The wechat technology account of "Wei Feng Chen" has been opened. In order to get the first-hand push of technical articles, you are welcome to search and pay attention!
At the beginning of the article, let's answer the questions left in the previous article, namely:
Why design multiple entities?
The layered architecture based on the principle of "separation of concerns" is a scheme we often use in application architecture design, such as the presentation layer, business logic layer, data access layer, persistence layer, etc. divided under the well-known MVC/MVP/MVVM architecture design mode. In order to maintain the independence of application architecture after layering, it is usually necessary to define different data models between various levels, so it is inevitable to face the problem of mutual transformation between data models.
Common data models at different levels include:
VO(View Object): a view object, which is used for the display layer and is associated with the display data of a specified page.
DTO(Data Transfer Object): data transfer object, which is used in the transport layer and generally refers to the data transmitted and interacted with the server.
DO(Domain Object): domain object, which is used in the business layer and the data required to execute specific business logic.
PO(Persistent Object): a persistent object, which is used in the persistence layer to persist the data stored locally.
Take messaging in instant messaging as an example:
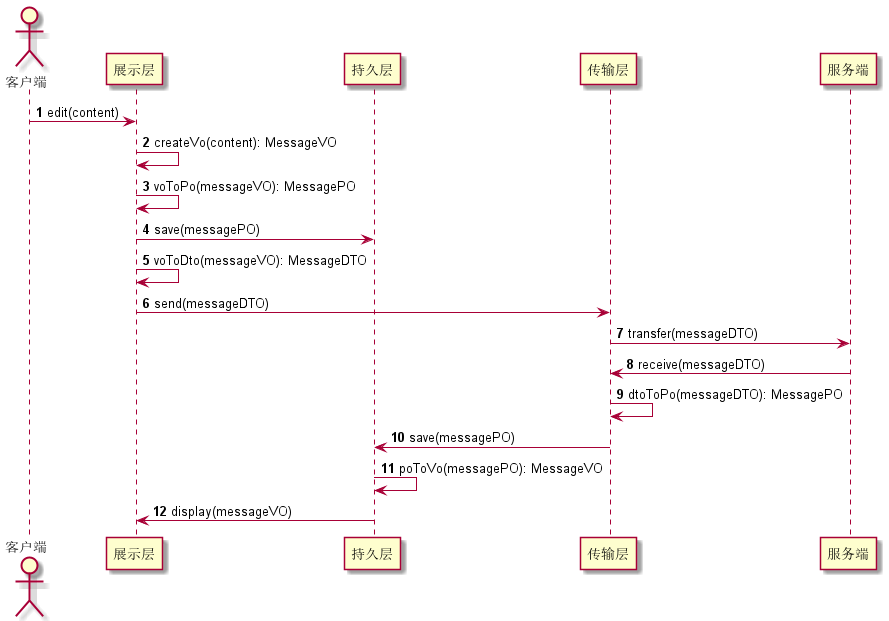
- After the client edits and sends the message on the session page, the data related to the message is constructed as MessageVO on the display layer and displayed in the chat record of the session page;
- After the display layer converts MessageVO to the MessagePO corresponding to the persistence layer, it calls the persistence layer persistence method to save the message to the local database or other places.
- After the presentation layer converts the MessageVO into the MessageDTO required by the transport layer, the transport layer transmits the data to the server
- As for the corresponding reverse operation, I believe you can also infer it, so I won't repeat it here.
In the last article, we manually wrote the mapping code in the way of get/set operation. This method is not only cumbersome and error prone. Considering that we have to do the same thing repeatedly when expanding other message types in the later stage, in order to improve the development efficiency, after some research, we decided to use MapStruct library to help us complete this thing in the form of automation.
What is MapStruct?
MapStruct is a code generator used to generate type safe, high-performance and dependency free mapping code.
What we need to do is to define a Mapper (Mapper) interface and declare the mapping method to be implemented. We can use the MapStruct annotation processor to generate the implementation class of the interface during compilation. The implementation class helps us complete the get/set operation in an automatic way to realize the mapping relationship between the source object and the target object.
Use of MapStruct
Add MapStruct dependency as Gradle:
Build at the module level Add to gradle file:
dependencies {
...
implementation "org.mapstruct:mapstruct:1.4.2.Final"
annotationProcessor "org.mapstruct:mapstruct-processor:1.4.2.Final"
}
If the Kotlin language is used in the project, you need to:
dependencies {
...
implementation "org.mapstruct:mapstruct:1.4.2.Final"
kapt("org.mapstruct:mapstruct-processor:1.4.2.Final")
}
Next, we will take the MessageVO and MessageDTO defined above as operation objects to practice how to use MapStruct to automatically complete the field mapping between them:
Create mapper interface
- Create a Java interface (also in the form of abstract classes) and add @ Mapper annotation to indicate that it is a Mapper:
- Declare a mapping method to specify the input parameter type and output parameter type:
@Mapper
public interface MessageEntityMapper {
MessageDTO.Message.Builder vo2Dto(MessageVO messageVo);
MessageVO dto2Vo(MessageDTO.Message messageDto);
}
Messagedto is used here Message. Builder instead of messagedto The reason for message is that the message generated by ProtoBuf uses the builder mode and sets the construction parameter to private in order to prevent direct external instantiation, which will cause MapStruct to report errors during compilation. As for the reason, you will understand it after reading the following contents.
Implicit mapping in default scenario
When the field name of the input parameter type is consistent with the field name of the output parameter type, MapStruct will help us implicitly map, that is, we don't need to deal with it actively.
The following types of automatic conversion are currently supported:
- Basic data type and its packaging type
- Between numeric types, but converting from a larger data type to a smaller data type (for example, from long to int) may result in a loss of precision
- Between basic data type and string
- Between enumeration type and string
- ...
This is actually an idea that convention is better than configuration:
convention over configuration, also known as programming by convention, is a software design paradigm, which aims to reduce the number of decisions that software developers need to make and obtain simple benefits without failure.
In essence, developers only need to specify the non-conforming parts of the application. If the agreement of the tools you use is consistent with your expectations, you can omit the configuration; Instead, you can configure to achieve the way you want.
Embodied in the MapStruct library, that is, we only need to configure the corresponding processing methods for those fields that the MapStruct library cannot help us complete implicit mapping.
For example, the names and data types of messageid, SenderID, targetid and timestamp fields of MessageVO and MessageDTO in our example are consistent, so we don't need to deal with them extra.
Field mapping processing in special scenarios
Inconsistent field names:
In this case, you only need to add @ Mapping annotation on the Mapping method to mark the name of the source field and the name of the target field.
For example, in our example, in message_ dto. The messageType defined in the proto file is an enumeration type, and ProtoBuf generates messagedto for us Message, an additional messageTypeValue is generated for us to represent the value of the enumeration type. We can complete the mapping from messageType to messageTypeValue by using the above method:
@Mapping(source = "messageType", target = "messageTypeValue")
MessageDTO.Message.Builder vo2Dto(MessageVO messageVo);
Inconsistent field types:
In this case, you only need to declare an additional mapping method for two different data types, that is, the mapping method with the type of source field as the input parameter type and the type of target field as the output parameter type.
MapStruct checks whether there is a mapping method. If there is, it will call the method in the implementation class of the mapper interface to complete the mapping.
For example, in our example, the content field is defined as bytes. For the generated messagedto The message class is represented by ByteString type, while the content field in MessageVO is of String type. Therefore, it is necessary to declare an additional byte2String mapping method and a string2Byte mapping method in the mapper interface:
default String byte2String(ByteString byteString) {
return new String(byteString.toByteArray());
}
default ByteString string2Byte(String string) {
return ByteString.copyFrom(string.getBytes());
}
For another example, instead of mapping messageType to messageTypeValue above, we want to directly complete the mapping from messageType to enumeration type. Then we can declare the following two mapping methods:
default int enum2Int(MessageDTO.Message.MessageType type) {
return type.getNumber();
}
default String byte2String(ByteString byteString) {
return new String(byteString.toByteArray());
}
Ignore some fields:
For special needs, some fields may be added to the data model of some levels to process specific businesses. These fields have no meaning to other levels, so it is not necessary to keep these fields in other levels. At the same time, in order to avoid errors caused by missing corresponding fields during MapStruct implicit mapping, We can add ignore = true to the annotation to ignore these fields:
For example, in our example, the messagedto generated by ProtoBuf Three additional fields mergeFrom, senderIdBytes and targetIdBytes are added to the message class. These three fields are not necessary for MessageVO, so MapStruct needs to help us ignore them:
@Mapping(target = "mergeFrom", ignore = true)
@Mapping(target = "senderIdBytes", ignore = true)
@Mapping(target = "targetIdBytes", ignore = true)
MessageDTO.Message.Builder vo2Dto(MessageVO messageVo);
Additional processing of other scenes
As we said earlier, due to messagedto The constructor of message is set to private, which leads to compilation errors. In fact, messagedto Message. The constructor of the Builder is also private, and the instantiation of the Builder is through messagedto Message. Newbuilder() method.
By default, MapStruct needs to call the default constructor of the target class to complete the mapping task, so we have no way?
In fact, MapStruct allows you to customize object factories, which will provide factory methods to call to get instances of the target type.
All we need to do is declare the return type of the factory method as our target type, then return the instance of the target type in the factory method in the desired way, and then add the use parameter in the @ Mapper annotation of the Mapper interface to pass in our factory class. MapStruct will automatically find the factory method first and complete the instantiation of the target type.
public class MessageDTOFactory {
public MessageDTO.Message.Builder createMessageDto() {
return MessageDTO.Message.newBuilder();
}
}
@Mapper(uses = MessageDTOFactory.class)
public interface MessageEntityMapper {
Finally, we define a member named INSTANCE, which calls mappers Getmapper () method, and pass in the mapper interface type to return a singleton of the mapper interface type.
public interface MessageEntityMapper {
MessageEntityMapper INSTANCE = Mappers.getMapper(MessageEntityMapper.class);
The complete mapper interface code is as follows:
@Mapper(uses = MessageDTOFactory.class)
public interface MessageEntityMapper {
MessageEntityMapper INSTANCE = Mappers.getMapper(MessageEntityMapper.class);
@Mapping(source = "messageType", target = "messageTypeValue")
@Mapping(target = "mergeFrom", ignore = true)
@Mapping(target = "senderIdBytes", ignore = true)
@Mapping(target = "targetIdBytes", ignore = true)
MessageDTO.Message.Builder vo2Dto(MessageVO messageVo);
MessageVO dto2Vo(MessageDTO.Message messageDto);
@Mapping(source = "messageTypeValue", target = "messageType")
default MessageDTO.Message.MessageType int2Enum(int value) {
return MessageDTO.Message.MessageType.forNumber(value);
}
default int enum2Int(MessageDTO.Message.MessageType type) {
return type.getNumber();
}
default String byte2String(ByteString byteString) {
return new String(byteString.toByteArray());
}
default ByteString string2Byte(String string) {
return ByteString.copyFrom(string.getBytes());
}
}
Automatically generate the implementation class of mapper interface
After the mapper interface is defined, when we rebuild the project, MapStruct will help us generate the implementation class of the interface. We can find the class in the path {module}/build/generated/source/kapt/debug / {package name} to find out the details:
public class MessageEntityMapperImpl implements MessageEntityMapper {
private final MessageDTOFactory messageDTOFactory = new MessageDTOFactory();
@Override
public Builder vo2Dto(MessageVO messageVo) {
if ( messageVo == null ) {
return null;
}
Builder builder = messageDTOFactory.createMessageDto();
if ( messageVo.getMessageType() != null ) {
builder.setMessageTypeValue( messageVo.getMessageType() );
}
if ( messageVo.getMessageId() != null ) {
builder.setMessageId( messageVo.getMessageId() );
}
if ( messageVo.getMessageType() != null ) {
builder.setMessageType( int2Enum( messageVo.getMessageType().intValue() ) );
}
builder.setSenderId( messageVo.getSenderId() );
builder.setTargetId( messageVo.getTargetId() );
if ( messageVo.getTimestamp() != null ) {
builder.setTimestamp( messageVo.getTimestamp() );
}
builder.setContent( string2Byte( messageVo.getContent() ) );
return builder;
}
@Override
public MessageVO dto2Vo(Message messageDto) {
if ( messageDto == null ) {
return null;
}
MessageVO messageVO = new MessageVO();
messageVO.setMessageId( messageDto.getMessageId() );
messageVO.setMessageType( enum2Int( messageDto.getMessageType() ) );
messageVO.setSenderId( messageDto.getSenderId() );
messageVO.setTargetId( messageDto.getTargetId() );
messageVO.setTimestamp( messageDto.getTimestamp() );
messageVO.setContent( byte2String( messageDto.getContent() ) );
return messageVO;
}
}
It can be seen that, as mentioned above, since the implementation class still completes field mapping with ordinary get/set method calls, reflection is not used in the whole process, and because the class is generated during compilation, the performance loss during run-time is reduced, so it meets the definition of "high performance".
On the other hand, when the attribute mapping is wrong, it can be known in time during the compilation period, which avoids the error reporting and crash at run time, and non empty judgment and other measures are added for some specific types, so it meets the definition of "type safety".
Next, we can replace the manually written mapping code with the mapping method of the mapper instance:
class EnvelopeHelper {
companion object {
/**
* Filling operation (VO - > dto)
* @param envelope Envelope class, containing the message view object
*/
fun stuff(envelope: Envelope): MessageDTO.Message? {
return envelope.messageVO?.run {
MessageEntityMapper.INSTANCE.vo2Dto(this).build()
} ?: null
}
/**
* Extraction operation (dto - > VO)
* @param messageDTO Message data transmission object
*/
fun extract(messageDTO: MessageDTO.Message): Envelope? {
with(Envelope()) {
messageVO = MessageEntityMapper.INSTANCE.dto2Vo(messageDTO)
return this
}
}
}
}
summary
As you can see, the final result is that we reduce a lot of template code to make the overall structure of the code easier to understand. In the later stage, we only need to add corresponding mapping methods to expand other types of objects, that is, we improve the readability / maintainability / scalability of the code at the same time.
MapStruct follows the principle that agreement is better than configuration, and helps us solve the cumbersome and error prone mutual transformation between different data models under the application layered architecture in an automated way as much as possible. It is really a sharp tool to greatly improve the development efficiency of developers!
The wechat technology account of "Wei Feng Chen" has been opened. In order to get the first-hand push of technical articles, you are welcome to search and pay attention!