B and B + trees
B tree and B + tree are data structures used for external search, and they are balanced multi-channel search trees. The differences between the two are as follows:
1. In B + tree, the node with n keywords contains n subtrees, that is, each keyword corresponds to a subtree, while in B tree, the node with n keywords contains (n+1) subtrees.
2. In the B + tree, except for the root node, the value range of the number of keywords n in each node is m/2~ m, and the value range of the root node n is 2~ m; In the B tree, except for the root node, the value range of the number of keywords n of all other non leaf nodes is [M / 2] - 1~m-1, and the value range of root node n is 1~m-1,
3. All leaf nodes in B + tree contain all keywords, that is, the keywords in other non leaf nodes are contained in leaf nodes, while in B tree, the keywords are not repeated.
4. All non leaf nodes in the B + tree only play the role of index, that is, each index item in the node only contains the maximum keyword of the corresponding subtree and the pointer to the subtree, and does not contain the storage address of the record corresponding to the keyword. In the B tree, each keyword corresponds to the storage address of a record.
5. Usually, there are two head pointers on the B + tree, one pointing to the root node and the other pointing to the leaf node with the smallest keyword. All leaf nodes are linked into an indefinite length linear linked list, so the B tree can only be searched randomly, while the B + tree can be searched randomly and sequentially
hash_map and unordered_map
hash_map: elements with duplicate key values will not be inserted
unordered_map: elements with duplicate key values will not be inserted
Usage example:
#include<unordered_map>
int main() {
pair<int, string> s1(2, "Li Ming"),s2(4,"Xiao Hong"),s3(5,"sink");
unordered_map<int, string>my;
my.insert(make_pair(1, "mary"));
my.insert(s2);
my.insert(s3);
unordered_map<int, string>::iterator it;
for (it = my.begin(); it != my.end(); it++)
cout << it->first << "," << it->second;
}
find method:
If the key exists, find returns the iterator corresponding to the key. If the key does not exist, find returns unordered_map::end
Design algorithms to remove duplicate elements
void deleteSame(int a[], int &n)
{
unordered_map<int, int>amap;
int k = 0;
for (int i = 0; i < n; i++)
{
if (amap.count(a[i]) == 0)
{
a[k] = a[i];//Modify the original array. Note that k starts from 0, so the repeated a[i] will be skipped
k++;
}
amap.insert(make_pair(a[i], i));//Insert a[i] as a keyword
}
n = k;//New length
}
Design an algorithm to find the element subscript whose sum of elements is target
#include<unordered_map>
vector<int>tSum(int a[], int n, int target)
{
int temp;
unordered_map<int, int>amap;
vector<int>vcc;
for (int i = 0; i < n; i++)
amap[a[i]] = i;//First, insert all the elements of a and use the element value as the key
for (int i = 0; i < n; i++)
{
temp = target - a[i];
if (amap.find(temp) != amap.end() && amap[temp] > i)//This statement indicates the condition for successful search
{
vcc.push_back(temp);
vcc.push_back(amap[temp]);
break;//sign out
}
}
return vcc;
}
Because unordered_ The lookup time of map table is constant, and the above time complexity is o(n), which is an efficient algorithm
Give a set of strings and return strings with the same modifier by group
#include<unordered_map>
void FindSame(vector<string>str, unordered_map<string, vector<string>>& tmap)
{
string temp;
vector<string>now;
//unordered_map<string, vector<string>>myhash;
unordered_map<string, vector<string>>::iterator it;
for (int i =0;i <str.size();i++)
{
temp = str[i];
sort(temp.begin(), temp.end());
now.clear();
now.push_back(str[i]);
it = tmap.find(temp);
if (tmap.find(temp) == tmap.end())
tmap.insert(make_pair(temp, now));//If not the same
else
it->second.push_back(str[i]);//If there are the same morphemes, put them into another unordermap
}
}
void display(unordered_map<string, vector<string>> tmap)
{
unordered_map<string, vector<string>>::iterator it;
vector<string>::iterator strit;
for (it = tmap.begin(); it != tmap.end(); it++)
{
cout << it->first << ":";
for (strit = it->second.begin(); strit != it->second.end(); strit++)
cout << *strit << ",";
cout << endl;
}
}
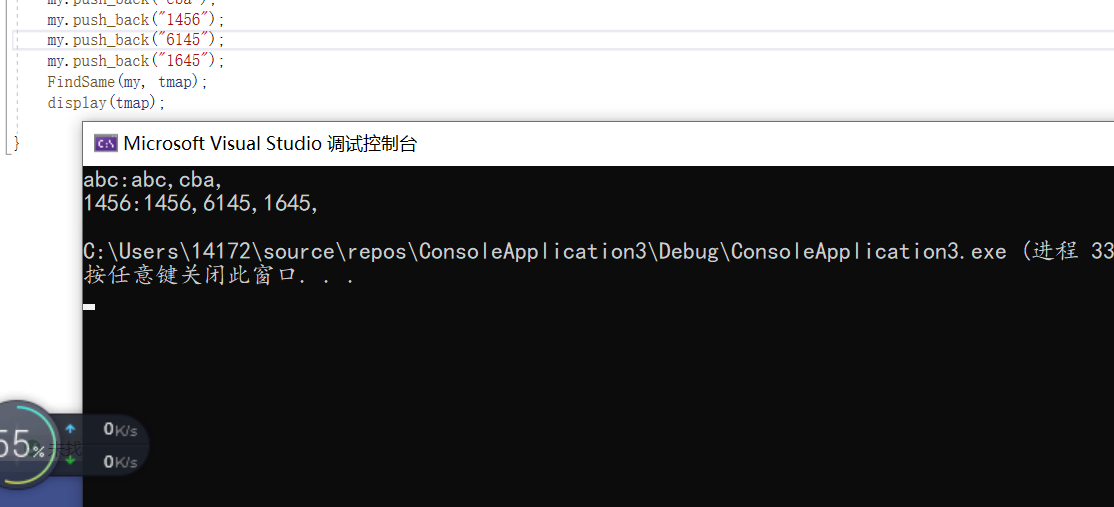
int main() {
unordered_map<string, vector<string>> tmap;
vector<string>my;
my.push_back("abc");
my.push_back("cba");
my.push_back("1456");
my.push_back("6145");
my.push_back("1645");
FindSame(my, tmap);
display(tmap);
}