Hello, I'm lex. I like bullying Superman. Lex
Areas of expertise: python development, network security penetration, Windows domain controlled Exchange architecture
Today's focus: analyze and cross Amazon's anti crawler mechanism step by step
it happened like this
Amazon is the world's largest shopping platform
Many commodity information, user evaluation and so on are the most abundant.
Today, hand in hand to take you across Amazon's anti crawler mechanism
Crawl for the products, reviews and other useful information you want
Anti reptile mechanism
However, when we want to use crawlers to crawl relevant data information
Large shopping malls like Amazon, TBao and JD
In order to protect their data information, they all have a perfect anti crawler mechanism
Try Amazon's anti crawl mechanism first
We use several different python crawler modules to test step by step
Finally, the anti climbing mechanism was successfully crossed.
1, urllib module
The code is as follows:
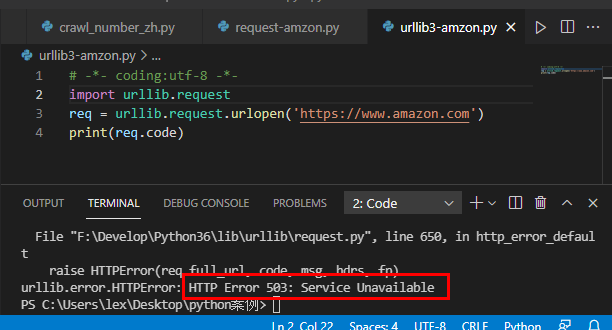
# -*- coding:utf-8 -*-
import urllib.request
req = urllib.request.urlopen('https://www.amazon.com')
print(req.code)Return result: status code: 503.
Analysis: Amazon identifies your request as a crawler and refuses to provide service.
With a scientific and rigorous attitude, let's try Baidu with 10000 people.
Return result: status code 200
Analysis: normal access
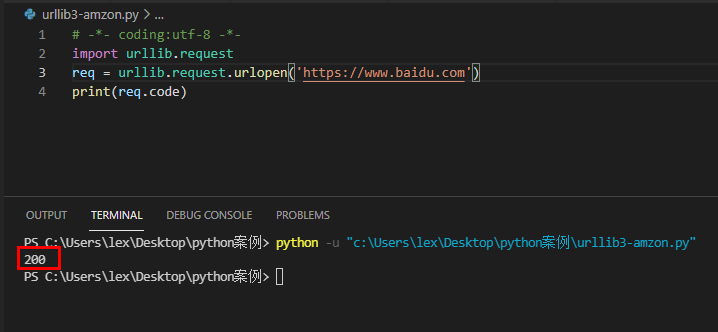
That shows that the request of urlib module is recognized as a crawler by Amazon and refuses to provide service
2, requests module
1. requests direct crawler access
The effect is as follows ↓↓
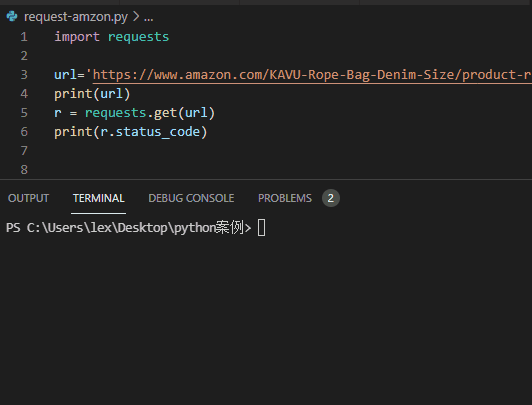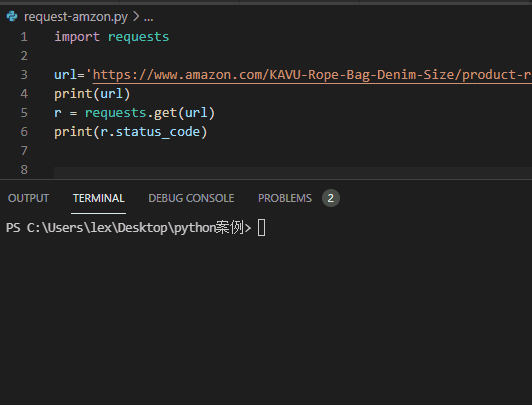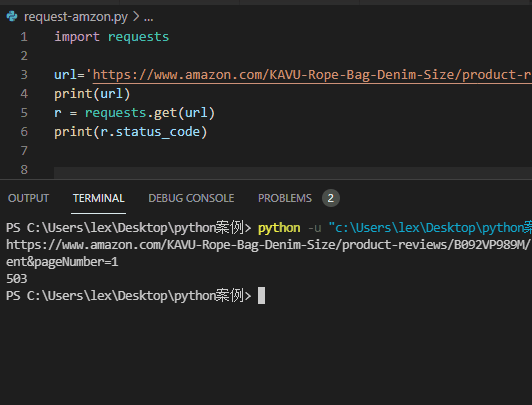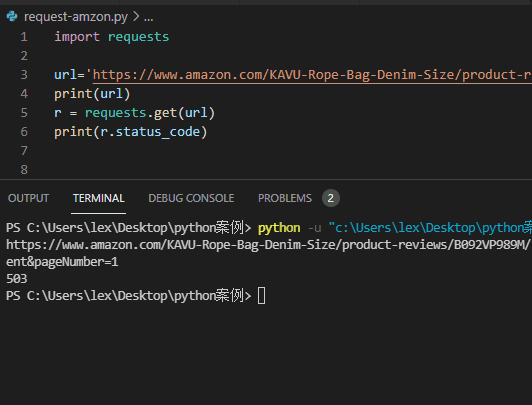
The code is as follows ↓↓
import requests url='https://www.amazon.com/KAVU-Rope-Bag-Denim-Size/product-reviews/xxxxxx' r = requests.get(url) print(r.status_code)
Return result: status code: 503.
Analysis: Amazon also rejected the request of requses module
Identify it as a crawler and refuse to provide service.
2. We add cookie s to requests
Add relevant information such as request cookie s
The effect is as follows ↓↓
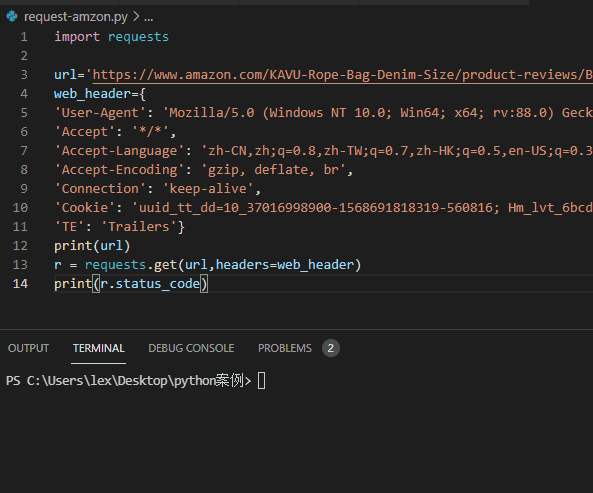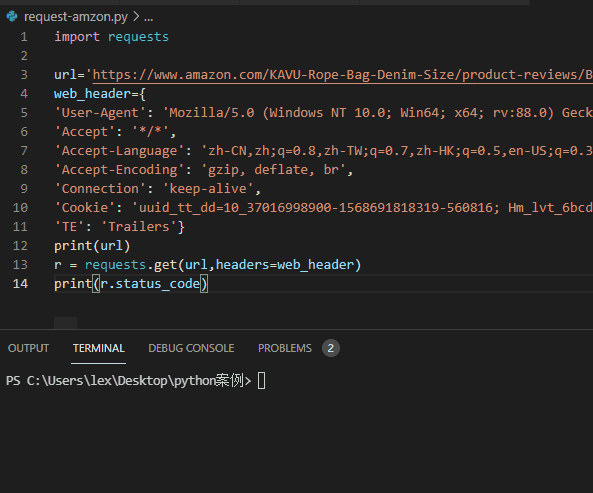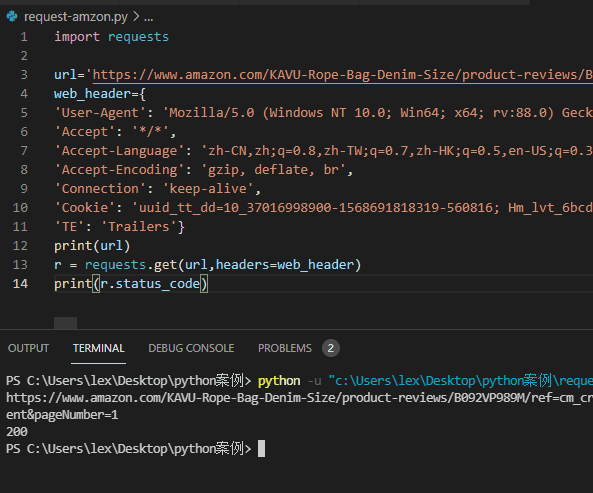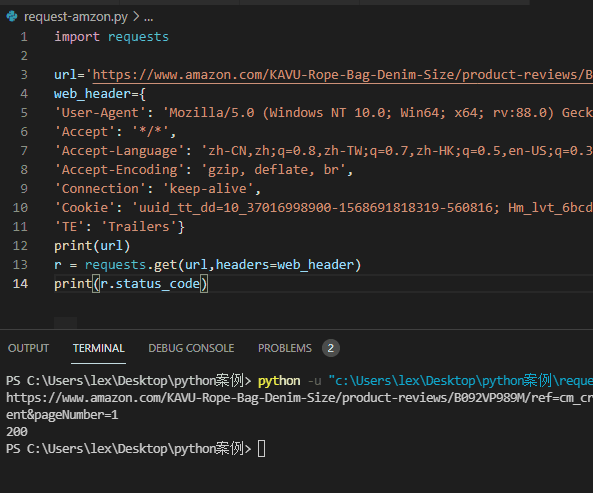
The code is as follows ↓↓
import requests
url='https://www.amazon.com/KAVU-Rope-Bag-Denim-Size/product-reviews/xxxxxxx'
web_header={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0',
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
'Cookie': 'Yours cookie value',
'TE': 'Trailers'}
r = requests.get(url,headers=web_header)
print(r.status_code)
Return result: status code: 200
Analysis: the returned status code is 200. It's normal. It smells like a reptile.
3. Check back page
Through the method of requests + cookies, we get the status code of 200
At present, at least Amazon's servers are providing services normally
We write the crawled page into the text and open it through the browser.
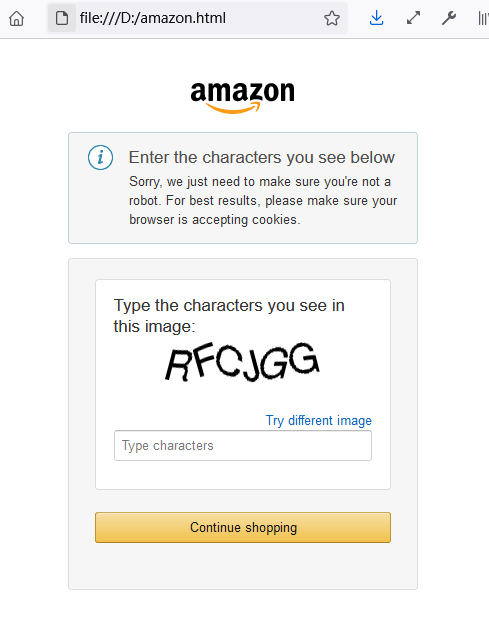
I step on a horse The return status is normal, but an anti crawler verification code page is returned.
Still blocked by Amazon.
3, selenium automation module
Installation of relevant selenium modules
pip install selenium
Introduce selenium into the code and set relevant parameters
import os
from requests.api import options
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
#selenium configuration parameters
options = Options()
#Configure headless parameters, that is, do not open the browser
options.add_argument('--headless')
#Configure selenium driver of Chrome browser
chromedriver="C:/Users/pacer/AppData/Local/Google/Chrome/Application/chromedriver.exe"
os.environ["webdriver.chrome.driver"] = chromedriver
#Combine parameter setting + browser drive
browser = webdriver.Chrome(chromedriver,chrome_options=options)Test access
url = "https://www.amazon.com" print(url) #Visit Amazon through selenium browser.get(url)
Return result: status code: 200
Analysis: the returned status code is 200, and the access status is normal. Let's take a look at the information of the web page we climbed to.
Save the web page source code locally
#Write the crawled web page information to the local file
fw=open('E:/amzon.html','w',encoding='utf-8')
fw.write(str(browser.page_source))
browser.close()
fw.close()
Open the local file we crawled and view it,
We have successfully crossed the anti crawler mechanism and entered the home page of Amazon
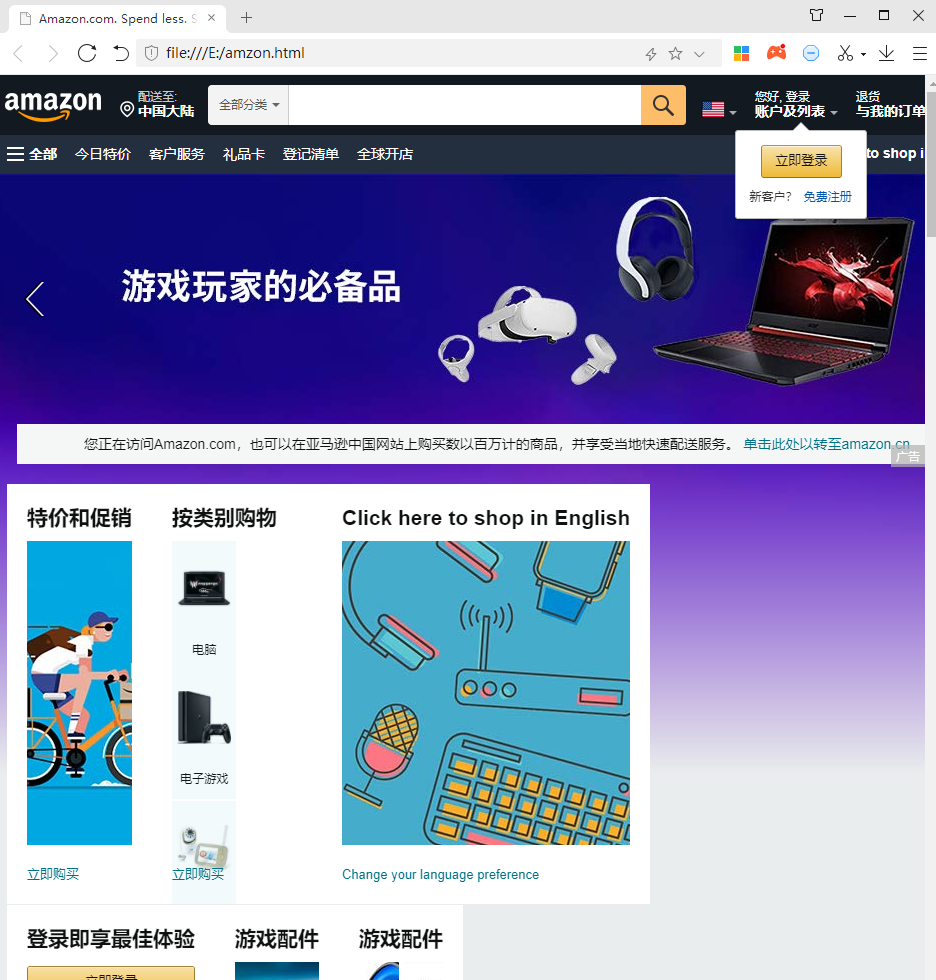
ending
Through selenium module, we can successfully cross
Amazon's anti crawler mechanism.
Next: let's continue to introduce how to crawl hundreds of thousands of Amazon Product information and comments.
[if you have any questions, please leave a message ~ ~]
Recommended reading
python actual combat
[python actual combat]For the ex girlfriend wedding, python cracked the WIFI at the wedding site and changed the name to
[python[actual combat] I forgot the password of the goddess album. I only wrote 20 lines of code in Python~~~
pygame series articles [subscribe to the column and get the complete source code]
Let's learn pygame together. 30 cases of game development (II) -- tower defense game
Let's learn pygame together. 30 cases of game development (4) -- Tetris games
Practical column of penetration test
Windows AD/Exchange management column
Linux high performance server construction
CSDN official learning recommendation ↓↓
The Python whole stack knowledge map produced by CSDN is too strong. I recommend it to you!
