel(inputs.float())
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch % 500 == 499:
print('[%d, %5d] loss: %.3f' % (epoch+1, batch+1, running_loss/300))
running_loss = 0.0Output:
[1, 500] loss: 3.591 [2, 500] loss: 3.011 [3, 500] loss: 2.957 [4, 500] loss: 2.940 [5, 500] loss: 2.902 [6, 500] loss: 2.881 [7, 500] loss: 2.873 [8, 500] loss: 2.800 [9, 500] loss: 2.789 [10, 500] loss: 2.779
3.5 forecast
with torch.no_grad():
output = []
for data in test_loader:
inputs,labels = data
outputs = torch.max(ottomodel(inputs.float()),1)[1]
output.extend(outputs.numpy().tolist())Save the results and submit to kaggle.
submission = pd.read_csv('./otto/sampleSubmission.csv')#(144368, 10)
submission['target'] = output
submission.to_csv('./otto/submission_result1.csv', index=False)The submission failed, and the data format is incorrect. In the view of the reasons, small partners who encounter the same problems can tell me. Thank you.
Note: take study notes. If you make mistakes, please correct them! It's not easy to write an article. Please contact me for reprint.